基于AutoDL平台的3D_Gaussian_Splatting初体验
阅前声明:
本文主要使用AutoDL平台部署和体验3D高斯泼溅模型。
由于该平台提供了3d_gaussian_splatting的镜像,所以整体上部署难度较低。本文的侧重点是介绍Autodl平台的一些新手使用方法、感受3D高斯泼溅的实际效果。
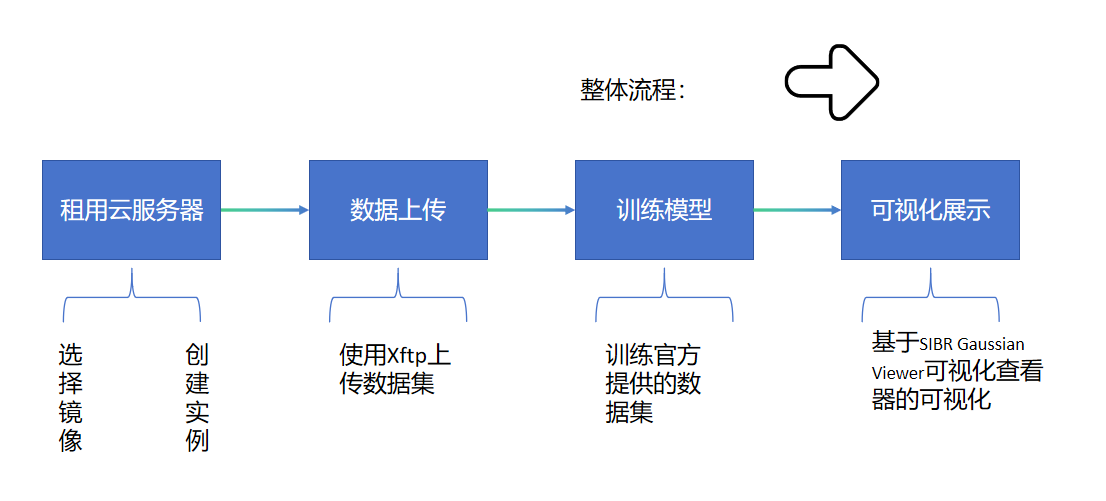
整个工作流程是:
官网项目链接:
GitHub - graphdeco-inria/gaussian-splatting: Original reference implementation of "3D Gaussian Splatting for Real-Time Radiance Field Rendering"
