RocketMq集群高可用
RocketMq部署模式简介-CSDN博客
从上面章节可以了解到,RocketMq集群有两种模式,一种是主从节点固定身份的模式,一种是可以自主选择主节点的Dledger集群。
那么Dledger集群是如何实现通信?如何实现自主选择主节点,实现高可用的呢?
另外,主从模式和Deldger集群还存在哪些问题?RocketMq这对这些问题又提出了哪些解决方案?
分布式集群特性
分布式集群需要解决的主要问题:
- 故障自动转移,保证系统高可用
- 数据一致性
分布式集群影响数据一致性的核心问题:
- 服务不稳定:Server可能宕机
- 网络抖动:可能导致请求数据丢失
- 网速问题:数据在Server之间的传输速度不一致,难以保证数据的顺序。分布式场景是要保证集群内最终反馈出来的数据是一致的。但是数据的变化通常跟操作顺序有关。所以,还需要引入操作日志集,并保证日志的顺序,才能最终保证集群对外数据的一致性。
- 快速响应:Server对客户端的响应不应该受限于集群中最慢的节点
解决数据一致性的算法
- 弱一致性算法:DNS系统、Gossip协议(使用场景:Fabric区块链,Cassandra,RedisCluster,Consul)
- 强一致性算法:Basic-Paxos、Multi-Paxos包括Raft系列(Nacos的JRaft,Kafka的Kraft以及RocketMQ的Dledger)、ZAB(Zookeeper)
Dledger
RocketMQ的Dledger其实也是基于Raft协议诞生的一种分布式一致性协议。
RocketMQ中的Dledger其实是一个外来品,来自于OpenMessage这样一个开源组织。而Dledger其实是一个保证分布式日志一致性的小框架,RocketMQ把这个小框架用在了自己的日志文件同步场景。
Raft协议
网上有个动画文稿,是对Raft算法最生动形象的描述。地址:http://thesecretlivesofdata.com/raft/
Raft协议的两个核心:
- Election选举:集群中选举产生主节点
- Log Replication日志同步:数据同步
