云轴科技ZStack AI翻译平台建设实践-聚焦中英
(一)前言
面对全球化商业竞争,企业出海亟需高质量翻译支持,包括不限于产品UI、技术文档、营销资料等面向出海国语种的全线配备。当下AI技术蓬勃发展,如何利用AI深度赋能提升翻译质量?如何将翻译工作流形成标准化工具链?如何构建切合实际场景的质量评估体系?这些都是企业翻译业务面临的现实挑战。
本文主要聚焦中英场景,从ZStack文档实践出发,围绕本地模型部署与精调、一站式AI翻译平台设计思路、实际建设难题与攻克等要点,向大家全面深入介绍ZStack AI翻译平台建设的成功实践。
(二)本地模型部署与精调
当下,以ChatGPT为代表的大语言模型(LLM)在通用翻译领域已展现出强大能力。借助零样本学习(Zero-shot)和提示词工程(Prompt Engineering, PE),LLM能够处理绝大多数日常语言的互译任务,其流畅度和上下文理解能力远超传统机器翻译系统。
然而,当场景切换至专业领域翻译(如云计算软件文档),通用LLM立即暴露出明显短板:无法理解企业特定术语体系和表达规范。
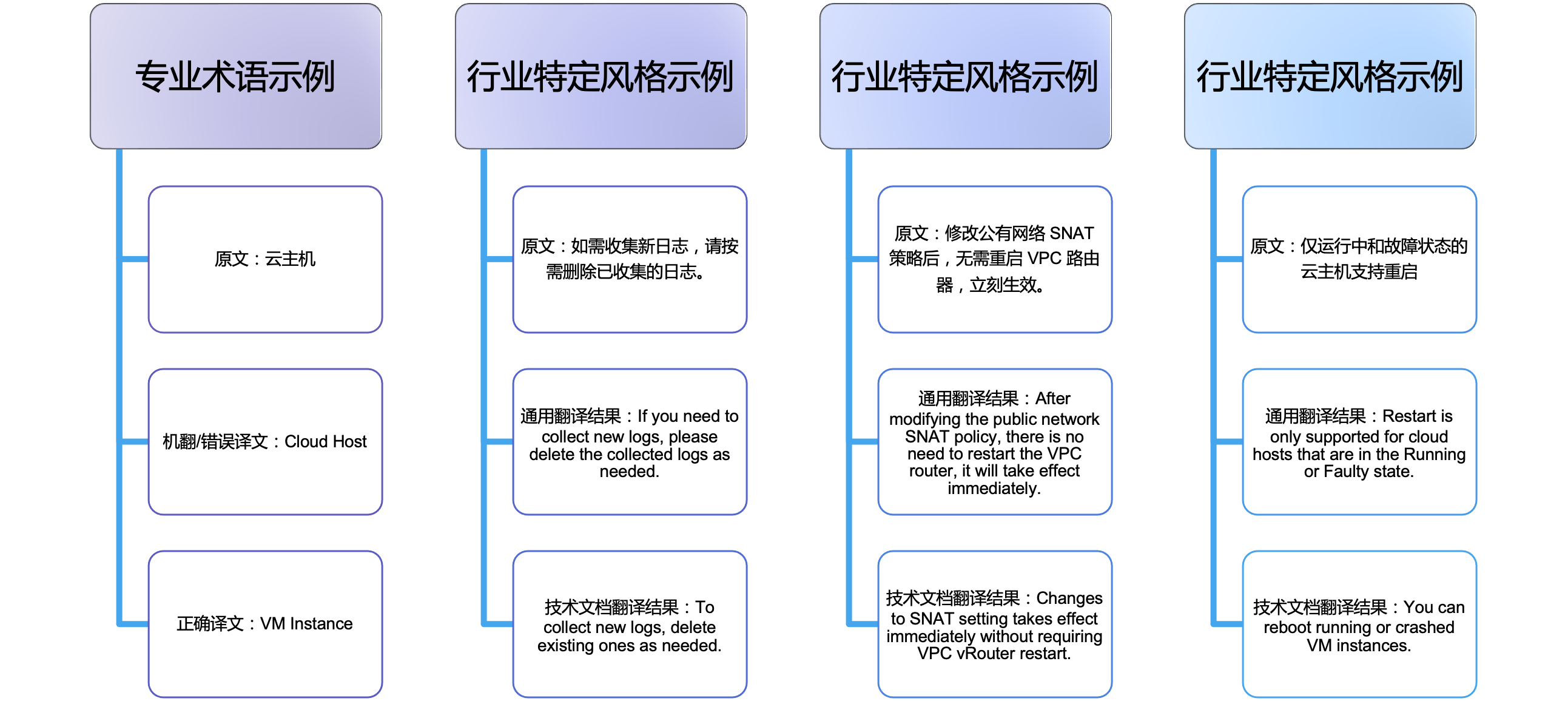
图1. 通用LLM的翻译短板
为应对上述挑战,ZStack采取“基础模型+领域精调”技术路线,通过以下五个关键环节构建专业翻译能力。
1.数据准备
模型精调的效果高度依赖训练语料的质量。ZStack构建了分层次、高标准的语料筛选体系,语料来源分布确保核心技术文档(如用户手册)占比50%、产品UI界面文字(如界面提示语)占比不低于40%、辅助技术文档(如实践教程)占比10%,并且所有双语语料均需通过术语准确性、风格一致性、技术深度、场景覆盖度等维度的严格审核。
2.模型选择
选用Qwen2.5-7B-Instruct作为基础模型,该开源模型在保持7B参数规模适中性的同时,展现出良好的多语言处理能力和架构扩展性。
3.模型精调
采用LoRA(Low-Rank Adaptation)等参数高效精调技术,在单张NVIDIA 3090显卡上即可完成训练,大幅降低计算资源需求。