https://github.com/graphdeco-inria/gaussian-splatting
1、租用云服务器:
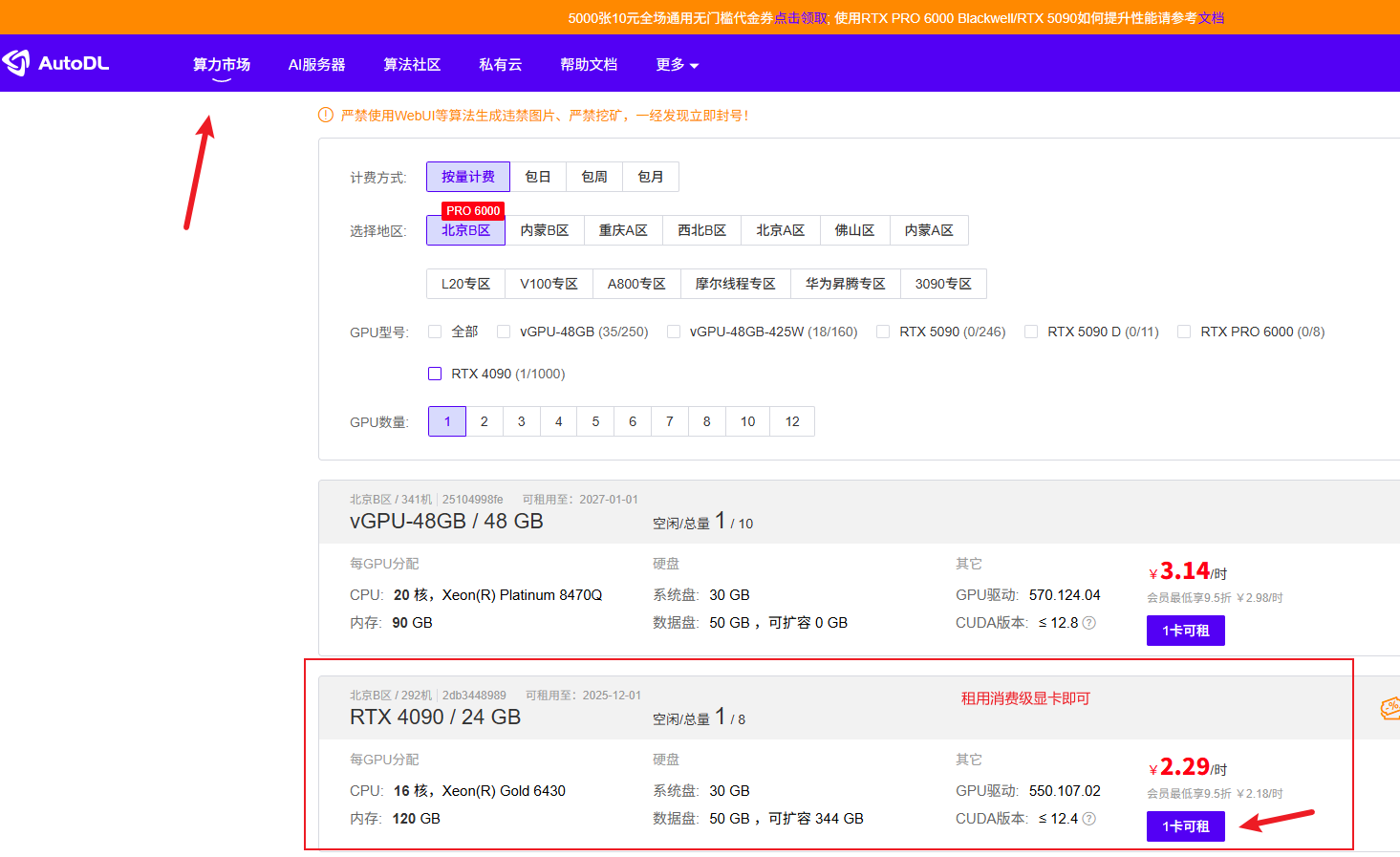
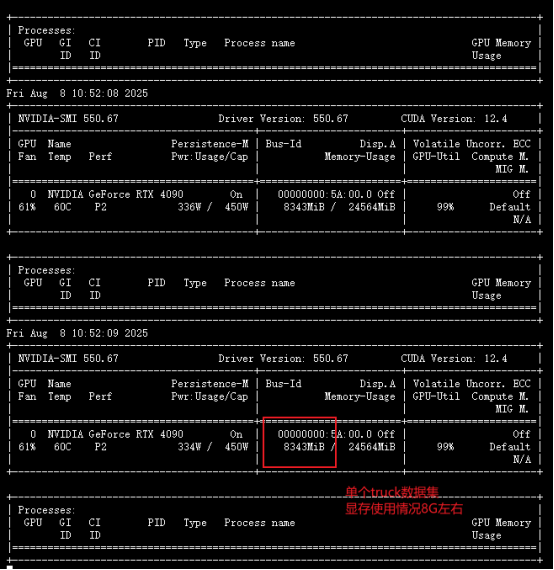
注册Autodl的账号,在算力市场里找到一台空闲多的显卡集群进行租用即可。这里有一点要注意,也是我踩得最大的一个坑之一:一定要租用消费级的显卡,显存24G大小的就足够了(在实际测试中,直接运行官方的代码,不做任何参数上的修改,训练单个数据集的显存占用大概是8GB)。不要租用V100,A800之类的算力卡。不清楚是官方代码的原因还是云端服务器商的原因,使用这两种算力卡会出现爆显存的问题,虽然他们的显存非常大!
