FPGA实现SRIO高速接口与DSP交互,FPGA+DSP异构方案,提供3套工程源码和技术支持
目录
- 1、前言:SRIO在FPGA+DSP架构中的作用
- 工程概述
- 免责声明
- 2、相关方案推荐
- 我已有的所有工程源码总目录----方便你快速找到自己喜欢的项目
- 我这里已有的FPGA+DSP异构方案
- 我这里已有的 GT 高速接口解决方案
- 3、工程详细设计方案
- 工程设计原理框图
- FPGA端工程源码
- FPGA端SRIO从设备(Target)
- FPGA端SRIO请求响应事务模块
- DSP端工程
- 4、工程源码1详解:FPGA逻辑工程
- 5、工程源码2详解:DSP裸机工程
- 6、工程源码3详解:DSP RTOS系统工程
- 7、工程移植说明
- vivado版本不一致处理
- FPGA型号不一致处理
- 其他注意事项
- 8、上板调试验证
- 准备工作
- 程序下载bit
- DSP裸机工程测试
- DSP RTOS系统工程测试
- 9、工程代码获取
FPGA实现SRIO高速接口与DSP交互,FPGA+DSP异构方案,提供3套工程源码和技术支持
1、前言:SRIO在FPGA+DSP架构中的作用
SRIO简介:
RapidIO 是由 Motorola 和 Mercury 等公司率先倡导的一种高性能、 低引脚数,基于数据包交换的互连体系结构,是为满足高性能嵌入式系统需求而设计的一种开放式互连技术标准;SRIO 包含三层结构协议,即物理层、传输层、逻辑层,SRIO体系结构如下:
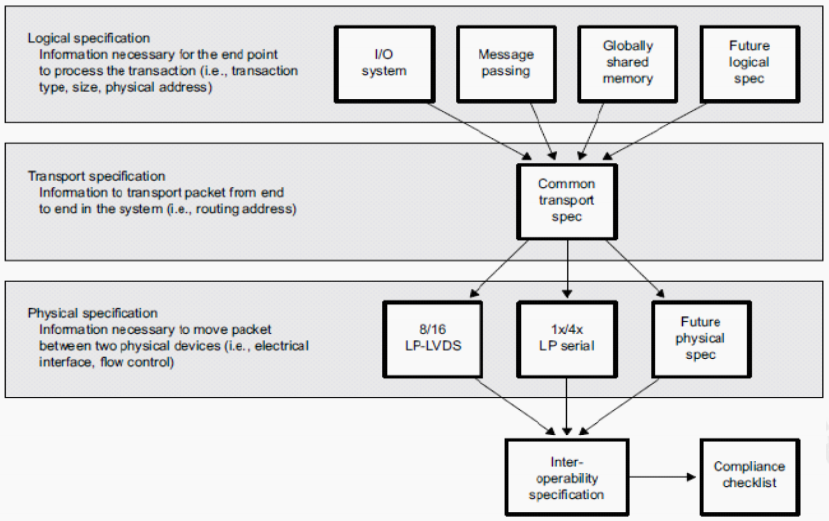
逻辑层:定义包的类型、大小、物理地址、传输协议等必要配置信息。
传输层:定义包交换、路由和寻址规则,以确保信息在系统内正确传输。
物理层:包含设备级接口信息,如电气特性、错误管理数据和基本流量控制数据等信息。
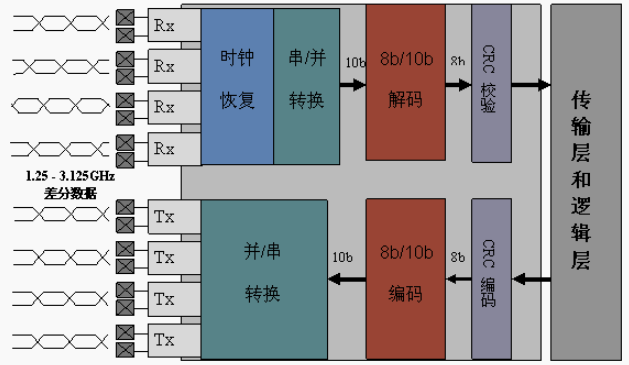
SRIO收发逻辑框图如下:
SRIO(Serial RapidIO)在FPGA+DSP异构架构中扮演着高速数据通道与系统互连核心的角色,其作用与优势主要体现在以下方面:
SRIO的核心作用
1、高速数据通道
实时数据传输:FPGA负责前端数据采集(如雷达回波、图像信号),通过SRIO将原始数据直接传输至DSP处理,速率可达 8-10 Gbps(实测效率>80%理论值)。
低延迟交互:点对点传输延迟仅微秒级,满足实时处理需求(如电机控制、雷达成像)。
2、直接内存访问(DMA)
DSP可通过SRIO直接读写FPGA的片上存储或外挂DDR,无需CPU干预。例如:
SWRITE事务实现零开销突发传输,效率达95%以上。
FPGA作为协处理器时,DSP直接获取处理结果(如滤波后图像)。
3、可靠消息通知
