Nature Genetics | 测序技术与深度学习在 circRNA 鉴定中的应用
生信碱移
抽丝剥茧: circRNA
环状 RNA(circRNA)是一类具有闭合环状结构的 RNA 分子,与线性 RNA 截然不同。多项研究揭示了这些环状转录本在基因调控和疾病发生中的作用。然而,circRNA 的低表达水平及其与线性 RNA 的高度序列相似性为 circRNA 的检测与表征带来了不少挑战。

DOI: 10.1038/s41588-025-02157-7
2025 年 4 月 17 日,中国科学院动物研究所 赵方庆团队 在 Nature Genetics [IF: 31.7] 上受邀撰写题为 Circular RNA discovery with emerging sequencing and deep learning technologies 的综述论文。系统总结了环形RNA序列重构、定量解析及功能挖掘中的最新进展和核心挑战,着重阐述了人工智能技术在环形RNA研究中的关键作用,并进一步提出了人工智能驱动环形RNA研究的理论框架和实践路径。
0.circRNA 领域概述
circRNA 是一类广泛分布于各种生物体中的共价闭合 RNA 分子,参与的功能包括:①隔离 miRNA 和 RNA 结合蛋白(RBP)、②调控线粒体活性氧、③编码隐蔽肽段以及调节先天免疫。需要注意的是,circRNA 的环状结构赋予了其对内源性 RNA 外切酶降解的抗性,使其相较于线性 RNA 具有更加卓越的稳定性。这一稳定性优势已被用于工程化 circRNA 的多种应用,如新型冠状病毒疫苗、基因组编辑平台、RNA 编辑和 RNA 疗法。
然而,circRNA 分子序列和细胞异质性的分析仍面临极大问题。circRNA 在许多组织中的表达水平通常较低,在转录组测序数据中占比极小。这种稀缺性使得全面分析细胞中的 circRNA 变得复杂。过去十年的研究表明,circRNA 具有组织和生物体特异性,这意味着组织批量 RNA 测序方法可能会因样本间细胞比例和组成的差异而产生有偏倚的 circRNA 表达谱。因此,急需在细胞分辨率下研究 circRNA 水平。
circRN 的生物学功能主要依赖于其序列中嵌入的顺式作用元件。与线性转录本类似,circRNA 也能通过可变剪接产生广泛的异构体,从而扩展了其功能谱。因此,准确表征全长 circRNA 异构体是当前 circRNA 研究的关键。传统的 circRNA 识别算法依赖于反向剪接连接点(BSJ)的特征,基于短读长 RNA 测序数据检测这些事件。然而,circRNA 与其线性 RNA 对应物之间的序列存在高度相似性,尤其是在外显子重叠区域,使得研究人员难以区分 circRNA 与线性转录本,从而阻碍了全长 circRNA 异构体的重建。
长读长和单细胞 RNA 测序(scRNA-seq)技术的近期进展显著提升了深入研究 circRNA 异质性的能力。特别是,利用长读长测序技术实现全长 circRNA 异构体的全面分析已取得多项突破,克服了以往 circRNA 重建效率与准确性的局限。与此同时,单细胞全转录组测序方法的发展使得 circRNA 分析达到单细胞分辨率。近期的一项研究通过整合大规模 scRNA-seq 数据,阐明了 circRNA 的细胞分布图谱。此外,基于人工智能的算法已被用于预测细胞类型特异性 circRNA 表达,在疾病和发育过程中 circRNA 的时空调控机制提供了新的工具。
01.circRNA 的定量与差异表达
(1) circRNA 的鉴定和定量
circRNA 是通过反向剪接将环化外显子的 3'端与 5'端连接形成的。这一过程由长外显子上的外显子定义复合体催化 ,并受到侧翼内含子互补序列和 RBP 的促进,这些因子使剪接位点紧密靠近。反向剪接在反向剪接位点(BSJ)产生独特的嵌合序列特征,从而将 circRNA 与线性 RNA 亚型区分开来。
