线程锁-互斥、自旋、读写、原子操作、线程池
1.自旋锁
2.互斥锁


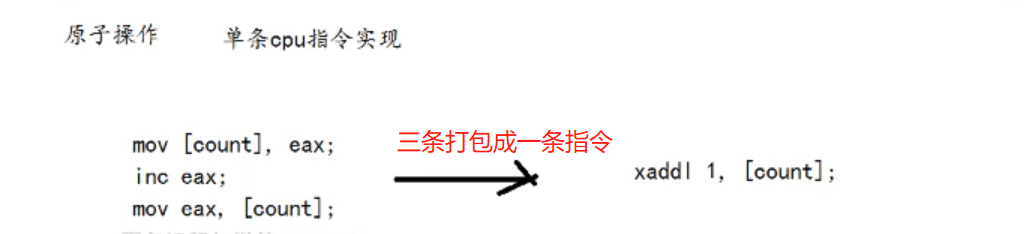
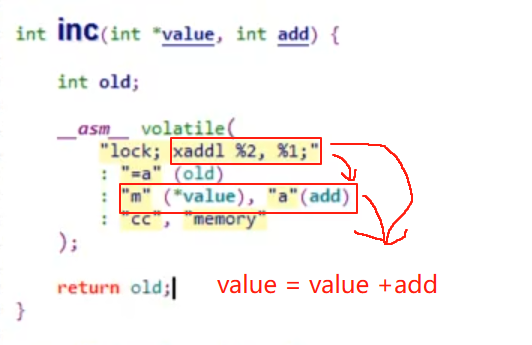
原子操作
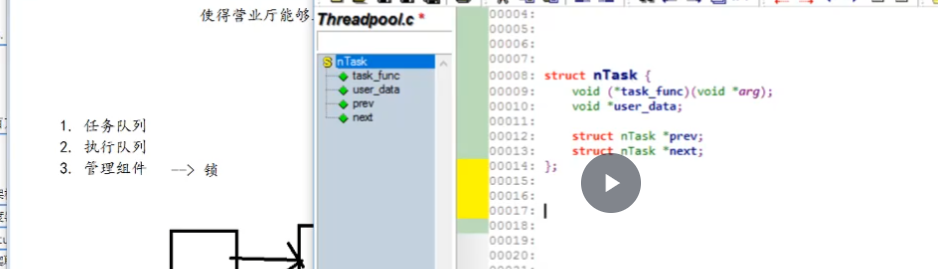
线程池
多线程同步编程详解
多线程同步是并发编程中的核心概念,下面我将详细介绍互斥锁、自旋锁、读写锁、原子操作和线程池,并提供代码示例、使用条件和常见易错点。
1. 互斥锁 (Mutex)
基本概念
互斥锁是最常用的线程同步机制,用于保护共享资源,确保同一时间只有一个线程可以访问临界区。
代码示例 (C++11)
#include <iostream>
#include <thread>
#include <mutex>std::mutex mtx;
int shared_data = 0;void increment() {for (int i = 0; i < 100000; ++i) {mtx.lock();++shared_data;mtx.unlock();}
}int main() {std::thread t1(increment);std::thread t2(increment);t1.join();t2.join();std::cout << "Final value: " << shared_data << std::endl;return 0;
}使用条件
- 当多个线程需要访问同一共享资源时
- 临界区代码执行时间较长(如文件I/O、复杂计算)
注意事项
- 避免死锁:确保锁总是被释放,可以使用
std::lock_guard或std::unique_lock自动管理 - 锁粒度:锁的范围不宜过大,否则会降低并发性能
- 异常安全:临界区内可能抛出异常,导致锁无法释放
易错点
- 忘记解锁(推荐使用RAII风格的锁管理)
- 锁的嵌套使用不当导致死锁
- 在不同函数中加锁/解锁,导致逻辑混乱
2. 自旋锁 (Spinlock)
基本概念
自旋锁是一种忙等待锁,线程在获取锁失败时会循环检查锁状态,而不是被挂起。
代码示例 (C++11)
#include <atomic>
#include <thread>class Spinlock {std::atomic_flag flag = ATOMIC_FLAG_INIT;
public:void lock() {while (flag.test_and_set(std::memory_order_acquire));}void unlock() {flag.clear(std::memory_order_release);}
};Spinlock spin;
int shared_data = 0;void increment() {for (int i = 0; i < 100000; ++i) {spin.lock();++shared_data;spin.unlock();}
}int main() {std::thread t1(increment);std::thread t2(increment);t1.join();t2.join();std::cout << "Final value: " << shared_data << std::endl;return 0;
}使用条件
- 临界区代码执行时间非常短
- 不希望线程被挂起(避免上下文切换开销)
- 多核处理器环境
注意事项
- CPU占用:自旋锁会持续占用CPU
- 单核慎用:单核CPU上可能导致性能问题
- 优先级反转:高优先级线程可能被低优先级线程阻塞
易错点
- 在长时间临界区使用自旋锁(应改用互斥锁)
- 忘记释放自旋锁
- 在单核系统上使用导致性能下降
3. 读写锁 (Read-Write Lock)
基本概念
读写锁允许多个读操作同时进行,但写操作需要独占访问,适用于读多写少的场景。
代码示例 (C++17)
#include <shared_mutex>
#include <thread>
#include <vector>std::shared_mutex rw_mutex;
int shared_data = 0;void reader(int id) {for (int i = 0; i < 5; ++i) {{std::shared_lock lock(rw_mutex);std::cout << "Reader " << id << " sees: " << shared_data << std::endl;}std::this_thread::sleep_for(std::chrono::milliseconds(100));}
