高并发内存池 设计PageCache(4)
文章目录
- 前言
- 一、整体设计
- 二、核心实现
- 三、获取Span
- 获取一个非空的Span
- 获取一个K页的Span
- 加锁版获取非空Span
- 总结
前言
这是最后一块缓存了,应该说也不简单,大家加油!!!
一、整体设计
page cache 与 central cache 的相同之处
central cache 的结构与 thread cache 是相同的,都是哈希桶结构,并且 page cache 的每个哈希桶中挂的也是一个个的 span ,这些 span 也是按照双链表的结构链接起来的。
page cache 与 central cache 的不同之处
-
page cache 与 central cache 的映射规则不同(包括 thread cache )。 page cache 的哈希桶映射规则采用的是直接定址法,比如 1 号桶挂的都是 1 页的 span , 2 号桶挂的都是 2 页的 span ,以此类推。
-
central cache 每个桶中的 span 被切成一个个对应大小的对象,以供 thread cache 申请。而 page cache 当中的 span 是没有被进一步切小的,因为 page cache 服务的是 central cache ,当 central cache 没有 span 时,向 page cache 申请的是某一固定页数的 span ,而如何切分申请到的这个 span 由 central cache 自己来决定。
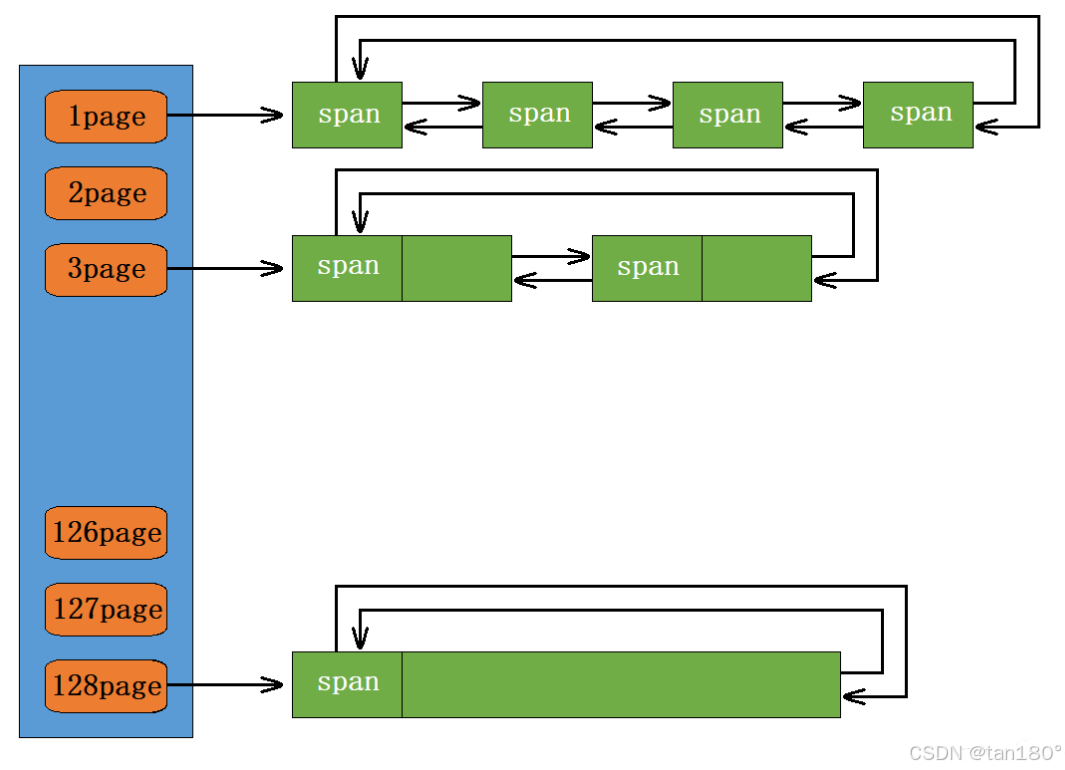
所以 page cache 一共有多少个桶,就取决于你最大想挂多少页的 span 了,我们这里就让 span 挂的最大页数为 128 ,同时为了让第 0 号桶空出来,我们需要将哈希桶的数量设置为 129
// page cache中哈希桶的个数
static const size_t NPAGES = 129;
我们可以思考一下为什么最大要挂 128 页的 span ,因为线程申请单个对象最大是 256KB ,而 128 页可以被切成 4 个 256KB 的对象,因此是足够的
那么如何在 page cache 中获取一个 n 页的 span 呢?
