SpringCloud(4)-多机部署,负载均衡-LoadBalance
1. 负载均衡介绍
1.1 问题描述
观察上个章节远程调⽤的代码
List<ServiceInstance> instances = discoveryClient.getInstances("productservice");//服务可能有多个, 获取第⼀个EurekaServiceInstance instance = (EurekaServiceInstance) instances.get(0);1. 根据应⽤名称获取了服务实例列表
2. 从列表中选择了⼀个服务实例
思考: 如果⼀个服务对应多个实例呢? 流量是否可以合理的分配到多个实例呢?
现象观察:
我们再启动2个product-service实例
选中要启动的服务, 右键选择 Copy Configuration...
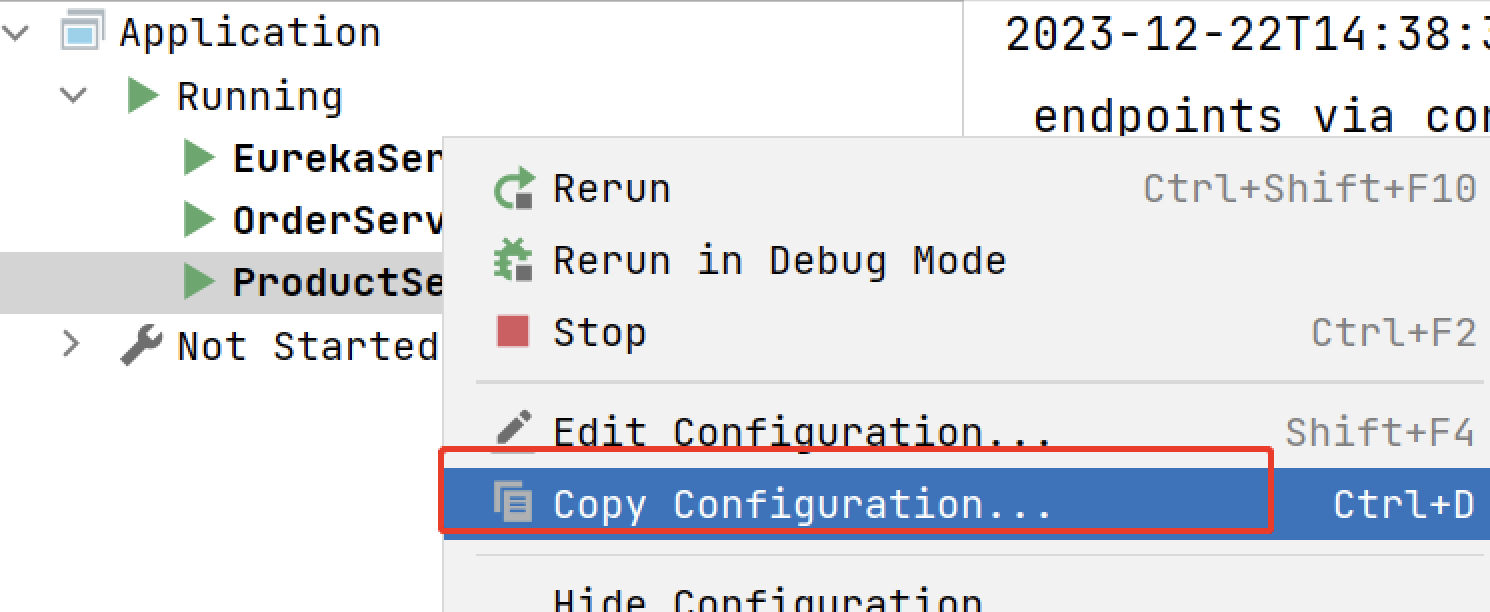
在弹出的框中, 选择 Modify options -> Add VM options
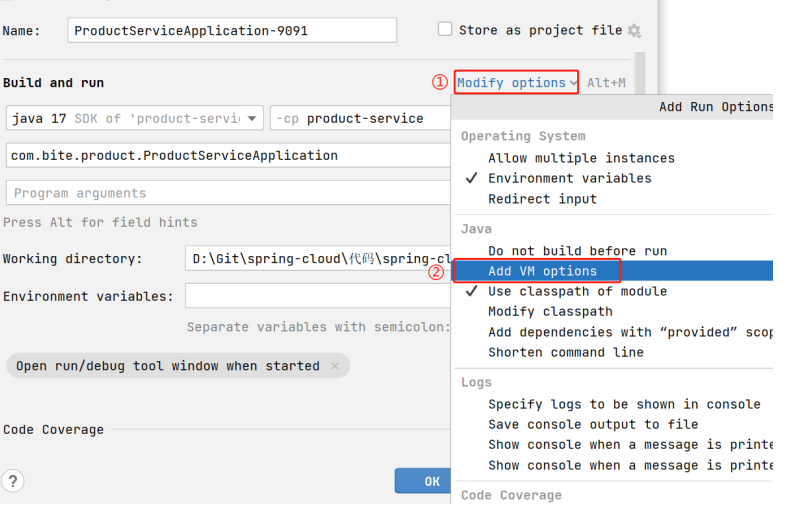
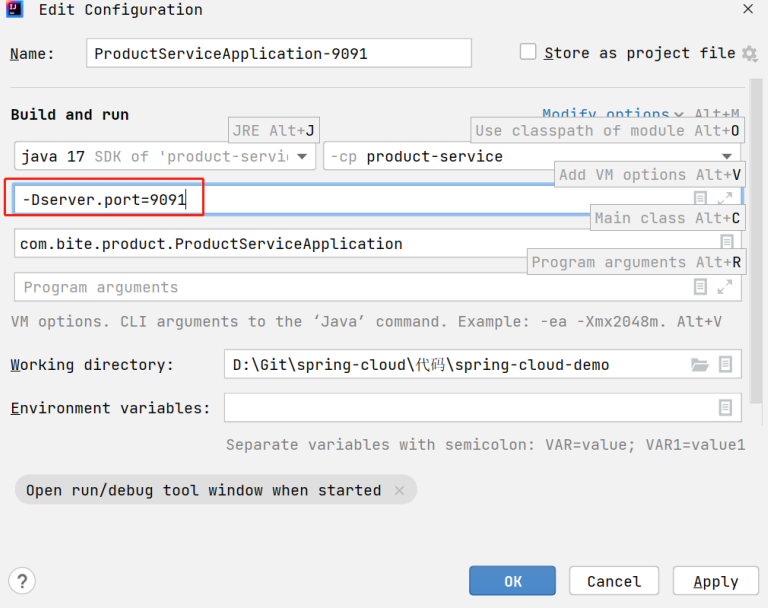
添加 VM options : -Dserver.port=9091
9091 为服务启动的端⼝号, 根据⾃⼰的情况进⾏修改