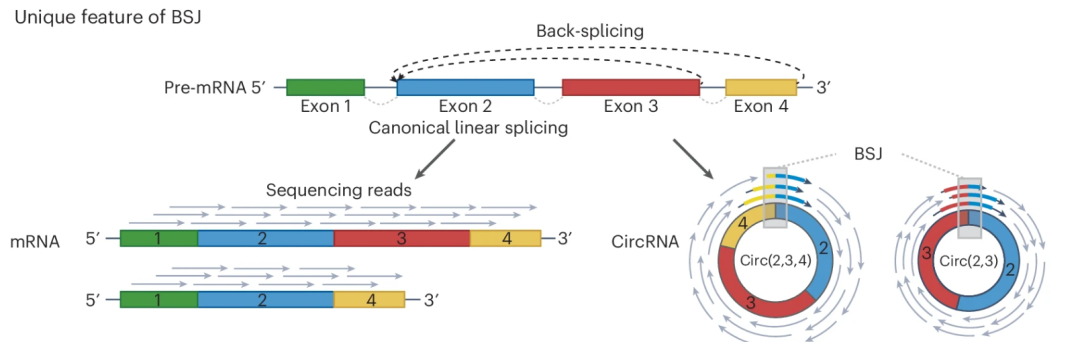
图:与线性 RNA 相比(左下),cicrRNA (右下)由于在 BSJ 处进行反向剪接而产生独特嵌合序列特征,能够用于区分将其与线性 RNA 区分开。
标准的 circRNA 分析流程首先从 RNA 测序数据中识别这些 BSJ 特征,随后进行类似于基因表达研究的定量和差异表达分析。大多数 circRNA 识别算法采用基于比对策略的方法,即从非共线性比对片段中检测并量化这一反向剪接特征,随后基于支持 BSJ 的测序读段数量计算 circRNA 的 丰度。多数工具如 acfs、CIRI2、find_circ、PTESFinder2 和 UROBORUS 使用标准比对工具(例如 BWA、Bowtie 和 TopHat)进行从头环状 RNA 识别。其他工具如 circRNA_finder、CircSplice、DCC 和 CIRCexplorer2 则依赖嵌合比对工具如 STAR 和 TopHat-Fusion,从报告的嵌合比对中检测 BSJ。专用比对工具如 segmehl、MapSplice 和 SPLASH2 可直接识别反向剪接模式。需要注意的是,许多算法会使用经典的GT/AG剪接信号对结果进行过滤。 虽然这提高了准确性并能够确定链特异性,但可能会排除非经典 circRNA,包括源自套索(一种环状中间体)的内含子 circRNA、转运 RNA 内含子 circRNA 等。
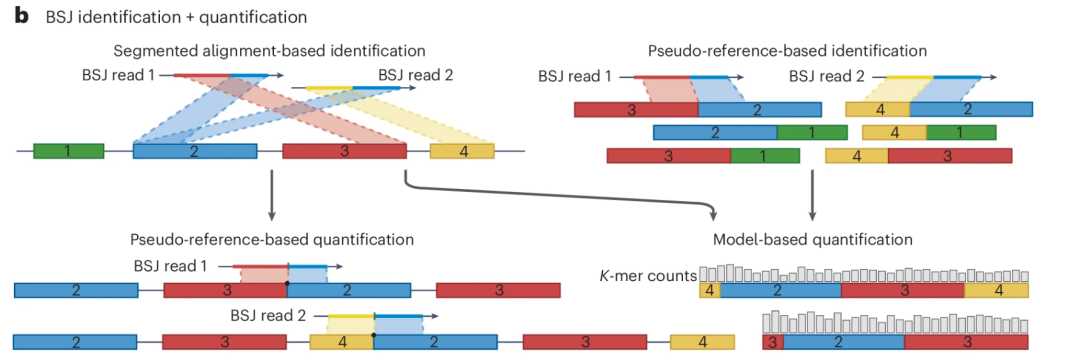
图:BSJ 可通过与参考基因组的分段比对或通过直接比对模拟 BSJ 序列的伪参考序列来识别。对于 circRNA 的定量分析,基于伪参考的策略利用其他工具预测的候选 circRNA,通过 BSJ 读段重比对进行假阳性过滤。另外,基于模型的策略可通过迭代 k-mer 分配来估计 circRNA 的丰度。
值得注意的是,反向剪接位点(BSJ)比对的高度复杂性常常使得区分 circRNA 与比对伪影(虚假比对情况)变得困难。相比之下,基于伪参考序列的方法(如 KNIFE 和 NCLscan)利用预先构建的候选 BSJ 序列来简化比对并减少假阳性。但是,这些方法需要基因组注释完善,且无法检测具有新剪接位点的 circRNA。一些研究表明,结合多种 circRNA 识别策略可提高检测灵敏度和定量准确性。例如,基于伪参考的定量方法如 CIRIquant 会将测序读段同时与参考基因组和伪环状参考序列进行重新比对,以减少假嵌合比对并提高定量精度。CirComPara2 等工具通过整合多种预测工具的结果进一步提升了可靠性。系统性基准研究表明,虽然大多数 circRNA 检测算法展现出可靠的准确性,但其灵敏度差异较大。因此,将高灵敏度工具与基于伪参考或比较的过滤算法相结合,可为 circRNA 精确识别和定量提供更平衡的方法。
基于模型的量化方法,如 Sailfish 和 Kallisto,已被广泛用于快速准确的线性 RNA 定量。这些工具依赖于匹配短序列片段(k-mers)来估计转录本丰度。然而,将这些策略应用于 circRNA 定量将受到 circRNA 与其线性对应物之间高度序列相似性的限制。
(2) circRNA 与线性 RNA 的比例估计
根据上面的内容我们可以发现,circRNA 的生物合成涉及反向剪接与正向剪接(经典流程)之间的竞争,后者生成线性 RNA。因此,环状转录本与线性转录本的比率是衡量 circRNA 形成过程中特定剪接位点利用效率的关键指标。目前已提出多种指标来评估这一比率。包括 CIRI2、CIRIquant 和 CirComPara2 在内的多种工具通过将反向剪接读数除以同一剪接位点的反向剪接与正向剪接读数之和,用于评估反向剪接包含率(类似于 mRNA 的可变剪接的 PSI)。反向剪接包含率反映了反向剪接相对于正向剪接的相对使用情况,并代表特定 BSJ 的使用效率。
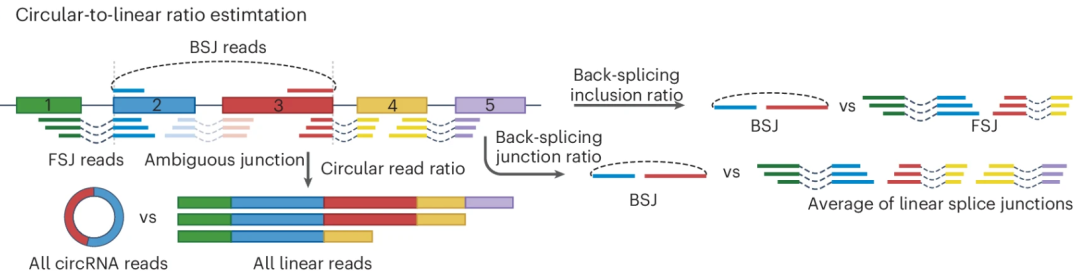