-
如果 central cache 要获取一个 n 页的 span ,那我们就可以在 page cache 的第 n 号桶中取出一个 span 返回给 central cache 即可。
-
如果第 n 号桶中没有 span ,这时我们并不是直接向堆申请一个 n 页的 span ,而是继续在后面的桶中寻找 span 。
-
当第 n 号桶中没有 span 时,我们可以找第 n+1 号桶,因为我们可以将第 n+1 页的 span 分成一个 n 页的 span 和一个 1 页的 span ,这时我们就可以将 n 页的 span 返回,而将切分后的 1 页挂接到 1 号桶中,依此类推
-
当后面的桶当中都没有 span ,这时我们就只能向堆申请一个 128 页的内存块,并将其用一个 span 结构管理起来,然后将 128 页的 span 切分成 n 页的 span 和 128-n 页的 span ,其中 n 页的 span 返回给 central cache ,而 128-n 页的 span 挂到第 128-n 号桶中。
相当奇妙不是吗,我们可以发现我们想要的 span 其实本质上都是从 128 页的那个桶中分出来的!看到这个过程描述可能有人都迫不及待地想看看代码实现了是吧!
二、核心实现
-
当每个线程的 thread cache 没有内存时都会向 central cache 申请,此时多个线程的 thread cache 如果访问的不是 central cache 的同一个桶,那么这些线程是可以同时进行访问的。这时 central cache 的多个桶可能同时向 page cache 申请内存,索引 page cache 也是存在线程安全问题的,因此在访问 page cache 时也必须要加锁。
-
但是 page cache 这里不能使用桶锁,因为当 central cache 向 page cache 申请内存时, page cache 可能会将其他桶当中大页的 span 切小再给 central cache 。此外,当 central cache 将某个 span 归还给 page cache 时, page cache 也会尝试将该 span 与其他桶当中的 span 进行合并。
-
换句话说,在访问 page cache 时,我们可能需要访问 page cache 中的多个桶,如果 page cache 用桶锁就会出现大量频繁的加锁和解锁,导致程序的效率低下。因此我们在访问 page cache 时没有使用桶锁,而是用一把大锁将整个 page cache 锁住。
-
page cache 在整个进程中只能存在一个,因此我们也需要将其设置为单例模式。
// 单例模式
class PageCache
{
public:// 提供一个全局访问点static PageCache* GetInstance(){return &_sInst;}std::mutex _pageMtx; // 大锁,设置公有方便调用
private:SpanList _spanLists[NPAGES];// C++98,构造函数私有PageCache(){}// C++11,禁止拷贝PageCache(const PageCache&) = delete;static PageCache _sInst;
};
因为是饿汉模式,当程序运行起来的时候我们直接创建该对象即可
// 类外初始化静态成员
PageCache PageCache::_sInst;
三、获取Span
获取一个非空的Span
central cache 到底是如何从对应的哈希桶中获取到一个非空的 Span 的呢?