现在IDEA的Service窗⼝就会多出来⼀个启动配置, 右键启动服务就可以
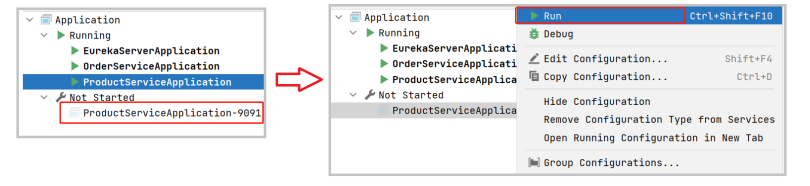
同样的操作, 再启动1个实例, 共启动3个服务
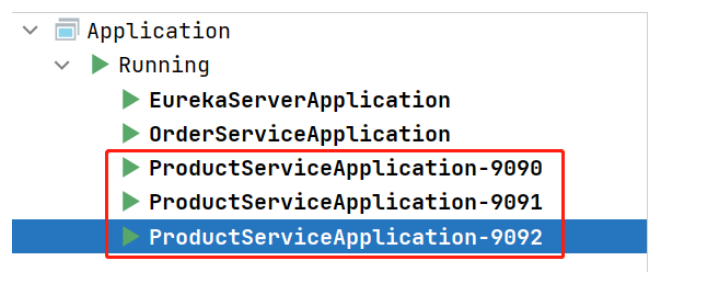
观察Eureka, 可以看到product-service下有三个实例:
访问结果:
访问:http://127.0.0.1:8080/order/1
11:46:05.684+08:00 INFO 23128 --- [nio-8080-exec-1]
com.bite.order.service.OrderService : LUCF:product-service:909011:46:06.435+08:00 INFO 23128 --- [nio-8080-exec-2]
com.bite.order.service.OrderService : LUCF:product-service:909011:46:07.081+08:00 INFO 23128 --- [nio-8080-exec-3]
com.bite.order.service.OrderService : LUCF:product-service:9090通过⽇志可以观察到, 请求多次访问, 都是同⼀台机器.
