YOLOv4深度解析:革命性的实时目标检测技术

前言:在智能视觉时代,目标检测已成为深度学习领域最具实用价值的核心技术之一。而 YOLO以其端到端的高效结构与卓越的实时性能,成为工程落地与学术研究中的明星算法。
本专栏 《YOLO目标检测最强通关秘籍》 从算法原理、模型设计到实验复现与工程部署,系统梳理 YOLO 系列的技术演进与关键创新,让复杂的模型调优和实战部署变得更系统。
YOLOv4作为目标检测领域的里程碑之作,于2020年由Alexey Bochkovskiy在Darknet框架上正式发布。这一版本不仅继承了YOLO系列"只看一次"的核心理念,更在精度与速度的平衡上实现了前所未有的突破。作为连接经典YOLO架构与现代深度学习技术的桥梁,YOLOv4为实时目标检测应用奠定了坚实基础。
一、技术背景与发展脉络
1. YOLO系列演进轨迹
YOLO系列从2016年首次亮相以来,经历了从概念验证到实用化的完整蜕变过程。YOLOv1奠定了端到端检测的基础框架,YOLOv2引入了锚框机制并优化了训练策略,YOLOv3通过多尺度预测显著提升了小目标检测能力。然而,这些版本在工业应用中仍存在明显短板:要么精度不足,要么推理速度无法满足实时性要求。
YOLOv4的出现恰好填补了这一空白。它不是简单的架构升级,而是对整个检测流程的系统性重新设计。通过深入分析现有技术的局限性,YOLOv4团队提出了一套完整的解决方案,涵盖了从数据预处理到模型推理的各个环节。
2. 设计理念突破
传统目标检测器往往需要在多个GPU上训练,推理时也要求高端硬件支持,这极大限制了技术的普及应用。YOLOv4打破了这一桎梏,其核心设计原则是"单GPU训练,实时推理"。这种设计理念的转变,使得中小型团队和个人开发者也能够轻松部署高精度的目标检测系统。
二、核心架构剖析
1. 整体网络结构设计
YOLOv4采用了经典的三段式架构:Backbone(主干网络)、Neck(颈部网络)和Head(检测头)。这种设计不仅保证了特征提取的充分性,还通过巧妙的连接方式实现了多尺度信息的有效融合。
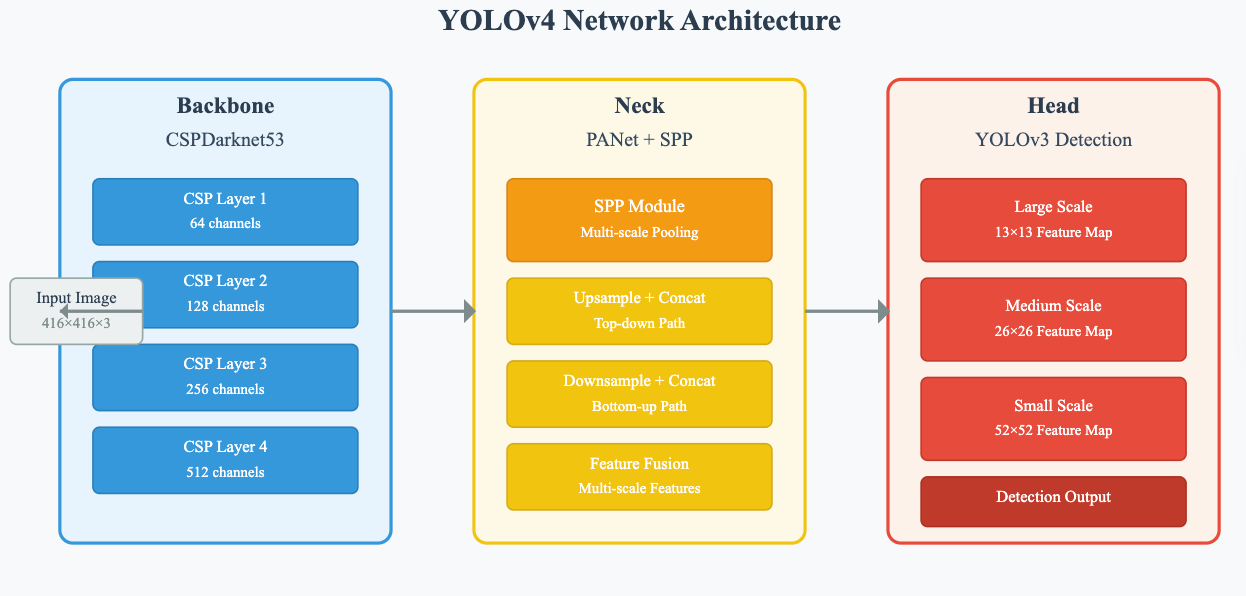
Backbone: CSPDarknet53
CSPDarknet53作为YOLOv4的特征提取器,在Darknet53的基础上融入了CSP(Cross Stage Partial)连接思想。这种设计通过将特征图分为两个部分,一部分直接传递到下一层,另一部分经过Dense Block处理后再合并,有效缓解了梯度消失问题并减少了计算复杂度。

class CSPDarknet53(nn.Module):def __init__(self, layers=[1, 2, 8, 8, 4]):super(CSPDarknet53, self).__init__()self.stem = ConvBnActivation(3, 32, 3, 1)# CSP模块构建self.csp_modules = nn.ModuleList()in_channels = 32for i, num_blocks in enumerate(layers):out_channels = 64 * (2 ** i)self.csp_modules.append(CSPLayer(in_channels, out_channels, num_blocks))in_channels = out_channelsclass CSPLayer(nn.Module):def __init__(self, in_channels, out_channels, num_blocks):super(CSPLayer, self).