4.模型评估
评估体系结合量化指标与人工质检,采用BLEU、ROUGE、COMET等自动评估工具,配合专业英文文档工程师审核,形成多维质量评估矩阵。
5.模型迭代
为确保模型能力与业务需求同步进化,采用“3+1”迭代模式(即:3个月语料筛选+1个月模型调优与质检),结合数据更新与评估反馈进行持续优化。
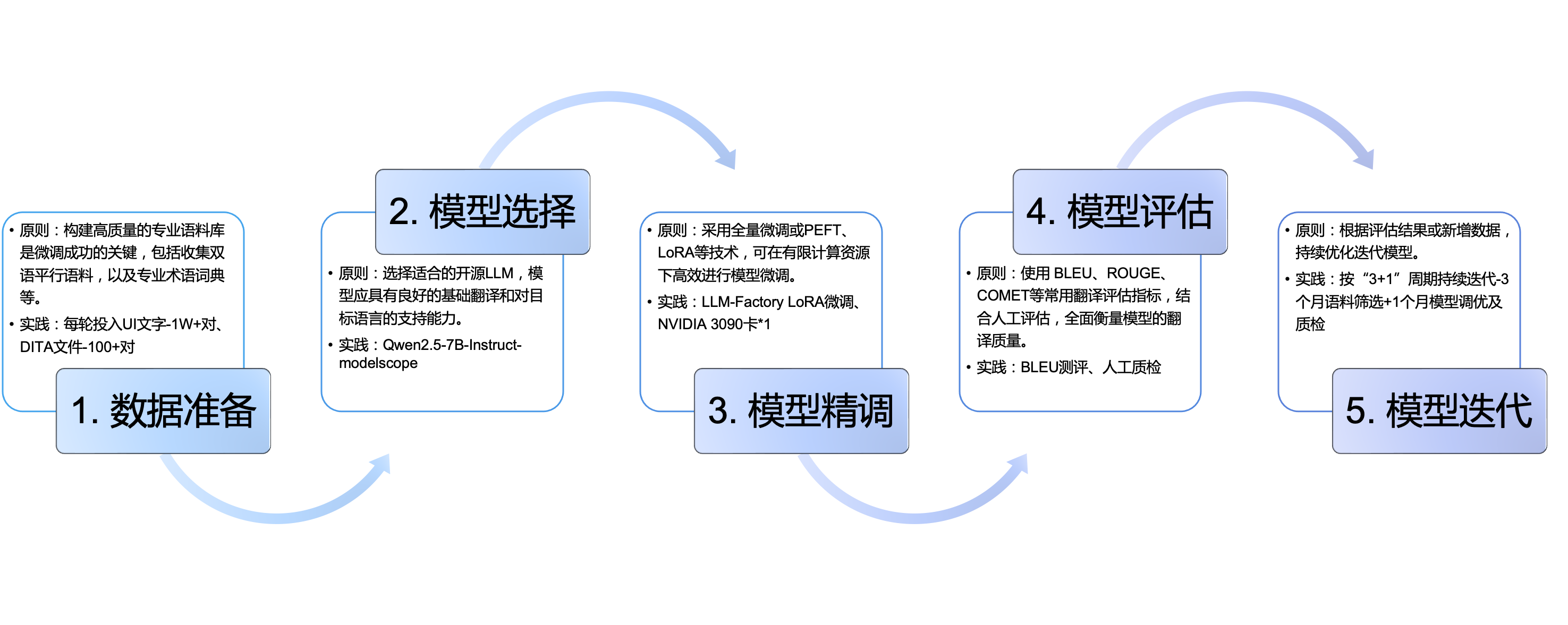
图2. 精调LLM的五个关键环节
(三)ZStack AI翻译平台整体设计思路
如何将精调LLM与翻译工作流有机整合,是下一个需攻克的难点。
ZStack AI翻译平台基于ZStack AIOS智塔平台构建,整合了从AI基础设施到应用接口的全栈能力,内接ZStack专业语料库+精调LLM,提供一站式翻译管理服务。
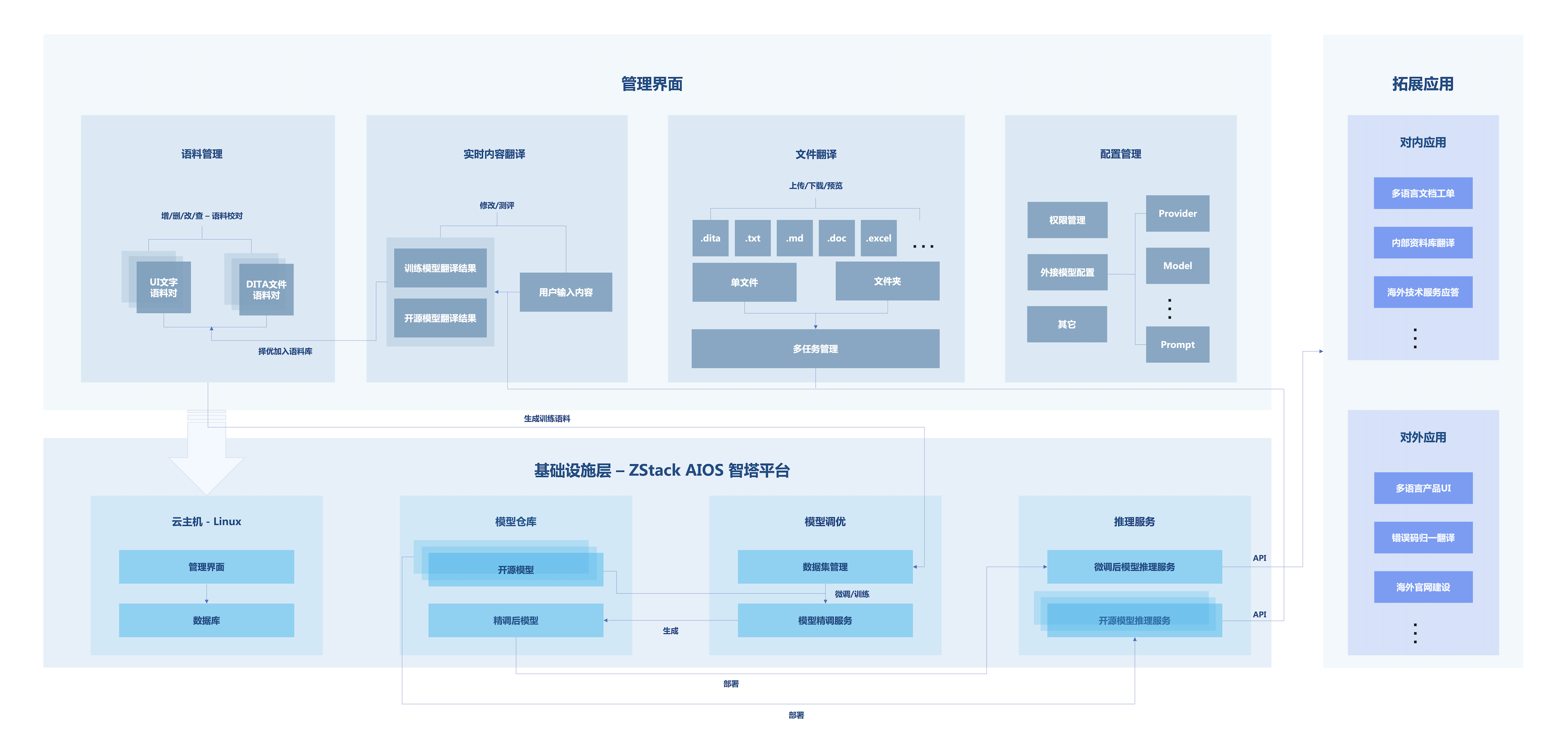
图3. 整体设计框架
1.基础设施层
整合了模型仓库、模型调优、推理服务和数据管理组件。