这肯定不是我们想要的结果, 我们启动多个实例, 是希望可以分担其他机器的负荷, 那么如何实现呢?
解决⽅案:
我们可以对上述代码进⾏简单修改:
private static AtomicInteger atomicInteger = new AtomicInteger(1);private static List<ServiceInstance> instances;@PostConstructpublic void init(){//根据应⽤名称获取服务列表instances = discoveryClient.getInstances("product-service");}public OrderInfo selectOrderById(Integer orderId) {OrderInfo orderInfo = orderMapper.selectOrderById(orderId);//String url = "http://127.0.0.1:9090/product/"+ orderInfo.getProductId();//服务可能有多个, 轮询获取实例int index = atomicInteger.getAndIncrement() % instances.size();ServiceInstance instance =instances.get(index);log.info(instance.getInstanceId());//拼接urlString url = instance.getUri()+"/product/"+ orderInfo.getProductId();ProductInfo productInfo = restTemplate.getForObject(url, ProductInfo.class);orderInfo.setProductInfo(productInfo);return orderInfo;}观察日志:
12:02:13.245+08:00 INFO 1800 --- [nio-8080-exec-1]
com.bite.order.service.OrderService : LUCF:product-service:909112:02:15.723+08:00 INFO 1800 --- [nio-8080-exec-2]
com.bite.order.service.OrderService : LUCF:product-service:909012:02:16.534+08:00 INFO 1800 --- [nio-8080-exec-3]
com.bite.order.service.OrderService : LUCF:product-service:909212:02:16.864+08:00 INFO 1800 --- [nio-8080-exec-4]
com.bite.order.service.OrderService : LUCF:product-service:909112:02:17.078+08:00 INFO 1800 --- [nio-8080-exec-5]
com.bite.order.service.OrderService : LUCF:product-service:909012:02:17.260+08:00 INFO 1800 --- [nio-8080-exec-6]
com.bite.order.service.OrderService : LUCF:product-service:909212:02:17.431+08:00 INFO 1800 --- [nio-8080-exec-7]
com.bite.order.service.OrderService : LUCF:product-service:9091通过⽇志可以看到, 请求被均衡的分配在了不同的实例上, 这就是负载均衡.
1.2 什么是负载均衡
负载均衡(Load Balance,简称 LB) , 是⾼并发, ⾼可⽤系统必不可少的关键组件.当服务流量增⼤时, 通常会采⽤增加机器的⽅式进⾏扩容, 负载均衡就是⽤来在多个机器或者其他资源中, 按照⼀定的规则合理分配负载.
⼀个团队最开始只有⼀个⼈, 后来随着⼯作量的增加, 公司⼜招聘了⼏个⼈. 负载均衡就是: 如何把⼯作量均衡的分配到这⼏个⼈⾝上, 以提⾼整个团队的效率
1.3 负载均衡的⼀些实现
上⾯的例⼦中, 我们只是简单的对实例进⾏了轮询, 但真实的业务场景会更加复杂. ⽐如根据机器的配置进⾏负载分配, 配置⾼的分配的流量⾼, 配置低的分配流量低等.
类似企业员⼯: 能⼒强的员⼯可以多承担⼀些⼯作.
服务多机部署时, 开发⼈员都需要考虑负载均衡的实现, 所以也出现了⼀些负载均衡器, 来帮助我们实现负载均衡.
负载均衡分为服务端负载均衡和客⼾端负载均衡.