选择主节点
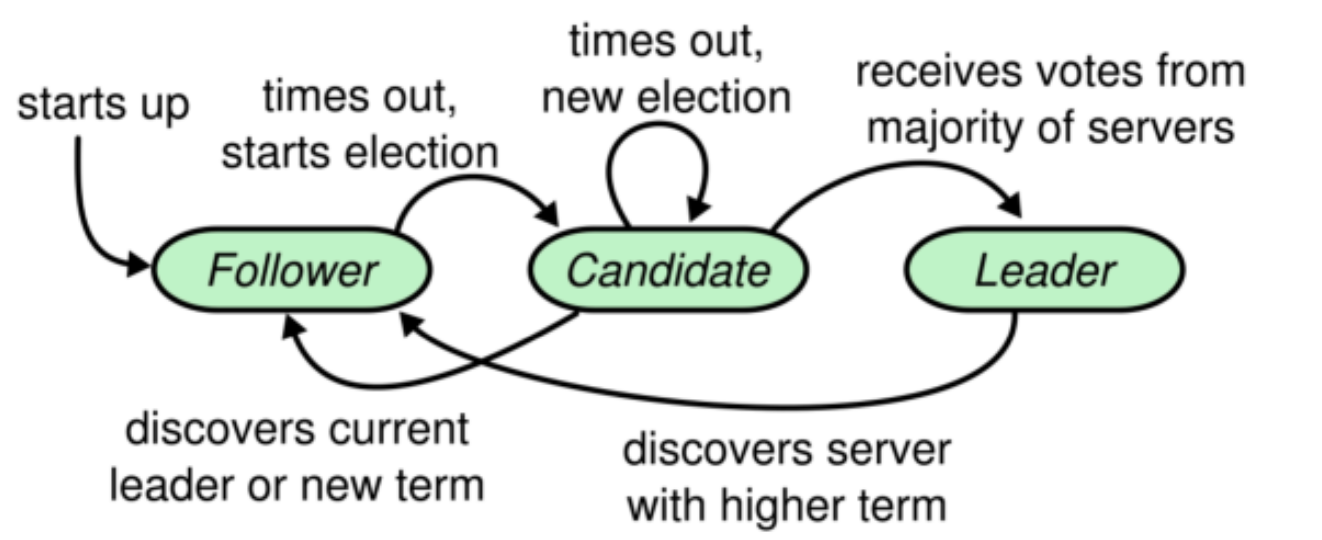
Raft协议给每个节点设定了三种不同的状态,Leader,Follower和Candidate。
选举过程:
注意两个过期时间:
- election timeout:选举过期时间,通常会设定为⼀个随机值,⼀般在 150ms到 300ms之间。
- heartbeat timeout :心跳超时时间
1、所有节点启动时都从 Follower 状态开始。
2、每个Follower 设定了⼀个选举过期时间Election Timeout 。Follower持续等待Leader 的⼼跳请求。如果超过选举过期时间,就转为 Candidate,向其他节点发起投票,竞选 Leader。
3、Candidate 开始新⼀个任期的选举。每个 Candidate 会投⾃⼰⼀票,然后向其他节点发起投票 RPC 请求。然后等待其他节点返回投票结果。等待时⻓也是Election Timeout。
- 如果两个节点过期时间一样,或者差的极其小(概率低),两个节点开启的任期id一样。
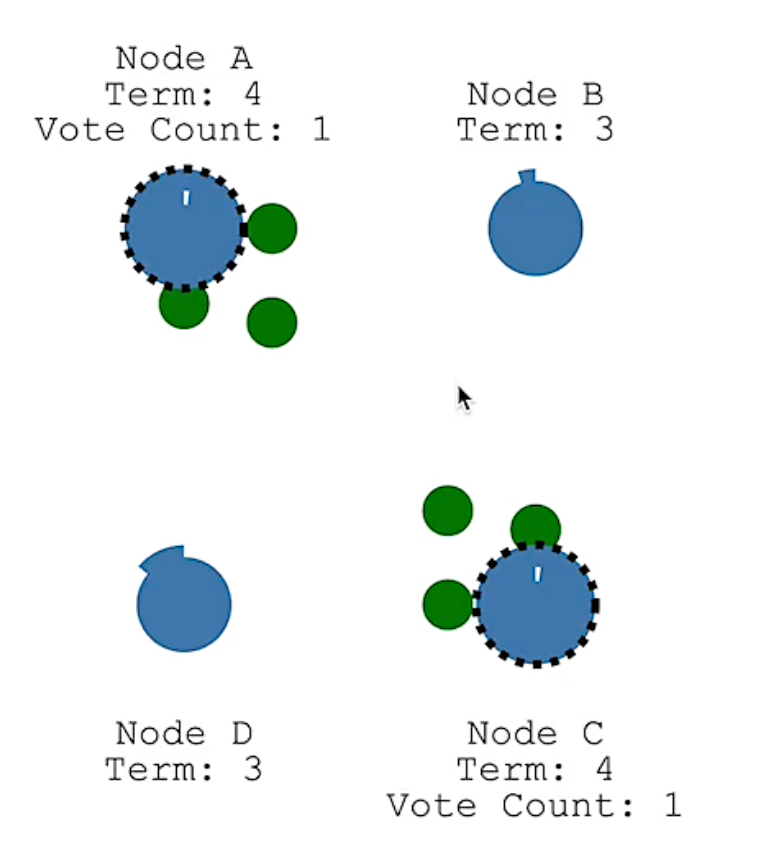
4、每个节点在每⼀个任期内有⼀次投票的资格。他们会响应Candidate的投票请求。按照一定的规则返回⽀持或者不⽀持。投了支持票后会重置自己的过期时间。
- Follower节点在收到心跳检测请求时也会重置自己的过期时间。
- Follower节点在收到数据同步请求时也会重置自己的过期时间。
- 一定的规则是什么:基本规则是,如果我在这个item任期内没有投过票,就投给发起请求的节点。详细规则可以由具体实现方自己定。因为Raft是一种思想,需要具体业务方实现。
5、⼀旦应某⼀个 Candidate 接收到了超过集群⼀半节点的投票同意结果后,就会转为 Leader 节点。并开始向其他节点发送⼼跳 RPC 请求。确认⾃⼰的 Leader 地位。
- Candidate如果没有超过半数的投票且集群也没有选出其他Leader,会重新设置一个election timeout,准备进入下一次选举。下一次选举任期也会增加1.
