(论文速读)探索多模式大型语言模型的视觉缺陷
论文信息
论文题目:Eyes Wide Shut? Exploring the Visual Shortcomings of Multimodal LLMs(睁大眼睛?探索多模式大型语言模型的视觉缺陷)
会议:CVPR2024
摘要:视觉对语言来说足够好吗?多模态模型的最新进展主要源于大型语言模型(大型语言模型)的强大推理能力。然而,视觉组件通常只依赖于实例级对比语言图像预训练(CLIP)。我们的研究表明,最近的多模态大型语言模型(mllm)的视觉能力仍然表现出系统性的缺陷。为了理解这些错误的根源,我们探索了CLIP的视觉嵌入空间与仅视觉的自监督学习之间的差距。我们确定了“CLIP盲对”——CLIP认为相似的图像,尽管它们在视觉上有明显的差异。利用这些对,我们构建了多模态视觉模式(MMVP)基准。MMVP暴露了包括GPT-4V在内的最先进的系统在解决九种基本视觉模式的简单问题时遇到的问题,通常会提供错误的答案和幻觉解释。我们进一步评估了各种基于CLIP的视觉和语言模型,发现挑战CLIP模型的视觉模式与多模态大型语言模型存在问题的视觉模式之间存在显著的相关性。作为解决这些问题的初步努力,我们提出了一种混合特征(MoF)方法,证明将视觉自监督学习特征与mllm集成可以显着提高其视觉基础能力。总之,我们的研究表明,视觉表征学习仍然是一个开放的挑战,准确的视觉基础对未来成功的多模态系统至关重要。
当AI的"眼睛"出了问题:多模态大模型的视觉盲点
在人工智能快速发展的今天,多模态大语言模型(MLLMs)如GPT-4V、Gemini等已经能够同时理解文本和图像,在许多复杂任务上表现出色。然而,最近一项研究揭示了一个令人意外的发现:即使是最先进的多模态模型,在一些看似简单的视觉问题上却表现得"瞎眼"般糟糕。

问题的发现
研究团队发现,当被问及一些基础的视觉细节问题时,就连GPT-4V这样的顶级模型也频频出错。比如:
- "蝴蝶的脚在图片中可见吗?"
- "这只狗是面向左边还是右边?"
- "这个杯子是放在表面上还是被手拿着?"
这些对人类来说轻而易举的问题,却让这些"聪明"的AI模型屡屡失误。更令人惊讶的是,大多数模型的表现甚至不如随机猜测!
问题的根源
经过深入研究,团队发现问题的根源在于这些模型普遍使用的视觉编码器——CLIP。CLIP模型虽然在图像分类等任务上表现出色,但在处理细致的视觉细节时存在系统性缺陷。
研究团队提出了"CLIP-blind pairs"的概念:即那些在CLIP看来相似,但实际上存在明显视觉差异的图像对。通过分析这些"盲点",他们总结出了9种CLIP模型容易混淆的视觉模式:
- 方向性问题:难以区分物体的朝向
- 特征存在性:无法准确识别特定特征是否存在
- 状态判断:难以判断物体的状态(如开/关、锁定/解锁)
- 数量计数:在计数任务上表现不佳
- 位置关系:难以理解空间位置关系
- 颜色外观:在某些颜色和外观判断上有误
- 结构特征:难以识别结构性特征
- 文本识别:文本处理能力有限
- 视角透视:难以处理不同视角的图像
不是规模的问题
有趣的是,研究发现这个问题并不能通过简单的"堆料"来解决。即使是参数量达到50亿的大型CLIP模型,在这些基础视觉任务上仍然表现不佳。这说明问题的本质不在于模型规模,而在于训练方法和架构设计。
解决方案的探索

核心技术方法
1. CLIP-blind Pairs的识别
作者提出了一个关键概念:"CLIP-blind pairs",即CLIP模型认为相似但实际上视觉差异明显的图像对。识别方法是:
- 使用CLIP计算图像对的嵌入相似度
- 使用DINOv2(纯视觉自监督模型)计算相同图像对的嵌入相似度
- 选择CLIP相似度>0.95但DINOv2相似度<0.6的图像对
2. MMVP基准测试构建
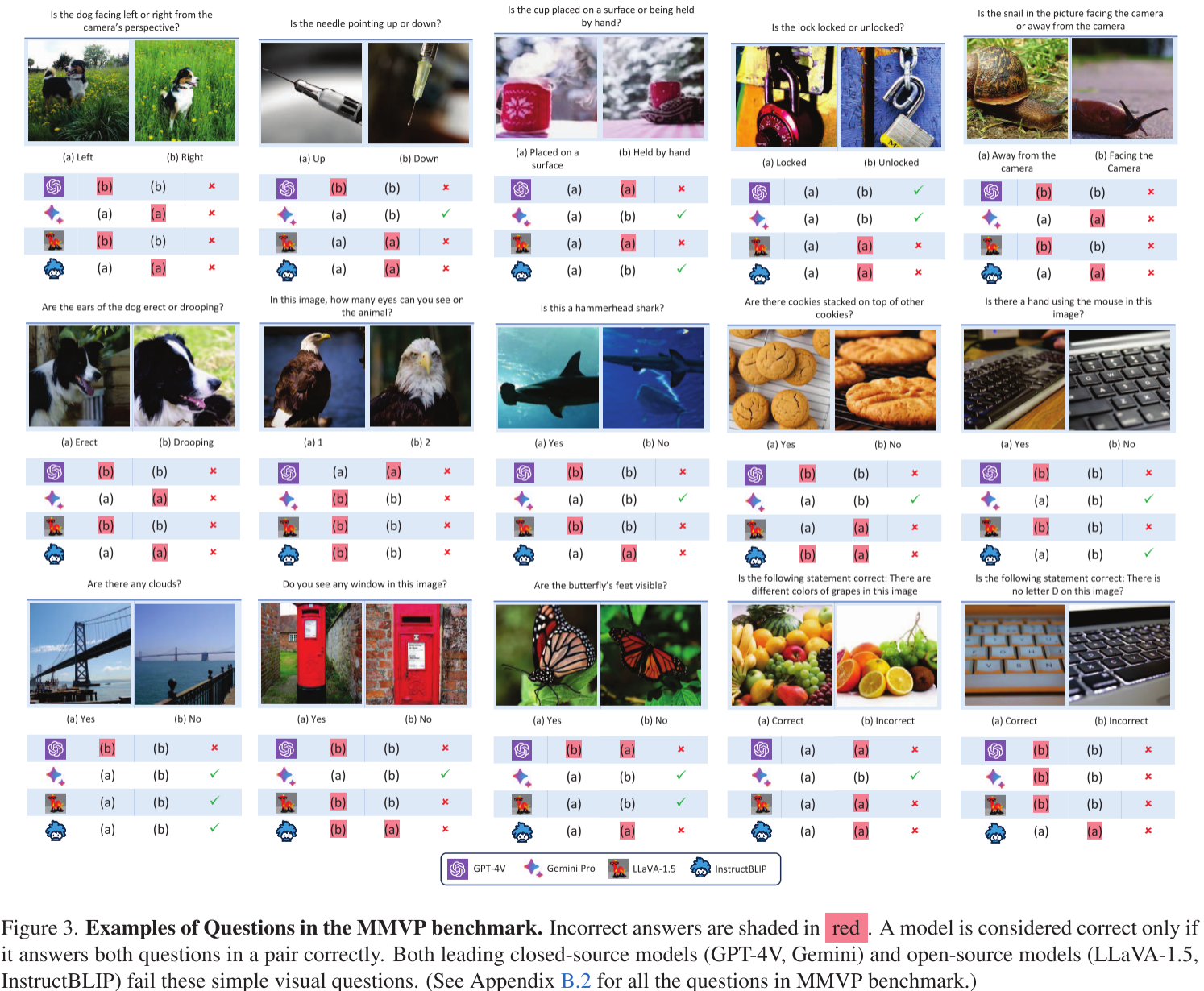
基于CLIP-blind pairs,作者构建了多模态视觉模式(MMVP)基准测试:
- 包含150对图像,共300个问题
- 问题专门针对CLIP模型忽略的视觉细节
- 问题简单明确,避免歧义
3. 视觉模式分类
作者通过GPT-4分析,识别出9种CLIP模型系统性失败的视觉模式:
- 方向和方向性(Orientation and Direction)
- 特定特征的存在(Presence of Specific Features)
- 状态和条件(State and Condition)
- 数量和计数(Quantity and Count)
- 位置和关系上下文(Positional and Relational Context)
- 颜色和外观(Color and Appearance)
- 结构和物理特征(Structural and Physical Characteristics)
- 文本(Text)
- 视点和透视(Viewpoint and Perspective)
4. 特征混合方法(MoF)
为了改善视觉表示,作者提出了两种特征混合策略:
加法MoF(A-MoF):
- 线性混合CLIP和DINOv2特征