门铃(Doorbell)中断:DSP向FPGA发送16位轻量级消息,触发实时响应(如任务启动/停止)。
中断延迟<1μs,优于传统GPIO。
4、系统级扩展性
通过SRIO交换器连接多DSP/FPGA,构建分布式计算网络(如4个DSP+FPGA的基带处理卡)。
支持动态路由与多播传输,适应复杂拓扑。
SRIO的技术优势
1、高带宽与低延迟

2、硬件级可靠性
错误检测与重传:内置CRC校验与链路层重传机制,误码率<10⁻¹²。
路径冗余:支持多路径备份,单点故障不影响系统运行(关键用于航天电子)。
3、灵活的协议支持
传输模式:
Direct I/O:直接存储映射(NWRITE/NREAD),适合大数据块传输。
Message Passing:信箱机制,支持复杂命令交互(如FPGA向DSP发送状态报告)。
物理层适配:支持1x/2x/4x链路聚合,兼容背板(VPX)、光模块等连接方式。
4、低功耗设计
相比PCIe,SRIO功耗低30-40%(实测1.5W@5Gbps)。
静态功耗<0.1W,适合电池供电设备(如无人机雷达)。
典型应用场景
1、实时图像处理系统

FPGA完成像素校正,DSP执行AI识别,传输延迟<10ms
2、无线通信基带
FPGA处理ADC采样数据,经SRIO分发至多DSP核(如LDPC解码)。
支持5G Massive MIMO的μs级波束成型。
3、高可靠性系统
航天器中的FPGA+DSP通过SRIO互连,抗辐射设计(如三模冗余)确保太空环境下的数据传输
总结
SRIO在FPGA+DSP架构中的核心价值是:
✅ 突破总线瓶颈:提供>8Gbps的稳定带宽,替代共享总线。
✅ 实现异构协同:FPGA并行预处理 + DSP复杂算法,通过SRIO无缝衔接。
✅ 构建高可靠网络:冗余链路与硬件校验机制,满足军工/航天级需求
工程概述
本文详细描述了Xilinx的7系列FPGA实现FPGA实现SRIO高速接口与DSP交互;以下从FPGA工程和DSP工程两个方向描述整个设计:
FPGA工程
FPGA工程调用Xilinx官方的SRIO IP核实现SRIO协议的物理层、传输层、逻辑层,作为SRIO的从设备(target),SRIO IP核留出了用户逻辑接口,用户只需要写自己的逻辑电路与之对接即可完成SRIO通信;本设计只做简单的数据缓存和读写,所以用户逻辑为纯verilog代码实现的请求响应事务模块,模块例化了两个RAMB36SDP的BRAM原语用户数据读写的缓存(4K Byte),为接收到的请求事务生成对应的响应事务,该模块参考了Xilinx官方SRIO IP核的仿真工程,根据请求-响应机制构造HELLO数据包,并根据读写地址操作BRAM以实现基于SRIO协议的数据收发架构;
DSP工程