- Candidate确定了Leader地位后,重置选举过期时间吗?Leader关注选举过期时间没有意义。
6、其他节点接收到 Leader 的⼼跳后,就会乖乖的转为 Follower 状态。 Candidate 也会转为 Follower 。然后等待从 Leader 同步⽇志。直到 Leader 节点⼼跳超时或者服务宕机,再触发下⼀轮选举,进⼊下⼀个 Term任期。
数据同步
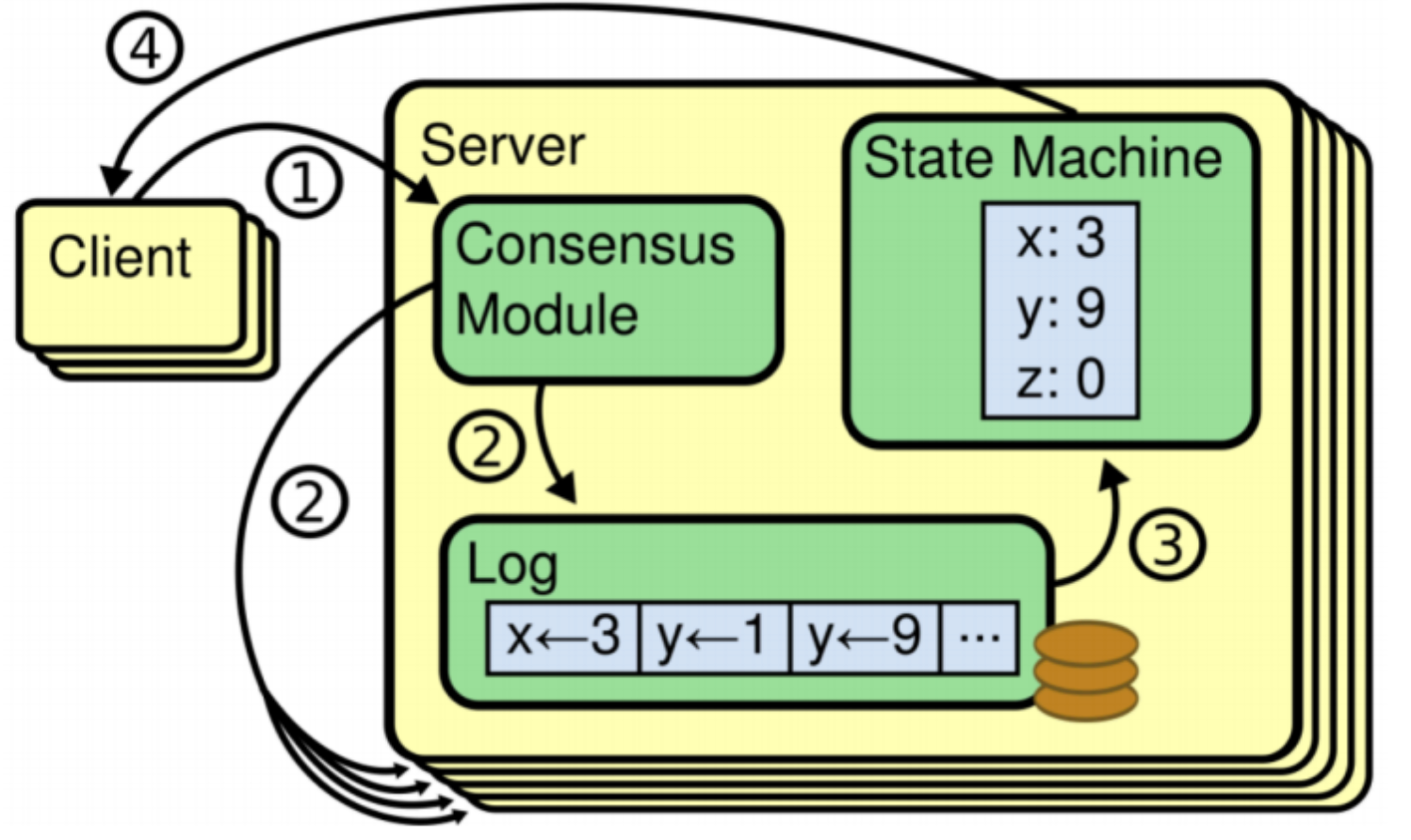
数据同步中的两个核心模块:
- Log日志:保存在Server上的操作日志,每个条目成为Entry. 保证了Entry的顺序,但是不保证Entry不丢失。
- State Machine: Entry所有的操作最终落地到State Machine中。
数据同步过程:
- Leader节点负责响应客户端的请求, 对于写请求,将请求指令以Entry的形式保存在自己的Log中
- Leader节点将请求指令跟随心跳检测发送到集群所有Follwer节点
