VOTE:基于轨迹集成投票的视觉-语言-动作模型优化
25年7月来自美国东北大学和硅谷创业公司 EmbodyX 的论文“VOTE: Vision-Language-Action Optimization with Trajectory Ensemble Voting”。
近期大规模视觉语言动作 (VLA) 模型在自然语言引导的机器人操作任务中展现出卓越的性能。然而,当应用于训练分布之外的新物体或陌生环境时,它们的泛化能力仍然有限。为了解决这个问题,许多现有方法集成了深度估计、分割甚至扩散等额外组件来提升泛化能力,但这会显著增加计算开销,导致效率低下。这促使人们探索高效的动作预测方法,这些方法不依赖于额外的高级视觉表示或扩散技术。本研究提出一个高效且通用的框架——VOTE,用于优化和加速 VLA 模型。具体而言,提出一种无 token 化器微调方法,用于并行精确的动作预测,从而降低计算开销并加快了推理速度。此外,采用集成投票策略进行动作采样,这显著提升模型性能并增强了泛化能力。实验结果表明,推理速度提高 35 倍,吞吐量达到 145 Hz。
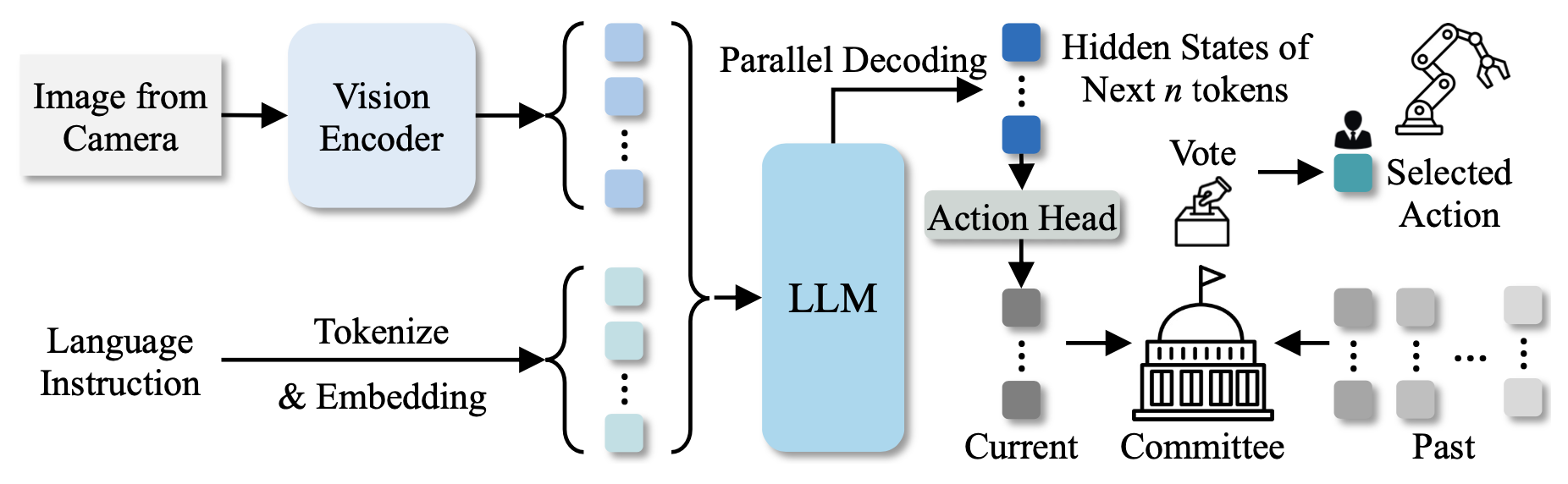
VOTE 模型如图所示,一个轻量级的 VLA 模型,利用集成投票(ensemble voting)策略来优化轨迹。为了在动作采样过程中实现更高的吞吐量和更快的推理速度,特意剔除额外的视觉模块,以获取额外的视觉信息,并摒弃基于扩散的技术。其模型完全基于 VLM 主干网络构建,移除动作 token化 器,并引入一个直接动作预测头来实现端到端的动作生成。具体来说,引入一个特殊的token化器 来表示整个动作块,从而显著减少生成的token化器数量。该策略避免了多次连续的解码器传递和token化,从而大大提高了效率。因此,它能够实现更快的推理速度并大幅降低训练成本,由于所需的输入输出token化器更少且解码过程更简单,因此快速微调也变得切实可行。同时,提出一种动作采样技术——集成投票,以提升模型在测试阶段的性能。
延迟分析
当前 VLA 模型 [12, 13, 15, 23] 的主要计算开销在于 VLA 架构中使用的 VLM 主干。在图左侧展示 SpatialVLA、CogACT 和 OpenVLA 的延迟分析。可以看出,VLM 的解码决定动作预测的延迟。尤其是 CogACT,由于 VLM 输出的动作解码使用了扩散过程,延迟显著增加。同时,SpatialVLA 依赖于多模态高级视觉表征,例如 3D 信息,这导致需要向 VLM 输入更多输入tokens,并且与没有额外视觉输入的方法相比,推理延迟显著增加。因此,VLM 推理和动作解码的高延迟促使人们探索一种优化的 VLA 模型动作预测方法,以避免依赖扩散或额外的视觉输入。
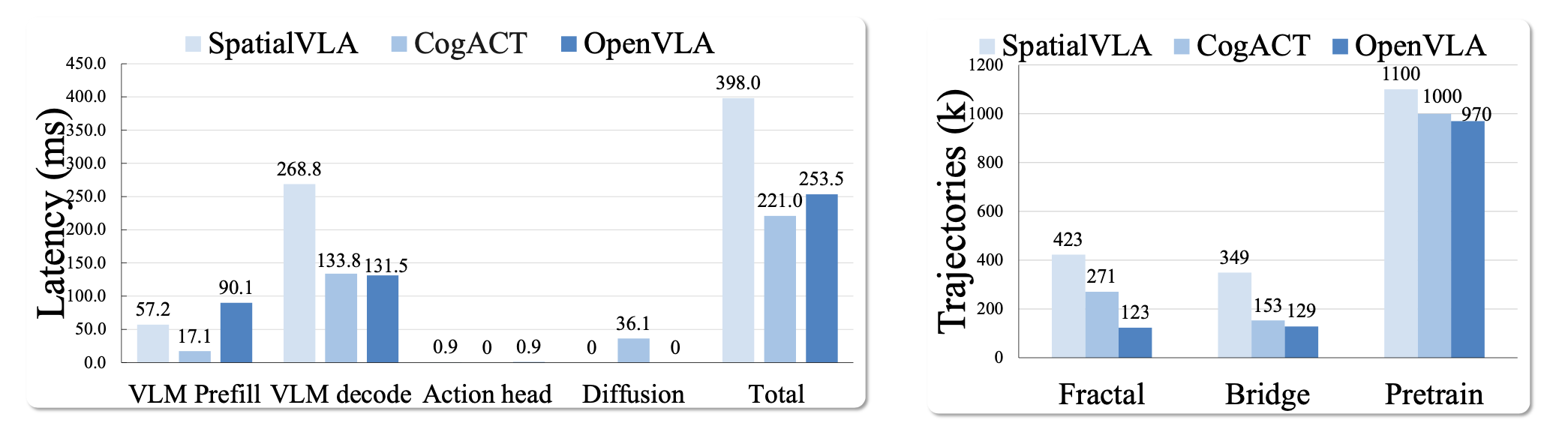
训练成本
VLA 模型通常使用来自新任务和实例的数据进行微调,以提高其在新环境中的性能 [15]。在上图的右侧,将 SpatialVLA、CogACT 和 OpenVLA 的训练成本与轨迹数量的关系绘制成图。现有方法依赖于大规模预训练数据来调整 VLM 主干模型以适应机器人动作预测任务。此外,所有方法都从 Fractal [3] 和 BridgeDataV2 [33] 获取额外数据进行进一步微调,从而提升泛化能力。然而,由于 SpatialVLA 和 CogACT 在其 VLA 模型架构中加入了额外的模块,因此它们需要比 OpenVLA 更多的额外数据。泛化所需的数据需求增加,导致微调过程中的计算成本大幅增加,这促使人们开发用于机器人动作预测的新型 VLA 模型,以最大限度地降低训练开销,并能够在数据有限的情况下快速适应新任务和实例。
前提
问题描述。模型基于图像 I 和语言指令 l 生成动作。对于时间步 t 的动作预测,利用模型 π 来预测执行所需任务的时间动作序列 (a_t, a_t+1, …, a_t+N)。
a_t 可以描述具有不同控制模式和末端执行器的各种机器人动作。遵循前文[12, 13, 15]中描述的策略,用 7 个自由度 (DoF) 来表示机械臂的末端执行器姿态,包括末端执行器的相对平移偏移量,旋转变化,夹持器的打开/闭合状态等。该动作空间能够对机械臂运动和末端执行器行为进行连续控制。
训练框架
概述。在训练过程中,LLM 的token化器中引入一个特殊token ,以明确指示动作预测任务。具体来说,将这个 token作为目标token标签附加到每个语言指令序列的末尾,记为 y_token。LLM 执行一次前向传递来生成这个token,并将对应于 的最后一层隐藏状态传递给动作头,以预测连续动作值 aˆ。
与原始 OpenVLA 不同,为了生成大量用于多个动作的token,训练模型输出一个特殊token ,从而显著减少输出token数量,从而加速训练。此外,没有像 OpenVLA、SpatialVLA 和其他方法那样使用token化器来获取动作token,而是直接利用动作头将特殊token 的隐藏状态映射到规范化的连续动作,从而实现高效的并行计算。
动作生成。给定一条语言指令 l 和对应的图像 I,该模型生成多个连续的动作预测。首先,输入数据经过 VLA 模型处理,得到隐状态。接下来,提取与特殊动作 token 对应的隐状态。注:这里的模型只需生成一个 token ,而不是为各种多维动作生成多个 token。
然后,需要将 的隐状态转换为实际的动作预测。这可以通过动作头来实现。具体来说,将获得的隐状态 h_ 传递给 MLP 动作头,以预测动作块(多个连续的动作)。
为了实现高效的并行计算,这些动作是通过 MLP 动作头获得的,而不是像传统 VLA 模型中那样使用计算密集型解码的token化器。
训练目标。训练目标结合 token 级和动作级的监督。用 L1 损失来衡量预测动作与真实动作之间的差异,记为 L_action。这两个损失合并为一个加权总损失,以平衡语言建模的语义理解和准确的动作生成。L_token 是基于 token 和所有指令 token 预测计算的交叉熵损失。
训练和推理的优势。本方法使用单个 token 将整个动作块压缩为一个紧凑的高级表示。该 token 的隐状态通过动作头传递,直接预测所有动作块。这显著减少了所需的 token 数量,从而提高了训练和推理的效率。
具体而言,对于动作维度为 D、时间步长为 N 的块(即 N 个连续动作预测),该方法生成单个 token 的隐状态,而不是 OpenVLA-OFT 中的 ND 个隐状态。此外,使用动作头从隐状态生成动作时,只需要一次前向传递,而不是 OpenVLA 中的 ND 次连续解码器前向传递。此外,采用本文方法,由于输出 token 数量显著减少,在 OpenVLA-OFT 训练期间无需填充 N 个空动作嵌入作为输入。由于机器人模型通常需要对新数据进行微调才能推广到新的目标和环境,因此传统 VLA 的训练成本通常很高。然而,通过该方法,可以快速微调一个满意的模型,并且训练成本要低得多,因为训练输入和输出 token 的数量减少了,解码速度也更快了。
集成投票
在推理过程中,VLA 模型会预测跨多个时间步的一系列动作。通常,机器人会根据当前观察结果直接执行当前时间步的动作,并丢弃之前时间步的历史动作预测。然而,这种方法未能充分利用历史视觉信息和模型预测,导致轨迹不稳定,并可能降低性能。
为了解决性能下降的问题,提出一种基于投票的自适应集成策略来进行动作聚合,该策略从相邻时间步的预测列表中选择更频繁的预测(正确率更高)。具体而言,给定观察值 o_t,令 (a_t|o_t) 表示当前时间步 t 的预测动作。由于模型为每个时间步提供连续动作预测列表,因此在当前时间步 t,之前时间步的动作预测也可用,表示为:H = {(a_t|o_t−K),…,(a_t|o_t)}。在时间步长 t 执行的集成动作 aˆ_t 是通过根据所选动作与当前预测的余弦相似度对其进行平均计算。
如图所示,这里计算每个先前动作与当前/最新预测 (a_t|o_t) 之间的相似度。基于所有这些相似度,将动作集 H 拆分为两个子集:M 表示相似度较高,N 表示相似度较低。根据投票规则,选择得票较多的子集,并计算所选子集中所有动作的平均值,作为时间步 t 的最终动作。
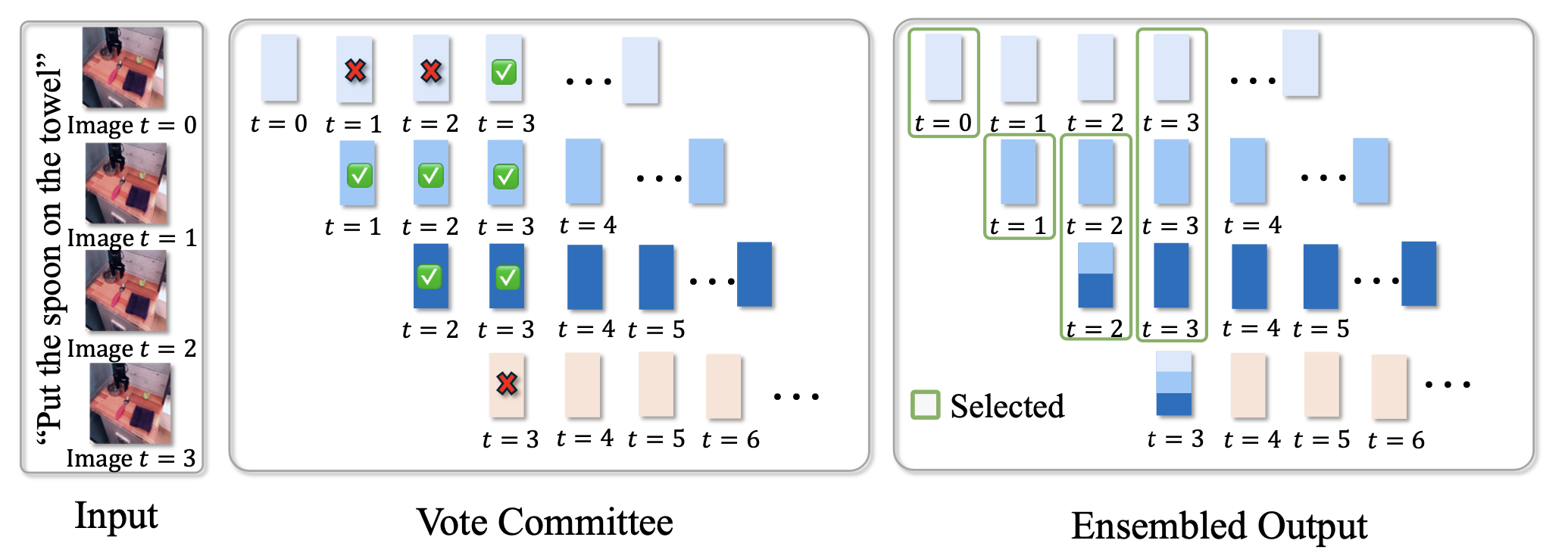
