二、Spark 开发环境搭建 IDEA + Maven 及 WordCount 案例实战
作者:IvanCodes
日期:2025年7月20日
专栏:Spark教程
本教程将从零开始,一步步指导您如何在 IntelliJ IDEA 中搭建一个基于 Maven 和 Scala 的 Spark 开发环境,并最终完成经典的 WordCount 案例。
一、创建 Maven 项目并配置 Scala 环境
1.1 新建 Maven 项目
首先,我们需要在 IDEA 中创建一个基础的 Maven 项目。
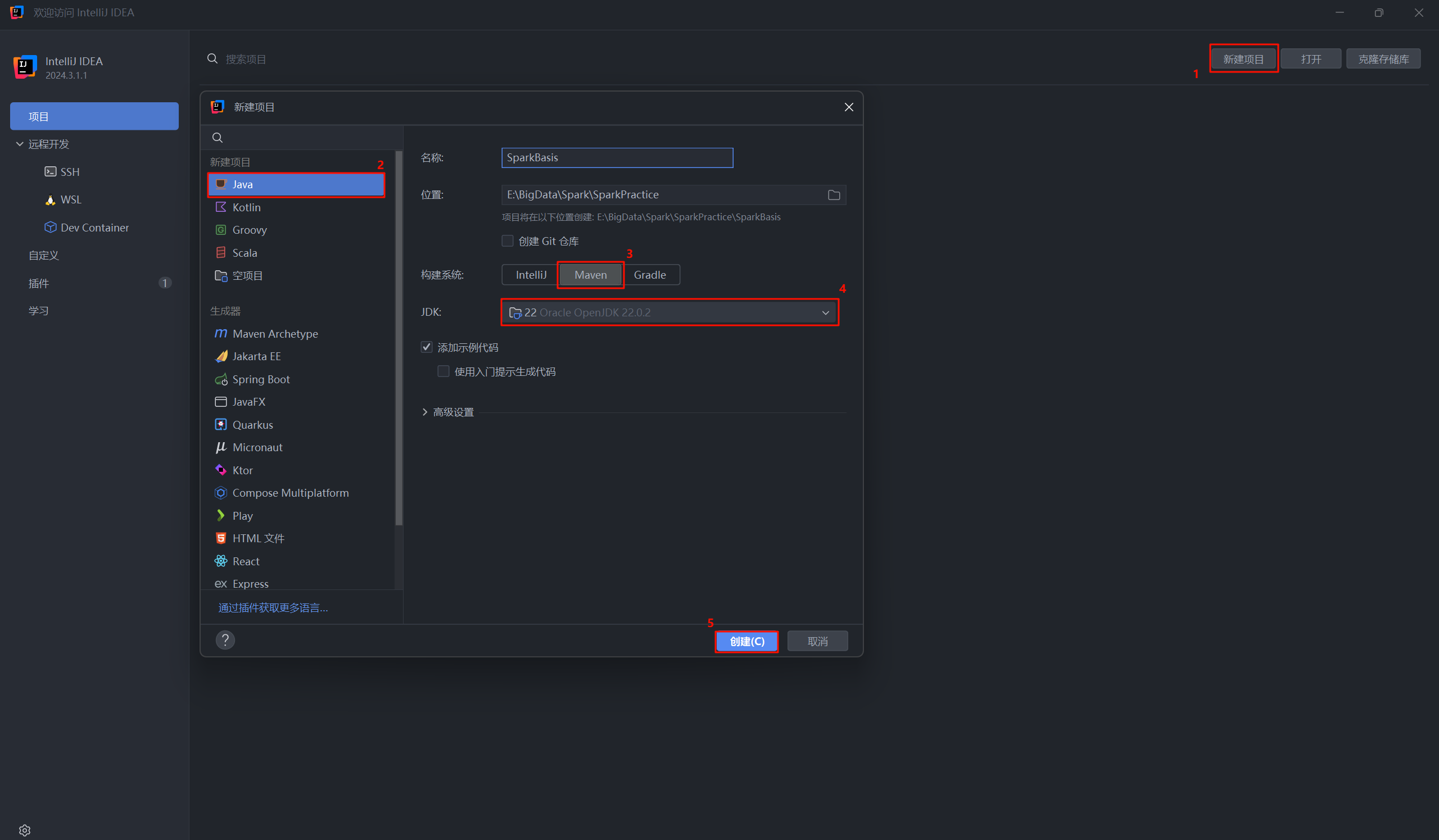
- 打开 IntelliJ IDEA,点击新建项目。
- 在弹出的窗口中,按照下图的数字顺序进行配置:
- 选择新建项目。
- 左侧列表选择 Java。
- 构建系统选择 Maven。
- 为项目选择一个 JDK,推荐JDK 11 (这里演示用 Oracle OpenJDK 22)。
- 点击创建。
1.2 为项目添加 Scala 框架支持
默认创建的是一个纯 Java 的 Maven 项目,我们需要为它添加 Scala 支持。
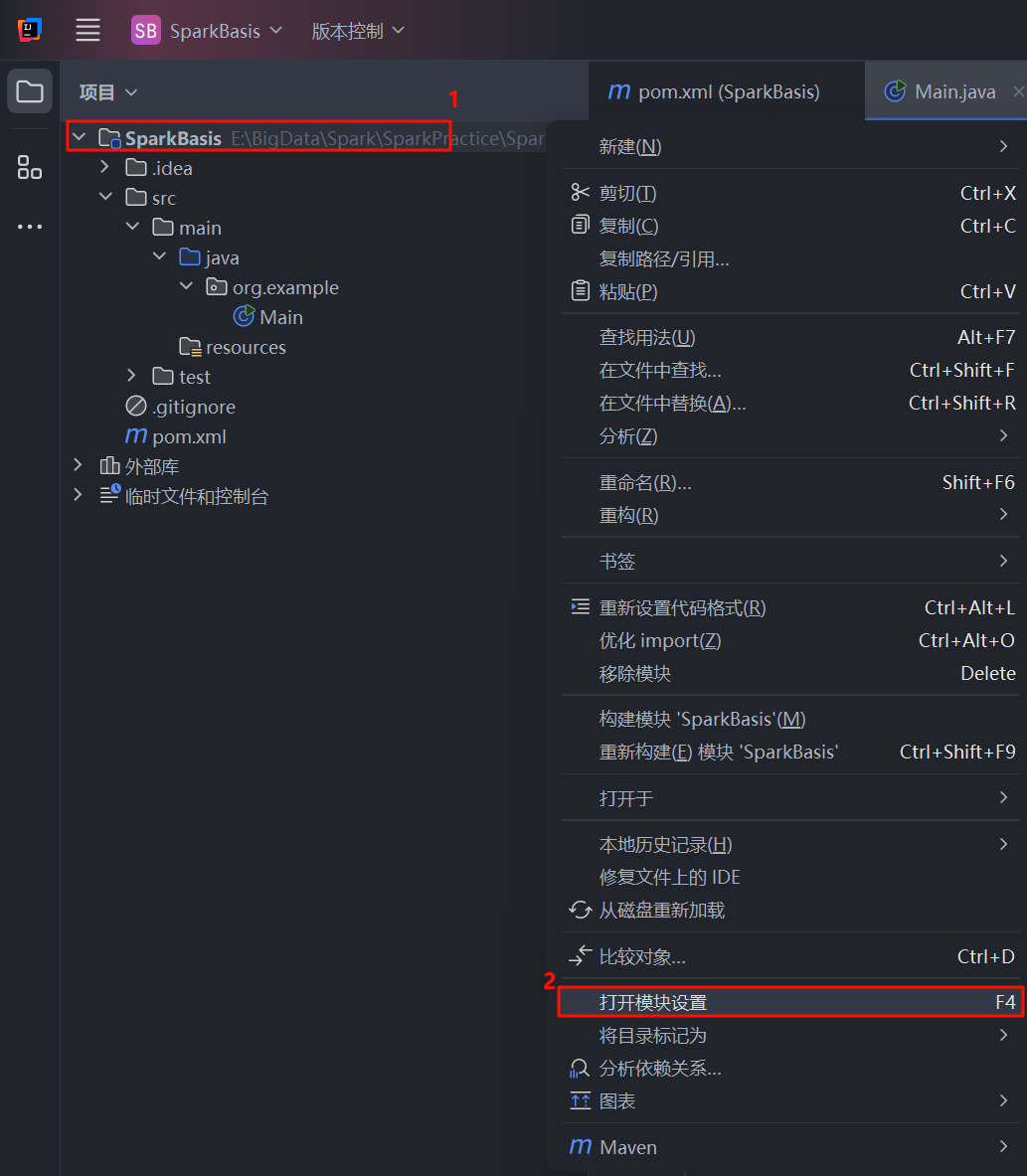
- 在项目结构视图中,右键点击项目根目录 (例如
SparkBasis,后面的SparkCore,SparkRDD等等其他的也同理)。 - 在弹出的菜单中选择打开模块设置 或按快捷键
F4。
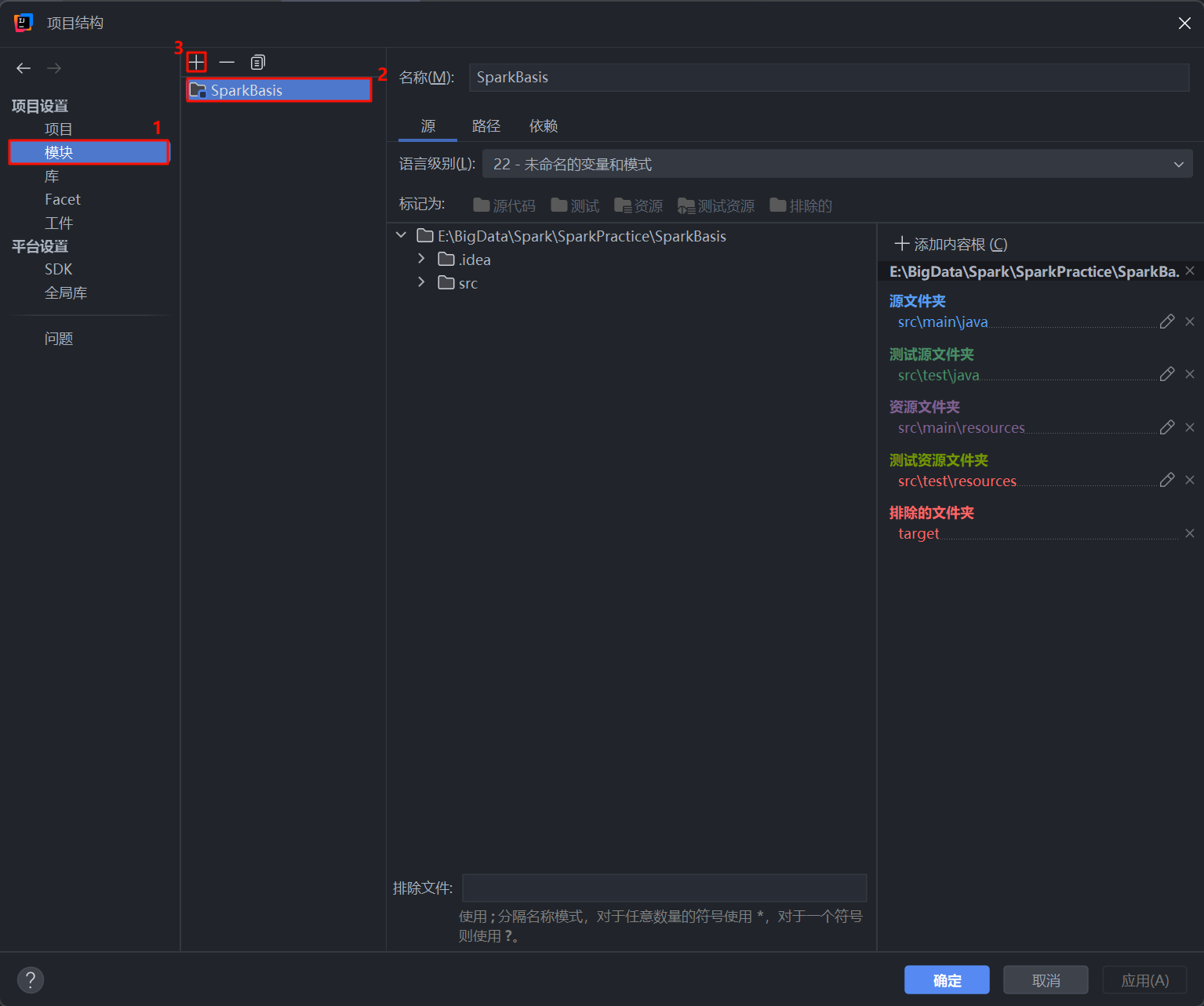
- 在项目结构 窗口中:
- 确保左侧选择了模块。
- 中间面板会显示当前的项目模块 (例如
SparkBasis)。 - 点击上方的 “+” 号按钮来添加框架。
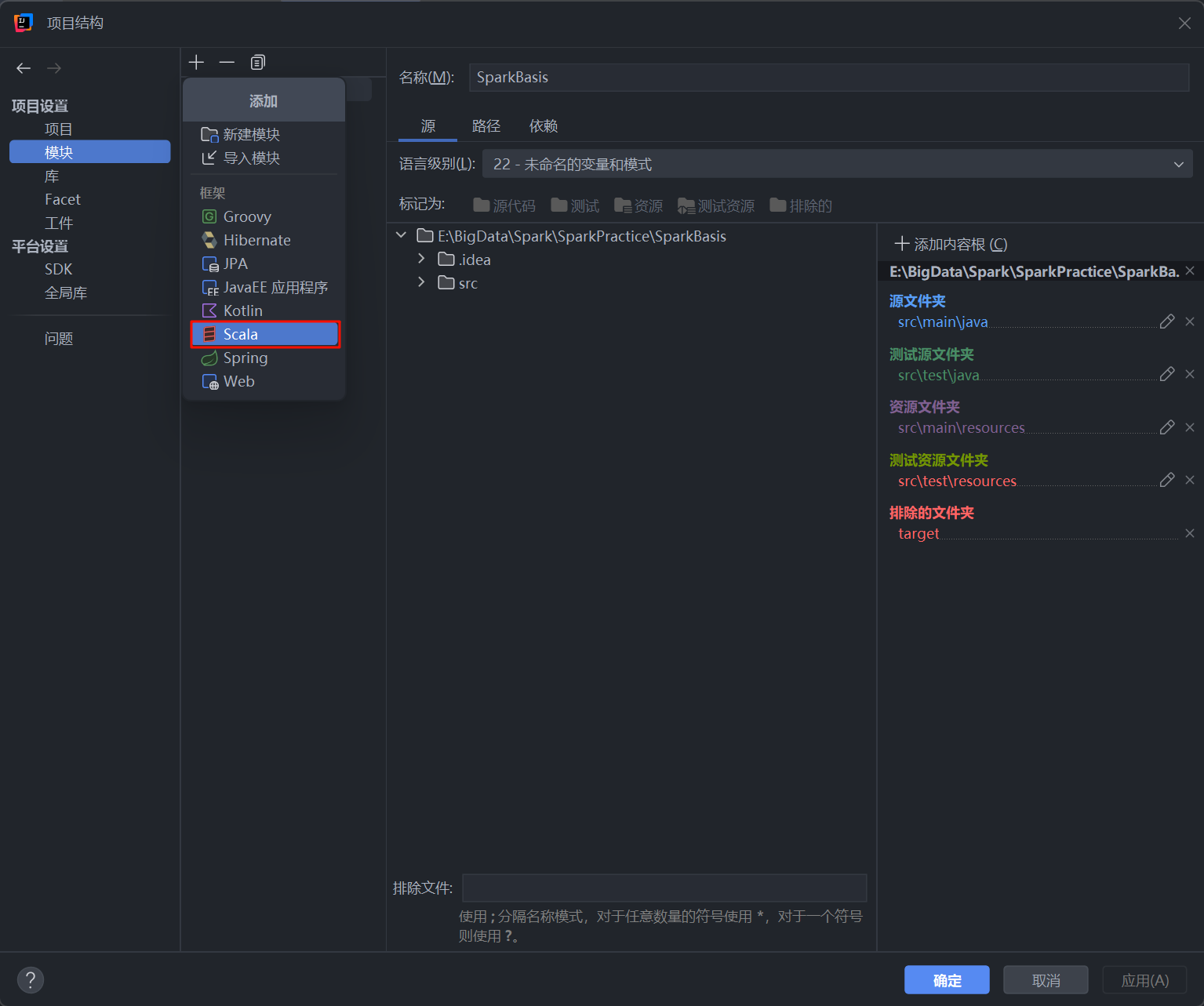
- 在弹出的菜单中,选择 Scala。
1.3 配置 Scala SDK
添加 Scala 框架后,IDEA 会提示你配置 Scala SDK。
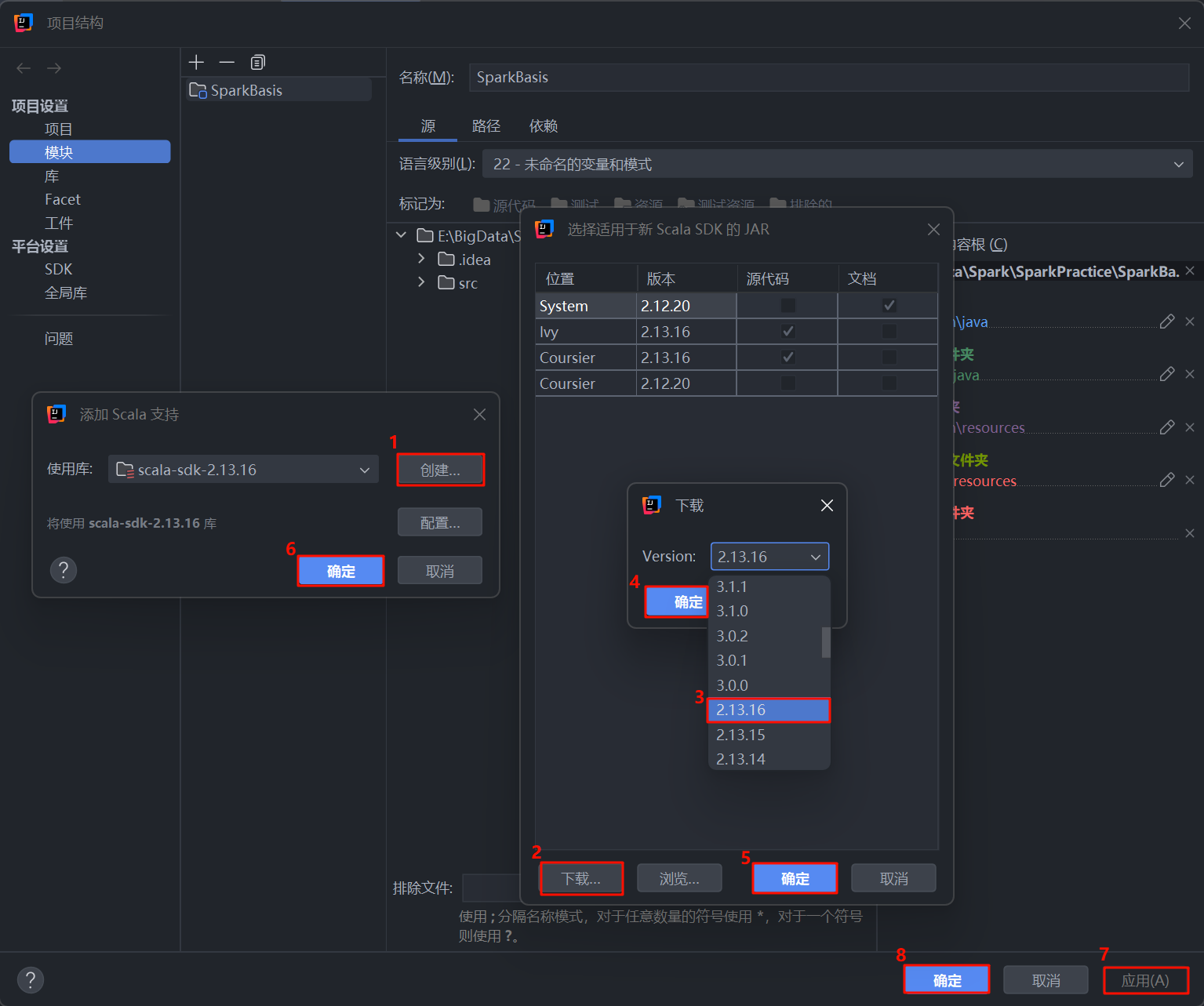
- 在弹出的“添加 Scala 支持”窗口中,按照下图的数字顺序操作:
- 如果“使用库”下拉框中没有可用的 Scala SDK,点击创建 按钮。
- 在下载 Scala SDK的窗口中,选择一个版本。非常重要:这个版本必须与你稍后要在
pom.xml中配置的 Spark 依赖版本相匹配。例如,Spark 3.x 版本通常对应 Scala 2.12 或 2.13。这里我们选择 2.13.16。 - 点击下载,IDEA 会自动下载并配置。
- 下载完成后,在选择 Scala SDK的窗口中确认版本。
- 点击确定。
- 返回到“添加 Scala 支持”窗口,再次点击确定。
- 最后,在项目结构窗口点击应用。
- 点击确定 关闭窗口。
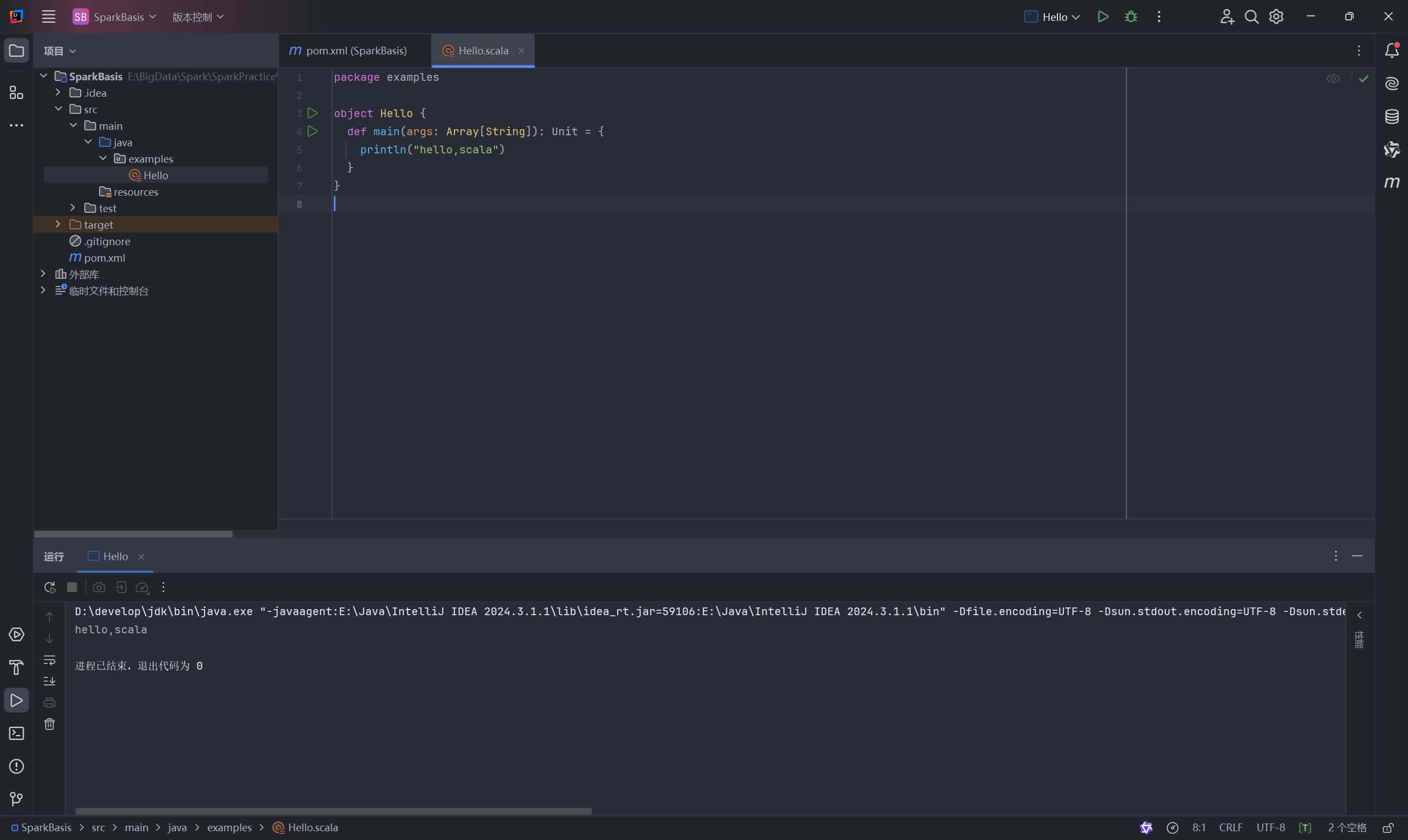
- 配置完成后,你的项目结构会发生变化,IDEA 会自动识别 Scala 源代码。你可以在
src/main目录下新建一个scala目录 (如果不存在),并将其标记为源代码根目录。可以创建一个简单的Hello.scala对象来测试环境是否配置成功。
二、配置 Maven 依赖与日志系统
为了使用 Spark 并拥有一个干净的运行环境,我们需要做两件事:1) 在 pom.xml 文件中添加 Spark 的相关库作为项目依赖;2) 配置日志系统,避免 Spark 运行时输出过多的调试信息。
2.1 配置 Maven 依赖 (pom.xml)
pom.xml 文件是 Maven 项目的核心配置文件,它告诉 Maven 我们的项目需要哪些外部库 (JARs)。
- 打开项目根目录下的
pom.xml文件。 - 在
<dependencies>标签内,添加spark-core和spark-sql的依赖。同时,为了避免 Spark 启动时出现关于SLF4J的警告,我们需要显式添加一个日志实现库,如slf4j-log4j12。 - 为了加速依赖下载,可以配置一个国内的 Maven 镜像仓库,如阿里云。
以下是完整的 pom.xml 核心配置代码:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><parent><groupId>org.example</groupId><artifactId>SparkBasis</artifactId><version>1.0-SNAPSHOT</version></parent><artifactId>SparkCore</artifactId><properties><maven.compiler.source>11</maven.compiler.source><maven.compiler.target>11</maven.compiler.target><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding></properties><dependencies><dependency><groupId>org.slf4j</groupId><artifactId>slf4j-log4j12</artifactId><version>1.7.32</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-core_2.13</artifactId><version>3.5.1</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-sql_2.13</artifactId><version>3.5.1</version></dependency></dependencies><repositories><repository><id>aliyunmaven</id><name>Alibaba Cloud Maven</name><url>https://maven.aliyun.com/repository/public</url></repository></repositories></project>
重要提示:
artifactId中的_2.13必须与您在第一步中配置的 Scala SDK 主版本完全一致。- Spark 的版本 (
3.5.1) 最好选择一个稳定且常用的版本。
编辑完 pom.xml 后,IDEA 通常会自动提示或在右上角显示一个Maven刷新图标,点击它让 Maven 重新加载项目并下载新添加的依赖。
2.2 配置日志属性 (log4j.properties)
当您首次运行 Spark 程序时,会发现控制台被大量的INFO级别日志刷屏,这些是 Spark 内部组件的运行日志,它们会淹没我们自己程序的输出结果,给调试带来困扰。
为了让输出更清爽,只显示警告 (WARN) 和错误 (ERROR) 级别的日志,我们可以通过添加一个 log4j.properties 文件来控制日志级别。
- 在项目的
src/main目录下,右键点击 -> 新建 -> 目录,创建一个名为resources的目录。 - 在
src/main/resources目录下,右键点击 -> 新建 -> 文件,创建一个名为log4j.properties的文件。
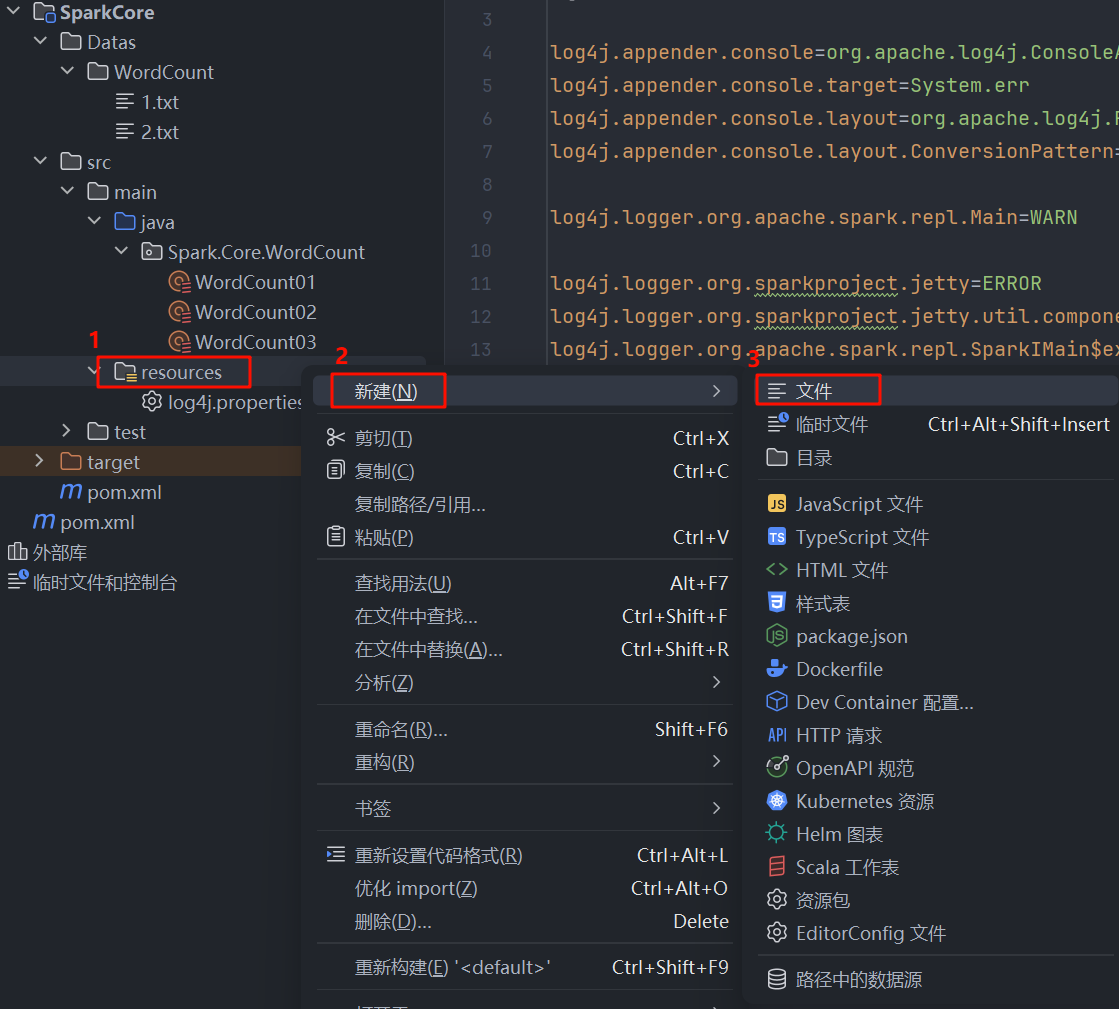
- 将以下内容复制到
log4j.properties文件中:
# 将根日志级别设置为ERROR,这样所有INFO和WARN信息都会被隐藏
log4j.rootCategory=ERROR, console# --- 配置控制台输出的格式 ---
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.target=System.err
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=%d{yy/MM/dd HH:mm:ss} %p %c{1}: %m%n# --- 为Spark-shell单独设置日志级别(可选) ---
# 运行spark-shell时,此级别会覆盖根日志级别,以便为shell和常规应用设置不同级别
log4j.logger.org.apache.spark.repl.Main=WARN# --- 将一些特别“吵”的第三方组件的日志级别单独调高 ---
log4j.logger.org.sparkproject.jetty=ERROR
log4j.logger.org.sparkproject.jetty.util.component.AbstractLifeCycle=ERROR
log4j.logger.org.apache.spark.repl.SparkIMain$exprTyper=ERROR
log4j.logger.org.apache.spark.repl.SparkILoop$SparkILoopInterpreter=ERROR
log4j.logger.org.apache.spark.parquet=ERROR
log4j.logger.parquet=ERROR
配置好这两个文件后,您的 Spark 项目就具备了必要的依赖库和一个清爽的日志环境,可以准备进行下一步的开发了。
三、Windows 环境配置 (解决 winutils.exe 问题)
在 Windows 系统上直接运行 Spark 代码,通常会因为缺少 Hadoop 的本地库而报错 (例如 NullPointerException)。我们需要手动配置 winutils.exe 和 hadoop.dll。
3.1 下载 winutils.exe 和 hadoop.dll
- 访问
winutils的 GitHub 仓库:https://github.com/cdarlint/winutils/ - 根据你使用的Hadoop版本选择对应的目录。重要提示:Spark 3.5.1 通常与 Hadoop 3.3.x 版本兼容。因此我们进入
hadoop-3.3.5/bin目录。- GitHub仓库链接:https://github.com/cdarlint/winutils/tree/master/hadoop-3.3.5/bin
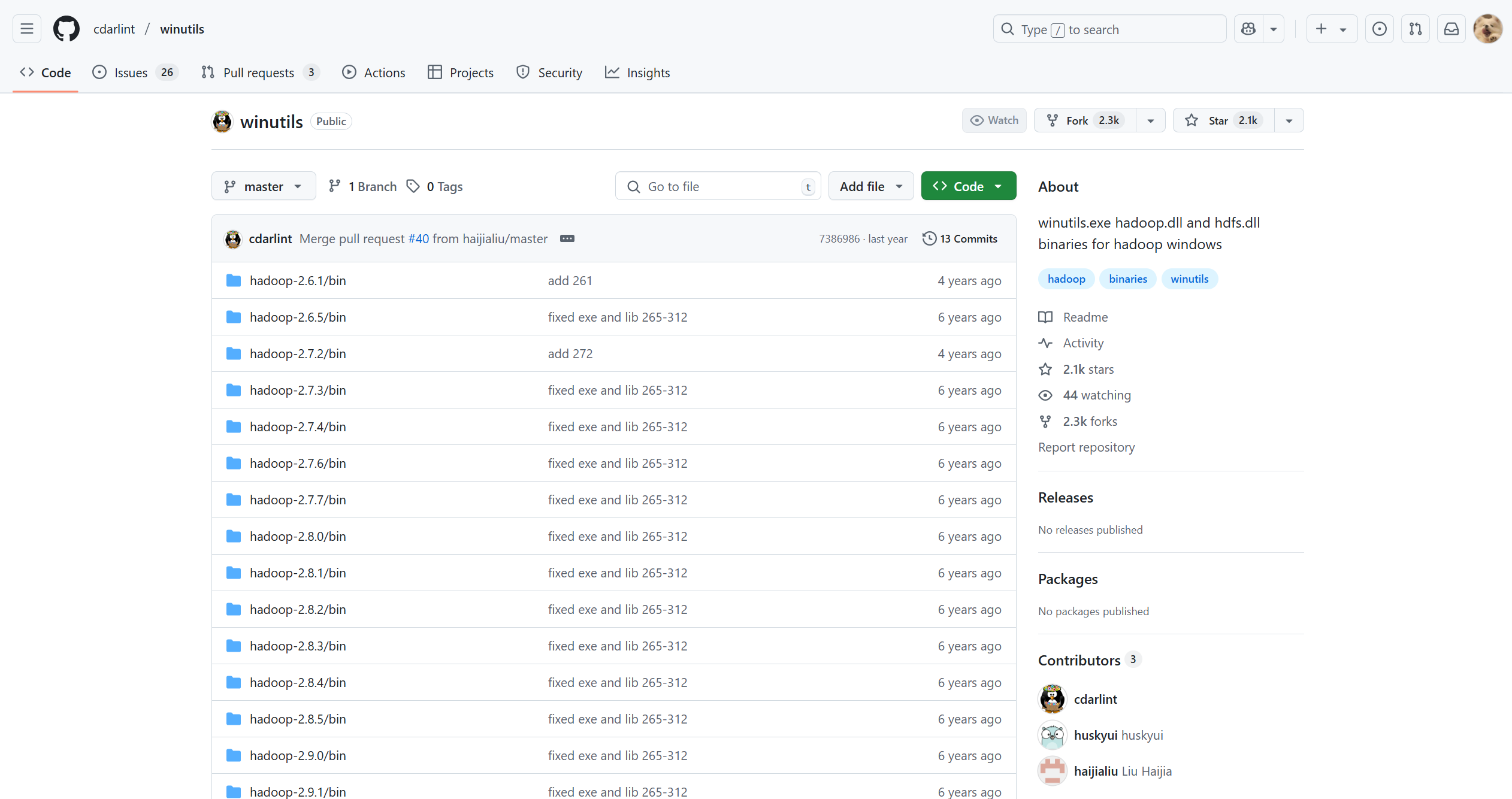
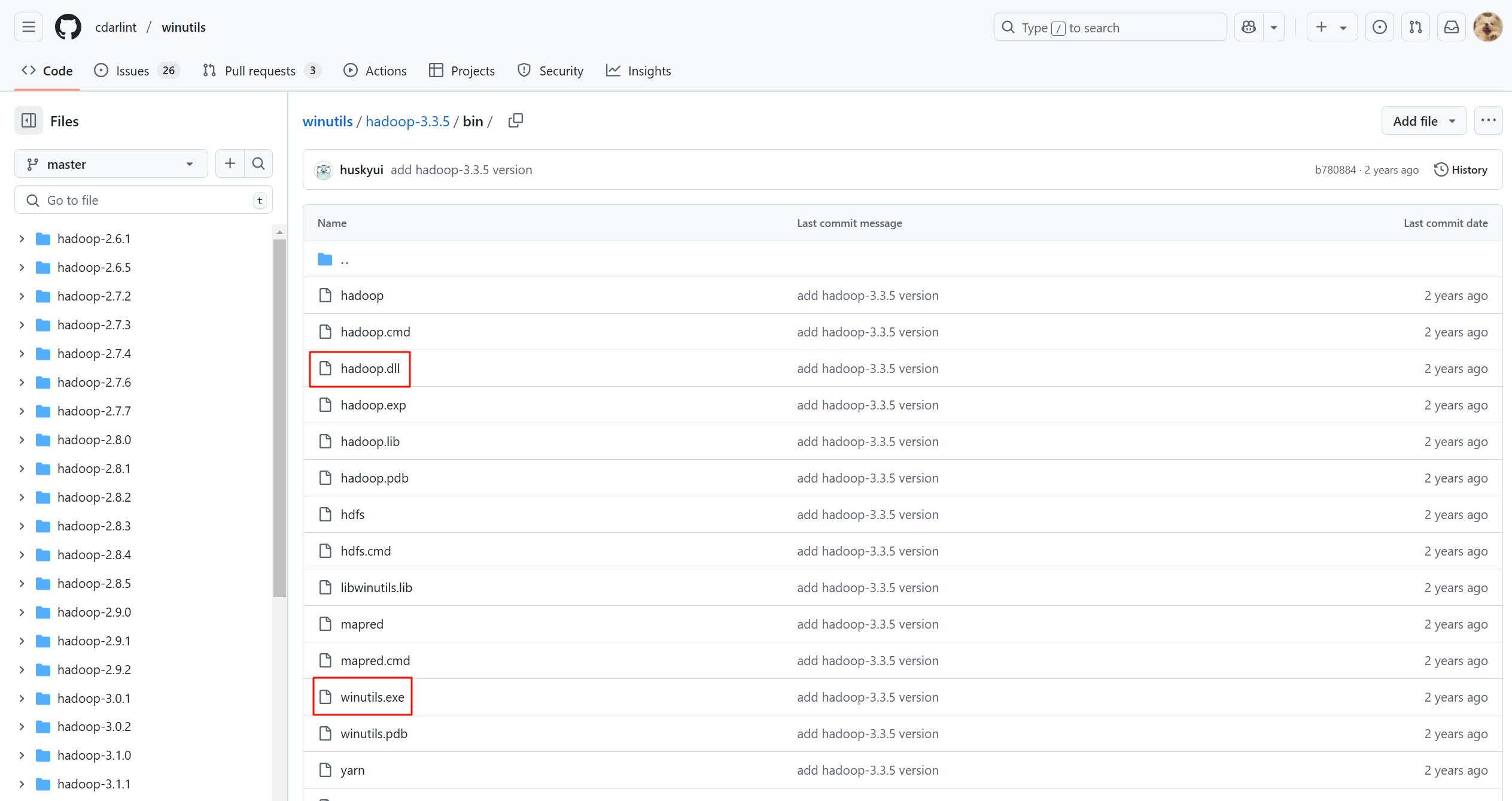
- 在该目录中,分别找到
hadoop.dll和winutils.exe文件,并点击下载按钮将它们保存到本地。
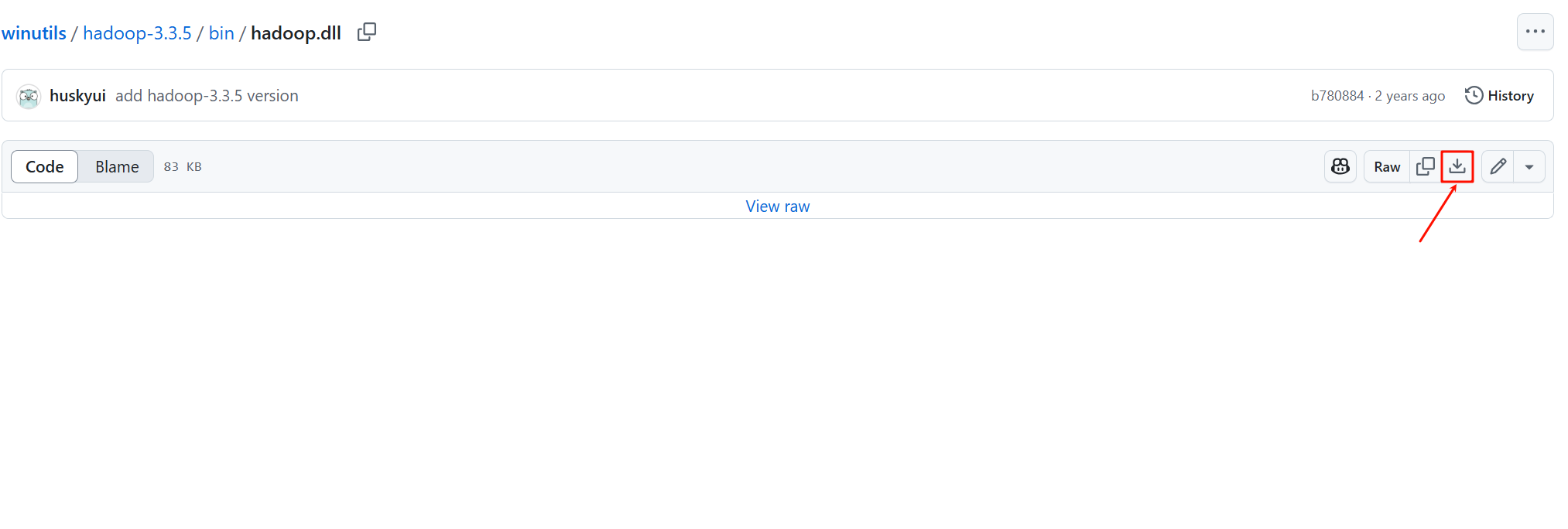
3.2 创建目录并放置文件
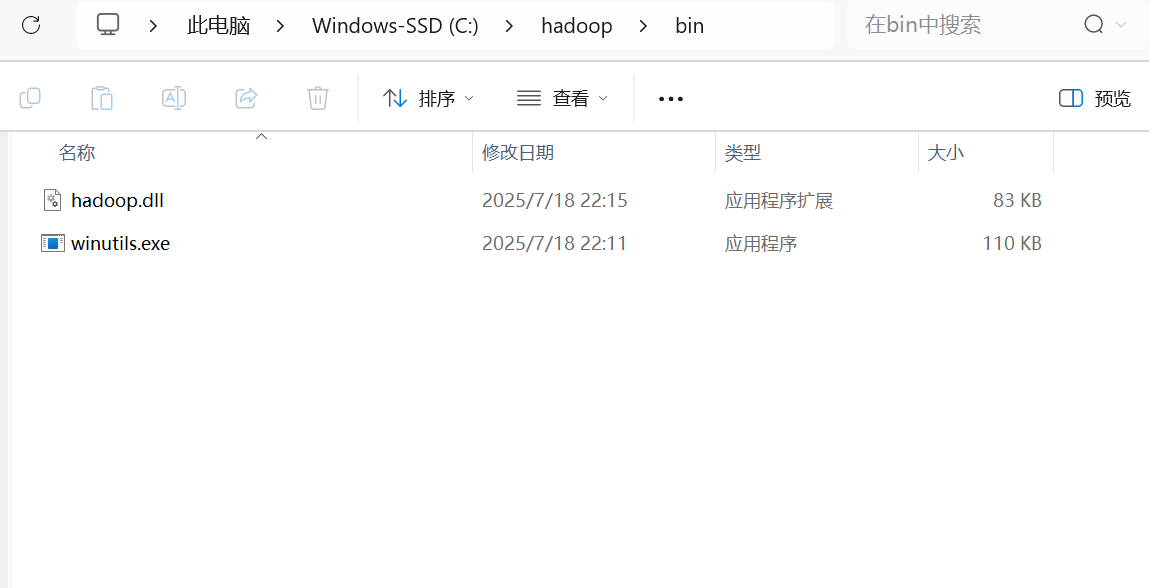
- 在你的电脑上创建一个不含中文和空格的路径作为 Hadoop 的主目录,例如
C:\hadoop。 - 在该目录下再创建一个
bin子目录,即C:\hadoop\bin。 - 将刚刚下载的
winutils.exe和hadoop.dll两个文件复制到C:\hadoop\bin文件夹中。
3.3 配置环境变量
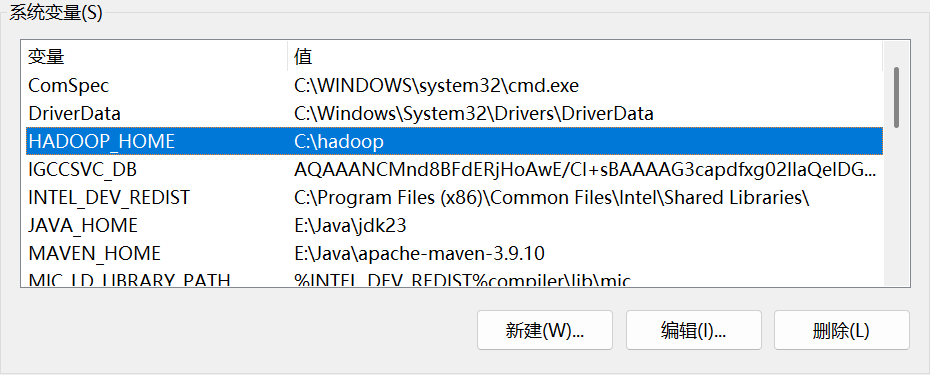
为了让系统和 Spark 能找到这些文件,需要配置两个环境变量:HADOOP_HOME 和 Path。
- 以管理员身份打开
PowerShell。 - 执行以下两条命令来设置系统级别的环境变量:
设置 HADOOP_HOME:
[System.Environment]::SetEnvironmentVariable('HADOOP_HOME', 'C:\hadoop', 'Machine')
将 HADOOP_HOME\bin 添加到 Path:
[System.Environment]::SetEnvironmentVariable('Path', ([System.Environment]::GetEnvironmentVariable('Path', 'Machine') + ';C:\hadoop\bin'), 'Machine')
- 配置完成后,重启 IntelliJ IDEA (甚至重启电脑) 以确保环境变量生效。
四、WordCount 案例实战
环境全部准备就绪后,我们来编写 WordCount 程序。
4.1 方法一:纯 Scala 实现
这种方法不使用 Spark,仅用 Scala 自身的集合操作来处理本地文件,用于对比和理解基本逻辑。
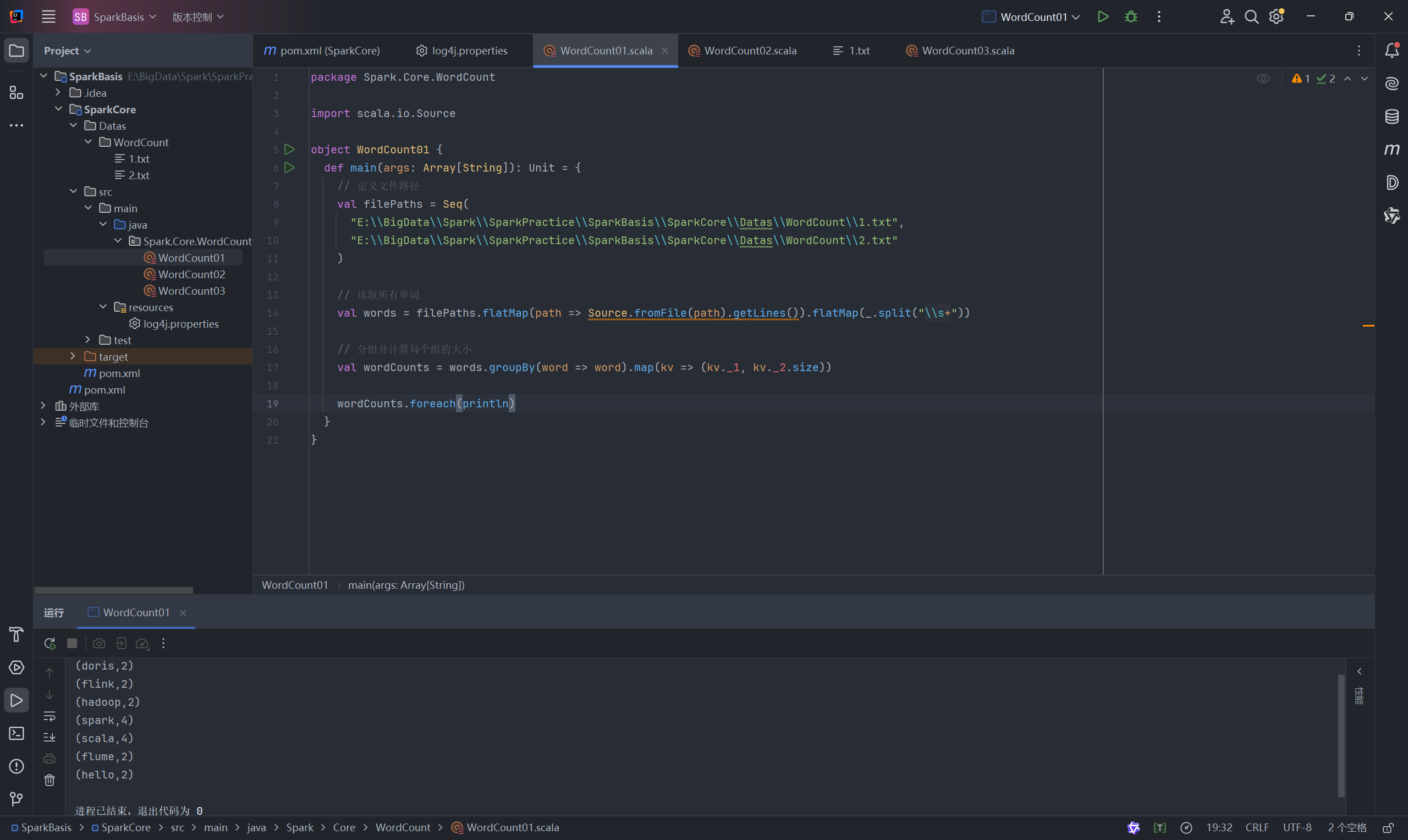
代码 (WordCount01.scala):
package Spark.Core.WordCountimport scala.io.Sourceobject WordCount01 {def main(args: Array[String]): Unit = {// 1、文件路径val filePaths = Seq("E:\\BigData\\Spark\\SparkPractice\\SparkBasis\\Datas\\WordCount\\1.txt","E:\\BigData\\Spark\\SparkPractice\\SparkBasis\\Datas\\WordCount\\2.txt")// 读取所有文件内容val words = filePaths.flatMap(path => Source.fromFile(path).getLines()).flatMap(_.split("\\s+"))// 将单词转换成键值对形式val wordcounts = words.groupBy(word => word).map(kv => (kv._1, kv._2.size))wordcounts.foreach(println)}
}
4.2 方法二:Spark RDD 实现 (使用 reduceByKey )
这是最经典、最高效的 Spark WordCount 实现方式。
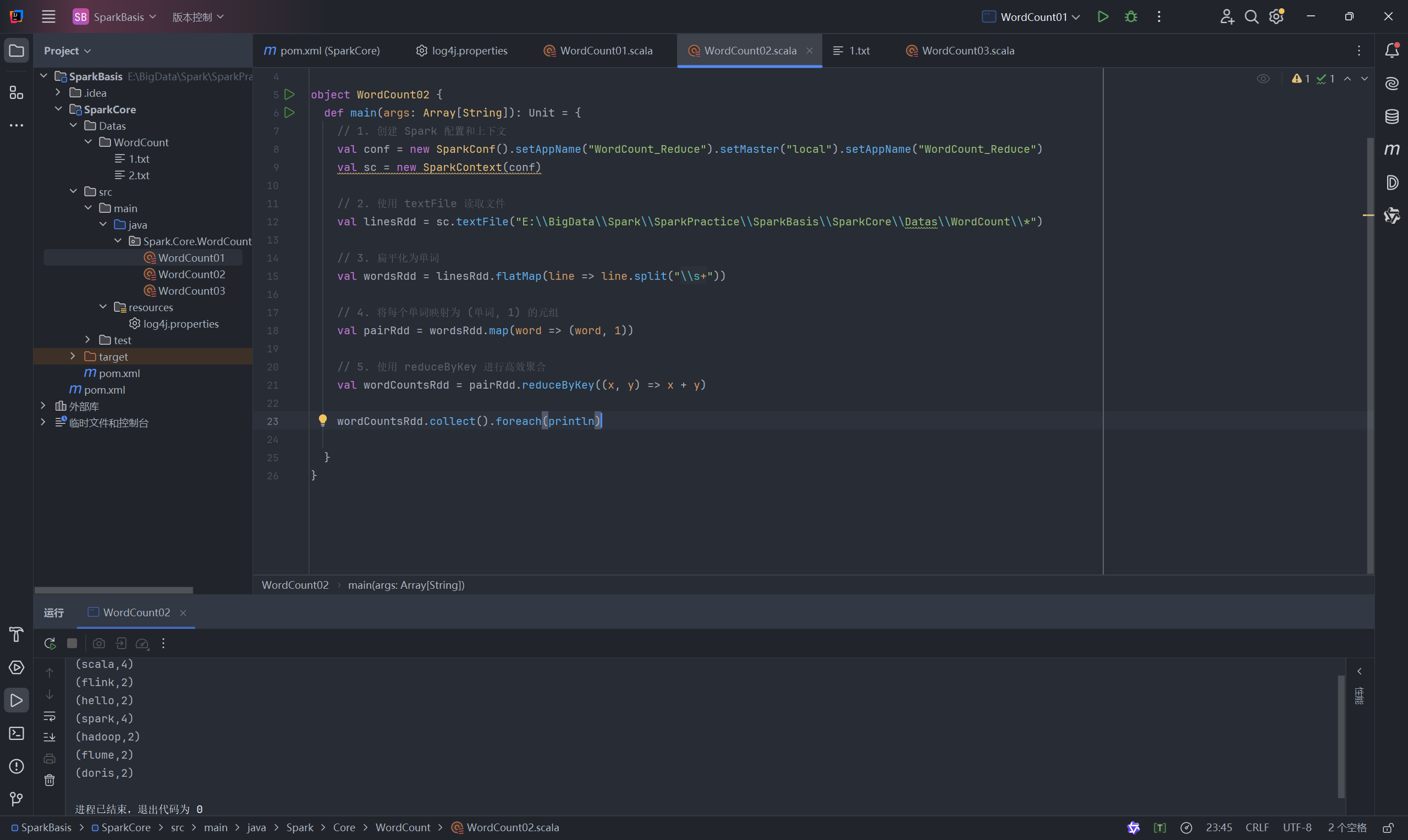
代码 (WordCount02.scala):
package Spark.Core.WordCountimport org.apache.spark.{SparkConf, SparkContext}object WordCount02 {def main(args: Array[String]): Unit = {// 1、创建 Spark 运行上下文val conf = new SparkConf().setAppName("WordCount_Reduce").setMaster("local[*]")val sc = new SparkContext(conf)// 2、读取 textFile 获取文件// 读取单个或多个文件val linesRdd = sc.textFile("E:\\BigData\\Spark\\SparkPractice\\SparkBasis\\Datas\\WordCount\\*")// 3、扁平化操作val wordsRdd = linesRdd.flatMap(line => line.split("\\s+"))// 4、结构转换(单词, 1)val pairRdd = wordsRdd.map(word => (word, 1))// 5、利用 reduceByKey 完成聚合val wordCountsRdd = pairRdd.reduceByKey((x, y) => x + y)wordCountsRdd.collect().foreach(println)sc.stop()}
}
4.3 方法三:Spark RDD 实现 (使用 groupByKey )
这种方法也能实现 WordCount,但通常性能不如 reduceByKey,因为它会导致大量的数据在网络中Shuffle。
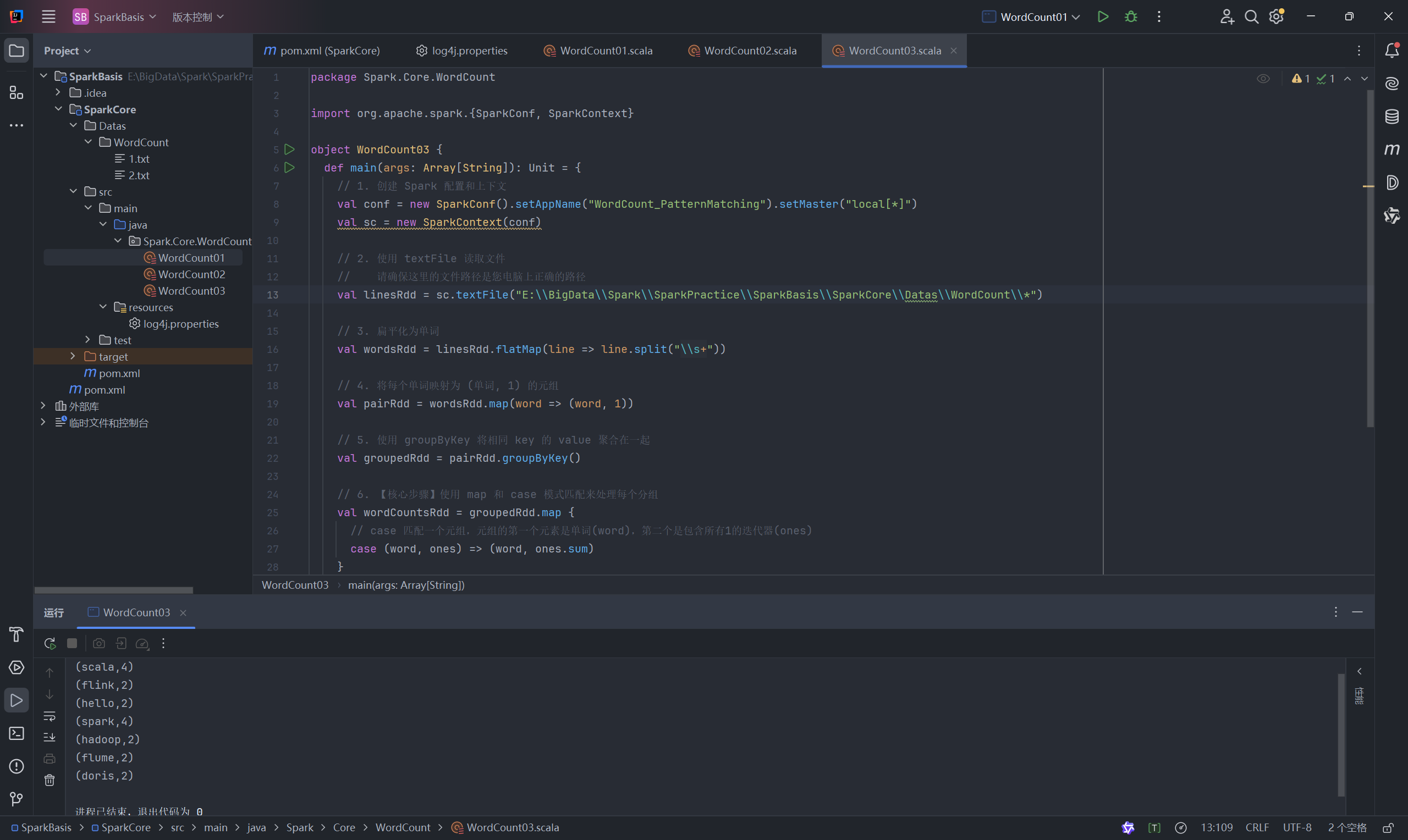
代码 (WordCount03.scala):
package Spark.Core.WordCountimport org.apache.spark.{SparkConf, SparkContext}object WordCount03 {def main(args: Array[String]): Unit = {// 1、创建 Spark 运行上下文val conf = new SparkConf().setAppName("WordCount_PatternMatching").setMaster("local[*]")val sc = new SparkContext(conf)// 2、读取 textFile 获取文件// 读取单个或多个文件val linesRdd = sc.textFile("E:\\BigData\\Spark\\SparkPractice\\SparkBasis\\Datas\\WordCount\\*")// 3、扁平化操作val wordsRdd = linesRdd.flatMap(line => line.split("\\s+"))// 4、结构转换val pairRdd = wordsRdd.map(word => (word, 1))// 5、利用 groupByKey 对 key 进行分组,再对 value 值进行聚合val groupedRdd = pairRdd.groupByKey()// 6、(自己选择) 利用 map 将每个元素处理成最终结果val wordCountsRdd = groupedRdd.map {case (word, ones) => (word, ones.sum)// case (word, ones) => (word, ones.size) // 对于 (word, 1) 的情况, .size 和 .sum 结果一样}wordCountsRdd.collect().foreach(println)sc.stop()}
}
总结
至此,您已经成功完成了在 IntelliJ IDEA 中搭建 Spark 开发环境的全过程,包括项目创建、Scala配置、Maven依赖管理,以及解决 Windows 环境下的关键问题,并通过三种不同的方式实现了 WordCount 案例。现在,您可以在这个强大的环境中开始您的Spark开发之旅了!