Datawhale AI夏令营--Task2:理解项目目标、从业务理解到技术实现!
实验基础了解
相关知识点清单:
| 学习模块 | 核心知识点 | 一句话介绍 |
| 大语言模型基础 | 大模型 API 调用方法 | 学习如何通过 API 使用大语言模型,发送请求并获取结果。 |
| Prompt 工程 | 掌握如何编写有效的提示词,引导模型输出期望的结果。 | |
| 参数高效微调 | LoRA 和合并精调的区别 | 了解 LoRA(低秩适配)与合并精调在模型微调中的不同原理和使用场景。 |
| 全量微调 | 对整个模型的所有参数进行训练,以适应特定任务或数据集。 | |
| 数据集构建 | pandas 的基本使用 | 学习使用 pandas 进行数据读写、整理和基础操作。 |
| pandas 的数据筛选 | 掌握 pandas 中按条件筛选和提取数据的方法,如 loc、iloc 和布尔索引等。 |
赛事相关内容:
1、本次赛事聚焦 铁路运输场景 ,基于真实列车时刻表数据,要求参赛者 构建能够理解表格语义、处理时间计算、跨字段推理的大模型 问答系统 ,提升信息查询自动化水平。
2、参赛者需基于讯飞星辰MaaS平台构建一个人工智能模型。该模型能基于给定表格中的结构化数据,结合表格内容提取信息并回答指定的问题。
赛事任务分为两个阶段:
1、让模型学习如何解析和表示表格数据。【生成可用于微调的QA对】
2、回答与表格数据对应的自然语言问题。【微调,让大模型掌握这个表格的知识并进行回答】
一、实验目标
构建一个能理解列车信息表(结构化数据)的大模型问答系统,通过生成高质量微调数据集(QA 对)并微调模型,使模型能准确回答与列车时刻表相关的自然语言问题(如车次查询、检票口位置、停留时间计算等)。
二、实验准备
2.1 软硬件环境
- 硬件:计算机(CPU≥4 核,内存≥8GB,需联网)
- 软件:Windows/macOS/Linux 系统,Python 3.8+,Jupyter Notebook
2.1 环境配置步骤
# 安装Python(略,需提前安装3.8+版本)(如果不会就去问AI)
pip install pandas requests tqdm jupyter notebook#启动 Jupyter Notebook
jupyter notebook如果路径有问题就修改系统环境或者尝试使用文件的完整路径
在浏览器中打开 Notebook 界面,创建新的baseline.ipynb文件。
访问硅基流动平台,Datawhale AI夏令营准备免费的大模型api资源,申请地址:硅基流动
注册讯飞星辰 MaaS 平台账号,熟悉平台微调流程(需提前完成实名认证)。
三、数据准备与预处理
3.1文件夹结构创建与数据创建
文件夹结构创建
