【分布式 ID】详解百度 uid-generator(源码篇)
文章目录
- 1. 前言
- 2. 继承关系
- 3. UidGenerator 接口
- 2.1 DefaultUidGenerator 实现
- 2.2 CachedUidGenerator 的实现
- 4. DefaultUidGenerator 源码分析
- 4.1 属性
- 4.2 afterPropertiesSet 初始化 workerID
- 5. CachedUidGenerator 源码分析
- 5.1 RingBuffer 源码分析
- 5.1.1 属性结构
- 5.1.2 构造器
- 5.1.3 put 添加 UID
- 5.1.4 take 获取 UID
- 5.1.5 并发限制
- 5.2 BufferPaddingExecutor 源码分析
- 5.2.1 属性构造器
- 5.2.2 paddingBuffer 填充 ID
- 5.2.3 uidProvider.provide 获取当前时间下的 id 集合(秒)
- 5.2.4 什么时候执行 paddingBuffer
- 5.3 afterPropertiesSet 方法
- 6. 小结
1. 前言
系列文章:
- 【分布式 ID】生成唯一 ID 的几种方式。
- 【分布式 ID】一文详解美团 Leaf
- 【分布式 ID】详解百度 uid-generator(基础篇)
上一篇文章我们讲解了 uid-generator 的演示和结构,这篇文章就来讲一下 uid-generator 的源码,项目开源地址:baidu/uid-generator。
2. 继承关系
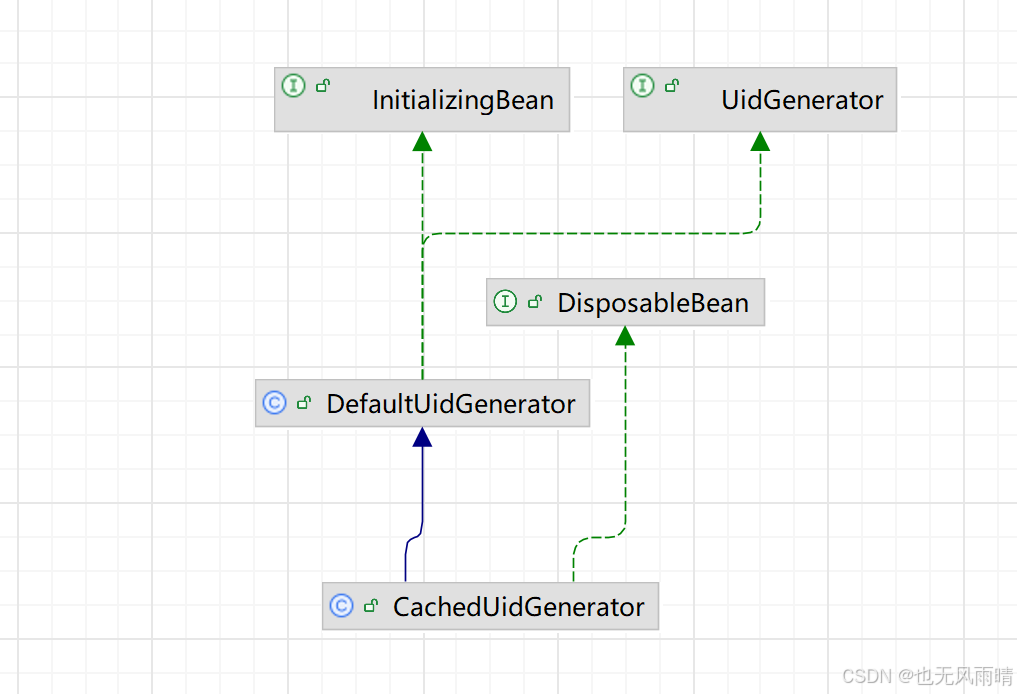
如果要看源码,首先就要从各个类的继承关系入手,CachedUidGenerator 就是继承自 DefaultUidGenerator,换句话说 CachedUidGenerator 生成 Uid 的方法和 DefaultUidGenerator 是一样的,也就是雪花算法。CachedUidGenerator 是对生成的 Uid 的获取和生成进行了一层封装,能够提供更高的 QPS,符合业务的需求,下面我们就从这个继承结构出发来讲一下 uid-generator 的源码。
3. UidGenerator 接口
首先来看下顶层接口 UidGenerator,这个接口里面定义了两个方法:getUID 和 parseUID,分别是获取 UID 和解析 UID。
public interface UidGenerator {/*** Get a unique ID** @return UID* @throws UidGenerateException*/long getUID() throws UidGenerateException;/*** Parse the UID into elements which are used to generate the UID. <br>* Such as timestamp & workerId & sequence...** @param uid* @return Parsed info*/String parseUID(long uid);}
getUID 就是通过雪花 ID 生成 ID,parseUID 就是通过 ID 解析出 timestamp、workerId、sequence,然后返回。我们来看下 DefaultUidGenerator 的实现。
2.1 DefaultUidGenerator 实现
@Override
public long getUID() throws UidGenerateException {try {// 通过 nextId 生成 IDreturn nextId();} catch (Exception e) {LOGGER.error("Generate unique id exception. ", e);throw new UidGenerateException(e);}
}protected synchronized long nextId() {// 获取当前的时间long currentSecond = getCurrentSecond();// 时钟回退if (currentSecond < lastSecond) {// 直接抛出异常long refusedSeconds = lastSecond - currentSecond;throw new UidGenerateException("Clock moved backwards. Refusing for %d seconds", refusedSeconds);}// 如果还是在同一秒if (currentSecond == lastSecond) {// 序列号 + 1sequence = (sequence + 1) & bitsAllocator.getMaxSequence();// Exceed the max sequence, we wait the next second to generate uidif (sequence == 0) {// 然后超过序号的上限了, 直接跑到下一秒currentSecond = getNextSecond(lastSecond);}// At the different second, sequence restart from zero} else {// 跟上一次是不同秒, 那么序号就从 0 开始sequence = 0L;}// 记录上一秒lastSecond = currentSecond;// 通过 bitsAllocator 去生成 UIDreturn bitsAllocator.allocate(currentSecond - epochSeconds, workerId, sequence);
}// 生成 UID
public long allocate(long deltaSeconds, long workerId, long sequence) {return (deltaSeconds << timestampShift) | (workerId << workerIdShift) | sequence;
}
可以看到这里面的逻辑跟雪花算法是一样的,要注意的是 uid-generator 记录的时间的单位是 s 而不是 ms,这个要注意下。而且由于要处理高并发的问题,这里也是加上了一个 synchronized 标记防止获取到相同的 ID。
那么下面再来看下 parseUID 的逻辑,这个方法传入 long 类型的 uid,然后解析出这个 uid 中的时间戳、workerID、序列号。
@Override
public String parseUID(long uid) {// 64 位long totalBits = BitsAllocator.TOTAL_BITS;// 符号位long signBits = bitsAllocator.getSignBits();// 时间戳long timestampBits = bitsAllocator.getTimestampBits();// workerID long workerIdBits = bitsAllocator.getWorkerIdBits();// 序列号long sequenceBits = bitsAllocator.getSequenceBits();// 解析出序列号、workerID、时间戳long sequence = (uid << (totalBits - sequenceBits)) >>> (totalBits - sequenceBits);long workerId = (uid << (timestampBits + signBits)) >>> (totalBits - workerIdBits);long deltaSeconds = uid >>> (workerIdBits + sequenceBits);// 然后根据时间戳获取到具体的时间Date thatTime = new Date(TimeUnit.SECONDS.toMillis(epochSeconds + deltaSeconds));// 解析成 yyyy-MM-dd HH:mm:ss 的格式String thatTimeStr = DateUtils.formatByDateTimePattern(thatTime);// 返回结果return String.format("{\"UID\":\"%d\",\"timestamp\":\"%s\",\"workerId\":\"%d\",\"sequence\":\"%d\"}",uid, thatTimeStr, workerId, sequence);
}
可以看到这个方法就是获取出各个信息的位数,然后从 uid 解析出,那么这里的解析逻辑是上面呢,我画一张图就能看懂了。
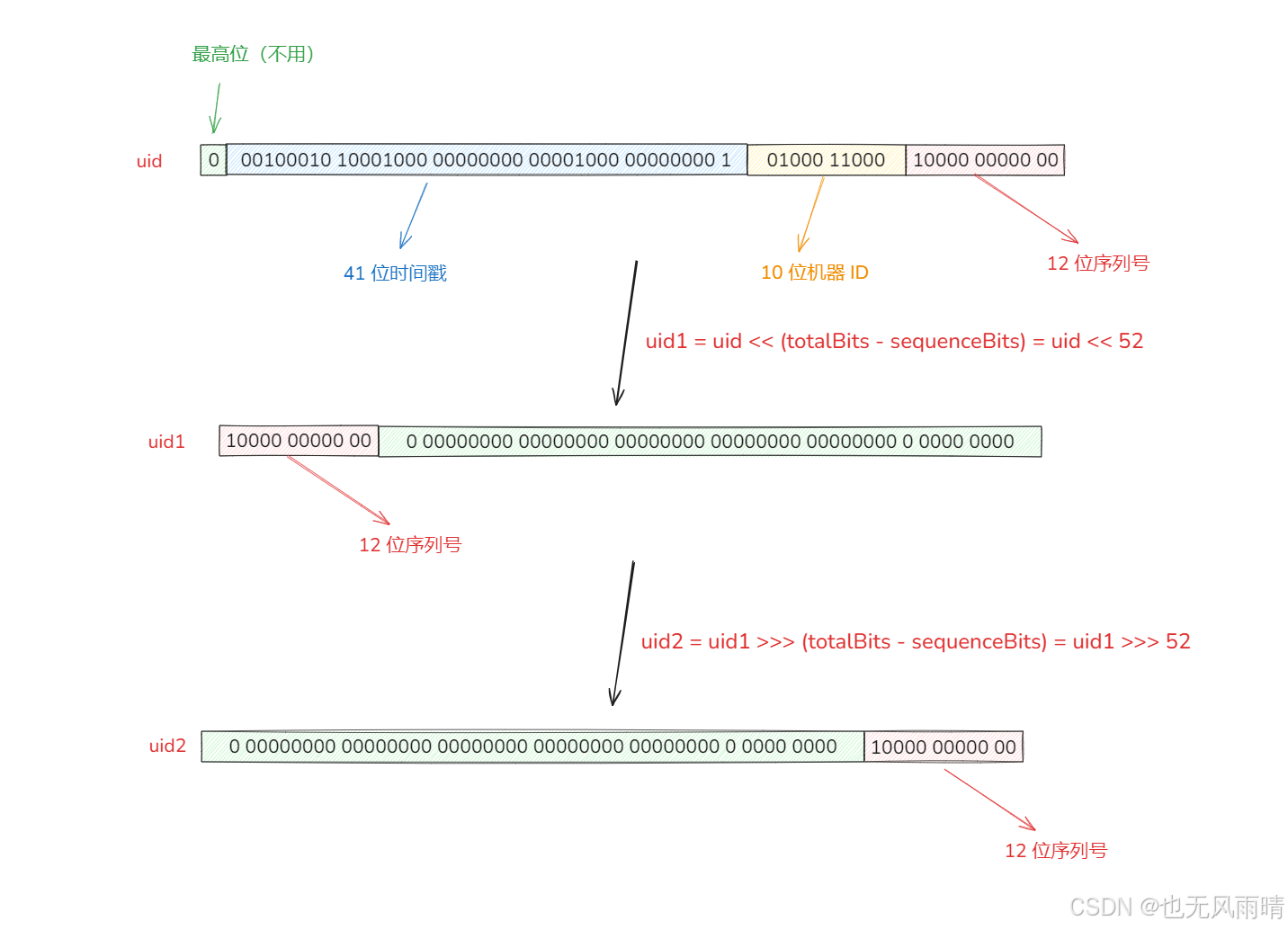
还是一样,以上面经典布局为例子,然后我们要从里面解析出 sequence,首先将 uid 左移 totalBits - sequenceBits,就变成了 uid1,这一步是为了将最后的 sequence 挪到开头,接下来使用 uid1 >>> (totalBits - sequenceBits),这一步是为了将开头的 12 位序列号挪到最后,要注意这里用了 >>> 意思是无符号移动,看上面图中的例子,如果不用 >>>,那么最后 uid2 的最高位会是负数。
总之就是如果我们要解析某一部分的数据,要分成两部分:
- 将这部分数据移到开头,这一步是为了将其他位置为 0。
- 再将这部分数据移到结尾,就能得到最终结果了。
对于时间戳,则是直接用 uid >>> (workerIdBits + sequenceBits),这是因为雪花算法最高位默认就是 0,可以直接把 最高位 + 时间戳 看成一个整体向右移 workerIdBits + sequenceBits 就得到时间戳了,也就是省去上面的第一步。
2.2 CachedUidGenerator 的实现
下面来看下 CachedUidGenerator 的实现,由于 CachedUidGenerator 是 DefaultUidGenerator 的子类,所以 parseUID 用的就是 DefaultUidGenerator 的实现。
@Override
public String parseUID(long uid) {return super.parseUID(uid);
}
而 getUID 由于 CachedUidGenerator 是用了双 Buffer 存储,所以 getUID 就是用 take 方法从 buffer 中获取。
@Override
public long getUID() {try {return ringBuffer.take();} catch (Exception e) {LOGGER.error("Generate unique id exception. ", e);throw new UidGenerateException(e);}
}
这个 take 方法留到后面讲 CachedUidGenerator 的源码时再具体来聊。
4. DefaultUidGenerator 源码分析
那还是一样,我们顺着上面第 2 小节的继承图,先从 DefaultUidGenerator 开始说起,那我们主要看的就是这个类里面的属性和 afterPropertiesSet,主要是看一些属性的设置,因为 CachedUidGenerator 相关字段的设置也是在这个父类的 afterPropertiesSet 方法中去设置的。
4.1 属性
/** Bits allocate */
protected int timeBits = 28;
protected int workerBits = 22;
protected int seqBits = 13;/** Customer epoch, unit as second. For example 2016-05-20 (ms: 1463673600000)*/
protected String epochStr = "2016-05-20";
protected long epochSeconds = TimeUnit.MILLISECONDS.toSeconds(1463673600000L);/** Stable fields after spring bean initializing */
protected BitsAllocator bitsAllocator;
protected long workerId;/** Volatile fields caused by nextId() */
protected long sequence = 0L;
protected long lastSecond = -1L;/** Spring property */
protected WorkerIdAssigner workerIdAssigner;
首先我们来看下这个类里面的属性,这些属性是什么意思下面就简单看下:
- timeBits:时间戳位数,默认 28 位。
- workerBits:workerID 位数,默认 22 位。
- seqBits:序列号位数,默认 13 位。
- epochStr:基准时间,默认 2016-05-20,时间戳存储以 s 为单位,存储的是当前时间 - 基准时间。
- bitsAllocator:雪花算法 ID 分配器,上面这些时间戳、workerID、seqBits 都会作为默认值设置到这个分配器里面。
- workerId:当前机器启动分配到的 workerID。
- sequence:序列号,递增 + 1。
- lastSecond:上一次获取 ID 的时间,用来判断是否发生时钟回拨的。
- workerIdAssigner:workerID 分配器,里面的默认实现就是往数据库里面插入一条启动记录,然后用数据库返回的自增 ID 作为当前服务的 workerID。
上面的属性都比较简单,然后可以看到这个类也提供了一些 set 方法,因此我们可以自己设置这些属性。
比如在上一篇文章的 test 中,我们就是通过 xml 文件配置了这几个属性。
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-3.1.xsd"><!-- UID generator --><bean id="disposableWorkerIdAssigner" class="com.baidu.fsg.uid.worker.DisposableWorkerIdAssigner"/><bean id="defaultUidGenerator" class="com.baidu.fsg.uid.impl.DefaultUidGenerator" lazy-init="false"><property name="workerIdAssigner" ref="disposableWorkerIdAssigner"/><!-- Specified bits & epoch as your demand. No specified the default value will be used --><property name="timeBits" value="29"/><property name="workerBits" value="21"/><property name="seqBits" value="13"/><property name="epochStr" value="2016-09-20"/></bean><!-- Import mybatis config --><import resource="classpath:/uid/mybatis-spring.xml"/></beans>
4.2 afterPropertiesSet 初始化 workerID
@Override
public void afterPropertiesSet() throws Exception {// 初始化 BitsAllocator, 用于分配 IDbitsAllocator = new BitsAllocator(timeBits, workerBits, seqBits);// 初始化 workerIDworkerId = workerIdAssigner.assignWorkerId();// 如果 workerID 大于最大的 ID 了, 直接抛出异常, 不能启动if (workerId > bitsAllocator.getMaxWorkerId()) {throw new RuntimeException("Worker id " + workerId + " exceeds the max " + bitsAllocator.getMaxWorkerId());}LOGGER.info("Initialized bits(1, {}, {}, {}) for workerID:{}", timeBits, workerBits, seqBits, workerId);
}
DefaultUidGenerator 是实现了 InitializingBean 的,所以在 bean 初始化的时候会调用 afterPropertiesSet 方法,这个方法主要就是初始化了 ID 分配器和 workerId,首先来看下 BitsAllocator,这个类就是存储雪花算法的那几个属性,结构比较简单,直接看源码。
public class BitsAllocator {/*** Total 64 bits*/public static final int TOTAL_BITS = 1 << 6;/*** Bits for [sign-> second-> workId-> sequence]*/private int signBits = 1;private final int timestampBits;private final int workerIdBits;private final int sequenceBits;/*** Max value for workId & sequence*/private final long maxDeltaSeconds;private final long maxWorkerId;private final long maxSequence;/*** Shift for timestamp & workerId*/private final int timestampShift;private final int workerIdShift;/*** 初始化 ID 分配器* @param timestampBits* @param workerIdBits* @param sequenceBits*/public BitsAllocator(int timestampBits, int workerIdBits, int sequenceBits) {// 确保四个部分加起来是 64 字节int allocateTotalBits = signBits + timestampBits + workerIdBits + sequenceBits;Assert.isTrue(allocateTotalBits == TOTAL_BITS, "allocate not enough 64 bits");// 初始化时间戳、workerID、序列号this.timestampBits = timestampBits;this.workerIdBits = workerIdBits;this.sequenceBits = sequenceBits;// 最大的时间戳序号, 比如时间戳是 10 位, 那么最大值就是 2^10 - 1 = 1023this.maxDeltaSeconds = ~(-1L << timestampBits);// 最大 WorkerIDthis.maxWorkerId = ~(-1L << workerIdBits);// 最大序列号this.maxSequence = ~(-1L << sequenceBits);// 时间戳偏移量this.timestampShift = workerIdBits + sequenceBits;// WorkerID 偏移量this.workerIdShift = sequenceBits;}public long allocate(long deltaSeconds, long workerId, long sequence) {return (deltaSeconds << timestampShift) | (workerId << workerIdShift) | sequence;}// 省略 get,set 方法
}
上面就是设置时间戳序号、WorkerID 和 序列号的位数以及最大值,这个最大值是用来判断当生成 ID 的时候有没有超过最大值的,这部分比较简单,大家直接看注释就行,下面来看下 assignWorkerId 是如何分配 workerID 的。
@Transactional
public long assignWorkerId() {// 创建 Worker 节点WorkerNodeEntity workerNodeEntity = buildWorkerNode();// 添加到数据库 WORKER_NODE 中, 相同的 IP 和 PORT 还是会添加一条记录的// 也就是说每一次启动都会重新分配一个 workerIDworkerNodeDAO.addWorkerNode(workerNodeEntity);LOGGER.info("Add worker node:" + workerNodeEntity);// 返回 ID 作为当前项目的 WorkerIDreturn workerNodeEntity.getId();
}/*** 根据 IP 和 PORT 创建 WorkerNodeEntity, 会判断是 Docker 启动还是正常服务器启动*/
private WorkerNodeEntity buildWorkerNode() {WorkerNodeEntity workerNodeEntity = new WorkerNodeEntity();if (DockerUtils.isDocker()) {workerNodeEntity.setType(WorkerNodeType.CONTAINER.value());workerNodeEntity.setHostName(DockerUtils.getDockerHost());workerNodeEntity.setPort(DockerUtils.getDockerPort());} else {workerNodeEntity.setType(WorkerNodeType.ACTUAL.value());workerNodeEntity.setHostName(NetUtils.getLocalAddress());workerNodeEntity.setPort(System.currentTimeMillis() + "-" + RandomUtils.nextInt(100000));}return workerNodeEntity;
}
首先就是通过 buildWorkerNode 方法构建出 WorkerNodeEntity 对象,这里面会去区分是 docker 启动还是正常的启动,主要是获取这里面的端口,然后插入数据库,接下来直接返回自增 ID。
如果分配的 workerID 比最大的 ID 要大,直接抛出异常,也就是说 uid-generator 采用的每次启动都需要重新获取递增 ID 的方式,所以需要评估好每天重启次数,避免频繁重启导致提前设置的 workerID 不够用。
5. CachedUidGenerator 源码分析
下面来看下 CachedUidGenerator 的源码分析,那我们先看下核心类 RingBuffer,也就是缓冲区双 Buffer。
5.1 RingBuffer 源码分析
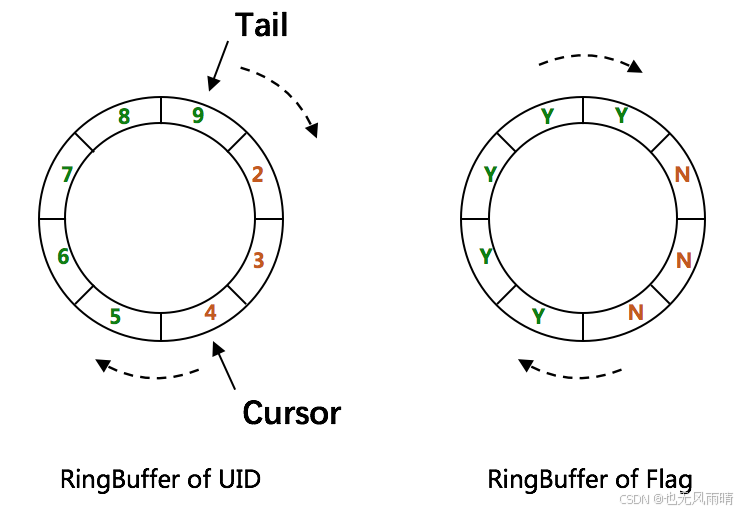
这里我们把上一篇文章的结构图给拿过来方便对着源码分析。
5.1.1 属性结构
下面来看下 RingBuffer 中的属性值。
- START_POINT: 默认是 -1,tail 和 cursor 的初始位置。
- CAN_PUT_FLAG: uid-generator 使用了双 Buffer, 一个 slots 存储 ID,一个 flags 用于表示 slots 对应的下标的状态,这个状态就表示 slots 下标的 ID 已经被获取了,现在可以往里面 Padding。
- CAN_TAKE_FLAG: 和上面相反,这个状态表示 slots 下标的 ID 已经准备好了,现在可以获取这个 ID。
- DEFAULT_PADDING_PERCENT: 默认的 PADDING 阈值,当 Buffer 中消耗的 ID 已经超过 50% 了,这时候就应该去 Padding 了。
- bufferSize: buffer 数组大小,默认是最大序号值 << 3,比如序号我们设置了 13 位,那么 2^13 就是 8192,所以算出来的 bufferSize = 8192 << 3 = 65536。
- indexMask: buffer 数组大小 - 1,主要是配合 tail 和 cursor 来算下标的,因为 buffer 数组大小是 2^n 次方,因此这里 - 1 之后算出来的 mask 二进制都是 1,为什么需要这个标记呢,因为 & 运算比较快。
- slots: 上面图中的第一个 Buffer,就是 RingBuffer of UID。
- flags: 上面图中的第二个 Buffer,就是 RingBuffer of Flag。注意下这里 flags 属性是 PaddedAtomicLong,使用 long 类型填充避免缓存伪共享的问题,具体可以看上一篇文章:【分布式 ID】详解百度 uid-generator(基础篇) 。
- tail: tail 指针, 可以理解成环形数组 slots 中最后一个可获取的 ID 的下标,当往 Buffer 里面 Put ID 的时候需要放到 tail + 1 的位置。
- cursor: cursor 指针,当获取 ID 的时候会从 cursor + 1 位置获取。
- paddingThreshold: 配合上面的 DEFAULT_PADDING_PERCENT 来使用,通过 DEFAULT_PADDING_PERCENT * bufferSize / 100 算出来,当 tail 和 cursor 之间的距离超过 paddingThreshold,就需要去启动一个线程异步 Padding ID 到 buffer 中。
- rejectedPutHandler: put 方法的拒绝策略,当 buffer 中没有空闲的位置能放生成的 ID 了,就会调用这个决绝策略,这里由于 put 是内部线程去调用,所以 rejectedPutHandler 默认就是打印下日志,标识现在 buffer 已经满了。
- rejectedTakeHandler: take 方法的拒绝策略,当 buffer 中没有 ID 可以获取了,这时候就会调用这个拒绝策略,默认是抛出异常。
- bufferPaddingExecutor: 填充 ID 的线程池,这里面封装了一个定时任务和执行 paddingBuffer 的线程池,线程大小是 CPU 核数 * 2,当 ID 消耗超过一定阈值(默认 50%) 之后就用线程池异步去补充 ID。同时如果用户配置了开启定时任务,那么 uid-generator 也会定时去生成 ID 填充 buffer。
那上面就是 RingBuffer 的属性,下面我们来看下 RingBuffer 的构造器。
5.1.2 构造器
RingBuffer 提供了两个构造器,一个是只传入 bufferSize,一个是传入 bufferSize 和 paddingFactor。
public RingBuffer(int bufferSize) {this(bufferSize, DEFAULT_PADDING_PERCENT);
}public RingBuffer(int bufferSize, int paddingFactor) {// check buffer size is positive & a power of 2; padding factor in (0, 100)Assert.isTrue(bufferSize > 0L, "RingBuffer size must be positive");Assert.isTrue(Integer.bitCount(bufferSize) == 1, "RingBuffer size must be a power of 2");Assert.isTrue(paddingFactor > 0 && paddingFactor < 100, "RingBuffer size must be positive");this.bufferSize = bufferSize;this.indexMask = bufferSize - 1;this.slots = new long[bufferSize];this.flags = initFlags(bufferSize);this.paddingThreshold = bufferSize * paddingFactor / 100;
}
CachedUidGenerator 用的是 RingBuffer:this.ringBuffer = new RingBuffer(bufferSize, paddingFactor);,而这里的 paddingFactor 也等于 DEFAULT_PADDING_PERCENT,就算是这里默认给的就是 50%,不过按照官方给的用例是可以配置的。

但是我这把源码都看了个遍,也没找到这个属性的 set 方法,感觉是写错了,如果真要可配置起码给个 set 方法吧。
还是回到构造器,可以看到这里面就是设置了下 bufferSize、indexMask、paddingThreshold 和两个 buffer,需要注意的是创建 flags 的时候所有下标默认值是 CAN_PUT_FLAG。
private PaddedAtomicLong[] initFlags(int bufferSize) {PaddedAtomicLong[] flags = new PaddedAtomicLong[bufferSize];for (int i = 0; i < bufferSize; i++) {flags[i] = new PaddedAtomicLong(CAN_PUT_FLAG);}return flags;
}
5.1.3 put 添加 UID
终于来到核心方法 put 了,put 方法就是往 buffer 里面填充一个 ID,由于同一时间可能有多个线程都往里面去 put,这里也是加了一个锁防止并发问题,那由于 put 都是内部在调用,并发不高,毕竟就算定时任务和 asyncPadding 一起执行那也就 2 个线程在跑,所以加个锁对性能影响不大,那下面我还是把 put 方法的代码和注释都贴出来。
/*** Put an UID in the ring & tail moved<br>* We use 'synchronized' to guarantee the UID fill in slot & publish new tail sequence as atomic operations<br>* * <b>Note that: </b> It is recommended to put UID in a serialize way, cause we once batch generate a series UIDs and put* the one by one into the buffer, so it is unnecessary put in multi-threads** @param uid* @return false means that the buffer is full, apply {@link RejectedPutBufferHandler}*/
public synchronized boolean put(long uid) {// 获取 tail 指针的位置long currentTail = tail.get();// 获取 cursor 指针的位置long currentCursor = cursor.get();// 由于 ID 需要放到 tail + 1 的位置, 所以先求出来 currentTail 和 currentCursor 的距离long distance = currentTail - (currentCursor == START_POINT ? 0 : currentCursor);// 如果等于 bufferSize - 1, 比如现在有一个数组长度是 10, tail 和 cursor 都是 -1 的位置, 然后一开始把这个数组填充满了, 这时候// tail 就会执向最后一个位置, tail - cursor = 9, 也就是 bufferSize - 1, 这种情况下就代表 buffer 满了if (distance == bufferSize - 1) {// 拒绝策略, 默认打印日志rejectedPutHandler.rejectPutBuffer(this, uid);// 放不下了, 外面别调用了return false;}// 1. 首先要放的位置是 currentTail + 1, calSlotIndex 就是和 indexMask 相与, 防止下标越界int nextTailIndex = calSlotIndex(currentTail + 1);// 判断这个位置是否可以放 ID, 如果不可以, 说明这个位置的 ID 还没有消耗, 比如 tail 是 2, cursor 是 3if (flags[nextTailIndex].get() != CAN_PUT_FLAG) {// 拒绝策略rejectedPutHandler.rejectPutBuffer(this, uid);return false;}// 2. 将 ID 添加到 tail + 1 的位置// 3. 更新 tail + 1 的位置状态为 CAN_TAKE_FLAG, 表示这个 ID 可以被获取// 4. 更新 tail 指针到 tail + 1 的位置slots[nextTailIndex] = uid;flags[nextTailIndex].set(CAN_TAKE_FLAG);tail.incrementAndGet();// The atomicity of operations above, guarantees by 'synchronized'. In another word,// the take operation can't consume the UID we just put, until the tail is published(tail.incrementAndGet())// 假设现在 cursor 消耗比较快, 已经追上 tail 了, 现在是 cursor = tail, 这时候当一个线程进入 put 方法之后, 其他线程是没办法同// 时 put 的, 由于 take 方法没有同步, 因此 tail 是可以和 put 并发执行的, 在 tail.incrementAndGet 之前 take 方法获取到的还// 是 currentTail 的位置, 因此这时候是获取不到值的, 而 tail.incrementAndGet 之后, take 方法的 nextCursor 就能获取到刚刚设// 置进去的 nextTailIndex, 确保了原子性return true;
}
在 put 方法调用之前,需要先获取下 currentTail 到 currentCursor 的距离,为什么是 currentTail - currentCursor 呢,这里涉及到一个重要的设计就是下标递增,uid-generator 不像有的循环数组当下标来到数组尾部的时候将这个值重新置为 0,tail 和 cursor 是不断递增的,由于一开始需要对 buffer 填充,所以 tail 指针会不断 ++,后面要 take 的时候 cursor 再不断 ++,所以 cursor 是一定 <= tail 的,因此 distance 是用 tail - cursor,能确保一定是正数。
如果 distance == bufferSize - 1,比如初始值,又比如当 put 方法已经把这个 distance 占满了,这种情况下就会执行拒绝策略,怎么理解呢?假设一开始数组长度为 10,那么就是下标 0 ~ 9,tail 和 cursor 都是 -1 的位置,这种情况下启动时先不断往 buffer 里面填充,当 tail 来到下标 9 的时候算出来的 distance 就是 9,这种情况下说明 0 ~ 9 已经被填充完了。
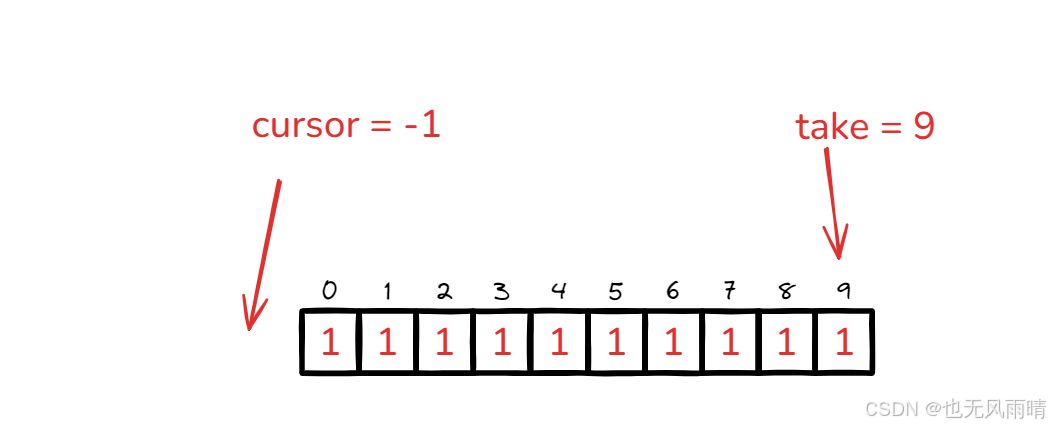
然后 cursor 指针开始移动了,不断从 buffer 里面获取 ID,因此 cursor 也不断逼近 take,我们知道获取 id 是从 cursor + 1 位置获取的,所以当 cursor 来到 take 的位置时候发现 cursor + 1 超过 take 指针的位置了,这时候说明没有 ID 可以获取了,也执行拒绝策略。
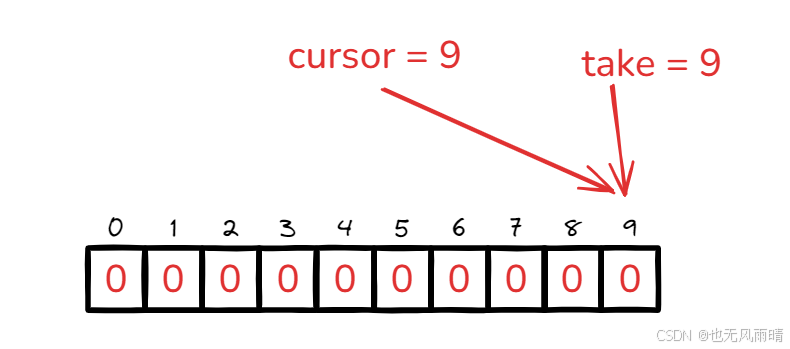
然后 take 继续往前移动,注意因为这里演示顺手就将数组长度写成 10 了,没有写成 2 的次方,大家知道就好。 比如 take 来到 10,这种情况下要操作的位置实际上是 (take + 1)% 10 = 0 ,所以当 take 来到 18 的时候,下一次要填充的位置是(18 + 1) % 10 = 9,这时候发现 18 - 9 = 9,就执行拒绝策略返回了,也就是只有第一次启动填充能一次性把 buffer 填满,后面一次性都填不满。
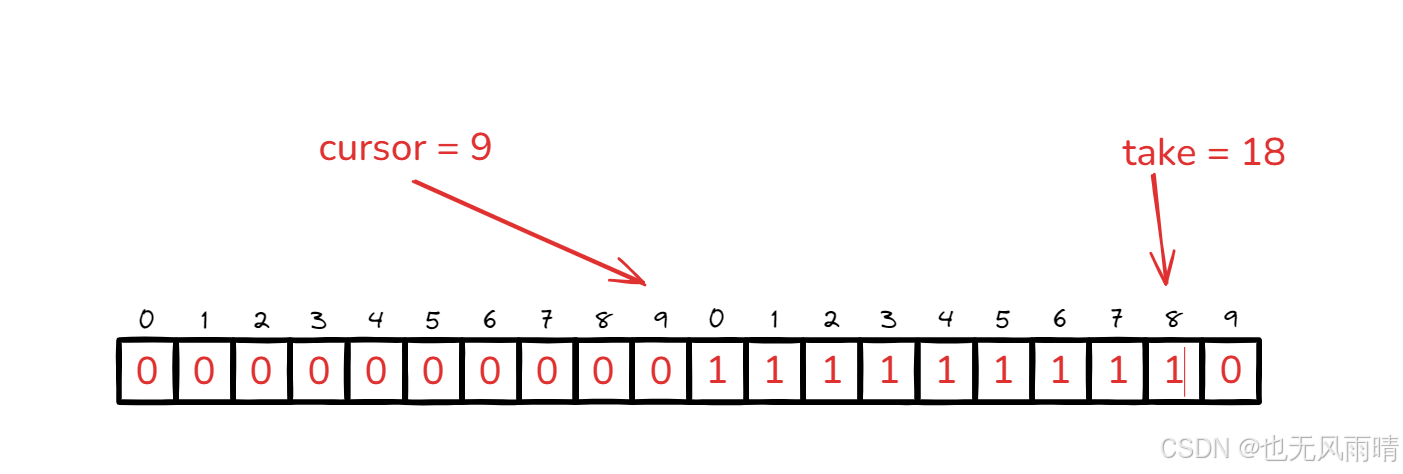
我们也可以来看下例子,由于干扰有点多,我们首先设置 seqBits = 1,这种情况下默认生成的 buffer 大小就是 15.

然后改下 take 方法,注释掉异步 padding 的代码,避免获取 ID 的时候达到阈值导致异步添加 ID 影响测试。
最后把 CachedUidGenerator 中的 bufferPaddingExecutor 设置为 public,方便直接引用。

我们编写测试类。
@Test
public void testSerialGenerateV2() throws InterruptedException {// Generate UIDfor (int i = 0; i <= 15; i++) {System.out.println(uidGenerator.getUID());}((CachedUidGenerator)uidGenerator).bufferPaddingExecutor.paddingBuffer();
}
首先启动的时候会把 buffer 填满,这时候 take 来到 15,cursor 还是 -1,然后获取 15 次 UID,这时候 cursor 也变成了 15,接下来再次去 paddingBuffer,当填充完 buffer 之后发现只能填充好下标 0~14,因为填充好 14 之后 tail 会来到 30,那么下一次填充 15 时发现 30 - 15 = bufferSize - 1,于是就执行拒绝策略了,我们来看下结果。
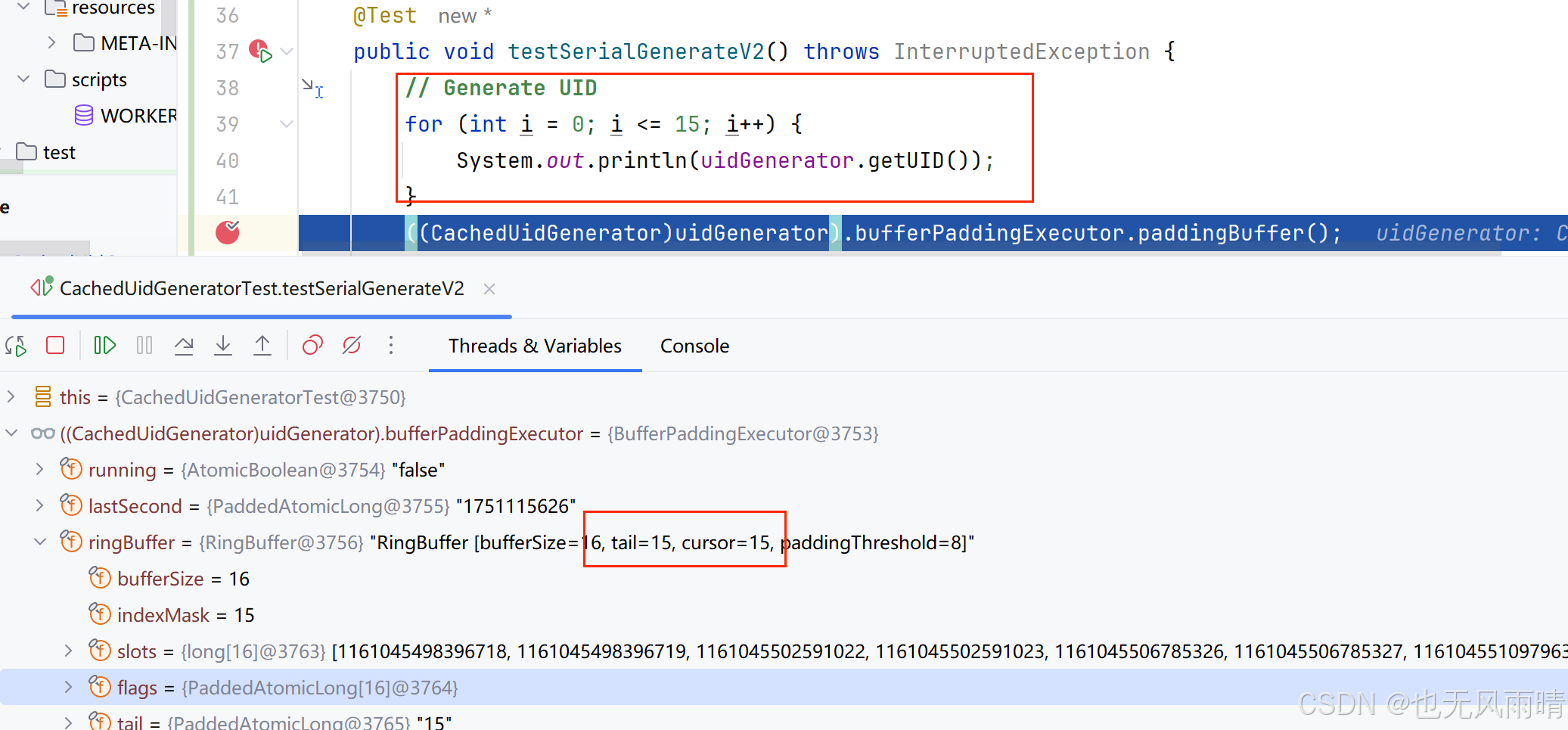
首先获取完 16 次 ID 之后 tail 和 cursor 都指向了 15,符合我们的想法,然后继续指向下面的代码。
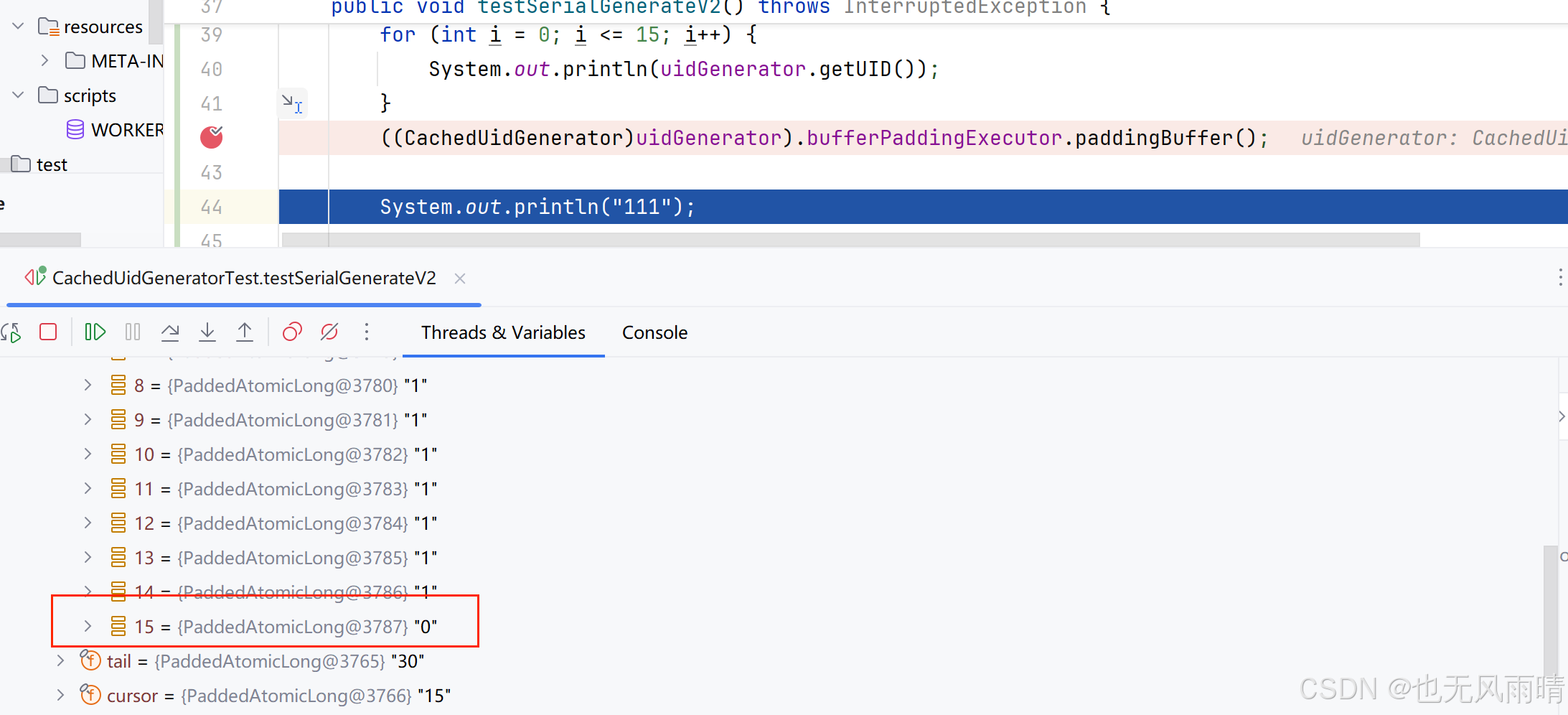
填充完之后可以发现 flag 数组最后一个下标没有填充好,也符合我们的猜测。
好了,回到 put 方法,继续往下看,接下来就是获取 nextTailIndex,然后判断这个位置是否可以放 ID,如果不可以,说明这个位置的 ID 还没有消耗,执行拒绝策略。
最后将 ID 设置到 tail + 1 的位置,更新 tail + 1 的位置状态为 CAN_TAKE_FLAG,表示这个 ID 可以被获取,然后更新 tail 指针到 tail + 1 位置,结束。
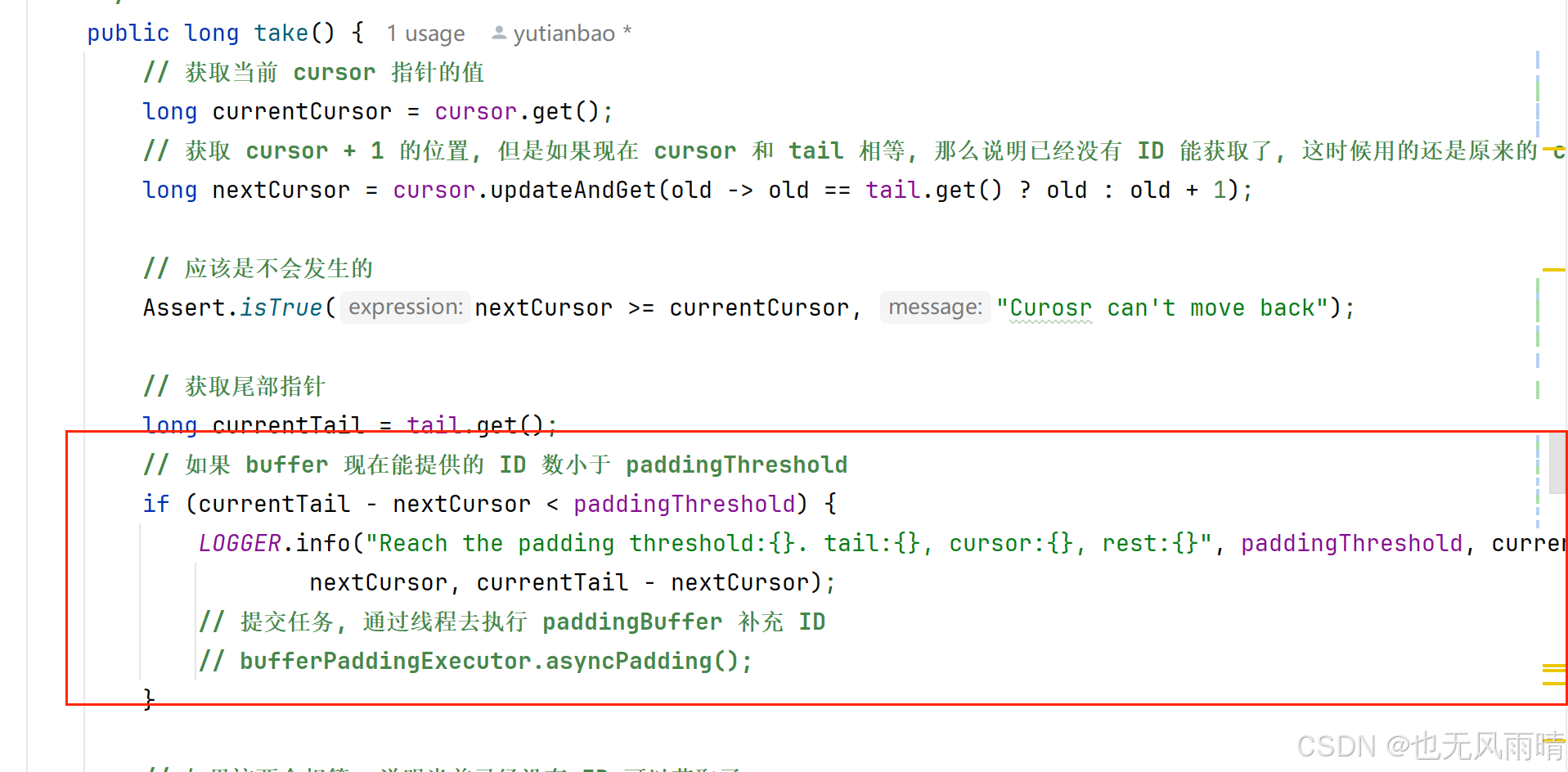
5.1.4 take 获取 UID
/*** Take an UID of the ring at the next cursor, this is a lock free operation by using atomic cursor<p>* * Before getting the UID, we also check whether reach the padding threshold, * the padding buffer operation will be triggered in another thread<br>* If there is no more available UID to be taken, the specified {@link RejectedTakeBufferHandler} will be applied<br>* * @return UID* @throws IllegalStateException if the cursor moved back*/
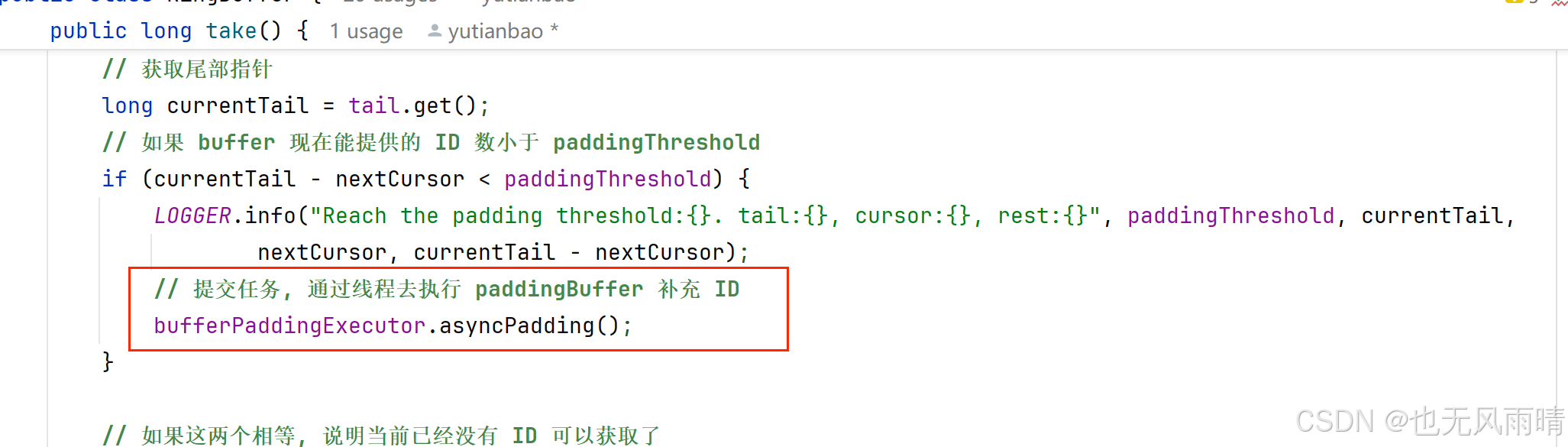
public long take() {// 获取当前 cursor 指针的值long currentCursor = cursor.get();// 获取 cursor + 1 的位置, 但是如果现在 cursor 和 tail 相等, 那么说明已经没有 ID 能获取了, 这时候用的还是原来的 currentCursorlong nextCursor = cursor.updateAndGet(old -> old == tail.get() ? old : old + 1);// 应该是不会发生的Assert.isTrue(nextCursor >= currentCursor, "Curosr can't move back");// 获取尾部指针long currentTail = tail.get();// 如果 buffer 现在能提供的 ID 数小于 paddingThresholdif (currentTail - nextCursor < paddingThreshold) {LOGGER.info("Reach the padding threshold:{}. tail:{}, cursor:{}, rest:{}", paddingThreshold, currentTail,nextCursor, currentTail - nextCursor);// 提交任务, 通过线程去执行 paddingBuffer 补充 ID// bufferPaddingExecutor.asyncPadding();}// 如果这两个相等, 说明当前已经没有 ID 可以获取了if (nextCursor == currentCursor) {// 拒绝策略抛出异常rejectedTakeHandler.rejectTakeBuffer(this);}// 1. 这里就是可以正常获取 ID, 首先还是一样先检查下这个 nextCursor 的状态是不是 CAN_TAKE_FLAG, 如果不是说明还不可以获取int nextCursorIndex = calSlotIndex(nextCursor);Assert.isTrue(flags[nextCursorIndex].get() == CAN_TAKE_FLAG, "Curosr not in can take status");// 2. 获取 ID// 3. 设置 nextCursorIndex 的状态为 CAN_PUT_FLAG, 意思是现在可以往里面放 ID 了long uid = slots[nextCursorIndex];flags[nextCursorIndex].set(CAN_PUT_FLAG);// Note that: Step 2,3 can not swap. If we set flag before get value of slot, the producer may overwrite the// slot with a new UID, and this may cause the consumer take the UID twice after walk a round the ringreturn uid;
}protected int calSlotIndex(long sequence) {return (int) (sequence & indexMask);
}
首先获取当前 cursor 的值,然后获取 cursor + 1 的位置,但是如果 cursor == tail,那么获取到的 nextCursor 就是 cursor 的值。
接下来获取尾部指针 tail,如果 buffer 现在能提供的 ID 数小于等于 paddingThreshold,这个能提供的 ID 数就是 currentTail - nextCursor + 1 的值,所以这里判断用的小于。符合这个条件就提交补充 ID 的任务到线程池去执行,这个任务就是调用 paddingBuffer 方法。
接下来判断如果 nextCursor == currentCursor,说明 cursor == tail,没有 ID 能获取,执行拒绝策略抛出异常,当然我们也可以自己定义拒绝策略,因为这个属性是有 set 方法的。
那如果能正常获取 ID,首先还是一样先检查下这个 nextCursor 的状态是不是 CAN_TAKE_FLAG,如果不是说明还不可以获取,如果是才可以获取,同时设置 nextCursorIndex 的状态为 CAN_PUT_FLAG,意思是现在可以往里面放 ID 了。
5.1.5 并发限制
上面 5.1.3 的 put 方法最后有一段注释,就是说 put 方法是加了 synchronized 的,因此 put 方法是可以防止并发添加 ID,而由于 take 方法没有加这个标记,因此 put 方法可以和 take 方法并行执行,但是由于 put 方法中当真正添加完之后才会通过 tail.incrementAndGet() 来设置 tail 指针到下一个位置,因此在 tail.incrementAndGet() 之前,take 方法获取到的 tail 还是之前的位置,这也就意味者在 cursor == tail 的时候 put 方法没有执行 tail.incrementAndGet() 之前,take 方法都是获取不到新增的 ID 的,确保了原子性。
5.2 BufferPaddingExecutor 源码分析
好了,上面最核心的源码已经说完了,下面来看下 BufferPaddingExecutor 的源码,经过上面的 put 和 take,相信大家也知道这是用来干什么的了,我们还是一样来看下里面的属性和方法。
5.2.1 属性构造器
下面来看下里面的属性。
- WORKER_NAME: RingBuffer-Padding-Worker,bufferPadExecutors 异步添加 ID 的线程名
- SCHEDULE_NAME: RingBuffer-Padding-Schedule,定时任务的线程名。
- DEFAULT_SCHEDULE_INTERVAL: 定时任务的执行时间间隔,就是 5 分钟。
- running: PaddingBuffer 方法是否正在调用, 也就是 Buffer 是否正在被其他线程补充,防止多个线程并发 padding 的。
- lastSecond: UidGenerator 通过借用未来时间来解决 sequence 天然存在的并发限制, 会提前根据 lastSecond 生成多秒的 ID 放到 Buffer 中等待获取。
- ringBuffer: 就是上面 5.1 小节的 RingBuffer,提供了核心的 put 方法以及 take 方法。
- uidProvider: UID 提供的方法接口, 用于获取某一秒的 ID 集合,这玩意是个函数式接口,创建 BufferPaddingExecutor 的时候将 nextIdsForOneSecond 方法复制给了这个属性。如果在后面的源码看到
uidProvider.provide,实际上就是调用的 nextIdsForOneSecond 方法。 - bufferPadExecutors: 执行 paddingBuffer 的线程池,线程大小是 CPU 核数 * 2,当 5.1.4 小节的 take 方法发现 ID 消耗超过一定阈值(默认 50%) 之后就用线程池异步去补充 ID。
- bufferPadSchedule: 定时任务线程池,定时执行 paddingBuffer 补充 ID,根据配置 scheduleInterval 决定要不要开启,如果想要开启就在创建 CachedUidGenerator 的时候设置 scheduleInterval 这个参数。
- scheduleInterval: 定时任务执行的间隔时间,这个参数是在 CachedUidGenerator 的 initRingBuffer 方法中设置的,配合上面 bufferPadSchedule 一起使用,这个后面源码会说。
下面再来看下构造器。
public BufferPaddingExecutor(RingBuffer ringBuffer, BufferedUidProvider uidProvider) {this(ringBuffer, uidProvider, true);
}public BufferPaddingExecutor(RingBuffer ringBuffer, BufferedUidProvider uidProvider, boolean usingSchedule) {// 设置状态为 falsethis.running = new AtomicBoolean(false);// 设置为当前时间this.lastSecond = new PaddedAtomicLong(TimeUnit.MILLISECONDS.toSeconds(System.currentTimeMillis()));// ringBuffer this.ringBuffer = ringBuffer;// uidProvider this.uidProvider = uidProvider;// 获取当前机器的核心线程数int cores = Runtime.getRuntime().availableProcessors();// 初始化 bufferPadExecutors,默认核心线程数是 CPU 核数 * 2bufferPadExecutors = Executors.newFixedThreadPool(cores * 2, new NamingThreadFactory(WORKER_NAME));// 如果需要初始化,这里是根据传入的 scheduleInterval != null 来决定的, scheduleInterval 是 CachedUidGenerator 的一个属性,也是可以配置的,如果用户配置了这个属性,就说明要开启定时任务,这里就会初始化if (usingSchedule) {bufferPadSchedule = Executors.newSingleThreadScheduledExecutor(new NamingThreadFactory(SCHEDULE_NAME));} else {bufferPadSchedule = null;}
}
5.2.2 paddingBuffer 填充 ID
paddingBuffer 就是往 5.1 的 RingBuffer 中补充 ID,下面来看下源码。
/*** Buffer 是一个环形数组, 里面有两个指针 tail 和 cursor, 获取 ID 从 cursor 开始, 而补充 ID 从 tail 开始补充*/
