DPO:大语言模型偏好学习的高效方案
大语言模型(LLMs)通常先通过大规模无监督语料进行预训练,再通过监督微调(SFT)来掌握指令跟随能力。但这远远不够:
-
SFT 往往只模拟了“人类写法”
-
模型仍会输出不安全、重复、冗长、不中立的回答
-
我们需要模型输出“我们想要的答案”
于是,RLHF(Reinforcement Learning with Human Feedback) 成为构建高质量助手(如 ChatGPT)的关键技术。
问题:RLHF(比如 PPO)太复杂了
经典的 RLHF 如 OpenAI 使用的 PPO(Proximal Policy Optimization):
-
需要训练 Reward Model
-
再用 RL 算法(PPO)优化语言模型的行为策略
-
训练代价高,架构复杂,收敛不稳定
于是,DPO 出现了:更简单、更稳定的替代方案。
什么是 DPO(Direct Preference Optimization)?
DPO 是 Anthropic 在 2023 年提出的一种 无需强化学习、直接优化偏好数据的算法,核心思想是:
给模型两个回答(一个好,一个差),直接优化让模型更倾向好回答,而不是差回答。
它不再使用 reward model 来打分,而是直接用语言模型自己的 log-likelihood 来判断哪个回答更“可信”。
原理详解:DPO 如何工作?
数据格式:
每条训练样本是一个三元组:
{"prompt": "你怎么看待996工作制?","chosen": "我认为996工作制对员工健康有害,应当避免。","rejected": "我觉得996挺好的,公司效率高。"
}
损失函数:
对于模型来说,我们计算:
-
r_chosen: 模型对prompt + chosen的 log-likelihood(语言概率) -
r_rejected: 模型对prompt + rejected的 log-likelihood
然后优化如下 loss:
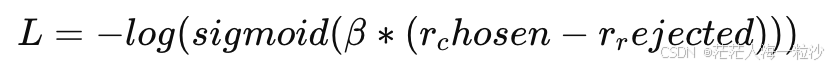
其中 β 是温度系数,控制模型对偏好的“分辨强度”。
直观来说:
-
如果模型更偏向 chosen →
r_chosen > r_rejected→ loss 小 -
如果模型反而偏向 rejected → loss 大 → 被惩罚
为什么选择 DPO?
| 特点 | DPO | PPO |
|---|---|---|
| 是否需要 Reward Model | ❌ 不需要 | ✅ 需要 |
| 算法类型 | Supervised Pairwise Ranking | Reinforcement Learning |
| 实现难度 | ✅ 简单 | ❌ 复杂 |
| 收敛速度 | ✅ 快 | ⚠️ 慢且不稳定 |
| 资源需求 | ✅ 低 | ❌ 高 |
| 可扩展性 | ✅ 好 | ⚠️ 难以并行 |
DPO 完美保留了 RLHF 的核心 —— 让模型更符合人类偏好,同时避开了强化学习的成本和不稳定性。
训练 DPO 的最佳实践
1. 数据构建建议
-
数据格式: prompt + chosen + rejected
-
来源可以是:
-
人工偏好标注(如 HH-RLHF、UltraFeedback)
-
用 reward model 自动筛选(pseudo preference)
-
对比两个模型的输出(如 GPT-4 vs SFT)
-
2. 模型选择
-
任何支持
AutoModelForCausalLM架构的模型都可以:-
LLaMA 2 / LLaMA 3
-
Qwen、Baichuan、Yi 等
-
-
推荐使用
LoRA来降低显存消耗
3. Hugging Face 的 DPOTrainer
你只需几行代码即可开始训练:
from trl import DPOTrainer, DPOConfig
from transformers import AutoModelForCausalLM, AutoTokenizermodel = AutoModelForCausalLM.from_pretrained("meta-llama/Meta-Llama-3-8B-Instruct")
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Meta-Llama-3-8B-Instruct")trainer = DPOTrainer(model=model,ref_model=None,tokenizer=tokenizer,train_dataset=your_dataset,args=DPOConfig(beta=0.1,per_device_train_batch_size=2,num_train_epochs=3,output_dir="./dpo_llama3")
)trainer.train()
DPO 在实际项目中的应用场景
-
🚀 想训练 ChatGPT 类助手但资源受限
-
✅ 已有人类偏好标注或自动偏好数据
-
🔁 快速对比多个版本输出的模型行为
-
🤖 微调开源模型让其更 align with human
⚠️ DPO 的局限
| 局限 | 说明 |
|---|---|
| ❌ 只能用 pairwise 数据 | 不支持 top-k 或打分型数据(reward score) |
| ❌ 无法主动探索 | 不适合用于在线强化学习框架中 |
| ⚠️ 依赖预训练质量 | 如果原始语言模型质量差,效果提升有限 |
train_dpo.py:完整训练脚本
import os
from datasets import load_dataset, Dataset
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
from peft import LoraConfig, get_peft_model
from trl import DPOTrainer, DPOConfig# ----------- 配置模型和路径 -----------
model_name = "C:\\apps\\ml_model\\Llama-3.2-1B-Instruct"
output_dir = ".\\dpo_llama3_lora"# ----------- 加载分词器 -----------
tokenizer = AutoTokenizer.from_pretrained(model_name)
tokenizer.pad_token = tokenizer.eos_token# ----------- 加载模型并应用 LoRA -----------
quant_config = BitsAndBytesConfig(load_in_8bit=True,llm_int8_threshold=6.0,llm_int8_skip_modules=None,llm_int8_enable_fp32_cpu_offload=True
)base_model = AutoModelForCausalLM.from_pretrained(model_name,# quantization_config=quant_config,device_map="auto",# trust_remote_code=True
)lora_config = LoraConfig(r=64,lora_alpha=16,target_modules=["q_proj", "v_proj"], # 根据模型结构定制lora_dropout=0.05,bias="none",task_type="CAUSAL_LM"
)model = get_peft_model(base_model, lora_config)# ----------- 加载偏好数据集 -----------
def load_preference_dataset(jsonl_path):import jsonwith open(jsonl_path, 'r', encoding='utf-8') as f:data = [json.loads(line) for line in f]return Dataset.from_list(data)# dataset = load_preference_dataset(dataset_path)
dataset = load_dataset("C:\\apps\\ml_datasets\\hh-rlhf", split="train", revision="harmless-base")# ----------- DPO Trainer 配置 -----------
training_args = DPOConfig(beta=0.1, # 偏好对比温度max_length=1024,per_device_train_batch_size=2,gradient_accumulation_steps=4,learning_rate=5e-5,lr_scheduler_type="cosine",warmup_ratio=0.1,num_train_epochs=3,logging_steps=10,save_strategy="epoch",output_dir=output_dir,report_to="none",remove_unused_columns=False,fp16=True, # 适用于支持的 GPUpadding_value=tokenizer.pad_token_id, # ← 加上这一行
)trainer = DPOTrainer(model=model,ref_model=None, # 不用引用模型,使用自身输出计算 log-likelihoodargs=training_args,train_dataset=dataset,# tokenizer=tokenizer,
)# ----------- 启动训练 -----------
trainer.train()补充说明
| 模块 | 功能说明 |
|---|---|
DPOTrainer | 主训练器,接受 (prompt, chosen, rejected) 结构 |
beta | 越大越偏好差异(推荐 0.1~1.0) |
ref_model | 可选,默认用当前模型计算两个响应的概率差 |
LoRAConfig | 可根据你的模型结构定制(注意 target_modules) |
BitsAndBytes | 使用 8bit 加载模型,节省显存(可选) |
参考资料
https://arxiv.org/abs/2305.18290
https://huggingface.co/datasets/Anthropic/hh-rlhf