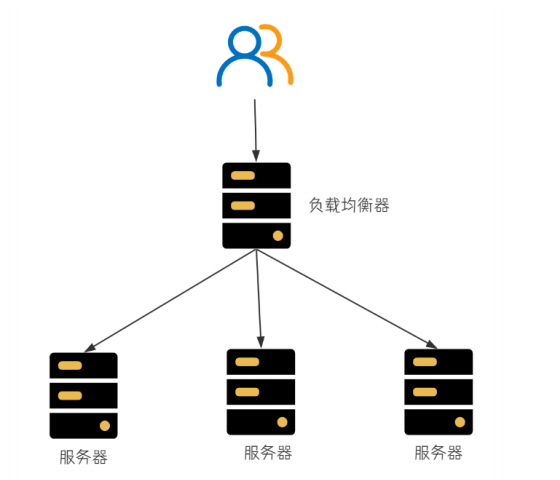
服务端负载均衡
在服务端进⾏负载均衡的算法分配.
⽐较有名的服务端负载均衡器是Nginx. 请求先到达Nginx负载均衡器, 然后通过负载均衡算法, 在多个服务器之间选择⼀个进⾏访问
客⼾端负载均衡
在客⼾端进⾏负载均衡的算法分配.
把负载均衡的功能以库的⽅式集成到客⼾端, ⽽不再是由⼀台指定的负载均衡设备集中提供.
⽐如Spring Cloud的Ribbon, 请求发送到客⼾端, 客⼾端从注册中⼼(⽐如Eureka)获取服务列表, 在发送请求前通过负载均衡算法选择⼀个服务器,然后进⾏访问.
Ribbon是Spring Cloud早期的默认实现, 由于不维护了, 所以最新版本的Spring Cloud负载均衡集成的是Spring Cloud LoadBalancer(Spring Cloud官⽅维护)
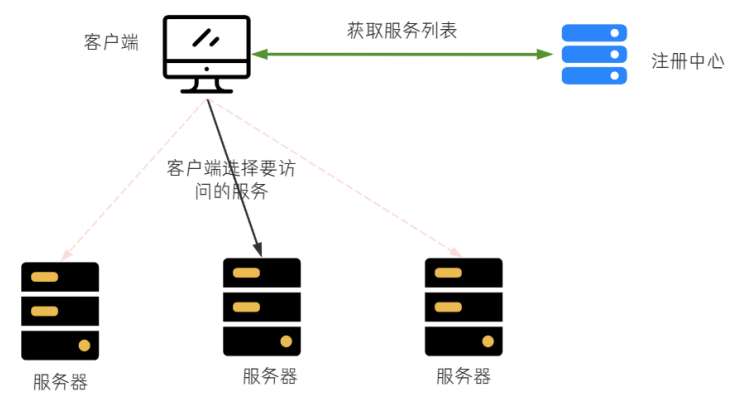
客⼾端负载均衡和服务端负载均衡最⼤的区别在于服务清单所存储的位置
2. Spring Cloud LoadBalancer
2.1 快速上⼿
SpringCloud 从 2020.0.1 版本开始, 移除了Ribbon 组件,使⽤Spring Cloud LoadBalancer 组件来代替 Ribbon 实现客⼾端负载均衡.