}void writer(int id) {for (int i = 0; i < 2; ++i) {{std::unique_lock lock(rw_mutex);++shared_data;std::cout << "Writer " << id << " updated to: " << shared_data << std::endl;}std::this_thread::sleep_for(std::chrono::milliseconds(200));}
}int main() {std::vector<std::thread> readers;for (int i = 0; i < 5; ++i) {readers.emplace_back(reader, i);}std::vector<std::thread> writers;for (int i = 0; i < 2; ++i) {writers.emplace_back(writer, i);}for (auto& t : readers) t.join();for (auto& t : writers) t.join();return 0;
}使用条件
- 读操作远多于写操作
- 读操作不需要修改共享数据
- 读操作持续时间较长
注意事项
- 写者饥饿:持续有读者可能导致写者无法获取锁
- 升级问题:从读锁升级到写锁通常不支持
- 公平性:某些实现可能不公平,导致某些线程长期得不到机会
易错点
- 在持有读锁时修改数据(未定义行为)
- 错误估计读写比例(写多读少时性能可能不如互斥锁)
- 忽略锁的升级限制
4. 原子操作 (Atomic Operations)
基本概念
原子操作是不可分割的操作,由CPU直接保证其原子性,无需额外锁机制。
代码示例 (C++11)
#include <atomic>
#include <thread>
#include <vector>std::atomic<int> counter(0);void increment(int n) {for (int i = 0; i < n; ++i) {counter.fetch_add(1, std::memory_order_relaxed);}
}int main() {const int num_threads = 10;const int increments_per_thread = 100000;std::vector<std::thread> threads;for (int i = 0; i < num_threads; ++i) {threads.emplace_back(increment, increments_per_thread);}for (auto& t : threads) t.join();std::cout << "Final counter value: " << counter << std::endl;return 0;
}使用条件
- 简单的共享变量操作(如计数器、标志位)
- 需要最高性能的同步场景
- 对单个变量的操作
注意事项
- 内存顺序:理解并正确使用memory_order
- 复合操作:多个原子操作组合不是原子的
- ABA问题:某些场景下需要考虑
易错点
- 错误使用memory_order导致可见性问题
- 认为多个原子操作组合是原子的
- 忽略缓存一致性问题
5. 线程池 (Thread Pool)
基本概念
线程池预先创建一组线程,避免频繁创建销毁线程的开销,提高任务执行效率。
代码示例 (C++11简单实现)
#include <vector>
#include <thread>
#include <queue>
#include <mutex>
#include <condition_variable>
#include <functional>
#include <future>class ThreadPool {
public:ThreadPool(size_t threads) : stop(false) {for (size_t i = 0; i < threads; ++i) {workers.emplace_back([this] {while (true) {std::function<void()> task;{std::unique_lock<std::mutex> lock(this->queue_mutex);this->condition.wait(lock, [this] {return this->stop || !this->tasks.empty();});if (this->stop && this->tasks.empty()) return;task = std::move(this->tasks.front());this->tasks.pop();}task();}});}}template<class F, class... Args>auto enqueue(F&& f, Args&&... args) -> std::future<typename std::result_of<F(Args...)