图:环状与线性比率反映了前体 mRNA 生成 circRNA 的比例,该比率可以通过 BSJ 读段数量相对于 BSJ 与正向剪接位点读段之和(反向剪接包含率)或者相对于所有线性剪接位点读段之和(BSJ 比率)来计算。BSJ 区域内无法明确归属为 circRNA 或 mRNA 的模糊剪接位点读段通常在计算时被舍弃。上图展示的是一个简化的转录模型以说明概念,但实际上经常观察到 circRNA 与线性转录本之间发生更复杂的重叠。
相比之下,CircTest、CIRCexplorer3-CLEAR 和 CiLiQuant 等工具计算的是 BSJ 比率,该比率衡量的是 BSJ 读段相对于同一基因内线性连接读段平均丰度的比例。这种方法可以表征环状转录本和线性转录本之间的整体平衡。为了确保准确性,研究人员通常会排除 BSJ 区域内的模糊读段,因为将内部 circRNA 连接错误分类为线性连接可能会扭曲 BSJ 比率的计算。在这其中,对于跨越较长基因组距离的大型 circRNA 或产生多个重叠 circRNA 的位点,BSJ 比率的计算可能不太精确。同样,Sailfish-cir 通过将 circRNA 的表达水平除以环状和线性 RNA 表达的总和来计算环状读段比率。不难发现,当准确估计环状和线性转录本的相对表达水平仍然是当下 circRNA 领域一个持续的挑战。
需要指出的是,上述两项指标反映的是特定样本中 circRNA 的稳态水平,这受到 circRNA 与 mRNA 生物合成及降解动态调控的影响。由于 circRNA 比 mRNA 更稳定,因此较高的环状-线性比率可能源于 circRNA 的积累而非活跃的生物合成过程。为直接估算生物合成与降解速率,一些研究者已采用诸如代谢 RNA 标记等实验方法来追踪新生 circRNA 的合成。
(3) circRNA 差异表达分析
差异 circRNA 表达分析是指评估其表达水平或环状与线性比率的变化。跨越 BSJ 位点的读数数量在概念上类似于通过转录本长度标准化的基因读数计数(Count),如 RPKM(每千碱基转录本每百万映射读数的读数)或其改进后的后继者 TPM(每百万转录本) 。因此,可以通过将 BSJ 读数除以映射读数的总数来估计 circRNA 的表达水平。然而,circRNA 表达分析与基因表达分析不同是,后者的假设大多数基因在不同条件下保持不变,circRNA 表达受到 circRNA 积累、降解或由 circRNA 富集测序方案引入的检测偏差等因素的影响。这使得标准化成为 circRNA 差异表达分析中的关键步骤。
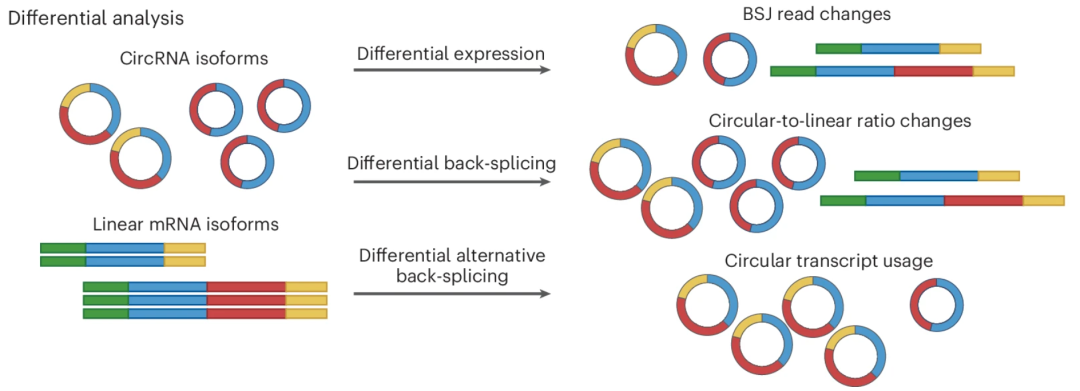
图:circRNA 表达的变化可以通过三种差异分析方法测量。① 通过 BSJ 读数的变化进行差异分析; ② 通过线性/环状比率进行差异分析; ③ 以及源自同一基因位点的不同 circRNA 之间变化比例的差异分析
为了量化环状与线性 RNA 比例的变化,CircTest 使用 β-二项式模型来测量线性与环状异构体之间的相对变化。CIRIquant 则采用精确比率检验来评估反向剪接包含率的差异变化。对于缺乏生物学重复的研究,β 分布和广义倍数变化方法可用于估计表达水平和反向剪接包含率的变化,为初步实验提供了相对稳健的策略。尽管如此,环状 RNA 表达分析还需要多方面的探索。差异选择性反向剪接用于分析考察不同反向剪接连接位点使用情况的变化,通过计算同一基因内特定 BSJ 与总 BSJ 的比值进行量化。例如,果蝇 mbl 基因已被证明会表达具有环境特异性的环状 RNA 亚型,如 circMbl(2) 在果蝇脑细胞中占主导地位,而其他选择性变体则在眼细胞中占优势。
03.利用短读长和长读长测序技术精细化 circRNA 识别
如上所述,彻底研究环状 RNA 的序列组成能够为理解其生物学功能提供一些参考。目前,一些基于短读长测序的算法已能有效重建短环状 RNA 异构体,而更加先进的长读长测序策略则进一步实现了更广尺寸范围内全长环状 RNA 的直接重构。