2.1.1 使⽤Spring Cloud LoadBalancer实现负载均衡
1. 给 RestTemplate 这个Bean添加 @LoadBalanced 注解就可以
@Configurationpublic class BeanConfig {@Bean@LoadBalancedpublic RestTemplate restTemplate(){return new RestTemplate();}}2. 修改IP端⼝号为服务名称
public OrderInfo selectOrderById(Integer orderId) {OrderInfo orderInfo = orderMapper.selectOrderById(orderId);//String url = "http://127.0.0.1:9090/product/"+ orderInfo.getProductId();String url = "http://product-service/product/"+ orderInfo.getProductId();ProductInfo productInfo = restTemplate.getForObject(url, ProductInfo.class);orderInfo.setProductInfo(productInfo);return orderInfo;}2.1.2 启动多个product-service实例
按照上⼀章节的⽅式, 启动多个product-service实例
2.1.3 测试负载均衡
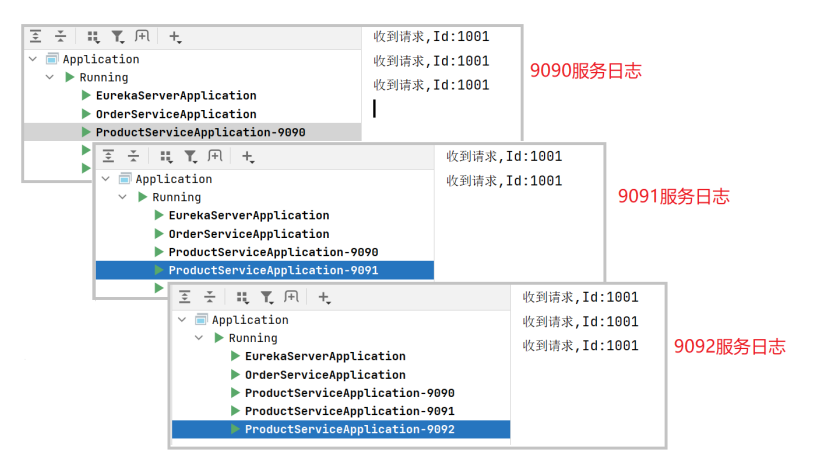
连续多次发起请求: http://127.0.0.1:8080/order/1
观察product-service的⽇志, 会发现请求被分配到这3个实例上了
2.2 负载均衡策略
负载均衡策略是⼀种思想, ⽆论是哪种负载均衡器, 它们的负载均衡策略都是相似的. Spring Cloud LoadBalancer 仅⽀持两种负载均衡策略: 轮询策略 和 随机策略
1. 轮询(Round Robin): 轮询策略是指服务器轮流处理⽤⼾的请求. 这是⼀种实现最简单, 也最常⽤的策略. ⽣活中也有类似的场景, ⽐如学校轮流值⽇, 或者轮流打扫卫⽣.
2. 随机选择(Random): 随机选择策略是指随机选择⼀个后端服务器来处理新的请求.
⾃定义负载均衡策略
Spring Cloud LoadBalancer 默认负载均衡策略是 轮询策略, 实现是 RoundRobinLoadBalancer, 如果服务的消费者如果想采⽤随机的负载均衡策略, 也⾮常简单.
参考官⽹地址:Spring Cloud LoadBalancer :: Spring Cloud Commons
1. 定义随机算法对象, 通过 @Bean 将其加载到 Spring 容器中
此处使⽤Spring Cloud LoadBalancer提供的 RandomLoadBalancer
import org.springframework.cloud.client.ServiceInstance;import org.springframework.cloud.loadbalancer.core.RandomLoadBalancer;import org.springframework.cloud.loadbalancer.core.ReactorLoadBalancer;import org.springframework.cloud.loadbalancer.core.ServiceInstanceListSupplier;import org.springframework.cloud.loadbalancer.support.LoadBalancerClientFactory;import org.springframework.context.annotation.Bean;import org.springframework.core.env.Environment;public class LoadBalancerConfig {@BeanReactorLoadBalancer<ServiceInstance> randomLoadBalancer(Environment environment,LoadBalancerClientFactory loadBalancerClientFactory) {String name=environment.getProperty(LoadBalancerClientFactory.PROPERTY_NAME);System.out.println("=============="+name);return new RandomLoadBalancer(loadBalancerClientFactory.getLazyProvider(name, ServiceInstanceListSupplier.class), name);}}💡 注意: 该类需要满⾜:
1. 不⽤ @Configuration 注释
2. 在组件扫描范围内
2. 使⽤ @LoadBalancerClient 或者 @LoadBalancerClients 注解
在 RestTemplate 配置类上⽅, 使⽤ @LoadBalancerClient 或 @LoadBalancerClients 注解, 可以对不同的服务提供⽅配置不同的客⼾端负载均衡算法策略.