public void paddingBuffer() {LOGGER.info("Ready to padding buffer lastSecond:{}. {}", lastSecond.get(), ringBuffer);// 如果这个方法在运行中, 这里直接返回了, 说明其他线程在干这个事if (!running.compareAndSet(false, true)) {LOGGER.info("Padding buffer is still running. {}", ringBuffer);return;}// 从 tail 开始补充 ID 到 cursorboolean isFullRingBuffer = false;while (!isFullRingBuffer) {// uid-generator 使用了未来时间来解决 sequence 天然存在的并发限制, 也就是在启动的时候会生成 lastSecond + 1 下面的所有 ID// 添加到 Buffer 中, 这样请求过来就可以直接获取了List<Long> uidList = uidProvider.provide(lastSecond.incrementAndGet());for (Long uid : uidList) {// 遍历所有 ID, 添加到 Buffer 中, 如果满了就添加失败, 退出isFullRingBuffer = !ringBuffer.put(uid);if (isFullRingBuffer) {break;}}}// 补充完 Buffer 之后设置标记为 falserunning.compareAndSet(true, false);LOGGER.info("End to padding buffer lastSecond:{}. {}", lastSecond.get(), ringBuffer);
}
可以看到在正式补充 ID 之前会先设置下 running 属性,这个属性是一个原子类,如果发现这时候已经有其他线程在填充 ID,就直接返回。
可以看到下面的 while 方法填充 ID 是一直填充到 ringBuffer.put 返回 false,那么什么情况下会返回 false 呢?可以看 5.1.3 小节,简单来说就是如果发现某一个下标的 ID 还没有被获取又或者填充 ID 数量已经达到一定程度了,就会返回 false,然后 while 循环就会退出,由于 put 方法在前面 5.1.3 小节已经说过了,这里我们也不多说,主要来看下 provide 方法。
5.2.3 uidProvider.provide 获取当前时间下的 id 集合(秒)
我们前面说过,uidProvider 是一个 函数式接口,类型是 BufferedUidProvider,这个属性的赋值是在 CachedUidGenerator 的构造器中赋值的,我们可以看下赋值的过程。

可以看到这里赋值就是将 nextIdsForOneSecond 方法赋值给了 uidProvider,所以我们要看 uidProvider.provide 方法,就要看 nextIdsForOneSecond 是怎么实现的。
protected List<Long> nextIdsForOneSecond(long currentSecond) {// 获取最大序号 + 1, 假设序号范围是 0~1023(10 位),那么这里的 listSize 就是 1024int listSize = (int) bitsAllocator.getMaxSequence() + 1;List<Long> uidList = new ArrayList<>(listSize);// 使用 bitsAllocator 获取第一个 id,就是序号为 0 的 idlong firstSeqUid = bitsAllocator.allocate(currentSecond - epochSeconds, workerId, 0L);// 从 0 开始遍历, 由于都是这一秒内的 id,所以只有序号变动for (int offset = 0; offset < listSize; offset++) {uidList.add(firstSeqUid + offset);}return uidList;
}
这个方法的实现也比较简单,首先获取最大序号 + 1,假设序号范围是 0~1023(10 位),那么这里的 listSize 就是 1024。然后使用 bitsAllocator 获取第一个 id,就是序号为 0 的 id,这个 bitsAllocator 在前面 4.2 小节说过了,这里 allocate 方法其实就是雪花算法将 timestamp、workerID、sequence 拼接出序号为 0 的 id。
为什么要先获取序号为 0 的 id 呢,因为这个方法是获取当前 1s 内的所有序号,获取出序号为 0 的 id 之后,我们就可以直接从 0 开始遍历,通过 firstSeqUid + offset 算出这一秒内的所有 id 了,这样有一个好处就是不需要再频繁调用 allocate。
5.2.4 什么时候执行 paddingBuffer
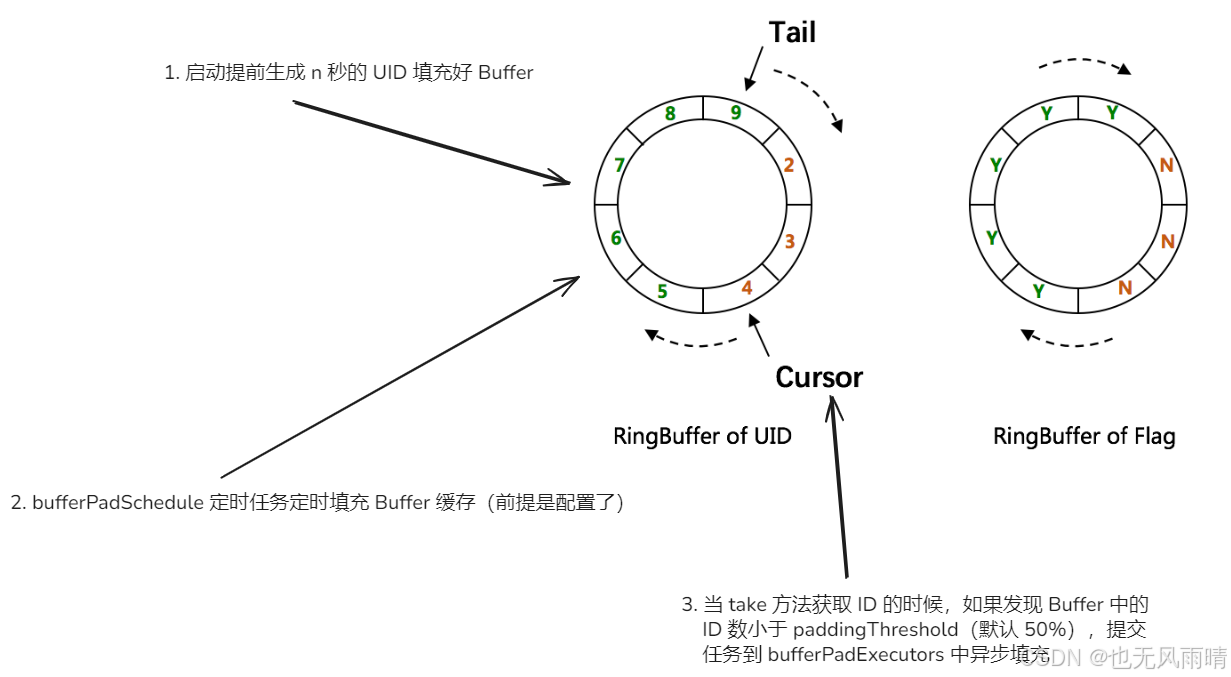
不知道大家还记不记得这张图,这是上一篇文章写的,可以看到往 UID-Buffer 填充的时机有三个:
- 启动提前生成 n 秒的 UID 填充好 Buffer
- bufferPadSchedule 定时任务定时填充 Buffer 缓存(前提是配置了)
- 当 take 方法获取 ID 的时候,如果发现 Buffer 中的 ID 数小于 paddingThreshold(默认 50%),提交任务到 bufferPadExecutors 中异步填充
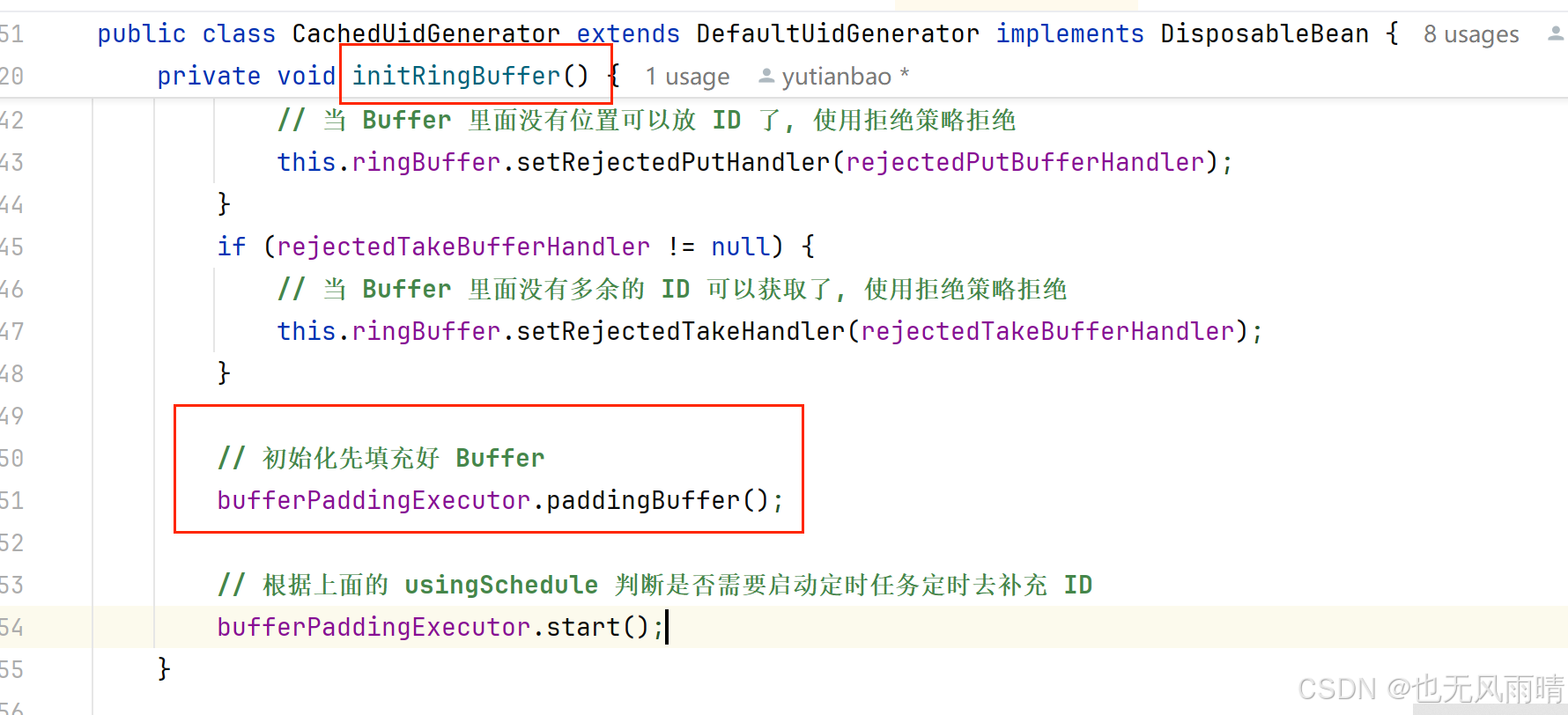
这三个时机都是调用的 paddingBuffer 来填充 UID,下面我们就看下这三个调用的源码。首先是初始化 CachedUidGenerator 的时候在 initRingBuffer 中会调用往 UID-Buffer 里面填充好 UID。
然后就是定时任务,这个在 5.2.1 小结的构造器中也说过了,如果 CachedUidGenerator 里面的 scheduleInterval 属性我们有配置,那么就会在创建 BufferPaddingExecutor 的时候创建出 bufferPadSchedule 来。

上面的 usingSchedule 就是 scheduleInterval != null 的值,那么这个 usingSchedule 什么时候启动定时任务呢?还是一样在 initRingBuffer 中启动的。
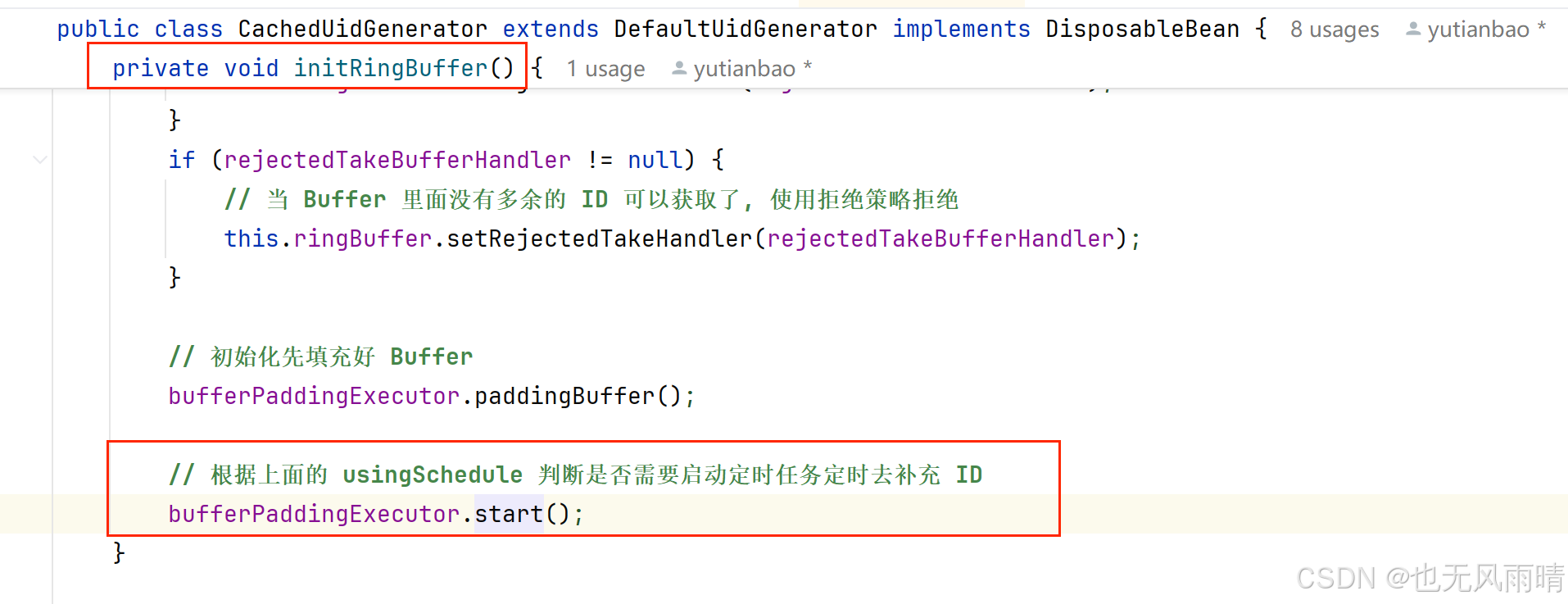
/*** 启动定时任务*/
public void start() {if (bufferPadSchedule != null) {bufferPadSchedule.scheduleWithFixedDelay(() -> paddingBuffer(), scheduleInterval, scheduleInterval, TimeUnit.SECONDS);}
}
最后就是第三点,当 take 方法获取 ID 的时候,如果发现 Buffer 中的 ID 数小于 paddingThreshold(默认 50%),提交任务到 bufferPadExecutors 中异步填充,大家也可以看 5.1.4 小节的源码介绍。
5.3 afterPropertiesSet 方法
现在来看下 CachedUidGenerator 的 afterPropertiesSet 方法。
@Override
public void afterPropertiesSet() throws Exception {// 初始化 workerID 和 ID 分配器 BitsAllocatorsuper.afterPropertiesSet();// 初始化 RingBuffer 和 RingBufferPaddingExecutorthis.initRingBuffer();LOGGER.info("Initialized RingBuffer successfully.");
}
可以看到首先调用的就是 DefaultUidGenerator 的 afterPropertiesSet 方法,这个方法在 4.2 小节有讲解过,可以去看下。
然后就是 initRingBuffer 方法,这个方法就是初始化 RingBuffer 的。
/*** Initialize RingBuffer & RingBufferPaddingExecutor*/
private void initRingBuffer() {// initialize RingBuffer// 获取 bufferSize, 默认是最大序列号 * 2^3 次方, 也就是说假设序列号是 8192, 那么创建出来的 Buffer 大小就是 8192 * 8 = 65536int bufferSize = ((int) bitsAllocator.getMaxSequence() + 1) << boostPower;// 创建 ringBuffer, 设置 Buffer 大小以及填充 ID 的阈值this.ringBuffer = new RingBuffer(bufferSize, paddingFactor);LOGGER.info("Initialized ring buffer size:{}, paddingFactor:{}", bufferSize, paddingFactor);// initialize RingBufferPaddingExecutor// 是否初始化定时任务定时补充 RingBuffer 里面的 IDboolean usingSchedule = (scheduleInterval != null);this.bufferPaddingExecutor = new BufferPaddingExecutor(ringBuffer, this::nextIdsForOneSecond, usingSchedule);if (usingSchedule) {// 设置定时时间bufferPaddingExecutor.setScheduleInterval(scheduleInterval);}LOGGER.info("Initialized BufferPaddingExecutor. Using schdule:{}, interval:{}", usingSchedule, scheduleInterval);// 设置拒绝策略this.ringBuffer.setBufferPaddingExecutor(bufferPaddingExecutor);if (rejectedPutBufferHandler != null) {// 当 Buffer 里面没有位置可以放 ID 了, 使用拒绝策略拒绝this.ringBuffer.setRejectedPutHandler(rejectedPutBufferHandler);}if (rejectedTakeBufferHandler != null) {// 当 Buffer 里面没有多余的 ID 可以获取了, 使用拒绝策略拒绝this.ringBuffer.setRejectedTakeHandler(rejectedTakeBufferHandler);}// 初始化先填充好 BufferbufferPaddingExecutor.paddingBuffer();// 根据上面的 usingSchedule 判断是否需要启动定时任务定时去补充 IDbufferPaddingExecutor.start();
}
首先就是计算出 bufferSize,计算的方法是 ((int) bitsAllocator.getMaxSequence() + 1) << boostPower,比如我们设置了序列号位数是 13,那么这里算出来的就是(8191 + 1)<< 3 = 65536。这个 boostPower 也可以通过 xml 文件去设置。
接下来创建出 RingBuffer,传入的阈值是用的默认值,也就是 50,比如 bufferSize 是 65536,那么算出来的填充阈值就是 65536 * 50 / 100 = 32768。
然后判断有没有配置了 scheduleInterval 这个属性,如果配置了,就设置定时任务执行的时间间隔到 BufferPaddingExecutor 中,后续将会启动定时任务定时填充 Buffer。
下面继续设置拒绝策略,分别是 take 和 put 方法的拒绝策略,我们可以看下这两个策略的实现,这两个属性都是在 RingBuffer 中的,大家可以看下 5.1.1 小节的介绍。

我们分别来看下这两个方法,还是一样的这两个拒绝策略都是函数式接口,可以直接将方法赋值过去。
// put 方法的拒绝策略,打印日志
protected void discardPutBuffer(RingBuffer ringBuffer, long uid) {LOGGER.warn("Rejected putting buffer for uid:{}. {}", uid, ringBuffer);
}// take 方法的拒绝策略,抛出异常
protected void exceptionRejectedTakeBuffer(RingBuffer ringBuffer) {LOGGER.warn("Rejected take buffer. {}", ringBuffer);throw new RuntimeException("Rejected take buffer. " + ringBuffer);
}
回到 initRingBuffer 的源码,最后就是通过 paddingBuffer 提前填充好 Buffer,然后就是判断是否要启动定时任务去定时填充 RingBuffer。
6. 小结
好了,到这里我们就看完了 uid-generator 的核心源码,如果你是想要看核心部分直接看 5.1 小节的就行,主要就是 put 和 take,不过除了这两个核心方法,其他的一些 padding 的时机也可以去学习下,了解 uid-generator 的整体思想。
如有错误,欢迎指出!!!