利用短读长 RNA 测序进行 circRNA 识别
短读长测序常被称为第二代测序技术,其最显著的特征是高通量与短读长,前者是指一次能对几十万到几百万条DNA分子进行序列测序,而后者是指每条测序读长(read length)相对较短,通常在50到300个碱基对(bp)之间。短读长意味着该方法虽然能够在一次实验中获得大量数据,但在重建长序列或存在重复区域的基因组时,可能带来拼接困难和准确性挑战。
(1) 基于短读长测序识别可变剪接:
先前的研究表明,circRNA 具有非常复杂且独特的可变剪接模式,如果我们直接使用 gtf 注释的线性外显子来代表 circRNA 结构可能导致偏差和准确率降低。研究人员开发了多种利用短读长 RNA-seq 数据的方法来分析 circRNA 的内部结构,用于识别 circRNA 的可变剪接事件,这些方法可以被归类为间接途径或直接途径。
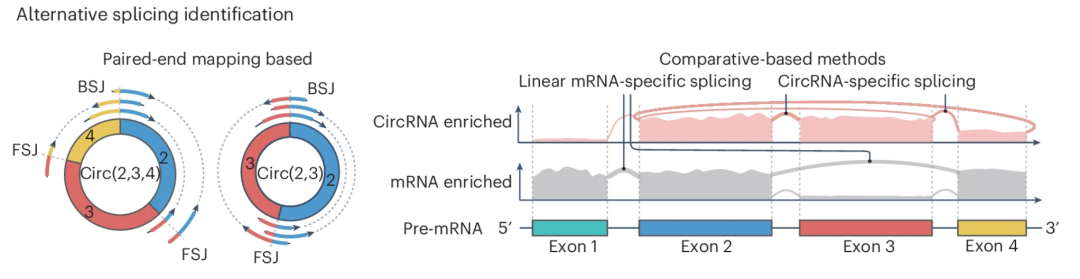
图:环状可变剪接事件的识别可通过间接或直接两种方式实现。① 是利用跨越 BSJ 位点的读段对,② 是比较环状 RNA 富集(红色)和 mRNA 富集(灰色)文库的覆盖度。上图 trackplot 显示了两个来源的 circRNA 亚型对应的特异性剪接事件覆盖情况(分别是外显子 2/3 和外显子 2/3/4。
直接方法通过跨越反向剪接位点(BSJ)的配对末端读段识别 circRNA 特异性剪接。诸如 CIRI-AS、CircSplice 和 FUCHS 等工具通过比对 BSJ 读段检测内部剪接位点。然而,其分辨率受限于 RNA-seq 片段长度,常导致超长 circRNA 中的内部剪接事件漏检。间接方法则比较 circRNA 富集样本(通常经 RNase R 处理)与未处理样本间的外显子覆盖度差异(RNase R 处理后几乎可以删除所有的线性RNA)。例如 CIRCexplorer2 分别使用polyA选择或 RNase R 消化建库的 RNA-seq 与 poly(A)+ RNA-seq 来定位 circRNA 和线性剪接。尽管这种方法规避了片段长度限制,但仍存在一些问题:① circRNA 富集样本通常仍含有>90%的线性读段,且 RNase R 对结构化 3'末端或 G-四链体的低效消化可能引入偏差;② 间接方法缺乏直接 BSJ 读段的证据来支持内部剪接结构,且需配对的处理/未处理数据集。
(2) 基于短读长测序的 circRNA 异构体鉴定:
目前开发了多种方法用于从短读长 RNA 测序数据中组装 circRNA 异构体,从而揭示不同生物过程中异构体水平的变化。与识别 circRNA 可变剪接的配对末端比对方法类似,CIRI-full 通过合并 Illumina PE250 和 PE300 平台的 BSJ 重叠读段对,以单分子分辨率重建 circRNA,实现了 500bp 以下 circRNA 的高保真组装。但其对较长 circRNA 异构体的组装能力有限。circseq_cup 则通过使用 CAP3 组装来自同一 circRNA 位点的所有 BSJ 读段进行扩展,增加了 circRNA 异构体的代表性,但需要高 circRNA 覆盖度且仍受片段长度限制。
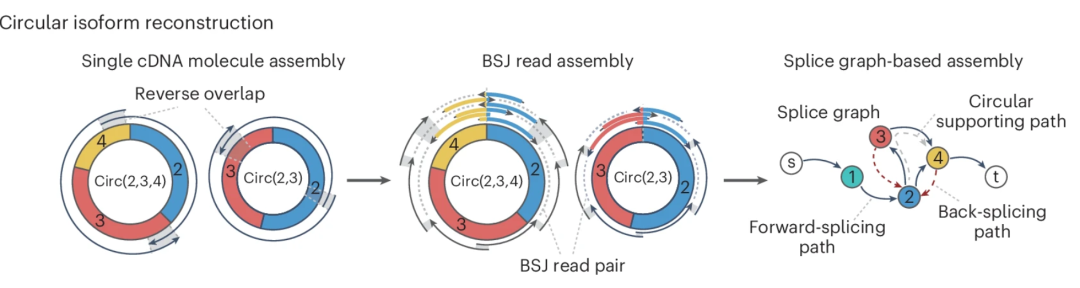
图:circRNA 亚型的重构可以通过3种方式实现。① 合并反向重叠读段对、② 组装来自同一连接位点的所有 BSJ 读段对或 ③ 基于整个基因位点的剪接图预测完成。BSJ 读段对组装方法为重构亚型的提供了强力的证据,而基于剪接图的方法虽能有效构建长链环状 RNA,但缺乏内部结构的直接证据。
