初探HashMap中的HashCode方法
灵感来源:
听课的时候,一个老师说,这个hash map里元素的哈希值是由键值计算的。
首先在HashMap里计算这个哈希值是用键值来计算的。那Hashcode,他不论重不重写,他不都是用这个键值来计算的吗?
解释:
虽然,无论重不重写这个hash code的方法,它都是用键值来计算的,但是利用的方式不一样(利用键值做的运算不一样)。
如果不重写的话,它是调用object类里面的Hash code方法。在这里面是利用键值的地址值来计算的,而如果重写的话,一般是用键值里面存储的值来计算的。所以两者还是不一样的。
默认的 hashCode() 是根据对象的内存地址(或某种与内存地址相关的算法)生成的。也就是说,针对HsahMap而言,这里的对象的内存地址就是键值的内存地址。
所以说,如果不重写的话,即使键值里面的内容一样。但是两个键值的内存地址是一定不一样的。该重写的还是要重写
结论:
所以严谨的表达应该是,如果不重写的话,HashMap里元素的哈希值是由键值的地址值计算得来的,而如果重写的话,HashMap里元素的哈希值是由键值里面的内容得来的。不能笼统地概括为由键值得来,不然容易引起误解。
灵感再现:
刚写完上面这段代码,我又出现了一个疑问,equals判断的是键值的值,hash code判断的也是键值的值,如果两个键值的哈希值都一样了,那它这两个元素不需要equals方法来判断相不相等。他俩一定相等啊
解释:
哈希值的确是由键值的值来算出来的,但是它是根据一个公式,并且这个公式涉及到多个键值的值,不同的值的组合可能会算出来相同的哈希值
而equals是真正比较键值的值的方法。其实,HashCode并没有真正比较键值的值,它只是利用键值的值来计算出了一个数,并且键值中不同值的组合,可能算出来相同的数
我一开始还不信邪,所以我就要看看,它这个哈希值到底是怎么算出来的
于是我查了String的HashCode的具体实现
String的HashCode的具体实现
关键公式
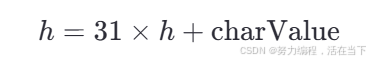
h:表示当前计算出的哈希值(hash)。31:是一个质数系数,用来“扰动”哈希值。charValue:当前字符的 Unicode 编码值(例如'a'是 97,'A'是 65)。
整个公式的意思是:
新的哈希值 = 旧的哈希值 × 31 + 当前字符的 Unicode 值
举个例子
我们来计算 "abc" 的哈希值。
'a'的 Unicode 是 97'b'是 98'c'是 99
计算过程如下:
- 初始
h = 0 - 第一个字符
'a':
h=31×0+97=97h=31×0+97=97 - 第二个字符
'b':
h=31×97+98=3007+98=3105h=31×97+98=3007+98=3105 - 第三个字符
'c':
h=31×3105+99=96255+99=96354h=31×3105+99=96255+99=96354
最终哈希值是:96354
那这样看来不同的键值,确实可能算出来相同的哈希值
然后我又好奇string的哈希值是通过ASCLL码表,容易理解,那其他自定义类型的哈希值是怎么算的呢
idea自带的快捷键直接重写hashcode方法,是怎么计算出哈希值的呢?
不同的基础数据类型对应不同的值
不同类型的字段如何处理?
| 字段类型 | 处理方式 |
|---|---|
String / 对象 | 调用 field.hashCode(),null 则为 0 |
int | 直接使用 field 值 |
long | 使用 (int)(field ^ (field >>> 32))(取高低位异或) |
boolean | field ? 1 : 0 |
float | Float.floatToIntBits(field) |
double | 先转 long,再用 Long.hashCode() |
数组 | 使用 Arrays.hashCode(field) |
✅ IDEA 会自动选择合适的哈希计算方式。