Day11(回溯法)——LeetCode79.单词搜索
1 前言
今天主要刷了一道热题榜中回溯法的题,现在的计划是先刷热题榜专题吧,感觉还是这样见效比较快。因此本文主要介绍LeetCode79。
2 LeetCode79.单词搜索(LeetCode79)
OK题目描述及相关示例如下:

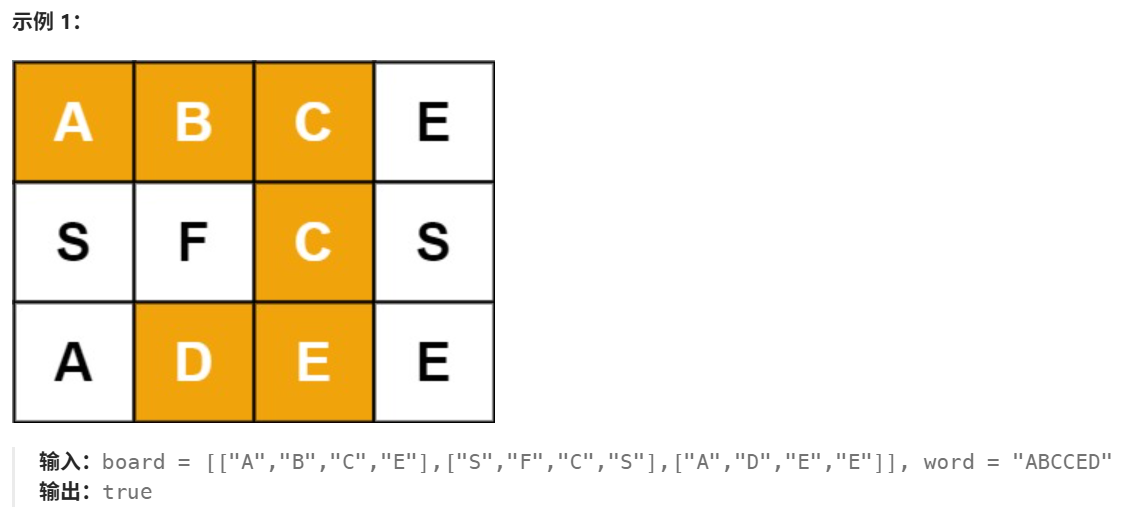
2.1 题目分析解决及优化
感觉回溯的方法并不难,难的是编写代码的过程,不过主要是因为自己代码敲的太少,回溯法还是挺八股文的。
主要思路是枚举每一个位置(i,j),以(i,j)为起点进行搜索,进行递归匹配word[k]。
递归的思路为,当前位置匹配时,则寻找下一个位置进行匹配下一个字母,下一个位置即为当前位置的四周(如果存在):
- 若
board[i][j]==word[k],则递归匹配board[i][j+1],board[i][j-1],board[i-1][j],board[i+1][j](如果存在)与word[k+1],若四周都没匹配成功返回false。
递归的终止条件为:
- 若
word[k]!=board[i][j],则匹配失败,返回false - 若
k+1==len(word),说明匹配到了最后一个字母,且匹配成功,返回true
注意不能重复使用board的同一个字母,因此可以在board[i][j]匹配成功的时候将board[i][j]设置为0,然后进行递归寻找下一个字母,当找不到下一个字母时,记得要恢复board[i][j]。
代码实现如下:
#include<string>
#include<vector>
#include<unordered_map>
#include<algorithm>
class Solution {
public://i,j为board当前匹配位置,k为string匹配位置bool dfs(vector<vector<char>>& board,int i,int j,int k,string word){int m=board.size();int n=board[0].size();//递归终止条件//不相等则匹配失败if(board[i][j]!=word[k]) return false;//若最后一个字母也匹配成功,则整个string匹配成功if(word.length()==k+1) return true;//如果当前位置匹配成功,则遍历其上下左右位置看是否能匹配下一个字母//为了避免重复,将匹配成功的位置设置为0board[i][j]=0;const int dx[4]={-1,0,1,0};const int dy[4]={0,1,0,-1};for(int d=0;d<4;d++){int next_i=i+dx[d];int next_j=j+dy[d];//如果四周存在,且匹配成功,返回trueif(next_i>=0&&next_i<m&&next_j>=0&&next_j<n&&dfs(board,next_i,next_j,k+1,word)){return true;}}//如果四周都不匹配,回溯board[i][j]=word[k];return false;}bool exist(vector<vector<char>>& board, string word) {int m=board.size();int n=board[0].size();//优化1unordered_map<char,int> mp;for(int i=0;i<m;i++){for(int j=0;j<n;j++){mp[board[i][j]]++;}}unordered_map<char,int> word_mp;int word_len=word.length();for(int i=0;i<word_len;i++){word_mp[word[i]]++;if(word_mp[word[i]]>mp[word[i]]){return false;}}//优化二if(mp[word[word_len-1]]<mp[word[0]]){reverse(word.begin(),word.end());}for(int i=0;i<m;i++){for(int j=0;j<n;j++){if(dfs(board,i,j,0,word)) return true;}}return false;}
};
这里学习了灵茶山艾府的两个优化思路,运行时间直接超过了100%!,他b站同名有专题算法讲解也很不错,推荐大家去学习。
优化一:统计word和board各个字母出现的次数,若word中某个字母出现的次数要比board中该字母出现的次数多,则一定不会匹配成功,直接返回false。
优化二:若word的最后一个字母出现的次数更少,则将从尾进行搜索,因为这样更容易在一开始满足board[i][j]=word[k]的(i,j)较少,减少了递归次数。
2.2 复杂度分析
主要是递归的次数,因为每个位置只能使用一次,因此某个递归的分支最多会进入三个分支,分治深度为k,且一共要调用mn次,因此时间复杂度为 O ( m n 3 k ) O(mn3^k) O(mn3k),但实际过程中很多分支会早早结束,因此时间复杂度远小于该值。
空间复杂度为 O ( 52 + k ) O(52+k) O(52+k)。两个无需集合,以及递归需要 O ( k ) O(k) O(k)的栈空间。