- 模型仓库集中管理AI模型,提供预置模型和自定义模型。
- 模型调优工作台支持基于数据集的参数精调。
- 推理服务提供模型快速部署到生产环境的能力。
- 数据管理组件通过云主机对外提供翻译平台的管理界面和数据库服务。
2.核心功能层
包含了语料管理、实时内容翻译、文件翻译、配置管理四大核心模块。
- 语料管理持续收集优质双语资源。
- 实时内容翻译提供自训练模型和外接模型,支持翻译结果对比,优质翻译可一键加入语料库,形成数据闭环。
- 文件翻译支持.dita、.txt、.md、.doc、.excel等格式文件的单个/批量翻译,提供翻译进程管理与翻译结果在线预览。
- 配置管理提供权限管理、外部模型接入设置等运维能力,确保系统灵活可控。
3.应用接口层
通过标准化API对接企业内外部业务系统,提供翻译赋能。
- 对内支持文档工单翻译、内部知识库翻译、海外技术服务应答等。
- 对外支持产品UI翻译、错误码归一翻译、海外官网建设等。
(四)ZStack AI翻译平台实际建设难题与攻克
1.DITA文档的分割与重组
考虑到LLM在结构化文本理解和层次化内容处理上的固有能力,在构建DITA语料库过程中采取格式保持策略,完整保留DITA文档的原始内容结构与标记信息。
相较于传统纯文本翻译流程,上述方法显著减少标记对、属性值、内嵌代码块等格式化元素和引用信息的后处理工作量,从而降低整体翻译任务的复杂度。然而,受制于模型的Token长度约束,仍需对超长文件进行合理分割,以避免LLM输出截断等异常情况发生。
考虑到翻译场景中词汇和句子语义高度依赖上下文信息,在DITA文档分割过程中采取段落级分割策略,最大程度避免产生孤立词汇、独立句子或句子截断的情况。
鉴于此,ZStack自研一套自适应分割算法,将长篇DITA文档动态分解为满足上述语义完整性要求的多个子文件片段。这些分割后的DITA片段将依次输入到训练后的LLM中进行处理,最终将翻译结果进行结构化整合。
2.多重机制保障结果准确性
考虑到LLM基于概率生成的工作机制导致输出结果存在固有的不确定性,以及DITA文档必须严格遵循类XML格式规范,平台构建多层次质量保障体系以确保翻译结果的准确性和可靠性。