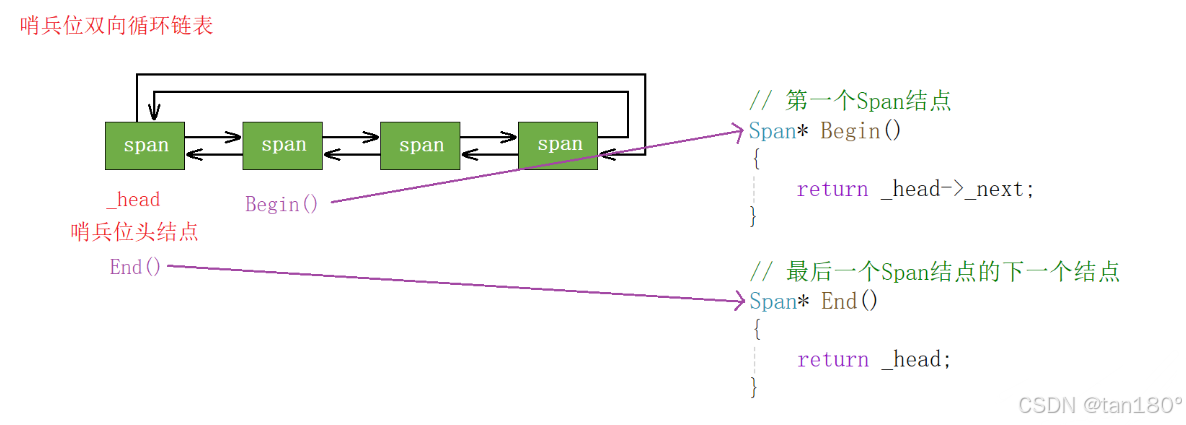
答案是遍历!遍历 central cache 对应哈希桶中的双链表,如果该双链表中有非空的 Span ,那么直接将 Span 返回即可,当然为了模拟这个迭代器,我们必须在 SpanList类 中添加这几个成员函数,如 Begin() 和 End()
// 管理Span的链表结构
class SpanList
{
public:Span* Begin(){return _head->_next;}Span* End(){return _head;}
private:Span* _head; // 双向链表头结点指针
public: std::mutex _mtx; // 桶锁,方便类外访问
};
但如果遍历双链表后发现双链表中没有 span ,或该双链表中的 span 都为空,那么此时 central cache 就需要向 page cache 申请内存块了,问题是申请多大页数的内存块呢?
答案是可以根据具体所需对象的大小来决定,先根据对象的大小计算出, thread cache 一次向 central cache 申请对象的个数上限,然后将这个上限值乘以单个对象的大小,就算出了具体需要多少字节,最后再将这个算出来的字节数转换为页数,如果转换后不够一页,那么我们就申请一页,否则转换出来是几页就申请几页
class SizeClass
{
public: // central cache一次向page cache获取多少页static size_t NumMovePage(size_t size){// 计算出thread cache一次向central cache申请对象的个数上限size_t num = NumMoveSize(size); // num 个size 大小的对象所需的字节数size_t nPage = num * size;nPage >>= PAGE_SHIFT; // 将字节数转换为页数if (nPage == 0)nPage = 1; // 至少给一页return nPage;}
};
PAGE_SHIFT 代表页大小转换偏移,我们这里以页的大小为 8K 为例, PAGE_SHIFT 的值就是13
// 页大小转换偏移,即一页定义为2^13,也就是8KB
static const size_t PAGE_SHIFT = 13;
当 central cache 申请到若干页的 span 后,还需要将这个 span 切成一个个对应大小的对象挂到该 span 的自由链表当中。
我们如何找到一个span管理的内存块呢?
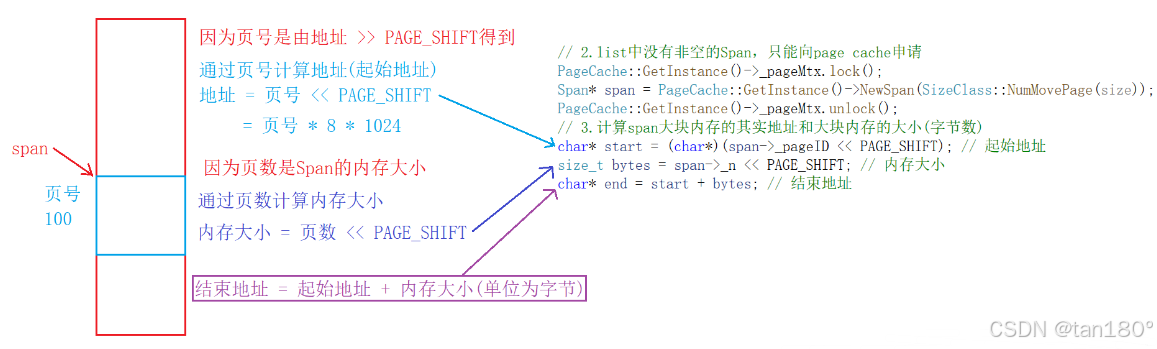
首先需要计算出该 span 的起始地址,我们可以用这个 span 的起始页号乘以一页的大小即可得到这个 span 的起始地址,然后用这个 span 的页数乘以一页的大小就可以得到这个 span 所管理的内存块的大小,用起始地址加上内存块的大小即可得到这块内存块的结束位置
明确了这块内存的起始和结束位置后,我们就可以进行切分了。根据所需对象的大小,每次从大块内存切出一块固定大小的内存块尾插到 span 的自由链表中即可,至于为什么是尾插,因为我们如果是将切好的对象尾插到自由链表,这些对象看起来是按照链式结构链接起来的,而实际它们在物理上是连续的,这时当我们把这些连续内存分配给某个线程使用时,可以提高该线程的 CPU 缓存利用率
//获取一个非空的span
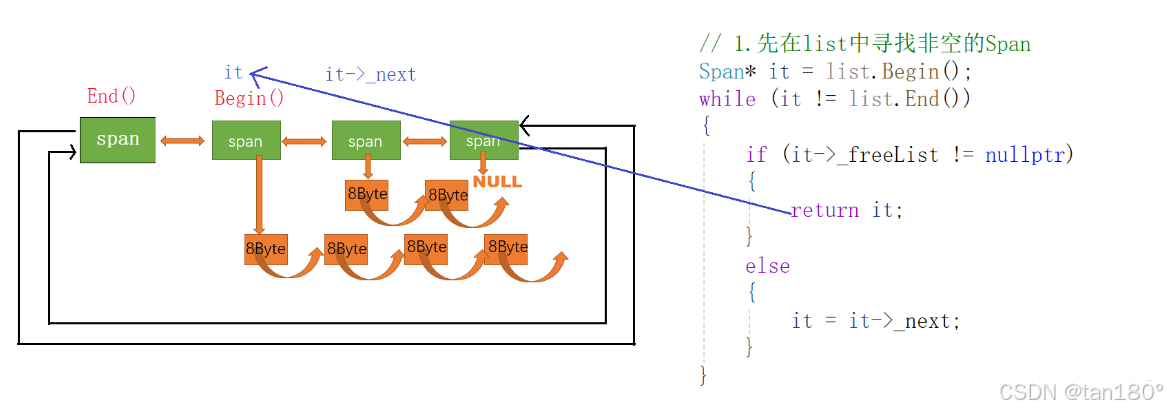
Span* CentralCache::GetOneSpan(SpanList& spanList, size_t size)
{//1、先在spanList中寻找非空的spanSpan* it = spanList.Begin();while (it != spanList.End()){if (it->_freeList != nullptr){return it;}else{it = it->_next;}}//2、spanList中没有非空的span,只能向page cache申请Span* span = PageCache::GetInstance()->NewSpan(SizeClass::NumMovePage(size));//计算span的大块内存的起始地址和大块内存的大小(字节数)char* start = (char*)(span->_pageId << PAGE_SHIFT);size_t bytes = span->_n << PAGE_SHIFT;char* end = start + bytes;//把大块内存切成size大小的对象链接起来//先切一块下来去做尾,方便尾插span->_freeList = start;start += size;void* tail = span->_freeList;//尾插while (start < end){NextObj(tail) = start;tail = NextObj(tail);start += size;}NextObj(tail) = nullptr; //尾的指向置空//将切好的span头插到spanListspanList.PushFront(span);return span;
}
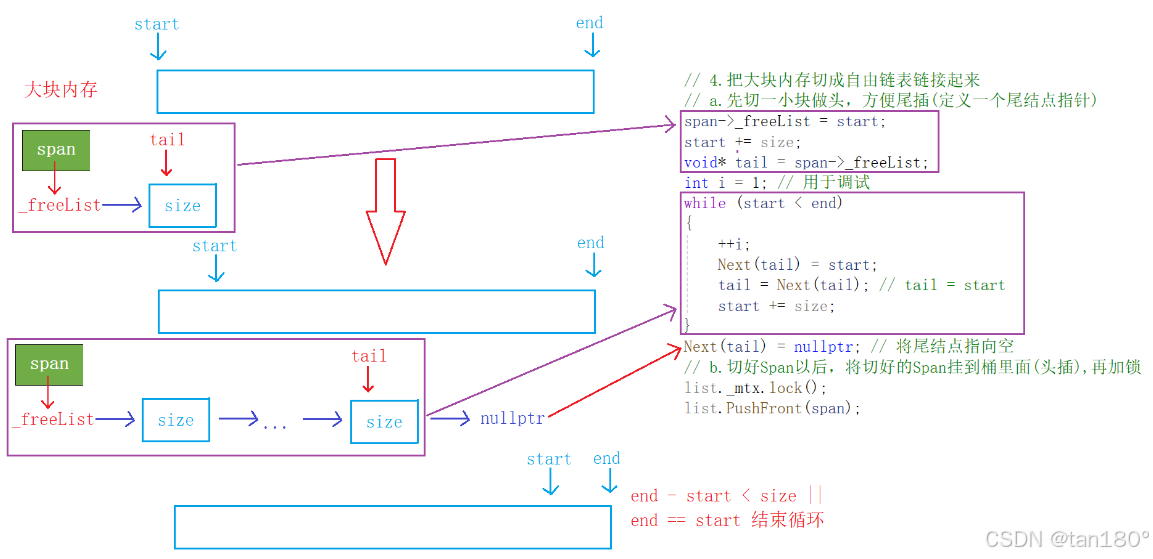
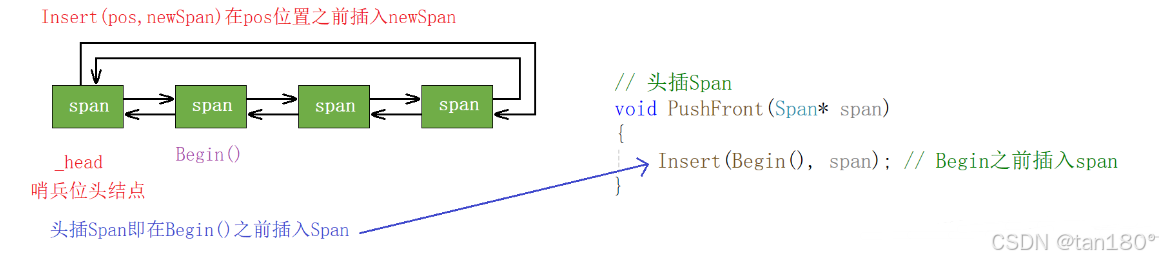
当我们把 span 切分好之后,需要将这个切分好的 span 挂接到 central cache 对应的哈希桶中。因此SpanList类需要提供一个将 span 插入到双链表的接口。此处我们选择头插,这样当 central cache 下一次从该双链表获取非空 span 时,一来就能找到。
// 管理Span的链表结构
class SpanList
{
public:// 头插Spanvoid PushFront(Span* span){Insert(Begin(), span); // Begin之前插入span}
private:Span* _head; // 双向链表头结点指针
public: std::mutex _mtx; // 桶锁,方便类外访问
};
获取一个K页的Span
当我们调用上述的 GetOneSpan 从 central cache 的某个哈希桶获取一个非空的 span 时,如果遍历哈希桶中的双链表后发现双链表中没有 span ,或该双链表中的 span 都为空,那么此时 central cache 就需要向 page cache 申请若干页的 span 了