- Follwer节点将指令以 Entry 的形式保存到自己的 Log 日志当中,此时 Entry 是uncommited状态。然后给Leader返回一个响应,通知Leader执行我保存成功了,同时也是承认Leader的地位
-
Leader收到多数Follwer节点共同保存了 Entry 的响应后, 就将本节点Log 的Entry提交到State Machine 状态机中,Entry 更新为commited状态。同时对客户端响应成功。
-
Leader向Follwer同步commit指令,Follwer也将自己Log 的Entry提交到State Machine 状态机中,Entry 更新为commited状态。
防止脑裂
Raft为了方式脑裂问题,增加一个Term任期的概念。
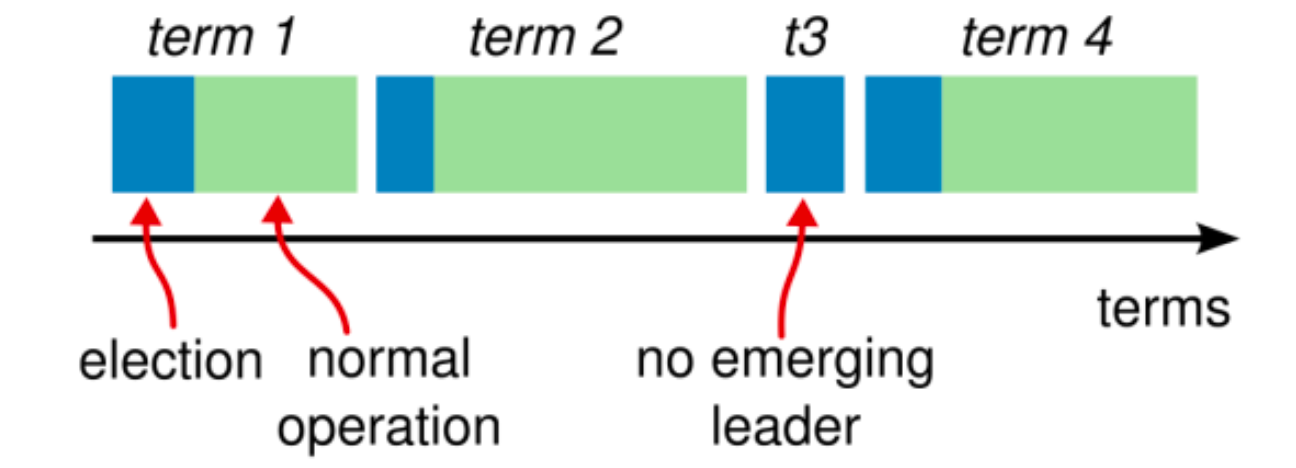
在出现网络分区时,集群中可能出现多个Leader节点:
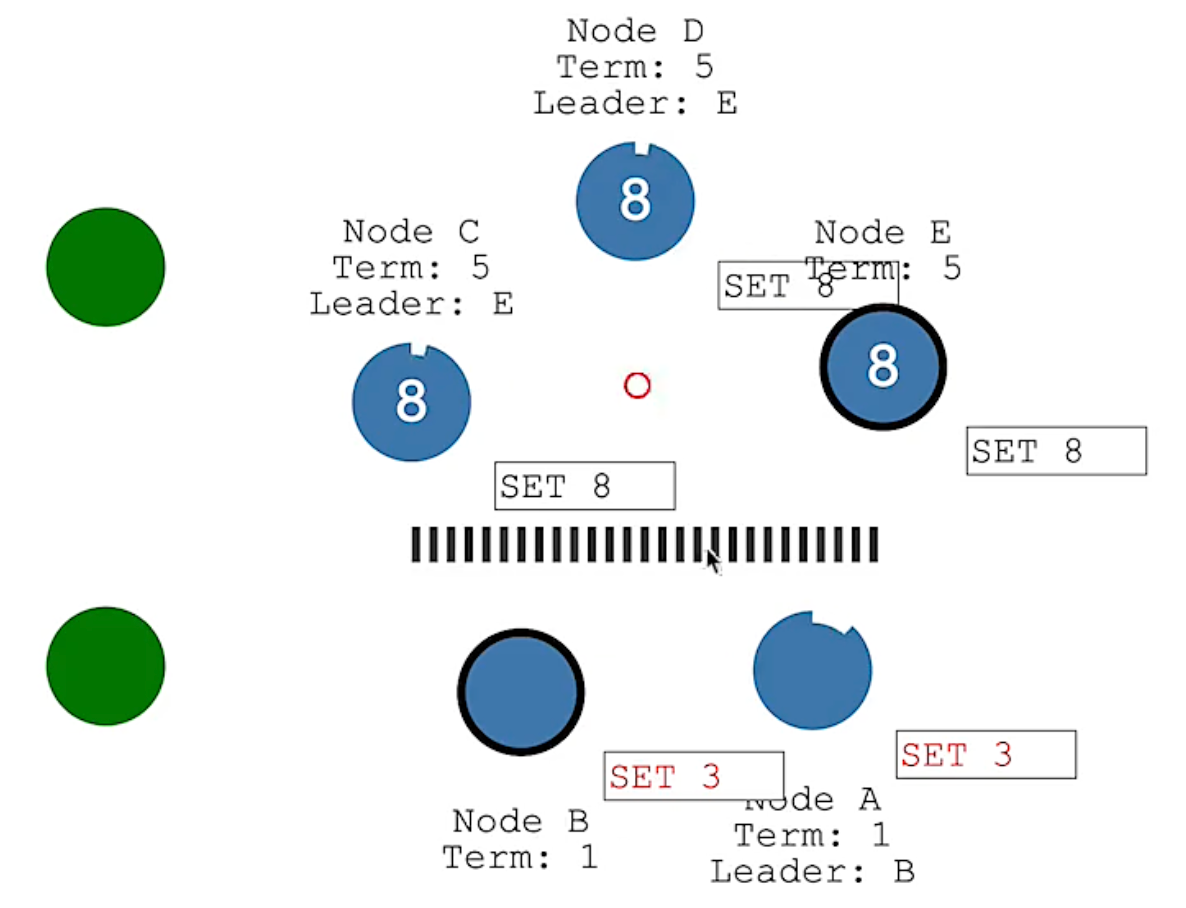
Raft协议下,虽然可能出现多个Leader节点,但是如果有写请求, 上面集群可以写成功(Node E可以获得3个节点的支持),下面集群就不能写成功(Node B只能获得2个节点的支持).
当网络分区恢复后,两个主节点向集群的其他节点发送心跳检测, A、B节点发现有更高版本的Term, 按照Raft协议, A、B节点为提交的Log Entry会丢弃,同时同步最新Leader节点的数据。这是A、B节点就出现了数据丢失。
解决脑裂问题, 不是说解决了不产生多个Leader节点, 而是即使产生多个Leader节点,最终也能完成Leader节点的确认和数据的最终一致性。
Raft在选举主节点的期间,集群是不能对外提供服务的(没有Leader节点处理客户端的请求了),所以,从CAP理论的角度分析,Raft优先保证的是CP,而放弃了A。与之形成对比的是Eureka,保证AP。
Raft协议中的数据
Server维护数据
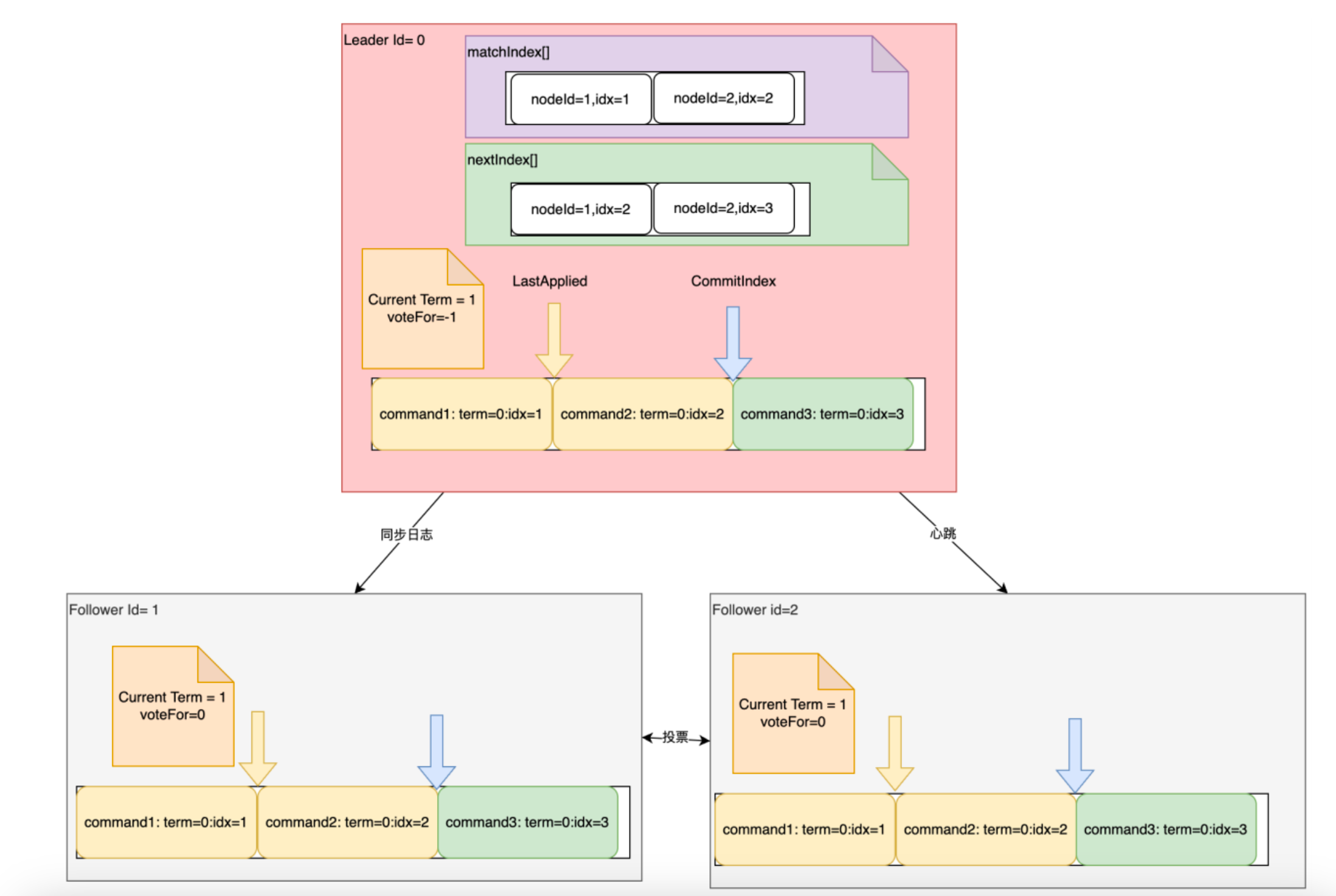
所有节点都需要的数据:
- currentIterm : 服务器当前的任期值
- votedFor : 当前任期内投票给了谁
- Log[Entry] :
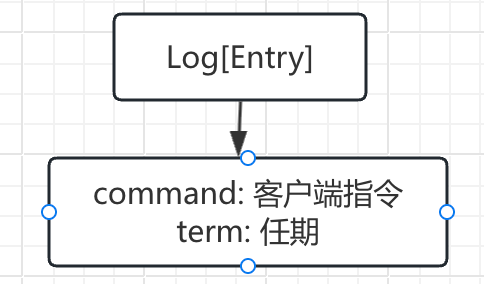
- LastApplied: 记录往状态机同步的速度
- commitIndex :记录消息同步的速度
Leader节点特有的数据(记录同步Follower节点的进度):
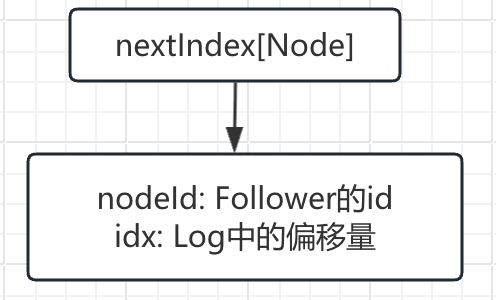
- nextIndex[Node]: 给每个Follower同步到了哪一条Entry, 记录与Follower的同步速度(可能还未收到Follower的响应)
- matchIndex[Node]:给每个Follower复制到哪一条Entry,记录哪些Entry发送给Follower且得到了Follower的确认。(Follower已经发了确认响应)