jupyter项目根目录/(一般在c盘的用户下)
├─ data/ # 存放原始数据
└─ train_data/ # 存放生成的微调数据集
原始数据放置
将
info_table(训练+验证集).xlsx文件复制到data/datawhale/文件夹中,并重命名为info_table.xlsx(简化后续路径调用)。
3.2 数据读取与初步处理
在baseline.ipynb中执行以下代码
# 导入库
import pandas as pd
import json
import re
import requests
from tqdm import tqdm# 读取原始数据
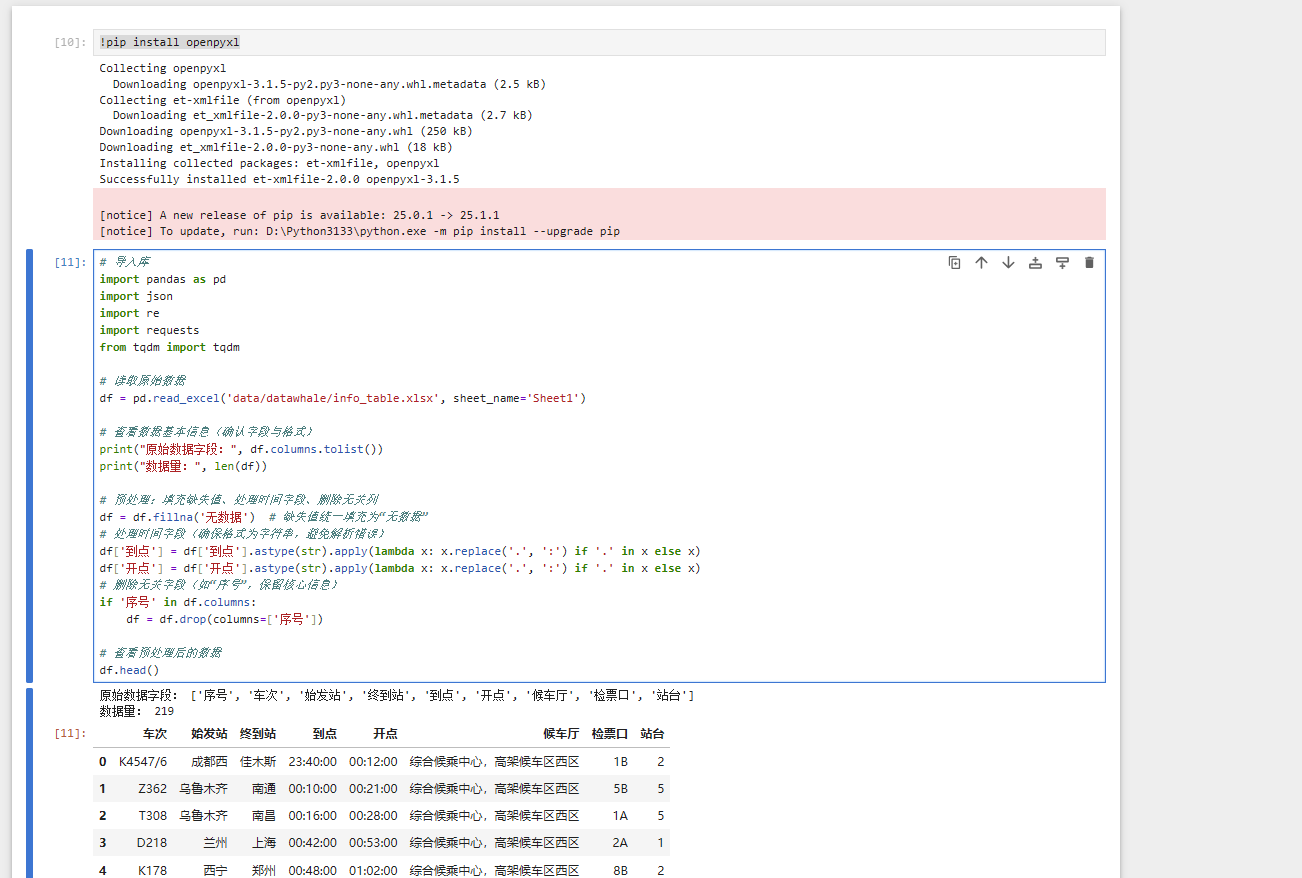
df = pd.read_excel('data/datawhale/info_table.xlsx', sheet_name='Sheet1')# 查看数据基本信息(确认字段与格式)
print("原始数据字段:", df.columns.tolist())
print("数据量:", len(df))# 预处理:填充缺失值、处理时间字段、删除无关列
df = df.fillna('无数据') # 缺失值统一填充为“无数据”
# 处理时间字段(确保格式为字符串,避免解析错误)
df['到点'] = df['到点'].astype(str).apply(lambda x: x.replace('.', ':') if '.' in x else x)
df['开点'] = df['开点'].astype(str).apply(lambda x: x.replace('.', ':') if '.' in x else x)
# 删除无关字段(如“序号”,保留核心信息)
if '序号' in df.columns:df = df.drop(columns=['序号'])# 查看预处理后的数据
df.head()如果出现没有安装openpyxl :则添加!pip install openpyxl命令
四、问题生成(编程式构造)
4.1 设计问题模板
基于列车信息表的字段,设计以下 7 类问题模板:
| 问题类型 | 模板示例 |
|---|---|
| 单字段查询 | "{车次} 的始发站是哪里?";"{车次} 在哪个检票口检票?" |
| 多字段组合查询 | "{车次} 的始发站、终到站和开点分别是什么?" |
| 时间推理(停留时长) | "{车次} 在本站的停留时间是多久?"(基于 “到点” 和 “开点” 计算) |
| 跨字段关联 | "从 {始发站} 到 {终到站} 的 {车次},应该在哪个候车厅等待?" |
| 条件筛选 | "开点在 {时间} 之后的列车有哪些?"(需结合多行数据,此处先基于单行生成) |