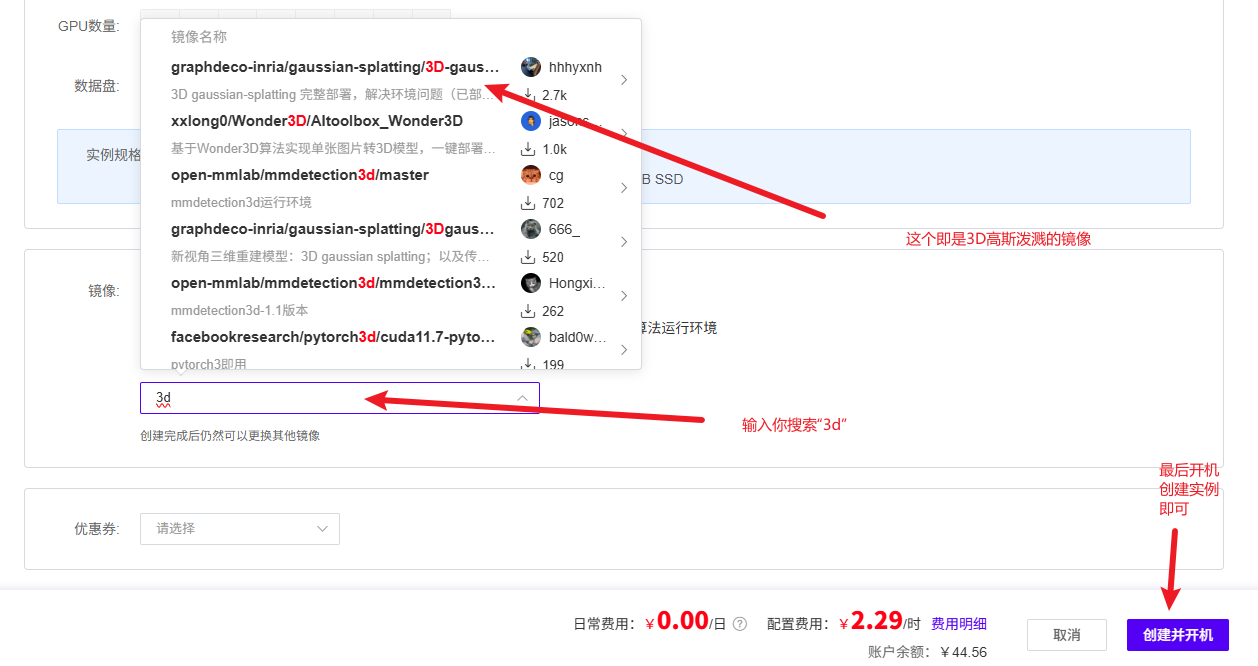
在社区镜像里进行搜索,就可以找到需要的镜像文件。
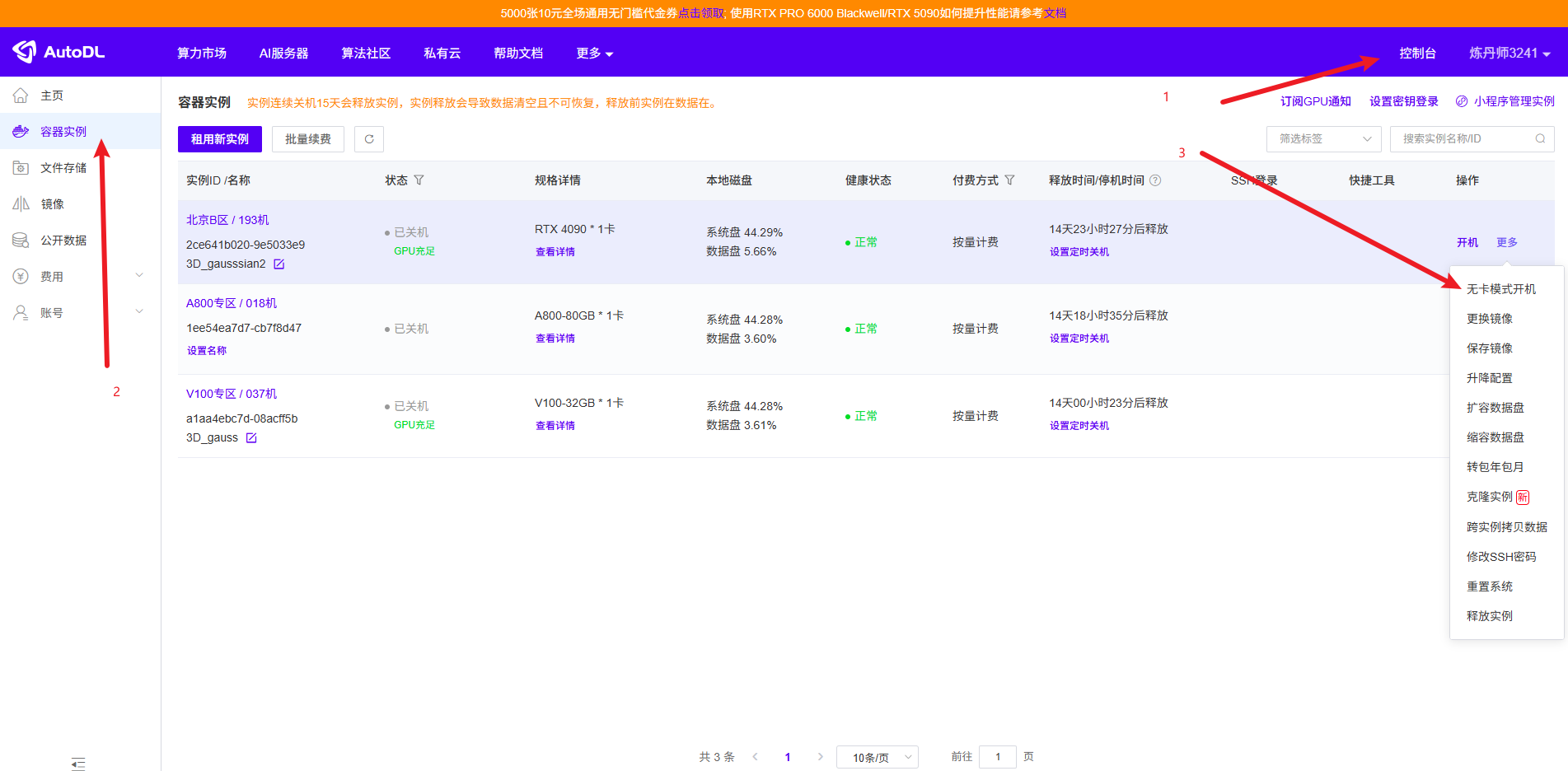
开机之后,在控制台的容器实例里,就可以找到自己租用的云服务器了。
在第一次开机时,默认是带有显卡开机的,因为后面需要上传数据或者进行环境配置之类,为了省钱,可以立马关机,然后选择无卡模式卡机,这样的话费用会低很多。
2、数据上传
3D高斯泼溅模型训练出来的模型不是通用模型,这项技术本质上是对某个物体进行3D重建,所以针对每一个物体,都需要对应的数据集去训练,然后才能够重建出来。每重建一个物体,就需要训练一次,对应的数据集也即不同的物体照片。
如果想重建自己身边的物体,那么就需要个人数据集。个人数据的制作需要使用colmap工具,这里先不做具体的使用方法。这里仅提供使用官方数据集进行物体重建的方法介绍。
官方数据集的下载链接是:
https://repo-sam.inria.fr/fungraph/3d-gaussian-splatting/

这个650M的就是数据集。
这个数据集提供了四种可以重建的物体,这里我选择的是truck这个物体,图方便的话,大家也可以先使用这个数据。
第一步:创建data文件夹
可以现将整个truck文件夹剪切出来,放入一个data文件夹中,如图所示:
第二步:data文件夹的上传
Autodl平台如果直接上传文件的话,只能一个文件一个文件的上传。一次性上传多个文件一般有两种方式:①通过autodl提供的文件存储,上传压缩包的形式;②使用第三方的如xftp之类的软件,可以直接跨系统,且能够直接上传文件夹;
这里采用第二种方法。
下载、安装XFTP的办法大家可自行搜索。这个软件是可以免费使用的,也不需要注册账号,免费版本在官网是通过点击那个“免费协议”跳转进去的。
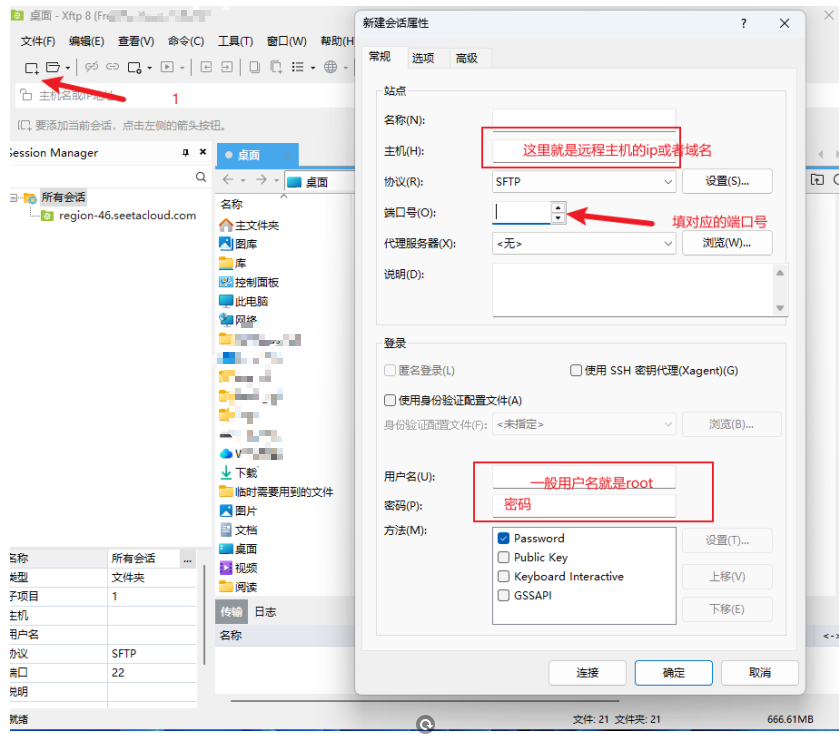
在使用XFTP的时候,需要输入远程服务器的ip/域名,密码之类的,在autodl上都可以找到。

复制远程连接的登录指令一般结构是这样的:

最后,域名、端口号、密码、用户名填进去就可以了。名称这一栏随便填。最后击连接。
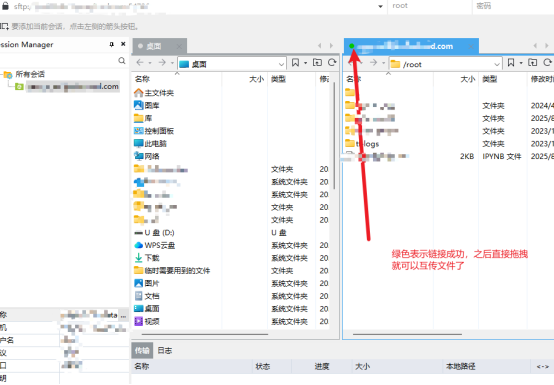
连接成功之后直接互相拖转就可以实现文件的互传。
为了保证运行时磁盘空间的大小,这里建议把:gaussian-splatting文件夹放在autodl-tmp中,然后把data文件夹拖入gaussian-splatting文件夹中。
整体的文件结构如图所示:
3、训练模型
成功上传数据后,先激活虚拟环境,然后跳转到含有train.py脚本的目录下,在终端使用指令:
python train.py -s data/truck/ -m data/truck/output
即可训练模型啦。
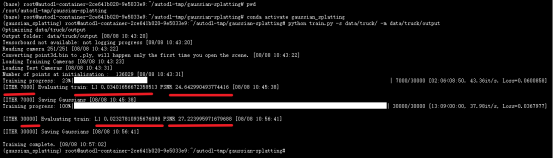