相比之下,不局限于反向剪接位点读段的策略提供了更广泛的转录本重构覆盖范围。CIRIT 采用从头转录组组装技术,通过识别组装转录本中的头尾重叠来发现 circRNA。然而,大多数转录本组装工具可能并未针对 circRNA 组装性能进行优化。另外的一些方法基于图结构进行异构体推断,比如 CircAST 和 TERRACE 在各自的反向剪接位点或基因位点内,基于比对片段构建剪接图,并应用路径查找算法(如扩展最小覆盖路径、动态规划)来推断覆盖所有 BSJ 读段支持的 circRNA 异构体。尽管这种方法绕过了环状 RNA 大小的限制,但对某些内部结构缺乏直接的 BSJ 读段支持,具有更高的假阳性。
利用长读长 RNA 测序进行 circRNA 识别
如上所述,尽管二代测序目前仍然更为广泛使用,但是其还是存在着一些先天漏缺陷。三代测序的开发很好的解决了这些问题。而在这些测序平台中,PacBio 公司与 Oxford Nanopore 最富盛名,两者都能够对多达几万 bp 的碱基序列进行全长测序。这里小编不具体讲述两种测序技术的原理,大家可以自行检索,理解上比二代测序的技术过程要简单不少。
随着长读长测序技术的出现,已涌现出多种直接鉴定全长 circRNA 结构的方法(图 2c)。这些方法主要利用逆转录酶的链置换活性进行滚环逆转录(RCRT),生成单个 circRNA 的多联体的 DNA 拷贝。想象一下,circRNA 是一个闭环结构,而逆转录酶在其模板上循环绕圈合成多个重复的 cDNA 拷贝,再通过长读长测序技术便可获得该 circRNA 的多个重复片段。其中,CIRI-long 和 circFL-seq 通过模板转换和 poly(A) 加尾实现 RCRT cDNA 的第二链合成。CIRI-long 优化了 RNase R 处理条件,将线性转录本消化为小片段后,通过大小筛选富集比线性 cDNA 更长的 RCRT 产物。富集的 cDNA 随后使用牛津纳米孔技术平台进行扩增测序。相比之下,isoCirc 采用核酸外切酶处理去除链置换突出端,再将 circRNA 来源的 cDNA 连接成完整环状结构,并通过滚环扩增进行放大。
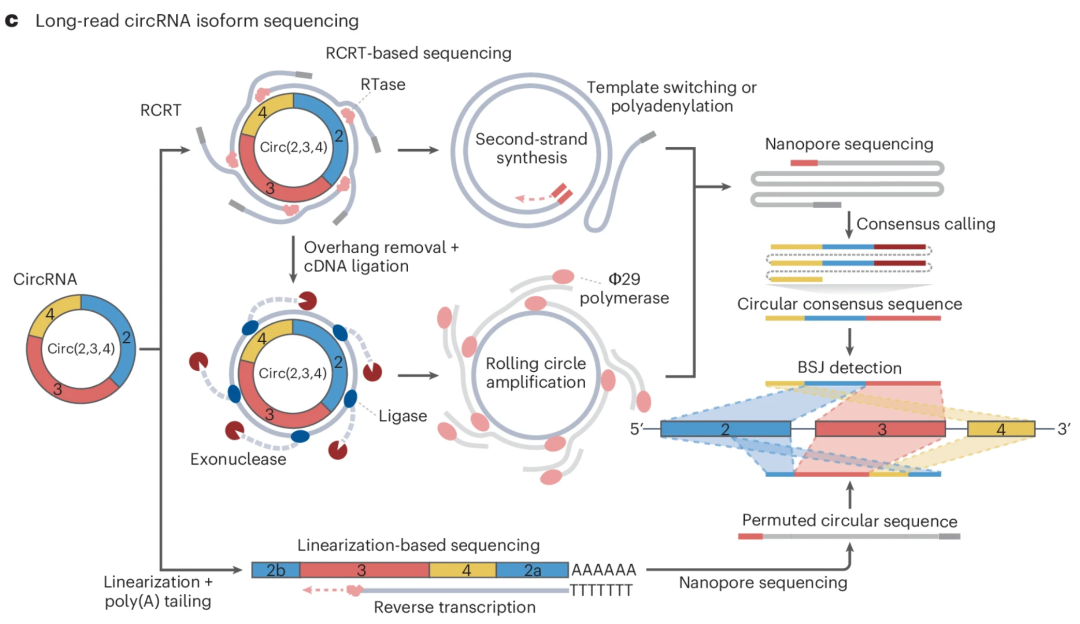
图:长读长测序策略可用于全长 circRNA 的单分子测序。在线性化策略中,环状 RNA 经片段化并加 poly(A) 尾生成带 poly(A) 尾的线性化 RNA,随后采用标准 Oxford Nanotechnologies cDNA 测序流程进行测序。circRNA 序列通过类似于短读长分析的分裂比对策略进行鉴定。另一种基于 RCRT(滚环逆转录)的策略则利用模板转换或多聚腺苷酸化来捕获 RCRT 产物,或采用核酸外切酶和单链 DNA 连接酶生成多拷贝序列的环状 cDNA。这些连接产物通过聚合酶进行滚环扩增以构建文库并进行纳米孔测序。基于 RCRT 策略的测序读长由全长 circRNA 序列的多拷贝串联体组成,随后通过一致性序列识别和 BSJ 检测来识别全长 circRNA 序列。
上述所有策略均产生长串联体测序 read,从而实现对全长 circRNA 单拷贝的鉴定。共识序列通过使用 trf 或部分顺序比对算法计算得出,并与参考基因组进行比对以识别 BSJ 和全长异构体。除了基于 RCRT 的策略外,circNick-LRS 结合不同的片段化条件来线性化 circRNA,随后进行聚腺苷酸化和纳米孔测序。测序分子展示出与 RCRT 方法相似的环状序列排列,但如果线性化发生在单个 circRNA 的多个位点,可能导致遗漏内部 circRNA 结构。
04.circRNA 的细胞异质性分析