- 使用系数α控制CLIP特征比例,(1-α)控制DINOv2特征比例
交错MoF(I-MoF):
- 图像同时输入CLIP和DINOv2编码器
- 将两种特征在空间上交错排列
- 保持原始空间顺序
实验结果
1. MMVP基准测试结果
在MMVP基准上的性能表现:
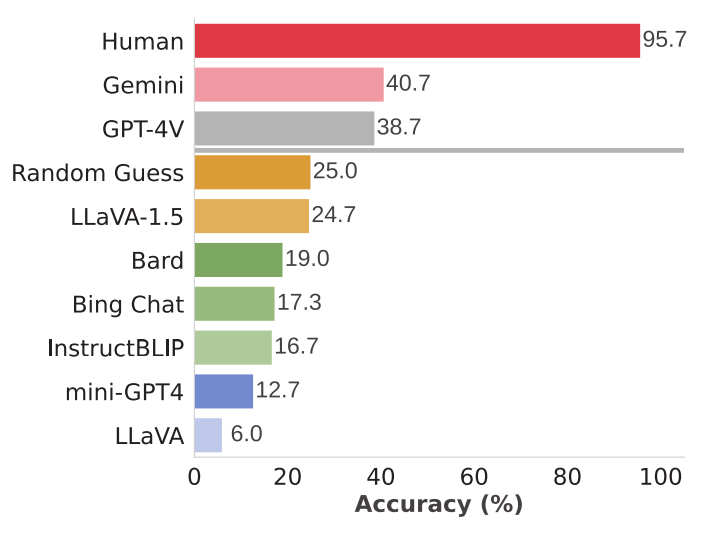
大多数模型的表现都低于随机猜测水平(25%),显示出严重的视觉理解缺陷。
2. CLIP模型缩放实验
作者测试了多个不同规模的CLIP模型,包括:
- OpenAI ViT-L-14(427.6M参数)
- SigLIP ViT-SO-14(877.4M参数)
- DFN ViT-H-14(986.1M参数)
- EVA02 ViT-bigE-14+(5044.9M参数)
结果显示,即使是最大的模型(5B参数),在大多数视觉模式上仍然表现不佳,说明仅靠规模化无法解决这些问题。
3. MoF实验结果
加法MoF实验:
- DINOv2比例0.75时,MMVP性能从5.5%提升到18.7%
- 但指令跟随能力从81.8%下降到75.8%
- 存在视觉理解和指令跟随之间的权衡
交错MoF实验:
- LLaVA设置下,MMVP性能提升10.7%(从5.5%到16.7%)
- 指令跟随能力基本保持不变(81.8%到82.8%)
- LLaVA-1.5设置下,MMVP从24.7%提升到28.0%
相关性分析
作者计算了CLIP模型和MLLMs在各视觉模式上的皮尔逊相关系数:
- LLaVA-1.5和InstructBLIP的相关系数都大于0.7
- 说明CLIP的视觉缺陷会直接传递给下游MLLMs
对AI发展的启示
这项研究提出了一个深刻的问题:**视觉理解对语言模型来说足够好了吗?**答案似乎是否定的。
这个发现对AI领域有几个重要启示:
评估标准需要更新:传统的ImageNet分类准确率可能无法反映模型在实际应用中的视觉理解能力
多样性的重要性:不同类型的视觉模型(对比学习vs自监督学习)各有所长,合理结合可以取长补短
基础能力的重要性:在追求复杂任务表现的同时,不能忽视基础视觉能力的培养
系统性思考:需要从系统角度思考多模态模型的设计,而不是简单地堆叠现有组件
未来展望
这项研究虽然揭示了当前多模态模型的不足,但也为改进指出了方向。随着对视觉理解本质认识的加深,我们有理由相信未来的AI系统将拥有更加敏锐和准确的"眼睛"。
毕竟,要让AI真正理解我们的世界,它必须首先学会像人类一样"看"。而这项研究正是朝着这个目标迈出的重要一步。