1)训练数据质量控制层面
考虑到训练数据质量直接影响模型质量,采取人工质检与AI质检相结合的双重质量控制机制。一方面,训练语料需通过专业英文文档工程师审核,另一方面,通过提示词工程结合指令微调技术,确保模型输出专注于翻译结果本身,排除思维过程、总结性文本等非翻译内容的干扰。
2)模型输出质量保障层面
针对DITA结构完整性,平台提供多级重试机制。当翻译结果不符合XML结构规范时,系统将自动调整参数进行二次尝试;如果结果仍不符合规范,将对原文件进一步分割后重新翻译。在极端情况下,系统会调用更大规模的模型进行处理。针对DITA内容准确性,平台下一步将部署AI质检系统,对翻译内容进行二次验证。
3.提示词工程
文档翻译作为高度专业化应用场景,要求系统将所有输入文本严格视为翻译源材料,而非对话交互内容。在训练阶段,通过系统提示词结合指令微调技术,使模型深度理解翻译任务的执行指令,实现“纯翻译、零对话”行为模式。值得注意的是,即使训练阶段仅使用中英翻译提示词,模型在推理阶段对英中翻译指令的理解同样保持高度准确性。
训练与推理是相互协同的过程。为优化训练与推理的时间效率,降低系统提示词的Token消耗至关重要。在训练与推理阶段,ZStack致力于构建精简而完备的提示词描述体系,涵盖翻译风格、输出格式、特定规则等关键要素,使模型在训练阶段逐步掌握翻译任务的偏好配置,并在推理阶段达到预期效果。鉴于模型已具备丰富的基础知识储备,部分提示词可采用通用性描述,无需过度细化,例如“保持XML结构输出”即可实现预期效果。
(五)ZStack AI翻译平台价值
1.统一管理、直观便捷
ZStack AI翻译平台提供统一的可视化管理界面,支持一站式维护训练语料、实时翻译文本内容、创建文件翻译任务、跟进翻译进程及结果。对于翻译失败的任务,可直接查看任务日志,快速定位问题。
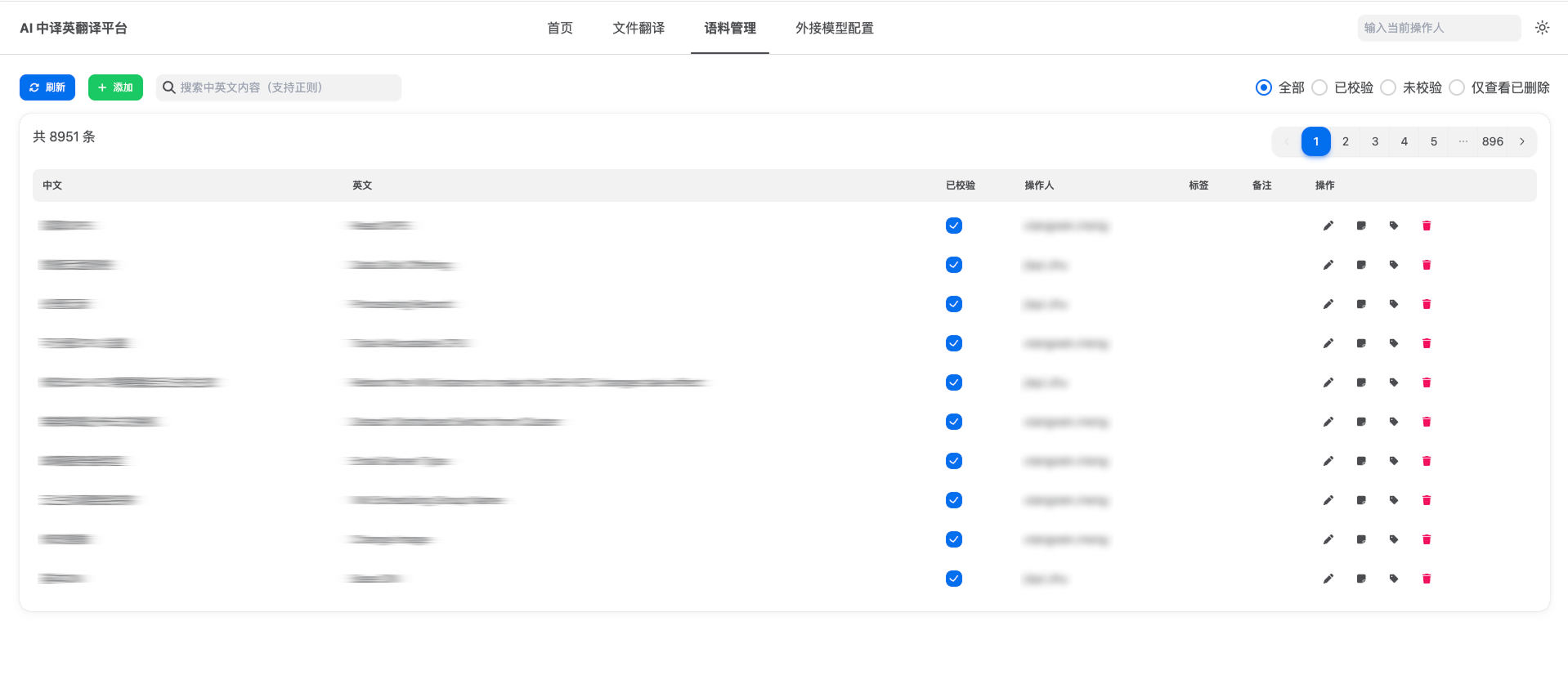
图4. 语料管理界面
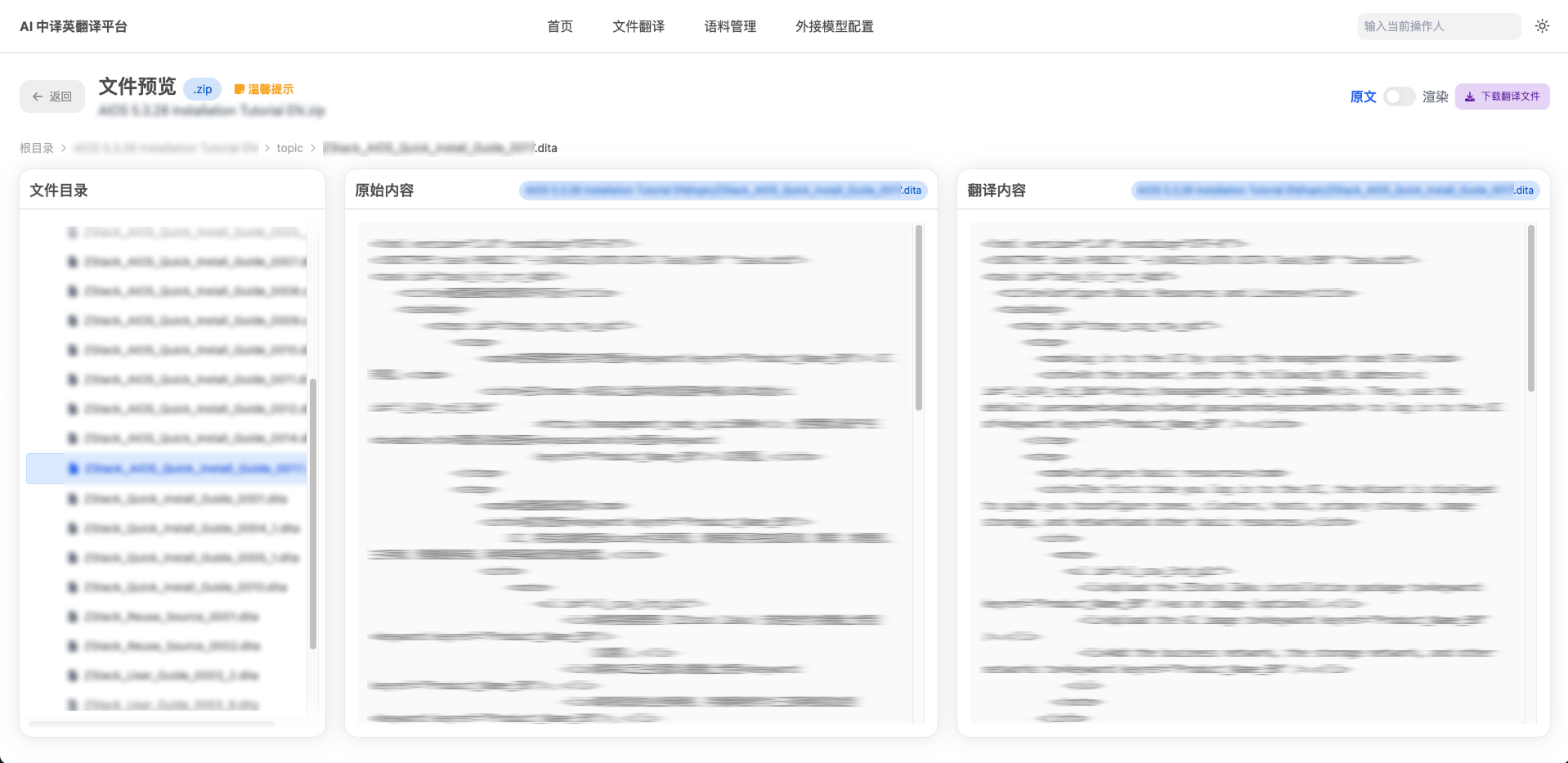