DSP工程实现 DSP作为SRIO主设备(Initiator),通过SRIO总线与远程设备通信,进行高速数据传输测试。核心功能包括SRIO子系统初始化与链路建立、NWRITE/SWRITE写操作性能测试、NREAD读操作与数据完整性验证、传输速率实时统计与错误检测等,DSP工程分为裸机工程和RTOS系统工程,裸机工程不带操作系统,实时性更好,RTOS系统工程带轻量版RTOS操作系统,稳定性更好,测试结果通过串口打印观察;
针对市场主流需求,本博客提供3套工程源码,具体如下:

现对上述3套工程源码做如下解释,方便读者理解:
工程源码1
开发板FPGA型号为Xilinx公司的XC7K325T-2FFG676I;FPGA工程调用Xilinx官方的SRIO IP核实现SRIO协议的物理层、传输层、逻辑层,作为SRIO的从设备(target),SRIO IP核留出了用户逻辑接口,用户只需要写自己的逻辑电路与之对接即可完成SRIO通信;本设计只做简单的数据缓存和读写,所以用户逻辑为纯verilog代码实现的请求响应事务模块,模块例化了两个RAMB36SDP的BRAM原语用户数据读写的缓存(4K Byte),为接收到的请求事务生成对应的响应事务,该模块参考了Xilinx官方SRIO IP核的仿真工程,根据请求-响应机制构造HELLO数据包,并根据读写地址操作BRAM以实现基于SRIO协议的数据收发架构;
工程源码2
开发板DSP型号为TI公司的TMS320C6678;DSP工程实现 DSP作为SRIO主设备(Initiator),通过SRIO总线与远程设备通信,进行高速数据传输测试。核心功能包括SRIO子系统初始化与链路建立、NWRITE/SWRITE写操作性能测试、NREAD读操作与数据完整性验证、传输速率实时统计与错误检测等,本套工程为CCS 裸机工程,不带操作系统,实时性更好,测试结果通过串口打印观察;
工程源码3
开发板DSP型号为TI公司的TMS320C6678;DSP工程实现 DSP作为SRIO主设备(Initiator),通过SRIO总线与远程设备通信,进行高速数据传输测试。核心功能包括SRIO子系统初始化与链路建立、NWRITE/SWRITE写操作性能测试、NREAD读操作与数据完整性验证、传输速率实时统计与错误检测等,本套工程为CCS RTOS工程,带RTOS操作系统,稳定性更好,测试结果通过串口打印观察;
本文详细描述了FPGA实现SRIO高速接口与DSP交互的设计方案,工程代码可综合编译上板调试,可直接项目移植,适用于在校学生、研究生项目开发,也适用于在职工程师做项目开发,可应用于医疗、军工等行业的高速接口领域;
提供完整的、跑通的工程源码和技术支持;
工程源码和技术支持的获取方式放在了文章末尾,请耐心看到最后;
免责声明