优势。基于投票的集成方法具有自适应性,正确率更高。(i) 与简单的平均或静态加权聚合方法不同,其方法能够自适应地自动选择更多已投票的动作(因此更有可能正确)。(ii) 虽然计算 H 中所有动作平均值的简单平均方法很简单,但它可能会将错误的预测考虑在内,从而导致性能下降。与平均方法不同,投票集成有效地滤除不合理或不一致的预测,从而增强最终聚合动作的可靠性和鲁棒性。(iii) 该方法更加关注或重视当前/最新的动作预测,因为所有相似度都是参考当前动作计算的,并且对高相似度动作投出一票。这是合理的,因为当前观察提供了更多关键的实时信息。(iv) 实验表明,其方法可以优于简单的平均或静态加权聚合方法。
在 LIBERO [20] 和 SimplerEnv [18] 模拟基准测试集上评估模型,这两个基准测试集包含模拟环境中的多种机器人操控任务。所有模拟评估均在 NVIDIA RTX A6000 和 H100 GPU 上进行。用 AdamW 对 OpenVLA 模型进行微调,学习率为 1 × 10−4。微调采用低秩自适应 (LoRA) [9],秩 r = 32,α = 16。
LIBERO 的训练细节。对于 LIBERO,在 A6000 GPU 上进行训练,全局批量大小为 40。默认情况下,模型经过微调,输出一个 token,块大小为 8。对于大小为 16 的动作块,预测两个 token,每个 token 解码 8 个动作。
SimplerEnv 的训练细节。对于 SimplerEnv 中的 WidowX 机器人模拟,在 BridgeDataV2 数据集 [33] 上使用 162,000 条轨迹进行微调,在 NVIDIA H100 GPU 上使用全局批次大小 96 进行 70,000 步。动作块大小 N 和集合范围 K + 1(包括当前预测)均设置为 5,与 OpenVLA-OFT 配置一致。对于 SimplerEnv 中的 Google 机器人模拟,在 Fractal 数据集 [3] 上使用 200,000 条轨迹进行微调,在 NVIDIA H100 GPU 上使用全局批次大小 144 进行 70,000 步。动作块大小 N 和集合范围 K + 1 均设置为 4,与 SpatialVLA [23] 一致。
基线。将模型与最先进的操作策略进行比较,包括 RT-1 [3]、RT-1-X [21]、RT-2-X [21]、Octo [32]、OpenVLA [12]、HPT [34]、TraceVLA [43]、RoboVLM [17]、Dita [8] 和 SpatialVLA[23]。RT-1-X、RT-2-X、Octo、OpenVLA、HPT、TraceVLA、Dita 和 RoboVLM 均使用 OXE 数据集 [21] 的混合数据进行训练。SpatialVLA 在由 OXE [21] 和 RH20T [7] 的子集组成的混合数据集上进行了预训练,并在 BridgeDataV2 [33] / Fractal 数据集上进行了微调,以进行 SimplerEnv 评估。