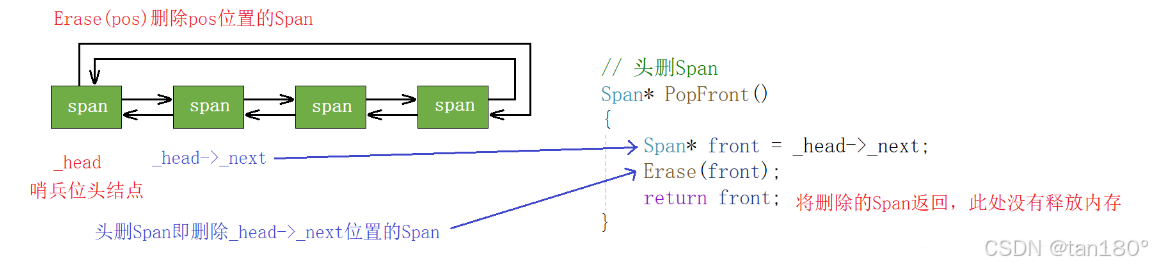
因为 page cache 是直接按照页数进行映射的,因此我们要从 page cache 获取一个 k 页的 span ,就应该直接先去找 page cache 的第 k 号桶,如果第 k 号桶中有 span ,那我们直接头删一个 span 返回给 central cache 就行了。所以我们这里需要再给 SpanList 类添加对应的 PopFront 函数
// 管理Span的链表结构
class SpanList
{
public:// 头删SpanSpan* PopFront(){Span* front = _head->_next;Erase(front);return front;}
private:Span* _head; // 双向链表头结点指针
public: std::mutex _mtx; // 桶锁,方便类外访问
};
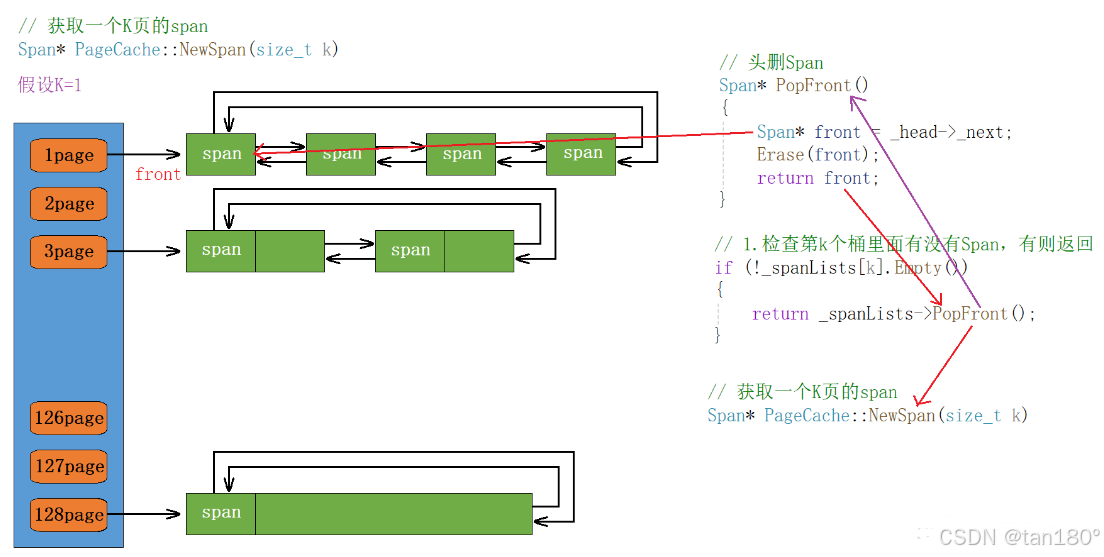
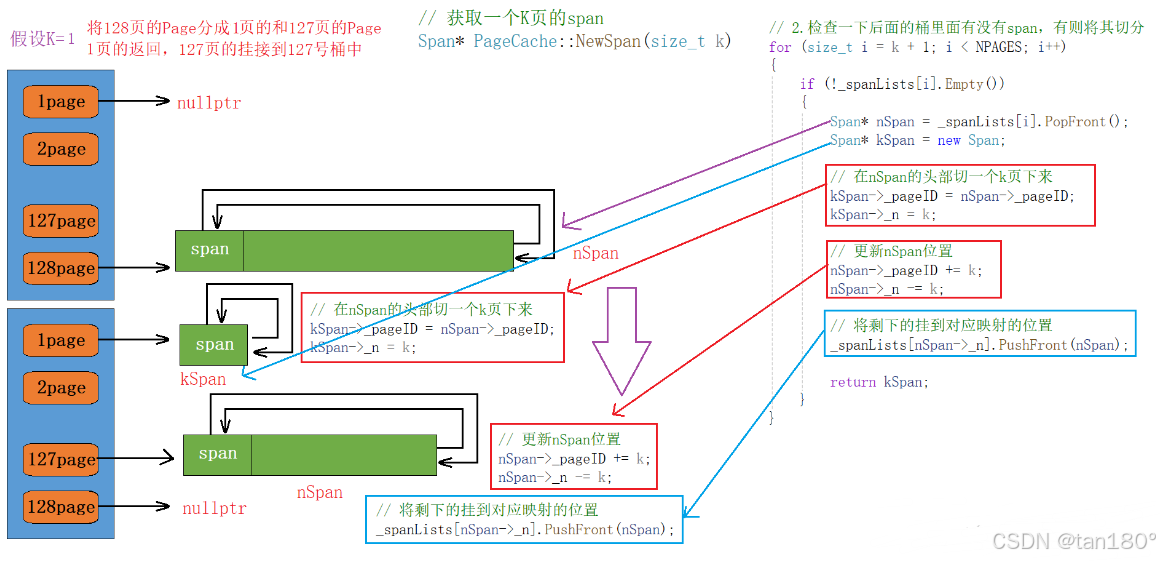
如果 page cache 的第 k 号桶中没有 span ,我们就应该继续找后面的桶,只要后面任意一个桶中有一个 n 页的span,我们就可以将其切分成一个 k 页的 span 和一个 n-k 页的 span ,然后将切出来 k 页 span 返回给 central cache ,再将 n-k 页的 span 挂接到 page cache 的第 n-k 号桶中。
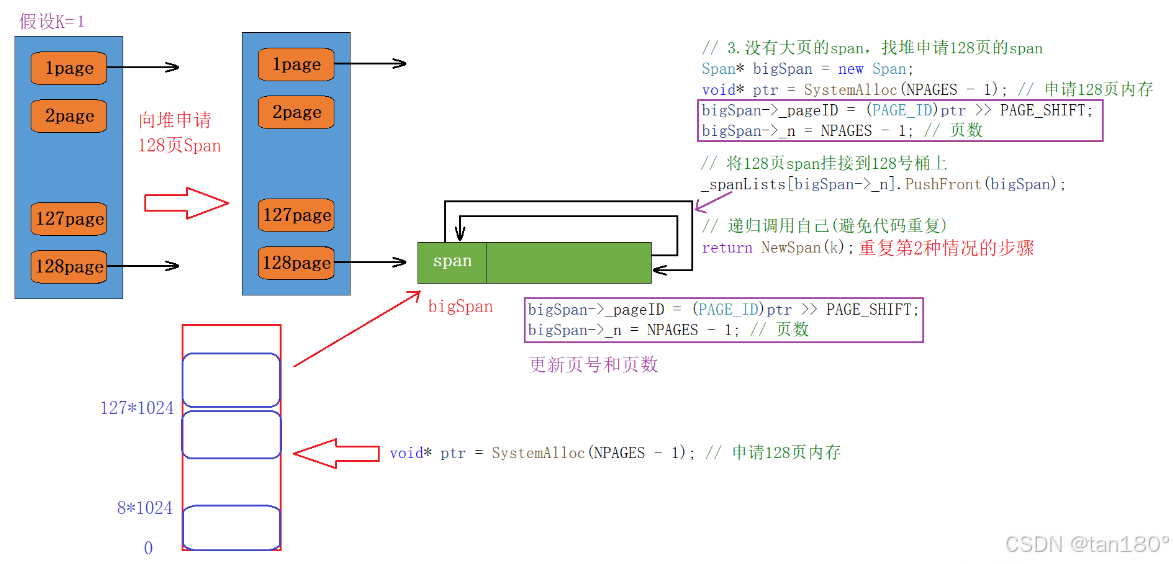
如果后面的桶中也都没有 span ,此时我们需要向堆申请一个 128 页的 span 了,在向堆申请内存时,直接调用我们封装的 SystemAlloc 函数即可。
