苍穹外卖|项目日记(完工总结)
前言: 大概16天完工, 我会深刻的总结, 作为练手的第一个项目

一.项目介绍:
1.1业务板块介绍:
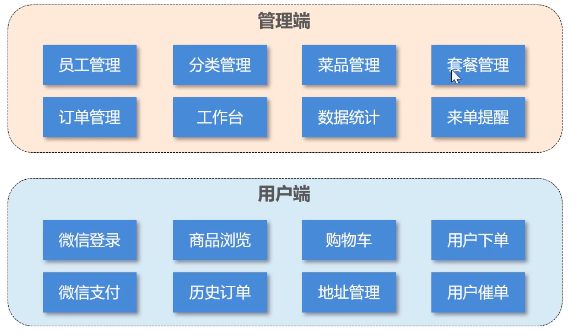
1.2 技术选型
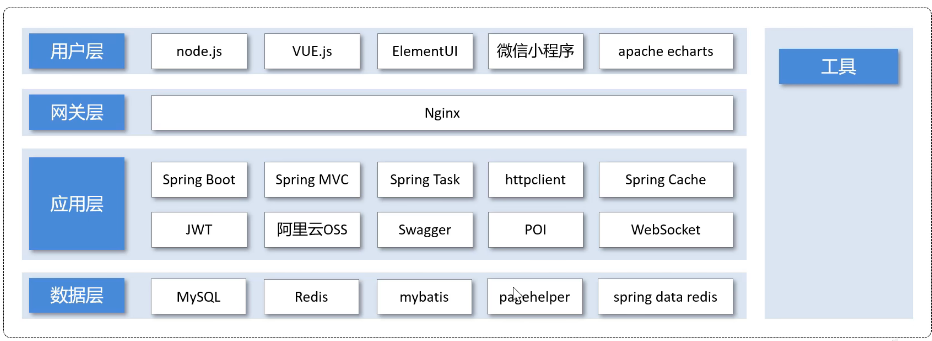
网关层(Nginx) :
Nginx是一款高性能的开源Web服务器、反向代理服务器、负载均衡器及HTTP缓存工具, 在项目中我们可以使用Nginx的负载均衡合理请求到多台服务器. 减少后端服务器的压力.
应用层:
SpringBoot:
基于spring的开源框架, 简化各项配置, 使得开发人员专注于业务功能的实现.
Spring MVC:
基于MVC(Model-View-Controller)模式的Web应用程序开发框架. 它提供了一种结构清晰, 模块化的方式来构建可扩展的Web应用程序.
Spring Task:
定时任务依赖, 完成相关配置, 后端可以定时完成任务
Httpclient:
HTTP开源的通信库, 使得后端可以发送和处理后端请求, 常用于后端请求各种接口时用到.
Spring Cache:
缓存依赖, 把数据存储到缓存中, 如果前端再次请求相同数据, 使得后端可以从缓存中拿数据, 减少了对数据库的IO操作, 降低了后端服务器的压力.
JWT:
令牌技术, 校验用户身份.
阿里云OSS:
第三方云存储技术, 后端调用阿里云OSS来存储菜品等图片.
Swagger:
开源框架, 实现设计, 构建和测试RESTful API的开源框架, 但在本项目中, 我们使用的时Swagger的优化版本Knife4j, 它基于注解的方式注解在启动类上, 在后端启动之后, 在网页输入localhost8080/doc.html就可以打开相关接口测试界面, 在内网穿透中, 可以短暂获得公网ip进行作为访问地址.
POI:
读取和写入Microsoft Office格式文件, 如Word文档, Excel电子表格和PowerPoint演示文稿.
WebSocket:
一种通信协议, 允许客户端于服务器进行持久化连接, 并且区别于请求-响应模式, WebSocket协议实现了客户端于服务器的双向通信
数据层:
MySQL:
关系型存储系统, 基于表的形式对数据进行存储, 直接存储数据到磁盘当中
Redis:
键值性存储系统, 基于键值对的形式对数据进行存储, 数据会被存储到缓存当中
Mybatis:
开源的持久层框架, 简化了java于关系型数据之间的操作
pagehelper:
分页框架, 简化分页查询中的分页操作
spring data redis:
spring框架提供的与Redis数据库进行交互的模块, 简化在java中使用Redis的操作步骤
工具:
Git:
分布式文件管理工具, 追踪管理文件变化, 适用于多人开发
maven:
开源的项目管理工具, 用于构建和管理java项目. 它提供了一种标准化的项目结构和构建过程, 使得开发人员可以更容易地管理项目依赖, 构建项目, 运行测试和部署应用程序
Junit:
Java开源单元测试框架, 可以对指定方法进行单元测试, 简化开发人员测试流程
apifox:
接口测试工具, 可以便捷地代替前端对后端发送各种请求, 测试接口运行效果.
后端初始环境介绍:

sky-common层:
| 包名 | 作用 |
| constant | 封装各种常量类, 代替硬编码, 降低耦合 |
| context | 封装基础上下文类 |
| enumeration | 封装各种枚举类 |
| exception | 封装各种异常类 |
| json | 处理json转换的类 |
| properties | 存放Spring boot的相关配置的类 |
| result | 封装各种返回结果的类 |
| utils | 封装各种工具类 |
sky-pojo层:
| 包名 | 作用 |
| dto | 提供实体, 封装前端发送给后端的数据, 方便后端处理 |
| entity | 提供各种实体类, 例如员工类 |
| vo | 提供实体, 封装后端发送给前端的数据, 方便前端处理 |
sky-server层:
| 包名 | 作用 |
| annotation | 存放自定义注解 |
| aspect | 存放各种切面 |
| config | 存放各种配置类 |
| controller | 存放各种处理前端请求的方法, 向下还细分为管理端, 用户端, 通用端 |
| handler | 封装和处理异步任务, 事件或消息 |
| interceptor | 存放拦截器, 按照指定条件拦截前端请求 |
| mapper | 存放mapper, 是Java与MySQL直接进行交互的包 |
| service | 存放各种业务功能的具体实现逻辑方法 |
| Task | 任务类, 存放各种任务 |