RPC请求中的数据
投票请求
- term : Candidate的任期term(必须)
- candidatedId : 候选者的id(必须)
- lastLogIndex : 候选者日志最后的Entry索引
- last logo term : 候选者最后日志条目的任期号(上次有效任期的term)
(Follower按照一定的规则投票,实际业务实现时,3和4都可以作为判断条件之)
心跳/数据同步请求
- term
- leaderId
- entries[] : 支持批量同步. 如果没有这个值,就是心跳请求。
- leaderCommit : Leader已知已提交的最高的日志条目的索引(commitIndex)。主要应用在主节点切换时,Follower要知道新的条目是从哪里开始同步的。 举个例子:比如Follower1节点本来Log中最新Entry索引是8, 切换的新Leader同步的Entry是7, Follower1就知道要抛弃索引8的Entry.
- 为了安全起见,建议将上一条Entry的Index已经Term发送过来。主要用来协助Follower定位Entry
实际心跳请求和数据同步请求可以合并在一起发送,Follower判断有没有日志条目可以区分是哪种请求。
RocketMq实现Deldger
引入三方包
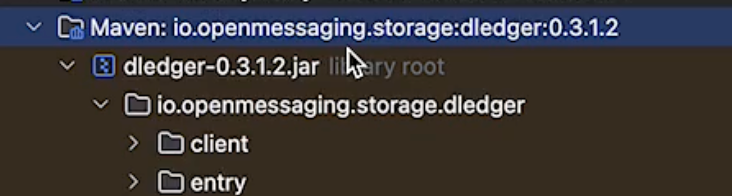
Deldger的请求体:
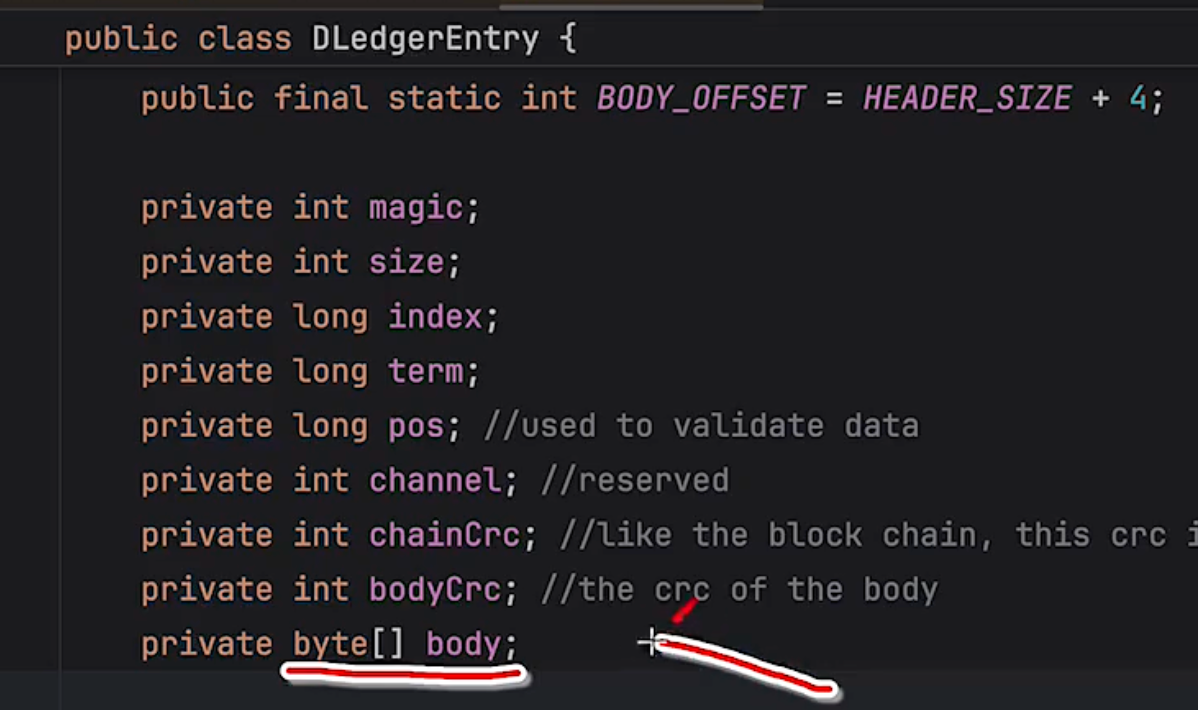
问题:deleger集群是否可以直接迁移成普通集群?
deleger集群下,rocketmq将自己的commit Log日志(请求内容)封装到body中, 同时也会配置term、index等其他deleger集群特殊的数据,组成完成的请求。这和普通RocketMq集群的请求体是不一致的。
所以迁移的话,可以迁移,但是数据不兼容,无法将之前的数据直接迁移到新的集群上。
RocketMq Controller模式
RocketMQ提供的Dledger(RocketMQ 引入 DLedger 的版本是 4.5.0)虽然确实增加了集群的高可用,但是他是把集群选举和同步日志都一起完成的。而Dledger集群下的日志,显然会比主从集群大很多。这就会增加写日志的IO负担。
在RocketMQ 5.X的大版本中,RocketMQ又提供了一种Controller机制,既可以使用Raft的选举机制带来的高可用特性,同时又可以使用RocketMQ原生的CommitLog日志。(实现主从切换和数据同步的核心任务)
Controller与Deldger比较
| 特性 | Controller 模式 | Delegate 模式 |
|---|---|---|
| 架构角色 | 独立部署的控制器集群 | 由 Broker 节点选举出的代理节点 |
| 一致性协议 | 基于 Raft 的强一致性 | 最终一致性 |
| 部署 | 独立部署 or 依托NameServer节点 | 依托现有 Broker 节点 |
| 资源消耗 | 额外需要 3-5 台服务器 or 利用NameServer节点 | 利用 Broker 节点资源 |
| 性能影响 | 元数据操作略慢(强一致性保证) | 元数据操作更快(最终一致性) |
| 适用规模 | 大型集群(100+ Broker) | 中小型集群(<100 Broker) |
| 故障恢复 | 自动快速故障转移 | 依赖 Broker 选举机制 |
| 元数据管理 | 集中式管理 | 分布式管理 |
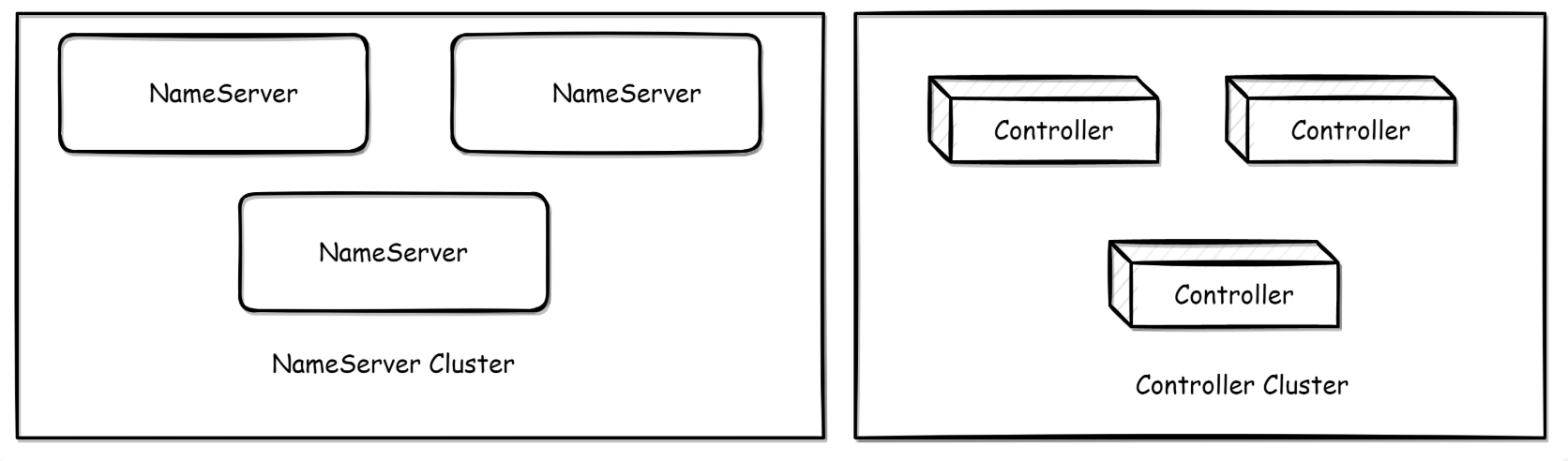