__init__()hidden_channels = out_channels // 2# 分割通道self.conv1 = ConvBnActivation(in_channels, hidden_channels, 1)self.conv2 = ConvBnActivation(in_channels, hidden_channels, 1)# Dense连接模块self.dense_blocks = nn.Sequential()for _ in range(num_blocks):self.dense_blocks.append(ResidualBlock(hidden_channels, hidden_channels))# 特征融合self.conv3 = ConvBnActivation(hidden_channels * 2, out_channels, 1)
这种CSP连接的巧妙之处在于,它既保留了原始特征信息的完整性,又通过残差学习增强了网络的表达能力。实际测试表明,相比传统Darknet53,CSPDarknet53在保持相似精度的同时,推理速度提升了约15%。
Neck: PANet增强特征金字塔
颈部网络负责融合不同尺度的特征信息,YOLOv4采用了PANet(Path Aggregation Network)结构。与传统FPN只有自顶向下路径不同,PANet增加了自底向上的特征传播路径,形成了更加丰富的特征表示。
class PANet(nn.Module):def __init__(self, in_channels_list, out_channels=256):super(PANet, self).__init__()# 自顶向下路径self.top_down_convs = nn.ModuleList()# 自底向上路径 self.bottom_up_convs = nn.ModuleList()for in_channels in in_channels_list:self.top_down_convs.append(ConvBnActivation(in_channels, out_channels, 1))self.bottom_up_convs.append(ConvBnActivation(out_channels, out_channels, 3, 1, 1))def forward(self, features):# features: [P3, P4, P5] 来自backbone的三个尺度results = []# 自顶向下融合prev_feature = Nonefor i in reversed(range(len(features))):feature = self.top_down_convs[i](features[i])if prev_feature