circRNA 表现出高度的组织和细胞类型特异性,这使得仅对组织进行批量 RNA-seq 分析容易受到细胞类型组成差异带来的偏差。例如, ciRS-7 最初因其 miR-7 海绵活性以及在肿瘤中的过表达而被认为是一种癌基因,但后续研究发现其在结肠癌中主要来源于基质细胞而非癌细胞。同样,circRNA 与 mRNA 表达水平之间的相关性更多反映了细胞组成的差异,而非传统认为的 circRNA 竞争性内源 RNA 作用。这些发现强调了迫切需要单细胞分辨率的方法来研究 circRNA 的异质性。然而,当前主流的单细胞测序平台(如 10x Chromium 系统)主要捕获线性转录本的 3′或 5′端序列,难以有效检测 circRNA。为此,部分研究人员设计了新的测序流程用于细胞异质性的 circRNA鉴定。值得注意的是,近期已经涌现不少研究通过深度学习建模顺式作用元件(如 BSJ 序列特征)于反式调控因子的表达水平,来直接预测 circRNA的细胞异质性。
(1) 利用单细胞测序解析 circRNA 的细胞异质性
在测序层面,一些研究人员采用激光捕获显微切割技术(LCM)对目标细胞类型的微批量样本进行区域分离和环状 RNA 测序。虽然 LCM 相比整体水平分析提高了细胞类型分辨率,但该方法工作量大且依赖于分离细胞群体的纯度。另外,流式细胞分选技术能对特定细胞类型中的环状 RNA 进行更高通量的测序。然而,LCM 和流式细胞术这两种方法都依赖于对研究细胞类型的已有经验,无法对新型细胞进行靶向。
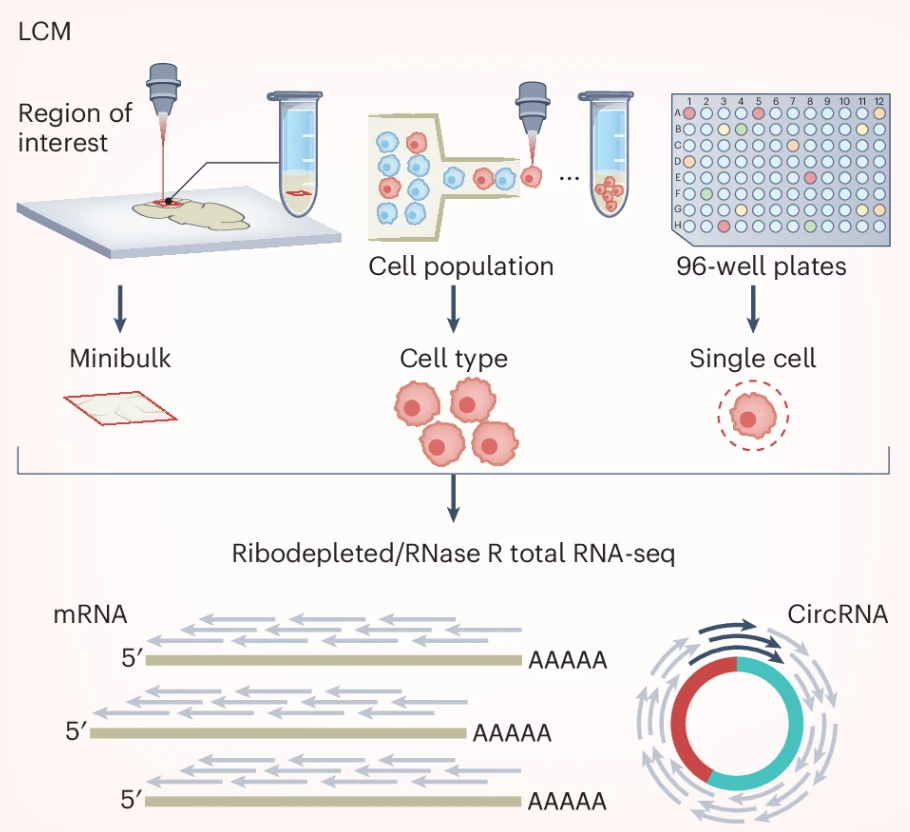
图:单细胞 circRNA 测序策略采用 ①激光捕获显微切割(LCM)、②流式细胞分选或 ③单细胞分离技术,对单个细胞进行 RNA 提取。随后,对提取的 RNA 进行核糖体 RNA 去除的全转录组测序,并可选 RNase R 处理以富集 circRNA。
单细胞测序技术如 SUPeR-seq 结合单细胞分选与随机引物逆转录,能够在小鼠和人类胚胎中表征 circRNA,并揭示胚胎发育过程中阶段特异性的 circRNA 动态变化。其他基于随机逆转录的单细胞 RNA 测序策略,包括 SMARTer total RNA 测序、MATQ-seq、VASA-seq 和 snRandom-seq,同样能够捕获这些环状转录本。与此同时,基于多聚腺苷酸化的方案,如 Smart-seq-total,也能检测到含有 BSJ 序列的降解 circRNA 片段。
尽管其他单细胞全长 scRNA-seq 方法主要依赖 polyA 选择(这种方法难以有效捕获缺乏 polyA 尾的 circRNA),但在这些富含 polyA的数据集中仍能够检测到大量 circRNA。另外,circSC 整合了 171 项全长 scRNA-seq 研究数据,绘制了人类和小鼠细胞中的 circRNA 图谱,揭示了脑组织样本、发育胚胎和乳腺肿瘤中高度细胞类型特异性的表达模式。然而,由于缺乏 circRNA 富集且测序深度较低,每个细胞仅能检测到少量 circRNA(其中许多 circRNA 仅由一两条 BSJ 读段支持),这增加了假阳性的风险。这些局限性凸显了对高通量单细胞 circRNA 测序策略的迫切需求。
(2) 利用深度学习预测 circRNA 的细胞异质性
深度学习算法彻底改变了 circRNA 的检测方式,使研究人员能够在单细胞甚至是空间分辨率水平进行分析。circRNA 的生物发生受到剪接体、RNA 结合蛋白(RBPs)以及侧翼内含子互补序列等因素的精细调控。这种复杂但明确的调控机制意味着,基于这些顺式作用序列特征和反式作用调节因子的表达水平潜在可以用于预测 circRNA 表达模式。
在此基础上,CIRI-deep 引入深度神经网络来预测配对样本间反向剪接包含率的变化。该模型基于来自批量 RNA-seq 样本的 2500 万个 circRNA 剪接事件进行训练,适用于预测单细胞和空间转录组数据中的 circRNA 剪接偏好,并采用改进的集成梯度策略评估各种顺式和反式调控特征的贡献,从而增强对不同测序方法下 circRNA 调控机制的探索。
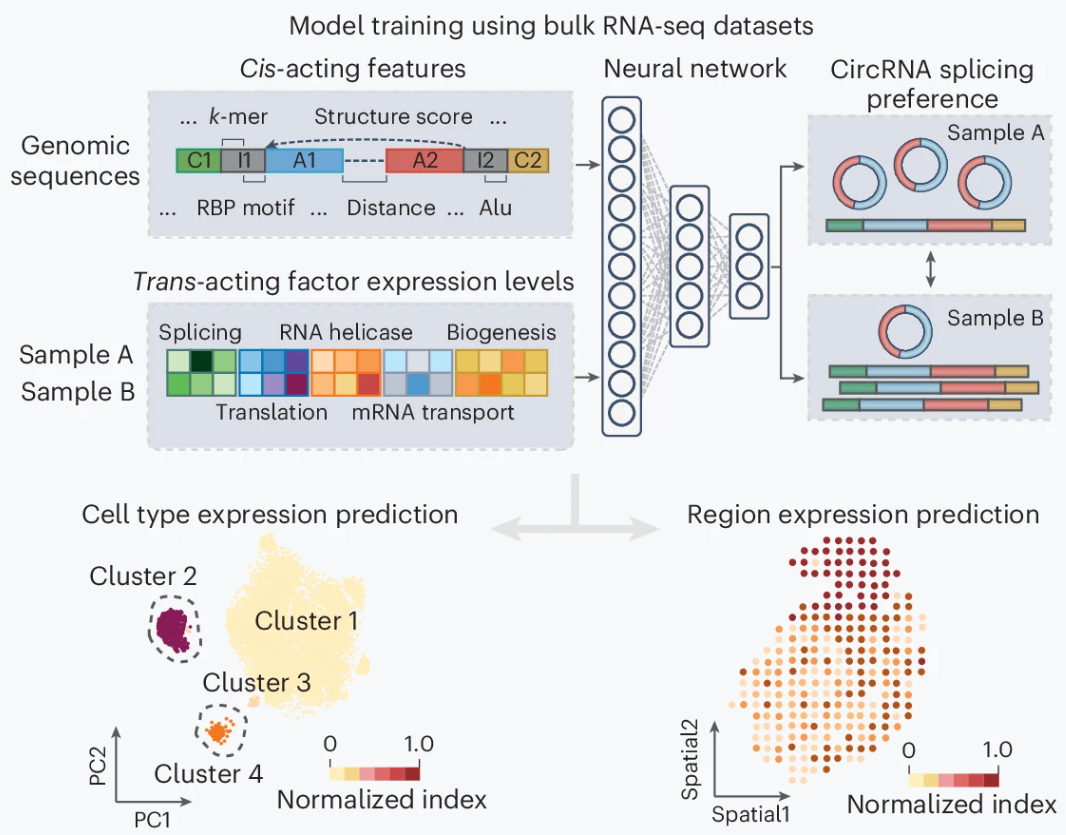
