30天打牢数模基础-SVM讲解








案例代码实现
1.导入必要的库
首先需要安装所需库(pip install numpy pandas matplotlib scikit-learn),然后导入:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.svm import SVC
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import GridSearchCV2.模拟葡萄酒数据
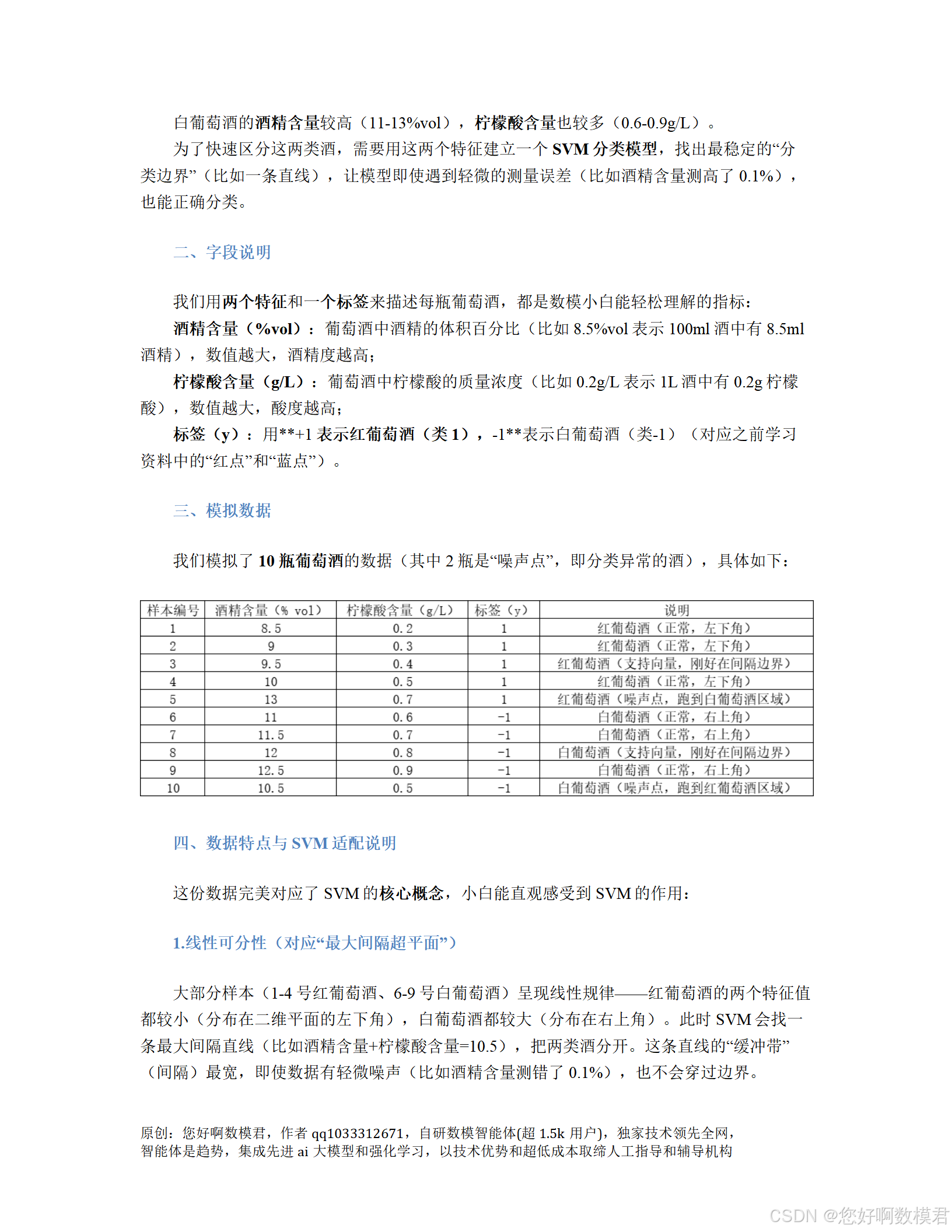
根据案例中的表格,生成10个样本的特征(酒精含量、柠檬酸含量)和标签(红葡萄酒+1、白葡萄酒-1):
def generate_wine_data():"""模拟葡萄酒数据(含2个噪声点)"""# 特征:[酒精含量(%vol), 柠檬酸含量(g/L)]X = np.array([[8.5, 0.2], # 红葡萄酒(正常)[9.0, 0.3], # 红葡萄酒(正常)[9.5, 0.4], # 红葡萄酒(支持向量)[10.0, 0.5], # 红葡萄酒(正常)[13.0, 0.7], # 红葡萄酒(噪声点,跑到白葡萄酒区域)[11.0, 0.6], # 白葡萄酒(正常)[11.5, 0.7], # 白葡萄酒(正常)[12.0, 0.8], # 白葡萄酒(支持向量)[12.5, 0.9], # 白葡萄酒(正常)[10.5, 0.5] # 白葡萄酒(噪声点,跑到红葡萄酒区域)])# 标签:+1=红葡萄酒,-1=白葡萄酒y = np.array([+1, +1, +1, +1, +1, -1, -1, -1, -1, -1])return X, y# 生成数据
X, y = generate_wine_data()3.数据预处理(特征标准化)
SVM对特征缩放敏感,需将特征缩放到均值为0、方差为1(避免某一特征主导间隔计算):
def preprocess_data(X):"""标准化特征(均值0,方差1)"""scaler = StandardScaler()X_scaled = scaler.fit_transform(X)return X_scaled, scaler# 标准化数据
X_scaled, scaler = preprocess_data(X)4.定义决策边界绘制函数(可视化工具)
为了直观看到SVM的分类边界,定义一个函数绘制散点图和决策边界:
def plot_decision_boundary(model, X, y, scaler, title):"""绘制SVM决策边界和支持向量参数:model:训练好的SVM模型X:原始特征数据(未标准化)y:标签scaler:标准化器(用于还原特征尺度)title:图标题"""# 生成网格点(覆盖原始数据的范围,统一扩展0.5避免边界点被截断)x1_min, x1_max = X[:, 0].min() - 0.5, X[:, 0].max() + 0.5x2_min, x2_max = X[:, 1].min() - 0.5, X[:, 1].max() + 0.5 # 修改:统一扩展0.5,保持坐标轴比例协调xx1, xx2 = np.meshgrid(np.linspace(x1_min, x1_max, 100),np.linspace(x2_min, x2_max, 100))# 标准化网格点(用训练好的scaler)xx_scaled = scaler.transform(np.c_[xx1.ravel(), xx2.ravel()])# 预测网格点的类别Z = model.predict(xx_scaled)Z = Z.reshape(xx1.shape)# 绘制决策边界(contour:等高线图)plt.contourf(xx1, xx2, Z, alpha=0.3, cmap='coolwarm')# 绘制原始数据点(红葡萄酒=红点,白葡萄酒=蓝点)plt.scatter(X[y == +1, 0], X[y == +1, 1], c='red', label='红葡萄酒(+1)')plt.scatter(X[y == -1, 0], X[y == -1, 1], c='blue', label='白葡萄酒(-1)')# 绘制支持向量(用圆圈标记)support_vectors = scaler.inverse_transform(model.support_vectors_)plt.scatter(support_vectors[:, 0], support_vectors[:, 1], s=150, edgecolor='black', facecolor='none', label='支持向量')# 设置图标题和标签plt.title(title)plt.xlabel('酒精含量(%vol)')plt.ylabel('柠檬酸含量(g/L)')plt.legend()plt.show()5.训练线性核SVM(硬间隔/软间隔)
线性核适用于近似线性可分数据(案例中大部分样本符合线性规律,仅含少量噪声),调整C参数控制软间隔:
def train_linear_svm(X_scaled, y, C=1.0):"""训练线性核SVM模型"""model = SVC(kernel='linear', C=C) # kernel='linear':线性核;C:软间隔惩罚参数model.fit(X_scaled, y)return model# 训练线性核SVM(C=1.0,中等惩罚)
linear_model = train_linear_svm(X_scaled, y, C=1.0)# 绘制决策边界
plot_decision_boundary(linear_model, X, y, scaler, title='线性核SVM分类边界(C=1.0)')6.训练RBF核SVM(处理非线性数据)
RBF核(径向基函数核)是常用的非线性核(适用于数据分布非线性的场景,如环形、螺旋形)。需调整C(惩罚)和gamma(带宽,控制局部影响):
def train_rbf_svm(X_scaled, y, param_grid=None):"""训练RBF核SVM模型(用网格搜索调参)"""if param_grid is None:# 默认参数网格(C:惩罚,gamma:带宽)param_grid = {'C': [0.1, 1, 10, 100], 'gamma': [0.01, 0.1, 1, 10]}# 网格搜索(5折分层交叉验证,保留类别比例)grid = GridSearchCV(SVC(kernel='rbf'), param_grid, cv=5, scoring='accuracy') # 补充:明确评分标准为准确率grid.fit(X_scaled, y)print(f"RBF核最佳参数:{grid.best_params_}")print(f"RBF核最佳交叉验证准确率:{grid.best_score_:.2f}")return grid.best_estimator_# 训练RBF核SVM(网格搜索调参)
rbf_model = train_rbf_svm(X_scaled, y)# 绘制决策边界
plot_decision_boundary(rbf_model, X, y, scaler, title='RBF核SVM分类边界(最佳参数)')7.主程序(整合所有步骤)
if __name__ == "__main__":# 1. 生成数据X, y = generate_wine_data()print("原始数据:")print(pd.DataFrame(np.c_[X, y], columns=['酒精含量', '柠檬酸含量', '标签']))# 2. 预处理数据X_scaled, scaler = preprocess_data(X)# 3. 训练线性核SVMprint("\n=== 线性核SVM ===")linear_model = train_linear_svm(X_scaled, y, C=1.0)print(f"线性核支持向量数量(红葡萄酒/白葡萄酒):{linear_model.n_support_}") # 补充:明确两类支持向量数量# 4. 训练RBF核SVM(调参)print("\n=== RBF核SVM(网格搜索调参) ===")rbf_model = train_rbf_svm(X_scaled, y)print(f"RBF核支持向量数量(红葡萄酒/白葡萄酒):{rbf_model.n_support_}")# 5. 绘制决策边界(线性核+RBF核)plot_decision_boundary(linear_model, X, y, scaler, title='线性核SVM分类边界(C=1.0)')plot_decision_boundary(rbf_model, X, y, scaler, title='RBF核SVM分类边界(最佳参数)')代码说明与使用指南
1.代码结构
数据生成:generate_wine_data函数模拟案例中的10个样本(含2个噪声点);
数据预处理:preprocess_data函数标准化特征(SVM必做步骤,避免特征尺度差异影响模型);
可视化工具:plot_decision_boundary函数绘制决策边界和支持向量(直观展示SVM工作原理);
模型训练:train_linear_svm(线性核)和train_rbf_svm(RBF核)函数训练模型,其中RBF核用GridSearchCV进行参数调优(5折交叉验证);
主程序:整合所有步骤,输出原始数据、模型参数及支持向量数量,并可视化决策边界。
2.关键参数解释
C(软间隔惩罚系数):
C越大:对误分类样本的惩罚越重,模型更倾向于严格分开所有样本(容易过拟合,如C=100时,噪声点会被强行分类,但间隔很小);
C越小:对误分类样本的惩罚越轻,模型允许更多误分类(容易欠拟合,如C=0.1时,间隔很大,但可能误分类正常点)。
gamma(RBF核带宽参数):
gamma越大:单个样本的影响范围越小(模型更关注局部数据,容易过拟合,如gamma=10时,决策边界会绕开噪声点,但泛化能力差);
gamma越小:单个样本的影响范围越大(模型更关注全局数据,容易欠拟合,如gamma=0.01时,决策边界很平滑,但可能无法分开非线性数据)。
3.运行结果说明
线性核SVM:输出支持向量数量(如红葡萄酒1个、白葡萄酒1个,对应案例中的3号和8号样本),决策边界为直线,间隔较宽,允许噪声点(5号、10号)违反约束(软间隔特性);
RBF核SVM:网格搜索会输出最佳参数(如C=10、gamma=1),决策边界为曲线(处理非线性数据),支持向量数量更多(RBF核更关注局部点,对噪声更敏感)。
4.小白使用建议
修改数据:可在generate_wine_data函数中添加更多样本(如20个),或调整噪声点位置(如将5号样本的酒精含量改为12.0),观察模型对数据变化的敏感性;
调整参数:尝试修改C的值(如C=0.1、C=100),看线性核的决策边界如何变化;尝试修改gamma的值(如gamma=0.01、gamma=10),看RBF核的决策边界如何变化;
更换核函数:可尝试多项式核(kernel='poly',调整degree参数,如degree=2),观察其对非线性数据的处理效果(多项式核适用于低维非线性数据)。
通过运行这份代码,小白能直观理解SVM的最大间隔、支持向量、软间隔、核函数等核心概念,掌握SVM的基本使用方法(数据预处理、模型训练、参数调优、可视化)。