// 获取一个K页的span
// 注意观察span的起始页号跟起始地址所对应的关系
Span* PageCache::NewSpan(size_t k)
{assert(k > 0 && k < NPAGES); // 保证在桶的范围内// 1.检查第k个桶里面有没有Span,有则返回if (!_spanLists[k].Empty()){return _spanLists[k].PopFront();}// 2.检查一下后面的桶里面有没有span,有则将其切分for (size_t i = k + 1; i < NPAGES; i++){if (!_spanLists[i].Empty()){Span* nSpan = _spanLists[i].PopFront();Span* kSpan = new Span;// 在nSpan的头部切一个k页下来kSpan->_pageID = nSpan->_pageID;kSpan->_n = k;// 更新nSpan位置nSpan->_pageID += k;nSpan->_n -= k;// 将剩下的挂到对应映射的位置_spanLists[nSpan->_n].PushFront(nSpan);return kSpan;}}// 3.没有大页的span,找堆申请128页的spanSpan* bigSpan = new Span;void* ptr = SystemAlloc(NPAGES - 1); // 申请128页内存bigSpan->_pageID = (PAGE_ID)ptr >> PAGE_SHIFT;bigSpan->_n = NPAGES - 1; // 页数_spanLists[bigSpan->_n].PushFront(bigSpan);// 递归调用自己(避免代码重复)return NewSpan(k);
}