图5. 文件翻译界面
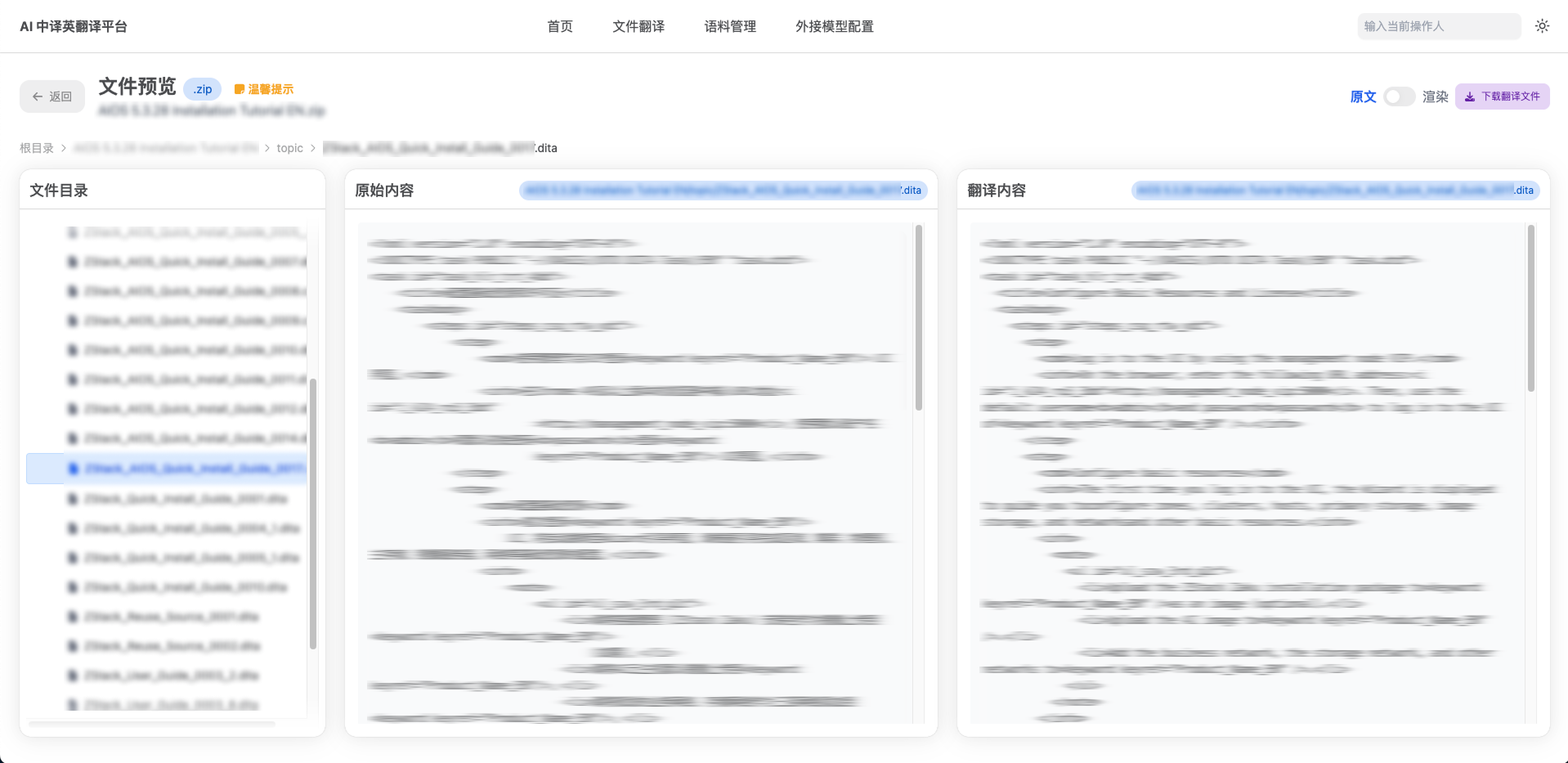
图6. 翻译结果预览
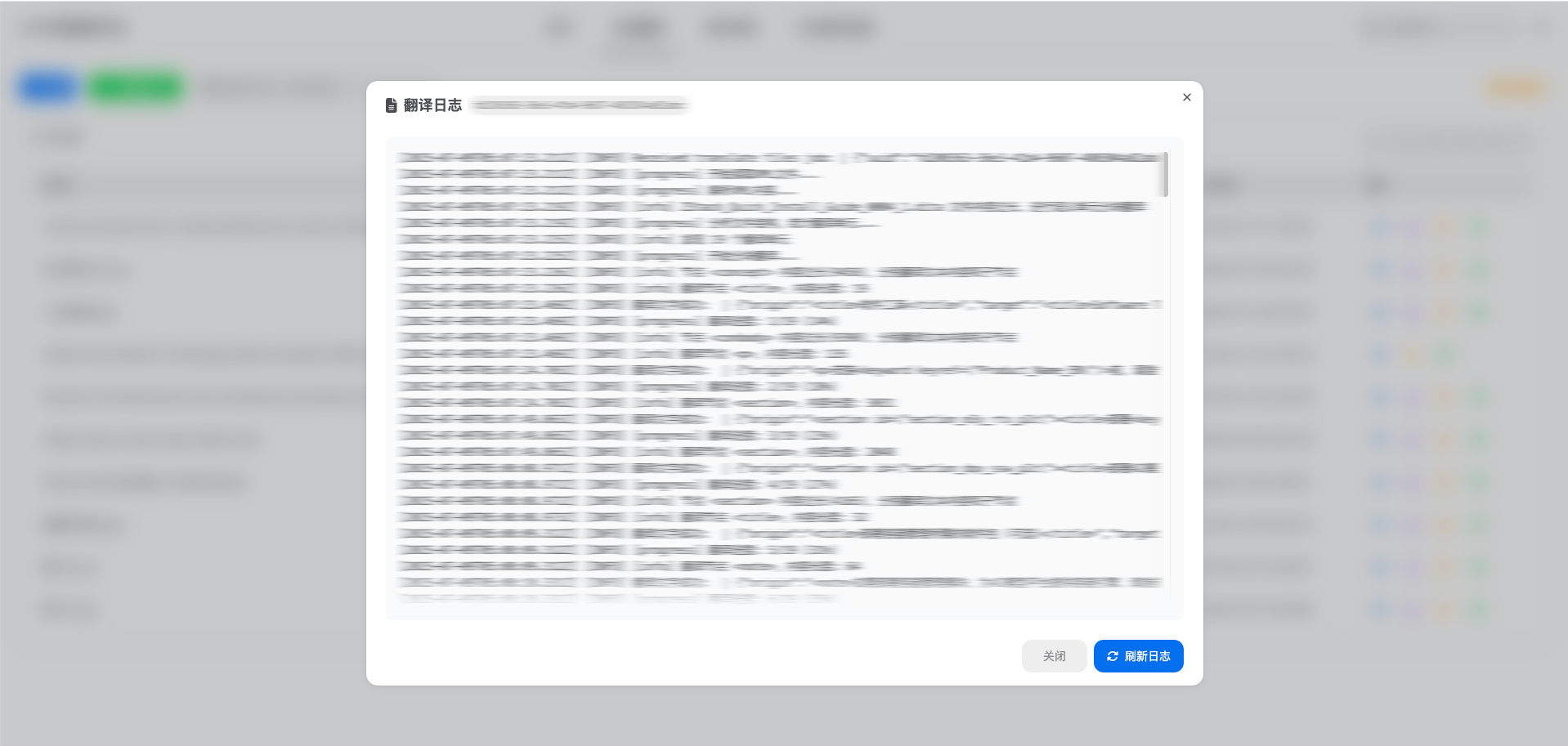
图7. 查看任务日志
2.灵活拓展,赋能提效
ZStack AI翻译平台通过标准化API接口,支持对接各种业务系统,提供翻译赋能。例如,将平台对接i18n系统,一键翻译产品UI界面文字,配合人工质检,加速产品UI翻译交付效率。
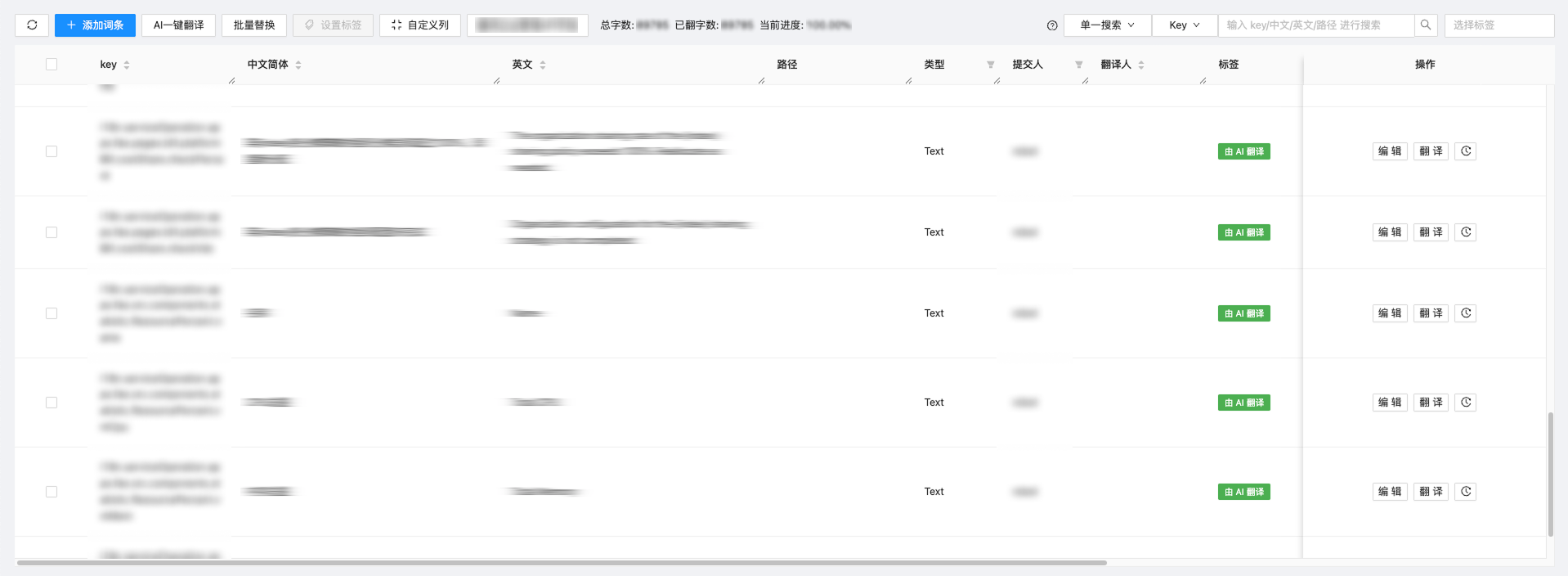
图8. 对接i18n系统
(六)结束语
为应对全球化挑战,ZStack文档一直致力于专业领域翻译技术的创新与实践。从LLM领域精调到ZStack AI翻译平台构建一站式翻译服务,不仅提升了翻译的准确性与专业性,而且深入实际业务场景,将翻译工作流形成标准化工具链。未来我们期待与更多同行者一起探索,进一步推进专业领域翻译技术向前发展。(联合作者:潘玲、孟祥文、黄浩)