| 模糊查询 | "有没有从 {始发站} 出发的列车?"(基于当前车次的始发站生成) |
| 综合信息查询 | "{车次} 的详细信息(包括始发站、终到站、检票口、开点)是什么?" |
4.2 编程实现问题生成函数
在baseline.ipynb中定义create_question_list函数
def create_question_list(row):"""基于单行列车数据生成问题列表row: 单行数据(字典格式,键为字段名,值为字段值)return: 问题列表(list of str)"""questions = []车次 = row['车次']始发站 = row['始发站']终到站 = row['终到站']到点 = row['到点']开点 = row['开点']候车厅 = row['候车厅']检票口 = row['检票口']站台 = row['站台']# 1. 单字段查询questions.append(f"{车次}的始发站是哪里?")questions.append(f"{车次}的终到站是哪里?")questions.append(f"{车次}的开点是什么时候?")questions.append(f"{车次}在哪个检票口检票?")questions.append(f"{车次}的站台是多少?")# 2. 多字段组合查询questions.append(f"{车次}的始发站、终到站和开点分别是什么?")questions.append(f"{车次}的候车厅和检票口信息是什么?")# 3. 时间推理(停留时长)if 到点 != '无数据' and 开点 != '无数据' and 到点 != 开点:questions.append(f"{车次}在本站的停留时间是多久?")# 4. 跨字段关联questions.append(f"从{始发站}到{终到站}的{车次},应该在哪个候车厅等待?")# 5. 模糊查询questions.append(f"有没有从{始发站}出发的列车?")questions.append(f"有没有到{终到站}的列车?")# 6. 综合信息查询questions.append(f"{车次}的详细信息(包括始发站、终到站、检票口、开点)是什么?")return questions# 测试单行数据的问题生成
sample_row = df.iloc[0].to_dict() # 取第一行数据作为示例
sample_questions = create_question_list(sample_row)
print("示例问题列表:")
for q in sample_questions:print(f"- {q}")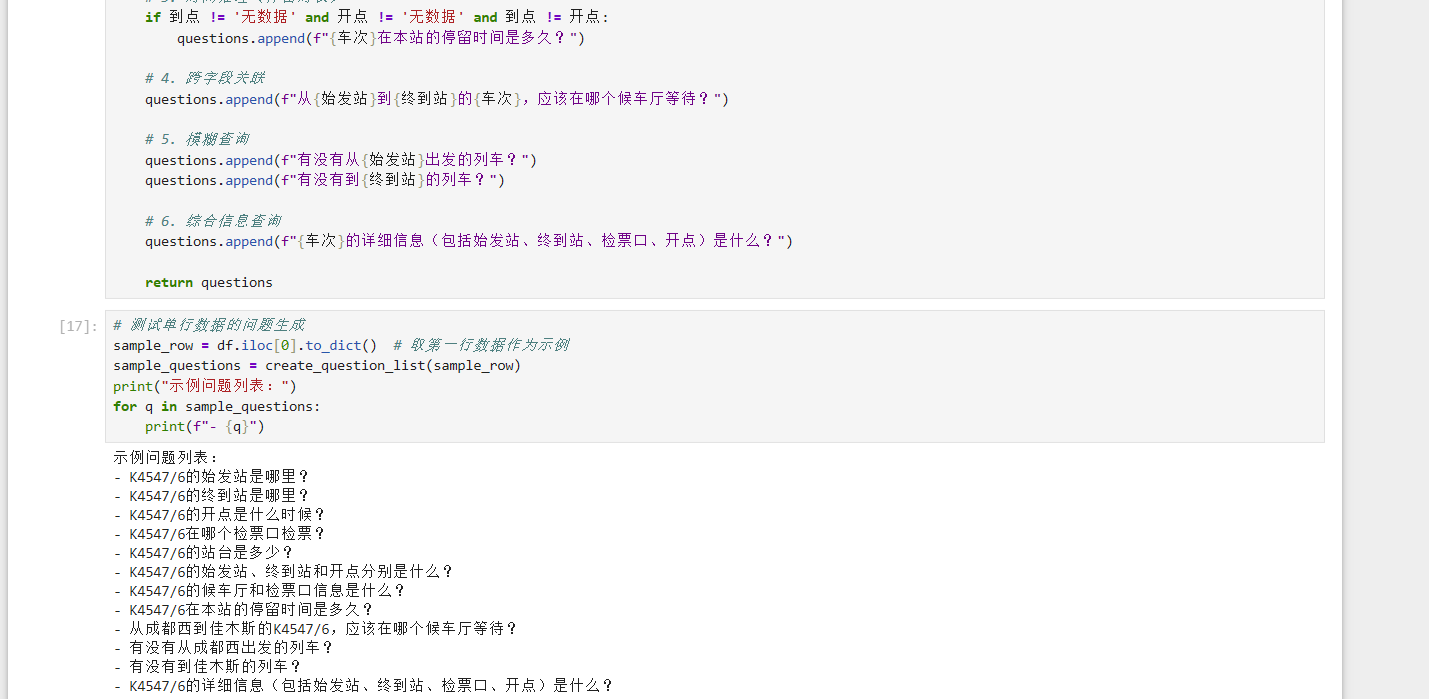