| websocket | 封装websocket, 简化websocket的使用 |
数据库各表的作用:
| 表名 | 作用描述 |
|---|---|
| address_book | 存放用户下单地址 |
| category | 存放菜品类型 |
| dish | 存放菜品基础信息 |
| dish_flavor | 存放菜品口味选项(如辣度、甜度等) |
| employee | 存放管理端员工信息 |
| order_detail | 存放各个订单的明细(菜品、数量等) |
| orders | 存放订单主信息(订单号、时间等) |
| setmeal | 存放套餐信息 |
| setmeal_dish | 存放套餐内包含的具体菜品 |
| shopping_cart | 购物车数据,用于前端购物车回显 |
| user | 用户表,存放用户账号密码等基本信息 |
本项目的数据表在处理逻辑关系的时候,采用 使用逻辑外键,舍弃物理外键的形式。也就是说:我们的表之间的关系不通过物理外键的形式来进行关联,而是在代码层面使用代码逻辑的方式进行关联。
二.项目第一阶段技术:
1.JWT令牌
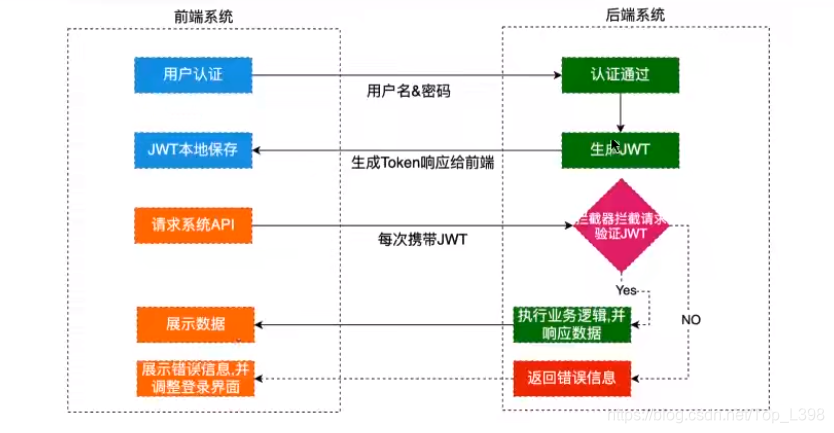
JWT令牌由标头, 载荷和签名组成, 前两个用Base64进行编码, 而签名是对编码后的标头和载荷进行加密.一般有对称加密和非对称加密.
对称加密:
- 使用同一个密钥进行加密和解密
- 发送方和接收方必须共享同一个密钥
- 例如:AES、DES、3DES、Blowfish、RC4
非对称加密:
- 使用一对密钥:公钥(Public Key)和私钥(Private Key)
- 公钥用于加密,私钥用于解密(或私钥签名,公钥验证)
- 例如:RSA、ECC、DSA、ElGamal
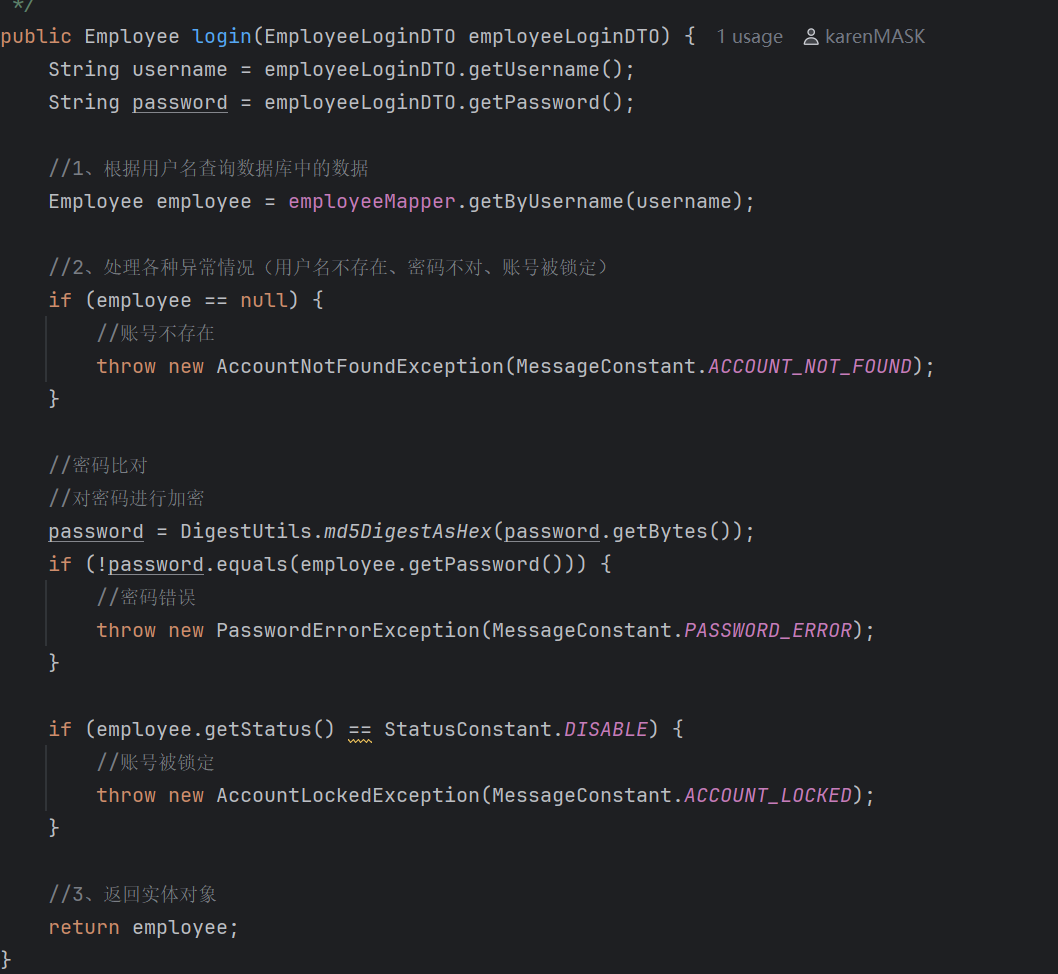
验证登录的代码:
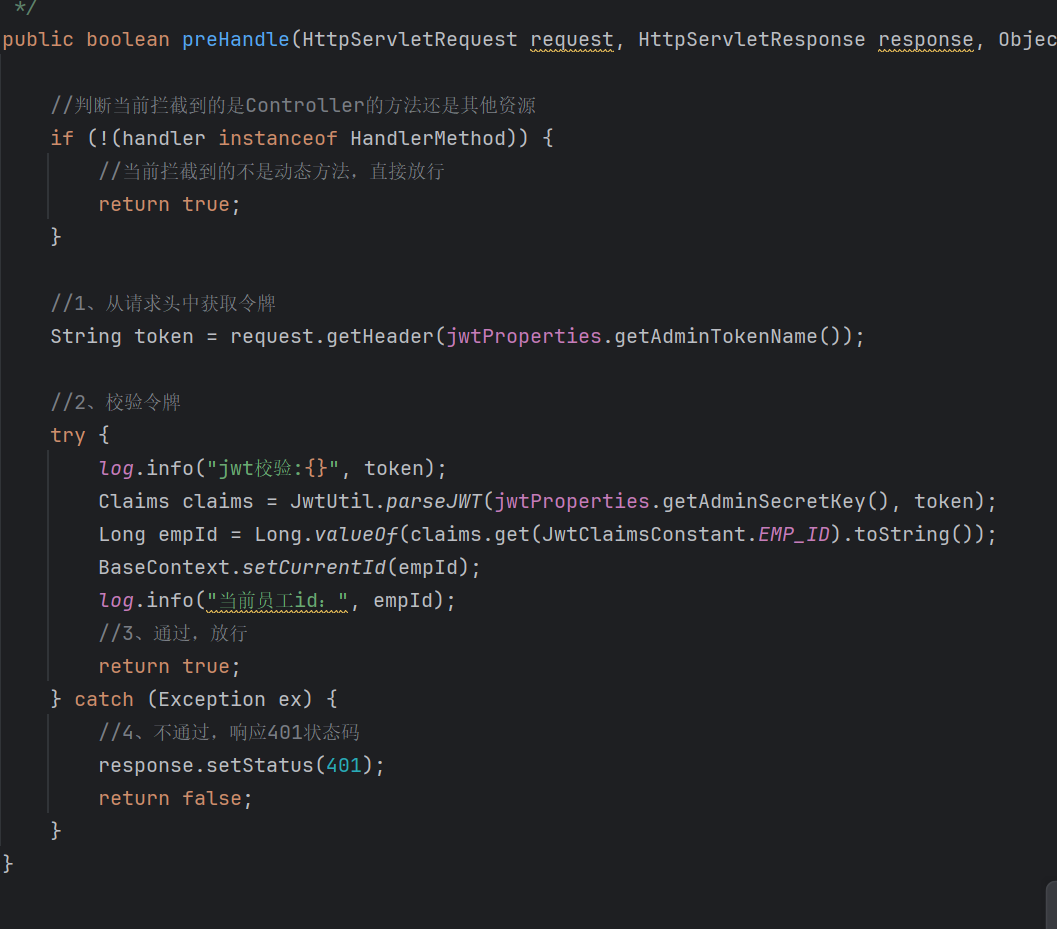
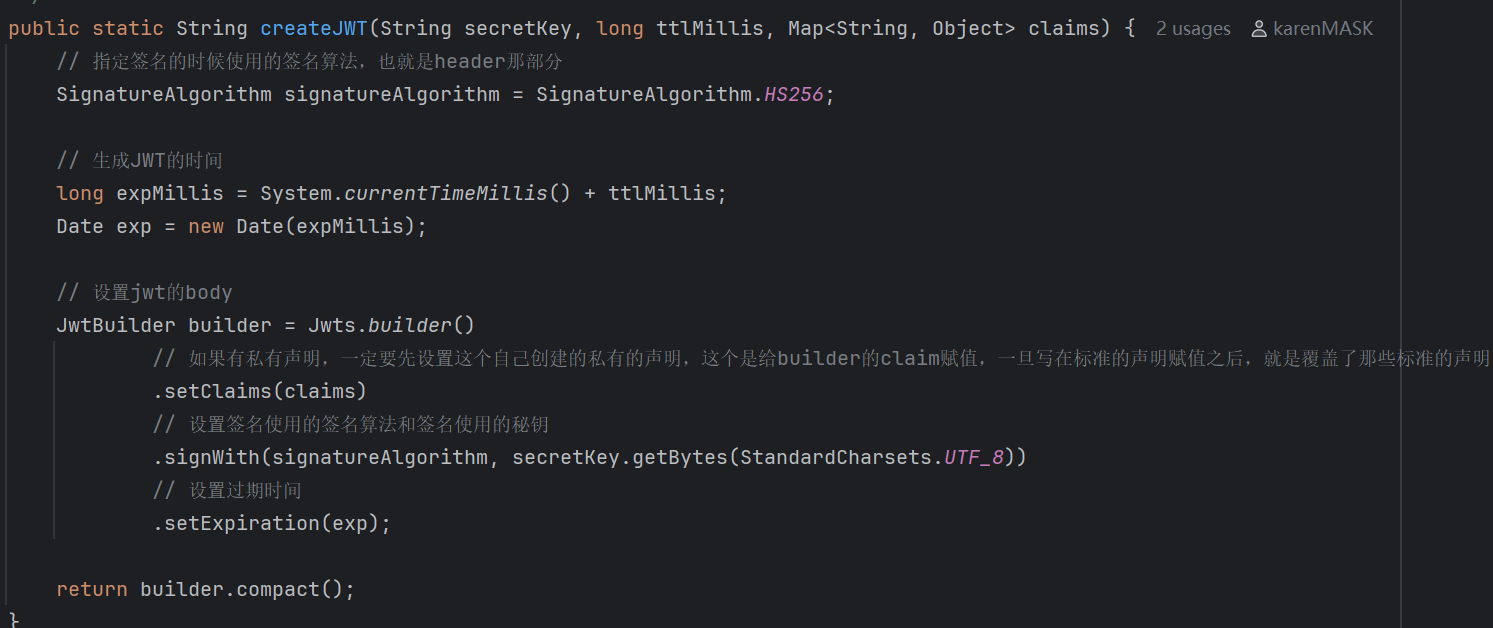
自定义JWT工具包内部:
jwt加密:
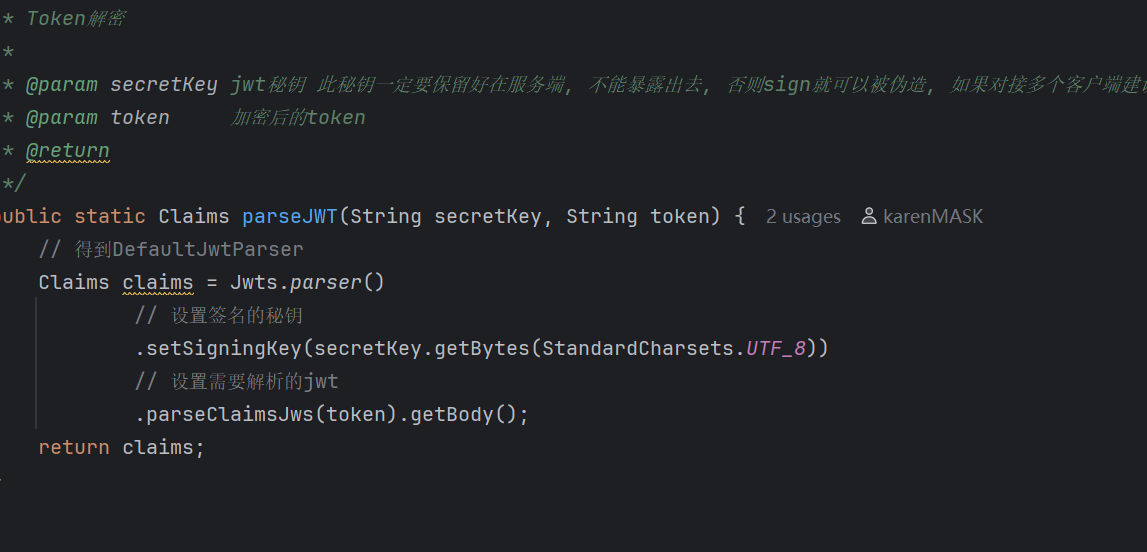
jwt解密:
2.Swagger前后端联调
Knife4j是Swagger的一个增强工具,是基于Swagger构建的一款功能强大的文档工具。它提供了一系列注解,用于增强对API文档的描述和可视化展示。
以下是一些常用的Knife4j注解介绍:
@Api:用于对Controller类进行说明和描述,可以指定Controller的名称、描述、标签等信息。
@ApiOperation:用于对Controller中的方法进行说明和描述,可以指定方法的名称、描述、请求方法(GET、POST等)等信息。
@ApiImplicitParam:用于对方法的参数进行说明和描述,可以指定参数的名称、描述、数据类型、是否必须等信息。
@ApiModel:用于对请求或响应的数据模型进行说明和描述,可以指定模型的名称、描述、属性等信息。
@ApiModelProperty:用于对模型的属性进行说明和描述,可以指定属性的名称、描述、数据类型、示例值等信息。
@ApiParam:用于对方法的参数进行说明和描述,可以指定参数的名称、描述、数据类型、是否必须等信息。
这些注解可以在Spring Boot项目中与Swagger集成使用,通过使用这些注解,可以在生成的API文档中提供更详尽的说明和描述。同时,Knife4j还提供了一些自定义配置。
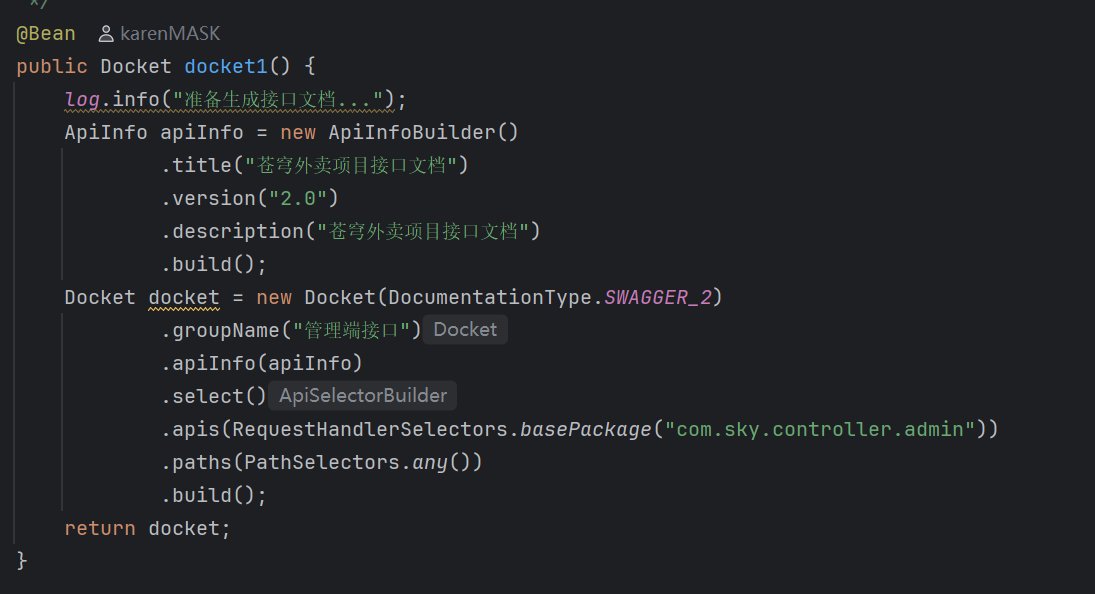
项目中在webMvcConfiguration配置Knife4j:
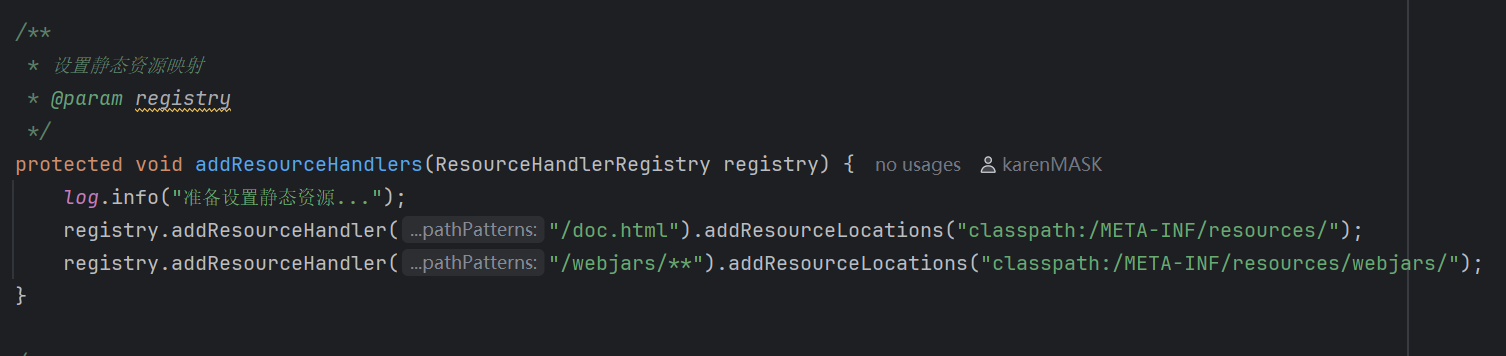
再设置静态资源映射:
3.MD5加密
基本特性
- 输出长度:128位(16字节),通常表示为32个十六进制字符
- 输入长度:理论上无限制(实际实现有上限)
- 确定性:相同输入总是产生相同输出
- 不可逆性:从哈希值无法反向推导原始数据(单向函数)
而基于MD5的特性,我们在验证用户密码是否正确的时候,思路是:把用户输入的密码与正确密码加密后得到的MD5字符串进行比较,如果相同则说明得到的是正确的密码。
三. 项目第二阶段技术
1.ThreadLocal
ThreadLocal是Java中一个非常有用的线程局部变量工具类,它提供了线程局部变量,每个线程都可以通过ThreadLocal保存和获取自己独立的变量副本,而不会与其他线程的副本冲突。
基本概念
ThreadLocal的主要作用是:
- 为每个线程提供独立的变量副本
- 保证线程安全(因为每个线程操作的都是自己的副本)
- 减少线程间共享变量的复杂度
使用ThreadLocal的主要步骤如下:
1.创建ThreadLocal对象:可以通过ThreadLocal的静态方法ThreadLocal.withInitial()来创建ThreadLocal对象,并初始化变量的初始值。
2.设置变量值:通过ThreadLocal对象的set()方法可以设置当前线程的变量副本的值。
3.获取变量值:通过ThreadLocal对象的get()方法可以获取当前线程的变量副本的值。
4.清除变量值:通过ThreadLocal对象的remove()方法可以清除当前线程的变量副本的值,释放资源。
在本项目中,它的应用主要是在token解析的时候,存储这时员工的ID,方便后续其他包对员工ID的调用。
而我们把Thread的所有的方法都封装到了包中,放在了Context类下:
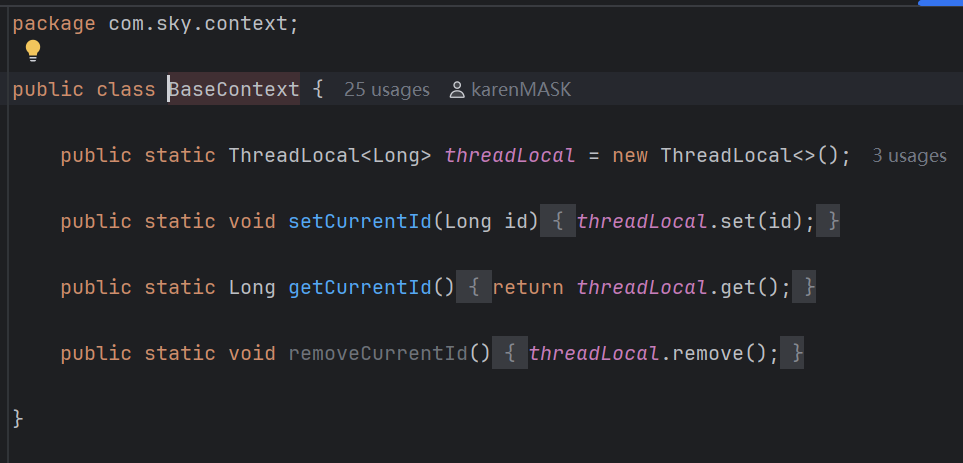
通过这个包,我们也可以更好的理解Context包的作用:存放可以操作和访问程序上下文的各种包和接口。
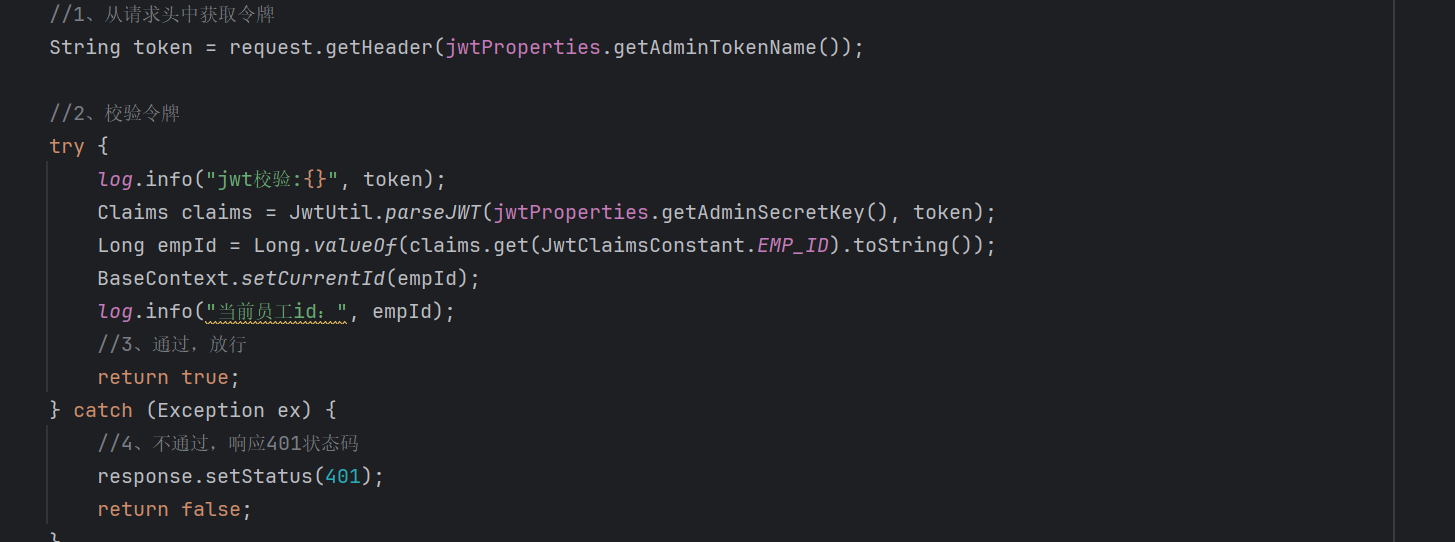
我们看一下在代码中我们是怎么实现的:
在拦截器拦截到请求并且下发令牌的时候,就利用ThreadLocal拿到当前登录员工的ID
2.基于消息转换器对时间进行格式化
我们无法控制前端给我们传递过来的时间参数的格式,因此我们要对前端传递过来的时间参数进行格式化。
而进行格式化,如果时间参数少,我们可以使用 @JsonFormat(pattern="yyyy-MM-dd HH:mm:ss")来对某个属性指定格式:
但是如果时间参数过多,我们再一个一个标注就太麻烦了。因此我们选择在Spirng MVC中再扩展一个消息转换器,统一对前端的发送给后端的时间数据进行处理:
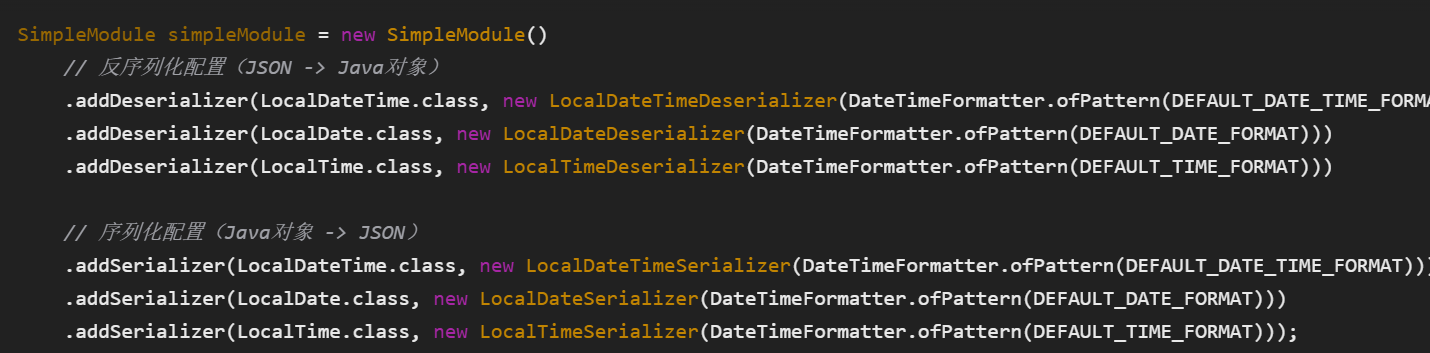
/*** 扩展SpringMVC框架的消息转换器* @param converters*/protected void extendMessageConverters(List<HttpMessageConverter<?>> converters) {log.info("扩展消息转换器...");//创建 一个消息转换器...//这是Spring专门用于JSON转换的组件//默认已经能处理基本数据类型和对象MappingJackson2HttpMessageConverter converter = new MappingJackson2HttpMessageConverter();//需要为消息转换器设置一个对象转换器, 对象转换器可以将java对象序列化为json数据//JacksonObjectMapper是项目中自定义的时间处理器, 配备了正确的时区,统一的时间格式converter.setObjectMapper(new JacksonObjectMapper());//将自己的消息转换器加入容器中converters.add(0,converter);}我们先创建一个用来处理Json格式的消息转换器,之后我们再为这个消息转换器指定自定义的对象转换器(JacksonObjectMapper)。而这个对象转换器的作用是指定序列化和反序列化的格式。我们可以看一下指定的这个JacksonObjectMapper。

为Java 8的日期时间类型设置统一的序列化(对象转JSON)和反序列化(JSON转对象)格式
3.Pagehelper分页查询
PageHelper是基于java的一个开源框架,用于在MyBatis等持久层框架中方便地进行分页查询操作。它提供了一组简单易用的API和拦截器机制,可以帮助开发者快速集成和使用分页功能。
PageHelper的主要功能包括:
1.分页查询支持:PageHelper提供了直接在SQL语句中添加分页相关的信息,如页码、每页记录数等,从而实现分页查询功能。
2.参数解析和设置:PageHelper可以解析传入的查询参数,并自动设置分页的相关参数,无需手动计算和设置。
3.SQL拦截器:PageHelper通过自定义的SQL拦截器拦截和处理查询SQL,自动添加分页的SQL语句,实现分页查询。
4.排序支持:PageHelper还提供了对排序的支持,可以在分页查询中指定排序字段和排序方式。
5.分页信息返回:PageHelper会将查询结果封装在一个Page对象中,包含了分页的相关信息,如总记录数、总页数等。
6.PageHelper的底层原理是拦截,拦截需要进行分页查询的SQL请求,读取用户传入参数,自主构造分页SQL语句。
4.基于注解和AOP的公共字段填充:
在项目中前期, 我们的项目会涉及到大量数据库表操作, 而这些数据库中有一些需要重复填充的字段, 如创建人, 创建时间, 修改人, 修改时间.对这一部分字段的填充代码相同。这些填充部分的代码分布在整个项目的四处,不涉及核心功能,却影响了多个模块. 为了代码重用和模块化, 我们可以使用AOP来解决问题.
聚焦到项目:我们可以通过注解的方式来标记项目, 创建切面类, 对被指定主键标记的项目进行切面, 增强其功能, 实现公共字段的填充.
让我们基于整个项目了解一下基于AOP思想的注解开发:
首先先创建一个注解: AutoFill
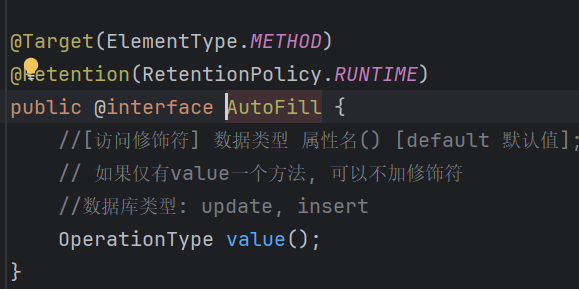
而这个注解的作用很明显:使用在mapper层,标记对数据库的操作类型。这里是因为公共字段的填充只有修改和新增这两个类业务。我们需要准确的拦截这两个数据库层面的操作,在切面中完成对公共字段的填充。
其次完成切面的代码:
先通过切入点表达式,拦截到带有AutoFill的注解,之后再写通知,本次我们采用的是前置通知。
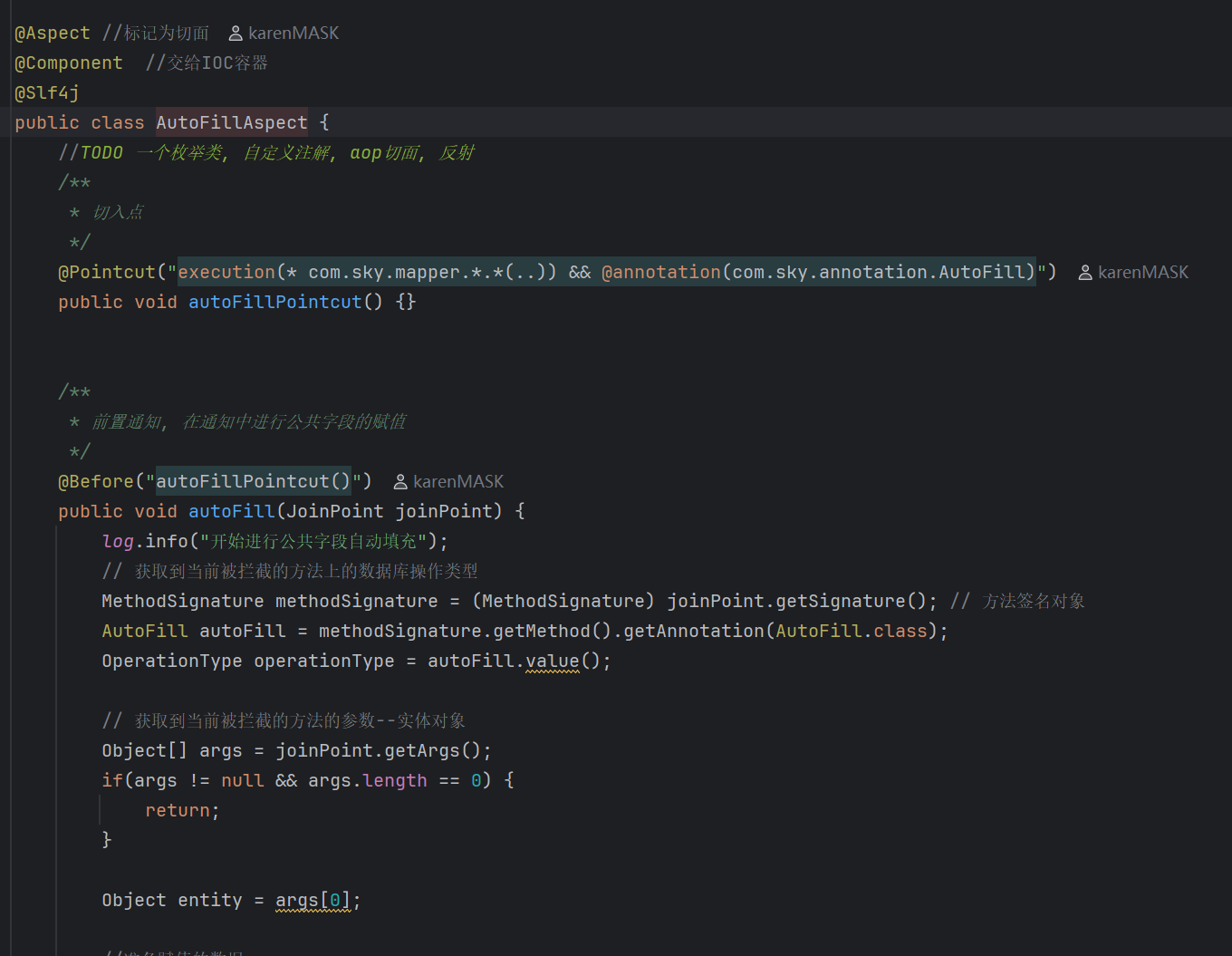
在上文我们已经拿到了目标方法的第一个参数(我们人为约定把需要填充的字段放在第一个字段上,主要是为了简化操作,不然我们就需要通过反射拿到所有的参数,再逐个判断哪一个是需要进进行填充的字段)
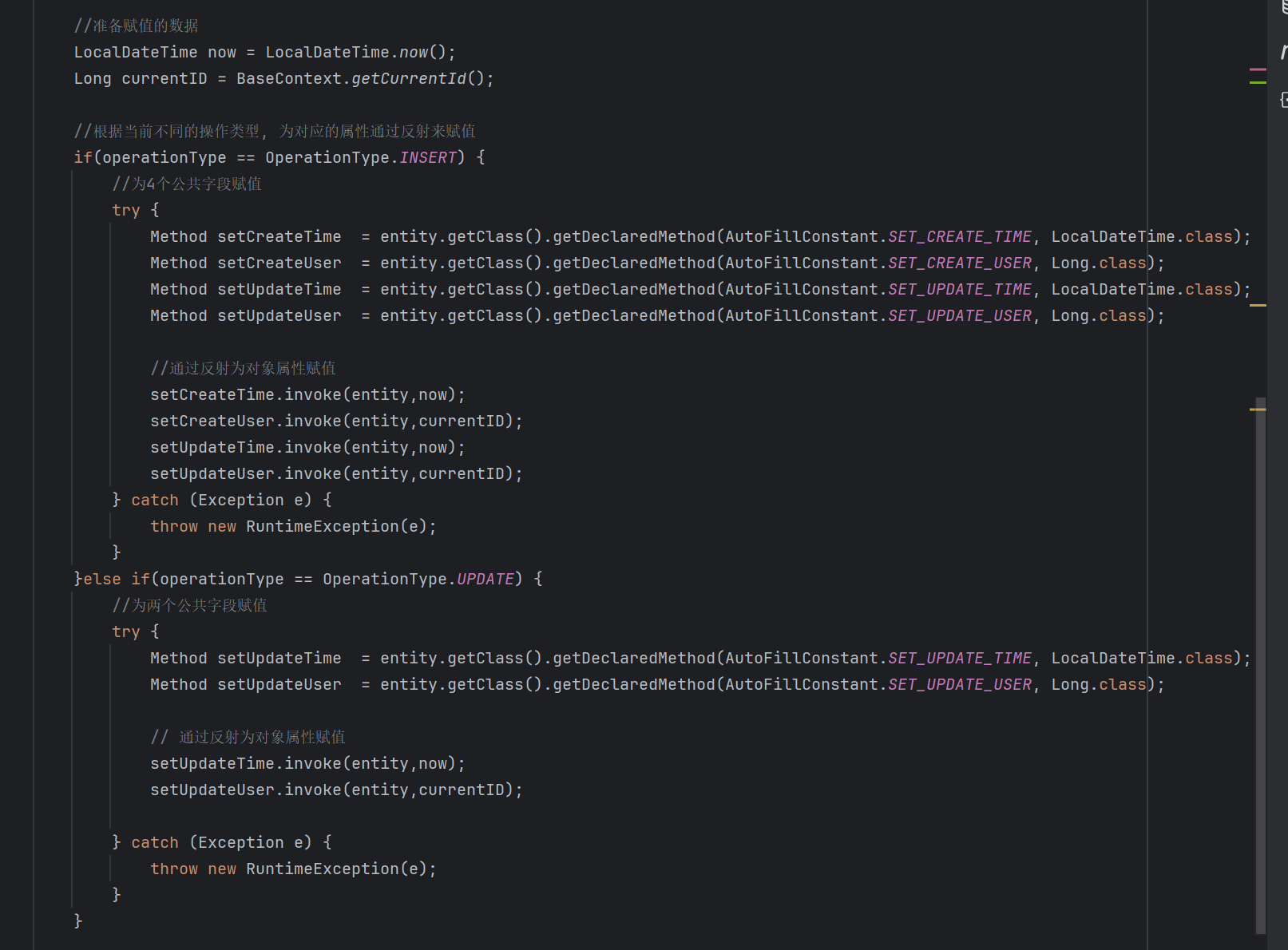
通过反射的思想进行字段赋值。
这样下来,我们就实现了公共字段的自动填充,我们回顾整个代码逻辑,可以把整个过程总结为两步
- 自定义注解(标记类型),通过注解快速标记目标方法
- 完成切面的逻辑代码,通过切入点表达式快速捕捉需要进行切入的方法,对这些方法进行处理
5.阿里云OSS云存储服务:
这是阿里巴巴为我们提供了一项云存储服务。我们通过这项技术来存储菜品,套餐,员工的图片。之所以不存到本地,这是因为前端无法回调服务器的本地图片,这也就造成我们只能存图片,无法回显图片的BUG,而我们如果调用阿里云的云存储服务,照片存储到阿里巴巴的云之后,会返送一个URL,我们通过这段URL就可以回调图片。
步骤为:先配置阿里云的各项配置
#application.yml
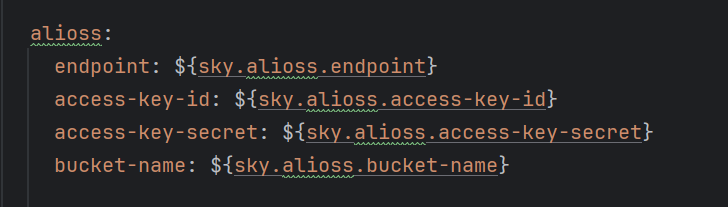
#application-dev.yml

#sky-common
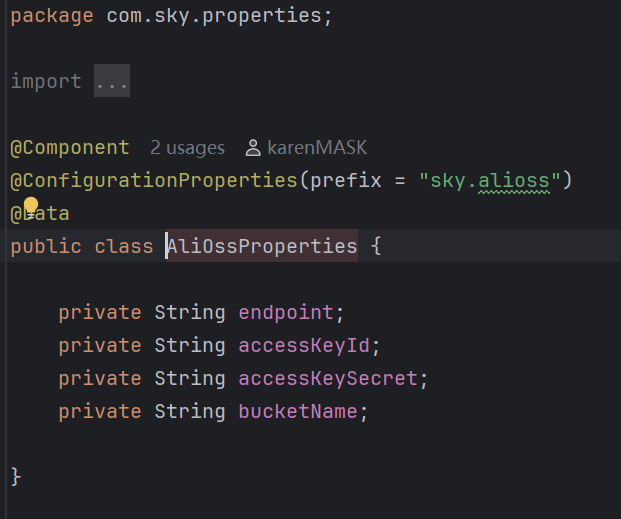
这段代码的作用是将以sky.alioss为前缀的配置项绑定到AliOssProperties对象中.
#sky-common-utils
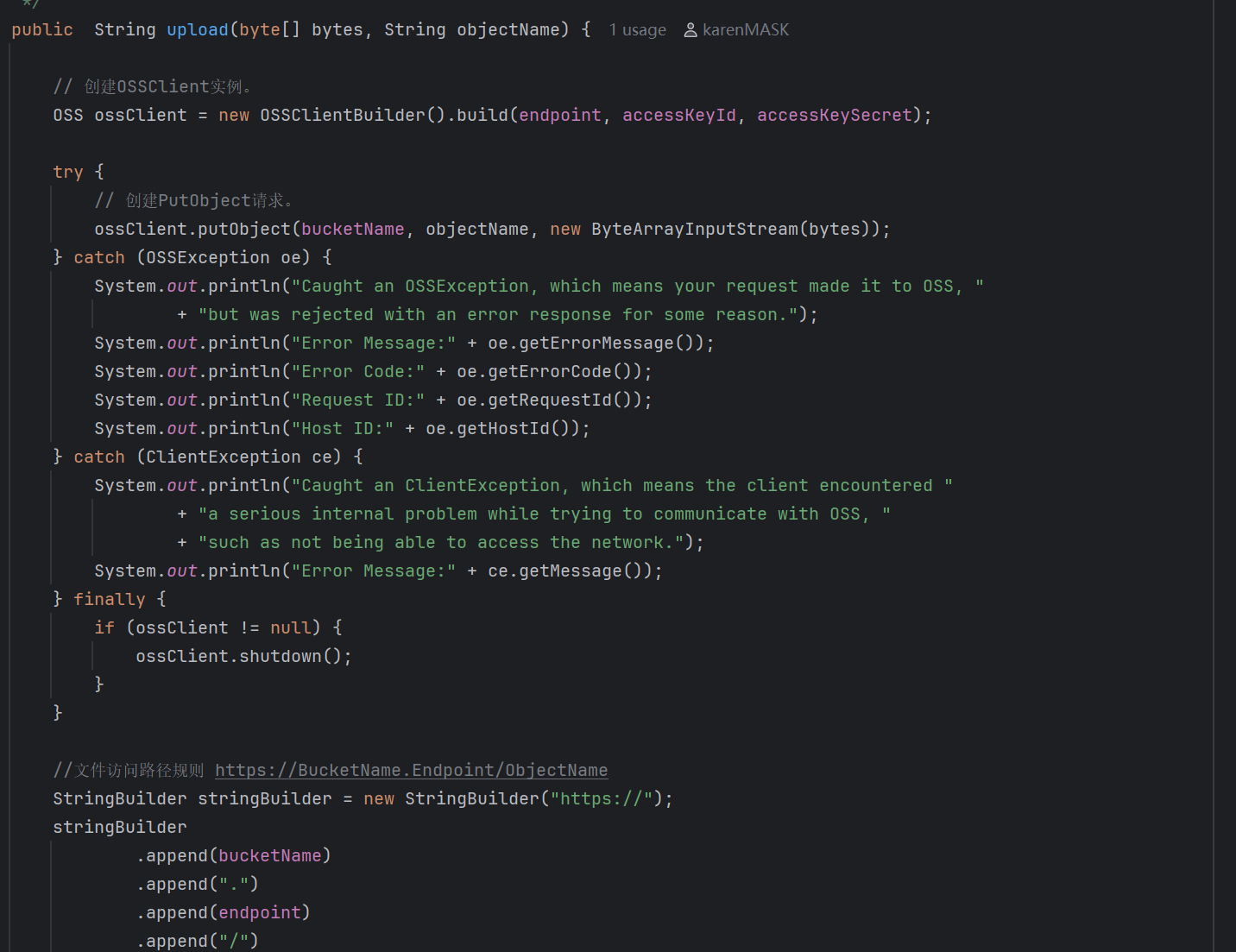
这时我们就也有了阿里云OSS这个工具类。而需要注意的是OSS服务于整个server层,不独属于某一个方法或者类。因此我们应该把创建阿里云OSS的代码放到server的配置类中,也就是说全局只需要有server一个类
#sky-server-config
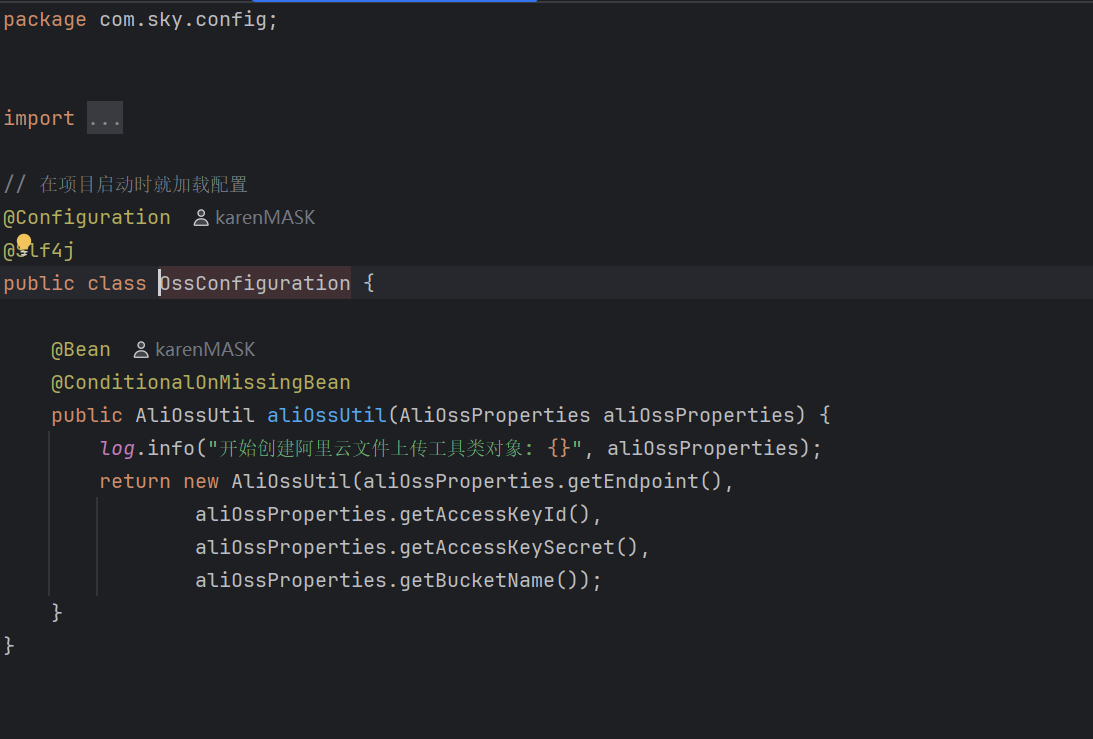
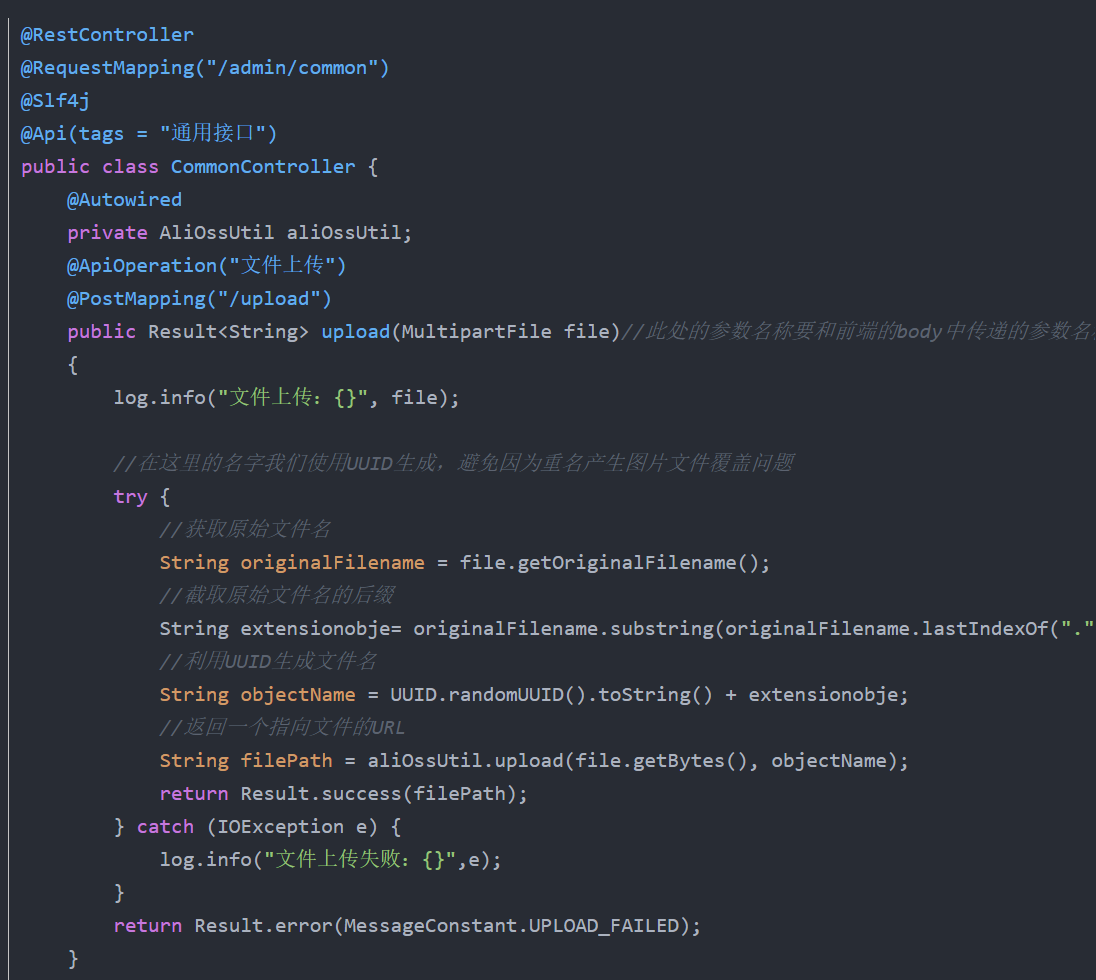
我们最后再来看看如何调用阿里云OSS这个工具类:
四.项目第三阶段技术
1.初步引入Redis
Redis(Remote Dictionary Server)是一个开源的内存存储系统,常用于构建高性能、高可扩展性的应用程序。它支持多种数据结构,如字符串、哈希表、列表、集合、有序集合等,并提供了丰富的操作命令,使开发人员能够快速、灵活地处理数据。
而我们的项目中引入Redis的地方是:查询店铺营业状态 ,像这种店铺营业状态,本项目无非就两个状态:营业中/打样。而且它属于高频查询。只要用户浏览到这个店铺,前端就要自动发送请求到后端查询店铺状态。
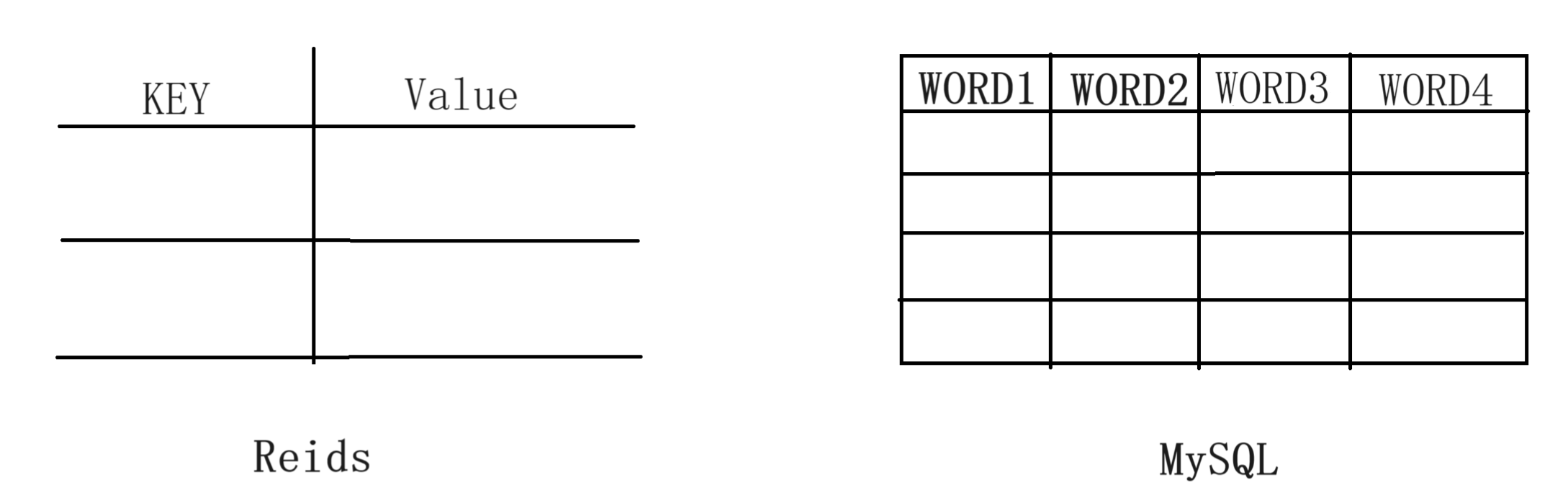
而键值对这种形式就符合我们对于店铺营业状态数据格式的理想存储状态,Redis也把数据放到缓存中,而不是磁盘,有效缓解了这种高频查询给磁盘带来的压力
首先,先要导入Spring Data Redis的依赖:
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>其次,配置redis数据源:
spring:redis:host: 地址port:端口号password:密码3.编写配置类,创建RedisTemplate对象:
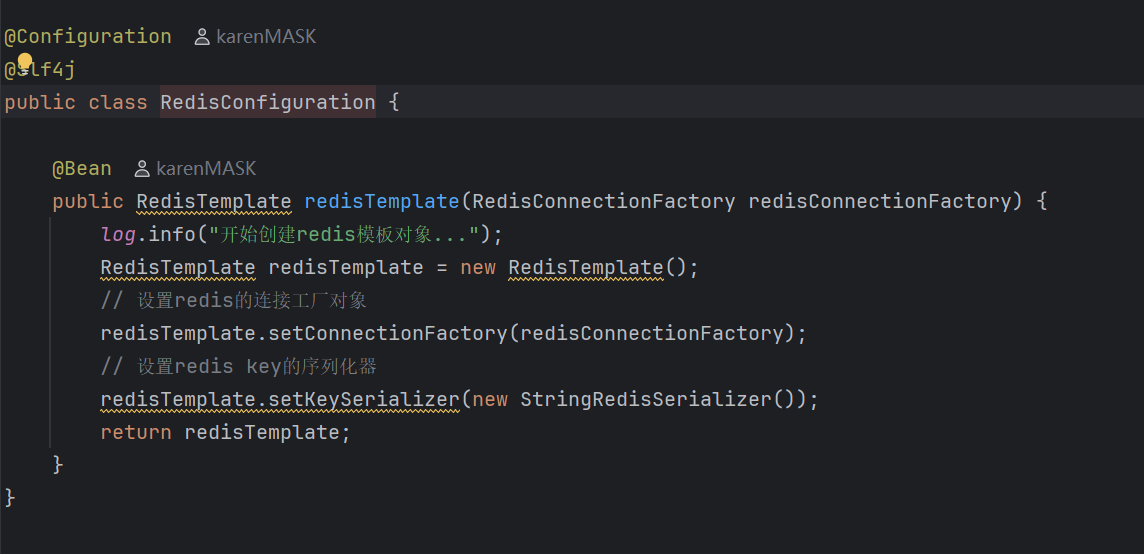
使用RedisTemplate 对象操作Redis
---------------------------------------------------------------------------------------------------------------------------------这样我们就可以在Java中操作Redis了。
只需要创建一个Redis对象,利用Spring Data Redis 就可以对Redis进行操作。
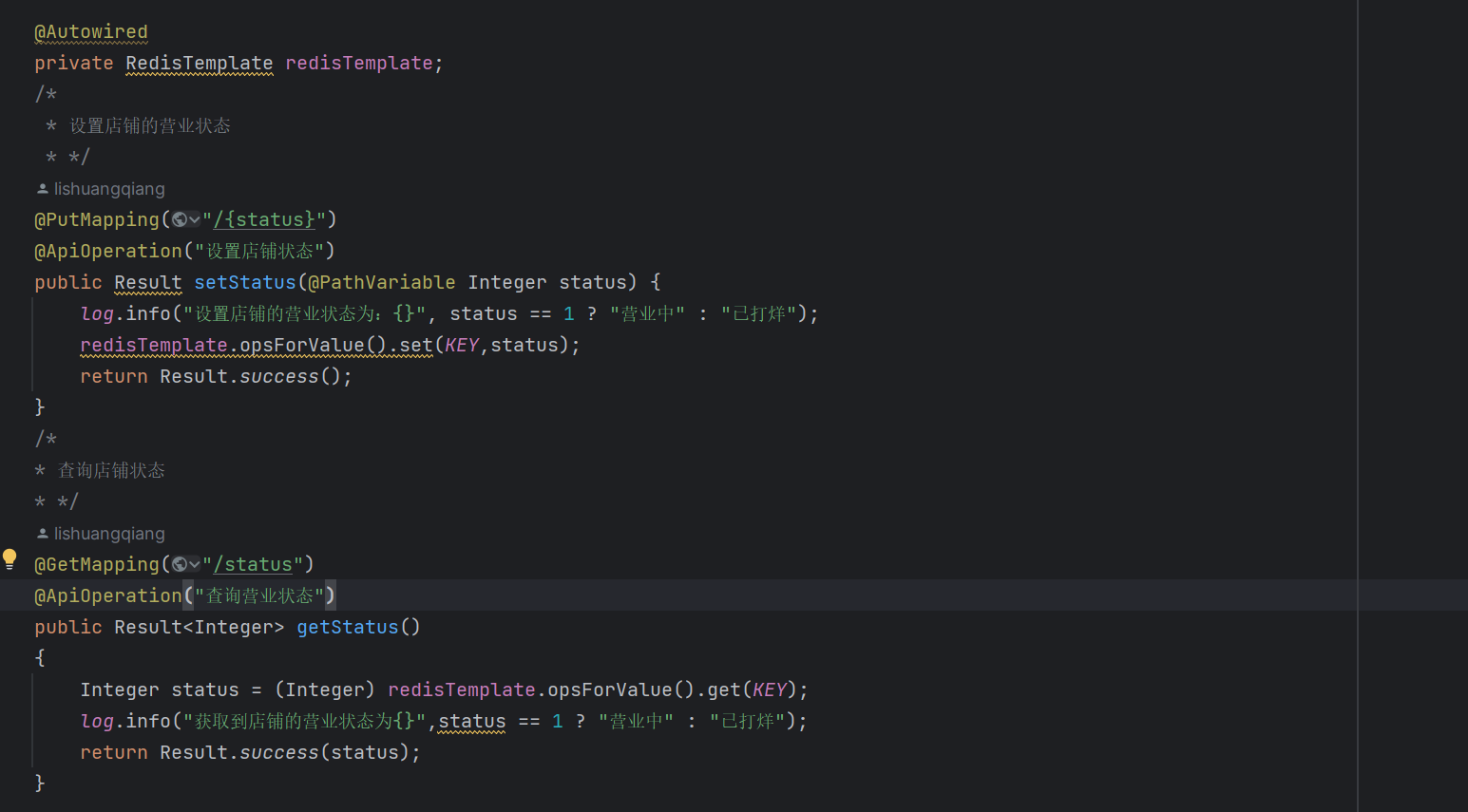
利用Redis来对业务优化:
用户一旦点进店铺,店铺就需要向用户展示菜品,套餐等等数据。这种通过少量的操作可以调起大量后端操作的行为,是一个很危险的杠杆操作。而在高并发环境下,这无疑又是在拷打服务器。
而且这种重复查询的请求,正是我们要优化的目标。
我们的思路很简单:缓存请求相应内容,如果小程序又发送相同请求,那么我们就从缓存中直接返回相应内容。这样就减少了直接对后端的数据库的查询。
而这句话中,解决问题的重点两个字就可以概括:缓存!
这与我们上面讲到的Redis的职能岂不是相同嘛?我们在初识Redis的时候就说过:Redis是高性能的,基于键值对的,写入缓存的 内存存储系统。
思路现在已经明确了,我们来看一下代码实现(我们以用户端查询菜品为例):
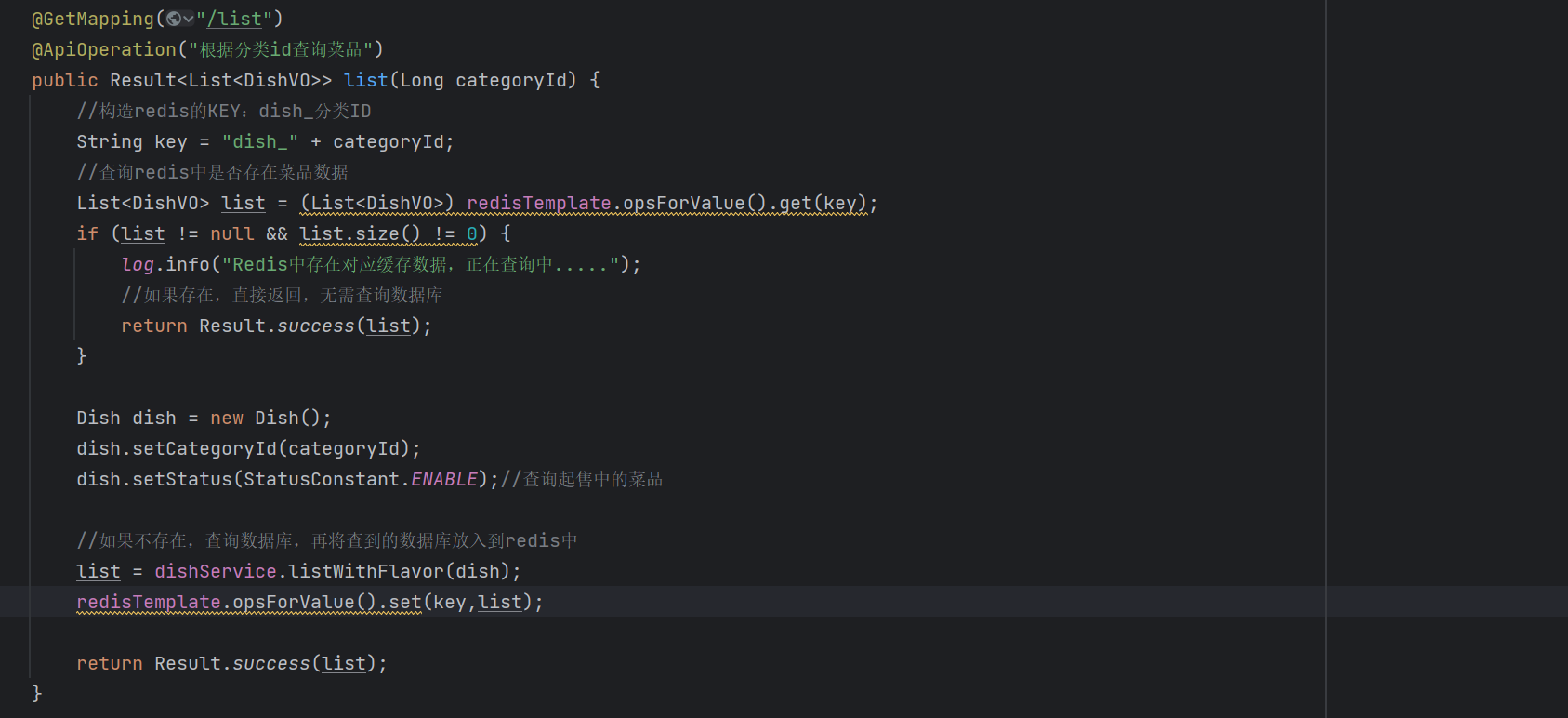
但这种忽视数据库, 从缓存中拿数据的方式存在问题: 数据库与缓存中的内容不一致, 导致返回的数据没有更新.
而我们本项目解决Redis缓存的问题非常简单:只要有更新业务或者新建业务就清空对应的缓冲区
2.利用Spring cache来对业务进行优化
Spring Cache 是 Spring Framework 提供的缓存抽象和实现框架。它为应用程序提供了一种统一的缓存抽象,支持多种缓存技术的集成,并支持 AOP 机制实现基于方法的缓存,从而简化了缓存的使用和管理。
下面是 Spring Cache 的一些特点和常用功能:
1.缓存技术支持:Spring Cache 支持多种主流的缓存技术,包括 EHCache、Redis、Guava 等。
2.基于注解的缓存:Spring Cache 提供了基于注解的缓存,可以在方法上直接使用 @Cacheable、@CachePut、@CacheEvict 等注解,实现对方法结果的自动缓存和更新
引入依赖:
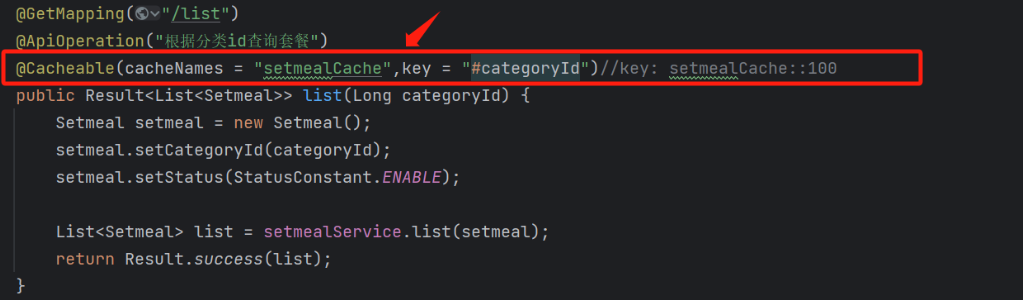
然后我们就可以通过调用相关注解的方式来达到缓存套餐的功能:(在这里我们的底层缓存实现选择使用redis)
3.Httpclient
Httpclient是一个服务器端进行HTTP通信的库,他使得后端可以发送各种HTTP请求和接收HTTP响应,使用HTTPClient,可以轻松的发送GET,POST,PUT,DELETE等各种类型的的请求
4.微信小程序登录
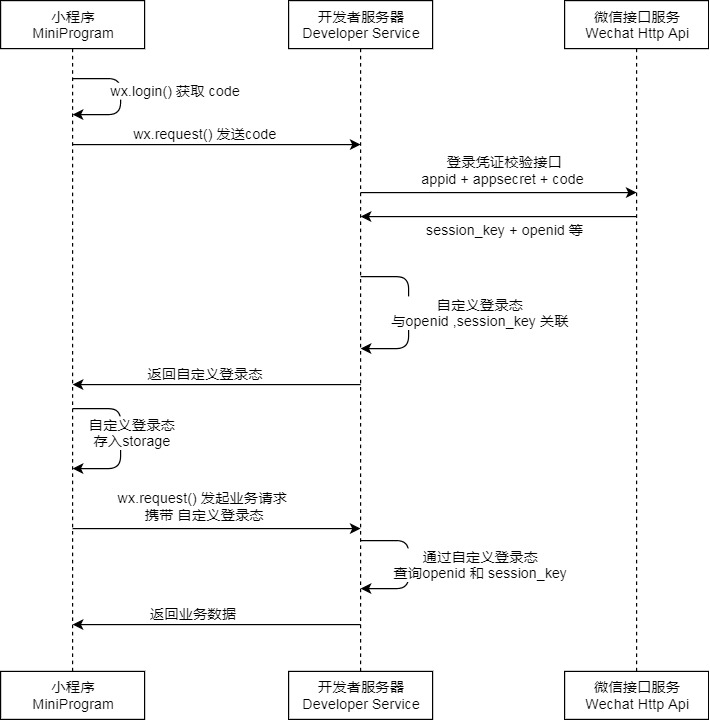
通过这张图,我们可以了解实现微信登录的基本流程
1.我们的小程序会调用wx.login()来获得一个code。该 code 的作用是用于后续的用户身份验证和获取用户信息。
2.小程序的wx.request会把code发送给后端,后端再打包自己的小程序ID(appid)和小程序密钥(appsecert) 最后加上小程序发送给自己的code,利用Httpclient从后端发送给微信接口服务。而微信接口服务会在校验之后返回session_key和openid
微信接口服务返回的session_key和openid具有以下用途:
1.用户身份识别:通过openid,可以唯一标识用户的身份。开发者可以将openid与用户在自己的系统中的账号进行关联,实现用户的登录、注册等功能。
2.数据加密解密:session_key是用于对用户敏感数据进行加密和解密的密钥。开发者可以使用session_key对用户的敏感数据进行加密,确保数据在传输过程中的安全性;同时,也可以使用session_key对加密后的数据进行解密,获取原始数据。
3.用户信息获取:通过openid和session_key,开发者可以向微信接口服务发送请求,获取用户的详细信息,如用户昵称、头像等。这些信息可以用于个性化展示、社交分享等功能
3.在后端获取到微信接口服务发送给自己的session_key和openid,自定义用户登录态,并且发送给小程序
自定义用户登录态指的是在用户登录时,后端根据一定的规则生成一个唯一的标识符(如token),并将其返回给前端。前端在接下来的请求中,需要带上这个标识符,以便后端可以识别当前请求的用户身份。
在微信小程序中,用户登录后,后端会返回一个session_key和openid,这两个值可以用于生成一个唯一的标识符,作为用户的登录态。具体实现方式可以是将session_key和openid拼接起来,再进行加密处理,生成一个token,并将其返回给小程序。小程序在接下来的请求中,需要在请求头或者请求参数中携带该token,以便后端可以验证用户的身份。
自定义用户登录态的好处是可以在后端实现用户身份验证和权限控制,保护系统的安全性。同时,由于token是由后端生成的,可以有效防止恶意攻击者伪造用户身份。
4.小程序把后端发送过来的自定义登录态存入到storge中
而此时小程序的微信登录就完成了。再往后的是解释一次小程序与服务器交互的过程。
wx.request()发送业务请求,携带自定义登录态,方便后端识别当前用户身份。后端根据前端发送过来的自定义登录态来查询openid和session_key。此时后端就可以识别当前用户身份。返回当前用户的个性化业务数据。
5.微信小程序支付
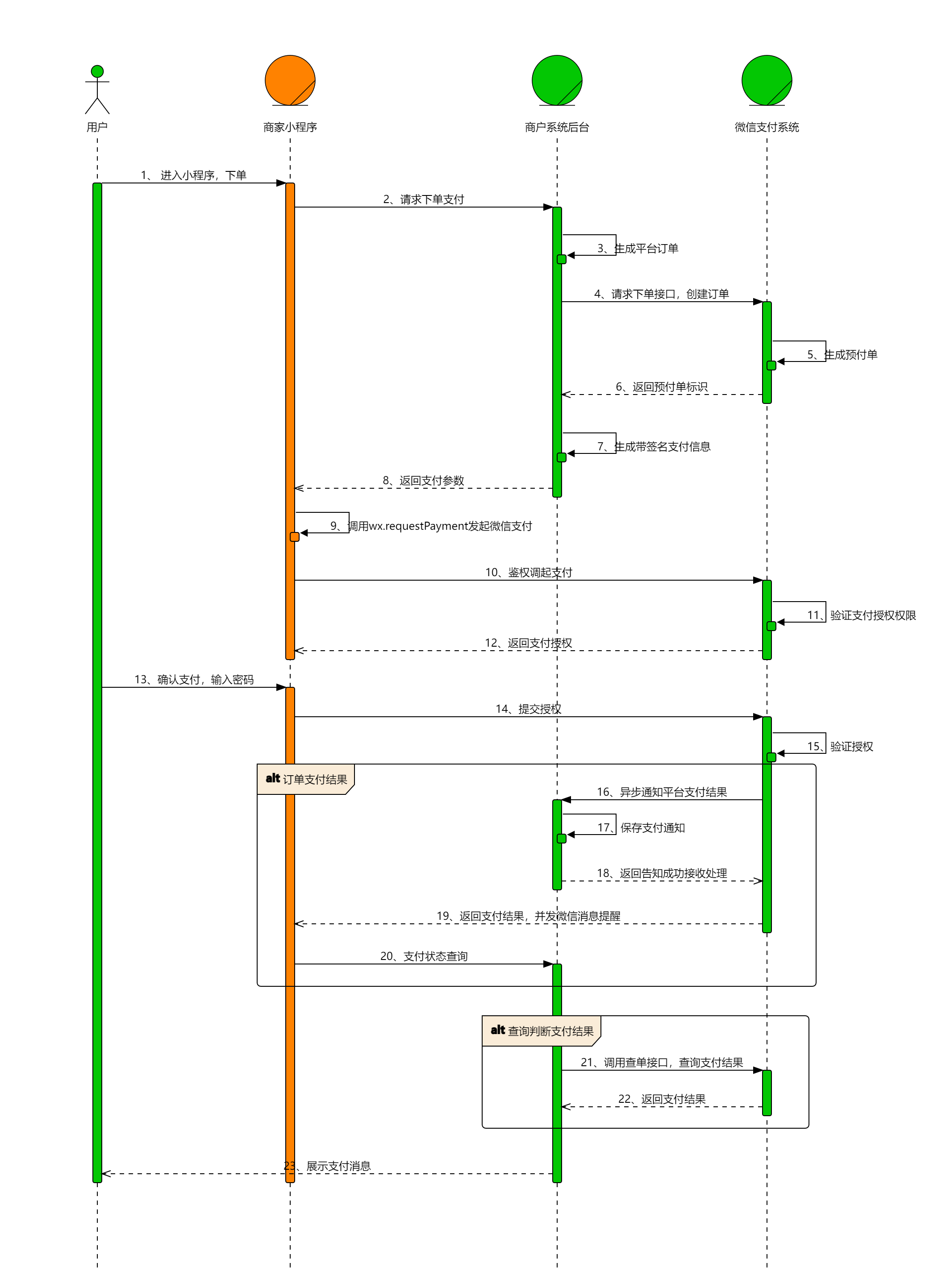
通过这张图,我们可以了解到小程序调用微信支付的基本流程
1.用户进入小程序下单 ,小程序会发送下单请求给商家系统后台,商家后端会生成平台订单,请求微信支付系统的下单接口,创建订单。微信支付系统接收到商家系统后台的请求后,会生成预付单,并且返回预付单标识给商家系统后台,此时商户系统后台利用算法生成带签名支付信息,并且把相关支付参数返回给商家小程序
2.当小程序接收到相关的参数之后,就会调用wx.requestPayment发起微信支付,此时小程序会先向微信支付系统发送请求,检查当前用户身份,微信支付系统在检验当前用户符合权限之后,会给小程序返回支付授权,允许小程序调起支付页面。
3.当小程序调起支付页面之后,用户输入密码确定支付,此时微信小程序会打包相关参数给微信支付系统,校验身份通过之后,就异步通知平台支付交易结果给商家后端,商家后端对其进行保存通知处理,并且在这同时返回支付结果,并且发送微信消息提醒。
异步通知是一种通信方式,用于在两个系统之间传递信息,其中发送方无需立即等待接收方响应的结果。它允许发送方继续执行其他任务,而不必阻塞并等待接收方的回应。
4.上述已经完整的介绍了一次微信小程序调用微信支付的具体过程。如果我们后续要查询判断微信支付结果,就在后端调用查寻订单接口,查询支付结果。而微信支付平台就会为商家后端返送支付结果,供我们进行各种判断。
五.项目第四阶段技术
1.Spring Task
Spring Task 是 Spring 框架提供的一种任务调度工具,用于在应用程序中执行定时任务或者周期性任务。它基于线程池机制,可以创建并管理多个线程来执行任务。
通过 Spring Task,开发人员可以通过注解或者配置的方式定义需要执行的任务,并设置执行的时间间隔或者执行时间点。Spring Task 提供了灵活的任务调度能力,可以满足各种任务执行的需求,例如定时的数据同步、定时的报表生成、定时的缓存清理等。
简单的说:Spring Task为我们提供了一种基于注解的方式来使得我们的后端具有定时处理任务的能力,这项功能可以说是十分常见:我们CSDN的每日周报,就是定时任务。
而这项工具,在我们的项目中的主要作用是:处理异常订单
在我们的数据库中,总会有一些异常订单,例如用户一直未点击送达的订单,而我们需要对这些订单进行集中的处理。
1.导入依赖:
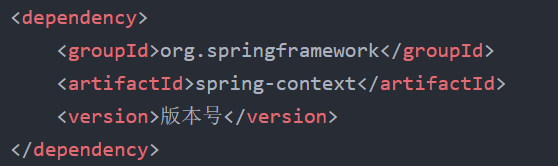
使用方法: 设置定时, 具体使用方法
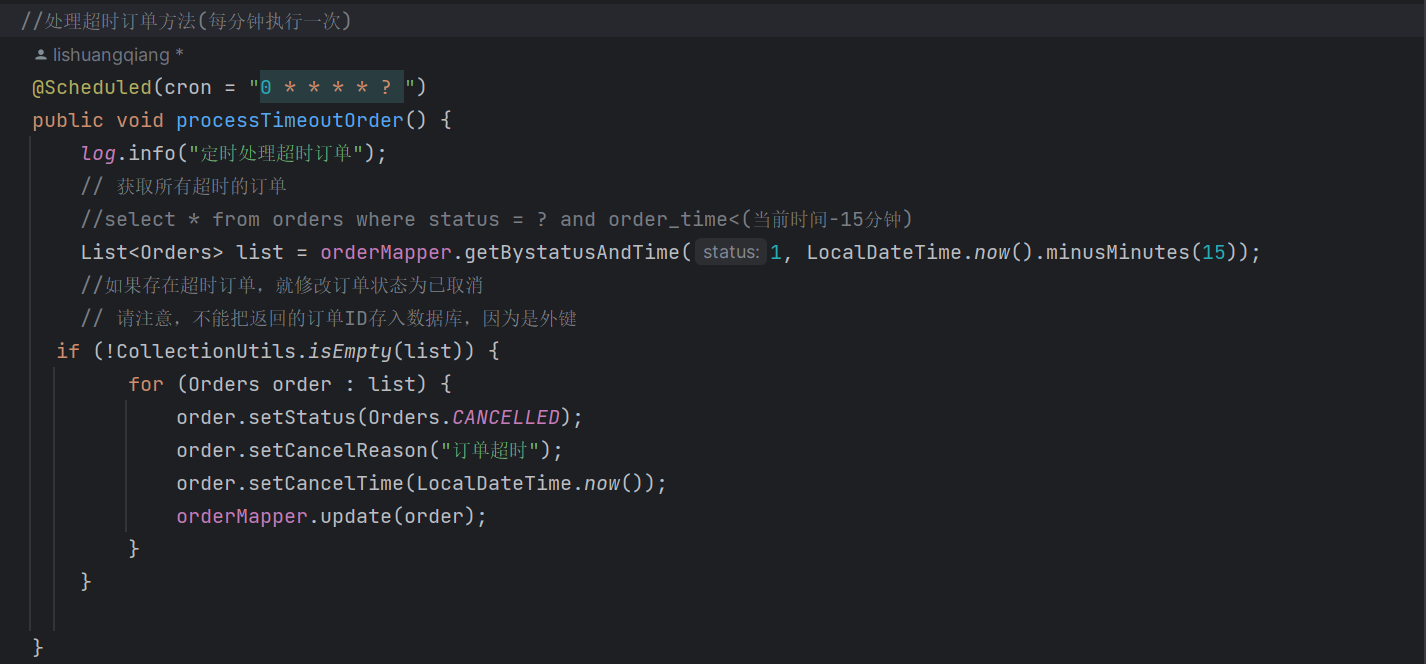
具体的定时任务很简单,就是简单的业务逻辑实现代码,而重点在这个注解@Scheduled
它是用来设置定时的注解,它里面采用的表达式叫做cron表达式,通过这个表达式,我们可以指定任务多久执行一次。
而Cron 表达式是一个字符串,由 6 个字段组成,每个字段表示不同的时间单位和限制条件
这几个字段从左到右分别为: 秒 分 时 天 周 月 年
之所以说是 六个字段是因为天和周不能同时出现。
而我们也不需要掌握如何书写Cron表达式,开源的互联网已经为我们提供了大量的Cron表达式,在这里我也贴一个:
在线Cron表达式生成器 (pppet.net)https://www.pppet.net/但是在设置一些任务的时候,还是要对定时上做好权衡,因为大量的查询数据库会造成数据库的高压力。
2.引入Websocket来实现用户端和商家端通信
在项目中,有外卖催单和来单提醒这两个功能。
这两个业务功能的逻辑思路很简单:
用户端下单或者催单后,发送特定请求到后端,后端再发送请求到商家端,商家端再根据后端的请求判断是催单还是来单提醒。
在这种思路中我们发现最关键的就在于:后端如何与商家端建立链接,实现实时通信?
基于这样的一个问题,我们使用了:Websocket 来实现这关键点:
WebSocket 是一种在 Web 应用程序中实现双向通信的协议。它允许客户端和服务器之间建立持久的、双向的通信通道,使得服务器可以主动向客户端推送消息,而无需客户端发送请求。
传统的 HTTP 协议是一种请求-响应模式,客户端需要定期发送请求并等待服务器的响应。但在某些场景下,需要实时地将数据推送给客户端,如聊天应用、实时数据监控等。这时就可以使用 WebSocket 协议。
WebSocket 协议通过在客户端和服务器之间建立一个持久的连接,实现了双向通信。它使用 HTTP 升级请求来升级到 WebSocket 连接,并在连接建立后,使用轻量级的帧来传递数据。与 HTTP 相比,WebSocket 具有更低的开销和更高的性能。
使用 WebSocket,客户端和服务器之间可以实时地发送消息和接收消息,不需要频繁地发起请求。这样可以减少网络流量和延迟,并提供更好的用户体验。在开发中,可以使用各种编程语言和框架来实现 WebSocket,如Java中的Spring WebSocket、Node.js中的Socket.io等。
总之,WebSocket 提供了一种简单、高效的方式,使得 Web 应用程序可以实现实时的双向通信。它在很多场景下都能发挥重要作用,特别是需要实时数据传输和服务器主动推送的应用场景。
我们展示一下代码:
首先,我们要在webSocket配置类中注册一个webSocket
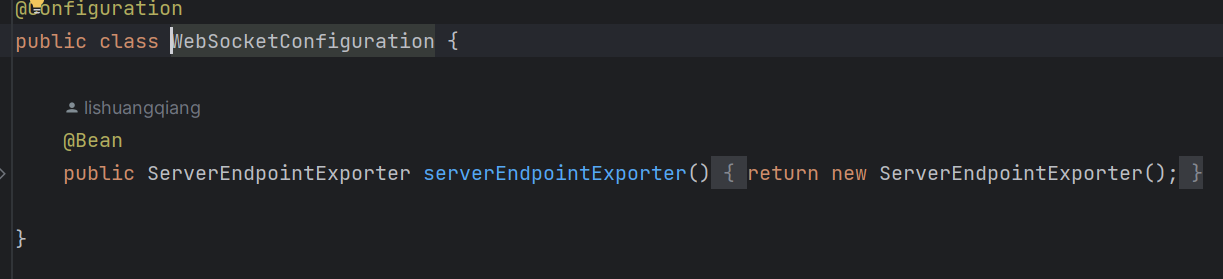
之后就可以用它与商家端进行实时通信:
实现用户催单后的商家提醒。
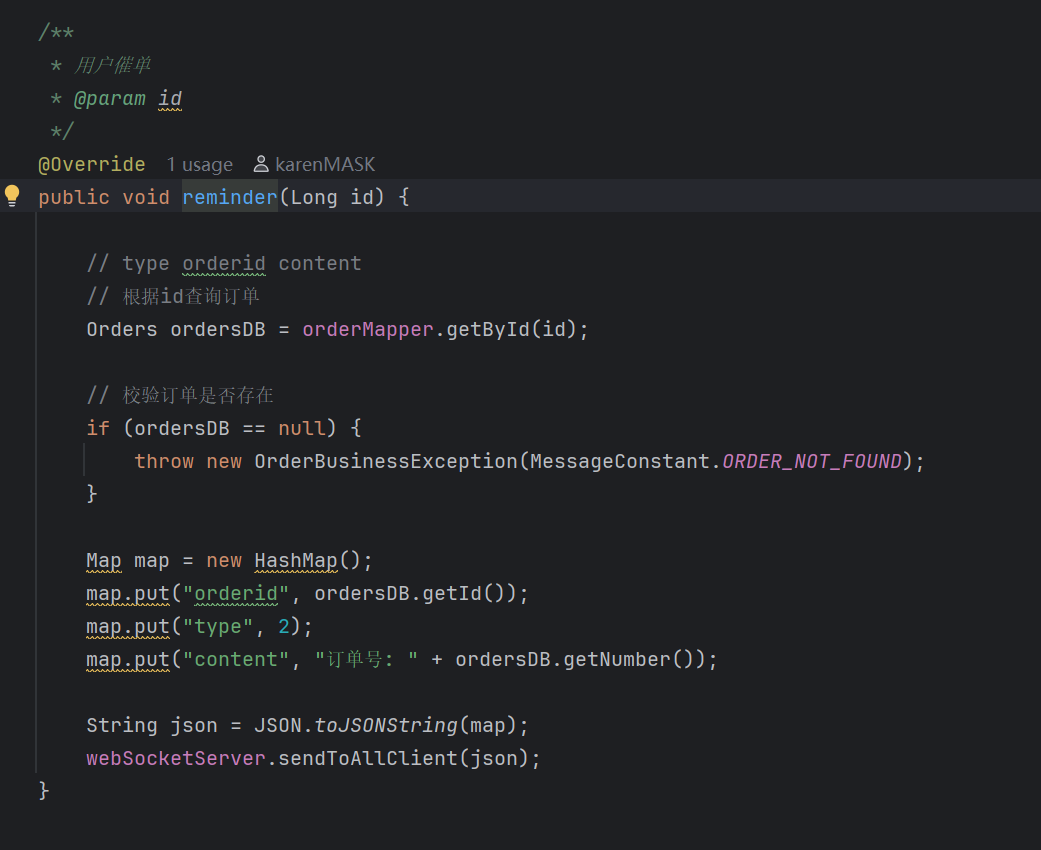
商家端效果:
主流实时通信技术对比
| 技术 | 协议 | 特点 | 适用场景 | 浏览器支持 |
|---|---|---|---|---|
| WebSocket | WS/WSS | 全双工、低延迟、持久连接 | 实时聊天、游戏、金融报价 | 全平台 |
| Server-Sent Events (SSE) | HTTP | 服务器到客户端的单向推送 | 实时通知、新闻推送 | 除IE外主流 |
| Long Polling | HTTP | 模拟实时、高延迟 | 简单实时需求 | 全平台 |
SSE 是一种特殊的 HTTP 机制,它允许服务器向客户端推送数据,以实现服务器和客户端之间的实时通信。SSE 与 WebSocket 不同的是,它是基于 HTTP 协议的,不需要像 WebSocket 那样建立专门的协议和通信通道。
长轮询则是一种模拟实时通信的技术,它通过客户端向服务器发送一个请求并保持长时间的连接,在服务器端有新数据到达时返回响应,并在客户端接收到响应后再次发送请求继续保持连接。长轮询的实现方式类似于 SSE,但是相对于 SSE 而言,因为需要频繁的开启和关闭连接,长轮询会增加服务器的负担,同时也不如 SSE 和 WebSocket 那样实时和高效。
通过这里我们可以可以看到,长轮询并不是真正的双向通信,他只是不断延长请求响应的时间。
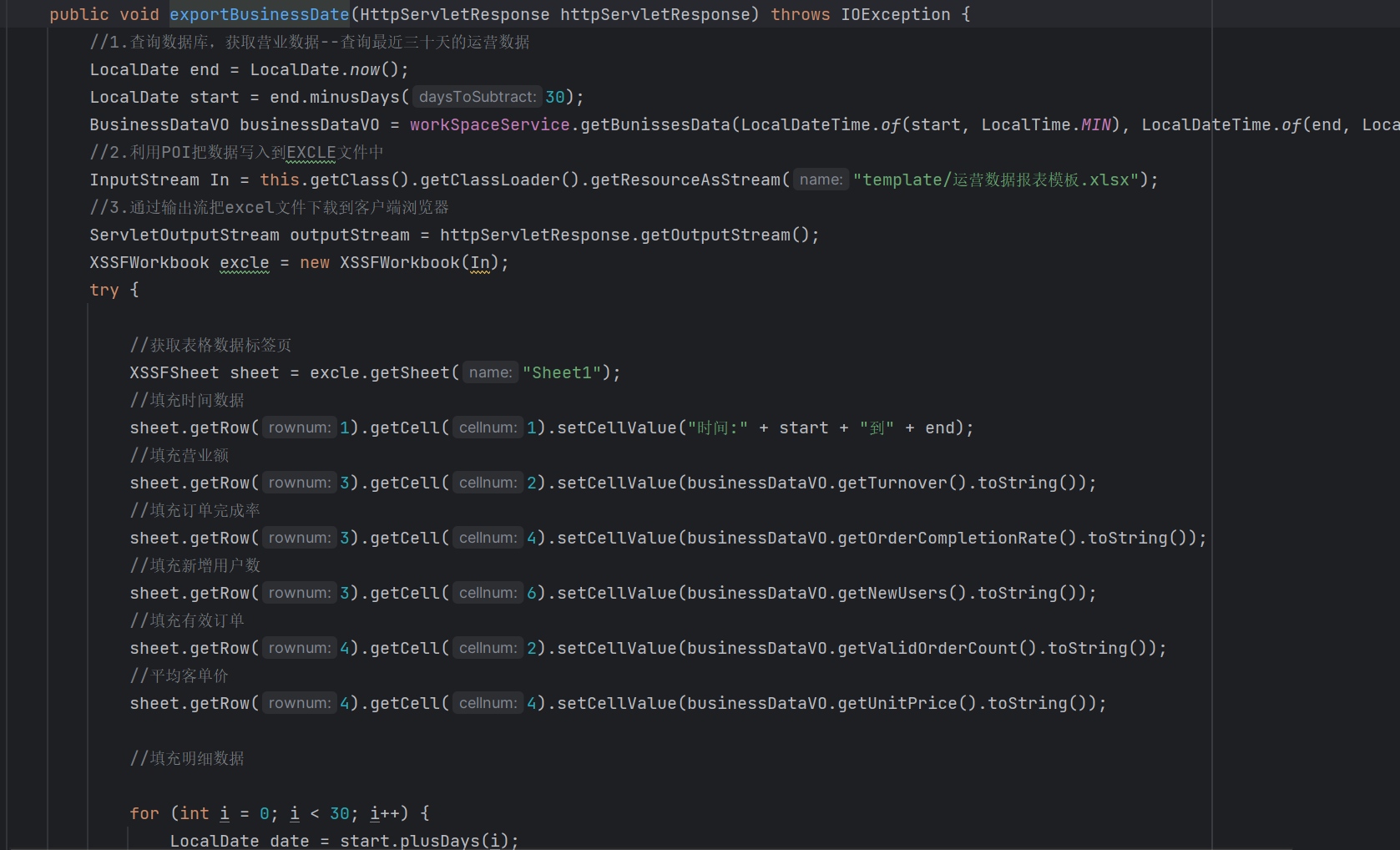
3.Apache POI技术实现导出文件
Apache POI(Poor Obfuscation Implementation)是一个用于处理Microsoft Office格式文档的开源Java库。POI提供了一组可以读取、写入和操作各种Office文件的API,包括Word文档(.doc和.docx)、Excel电子表格(.xls和.xlsx)以及PowerPoint演示文稿(.ppt和.pptx)。
通过POI,开发者可以在Java应用程序中读取和编辑Office文档,实现对文档内容、样式、格式和元数据的操作。它提供了向现有文档添加新内容、修改现有内容、删除内容以及进行格式设置和样式调整等功能。
而在本项目中,我们并不使用ApachePOI建表,这样无疑是在拷打自己。我们的想法是直接就提供一张创建好的模板表,这样我们只需要使用ApachePOI来实现填充数据就好了。
代码太多,仅展示一部分:
这项技术其实还属于应用类,会用就好了。