redis常用数据类型
1.字符串string(需要注意的是字符串最大长度为512M)
1.1常用命令:
set、get、 del、
append(将给定的value追加到原值的末尾)、
strlen(获得值的长度)、
incr(将 key 中储存的数字值增1,只能对数字值操作,如果为空,新增值为1)、decr、
setnx (只有在 key不存在时设置 key 的值)、
setex <key> <过期时间> <value> (设置键值的同时,设置过期时间,单位秒。)
incrby / decrby <key> <步长>(将 key 中储存的数字值增减。自定义步长。)
mset(同时设置一个或多个 键值对)、mget
2.List(列表)
2.1简介
Redis 列表是简单的字符串列表,按照插入顺序排序。你可以添加一个元素到列表的头部(左边)或者尾部(右边)。
它的底层实际是个双向链表,对两端的操作性能很高,通过索引下标操作中间的节点性能会较差。

2.2常用命令
lpush/rpush (从左边/右边插入一个或多个值)、
lpop/rpop(从左边/右边删除一个或多个值)、
lrange、llen、
lrem(从左边删除n个value(从左到右))
3.Set(无序集合)
3.1简介
Redis set对外提供的功能与list类似是一个列表的功能,特殊之处在于set是可以自动去重的,当你需要存储一个列表数据,又不希望出现重复数据时,set是一个很好的选择,并且set提供了判断某个成员是否在一个set集合内的重要接口,这个也是list所不能提供的。
Redis的Set是string类型的无序集合。它底层其实是一个value为null的hash表,所以添加,删除,查找的复杂度都是O(1)。
Set数据结构是dict字典,字典是用哈希表实现的。
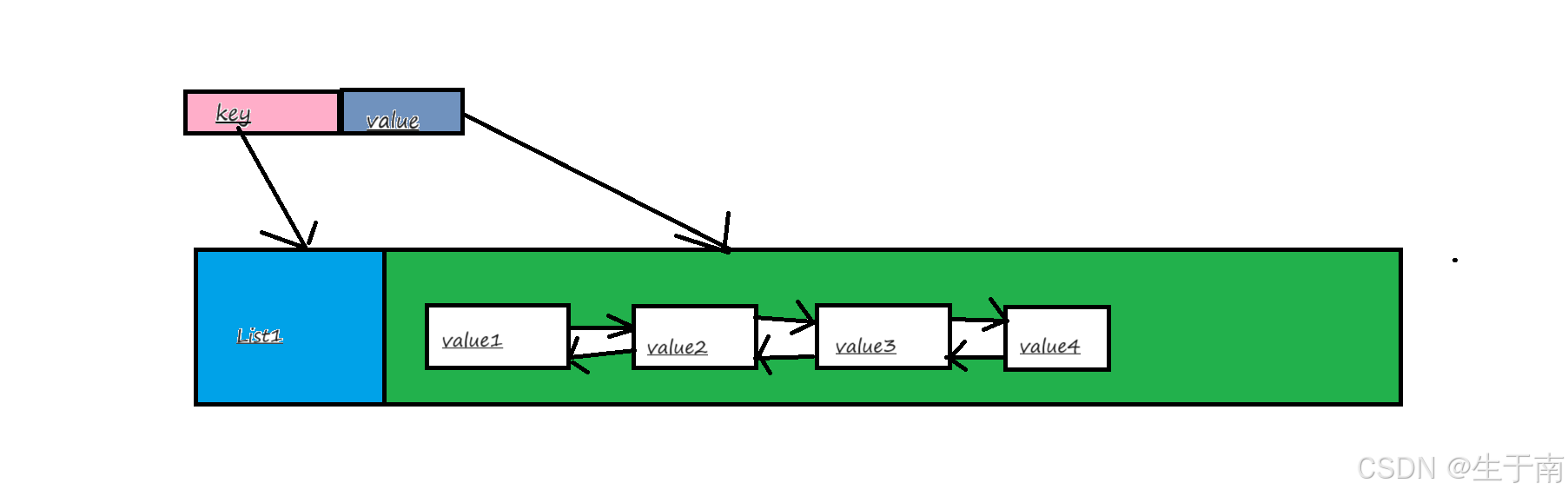
3.2常用命令
sadd <key> <value1> <value2> …(将一个或多个 member 元素加入到集合 key 中,已经存在的 member 元素将被忽略)
smembers <key> (取出该集合的所有值)
sismember <key> <value> (判断集合<key>是否为含有该<value>值,有1,没有0)
srem <key> <value1> <value2> … (删除集合中的某个元素。)
spop <key> (随机从该集合中吐出一个值)
sdiff <key1> <key2> (返回两个集合的差集元素(key1中的,不包含key2中的))
scard <key> (返回该集合的元素个数。)
4.Hash哈希
4.1简介
Redis hash 是一个键值对集合。
Redis hash是一个string类型的field和value的映射表,hash特别适合用于存储对象。
在绝大多数情况下,String 更适合存储对象数据,尤其是当对象结构简单且整体读写是主要操作时。
如果你需要频繁操作对象的部分字段或节省内存,Hash 可能是更好的选择
4.2常用命令
hset <key> <field> <value> (给<key>集合中的 <field> 键赋值<value>)
hget <key1> <field> (从<key1>集合<field>取出 value)
hmset <key1> <field1> <value1> <field2> <value2>… (批量设置hash的值)
hexists <key1> <field> (查看哈希表 key 中,给定域 field 是否存在。)
hkeys <key> (列出该hash集合的所有field)
hvals <key> (列出该hash集合的所有value)
hincrby <key> <field> <increment> (为哈希表 key 中的域 field 的值加上增量 1、 -1)
hsetnx <key> <field> <value> (将哈希表 key 中的域 field 的值设置为 value ,当且仅当域 field 不存在 .)
4.3 数据结构
Hash类型对应的数据结构是两种:ziplist(压缩列表),hashtable(哈希表)。当field-value长度较短且个数较少时,使用z
5、Redis 有序集合Zset
5.1 简介
Redis有序集合zset与普通集合set非常相似,是一个没有重复元素的字符串集合。
不同之处是有序集合的每个成员都关联了一个评分(score),这个评分(score)被用来按照从最低分到最高分的方式排序集合中的成员。集合的成员是唯一的,但是评分可以是重复了 。
因为元素是有序的, 所以你也可以很快的根据评分(score)或者次序(position)来获取一个范围的元素。
访问有序集合的中间元素也是非常快的,因此你能够使用有序集合作为一个没有重复成员的智能列表。如图所示:
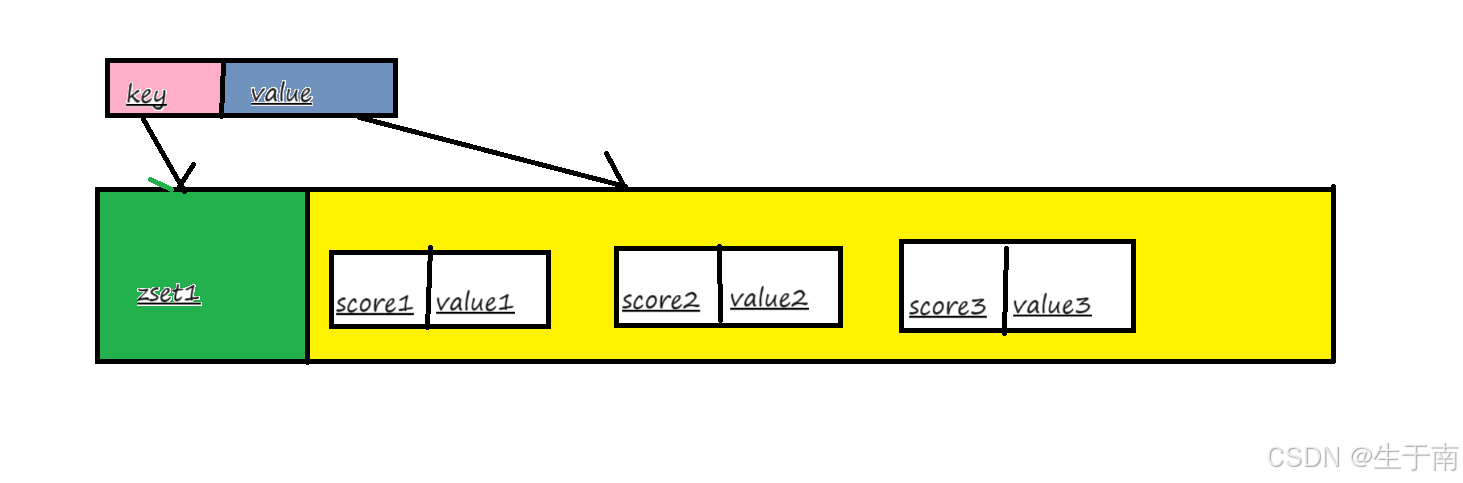
5.2常用命令
zrange <key> <start> <stop> [WITHSCORES] (返回有序集 key 中,下标在<start> <stop>之间的元素,带WITHSCORES,可以让分数一起和值返回到结果集。)
zrangebyscore key min max [withscores] [limit offset count]
返回有序集 key 中,所有 score 值介于 min 和 max 之间(包括等于 min 或 max )的成员。有序集成员按 score 值递增(从小到大)次序排列。
zrevrangebyscore key max min [withscores] [limit offset count]
同上,改为从大到小排列。
zincrby <key> <increment> <value>
为元素的score加上增量 increment
zrem <key> <value>
删除该集合下,指定值的元素
zcount <key> <min> <max>
统计该集合,分数区间内的元素个数
zrank <key> <value>
返回该值在集合中的排名,从0开始。
5.3 数据结构
zset底层使用了两个数据结构
(1)hash,hash的作用就是关联元素value和权重score,保障元素value的唯一性,可以通过元素value找到相应的score值。
(2)跳跃表,跳跃表的目的在于给元素value排序,根据score的范围获取元素列表。