五、教师模型调用与答案生成
在硅基流动创建一个API密钥,记得将密钥复制记录,不然后面可能复制不成功
5.1 使用代码
#实现call_llm函数,用于向教师模型发送请求并获取答案:def call_llm(prompt, api_token):"""调用硅基流动的Qwen3-8B模型API生成答案prompt: 输入的提示词api_token: 硅基流动的API Tokenreturn: 模型生成的文本"""url = "https://api.siliconflow.cn/v1/chat/completions" # 硅基流动API端点headers = {"Content-Type": "application/json","Authorization": f"Bearer {api_token}"}data = {"model": "Qwen/Qwen3-8B", # 教师模型选择"messages": [{"role": "user", "content": prompt}],"temperature": 0.3, # 低温度确保答案稳定性"max_tokens": 1024 # 限制生成长度}response = requests.post(url, headers=headers, json=data)response_json = response.json()return response_json["choices"][0]["message"]["content"]设计 Prompt 模板,明确要求模型基于表格数据回答问题,并输出结构化格式:
def build_prompt(row, questions):"""构造Prompt,包含列车信息和问题列表row: 单行列车数据(字典)questions: 问题列表(list)return: 完整的Prompt字符串"""# 将列车数据转换为自然语言描述row_text = f"列车信息如下:车次={row['车次']},始发站={row['始发站']},终到站={row['终到站']},到点={row['到点']},开点={row['开点']},候车厅={row['候车厅']},检票口={row['检票口']},站台={row['站台']}。"# 问题列表文本questions_text = "请回答以下问题:\n"for i, q in enumerate(questions, 1):questions_text += f"{i}. {q}\n"# 输出格式要求(确保答案可解析)output_format = """
请按照以下JSON格式返回答案,键为问题,值为答案:
{"问题1": "答案1","问题2": "答案2",...
}
注意:答案必须基于提供的列车信息,不得编造;若问题涉及时间计算(如停留时间),需写出计算过程(如“到点10:00,开点10:10,停留10分钟”)。
"""return row_text + "\n" + questions_text + output_format#遍历所有行数据,生成问题并调用教师模型获取答案,存储为列表:# 配置API Token(替换为你的实际Token)
API_TOKEN = "your_siliconflow_token_here"# 存储最终的问答对(用于生成微调数据集)
qa_pairs = []# 遍历每一行数据生成问答对(此处为示例,可先测试前5行,再全量运行)
for idx, row in tqdm(df.iterrows(), total=len(df), desc="生成问答对"):row_dict = row.to_dict()# 生成问题列表questions = create_question_list(row_dict)# 构造Promptprompt = build_prompt(row_dict, questions)# 调用教师模型生成答案try:response = call_llm(prompt, API_TOKEN)# 从响应中提取JSON格式的答案(使用正则匹配)json_match = re.search(r"\{.*\}", response, re.DOTALL)if json_match:answer_json = json.loads(json_match.group())# 将问答对转换为微调格式(instruction:问题,output:答案)for q, a in answer_json.items():qa_pairs.append({"instruction": q, "output": a})except Exception as e:print(f"处理第{idx}行时出错:{e}")continue# 查看生成的问答对示例
print("生成的问答对示例:")
for pair in qa_pairs[:3]:print(f"问题:{pair['instruction']}")print(f"答案:{pair['output']}\n")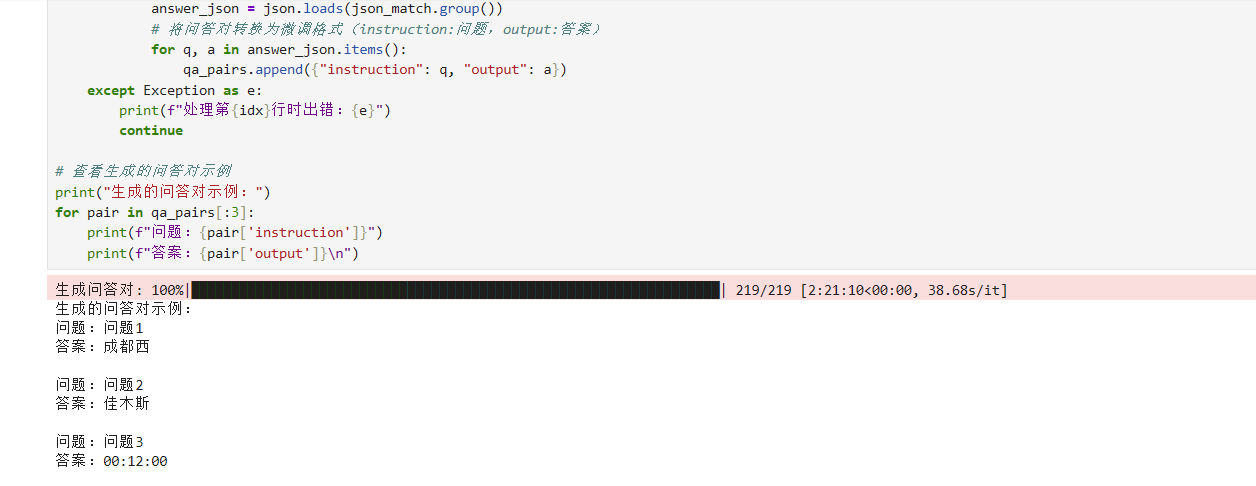
5.2 微调数据集格式转换
##将生成的问答对转换为讯飞星辰 MaaS 平台要求的 SFT 格式(instruction-output结构),并保存为 JSON 文件:# 保存为JSON文件(编码为utf-8,避免中文乱码)
with open('train_data/single_row.json', 'w', encoding='utf-8') as f:json.dump(qa_pairs, f, ensure_ascii=False, indent=2)print(f"微调数据集生成完成,共{len(qa_pairs)}条数据,保存路径:train_data/single_row.json")六、模型微调(讯飞星辰 MaaS 平台)
使用生成的single_row.json数据集在讯飞星辰 MaaS 平台进行 LoRA 微调,使模型掌握列车信息表的知识。