Controller 部署方式
方式一:嵌入于 NameServer 进行部署, 在该模式下,NameServer 本身能力仍然是无状态的,也就是内嵌模式下若 NameServer 挂掉多数派,只影响切换能力,不影响原来路由获取等功能。
配置:在 NameServer 的配置文件中增加相应配置
启动:指定配置文件启动 Nameserver
$ nohup sh bin/mqnamesrv -c namesrv.conf &
方式二:独立部署,需要单独部署 Controller 组件。
配置:配置文件controller.conf
启动:
$ nohup sh bin/mqcontroller -c controller.conf &
另外,Broker启动的配置文件中增加Controller相关配置。
RocketMq BrokerContainer模式
在RocketMQ 4.x版本中,一个Broker就是一个进程。无论 主从、Dledger模式,一个进程中都只有一个Broker服务。而Broker又是分主从的,他们的压力式不一样的。Broker负责响应客户端的请求,非常繁忙。Slave一般只承担冷备或热备的作用。这种节点之间角色的不对等会导致RocketMQ的服务器资源没有办法充分利用起来。
RocketMQ5.x版本中,提供了一种新的模式BrokerContainer。在一个BrokerContainer进程中可以加入多个Broker。这些Broker可以是Master Broker、Slave Broler或者DledgerBroker。通过这种方式,可以提高单个节点的资源利用率。并且可以通过各种形式的交叉部署来实现节点之间的对等部署。
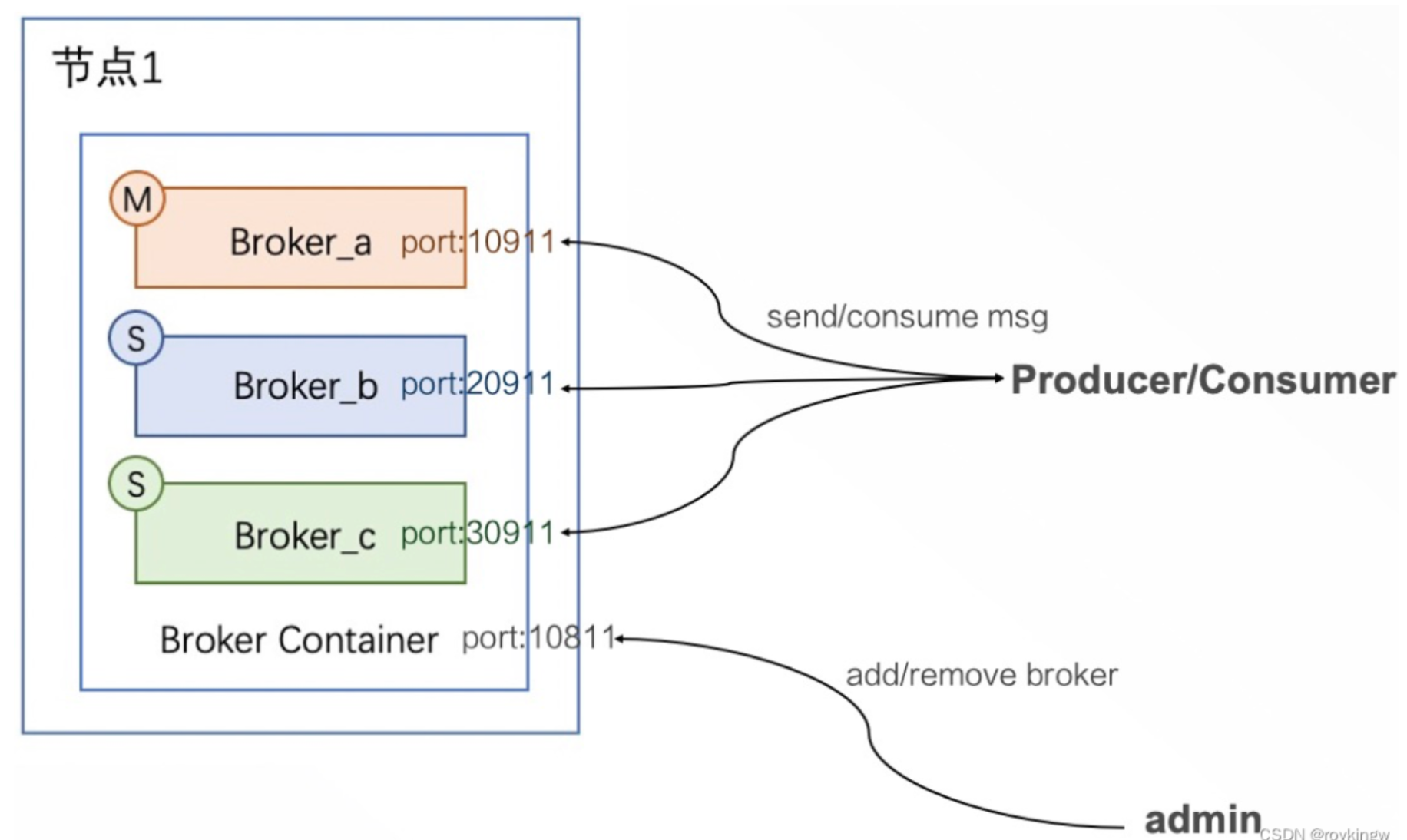
启动:使用bin/mqbrokercontainer脚本启动
bin/mqbrokercontainer -c broker-container.conf