由于咱们项⽬中只有⼀个服务提供者, 所以使⽤@LoadBalancerClient
@LoadBalancerClient(name = "product-service", configuration =
LoadBalancerConfig.class)
@Configuration
public class BeanConfig {@Bean@LoadBalancedpublic RestTemplate restTemplate(){return new RestTemplate();}}@LoadBalancerClient 注解说明
1. name: 该负载均衡策略对哪个服务⽣效(服务提供⽅)
2. configuration : 该负载均衡策略 ⽤哪个负载均衡策略实现
2.3 LoadBalancer 原理
LoadBalancer 的实现, 主要是 LoadBalancerInterceptor , 这个类会对 RestTemplate 的请求进⾏拦截, 然后从Eureka根据服务id获取服务列表,随后利⽤负载均衡算法得到真实的服务地址信息,替换服务id
我们来看看源码实现:
public class LoadBalancerInterceptor implements ClientHttpRequestInterceptor {//...public ClientHttpResponse intercept(final HttpRequest request, finalbyte[] body, final ClientHttpRequestExecution execution) throws IOException {URI originalUri = request.getURI();String serviceName = originalUri.getHost();Assert.state(serviceName != null, "Request URI does not contain a valid hostname: " + originalUri);return (ClientHttpResponse)this.loadBalancer.execute(serviceName, this.requestFactory.createRequest(request, body, execution));}
}可以看到这⾥的intercept⽅法, 拦截了⽤⼾的HttpRequest请求,然后做了⼏件事:
1. request.getURI() 从请求中获取uri, 也就是 http://product-service/product/1001
2. originalUri.getHost() 从uri中获取路径的主机名, 也就是服务id, product-service
3. loadBalancer.execute 根据服务id, 进⾏负载均衡, 并处理请求
点进去继续跟踪
public class BlockingLoadBalancerClient implements LoadBalancerClient {public <T> T execute(String serviceId, LoadBalancerRequest<T> request)
throws IOException {String hint = this.getHint(serviceId);LoadBalancerRequestAdapter<T, TimedRequestContext> lbRequest = newLoadBalancerRequestAdapter(request, this.buildRequestContext(request, hint));Set<LoadBalancerLifecycle> supportedLifecycleProcessors = this.getSupportedLifecycleProcessors(serviceId);supportedLifecycleProcessors.forEach((lifecycle) -> {lifecycle.onStart(lbRequest);});//根据serviceId,和负载均衡策略, 选择处理的服务ServiceInstance serviceInstance = this.choose(serviceId, lbRequest);if (serviceInstance == null) {supportedLifecycleProcessors.forEach((lifecycle) -> {lifecycle.onComplete(new CompletionContext(Status.DISCARD, lbRequest, new EmptyResponse()));});throw new IllegalStateException("No instances available for "+ serviceId);} else {return this.execute(serviceId, serviceInstance, lbRequest);}}/*** 根据serviceId,和负载均衡策略, 选择处理的服务**/public <T> ServiceInstance choose(String serviceId, Request<T> request) {//获取负载均衡器ReactiveLoadBalancer<ServiceInstance> loadBalancer = this.loadBalancerClientFactory.getInstance(serviceId);if (loadBalancer == null) {return null;} else {//根据负载均衡算法, 在列表中选择⼀个服务实例Response<ServiceInstance> loadBalancerResponse = (Response)Mono.from(loadBalancer.choose(request)).block();return loadBalancerResponse == null ? null : (ServiceInstance)loadBalancerResponse.getServer();}}
}3. 服务部署(Linux)
接下来我们把服务部署在Linux系统上
3.1 准备数据
安装mysql
数据初始化
修改配置⽂件
修改配置⽂件中, 数据库的密码
3.2 服务构建打包
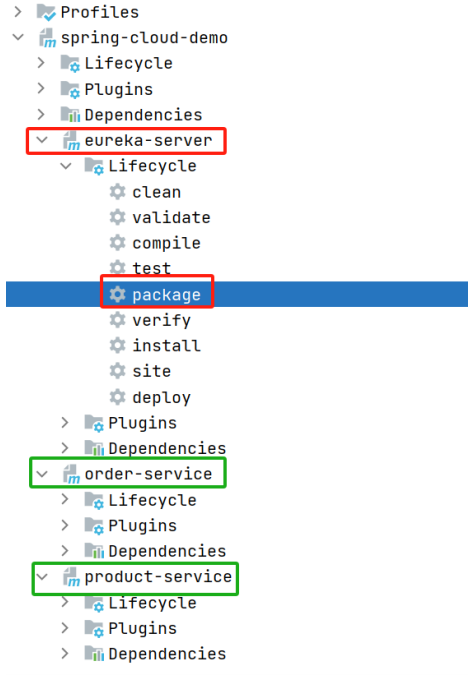
采⽤Maven打包, 需要对3个服务分别打包:
eureka-server, order-service, product-service
1. 打包⽅式和SpringBoot项⽬⼀致, 依次对三个项⽬打包即可.