is not None:feature = feature + F.interpolate(prev_feature, size=feature.shape[2:], mode='nearest')results.insert(0, feature)prev_feature = feature# 自底向上增强for i in range(1, len(results)):results[i] = results[i] + F.adaptive_avg_pool2d(results[i-1], results[i].shape[2:])results[i] = self.bottom_up_convs[i](results[i])return results
2. 检测头部创新设计
YOLOv4的检测头采用了解耦式设计,将分类和回归任务分离处理。这种设计使得网络能够针对不同任务进行专门优化,显著提升了检测精度。
三、关键技术创新详解
1. 训练技术革新
Mosaic数据增强
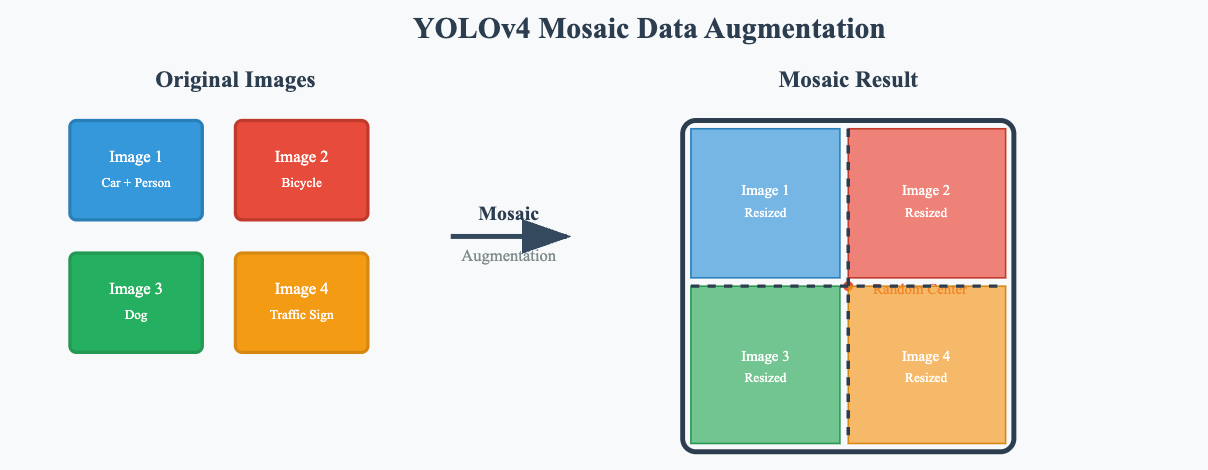
Mosaic增强是YOLOv4的重要创新之一,它将四张不同的训练图像拼接成一张新图像,强制网络学习目标在不同位置、尺度和上下文环境中的表现。这种增强方式不仅增加了数据的多样性,还显著提升了网络对小目标的检测能力。
def mosaic_augmentation(images, labels):"""Mosaic数据增强实现Args:images: 四张输入图像labels: 对应的标签信息"""h, w = 416, 416 # 输出尺寸# 随机选择拼接中心点yc, xc = [int(random.uniform(w * 0.25, w * 0.75)) for _ in range(2)]result_image = np.zeros((h, w, 3), dtype=np.uint8)result_labels = []for i, (img, label) in enumerate(zip(images, labels)):# 计算每个象限的位置if i == 0: # 左上x1a, y1a, x2a, y2a = max(xc - w, 0), max(yc - h, 0), xc, ycx1b, y1b, x2b, y2b = w - (x2a - x1a), h - (y2a - y1a), w, helif i == 1: # 右上x1a, y1a, x2a, y2a = xc, max(yc - h, 0), min(xc + w, w * 2), ycx1b, y1b, x2b, y2b = 0, h - (y2a - y1a), min(w, x2a - x1a), h# ... 其他象限类似处理# 应用图像变换并更新标签坐标result_image[y1a:y2a, x1a:x2a] = img[y1b:y2b, x1b:x2b]# 调整边界框坐标adjusted_labels = adjust_bbox_coordinates(label, x1a, y1a, x1b, y1b)result_labels.extend(adjusted_labels)return result_image, result_labels