本工程及其源码即有自己写的一部分,也有网络公开渠道获取的一部分(包括CSDN、Xilinx官网、Altera官网等等),若大佬们觉得有所冒犯,请私信批评教育;基于此,本工程及其源码仅限于读者或粉丝个人学习和研究,禁止用于商业用途,若由于读者或粉丝自身原因用于商业用途所导致的法律问题,与本博客及博主无关,请谨慎使用。。。
2、相关方案推荐
我已有的所有工程源码总目录----方便你快速找到自己喜欢的项目
其实一直有朋友反馈,说我的博客文章太多了,乱花渐欲迷人,自己看得一头雾水,不方便快速定位找到自己想要的项目,所以本博文置顶,列出我目前已有的所有项目,并给出总目录,每个项目的文章链接,当然,本博文实时更新。。。以下是博客地址:
点击直接前往
我这里已有的FPGA+DSP异构方案
目前我这里有大量FPGA+DSP异构方案的工程源码,包括EMIF、SRIO、PCIE等等,对FPGA+DSP异构方案有需求的兄弟可以去看看:
直接点击前往
我这里已有的 GT 高速接口解决方案
我的主页有FPGA GT 高速接口专栏,该专栏有 GTP 、 GTX 、 GTH 、 GTY 等GT 资源的视频传输例程和PCIE传输例程,其中 GTP基于A7系列FPGA开发板搭建,GTX基于K7或者ZYNQ系列FPGA开发板搭建,GTH基于KU或者V7系列FPGA开发板搭建,GTY基于KU+系列FPGA开发板搭建;以下是专栏地址:
点击直接前往
3、工程详细设计方案
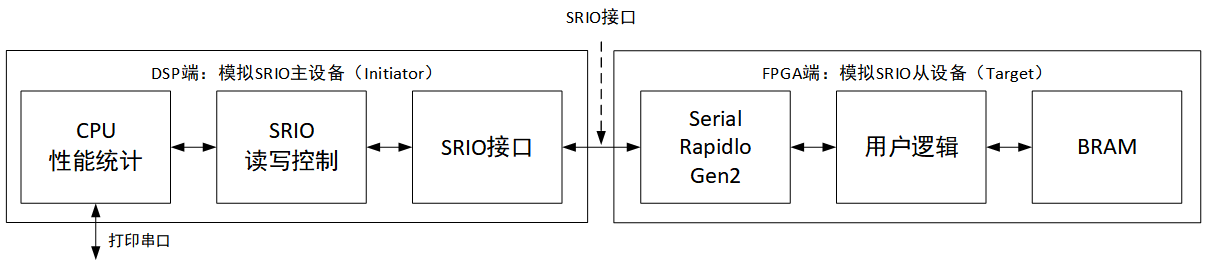
工程设计原理框图
工程设计原理框图如下:
FPGA端工程源码
FPGA端工程源码架构如下:

FPGA端SRIO从设备(Target)
FPGA工程调用Xilinx官方的SRIO IP核实现SRIO协议的物理层、传输层、逻辑层,作为SRIO的从设备(target),SRIO IP核留出了用户逻辑接口,用户只需要写自己的逻辑电路与之对接即可完成SRIO通信;本设计使用Xilinx官方的Serial Rapidlo Gen2 IP核,基础配置如下:
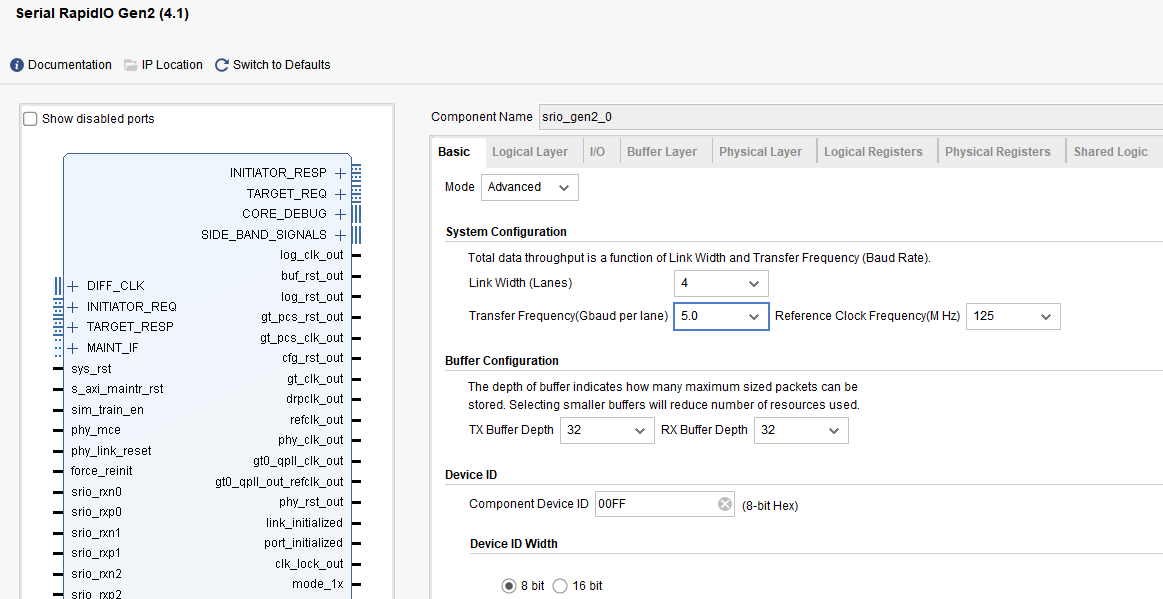
SRIO配置为5Gbps×4 Lane,对应的GT差分时钟需为125M;工程代码中通过配置cdcm61002时钟芯片输出125M连接至GTX高速收发器BANK;SRIO设计请参考Xilinx官方数据手册《pg007_srio_gen2》;I/O 端口配置使用 HELLO 格式包,其他参数保持默认值即可;
FPGA端SRIO请求响应事务模块
本设计只做简单的数据缓存和读写,所以用户逻辑为纯verilog代码实现的请求响应事务模块,模块例化了两个RAMB36SDP的BRAM原语用户数据读写的缓存(4K Byte),为接收到的请求事务生成对应的响应事务,该模块参考了Xilinx官方SRIO IP核的仿真工程,根据请求-响应机制构造HELLO数据包,并根据读写地址操作BRAM以实现基于SRIO协议的数据收发架构;