3.3 启动服务
1. 上传Jar包到云服务器
第⼀次上传需要安装lrzsz
apt install lrzsz
直接拖动⽂件到xshell窗⼝, 上传成功.
2. 启动服务
#后台启动eureka-server, 并设置输出⽇志到logs/eureka.log
nohup java -jar eureka-server.jar >logs/eureka.log &
#后台启动order-service, 并设置输出⽇志到logs/order.log
nohup java -jar order-service.jar >logs/order.log &
#后台启动product-service, 并设置输出⽇志到logs/order.log
nohup java -jar product-service.jar >logs/product-9090.log &
再多启动两台product-service实例
#启动实例, 指定端⼝号为9091
nohup java -jar product-service.jar --server.port=9091 >logs/product-9091.log &
#启动实例, 指定端⼝号为9092
nohup java -jar product-service.jar --server.port=9092 >logs/product-9092.log &
3.4 开放端⼝号
根据⾃⼰项⽬设置的情况, 在云服务器上开放对应的端⼝号
不同的服务器⼚商, 开放端⼝号的⼊⼝不同, 需要⾃⾏找⼀找或者咨询对应的客服⼈员.
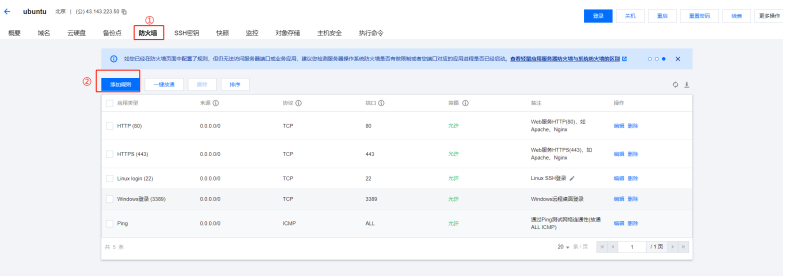
以腾讯云服务器举例:
1) 进⼊防⽕墙管理⻚⾯
2) 添加规则
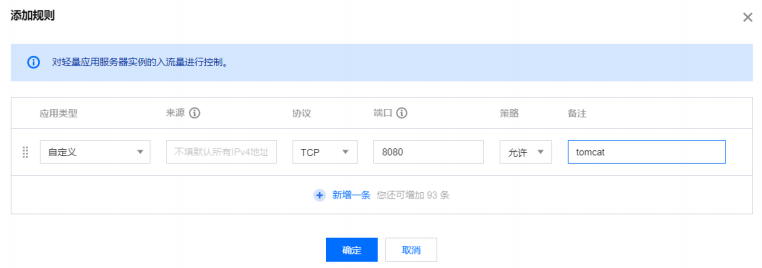
端⼝号写需要开放的端⼝号, 多个端⼝号以逗号分割.
3.5 测试
1. 访问Eureka Server:
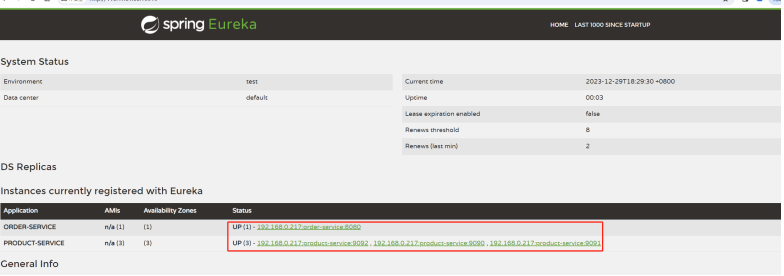
2. 访问订单服务接⼝: http://110.41.51.65:8080/order/1

远程调用成功.