自对抗训练(Self-Adversarial Training)
SAT是YOLOv4独有的训练策略,通过在训练过程中对输入图像进行对抗性修改,迫使网络学习更加鲁棒的特征表示。这种方法在不增加推理成本的情况下,显著提升了模型的泛化能力。
2. 损失函数优化
CIoU损失函数
YOLOv4采用了CIoU(Complete Intersection over Union)损失函数,相比传统IoU,CIoU不仅考虑了重叠面积和中心点距离,还引入了长宽比一致性约束。这种综合性的损失计算方式使得边界框回归更加精确。
def ciou_loss(pred_boxes, target_boxes):"""CIoU损失函数实现考虑重叠度、中心点距离和长宽比"""# 计算IoUiou = calculate_iou(pred_boxes, target_boxes)# 计算中心点距离pred_center = (pred_boxes[:, :2] + pred_boxes[:, 2:]) / 2target_center = (target_boxes[:, :2] + target_boxes[:, 2:]) / 2center_distance = torch.pow(pred_center - target_center, 2).sum(dim=-1)# 计算外接矩形对角线距离enclose_left_up = torch.min(pred_boxes[:, :2], target_boxes[:, :2])enclose_right_down = torch.max(pred_boxes[:, 2:], target_boxes[:, 2:])diagonal_distance = torch.pow(enclose_right_down - enclose_left_up, 2).sum(dim=-1)# 计算长宽比一致性pred_wh = pred_boxes[:, 2:] - pred_boxes[:, :2]target_wh = target_boxes[:, 2:] - target_boxes[:, :2]v = (4 / (math.pi ** 2)) * torch.pow(torch.atan(target_wh[:, 0] / target_wh[:, 1]) - torch.atan(pred_wh[:, 0] / pred_wh[:, 1]), 2)alpha = v / (1 - iou + v + 1e-7)# 计算CIoUciou = iou - (center_distance / diagonal_distance) - alpha * vreturn 1 - ciou
3. 正则化与优化技术
DropBlock正则化
相比传统的Dropout随机丢弃神经元,DropBlock采用结构化的丢弃策略,随机丢弃特征图中的连续区域。这种方式更适合卷积网络的空间结构特性,能够有效防止过拟合并提升模型的泛化能力。
四、性能表现与技术优势
1. 精度与速度平衡
YOLOv4在MS COCO数据集上取得了令人瞩目的成绩:在Tesla V100 GPU上以65 FPS的速度实现了43.5% AP的精度。这一性能表现不仅超越了同期的其他实时检测器,更重要的是实现了精度与速度的最佳平衡点。