图:基于深度学习模型预测特定细胞类型或空间域中 circRNA 的剪接结果。这些模型一般整合了顺式作用基因组特征和跨样本反式作用因子的表达水平。通过训练深度神经网络,确定每对样本中每个 circRNA 的剪接偏好。训练后的模型可用于预测细胞类型特异性 circRNA 表达模式,或根据空间转录组数据估算区域特异性 circRNA 表达。上图色条代表归一化的 circRNA 指数,反映 circRNA 在细胞类型或区域间的相对剪接偏好。
然而,上述模型在正常组织样本上的训练限制了其在肿瘤或其他疾病背景中的应用。不仅如此,批量 RNA-seq 训练集还将 RBP-circRNA 调控关系与细胞类型组成异质性及技术批次效应混为一谈,这可能导致假阳性/假阴性预测。值得注意的是,最新的一项剪接体扰动研究强调了利用 RBP 敲除数据集或全基因组 CRISPR 筛选数据来优化模型的策略,这可以更好地模拟 circRNA 反向剪接的调控机制。
5.circRNA 的功能表征分析
通过差异表达和剪接分析,研究人员可在多种实验条件下探索 circRNA 的调控功能。在大规模队列中,将 circRNA 水平与基因和/或 miRNA 表达相关联,可揭示潜在的调控网络,如 circRNA–miRNA–mRNA 轴。另外,一些深度学习模型能够整合实验验证的 circRNA 与疾病关联,以预测新的关联。
(1) 经典套路分析的功能性 circRNA 预测
差异表达和剪接分析可测量 circRNA 在不同条件下的变化,例如疾病状态或实验处理。随后利用公共数据库或基于序列特征(包括 RBP 结合基序和 miRNA 响应元件)进行从头预测,对差异表达 circRNA 的调控功能进行注释。许多研究使用 circRNA 靶基因进行进行 GO 和 KEGG 富集分析,但这种方法可能产生错误的结论,因为 circRNA 的表达常与靶基因存在差异。
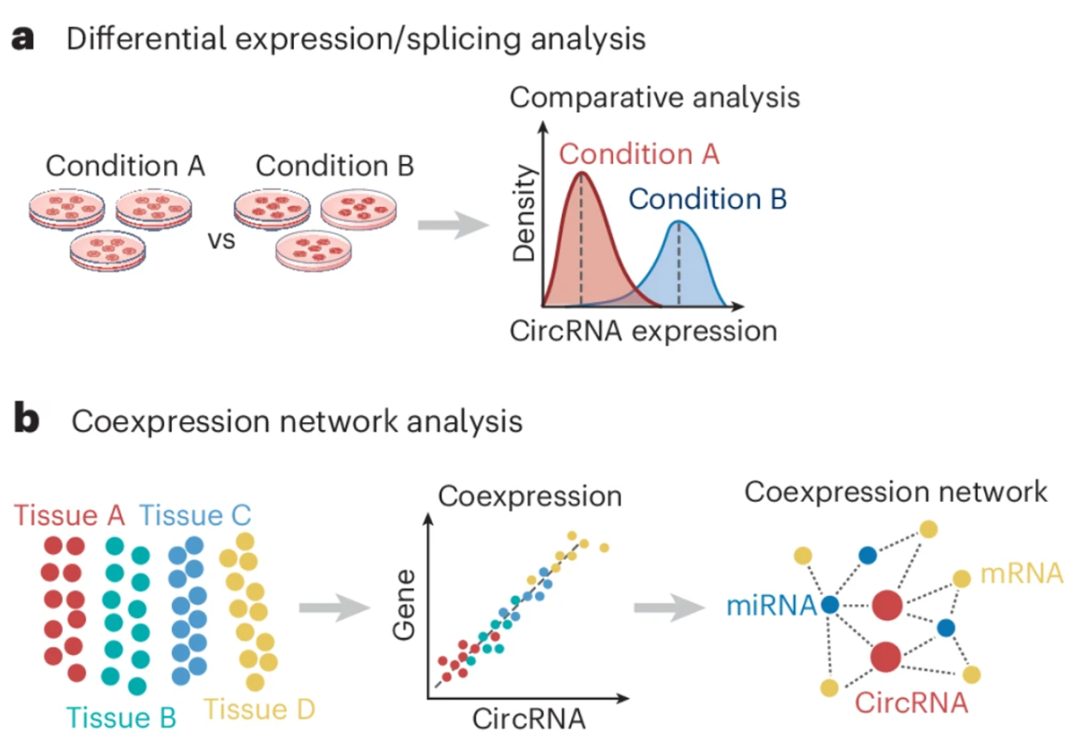
图:基于差异表达 (a) 或 共网络建模 (b) 的分析解释表型特异的 circRNA。
近期的研究转而采用基于网络的算法来筛选功能性 circRNA。这类 mRNA-circRNA 共表达网络通常基于大规模 circRNA 与 mRNA 表达数据构建。circRNA 与 mRNA 表达间的强正相关性暗示共表达或共功能关系,而负相关则表明潜在的负向调控。在此基础上,为了优先筛选疾病相关的 circRNA,可采用随机游走算法量化候选 circRNA 与已知疾病相关基因的邻近程度。此外,基因组序列的保守性可以进一步结合进来,为功能性相关 circRNA 的筛选提供有效策略。
(2) AI 辅助方法的功能性 circRNA 预测
近期衍生了不少基于深度学习的疾病相关 circRNA 预测算法,这些算法通常利用 circRNA-疾病网络。① 首先,它们从经过整理的环状 RNA 数据库中收集实验验证的 circRNA-疾病关联 。② 随后采用不同方法测量 circRNA 与疾病之间的相关性:circRNA 相似性(通过序列匹配)、疾病相似性(通过语义方法,如共享的临床特征和分子机制)以及 circRNA-疾病相互作用相似性(通过熵、拓扑结构、功能特征和高斯相互作用谱核 )。③ 为预测新关联,这些算法采用了卷积神经网络、自编码器和图神经网络等深度学习模型。值得注意的是,一些最新模型如 CLCDA 和 CircDA 等整合了 RBP 结合位点和 miRNA 响应元件,为 circRNA 调控预测提供了额外信息。
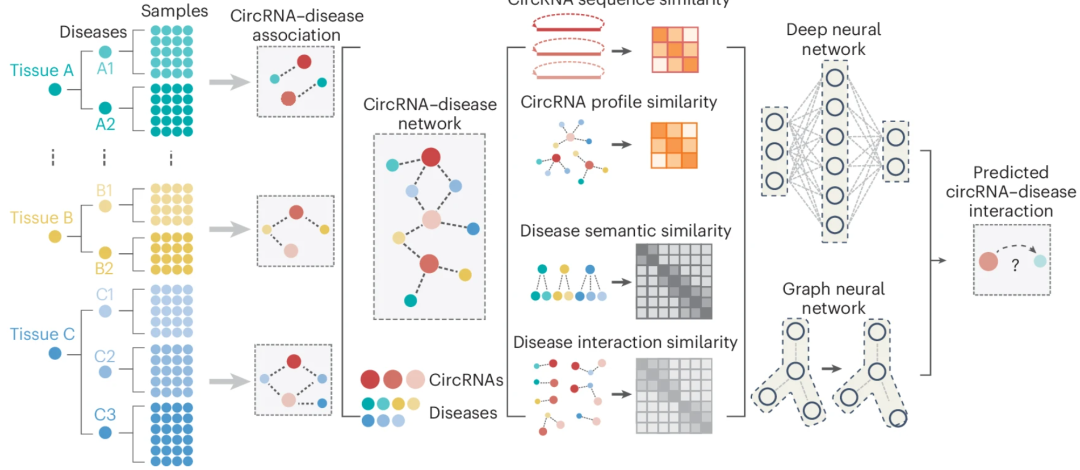
图:基于深度学习表征功能 circRNA,一般需计算单个疾病的 circRNA–疾病关联并整合构建 circRNA–疾病关联网络。上述模型使用到的特征涉及 circRNA 序列相似性、疾病语义相似度(如共享临床特征和分子机制)以及 circRNA 与疾病间相互作用谱相似性等参数。