>::type> {using return_type = typename std::result_of<F(Args...)>::type;auto task = std::make_shared<std::packaged_task<return_type()>>(std::bind(std::forward<F>(f), std::forward<Args>(args)...));std::future<return_type> res = task->get_future();{std::unique_lock<std::mutex> lock(queue_mutex);if(stop) throw std::runtime_error("enqueue on stopped ThreadPool");tasks.emplace([task](){ (*task)(); });}condition.notify_one();return res;}~ThreadPool() {{std::unique_lock<std::mutex> lock(queue_mutex);stop = true;}condition.notify_all();for (std::thread &worker : workers)worker.join();}private:std::vector<std::thread> workers;std::queue<std::function<void()>> tasks;std::mutex queue_mutex;std::condition_variable condition;bool stop;
};// 使用示例
int main() {ThreadPool pool(4);std::vector<std::future<int>> results;for (int i = 0; i < 8; ++i) {results.emplace_back(pool.enqueue([i] {std::cout << "Task " << i << " started\n";std::this_thread::sleep_for(std::chrono::seconds(1));std::cout << "Task " << i << " finished\n";return i*i;}));}for (auto&& result : results)std::cout << "Result: " << result.get() << std::endl;return 0;
}使用条件
- 需要执行大量短期任务
- 避免频繁创建销毁线程的开销
- 需要限制并发线程数量
注意事项
- 任务队列大小:无界队列可能导致内存耗尽
- 异常处理:任务中的异常需要妥善处理
- 线程数量:根据CPU核心数和任务类型选择合适数量
- 任务依赖:注意任务间的依赖关系
易错点
- 忘记正确处理线程池关闭
- 任务抛异常导致线程退出
- 任务之间有共享状态但未同步
- 线程数量设置不合理(过多或过少)
综合对比
| 同步机制 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|
| 互斥锁 | 一般共享资源访问 | 简单可靠,线程挂起不占CPU | 上下文切换开销大 |
| 自旋锁 | 极短临界区,多核 | 无上下文切换,响应快 | 忙等待消耗CPU |
| 读写锁 | 读多写少场景 | 允许多个读者并发 | 实现复杂,可能写者饥饿 |
| 原子操作 | 简单变量操作 | 最高性能,无锁 | 只能用于简单操作 |
| 线程池 | 大量短期任务 | 避免线程创建开销,控制并发度 | 实现复杂,需管理任务队列 |
最佳实践建议
- 优先考虑更高层次的抽象:如任务并行库(TBB)、OpenMP等
- 避免过早优化:先用简单互斥锁,有性能问题再考虑其他
- 尽量减少共享数据:通过设计减少同步需求
- 使用工具检测问题:如ThreadSanitizer检测数据竞争
- 理解内存模型:特别是使用原子操作时
- 测试多线程代码:多线程bug往往难以重现,需要专门测试
多线程编程复杂但功能强大,正确使用这些同步机制可以构建高效可靠的并发程序。