当 Initiator 发过来的写请求的目标地址的第 31 位到 16 位为 0x1087(address[31:16]=8’h1087),数据将会存储至 BRAM;其他所有无需返回响应的写请求将会被丢弃,该模块不会为 SWRITE 返回响应。当 Initiator 发过来的读请求的目标地址的第 31 位到 16 位为 0x1087(address[31:16]=8’h1087),数据将会从实际地址读出;
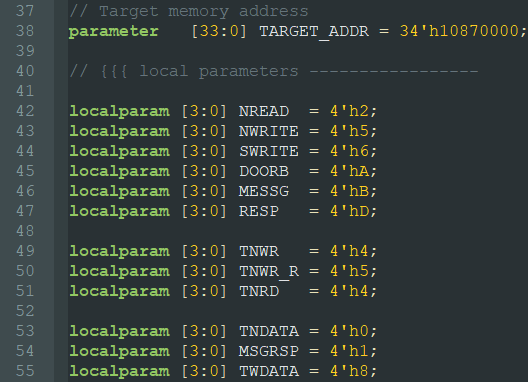
定义 HELLO 格式包头 FTYPE 字段与 TTYPE 字段的值,这两个字段的值与事务的类型有关。如下:
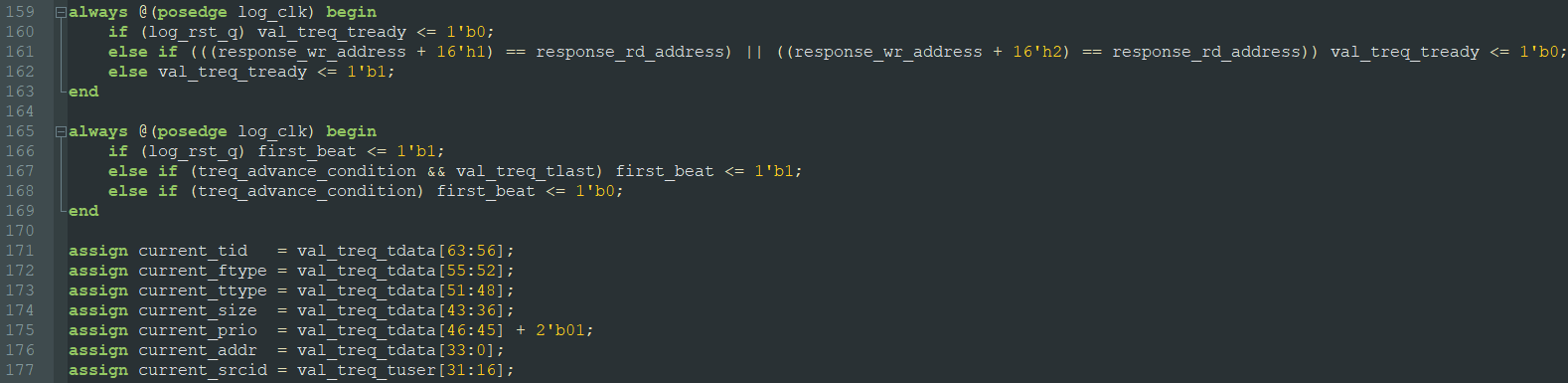
将 Initiator 发送的请求 treq_tdata 中的数据,按照 HELLO 格式的定义把对应的关键字段分离出来,如下:
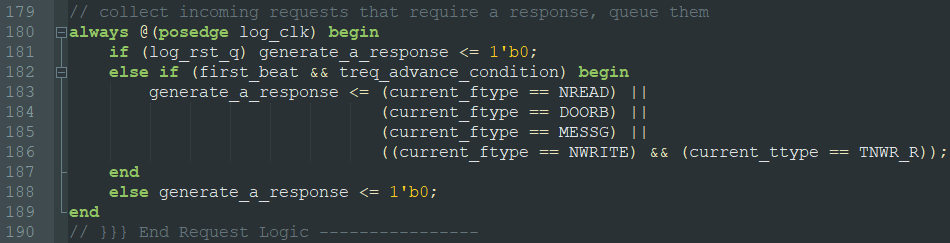
生成有响应事务的标志,可看到没有 SWRITE 的标志,如下:
配置 SRIO Initiator 发送的读写事务基地址为 0x10870000;当地址字段的第 31 位到第 16 位为 0x1087,写事务的数据将会存储至 BRAM,如下:

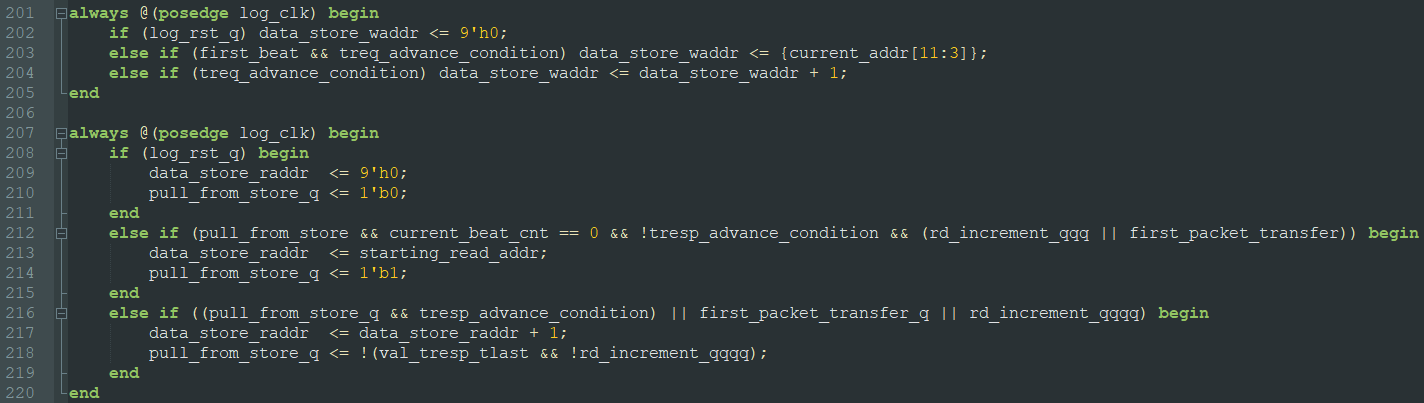
生成数据存储的写地址信号 data_store_waddr 和读地址信号 data_store_raddr,该模块的数据位宽为 64bit,其中地址取了 current_addr[11:3],而不是从第 0bit 开始取,即一次从 BRAM 读写 8Byte 大小的数据,一个地址对应一个字节,所以每读写一
次地址需递增(加 8),如下:
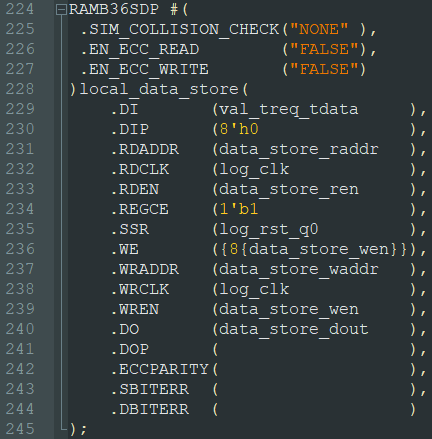
例化一个 RAMB36SDP,用于存储数据。DATA_WIDTH 为 64bit,ADDR 为 9bit,总容量为 2^9 x (64 / 8) = 512 x 8Byte = 4KByte,如下:
DSP端工程
DSP工程实现 DSP作为SRIO主设备(Initiator),通过SRIO总线与远程设备通信,进行高速数据传输测试。核心功能包括SRIO子系统初始化与链路建立、NWRITE/SWRITE写操作性能测试、NREAD读操作与数据完整性验证、传输速率实时统计与错误检测等,DSP工程分为裸机工程和RTOS系统工程,裸机工程不带操作系统,实时性更好,RTOS系统工程带轻量版RTOS操作系统,稳定性更好,测试结果通过串口打印观察;
代码功能概述
