数据结构 | 栈:构建高效数据处理的基石
个人主页-爱因斯晨
文章专栏-数据结构
博主好久没学数据结构了,以至于忘了学到哪儿了,看了博客还在想,这是我写的吗?我学过吗?
文章目录
- [个人主页-爱因斯晨 ](https://blog.csdn.net/2401_87533975?spm=1011.2266.3001.5343)
- 文章专栏-数据结构
- 一、栈的概念与核心特性
- 二、栈的基本操作及原理
- 三、栈的两种实现方式(C 语言)
- 1. 顺序栈(数组实现)
- 2. 链式栈(链表实现)
- 四、栈的典型应用场景
- 五、栈的性能分析与选择建议
- 六、总结
- 六、总结
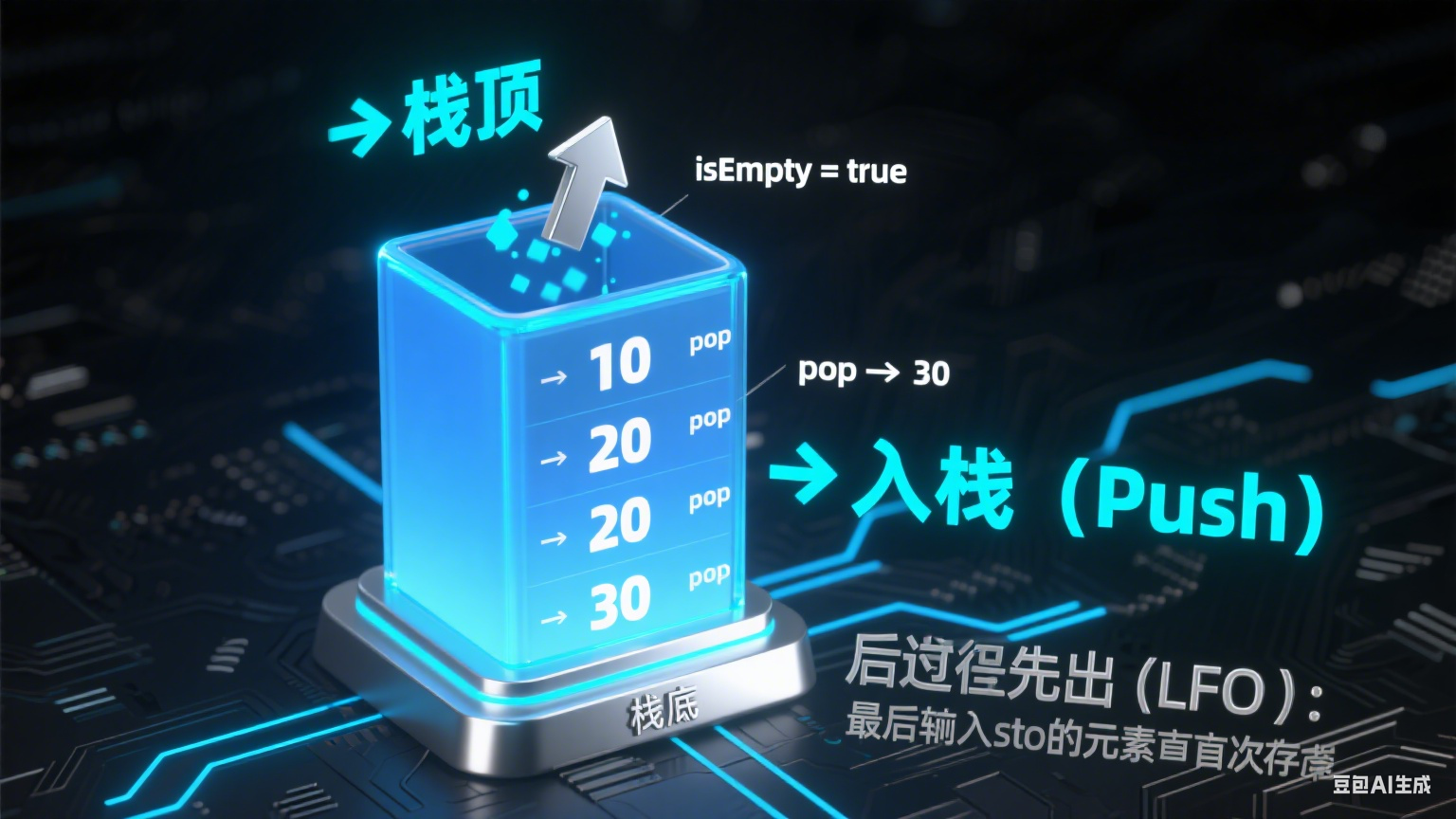
一、栈的概念与核心特性
栈是一种特殊的线性数据结构,其操作遵循 “后进先出”(LIFO,Last In First Out)原则。想象一叠叠放在桌上的书籍,最后放上去的书总是最先被拿走,栈的工作方式与此完全一致。
栈的核心特性体现在两个方面:
-
操作限制性:仅允许在栈的一端(称为 “栈顶”)进行插入和删除操作,另一端(“栈底”)始终固定不动。
-
顺序依赖性:元素的访问顺序严格依赖于入栈顺序,后进入的元素必须先离开,无法直接访问中间或底部的元素。
这种特性让栈在处理具有明确先后依赖关系的问题时效率极高,例如函数调用、表达式解析等场景。
二、栈的基本操作及原理
栈的操作接口简洁而明确,所有操作都围绕栈顶展开:
- 入栈(Push)
-
功能:在栈顶添加新元素
-
过程:先判断栈是否已满,若未满则将栈顶指针上移,再存入新元素
-
时间复杂度:O (1)
- 出栈(Pop)
-
功能:移除并返回栈顶元素
-
过程:先判断栈是否为空,若不为空则取出栈顶元素,再将栈顶指针下移
-
时间复杂度:O (1)
- 查看栈顶(Top/Peek)
-
功能:返回栈顶元素但不改变栈结构
-
限制:仅当栈非空时有效
-
时间复杂度:O (1)
- 判空(IsEmpty)
-
功能:判断栈是否不含任何元素
-
实现:通过检查栈顶指针位置或元素数量是否为 0
- 求长(Size)
-
功能:返回栈中元素的总个数
-
实现:可通过维护计数器或计算栈顶与栈底的偏移量
这些操作的高效性(均为常数时间)是栈被广泛应用的重要原因。
三、栈的两种实现方式(C 语言)
在 C 语言中,栈主要有两种实现方式:数组实现(顺序栈)和链表实现(链式栈),各有适用场景。
1. 顺序栈(数组实现)
顺序栈利用连续的数组空间存储元素,通过栈顶指针标记当前栈顶位置。
#include <stdio.h>
#include <stdlib.h>
#define MAX_SIZE 100 // 栈的最大容量// 顺序栈结构体定义
typedef struct {int data[MAX_SIZE]; // 存储元素的数组int top; // 栈顶指针,-1表示空栈
} SeqStack;// 初始化栈
void initStack(SeqStack *stack) {stack->top = -1;
}// 入栈操作
int push(SeqStack *stack, int value) {if (stack->top == MAX_SIZE - 1) {printf("栈已满,无法入栈\n");return 0; // 入栈失败}stack->top++;stack->data[stack->top] = value;return 1; // 入栈成功
}// 出栈操作
int pop(SeqStack *stack, int *value) {if (stack->top == -1) {printf("栈为空,无法出栈\n");return 0; // 出栈失败}*value = stack->data[stack->top];stack->top--;return 1; // 出栈成功
}// 查看栈顶元素
int getTop(SeqStack *stack, int *value) {if (stack->top == -1) {printf("栈为空\n");return 0;}*value = stack->data[stack->top];return 1;
}// 判断栈是否为空
int isEmpty(SeqStack *stack) {return stack->top == -1;
}// 获取栈的长度
int getSize(SeqStack *stack) {return stack->top + 1;
}// 示例用法
int main() {SeqStack stack;initStack(&stack);push(&stack, 10);push(&stack, 20);push(&stack, 30);printf("栈的长度:%d\n", getSize(&stack)); // 输出3int topVal;getTop(&stack, &topVal);printf("栈顶元素:%d\n", topVal); // 输出30while (!isEmpty(&stack)) {pop(&stack, &topVal);printf("出栈元素:%d\n", topVal); // 依次输出30、20、10}return 0;
}
顺序栈的优点是实现简单、访问速度快,但缺点是容量固定,扩容需要重新分配内存并复制元素。
2. 链式栈(链表实现)
链式栈通过链表节点存储元素,链表头部作为栈顶,无需预先指定容量。
#include <stdio.h>
#include <stdlib.h>// 链表节点结构体
typedef struct Node {int data; // 节点数据struct Node *next; // 指向后一个节点的指针
} Node;// 链式栈结构体
typedef struct {Node *top; // 栈顶指针int size; // 栈的长度
} LinkStack;// 初始化栈
void initStack(LinkStack *stack) {stack->top = NULL;stack->size = 0;
}// 创建新节点
Node* createNode(int value) {Node *newNode = (Node*)malloc(sizeof(Node));if (newNode == NULL) {printf("内存分配失败\n");exit(1);}newNode->data = value;newNode->next = NULL;return newNode;
}// 入栈操作
void push(LinkStack *stack, int value) {Node *newNode = createNode(value);newNode->next = stack->top; // 新节点指向原栈顶stack->top = newNode; // 更新栈顶为新节点stack->size++;
}// 出栈操作
int pop(LinkStack *stack, int *value) {if (stack->size == 0) {printf("栈为空,无法出栈\n");return 0;}Node *temp = stack->top;*value = temp->data;stack->top = stack->top->next; // 更新栈顶free(temp); // 释放原栈顶节点内存stack->size--;return 1;
}// 查看栈顶元素
int getTop(LinkStack *stack, int *value) {if (stack->size == 0) {printf("栈为空\n");return 0;}*value = stack->top->data;return 1;
}// 判断栈是否为空
int isEmpty(LinkStack *stack) {return stack->size == 0;
}// 获取栈的长度
int getSize(LinkStack *stack) {return stack->size;
}// 销毁栈
void destroyStack(LinkStack *stack) {Node *temp;while (stack->top != NULL) {temp = stack->top;stack->top = stack->top->next;free(temp);}stack->size = 0;
}// 示例用法
int main() {LinkStack stack;initStack(&stack);push(&stack, 100);push(&stack, 200);push(&stack, 300);printf("栈的长度:%d\n", getSize(&stack)); // 输出3int topVal;getTop(&stack, &topVal);printf("栈顶元素:%d\n", topVal); // 输出300while (!isEmpty(&stack)) {pop(&stack, &topVal);printf("出栈元素:%d\n", topVal); // 依次输出300、200、100}destroyStack(&stack);return 0;
}
链式栈的优点是容量动态扩展,无需担心溢出问题,但相比顺序栈多了指针域的内存开销,且访问速度略慢。
四、栈的典型应用场景
栈的 “后进先出” 特性使其在多个领域发挥关键作用:
- 函数调用管理
程序运行时,系统会使用栈保存函数调用信息(称为 “调用栈”)。每次函数调用时,将返回地址、局部变量等信息压入栈;函数执行完毕后,从栈顶弹出这些信息,恢复到调用前的状态。这种机制保证了嵌套调用(如递归)的正确执行。
- 表达式求值与转换
在数学表达式计算中(如 “3 + 4 × (2 - 1)”),栈可用于暂存运算符和操作数,确保运算优先级正确。例如:
-
遇到数字直接输出
-
遇到运算符时,与栈顶运算符比较优先级,弹出优先级更高或相等的运算符
-
括号处理时,左括号入栈,右括号则弹出栈中元素直到遇到左括号
- 括号匹配校验
代码中的括号(()、[]、{})必须成对出现且正确嵌套,可通过栈实现校验:
// 括号匹配函数示例
int isParenthesesValid(char *str) {LinkStack stack;initStack(&stack);for (int i = 0; str[i] != '\0'; i++) {if (str[i] == '(' || str[i] == '[' || str[i] == '{') {push(&stack, str[i]); // 左括号入栈} else if (str[i] == ')' || str[i] == ']' || str[i] == '}') {if (isEmpty(&stack)) return 0; // 右括号多了int topChar;pop(&stack, &topChar);// 检查括号是否匹配if ((str[i] == ')' && topChar != '(') ||(str[i] == ']' && topChar != '[') ||(str[i] == '}' && topChar != '{')) {destroyStack(&stack);return 0;}}}int result = isEmpty(&stack); // 栈为空说明所有括号匹配destroyStack(&stack);return result;
}
- 浏览器历史记录
浏览器的 “后退” 和 “前进” 功能本质是两个栈的操作:
-
访问新页面时,将当前页面压入 “后退栈”
-
点击后退时,从 “后退栈” 弹出页面,压入 “前进栈”
-
点击前进时,从 “前进栈” 弹出页面,压入 “后退栈”
- 深度优先搜索(DFS)
在图和树的遍历中,DFS 算法通常使用栈(或递归,递归本质是系统栈)实现:
-
先将起始节点入栈并标记访问
-
弹出栈顶节点,访问其未标记的邻接节点并压入栈
-
重复操作直到栈为空
五、栈的性能分析与选择建议
- 时间复杂度
栈的所有基本操作(push、pop、top 等)的时间复杂度均为 O (1),不受数据量影响,这是栈高效性的核心保障。
- 空间复杂度
-
顺序栈:空间复杂度为 O (n),n 为预分配的容量,可能存在内存浪费
-
链式栈:空间复杂度为 O (n),n 为实际元素数量,但每个节点多一个指针的开销
- 实现方式选择
-
若元素数量固定且已知,优先选顺序栈(内存连续,访问快)
-
若元素数量动态变化或无法预估,优先选链式栈(避免溢出问题)
-
频繁入栈出栈场景下,两种实现性能差异可忽略,主要考虑容量需求
六、总结
栈作为一种简单而强大的数据结构,通过限制操作方式实现了高效的 “后进先出” 管理。其核心价值不在于存储数据,而在于对数据访问顺序的精准控制。无论是底层的程序运行机制,还是上层的应用功能实现,栈都扮演着不可或缺的角色。
性的核心保障。
- 空间复杂度
-
顺序栈:空间复杂度为 O (n),n 为预分配的容量,可能存在内存浪费
-
链式栈:空间复杂度为 O (n),n 为实际元素数量,但每个节点多一个指针的开销
- 实现方式选择
-
若元素数量固定且已知,优先选顺序栈(内存连续,访问快)
-
若元素数量动态变化或无法预估,优先选链式栈(避免溢出问题)
-
频繁入栈出栈场景下,两种实现性能差异可忽略,主要考虑容量需求
六、总结
栈作为一种简单而强大的数据结构,通过限制操作方式实现了高效的 “后进先出” 管理。其核心价值不在于存储数据,而在于对数据访问顺序的精准控制。无论是底层的程序运行机制,还是上层的应用功能实现,栈都扮演着不可或缺的角色。