然而,上述模型大多仍停留在概念验证阶段,依赖于相互作用谱相似性或来自 RBP 与 miRNA 相互作用数据库的数据,这可能限制了它们独立识别新型疾病相关 circRNA 的能力。因此,亟需开发更具普适性的模型,能够系统性地对新检测到的 circRNA 进行优先级排序。此外,下一步研究重点应放在开发可解释且多功能的深度学习模型上,这些模型应整合基因表达谱数据,而非仅依赖语义上的疾病-疾病相似性,以增强疾病间相似性的可解释性,并提升靶基因预测的准确性。最后,并非所有 circRNA 都具有功能相关性。近期的一些研究表明,大多数 circRNA 可能是真核生物剪接的非适应性副产物,而非功能性实体。因此,在优先级排序时纳入宿主基因表达变化或细胞类型组成转变,有助于在区分剪接副产物的同时更精准地识别功能性 circRNA。
5.当前挑战与未来的发展方向
circRNA 检测目前仍然存在几大挑战:① RNA质量影响显著,低 RNA 完整性数 (RIN值) 会导致降解,从而影响BSJ位点的识别;② 富集策略选择不一,如rRNA去除法BSJ比例低,而RNase R处理虽提高灵敏度,却存在结构依赖性、重复性差等问题,改进方法包括poly(A)去除和结构优化等;③ 实验设计差异带来强烈批次效应,影响数据整合;④ 测序技术方面,短读长(Illumina)适合大规模研究但分辨率有限,长读长(Nanopore/PacBio)虽能检测全长circRNA但成本高、精度不一。另外,测序深度也决定了检测能力,尤其在BSJ极少的情况下尤为重要。⑤ 算法层面上,不同工具的 BSJ 支持读数门槛不同,造成灵敏度和结果不一致。同时,线粒体 circRNA 因伪基因干扰难以准确识别;⑥ 在功能注释上,尽管已有多种数据库和方法集成RBP、miRNA结合位点及翻译潜力等信息,但由于数据来源异质性大,整合困难,且缺乏成体系的多组学数据限制了 circRNA 功能预测的准确性和通用性。
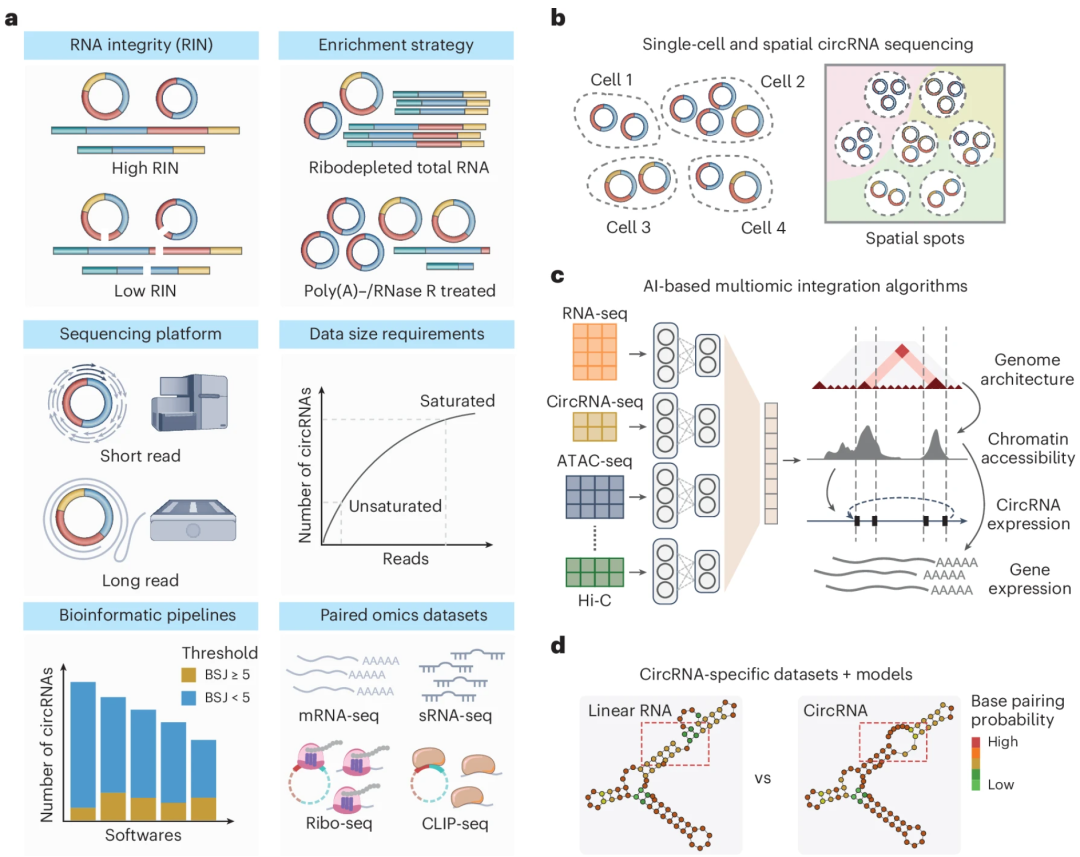
图:circRNA 检测的调整与未来发展。a,整合大规模环状 RNA 测序数据面临的挑战。首先,RIN 至关重要,因为降解的 circRNA 会在下游处理过程中丢失,阻碍 BSJ 读段的检测。其次,多样化的 circRNA 富集策略会导致检测效率差异并产生显著的批次效应,影响 circRNA 定量的准确性。测序层面上,短读长测序通常只能在 BSJ 水平提供结果,而长读长方法能实现更复杂的异构体水平定量。另外,测序深度会影响 circRNA 检测的饱和度,不同生物信息学流程的灵敏度与过滤阈值差异也增加了数据整合难度。值得注意的是,虽然配对测序数据集能为推断 circRNA 调控机制和功能提供证据,但不同研究间的异质性给整合带来了更多难度; b,单细胞和空间 circRNA 测序技术的发展为以更高分辨率表征 circRNA 表达模式提供了机遇。在此,优化的 circRNA 测序策略对于从单细胞和空间位点的有限材料中检测 circRNA 至关重要;c,基于 AI 的多组学算法的发展可以整合组学特异性特征,为基因组结构、染色质可及性及其他表观遗传特征如何影响 circRNA 生物发生提供关键见解;d,circRNA 及其同源线性 RNA 可能表现出不同的结构和功能。因此,开发 circRNA 特异性 AI 模型需要积累 circRNA 训练集,并开发定制算法以纳入 circRNA 特异性特征,如外显子混杂模式和独特的 BSJ 序列。
一些新兴领域如 circRNA 的单细胞与空间测序仍处于初期阶段,现有技术多依赖 polyA 捕获,而这不适用于无尾的circRNA,故亟需结合长读长测序与单细胞条码技术的发展。同时,AI算法在表达数据补全、结构预测方面显示出巨大潜力。已有模型能预测 mRNA 翻译效率,未来可拓展至 circRNA 功能预测与设计。尽管如此,circRNA 特有的环状结构、外显子重排等特征,使其无法直接套用现有模型,需进一步构建专属训练集与建模策略。此外,目前可用于训练的高质量、经实验验证的 circRNA 功能和结构数据仍较缺乏,严重制约了 AI 模型在 circRNA 研究中的进一步应用。