此代码实现 DSP作为SRIO主设备(Initiator),通过Serial RapidIO(SRIO)总线与远程设备通信,进行高速数据传输测试。核心功能包括:
1、SRIO子系统初始化与链路建立
2、NWRITE/SWRITE写操作性能测试
3、NREAD读操作与数据完整性验证
4、传输速率实时统计与错误检测
DSP端工程流程图如下:

DSP端SRIO读写核心细节
1、SRIO物理层配置(srio_device_init)
关键配置参数如下:
// SERDES PLL配置(250MHz参考时钟→2.5GHz)
CSL_BootCfgSetSRIOSERDESConfigPLL(0x51); // MPY=10x
// 接收器配置(5Gbps速率)
CSL_BootCfgSetSRIOSERDESRxConfig(i, 0x00468495); // EQ/CDR/TERM使能
// 发送器配置(5Gbps速率)
CSL_BootCfgSetSRIOSERDESTxConfig(i, 0x001C8F95); // TAP权重/输出摆幅
链路建立流程如下:
while(!CSL_SRIO_IsPortOk(hSrio, 0)) { // 轮询端口状态cpu_delaycycles(1000000); // 延迟1ms
}
2、数据传输机制(srio_test)
NWRITE写操作配置如下:
tparams.ftype = Srio_Ftype_WRITE; // 快速非确认写
tparams.ttype = Srio_Ttype_Write_NWRITE;
tparams.bytecount = 4096; // 4KB传输
tparams.rapidIOLSB = 0x10870000; // 目标设备地址
tparams.dspAddress = w_buff_global; // 源数据地址(DSP全局地址)
SWRITE写操作配置如下:
tparams.ftype = Srio_Ftype_SWRITE; // 流式写(低开销)
tparams.ttype = Srio_Ttype_Write_SWRITE;
NREAD读操作配置如下:
tparams.ftype = Srio_Ftype_REQUEST; // 请求类型
tparams.ttype = Srio_Ttype_Request_NREAD;
tparams.rapidIOLSB = 0x10870000; // 源数据地址(远程)
tparams.dspAddress = r_buff_global; // 目标地址(DSP)
传输控制流程
传输控制流程如下:

性能计算原理
transStart = _itoll(TSCH, TSCL); // 记录开始时间戳
// ...传输执行...