成功训练模型示意图:
具体的参数调整可参考官方介绍文档。
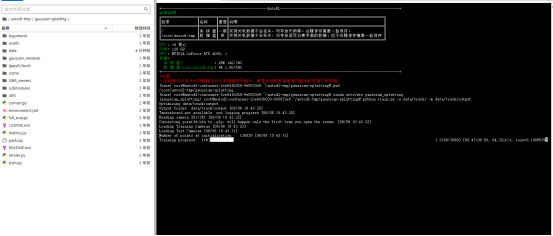
训练过程中显存使用情况:
loss值和psnr值情况:
4、可视化展示
这里使用的是官方提供的SIBR Gaussian Viewer可视化查看器,下载地址是:
https://repo-sam.inria.fr/fungraph/3d-gaussian-splatting/binaries/viewers.zip
模型训练完成后,可以将保存输出结果的output文件夹下载到本地,然后将output和上面的那个可视化工具解压到同一个目录下。
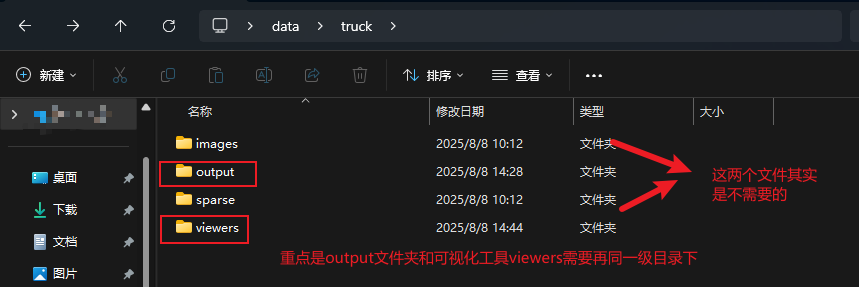
之后在该目录下开启终端,使用命令:
.\viewers\bin\SIBR_gaussianViewer_app -m data/output
即可获得模型重建的效果。
需要说明的是,这个过程是在本地电脑上实现的,没有使用远程服务器进行可视化。
关于这个可视化工具,可以使用w,a,s,d,q,e来进行位置移动,u,i,o,j,k,l来进行视角的移动。
如果是直接运行这个可视化工具的话,它使用的是最后一个30000轮的模型。想分别查看七千和三万两个模型的效果,可以直接将output中的某个结果暂时移除,来进行查看。
5、效果展示





就个人感觉来说,三万轮较之七千轮,提升的效果还是比较明显的。