这个时候我们要思考一个问题,当 central cache 向 page cache 申请内存时, central cache 对应的哈希桶是处于加锁的状态的,那在访问 page cache 之前我们应不应该把 central cache 对应的桶锁解掉呢?
这里建议在访问 page cache 前,先把 central cache 对应的桶锁解掉。虽然此时 central cache 的这个桶当中是没有内存供其他 thread cache 申请的,但 thread cache 除了申请内存还会释放内存,如果在访问 page cache 前将 central cache 对应的桶锁解掉,那么此时当其他 thread cache 想要归还内存到 central cache 的这个桶时就不会被阻塞。
因此在调用 NewSpan 函数之前,我们需要先将 central cache 对应的桶锁解掉,然后再将 page cache 的大锁加上,当申请到 k 页的 span 后 ,我们需要将 page cache 的大锁解掉,但此时我们不需要立刻获取到 central cache 中对应的桶锁。因为 central cache 拿到 k 页的 span 后还会对其进行切分操作,因此我们可以在 span 切好后需要将其挂到 central cache 对应的桶上时,再获取对应的桶锁
加锁版获取非空Span
spanList._mtx.unlock(); //解桶锁PageCache::GetInstance()->_pageMtx.lock(); //加大锁
//从page cache申请k页的span
PageCache::GetInstance()->_pageMtx.unlock(); //解大锁//进行span的切分...spanList._mtx.lock(); //加桶锁
//将span挂到central cache对应的哈希桶
总结
感觉如何!哈哈,下篇内容较为简单,大家可以放松一下