transCost = _itoll(TSCH, TSCL) - transStart; // 计算周期数// 计算带宽(Gbps)
w_rate = (transfer_size * 8) * (main_pll_freq / transCost) / 1e9;

关键代码解析
1、地址转换机制
w_buff_global = (uint8_t*)Convert_CoreLocal2GlobalAddr((uint32_t)w_buff);
2、数据验证方法
for(i=0; i<transfer_size; i++) {if(w_buff_global[i] != r_buff_global[i]) {err_count++;// 记录首个错误位置}
}
测试数据生成:基于种子随机数(保证可重复性)
srand(i);
w_buff[i] = rand() % 0xFF;
3、传输状态监控
CSL_SRIO_GetLSUCompletionCode(hSrio, LSU_Number, transactionID, &uiCompletionCode, &context);
DSP端性能测试结果
典型输出示例如下:
=== loop times: 0 | err_count: 0 |
trans_size: 4096 Byte | NWRITE write times: 1200 ns(3.28 Gbps) |
NREAD read times: 1500 ns(2.73 Gbps)SRIO test 8 cycles, errcnt: 0, total size 32 KB,
write type: NWRITE, avg write rate: 3.20 Gbps,
read type: NREAD, avg read rate: 2.70 Gbps
性能分析:
NWRITE优势:无确认开销,实测带宽达理论值(5Gbps)的 64%
NREAD瓶颈:需等待远程响应,带宽利用率降至 54%
核心价值总结
此代码实现的价值在于:
1、验证SRIO物理层:通过SERDES配置确保5Gbps稳定链路
2、量化传输性能:精确测量NWRITE/SWRITE/NREAD的实时带宽
3、构建可靠基础:错误检测机制满足军工/航天级数据传输要求
4、提供优化基准:为异构系统(FPGA+DSP)提供高速互联参考实现
通过该测试框架,可快速评估SRIO在特定硬件平台上的极限性能,为实时信号处理、无线通信基带等场景提供关键互联技术支持。
4、工程源码1详解:FPGA逻辑工程
开发板FPGA型号:Xilinx–XC7K325T-2FFG676I;
FPGA开发环境:Vivado2019.1;
输入输出接口:SRIO高速接口;
实现功能:FPGA为SRIO从设备(Target);
工程作用:此工程目的是让读者掌握FPGA实现SRIO高速接口与DSP交互的设计能力,以便能够移植和设计自己的项目;
工程Block Design和工程代码架构请参考第3章节的《工程源码架构》小节内容;
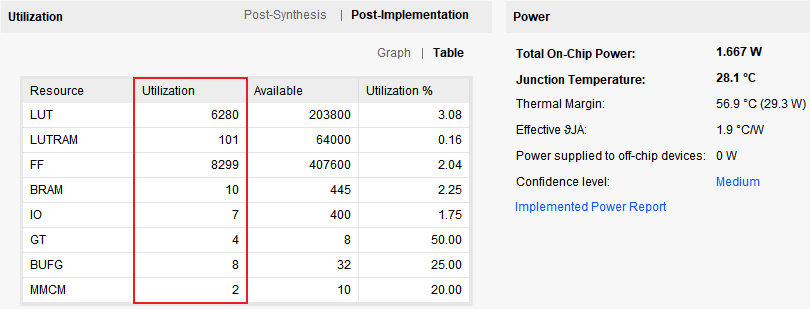
工程的资源消耗和功耗如下:
5、工程源码2详解:DSP裸机工程
开发板DSP型号:TI–TMS320C6678;
FPGA开发环境:CCS5.5;
输入输出接口:SRIO高速接口;
实现功能:DSP为SRIO主设备(Initiator);
DSP工程操作系统:裸机,无操作系统;
工程作用:此工程目的是让读者掌握FPGA实现SRIO高速接口与DSP交互的设计能力,以便能够移植和设计自己的项目;
工程Block Design和工程代码架构请参考第3章节的《工程源码架构》小节内容;