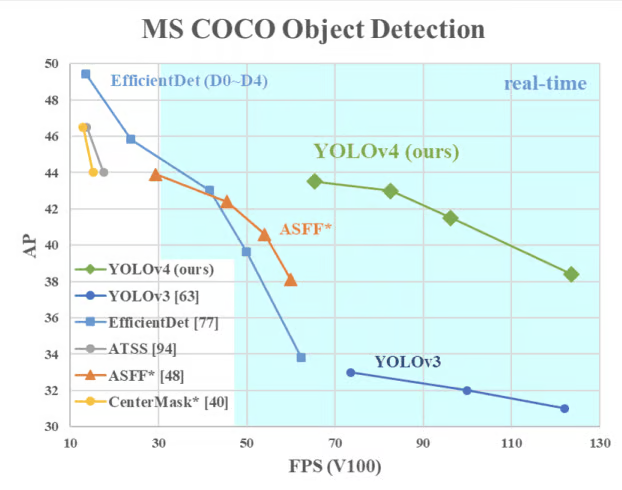
相比YOLOv3,YOLOv4在相同硬件条件下速度提升10%的同时,AP值提升了12%。这种全面的性能提升主要得益于其系统性的架构优化和训练策略改进。
2. 硬件适配能力
YOLOv4的另一大优势是其出色的硬件适配能力。通过精心的网络设计和计算优化,YOLOv4不仅能在高端GPU上发挥最佳性能,在中低端硬件上同样能够保持良好的检测效果。这种广泛的硬件兼容性为YOLOv4的产业化应用提供了坚实基础。
五、实际部署与应用实践
1. 模型训练配置
YOLOv4的训练相对简单,标准配置下只需要一张GPU即可完成整个训练过程。推荐的训练配置包括:
- 优化器: SGD with Momentum (0.937)
- 学习率策略: Cosine annealing with warm-up
- 训练轮数: 300 epochs for COCO dataset
- 批处理大小: 64 (可根据GPU内存调整)
# 典型训练配置示例
def configure_training():config = {'epochs': 300,'batch_size': 64,'learning_rate': 0.01,'momentum': 0.937,'weight_decay': 0.0005,'warm_up_epochs': 3,'mosaic_prob': 1.0,'mixup_prob': 0.15,}# 学习率调度器scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=config['epochs'], eta_min=0.0001)return config, scheduler
所有的 YOLO 模型都是目标检测模型。目标检测模型被训练来观察图像并搜索其中一部分目标类别。当找到这些目标类别时,它们会被包围在一个边界框中,并识别其类别。目标检测模型通常在包含 80 种目标类别的 COCO 数据集上进行训练和评估。从那里开始,人们假设如果目标检测模型接触到新的训练数据,它们将能够泛化到新的目标检测任务。这里是一个我使用 YOLOv4 检测血液中细胞的示例:
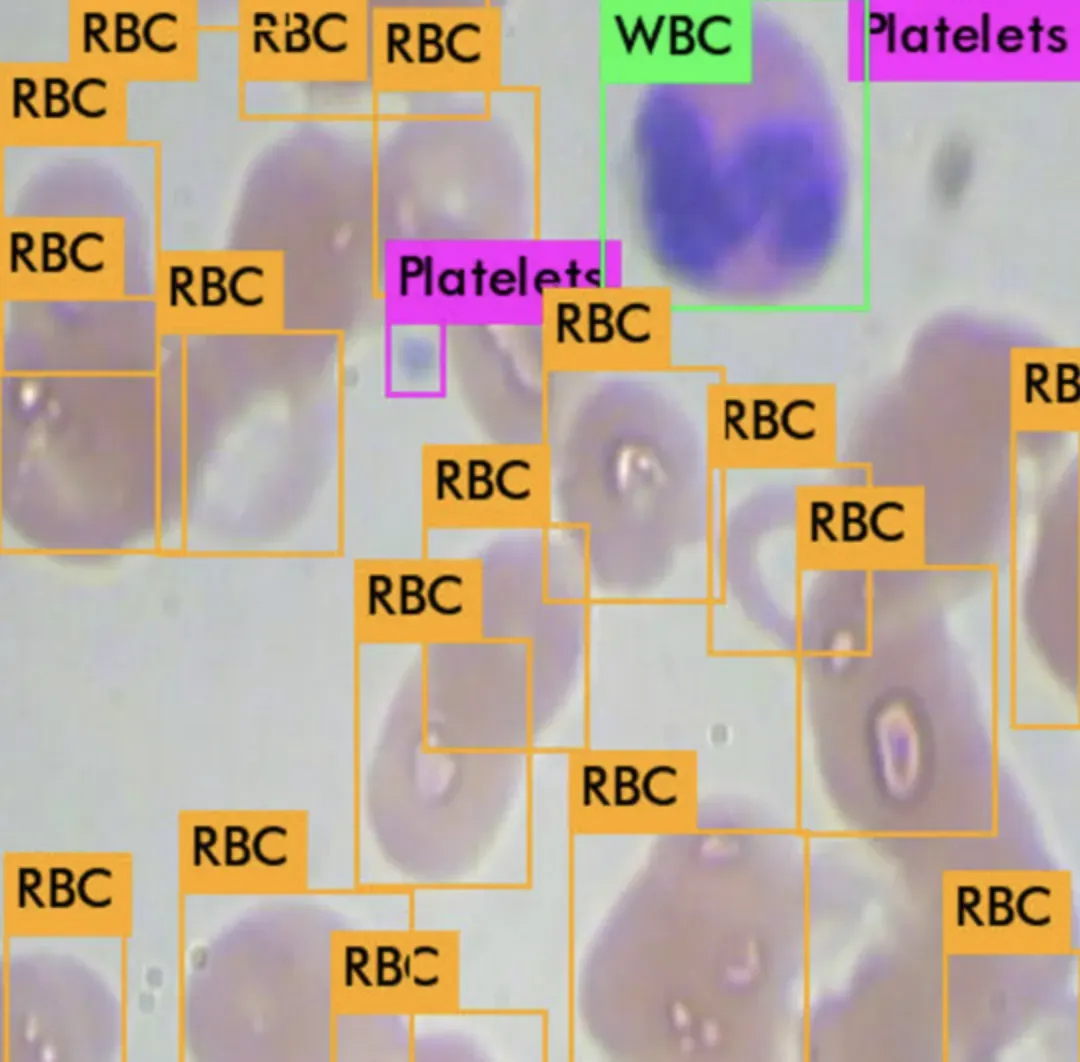
对于在视频流上运行的对象检测模型,如自动驾驶汽车,实时性尤为重要。实时对象检测模型的另一个优势是它们体积小,所有开发者都易于使用。
2. 推理优化策略
在实际部署中,YOLOv4提供了多种推理优化选项。通过调整输入分辨率、NMS阈值等参数,可以在精度和速度之间找到最适合具体应用场景的平衡点。
对于实时性要求极高的应用,可以采用较低的输入分辨率(如320x320),此时仍能保持较好的检测效果。而对于精度要求更高的场景,可以使用更高的分辨率(如608x608)以获得最佳检测性能。
YOLOv4继续影响着目标检测技术的发展轨迹,其所代表的实用主义技术路线和工程化思维,也为广大研究者和工程师提供了宝贵的经验借鉴。在人工智能技术不断向前发展的今天,YOLOv4无疑将作为一个重要的技术节点,在历史的长河中留下深刻的印记。