第九章:了解特殊场景下的redis
一.特殊场景下的redis命令
概念:
Redis 提供了多种高级数据类型来应对不同的业务需求,其中 Streams 是一种日志结构化的消息队列类型,支持多生产者、多消费者模型,适用于事件流处理和任务分发等场景;Geospatial 则用于存储地理空间数据(如经纬度坐标),支持基于位置的半径查询,非常适合实现“附近的人”、“附近的商家”等功能;HyperLogLog 是一种基于概率的计数器,用于高效估算集合中唯一元素的个数,极大地节省内存,常用于 UV 统计;Bitmaps 通过位图实现高效状态标记,适用于布尔值记录场景,比如用户是否登录、是否签到等操作;Bitfields 是位图的进一步扩展,允许以结构化的方式存储和操作多个位段,可进行位级别的加减、赋值等操作,用于实现节省空间的复杂数值存储结构。这些数据类型都围绕“高性能、低内存”设计,在特定场景下比常规数据结构(如 String、List、Set 等)更具优势。
ps:因为用的少,所以不展示演示,需要用到请查看官方文档
1.1Streams
Stream 是 Redis 中用于处理消息流的数据类型,可在特定场景中使用,例如模拟实现事件传播机制。它类似于一个阻塞队列,是 Redis 作为消息队列的重要支撑,属于 List 的 blpop/brpop 升级版。
1.2Redis geospatial
实体信息:Redis geospatial 是 Redis(一种开源的内存数据结构存储系统,用作数据库、缓存和消息代理)的一个数据类型。
背景知识:它主要用于存储地理空间坐标(经纬度),在存储了一些点之后,用户可以给定一个坐标,在这些存储的点里按照半径、矩形区域等方式进行查找,在地图类应用中具有重要作用,例如查找附近的商家、用户等场景。
1.3Redis HyperLogLog
实体信息:Redis HyperLogLog 是 Redis 的一种数据类型。
背景知识:其唯一的应用场景是估算集合中的元素个数。在统计服务器 UV(用户访问次数)时,若使用 Set 存储 userld(假设每个 userld 为 8 个字节),1 亿 UV 会占用约 800MB 内存,而 HyperLogLog 最多仅需 12KB 空间就能实现类似效果。它不存储元素内容,而是记录元素特征,以此来判断新增元素是否为新元素,不过存在约 0.81% 的标准误差。
1.4Redis bitmaps
实体信息:Redis bitmaps 是 Redis 的一种数据类型。
背景知识:它使用 bit 位来表示整数,本质上是 Set 类型针对整数的特化版本,能够节省空间。与 HyperLogLog 相比,它更节省空间,且既可以存储数字也可以存储字符串,同样不存储元素内容,仅起到计数效果。但 HyperLogLog 在存储元素时提取特征的过程是不可逆的,会丢失信息。
1.5Redis bitfields
实体信息:Redis bitfields 是 Redis 的一种数据类型。
背景知识:它与 C 语言中的位域(位段)概念相似,可理解为一串二进制序列(字节数组)。用户可以把字节数组中的某几个位赋予特定含义,并进行读取、修改、算术运算等操作。其主要目的也是节省空间,相较于 Redis 中的 String 和 hash 数据类型,在空间利用上更具优势。
二.scan
Redis 渐进式遍历(Scan 命令)
2.1渐进式遍历的概念
Redis 中的 keys * 命令会一次性获取 Redis 中所有的键,这个操作比较危险,可能会一下子得到太多的键,从而阻塞 Redis 服务器。而通过渐进式遍历(即使用 scan 命令及其相关命令),可以做到既能获取到所有的键,同时又不会卡死服务器。
渐进式遍历不是一个命令就能把所有的键都拿到,而是每执行一次命令,只获取其中的一小部分,这样能保证当前这一次操作不会太卡。要想得到所有的键,就需要多次执行渐进式遍历命令,也就是 “化整为零”。
2.2Scan 命令
- 基本语法:
SCAN cursor [MATCH pattern] [COUNT count] [TYPE type] - 关键概念 - 光标(cursor):光标指向了当前遍历的位置。需要注意的是,cursor 不能理解成 “下标”,它不是一个连续递增的整数,仅仅就是一个 “字符串”。程序 / 客户端不能识别这个光标概念,只有 Redis 服务器知道这个光标对应的元素位置。当光标设置成 0 时,意味着这次遍历是从头开始获取。返回值的前半部分是下次继续遍历时光标要从哪里开始,后半部分是真正遍历到的键的内容。
- MATCH pattern:用于匹配指定的键模式,和之前介绍的
keys命令功能类似(keys *命令可以忘记,推荐使用scan命令)。 - COUNT count:用于限制这一次遍历能够获取到的元素数量,默认是 10。但需要注意的是,此处的
count和 MySQL 的limit不一样,它只是给 Redis 服务器一个 “提示” 或 “建议”,写入的count和实际返回的键的个数不一定完全相同,但不会差很多。 - TYPE type:可以指定要遍历的键的类型。
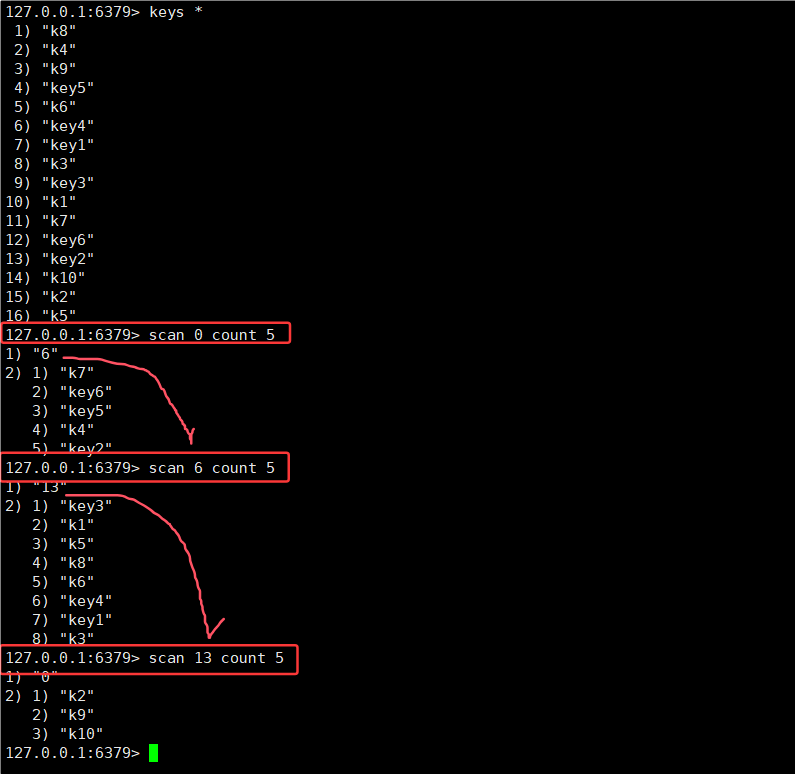
2.3Scan 命令的执行过程
以实际示例来看,比如执行 scan 0 count 3 等命令,每次执行会返回下次 scan 光标的位置以及本次遍历拿到的键。当命令返回的 cursor 回到 0 时,才说明遍历结束了。另外,scan 命令有可能返回空的集合。在渐进式遍历过程中,不会在服务器端存储任何状态信息,遍历随时可以终止,不会对服务器产生任何副作用,而且每次遍历设置的 count 数字也不要求每次都一样。
2.4Redis 键值类型说明
Redis 里的键(key)都是字符串类型,但值(value)的类型不一样,包括 5 个通用的数据类型(String、List、Hash、Set、ZSet)和 5 个特殊场景使用的类型(如 Stream、Geospatial、HyperLogLog、Bitmaps、Bitfields)。
提醒:
渐进性遍历 scan 虽然解决了阻塞的问题,但如果在遍历期间键有所变化(增加、修改、删
除),可能导致遍历时键的重复遍历或者遗漏,这点务必在实际开发中考虑。
三.数据库管理命令
3.1Redis 中 Database 的概念
- 与 MySQL 的对比
- 在 MySQL 中,一个服务器可以有多个 database,一个 database 上可以有多个表,并且可以随意创建和删除数据库。
- Redis 也有 database 的概念,但不像 MySQL 那样随意。Redis 中的 database 是现成的,用户不能创建新的数据库,也不能删除已有的数据库。
- Redis 数据库的数量与隔离性
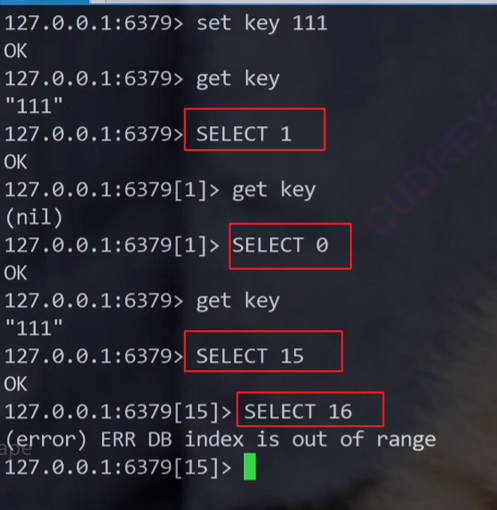
- 默认情况下,Redis 提供了 16 个数据库,编号为 0 到 15。
- 这 16 个数据库中的数据是相互隔离的,即不同数据库之间的数据不会相互影响。
- 默认使用的数据库
- 默认情况下,Redis 使用的是 0 号数据库。
- 可以使用
select dbIndex命令来切换数据库,例如select 1会切换到 1 号数据库。 - 实际使用 Redis 时,很少会关注到数据库,一般默认使用 0 号数据库即可。
3.2相关命令
- FLUSHDB
- 作用:删除当前数据库中的所有 key。
- 语法:
FLUSHDB [ASYNC | SYNC]ASYNC:异步执行,不会阻塞 Redis 服务器,立即返回 OK,但实际删除操作在后台进行。SYNC:同步执行,会阻塞 Redis 服务器,直到删除操作完成才返回 OK。
- FLUSHALL
- 作用:删除所有数据库中的所有 key。
- 注意:这个命令非常危险,在公司尤其是生产环境中千万不能乱用,否则会造成严重的数据丢失。
- DBSIZE
- 作用:获取当前数据库中 key 的个数。
- 可用性:从 Redis 1.0.0 版本开始可用。
- 时间复杂度:O (1),即获取键数量的操作是常数时间复杂度。
- ACL 分类:属于 @keyspace、@read、@fast 类别。
举个栗子~:
切换数据库: