[LLM]Synthetic Visual Genome
1. BaseInfo
| Title | Synthetic Visual Genome |
| Adress | https://openaccess.thecvf.com/content/CVPR2025/html/Park_Synthetic_Visual_Genome_CVPR_2025_paper.html |
| Journal/Time | CVPR 2025 |
| Author | 华盛顿、allen institute fro ai、斯坦福、丰田 |
| Code | https://synthetic-visual-genome.github.io/ |
| Read | 250715 - 250722 |
2. Creative Q&A
视觉关系。
图中的物体之间的关系是很复杂的,以往的大型多模态模型(multimodal language models ,MLMs) 在理解复杂关系方面仍存在问题。
- 构建数据集 : SVG (Synthetic Visual Genome) 大规模合成场景数据集。包含了14.6万张图片,260万个物体和560万个关系。
- ROBIN 模型:理解与推理图像中各个区域及关系。
- SG-EDIT 框架:生成场景图的自蒸馏框架。
3. Concrete
3.1. Dataset:SVG
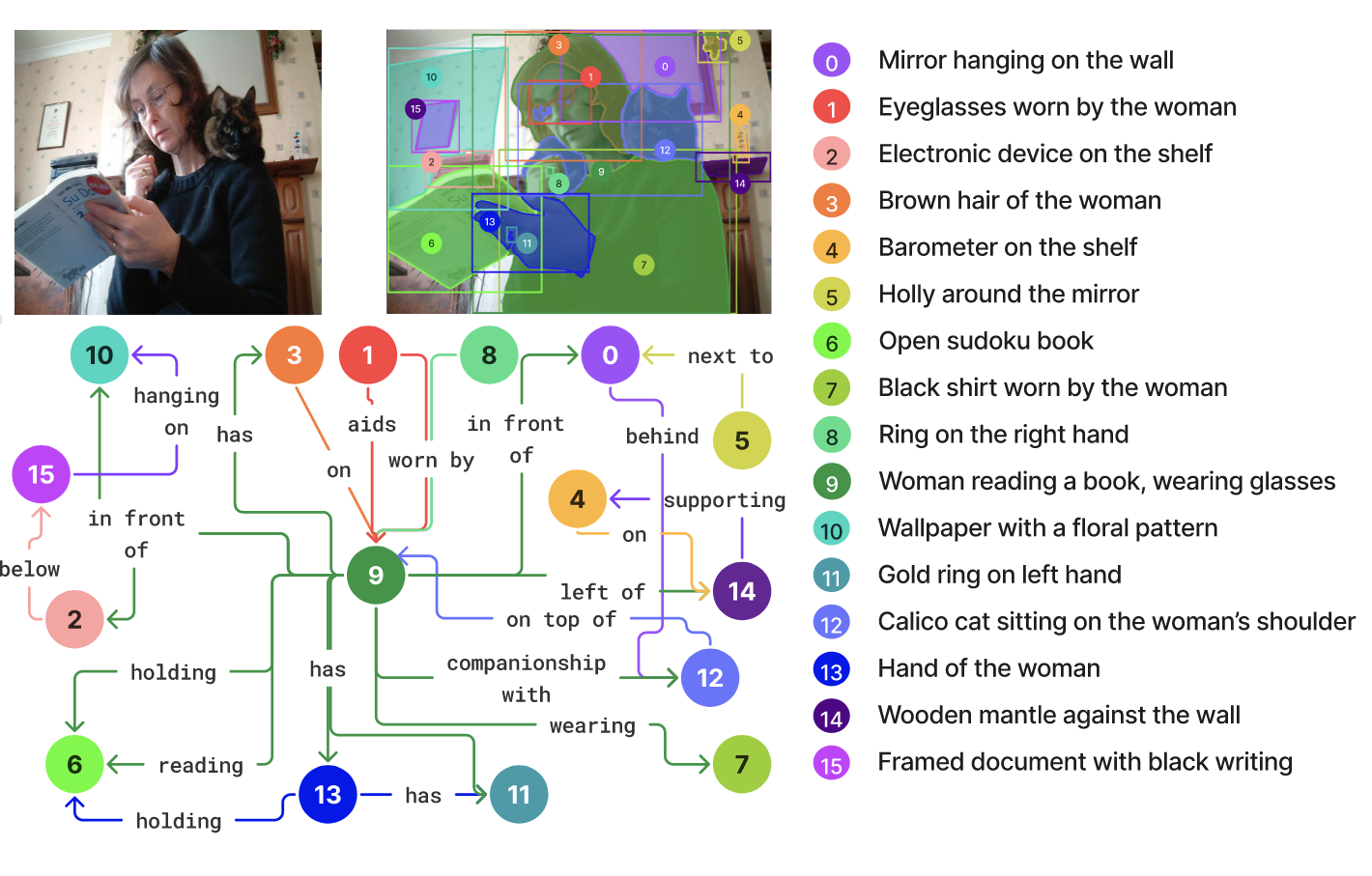
SVG 的图片
3.1.1 数据生产流程
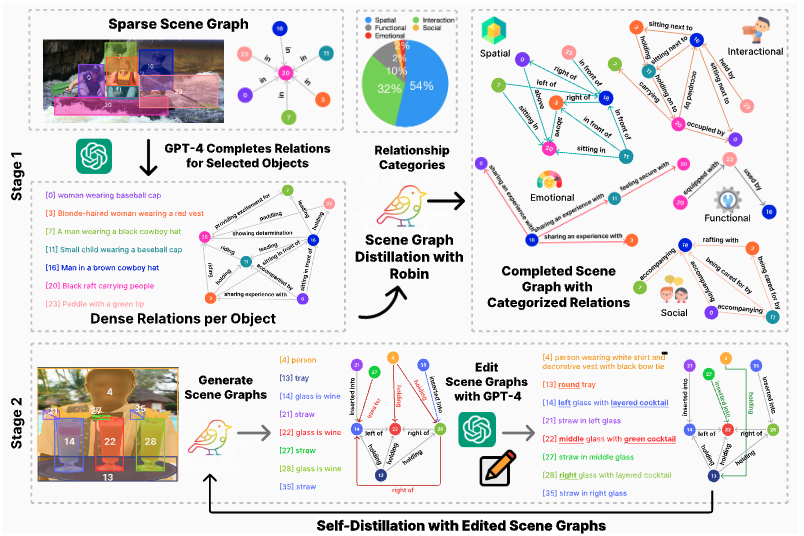
是因为人工标记复杂,所以用大语言模型,又因为从头开始标GPT会产生严重的幻觉,所以是基于之前的人工标注场景图构建的,再通过模型训练扩大样本,最终得到了这个数据集。
主要分为两个阶段:
阶段一:SVG-Relations
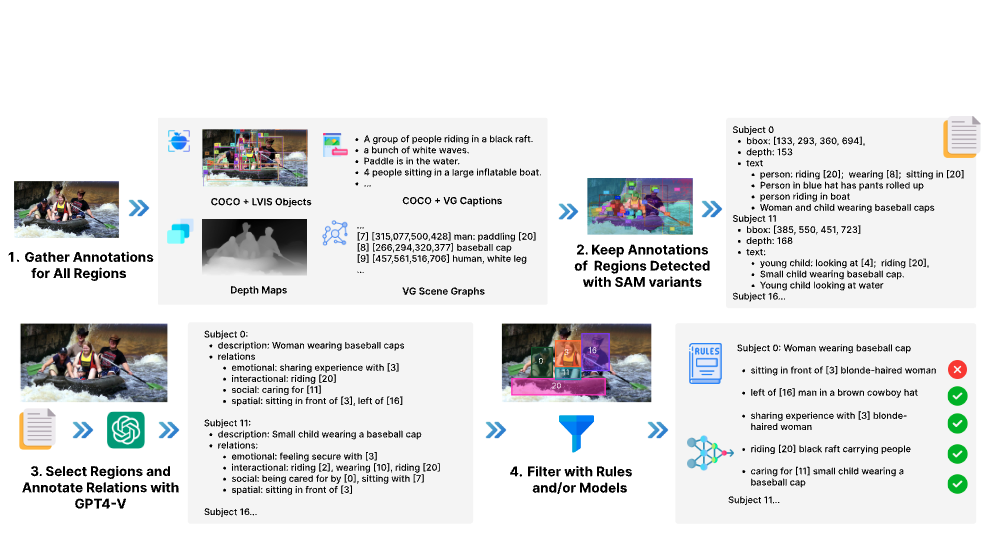
- 选取种子图像:选择了COCO [ 44 ]图像的子集,其中包括:a )来自COCO [ 44 ]和LVIS [ 21 ]的目标检测标签,b )来自RefCOCO [ 90 ]和Visual Genome ( VG ) [ 37 ]的区域描述,c )来自VG和GQA [ 25 ]的场景图,以及d )由Depth - Anything模型生成的深度图[ 86 ]。这就产生了33K张带有全面注释的种子图像。
- 筛选重要物体:为了只保留视觉上显著且有意义的元素,他们使用了 Segment Anything Model (SAM) 和 Semantic-SAM 来生成图像中主要物体和区域的分割掩码 。对于种子数据集中的每个注释区域,我们计算注释区域与SAM和Semantic - SAM生成的分割掩膜之间的交并比( Intersection over Union,IoU )得分。然后,我们用任何分割掩码保留IoU得分大于0.5的注释区域。
- GPT-4V 生成关系: 对于每个经过筛选的区域,他们提示 (Prompt) GPT-4V 模型来识别场景中至少5个主体对象 。对每个主体,GPT-4V 需要完成两项任务:提供该主体的描述 。提供该主体与其他物体之间的全面关系列表,并分为五大类:空间、互动、功能、社交和情感。
- 过滤错误关系:尽管有高质量的物体区域作为基础,GPT-4V 在生成关系时仍可能出错 。为了提升数据的可靠性,他们设计了一套强大的过滤策略 。对于空间关系:采用基于规则的过滤方法(例如,基于深度图或bbox框坐标来验证“前面”/“后面”这类关系) 。对于其他关系(互动、功能等):采用基于模型的VQA(视觉问答)过滤方法,即向另一个视觉模型提问来验证关系是否成立 。
经过这套流程过滤后,最终产出的高质量、密集关系数据集被称为 SVG-RELATIONS 。33K images with 25.5 triplets per image and 1.9 predicates per region
3.1.2 阶段二 GPT-4精炼的密集场景图 (SVG-FULL的诞生)
- 训练初版 ROBIN 模型:使用第一阶段产出的 SVG-RELATIONS 数据集,训练一个“学生”模型,即初版的 ROBIN 模型 (论文中称为 Robin-3B (Stage 1)) 。这个模型已经具备了为图像中的物体生成密集关系的能力 。
- ROBIN 为新图像生成场景图: 研究者们将这个初版 ROBIN 模型应用到更多、更多样的数据集上,包括 ADE20K, PSG 和 VG 。这样,模型就可以为这些数据集中的海量新图像从头开始生成完整的、密集的场景图 。
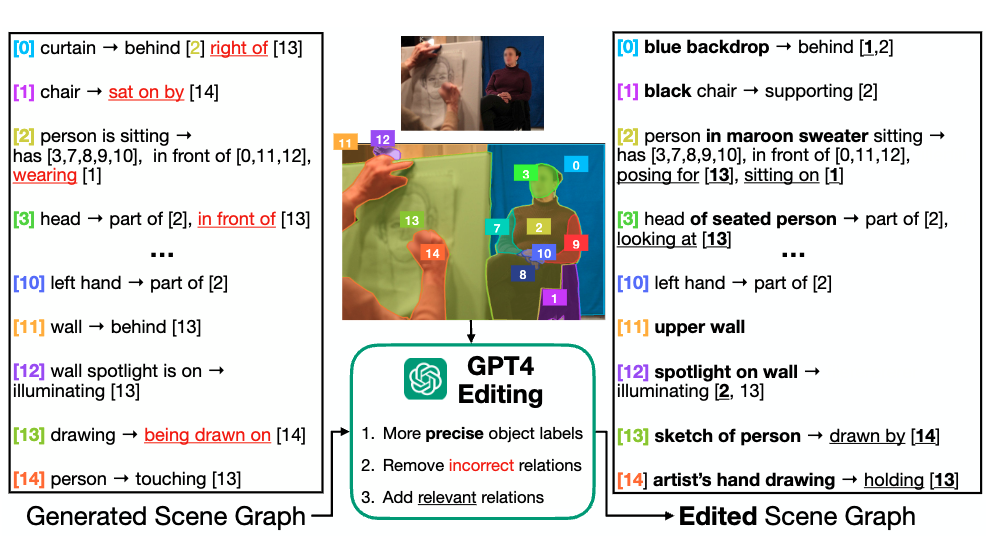
- SG-EDIT: GPT-4 编辑: 由于初版模型在处理“野外”图像(in the wild)时可能会产生噪声,研究者们没有直接使用这些生成的场景图 。他们引入了 GPT-4 作为一个强大的“自动编辑” 。GPT-4 会对 ROBIN 生成的场景图进行精炼(refine):
移除不正确的或不相关的关系 (例如,图中人并没有“穿”着椅子) 。
添加遗漏但相关的关系 (例如,补充人正在“为…摆姿势”或“坐在…上”) 。
使物体描述更精确 (例如,将“人”细化为“穿着栗色毛衣的人”) 。
113K images with 42.3 triplets per image and 2.4 predicates per region
两阶段的生成图对比
数据集的格式标注都是什么类型。看起来是有关系的。图中最主要的关系是在中间的 9.
using a set of spatial (woman-above-raft), social (child-cared by-woman), functional (man-using-paddle), interactional (woman-holding-baby) and emotional (mansharing an experience with-family) relationships.将关系主要分为了 空间关系、社交联系、功能性、交互型以及情感关系。也就是图中 0-15 的描述都属于这几个关系中的一种吗?是的
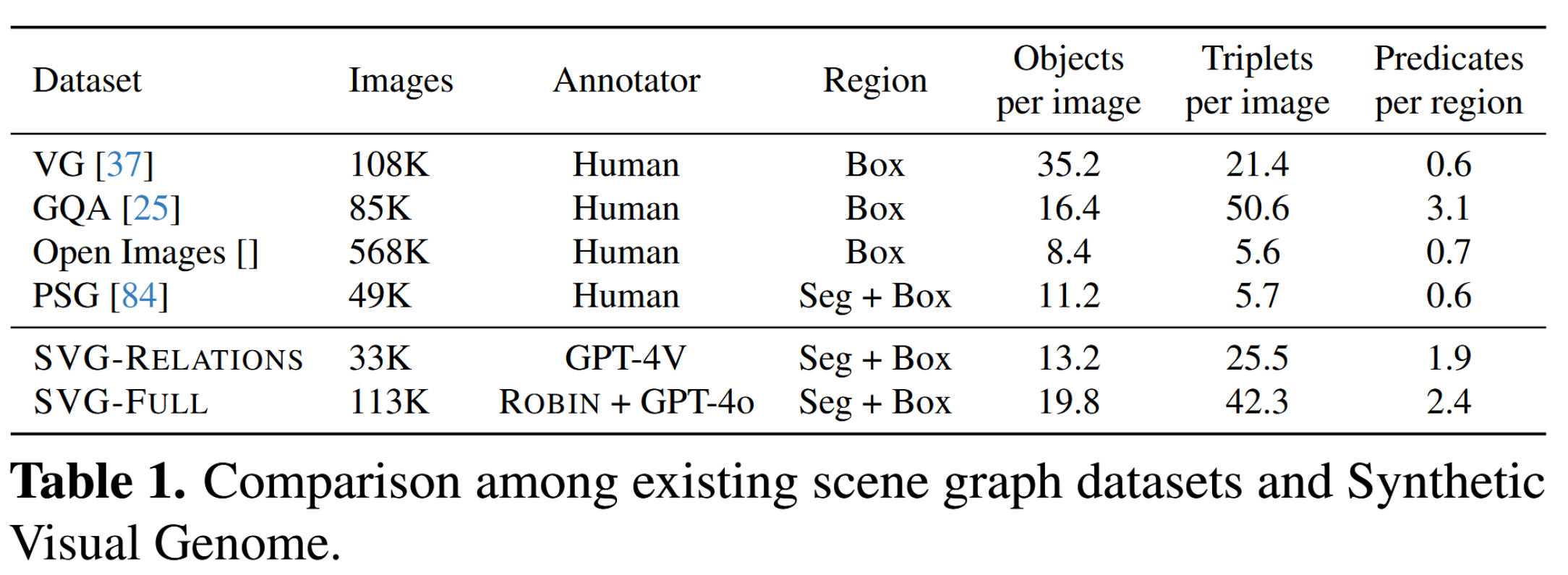
数据集的标注这种集合类的,一张图最多会有多少个?看表1
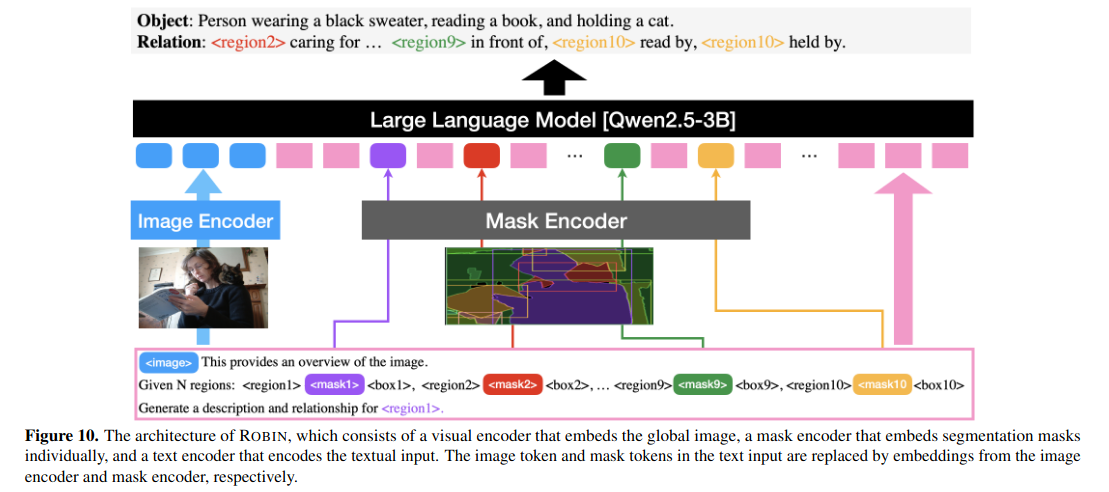
3.2. ROBIN-3B
利用数据集训练能理解图像不同区域关系的模型,最后能生成场景图。
架构参考 Osprey-7B [92] Yuqian Yuan, Wentong Li, Jian Liu, Dongqi Tang, Xinjie Luo, Chi Qin, Lei Zhang, and Jianke Zhu. Osprey: Pixel understanding with visual instruction tuning, 2024. 4, 5, 6, 8, 3 这个模型。
- 视觉编码器 (Vision Encoder):image -> image tokens 使用了 ConvNext-Large
- 像素级掩码感知提取器 (Pixel-level mask-aware extractor): segmentation mask -> mask tokens 只处理 mask 部分,使用了 ConvNext-Large
- 语言模型 (Language Model, LM):负责处理来自前两个组件的图像词元、掩码词元,以及用户的文本指令,整合。利用 Qwen2.5-3B 。
训练阶段:三阶段
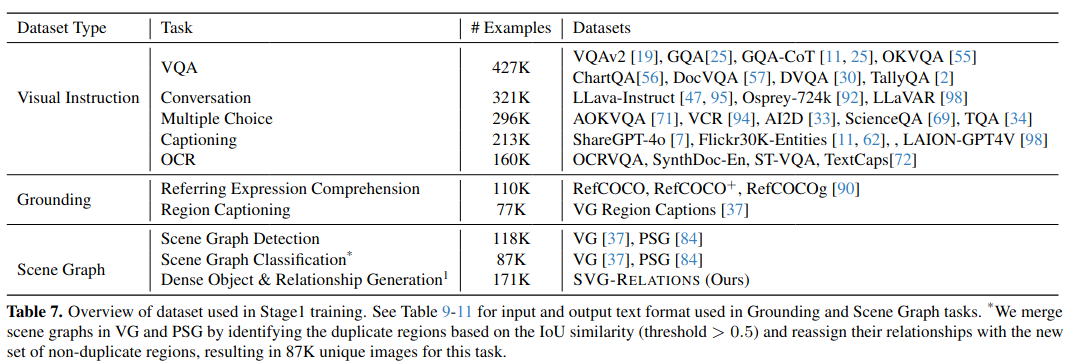
- 图像-分割-文本对齐 (Image-segmentation-text alignment):让语言模型(Qwen2.5-3B)能够适应并处理来自视觉编码器和掩码提取器的图像与掩码词元. Vision Encoder 冻结,掩码编码器、投影层和语言模型则进行训练 。使用了 LLaVA-Pretrain-558K 的图文对和 Osprey-724K 的指令数据集,总计约128万个实例 。
- 场景图指令微调 (Instruction tuning with scene graphs) :解冻 vision decoder。使用了三大类核心数据:(1) Visual Instructions, (2) Grounding, and (3) Scene Graphs. 总训练实例达到了198万个,这个阶段训练出的模型被称为 Robin-3B (Stage 1) 。
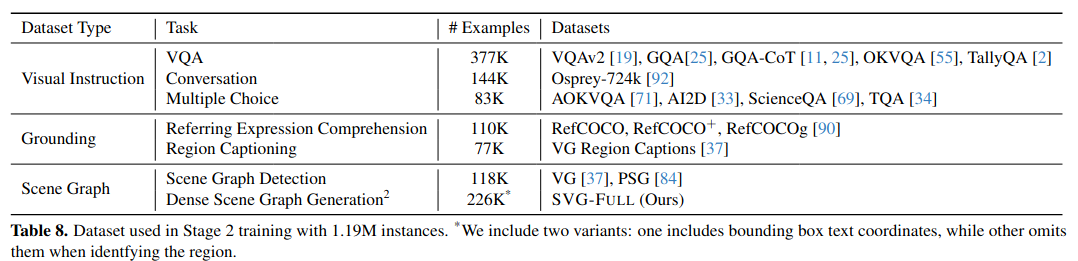
- GPT-4 编辑场景图的蒸馏 (Distillation with GPT4 edited scene graphs):使用 Stage 1 的模型生成完整的场景图,然后通过 SG-EDIT 流程让 GPT-4 进行编辑,从而构建出 SVG-FULL 数据集 。数据混合中使用。继续训练得到Robin-3B。
3.3 Exp
评估 ROBIN-3B 在关系理解任务上的性能。
验证 SG-EDIT 自蒸馏流程(即从 Stage 1 到 Stage 2 的训练)带来的性能提升 。
检验场景图训练是否能增强模型在定位和区域理解方面的能力 。
直接评估 ROBIN-3B 生成场景图的准确性 。
- 关系理解基准测试 (Relationship understanding benchmarks) :7 个数据集
测试数据集:GQA:一个为关系推理设计的图像场景图数据集 。MMBench 和 SEED-Bench:覆盖了空间关系和物体互动理解 。VSR (Visual Spatial Reasoning):专注于视觉空间推理 。CRPE:专注于关系理解,包含了合成图像中的异常关系 。SugarCrepe:用于评估对关系的组合性理解能力 。What’s Up:在受控环境中测试对无歧义物体关系的理解 。
与小尺寸模型 (<4B) 相比,与大尺寸模型 (7B-13B) 相比,Stage 1 vs. Stage 2。 - 指代表达理解 (Referring expression comprehension)
测试数据集:RefCOCO, RefCOCO+, 和 RefCOCOg 。评估指标 PR@0.5 - 区域识别 (Region recognition) 开放词汇
测试任务:在 ADE20k 数据集上进行语义分割,以及在 LVIS 和 PACO 数据集上进行区域分类 。 - 场景图生成 (Scene graph generation)
测试数据集:Panoptic Scene Graph (PSG) 。
3.4. Ablation
- 场景图在指令微调中的作用
- GPT-4 编辑和自蒸馏的优势
- 人类标注 vs. 机器编辑的场景图
4. Supplemental
- 给了一些可视化的例子,对比了Stage 1 vs. Stage 2 ,还有 GPT的生成
- 提供了一些实施细节,包括学习率、算力资源、编码形式、模型架构等。
- 训练数据
- 验证细节,包括评估协议等各种细节,很详细。
5. Additional
好久没读了也没写,前段时间在粗读。
visual relationship reasoning 视觉关系推理 新名词:将每个单独的物体利用关系联系在一起
Instruction-tuning 这个是什么意思该如何准确解释?师生关系?
文献 37 的和这个有什么不同。Ranjay Krishna, Yuke Zhu, Oliver Groth, Justin Johnson, Kenji Hata, Joshua Kravitz, Stephanie Chen, Yannis Kalantidis, Li-Jia Li, David A Shamma, et al. Visual genome: Connecting language and vision using crowdsourced dense image annotations. International journal of computer vision, 123:32–73, 2017. 1, 2, 3, 4, 8, 5, 6, 14
少见的将 Related work 放在 conclusion 前面的文章。
拖了一周终于写完了。