DSP裸机工程源码架构如下:
6、工程源码3详解:DSP RTOS系统工程
开发板DSP型号:TI–TMS320C6678;
FPGA开发环境:CCS5.5;
输入输出接口:SRIO高速接口;
实现功能:DSP为SRIO主设备(Initiator);
DSP工程操作系统:RTOS操作系统;
工程作用:此工程目的是让读者掌握FPGA实现SRIO高速接口与DSP交互的设计能力,以便能够移植和设计自己的项目;
工程Block Design和工程代码架构请参考第3章节的《工程源码架构》小节内容;
DSP裸机工程源码架构如下:
7、工程移植说明
vivado版本不一致处理
1:如果你的vivado版本与本工程vivado版本一致,则直接打开工程;
2:如果你的vivado版本低于本工程vivado版本,则需要打开工程后,点击文件–>另存为;但此方法并不保险,最保险的方法是将你的vivado版本升级到本工程vivado的版本或者更高版本;

3:如果你的vivado版本高于本工程vivado版本,解决如下:

打开工程后会发现IP都被锁住了,如下:

此时需要升级IP,操作如下:


FPGA型号不一致处理
如果你的FPGA型号与我的不一致,则需要更改FPGA型号,操作如下:



更改FPGA型号后还需要升级IP,升级IP的方法前面已经讲述了;
其他注意事项
1:由于每个板子的DDR不一定完全一样,所以MIG IP需要根据你自己的原理图进行配置,甚至可以直接删掉我这里原工程的MIG并重新添加IP,重新配置;
2:根据你自己的原理图修改引脚约束,在xdc文件中修改即可;
3:纯FPGA移植到Zynq需要在工程中添加zynq软核;
8、上板调试验证
准备工作
需要准备的器材如下:
FPGA+DSP异构开发板;
测试用PC电脑;
串口线;
程序下载bit
步骤如下:(顺序一定要对)
1、先下载FPGA程序
2、再下载DSP程序
DSP裸机工程测试
DSP裸机工程测试结果如下:
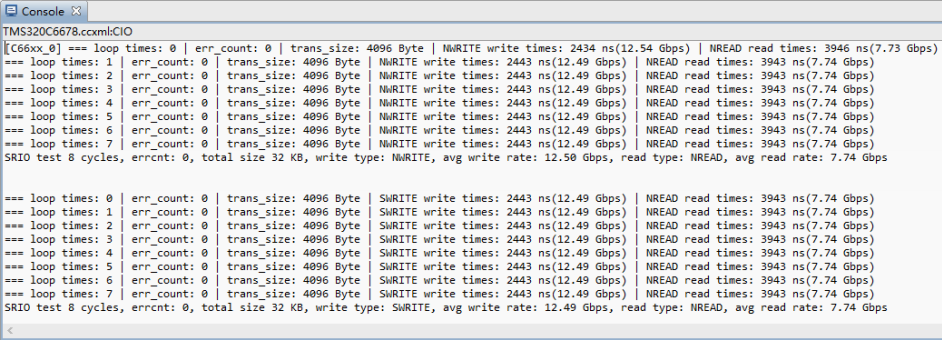
NWRITE + NREAD 模式:NWRITE=12.50Gbps NREAD=7.74Gbps
SWRITE + NREAD 模式:SWRITE=12.49Gbps NREAD=7.74G
DSP RTOS系统工程测试
DSP RTOS系统工程测试结果如下:
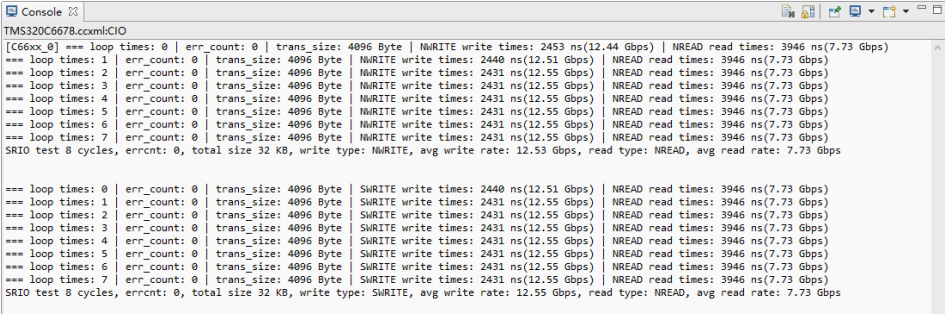
NWRITE + NREAD 模式:NWRITE=12.53Gbps NREAD=7.73Gbps
SWRITE + NREAD 模式:SWRITE=12.55Gbps NREAD=7.73Gbps
打印信息解析
loop time: N :当前处于第 N 次循环读写;
err_count : 读写校验误码率;
trans_size : 读写大小;
NWRITE、SWRITE、”NREAD : 表示使用 NWRITE、SWRITE 等方式传输;
write_time、read_times : 读写耗时,并根据 trans_size 计算读写速率;
SRIO test 8 cycles, errcnt: 0, total size 32 KB,
write type: NWRITE, avg write rate: xx.xx Gbps,
read type: NREAD, avg read rate: xx.xx Gbps
表示共进行了 8 次循环读写,总读写大小为32KByte,码率为 0,并打印在 NWRITE + NREAD模式 8 次循环的平均速率;
9、工程代码获取
工程代码如下:
