Transformer是什么 - 李沐论文《Attention Is All You Need》精读
文章目录
- 今日的语言模型是如何做文字接龙的|Transformer简述版本
- Transformer概述
- 1.Tokenization
- 2.Input Layer理解每个Token
- 理解每个Token-语义
- 理解每个Token-位置
- 3.Attention考虑上下文 理解token与token之间的关系
- Attention模组的基本工作原理
- 注意力机制-举例理解版本
- 自注意力机制
- 3Blue1Brown Transformer是什么
- 注意力机制
- 计算token之间的相关性
- Causal Mask 因果掩码
- 使用相关性更新原来的嵌入向量
- Unembedding vec 转为 word
- 温度调控Softmax
- 李沐:论文《Attention Is All You Need》精读
- Transformer架构概述
- Transformer里的编码器和解码器概述
- 编码器
- LayerNorm vs BatchNorm
- 解码器
- 注意力子层
- Scaled Dot-Product Attention 缩放点积注意力
- Causal Mask 因果掩码
- Multi-Head Attention
- Transformer模型里如何使用Attention
- Position-wise Feed-Forward Networks 位置感知的前馈神经网络
- Embeddings
- 点积的一个角度
- 在嵌入层中,将权重矩阵乘以 dmodel\sqrt {d_{model}}dmodel
- Positional Encoding
- 为什么使用自注意力
今日的语言模型是如何做文字接龙的|Transformer简述版本
语言模型的函数是一个类神经网络,语言模型最常用的类神经网络模型Transformer。

Transformer概述
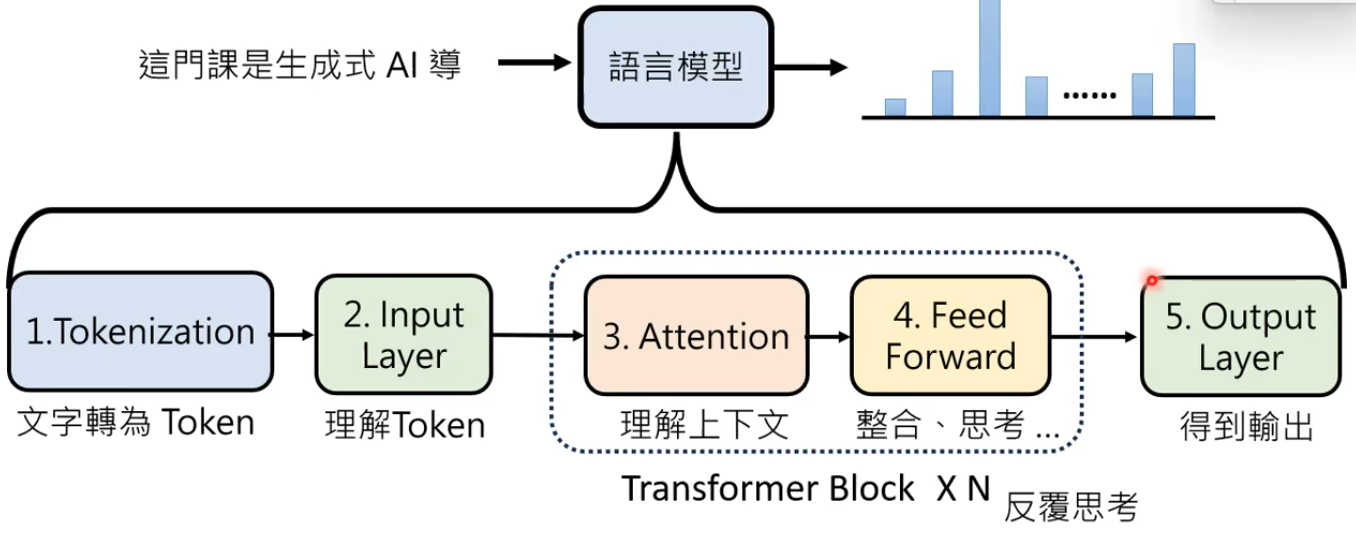
Tokenization:文字转换为Token
Input Layer:理解token
Attention模组:理解token与token之间的关系
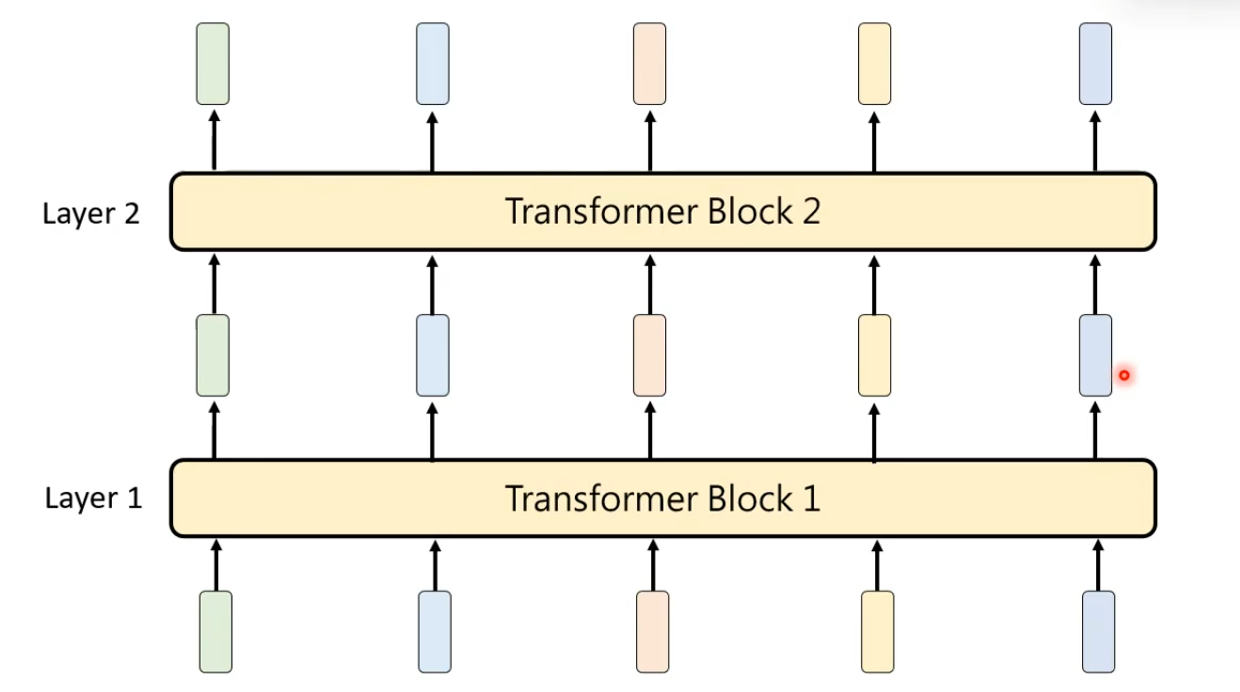
Attention模组+Feed Forward = Transformer Block,一个Transformer = N 个 Transformer Block
Output Layer:将Transformer block的输出转换为概率
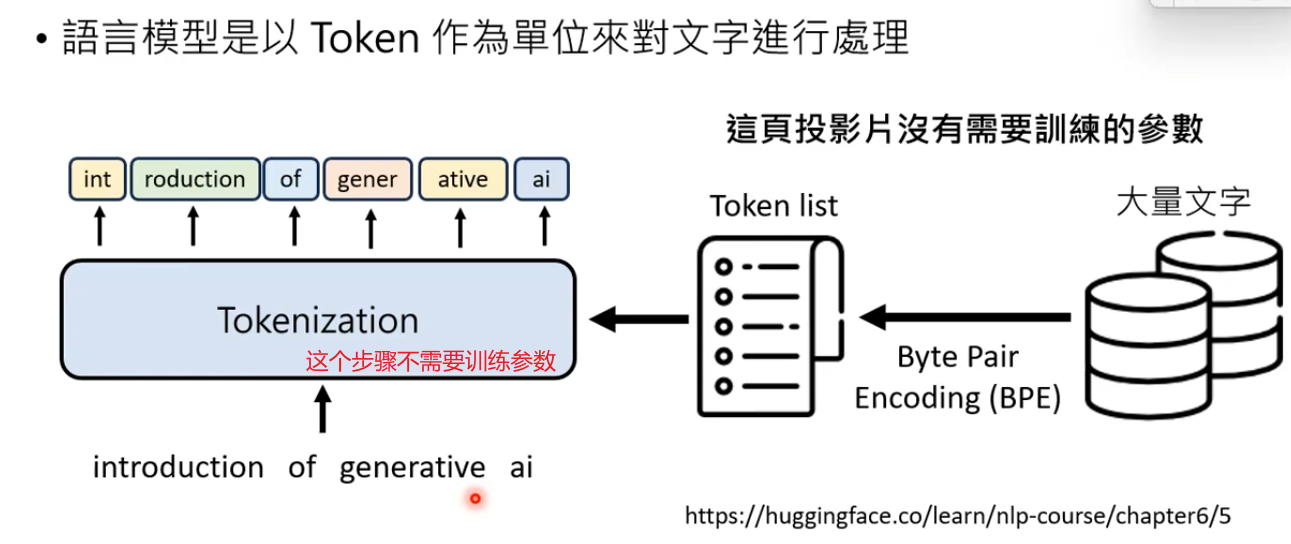
1.Tokenization
作用:将文字变成Token序列
说明:语言模型是以Token作为单位来对文字进行处理,输入输出的单位都是Token
问题:怎么知道怎么划分Token?
解答:打造语言模型时,根据对语言的理解准备Token list(自定义)。不同语言模型的Token list是不同,中文通常一个方块字会被当做一个Token,在GPT中好几个Token组成一个中文字。
Token也可以通过算法自动生成:BPE、WordPiece等分词算法
BPE:收集一堆文字,观察哪些符号通常一起出现进行划分。
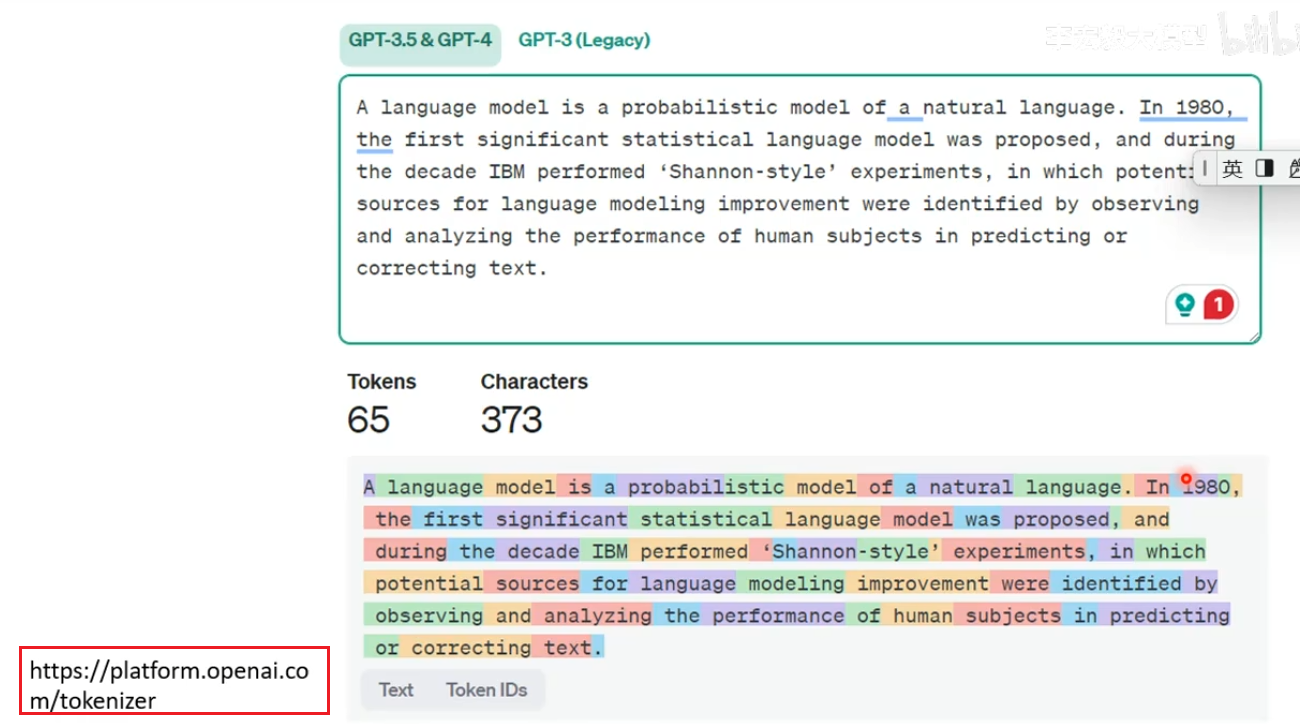
目前网上有可以查询一段话划分为多少个Token的工具,下面是查询OpenAi开发模型的Token划分网站。
2.Input Layer理解每个Token
Embedding矩阵映射:将Token转化为高维向量表示
理解每个Token-语义
每个Token都是一个独立的符号,如果直接用Token,那么run jump都是独立的没有什么特别的关系。
其实run jump是动词感觉比较相近, 我们将每一个Token表示成一个向量(这个向量有时也被称为Embedding),意思相近的Token会有接近的Embedding。
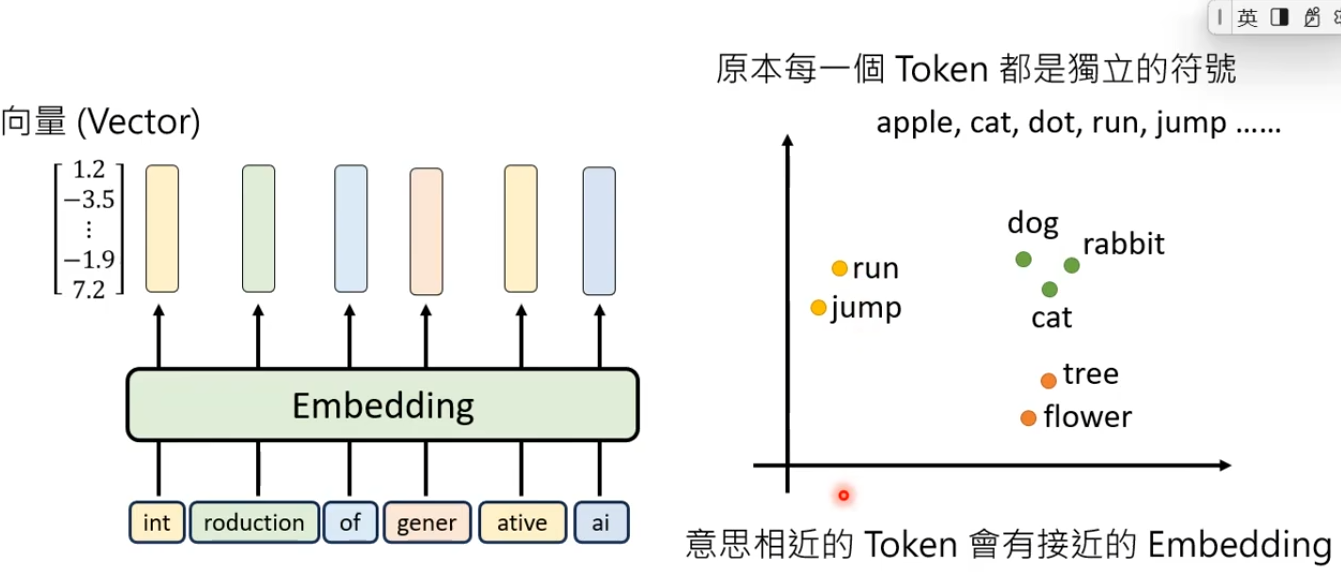
问题:怎么实现意思相近的Token会有接近的Embedding?
解答:有一个Table里面存储了所有Token以及每一个Token对应的Embedding(Token Embedding list),在进行转换时,其实通过查表操作,查询这个Token对应的Embedding是什么。
Token Embedding的映射表是在训练时得到的,每一个Token对应的向量Embedding是语言模型对应的一部分参数,是语言模型通过资料训练找出来的。
同一个Token的Embedding是相同的,比如bank有银行、岸两个意思,但无论它在句子中表示什么意思都是同一个Embedding。
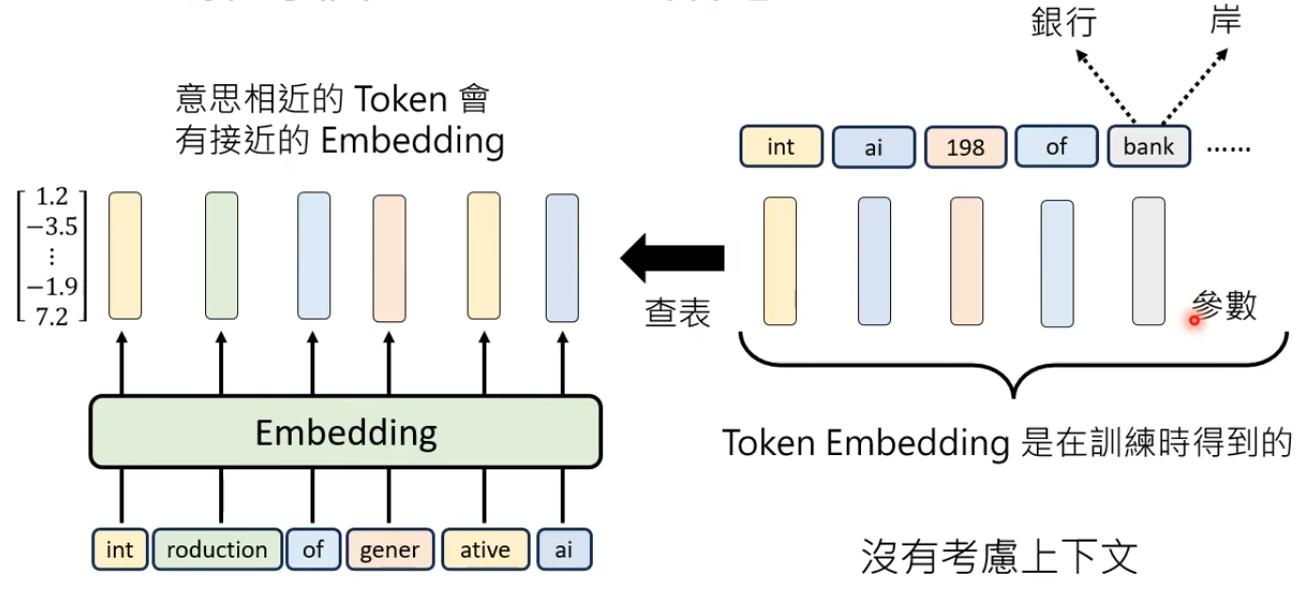
理解每个Token-位置
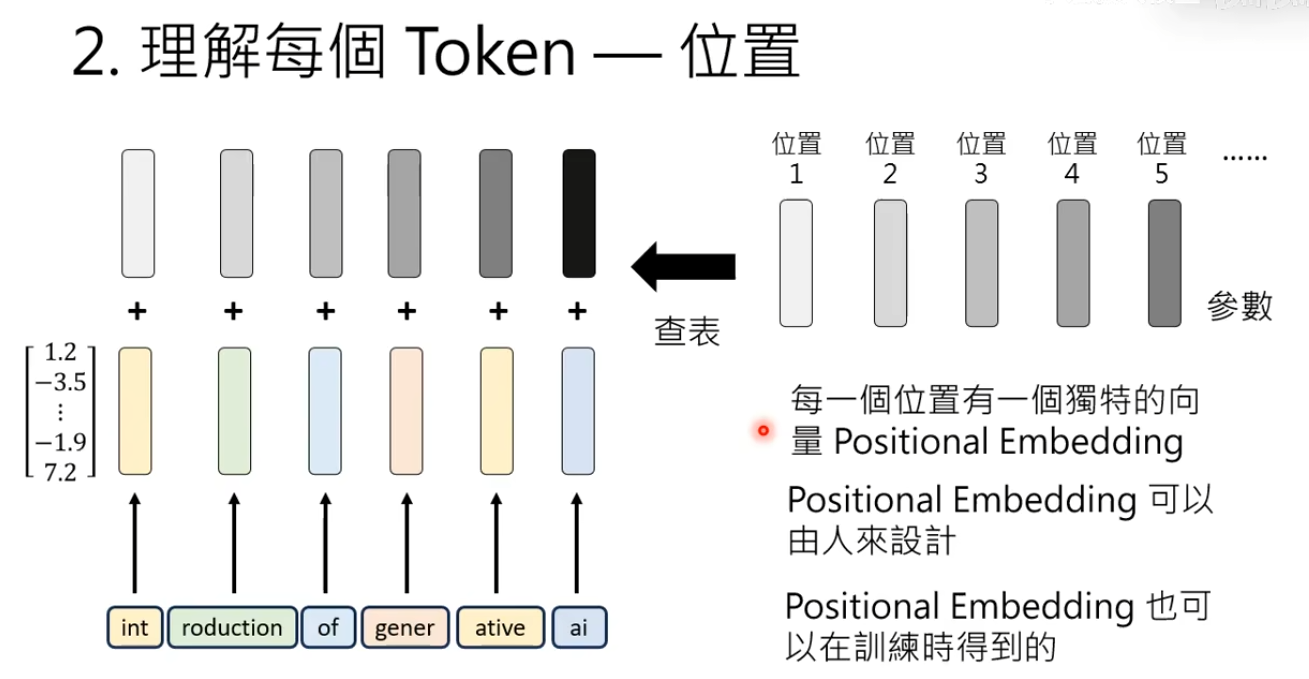
每一个Token在句子里面的位置信息添加到Token的Embedding里面,可能的做法是为每一个位置设置一个独特的向量Positional Embedding
token = 表示语义的向量+表示位置的向量
最早的Positional Embedding是由人来设计的,近年来Positional Embedding也可以在训练时得到。将Positional Embedding也当作参数的一部分,用训练资料自动学习。
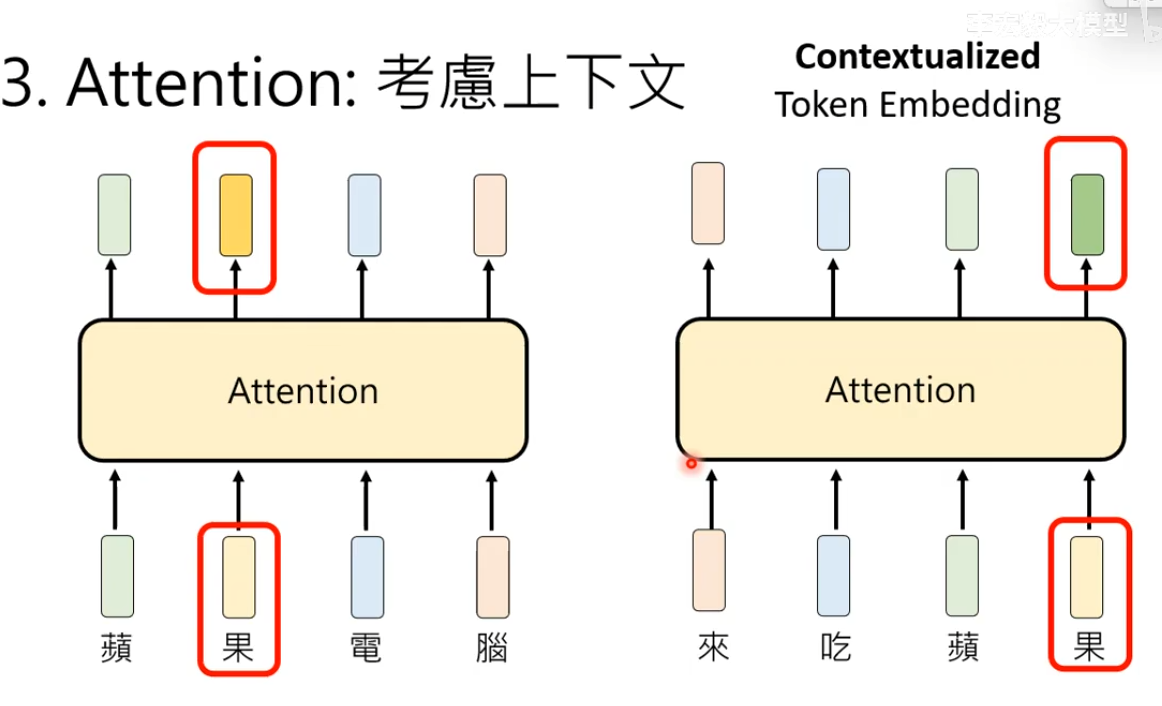
3.Attention考虑上下文 理解token与token之间的关系
考虑了上下文的Embedding叫做上下文相关的词嵌入Contextualized Token Embedding,同一个词在不同上下文中会生成不同的向量表示。
17年6月论文《Attention Is AII You Need》的主要贡献发现不需要Recurrent Neural Network,只需要Attention就能发挥较好的效果了。

输入一排向量Token Embedding,对每一个Token来说Attention的作用就是将上下文信息添加进去,输出长度相同的向量Contextualized Token Embedding
Attention模组的基本工作原理
- 对于某个输入的TokenA,计算句子中每一个Token与TokenA的相关性
计算相关性的模组是一个函数,通过训练资料得到参数。
计算相关性的模组:输入是TokenA和整个句子的某一个TokenB,输出一个分数表示TokenA和TokenB的相关性Attention Weight。
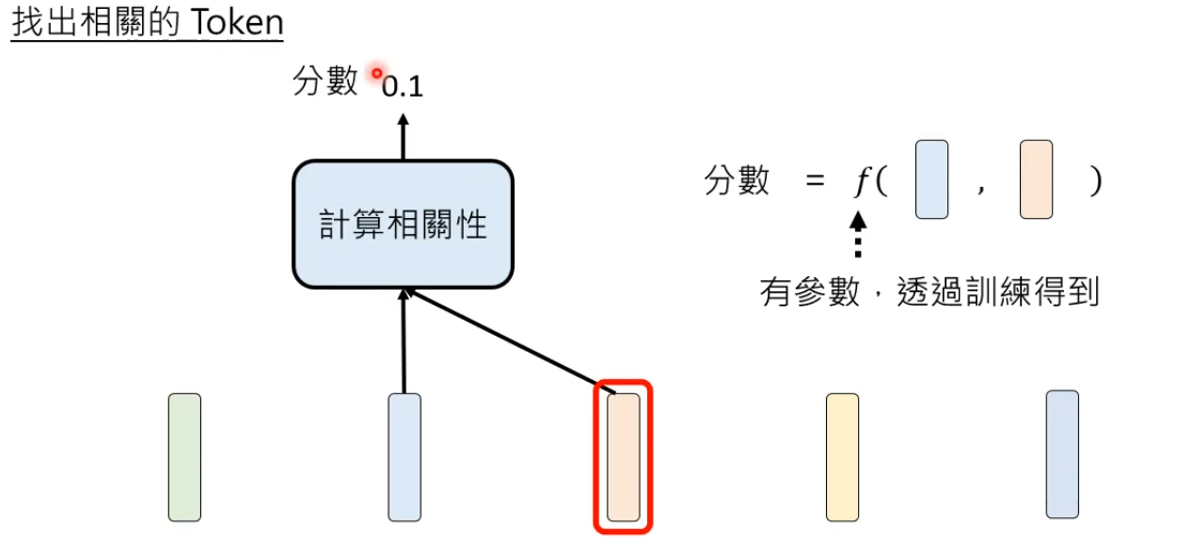
TokenB会从句子里依次选择Token,包括TokenA本身。
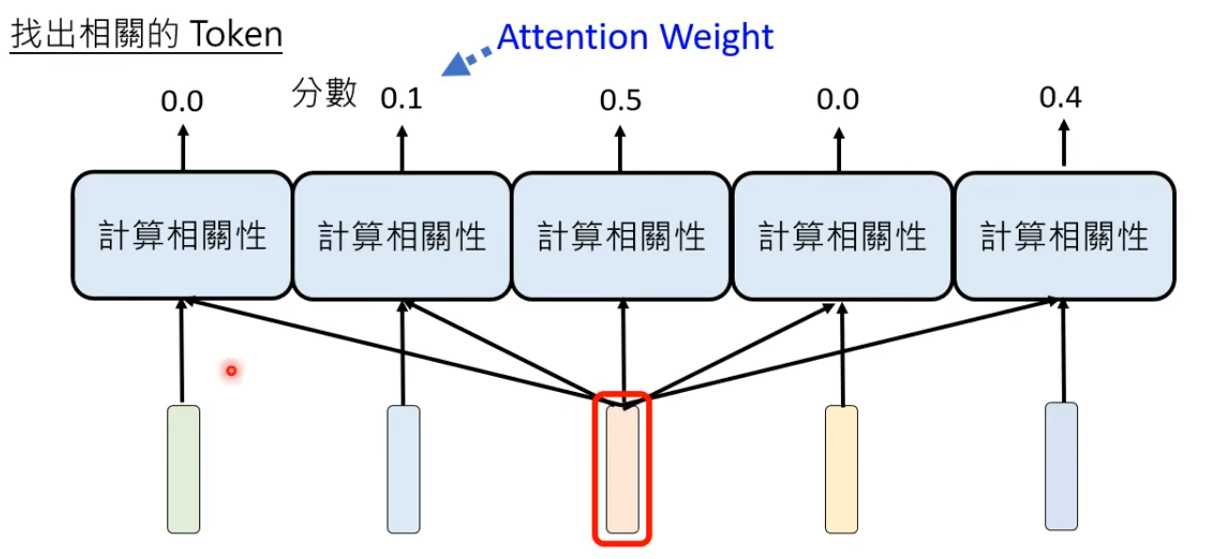
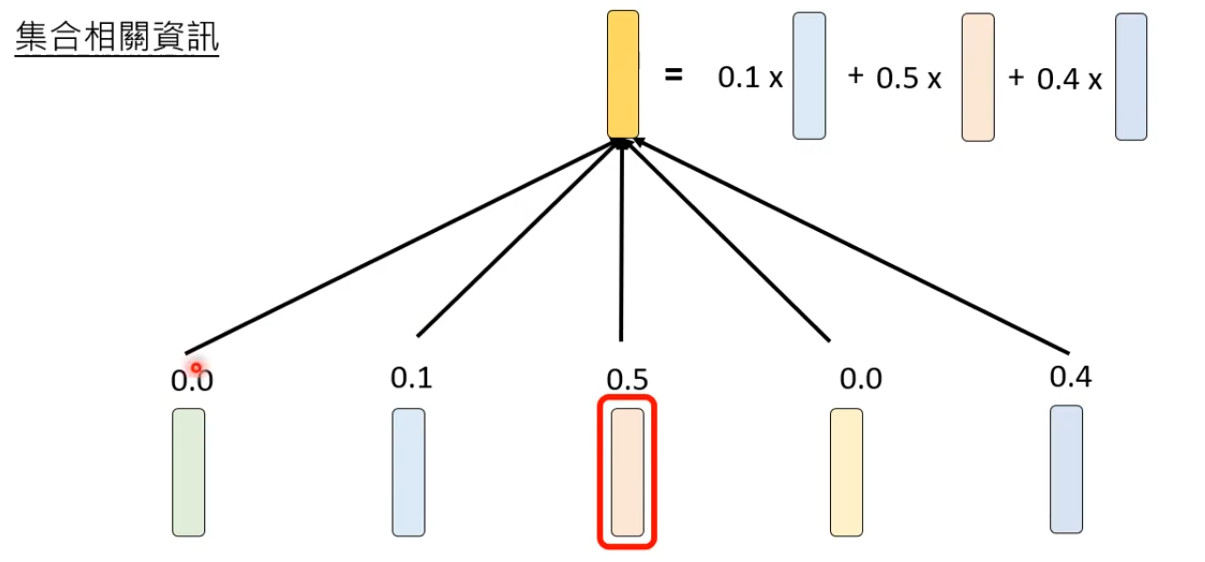
- 每一个Token与TokenA的Attention Weight * Token本身的向量求和,求和的结果就是TokenA经过Attention模组后的输出
Attention的分类
- 假设有5个Token,一共需要计算5*5个Attention Weight,将其称为Attention Matrix
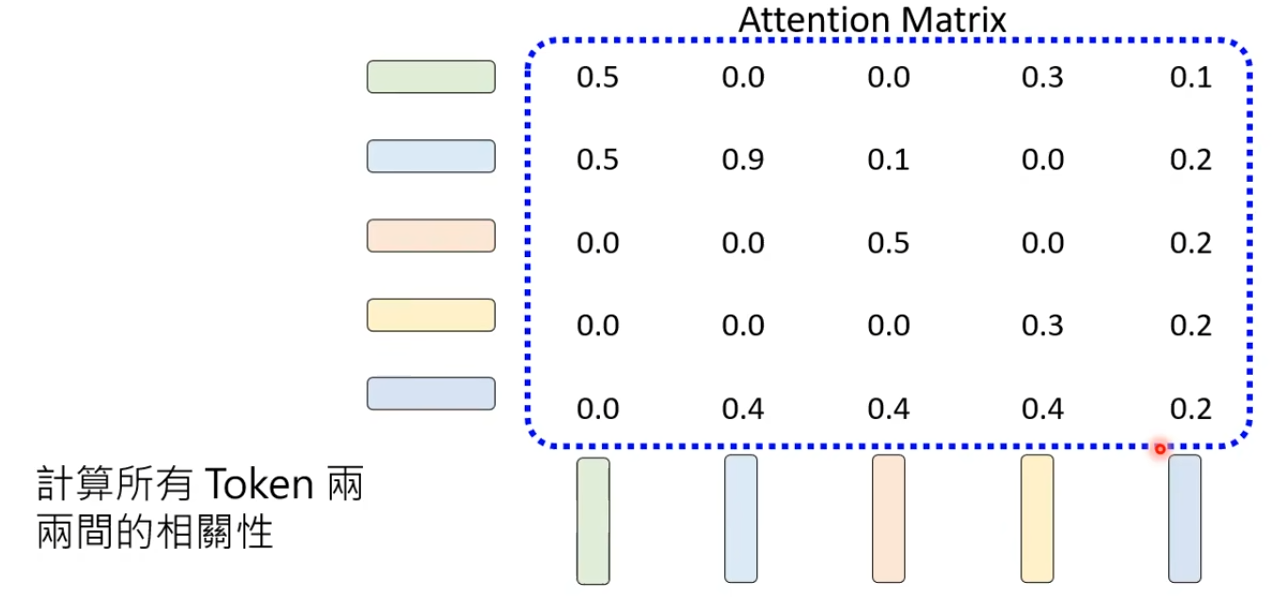
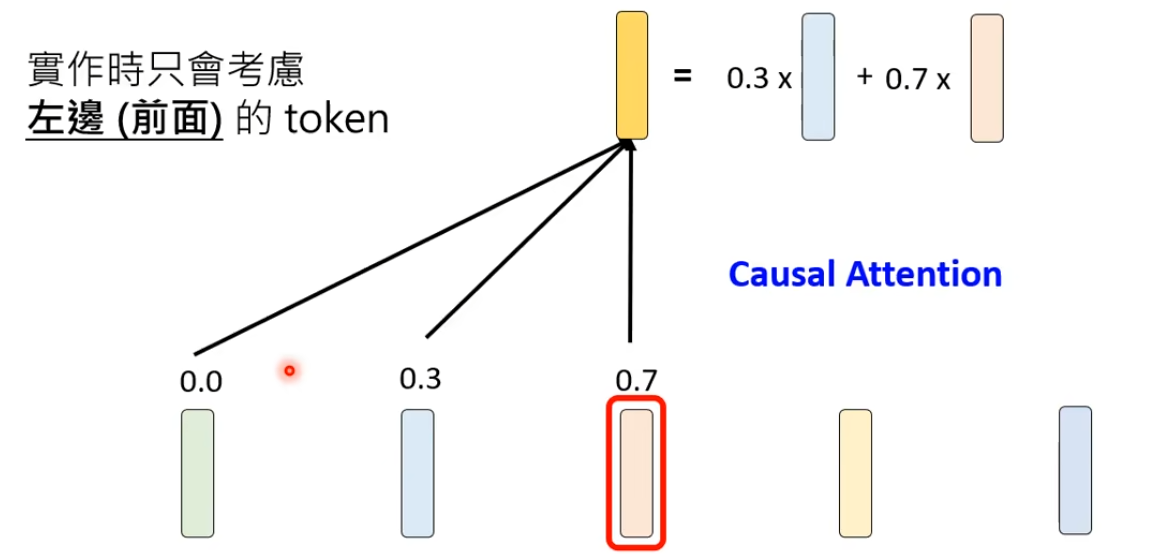
- Causal Attention(因果注意力):实际操作中,只会考虑当前Token(包含)前面(左边)的Token,是Transformer模型中用于确保序列生成符合时间因果性的核心机制,其核心目标是阻止模型在预测当前位置时访问未来信息,从而避免信息泄露。
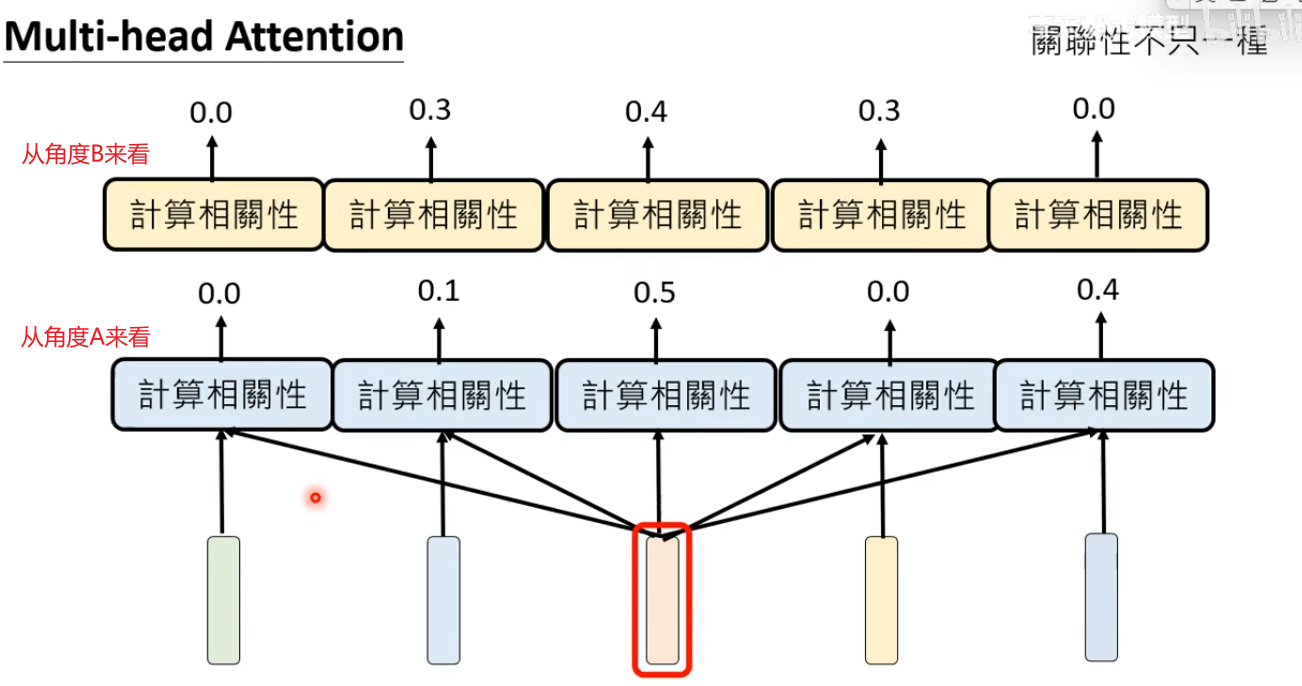
- Multi-head Attention多头注意力机制:目前语言模型常用的机制,通过并行处理多个注意力头(Head)显著提升了模型对序列数据的理解能力。
两个词汇是否相关,可以从多个角度来看,比如从时间上来看,从词性来看等…
计算相关性的模组是一个函数,通过训练资料得到参数。下面图展示了两个计算相关性的模组(通常至少16组),他们的函数是不一样的。
每一个计算相关性的模组都会输出一组向量,通过Feed Forward整合多个输出最终输出一组考虑了上下文的向量Embedding。
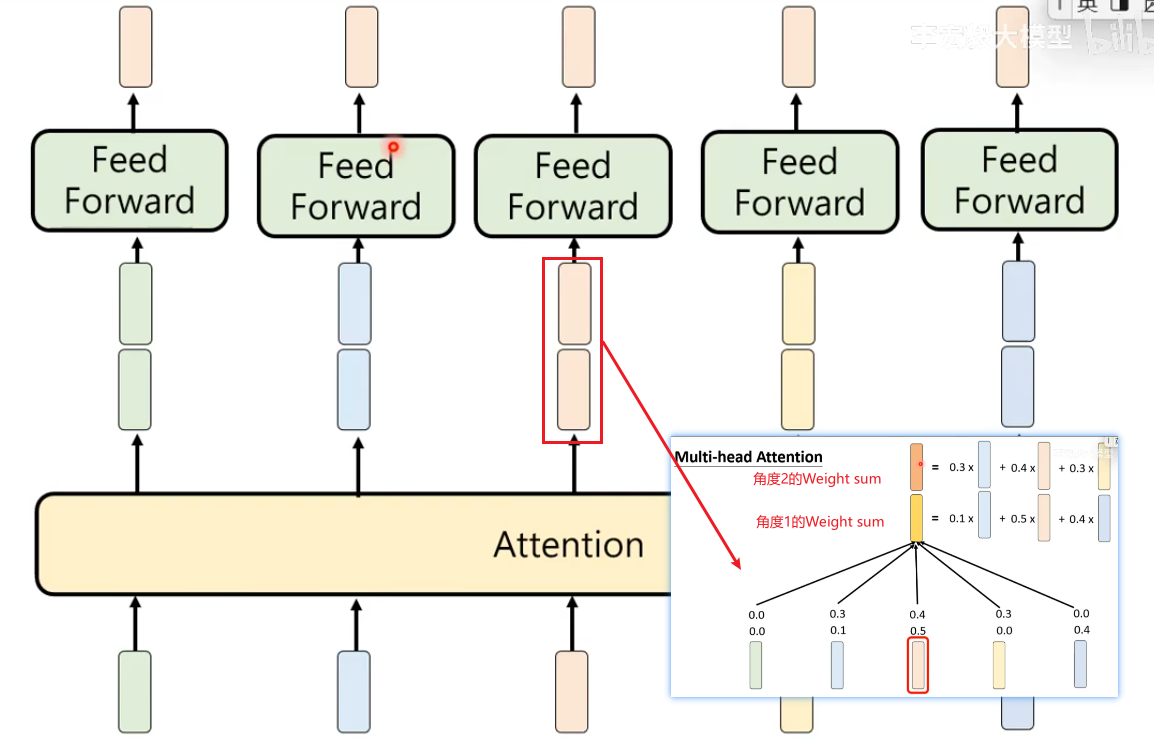
Attention模组+Feed Forward = 一个 Transformer Block,一个Transformer Block是Transformer里面的基本单位。虽然一个 Transformer Block里面也有很多层,但通常在论文中一个 Transformer Block称为一个Layer。
取出最后一个向量(词语接龙的最后一个词),通过Output Layer,这个函数做的事情是Linear Transform+ Softmax得到下一个token的概率分布。
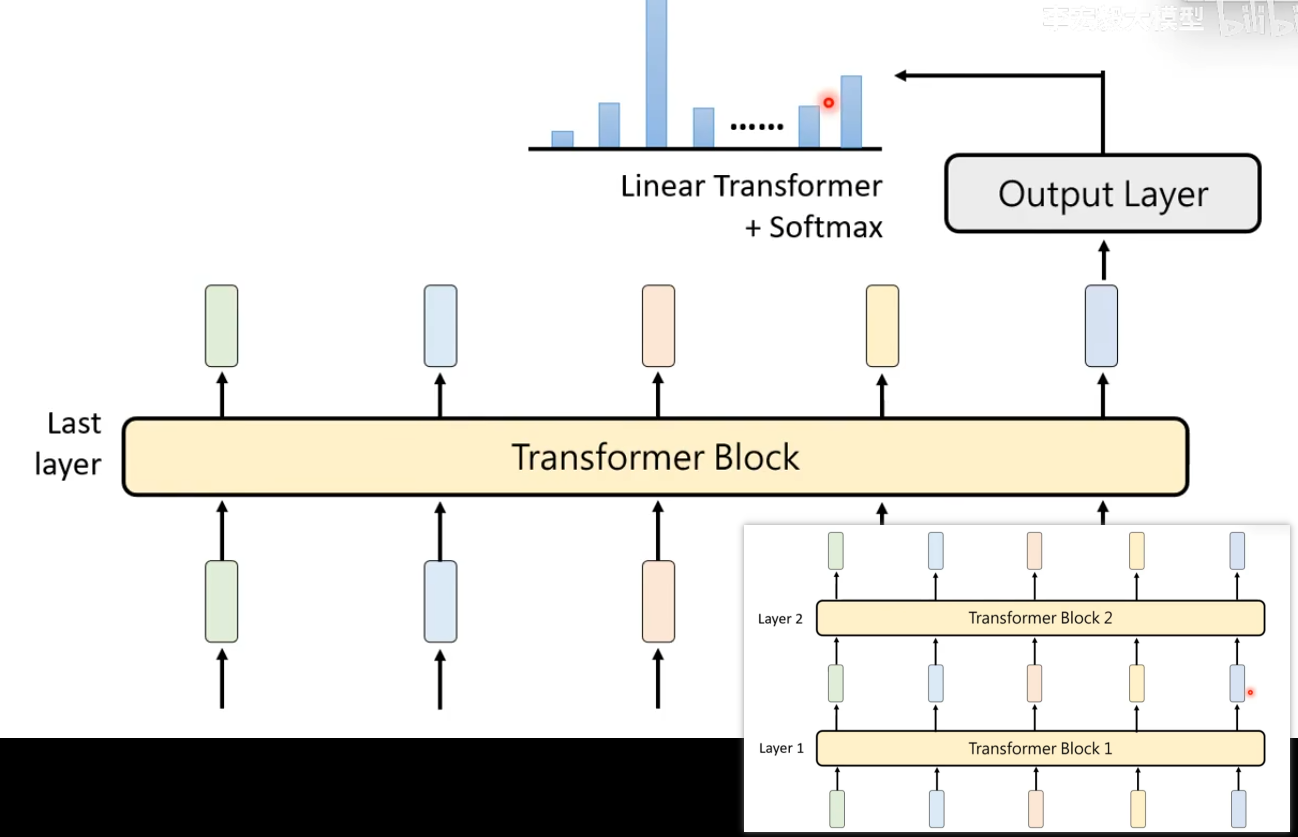
问题:为什么语言模型在做Attention的实际操作中,只会考虑当前Token(包含)前面(左边)的Token
解答:语言模型的本质是做文字接龙
- 第一轮接龙:计算AI:这个Token与左边所有Token的相关性Attention Weight,最后产生下一个Token时w1w_1w1
- 第二轮接龙:w1w_1w1作为输入的最后一个Token,再将新的句子输入给同样的语言模型。对于第一轮AI之前的Token相关性已经计算,不需要重复计算,每次生成新token时,只计算当前token与历史token的相关性。
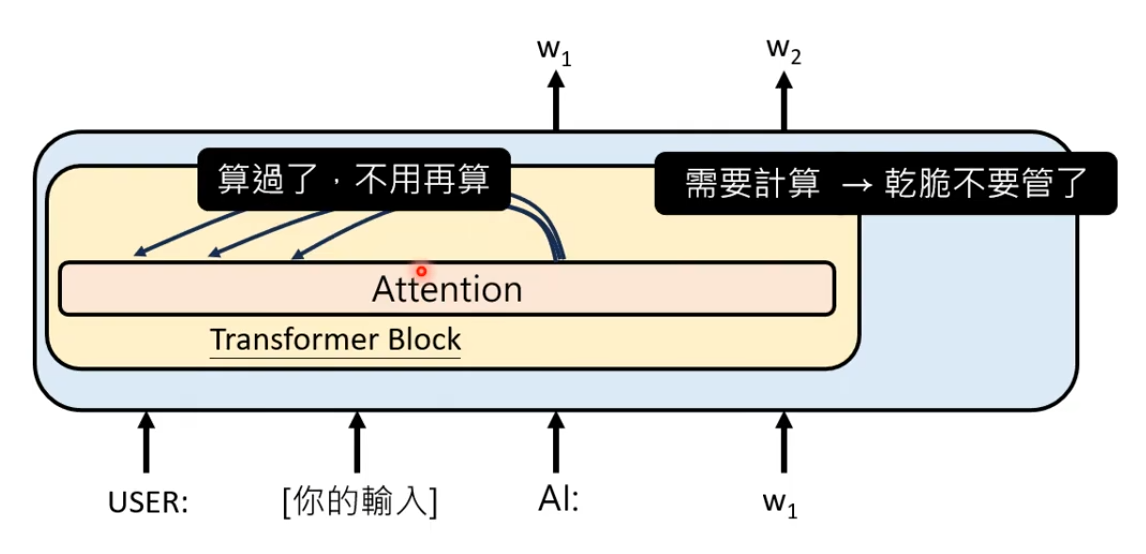
问题:为什么处理超长的文本会是挑战
假设输入100k tokens,Transformer Block需要对每两个Token计算Attention Weight次数,次数和文本长度的平方成正比。
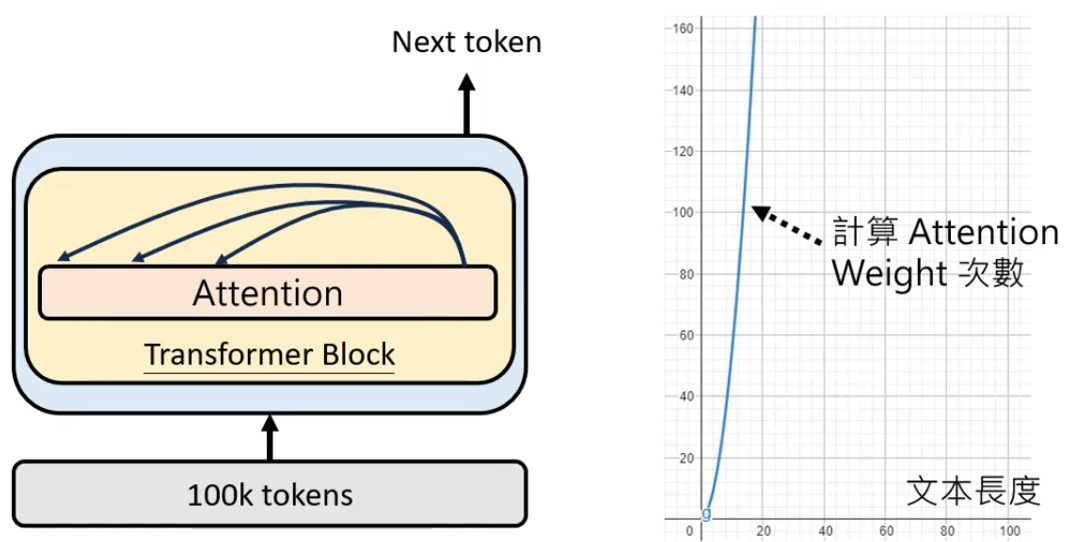
注意力机制-举例理解版本
需要注意的是,公式中提到softmax实际做的事情是对这个矩阵每一行做了softmax
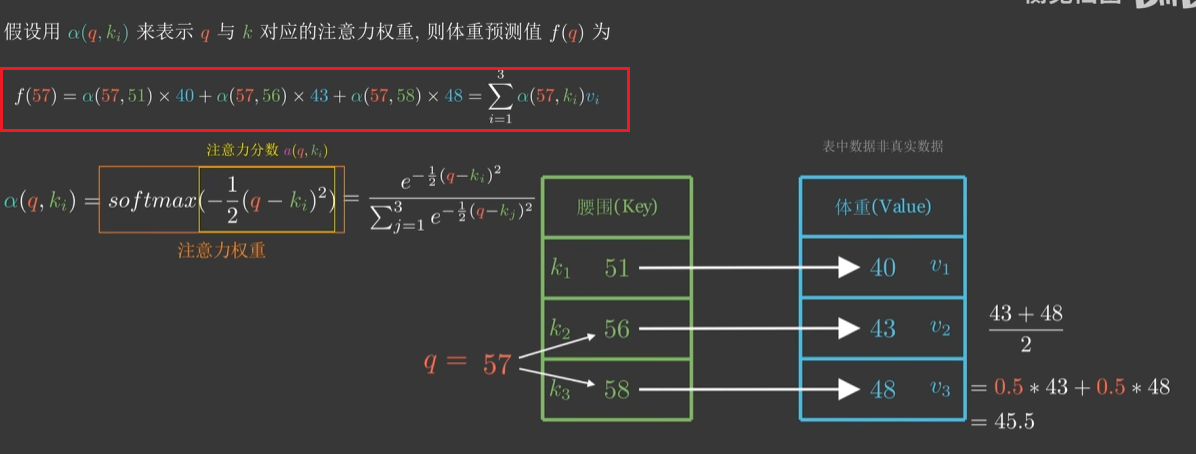
假设我们有一个腰围-体重的键值对,现在给出一个人的腰围为57,想要预测其体重。
由于57到56、58的距离一样,所以一种方法是取他们对应value的平均值。57离56、58最近,我们自然会注意到他们,所以我们分给他们的注意力权重各为0.5。
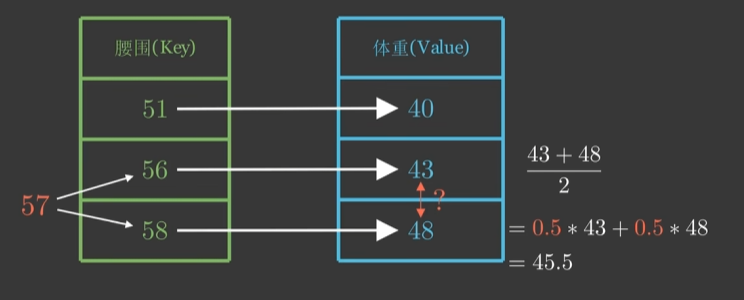
问题:这里没有用上其他的键值对,如果要用上其他的键值对,应该怎么设置权重?
假设qqq表示我们需要查询的腰围57,使用α(q,ki)\alpha(q,k_i)α(q,ki)来表示qqq与kik_iki对应的注意力权重,也就是需要给kik_iki多少注意力,则体重f(q)f(q)f(q)的预测值为f(q)=α(q,k1)v1+α(q,k2)v2+α(q,k3)v3=∑13α(q,ki)vif(q)=α(q,k_1)v_1+α(q,k_2)v_2+α(q,k_3)v_3=\sum_1^3α(q,k_i)v_if(q)=α(q,k1)v1+α(q,k2)v2+α(q,k3)v3=∑13α(q,ki)vi
其中α\alphaα是任何能刻画相关性的函数,相关性高就多给点注意力,相关性低就少给点注意力。但是计算出来的相关性需要归一化,这里以高斯核(注意力分数)为例,包括最后的softmax归一化操作。
注意力分数的函数为−12(q−ki)2-\frac{1}{2}(q-k_i)^2−21(q−ki)2,那么注意力权重α(q,ki)=softmax(−12(q−ki)2))\alpha(q,k_i) = softmax(-\frac{1}{2} (q-k_i)^2))α(q,ki)=softmax(−21(q−ki)2)),带入数据就可以求得体重估计值。
当输入是多维的,注意力分数可以是以下的几种
- 点积模型:α(q,ki)=qkiTα(q,k_i)=qk_i^Tα(q,ki)=qkiT
- 缩放点积模型(Transformer默认):α(q,ki)=qkiTd\alpha (q,k_i)=\frac {qk_i^T}{\sqrt d}α(q,ki)=dqkiT,其中d表示向量维度,d\sqrt dd表示标准化缩放因子目的是为了保证Softmax输入稳定
- …
这里使用缩放点积模型,则体重f(q)f(q)f(q)的预测值为f(q)=α(q,k1)v1+α(q,k2)v2+α(q,k3)v3=∑13α(q,ki)vi=∑13softmax(qkiT)vif(q)=α(q,k_1)v_1+α(q,k_2)v_2+α(q,k_3)v_3=\sum_1^3α(q,k_i)v_i = \sum_1^3 softmax(qk_i^T)v_if(q)=α(q,k1)v1+α(q,k2)v2+α(q,k3)v3=∑13α(q,ki)vi=∑13softmax(qkiT)vi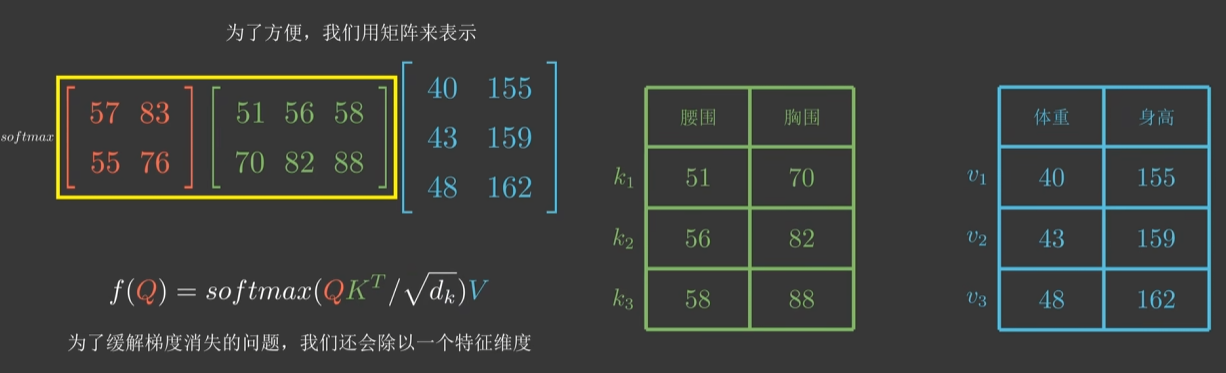
自注意力机制
特点:QKV来源于同一个输入矩阵X,表现在Transformer里自注意力就是给一段话,计算这段话自己的词与词之间的相关性。
在实际运行中会对X先做不同的线性变换再输入,比如Transformer里,提供三个可以训练的矩阵WQ、WK、WVW_Q、W_K、W_VWQ、WK、WV,分别对矩阵X进行变换得到Q、K、V=XWQ、XWK、XWVQ、K、V=XW_Q、XW_K、XW_VQ、K、V=XWQ、XWK、XWV,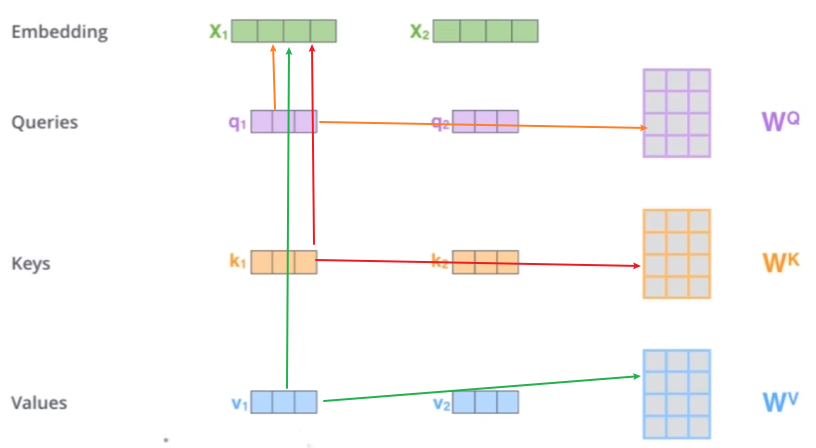
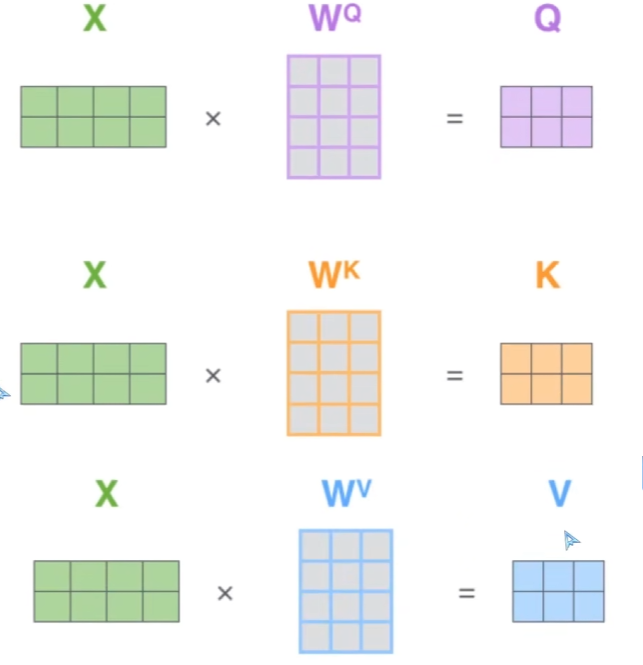
带入公式f(X)=softmax(XWQ(XWK)Td)XWVf(X)=softmax(\frac {XW_Q(XW_K)^T}{\sqrt d})XW_Vf(X)=softmax(dXWQ(XWK)T)XWV
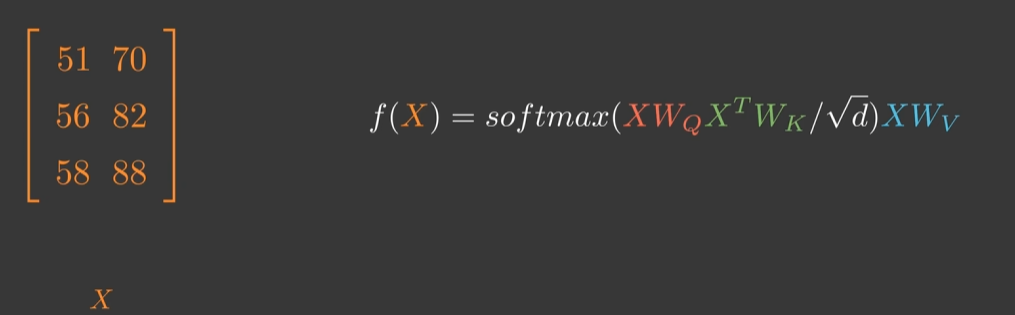
示例XT=[猫向量、追向量、老鼠向量]X^T=[猫向量、追向量、老鼠向量]XT=[猫向量、追向量、老鼠向量]物理意义:
+QQQ:每个词想“问什么”(如“追”需要查询动作对象)
+KKK:每个词能“回答什么”(如“猫”可回答主语身份)
+VVV:每个词的完整语义(如“老鼠”的动物属性)
3Blue1Brown Transformer是什么
注意力机制
注意力模块的作用:精细化了一个词的含义,允许模型相互传递这些嵌入向量所蕴含的信息。
第一步word2vec时,相同的token在词汇表中对应的Embedding是相同的
相同的token可能表示不同的意思,可以想象,嵌入空间有多个方向编码了同一token(比如mole)的不同含义。注意力模块的作用是能计算出需要给初始的泛型嵌入加什么向量才能把它移动到上下文对应的具体方向上,从而得到融合上下文语义后的新向量。
最后一个token向量编码了整个上下文的语义,包含远超单个词的信息量。

计算token之间的相关性
我们使用E1,E2,...E_1,E_2,...E1,E2,...来表示第1步输出的嵌入向量,目标是通过一系列计算产生一组融合了上下文信息更为精准的嵌入向量E1′,E2′,...E'_1,E'_2,...E1′,E2′,...
在深度学习中,我们希望多数计算都是矩阵向量乘法,其中矩阵中填满了由模型学习数据来调整的权重参数。

假设creature询问我前面有形容词吗?提问被编码为了另一个向量称为查询向量,查询向量的维度比嵌入向量小得多
先取一个查询矩阵记为WQW_QWQ,矩阵内部的数值都是模型的参数。查询向量Q4=WQ∗嵌入向量E4查询向量Q_4 = W_Q * 嵌入向量E_4查询向量Q4=WQ∗嵌入向量E4,把查询矩阵分别与文中的所有嵌入向量相乘,计算出每个token的查询向量。
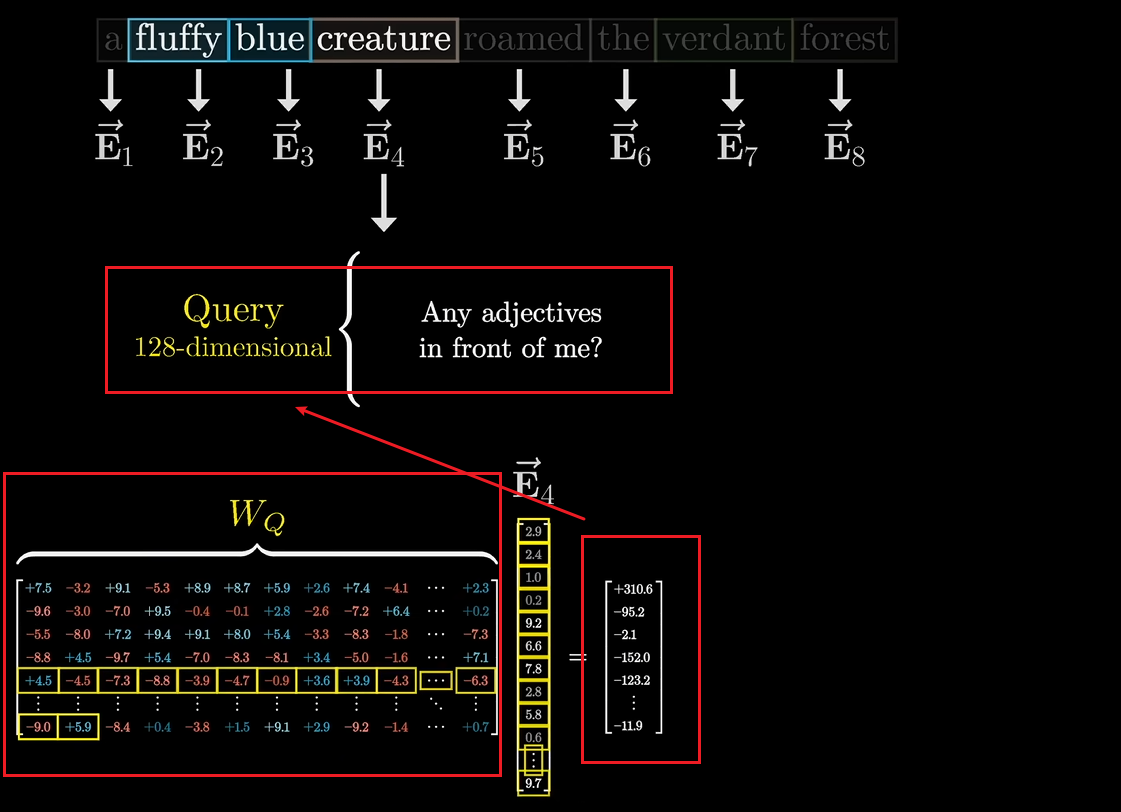
第二个矩阵叫做键矩阵key matrix记为WkW_kWk,矩阵内部的数值都是模型的参数。键矩阵也和每个嵌入向量相乘产生第二个向量序列,称为键向量Keys。可以将Keys看成是每个token回答查询的答案。

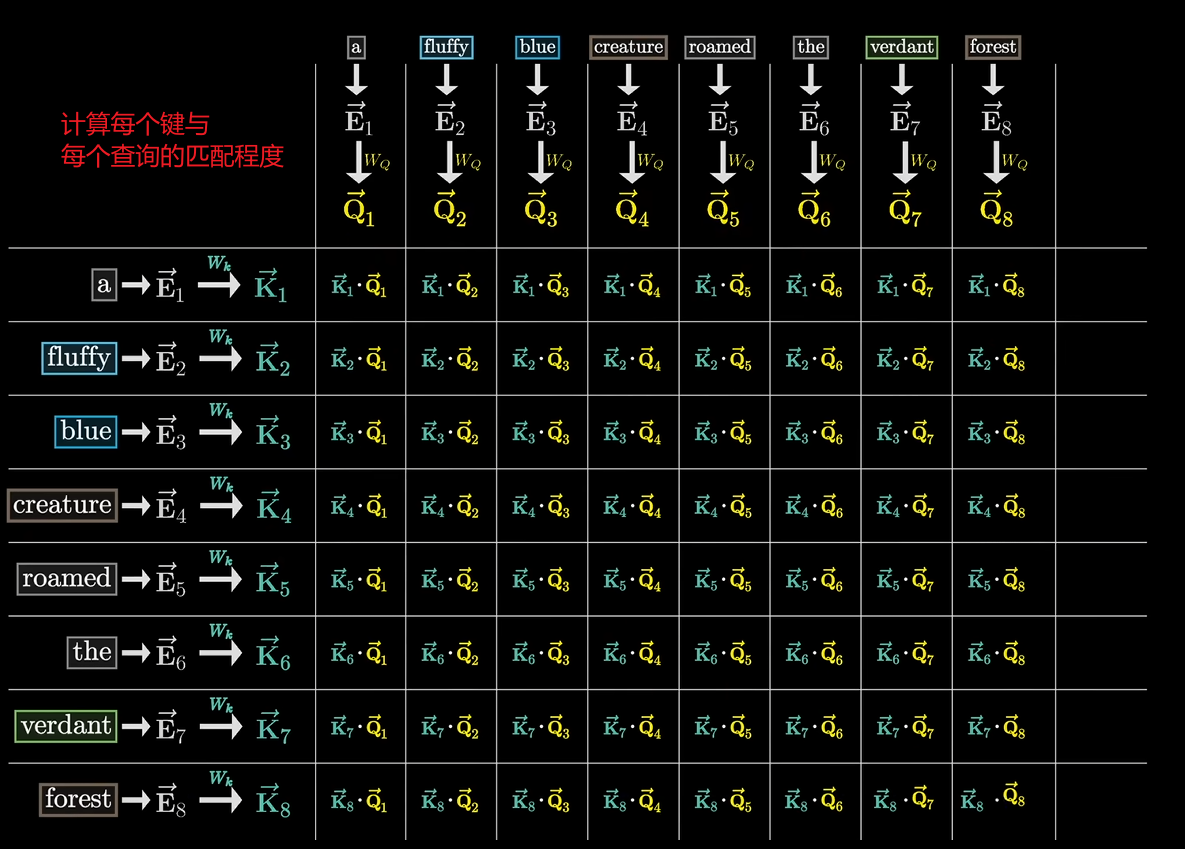
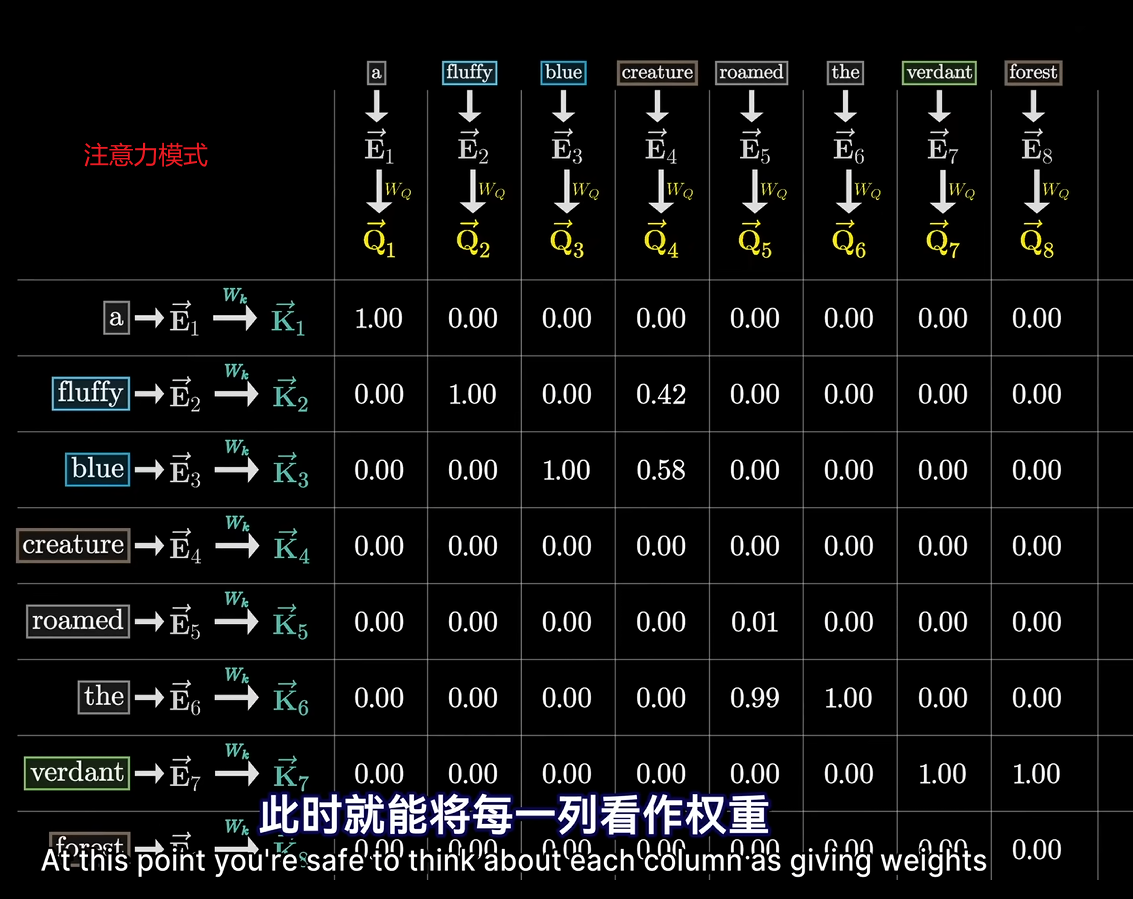
计算每个键与每个查询的匹配程度,网格中的值是负无穷到正无穷的任何实数,值表示每个词与其他词的相关度。
我们希望值的范围是0-1之间,并且每列总和为1,所以需要把Keys和Query点积的结果做softmax。
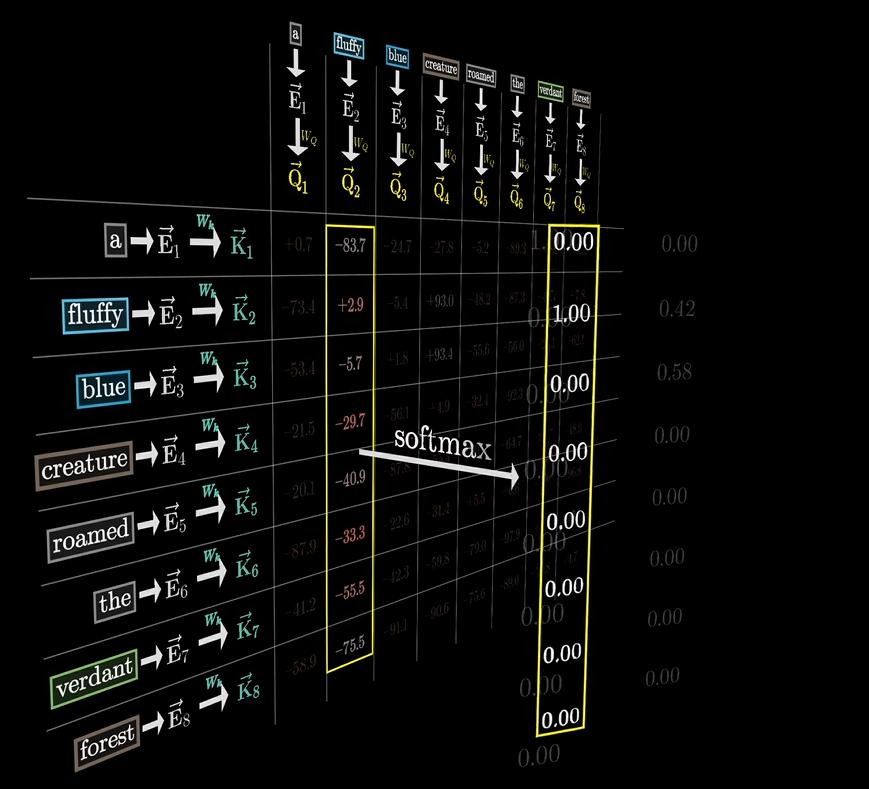
下面的表格就是注意力模式,每一列看作权重表示Keys和Query的相关度,注意力模式的大小 = 上下文长度的平方。
Causal Mask 因果掩码
掩码规则:预测位置t时,只能看见0到t-1的位置。注意力模式不能让后面词影响前面词,不然就会泄露接下来的答案。
添加了因果掩码之后的新步骤
1.通过嵌入向量与查询矩阵和键矩阵相乘得到Query向量和Keys向量,QKTQK^TQKT表示所有可能K-Q对之间点积的网络。为了数值稳定性,建议将所有点积除以K-Q空间维度的平方根。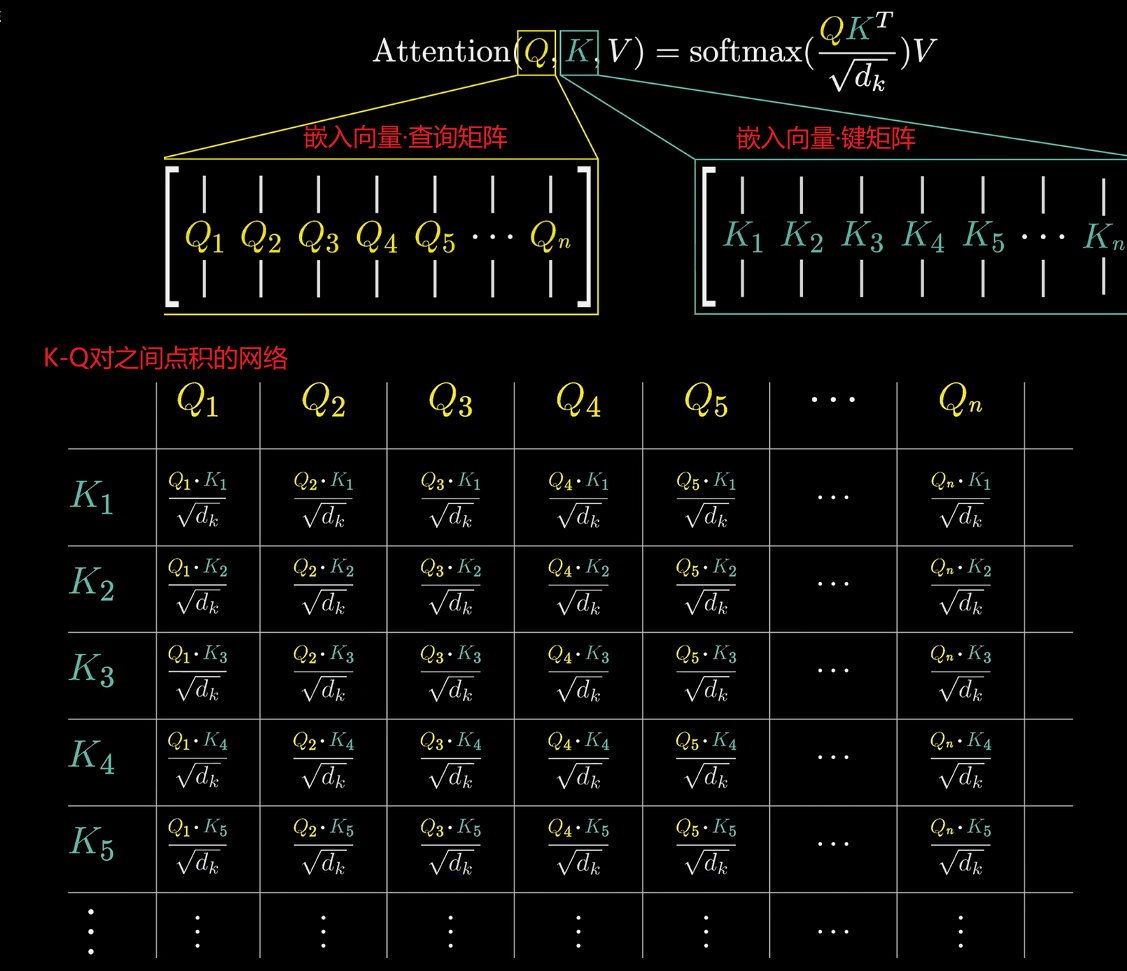
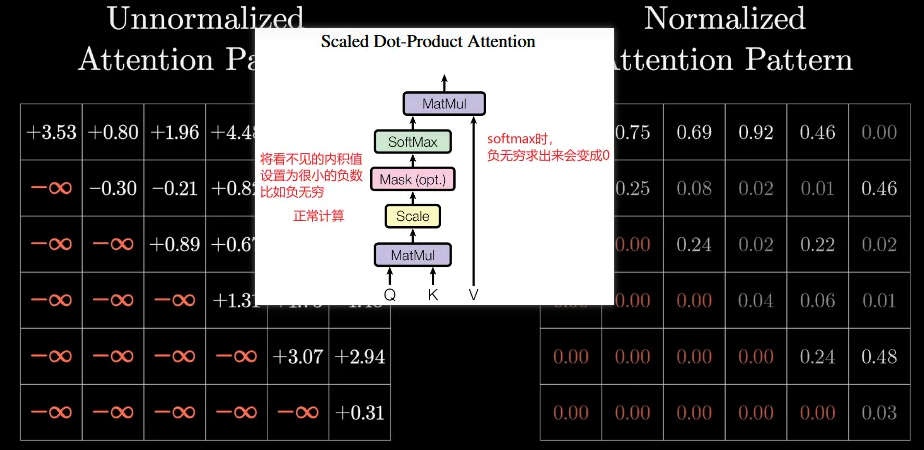
2.为了强制当前位置的token只能看见当前及以前的token,将不能看见的位置设置为负无穷,目的是应用sotfmax之后,不能看见的token与当前token的相关性会变成0
3.将每列的值进行softmax计算,得到了token之间的相关性,我们称其为权重。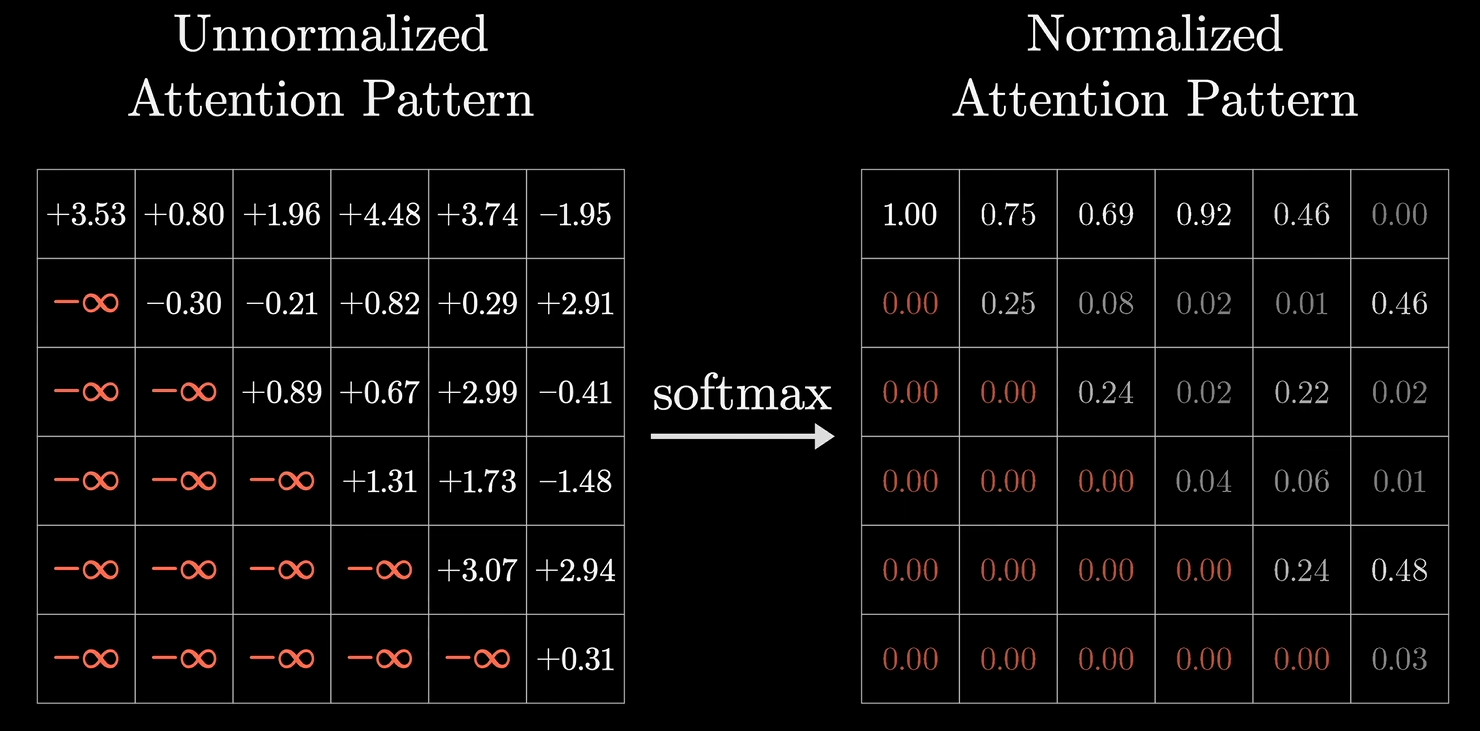
使用相关性更新原来的嵌入向量
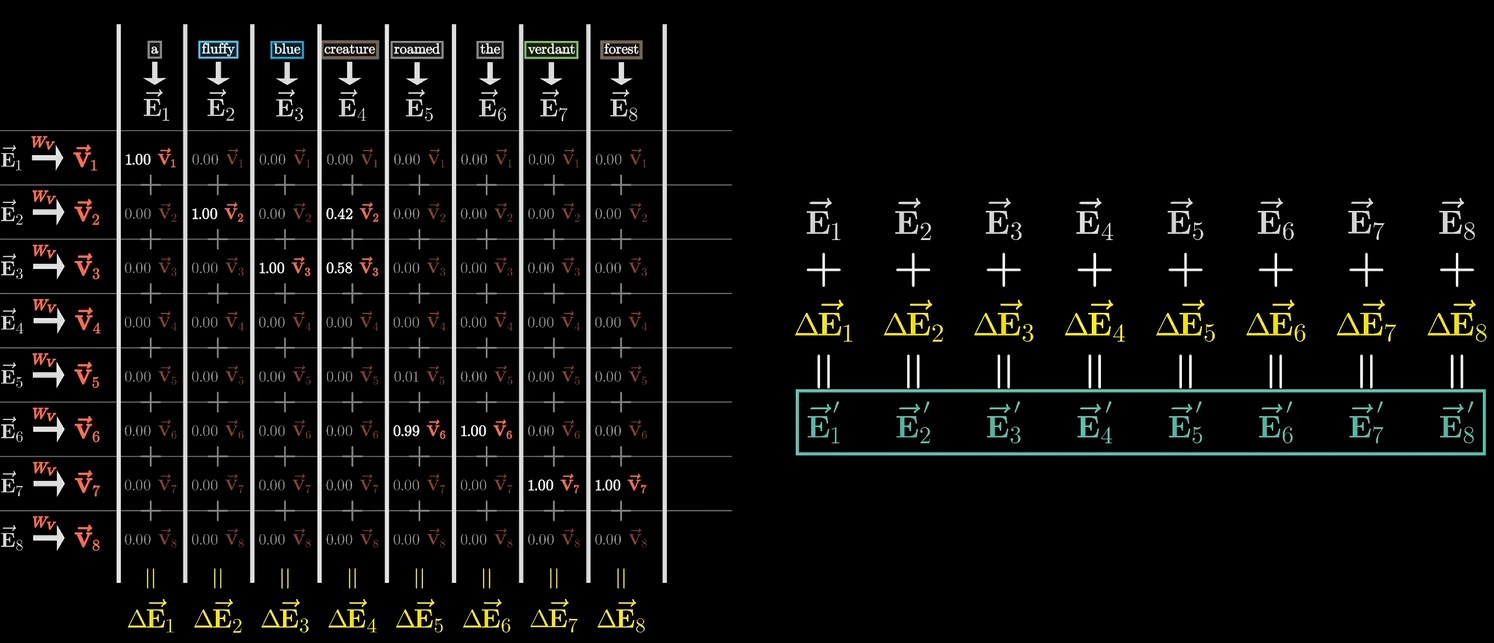
计算出注意力模式后,就不再使用查询向量与键向量。使用嵌入向量乘值矩阵,得到值向量。
每个值向量乘上该列的对应权重(步骤3得到的token相关性),之后求和来更新原来的嵌入向量。
Unembedding vec 转为 word
使用一个Unembedding matrix解嵌入矩阵,记为wUw_UwU。解嵌入矩阵的每行对应词汇库中的一个词,每列对应一个嵌入维度,嵌入矩阵中每一个列表示词库中的一个词。嵌入矩阵初始值也是随机的,然后基于数据进行学习,矩阵中的每一个值都是一个参数,GPT-3中每个词12288个维度,词汇库里有50257个token,需要学习的参数是12288*50257 = 617558016个。
使用解嵌入矩阵将上下文中的最后一个向量映射到一个包含50000个值的列表,每个值对应词库里的一个token,然后使用函数softmax将其归一化为概率分布。

温度调控Softmax
在某些情况下,比如ChatGPT利用该分布生成下一个词时,给softmax函数加入一点趣味性,给指数添加分母常量T。添加了常量T的softmax函数变为:y^i=exp(oiT)∑kexp(okT)\hat y_i = \frac{exp(\frac{o_i}{T})}{\sum_k exp(\frac {o_k}{T})}y^i=∑kexp(Tok)exp(Toi)。
常量T被称为温度,其效果是当T较大时,会给低值赋予更多的权重(低值的概率变大)使得分布更均匀;如果T较小,那么较大的数值会更占优势。
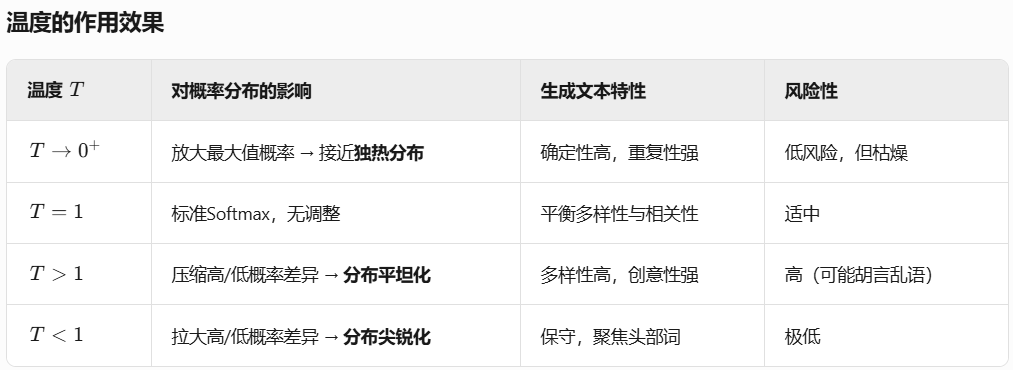
温度为0表示模型总是选择最可能的词,每轮都选概率最大的值;温度越高,模型就更愿意选择可能性较低的词但风险也更大。严格来说API并不允许选择大于2的温度,没有数学依据只是人为限制,避免工具产生过于荒诞的内容。
李沐:论文《Attention Is All You Need》精读
Transformer模型:仅依赖Attention注意力机制,是首个完全依赖自注意力来计算输入和输出表示的转换模型,无需使用递归和卷积。
- 可以并行
- 提出了Multi-Head Attention可以模拟卷积神经网络多输出通道的一个效果,每个注意力头(Head)类似CNN中的一个通道,负责从不同角度建模Token之间的关系。
灵感来源于卷积神经网络有多个输出通道,每个输出通道可以去识别不一样的模式。
Transformer架构概述
Transformer使用了编码器-解码器架构,架构图如下图所示
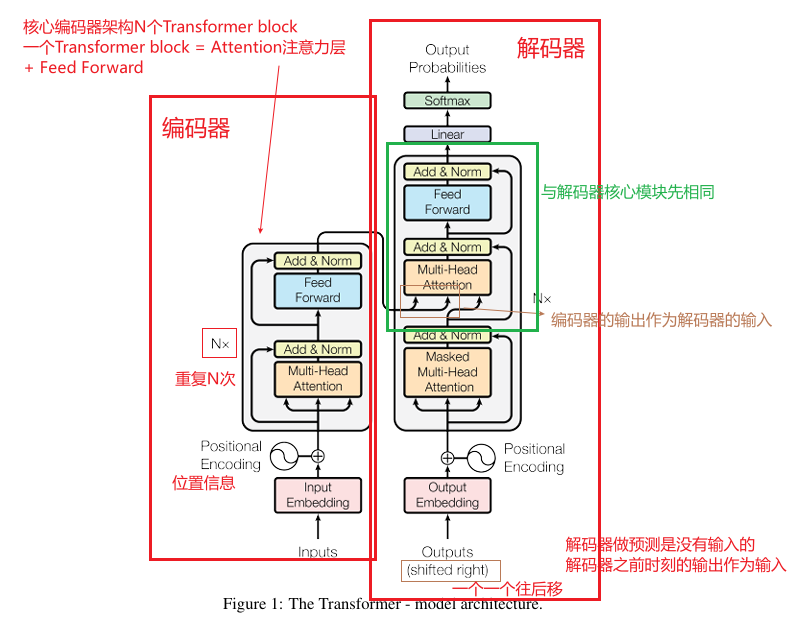
编码器-解码器架构
- 编码器:假设输入为(x1,...,xn)(x_1,...,x_n)(x1,...,xn),如果输入是一个句子,那么xtx_txt表示第ttt个词。编码器将输入转换为向量组z=(z1,...,zn)z=(z_1,...,z_n)z=(z1,...,zn),ztz_tzt表示第ttt个词的向量表示。
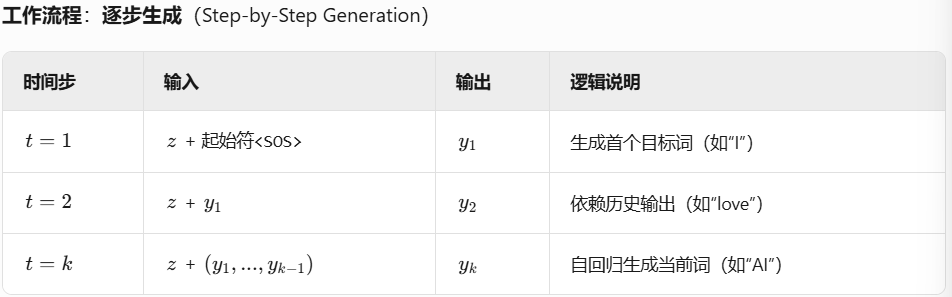
- 解码器:在生成下一个时,将先前生成的符号作为额外输入。先得到y1y_1y1,然后再生成y2y_2y2,如果要生成yty_tyt,可以把之前所有的y1−yt−1y_1-y_{t-1}y1−yt−1都拿到,自回归是指过去时刻的输出也会作为当前时刻的输入。
输入:①编码器输出z=(z1,...,zn)z=(z_1,...,z_n)z=(z1,...,zn)② 自回归输入,已生成的部分序列(y1,...,yt−1)(y_1,...,y_{t−1})(y1,...,yt−1)
输出:能与序列目标序列y=(y1,y2,...,ym)目标序列 y=(y_1,y_2,...,y_m)目标序列y=(y1,y2,...,ym)
Transformer里的编码器和解码器概述
编码器
编码器由N个相同的Transformer block组成,每个Transformer block有2个子层, multi-head self-attention mechanism和simple, position wise fully connected feed-forward network(MLP)。
每个子层的输出是LayerNorm(x+Sublayer(x))LayerNorm(x+Sublayer(x))LayerNorm(x+Sublayer(x)): ①输入xxx②进入不同子层得到输出Sublayer(x)Sublayer(x)Sublayer(x)③ 残差连接 ④残差连接的结果输入LayerNormLayerNormLayerNorm
在这篇论文中,N=6,约定每一层的维度为512,这两个都是超参数。
LayerNorm vs BatchNorm
简单情况引入:假设有一个小批量样本是二维输入,每一行是样本,每一列是一个特征。
- BatchNorm
为了将所有特征放在一个共同的尺度上,批量归一化Batch Normalization的做法我们通过将特征重新缩放到零均值和单位方差来标准化数据,训练是小批量数据的标准化,预测是全局数据标准化。
训练时计算出每一个小批量的均值与方差,对输入的每个xxx进行标准化:x标准=x−μσ+ϵx_{标准}=\frac{x−μ}{σ+\epsilon}x标准=σ+ϵx−μ。其中μμμ和σσσ分别表示小批量特征的均值和标准差,ϵ\epsilonϵ是一个很小值目的是防止分母为0。 标准化之后,特征具有零均值和单位方差,即E[x−μσ]=μ−μσ=0E[\frac{x−μ}{σ}] = \frac{μ-μ}{σ}=0E[σx−μ]=σμ−μ=0和E[(x−μ)2]=(σ2+μ2)−2μ2+μ2=σ2E[(x−μ)^2]=(σ^2+μ^2)−2μ^2+μ^2=σ^2E[(x−μ)2]=(σ2+μ2)−2μ2+μ2=σ2。
- LayerNorm
对每个样本进行标准化
二维输入的情况:LayerNorm的结果 = 将数据转置之后放入BatchNorm在转置回来的结果
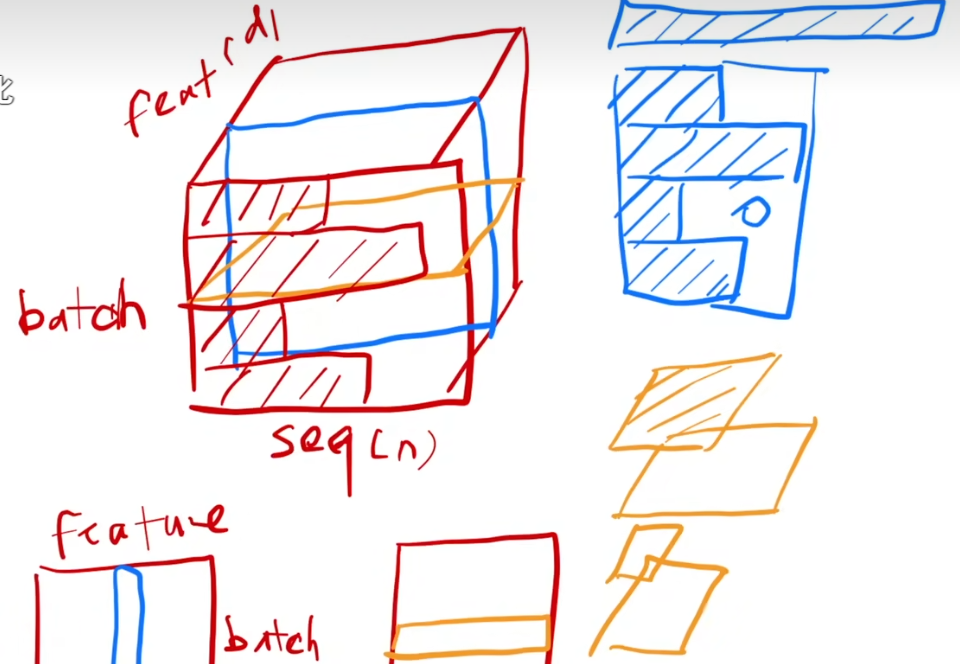
Transformer的输入常为三维张量[Batch Size, Sequence Length, Feature Dimension],假设输入样本["I love AI", "Hello world"],设最大长度 L=4,短序列需填充特殊标记 [PAD]
| 原始句子 | 分词结果 | 填充后序列 |
|---|---|---|
| I love AI | [“I”, “love”, “AI”] | ["I", "love", "AI", "[PAD]"] |
| Hello world | [“Hello”, “world”] | ["Hello", "world", "[PAD]", "[PAD]"] |
| 维度 | 描述 |
|---|---|
| Batch Size(B) | Batch Size 表示并行处理的独立样本数量。例如输入2个句子时 B=2,该维度的索引 b ∈ [0, B-1] 对应第b个样本 |
| Sequence Length(L) | L是固定长度表示填充对齐后的最大Token数,每个样本的实际Token数≤L。每个位置索引 l ∈ [0, L-1] 对应序列中第 l 个位置:有效Token或填充符[PAD]。 |
| Feature Dimension(D) | Feature Dimension 是每个Token的融合表示向量维度,由词嵌入(Word Embedding)与位置编码(Positional Encoding)相加而成,同时编码语义与位置信息。 |
- BatchNorm:每次取一个特征维度(特征维度的值不变) = 所有样本所有序列的某一维度,取出来应该是矩形下图中的蓝色部分,拉成一个向量和之前二维输入做一样的运算。
- LayerNorm:每次取一个特定的样本(样本维度的值不变) = 一个样本的所有序列的所有向量(取一个句子),下图中的黄色部分
问题:为什么LayerNorm用的更多一点
解答:在序列模型(序列中元素的顺序包含重要信息,且前后元素存在动态关联)里面,每个样本的长度是不一样的。
BatchNorm如果样本长度变化较大,每次做小批量时计算出来均值和方差上抖动较大(有些地方是填充值)。做预测时,需要把全局的均值和方差记录下来,假设预测的样本特别长,可能之前计算的均值和方差不那么好用。
LayerNorm①每个样本自己算均值和方差 ②用均值和方差标准化该样本的每个数据点。 ③对标准化结果进行缩放和平移(引入可学习参数γγγ和βββ)
Transformer作者的原话:BatchNorm要求所有序列等长,而语言的本质就是参差不齐!

问题:为什么主流归一化方法中,最后需要对标准化的结果进行缩放和平移,引入可学习参数γγγ和βββ
解答:标准化会强制数据分布变化,所有制被压缩到标准正态分布,会造成信息损失。
①幅度丢失,原本 “非常重要”(数值=100)和 “一般重要”(数值=10)的差异被压缩成微小区间。
②结构破坏,原本不同群体(如名词/动词)的分层结构被抹平。
数学表达公式:y=γ⋅x^+β,其中x^=x−μσ+ϵy=γ⋅ \hat x+β,其中 \hat x=\frac{x−μ}{\sigma+\epsilon}y=γ⋅x^+β,其中x^=σ+ϵx−μ
- γ(缩放因子):恢复数据原始幅度差异,值约等于标准差
- β(平移因子):恢复数据的分布偏移,值约等于均值
标准化在预处理阶段先将所有特征强行拉回零点附近(均值0)并统一尺度(方差1)去解决梯度爆炸/消失问题,然后在训练阶段允许模型通过γγγ和βββ参数自主学习最优分布形态(在安全范围内调整数值范围)。
解码器
自回归(Autoregressive, AR) 是一种基于历史数据预测未来的方法,其核心思想是当前时刻的值yty_tyt是过去时刻值yt−1,,...,y1y_{t−1},,...,y_{1}yt−1,,...,y1的线性组合。在大型语言模型(如GPT)中,自回归体现为:每一步生成一个新词,将其重新输入以生成下一个词。
Masked Multi-Head Attention 的核心目的:解决自回归任务中的“信息泄露”问题,保持训练和预测时行为的一致性 —— 在预测第 t 个时刻的输出时,强制模型仅能关注前 t-1 的历史时刻(当前位置及左侧),禁止偷看 t 及之后的信息(右侧)
注意力子层
Scaled Dot-Product Attention 缩放点积注意力
注意力分数的选择有很多种方式,Transformer里使用的是Scaled Dot-Product Attention 缩放点积注意力。
这里公式的理解可以参考第二章的内容[注意力机制-举例理解版本]
Scaled Dot-Product Attention缩放点积注意力公式:Attention(Q、K、V)=softmax(QKTdk)VAttention(Q、K、V)=softmax(\frac {QK^T}{\sqrt d_k})VAttention(Q、K、V)=softmax(dkQKT)V
- 矩阵Q矩阵的形状是n×dkn \times d_kn×dk,每个query表示"当前需要获取什么信息",所以n表示当前需要计算的序列长度。
- 矩阵K形状是m×dkm \times d_km×dk,其中dkd_kdk表示向量维度。每个key表示"我能提供什么信息",m用于计算注意力的上下文序列长度(总的),为 n 个位置生成表示,但基于 m 个上下文计算。
- 矩阵V形状为m×dvm \times d_vm×dv,key-value是成对出现的,dvd_vdv表示存储词原始的语义(决定输出的信息),加权求和时保留信息量
问题:为什么要除以dk\sqrt d_kdk
dkd_kdk比较大时,内积的结果可能会非常大,不同元素之间的相对差距变大。
大的值softmax之后靠近1,小的值softmax之后靠近0,这样导致将权重集中在一个地方没有考虑其他词的影响。最终模型训练出来我们希望的结果是置信的地方接近1,其余两端靠拢,当前情况差不多符合条件,计算出来梯度比较小,模型认为已经完美预测就停止学习了。

除以dk\sqrt d_kdk 的好处:
- 压缩输入幅值 → 使softmax保持在敏感区间
- 维持合理概率分布 → 提供持续学习信号
- 保护信息多样性 → 增强模型表达能力
Causal Mask 因果掩码
目的:避免t时刻看见之后的信息
对于qtq_tqt来说我们希望它只能看见k1,k2,...,kt−1k_1,k_2,...,k_{t-1}k1,k2,...,kt−1,但是在注意力机制中QK做内积的时候,相当于所有信息都看见了,所以这里添加Mask操作来实现只看前面时刻的信息。内积时正常计算,在Mask操作里把不应该看见的内积值设置为负无穷,softmax时该值会变成0也就是不分配权重。
Multi-Head Attention
多头注意力机制公式:
MultiHead=Concat(head1,head2,...,headh)WO,whereheadi=Attention(QWiQ,KWiK,VWiV)MultiHead=Concat(head_1,head_2,...,head_h)W^O,where\;head_i = Attention(QW_i^Q,KW_i^K,VW_i^V)MultiHead=Concat(head1,head2,...,headh)WO,whereheadi=Attention(QWiQ,KWiK,VWiV)
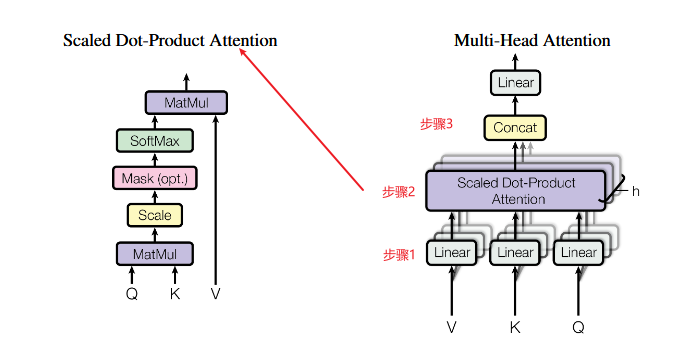
多头注意力机制思路:将模型分为多个头,形成多个子空间,可以让模型去关注不同方面的信息。上图中Multi-Head Attention 就是将 Scaled Dot-Product Attention 过程做 H 次,再把输出合并起来。
- 步骤1:输入变换与线性投影
从左边的图来看,每一组单头注意力机制都需要一组QKV作为输入。图上的QKV是通用定义,在Transformer里其实是自注意力场景,表示同一个原始序列输入X。
这里有个讨论点说,论文中描述是使用多个W变换到子空间,但实现上一般采用分段Wq,k,vW^{q,k,v}Wq,k,v的方式。

Qi=XWiQQ_i=XW_i^QQi=XWiQ投影到dkd_kdk维
Ki=XWiKK_i = XW_i^KKi=XWiK投影到dkd_kdk维
Vi=XWiVV_i=XW_i^VVi=XWiV投影到dvd_vdv维
i表示独立注意力头的索引,从图上来看就是h层独立注意力头中的第i个Scaled Dot-Product Attention,不同的独立注意力层表示从不同的角度看相关性,或者说聚焦于输入数据的不同部分。
- 步骤2:每个头独立计算注意力,每个头有独立的、可学习的、参数矩阵 WiQ,WiK,WiVW_i^Q,W_i^K,W_i^VWiQ,WiK,WiV_。_各头并行计算headi=softmax(QiKiTdk)Vihead_i=softmax(\frac {Q_iK_i^T}{\sqrt d_k})V_iheadi=softmax(dkQiKiT)Vi,互不影响。
whereheadi=Attention(QWiQ,KWiK,VWiV)where\;head_i = Attention(QW_i^Q,KW_i^K,VW_i^V)whereheadi=Attention(QWiQ,KWiK,VWiV)
这里的QKV是通用定义,在Transformer里其实是自注意力场景,表示同一个原始序列输入X。
- 步骤3:拼接与融合
MultiHead=Concat(head1,head2,...,headh)WOMultiHead=Concat(head_1,head_2,...,head_h)W^OMultiHead=Concat(head1,head2,...,headh)WO
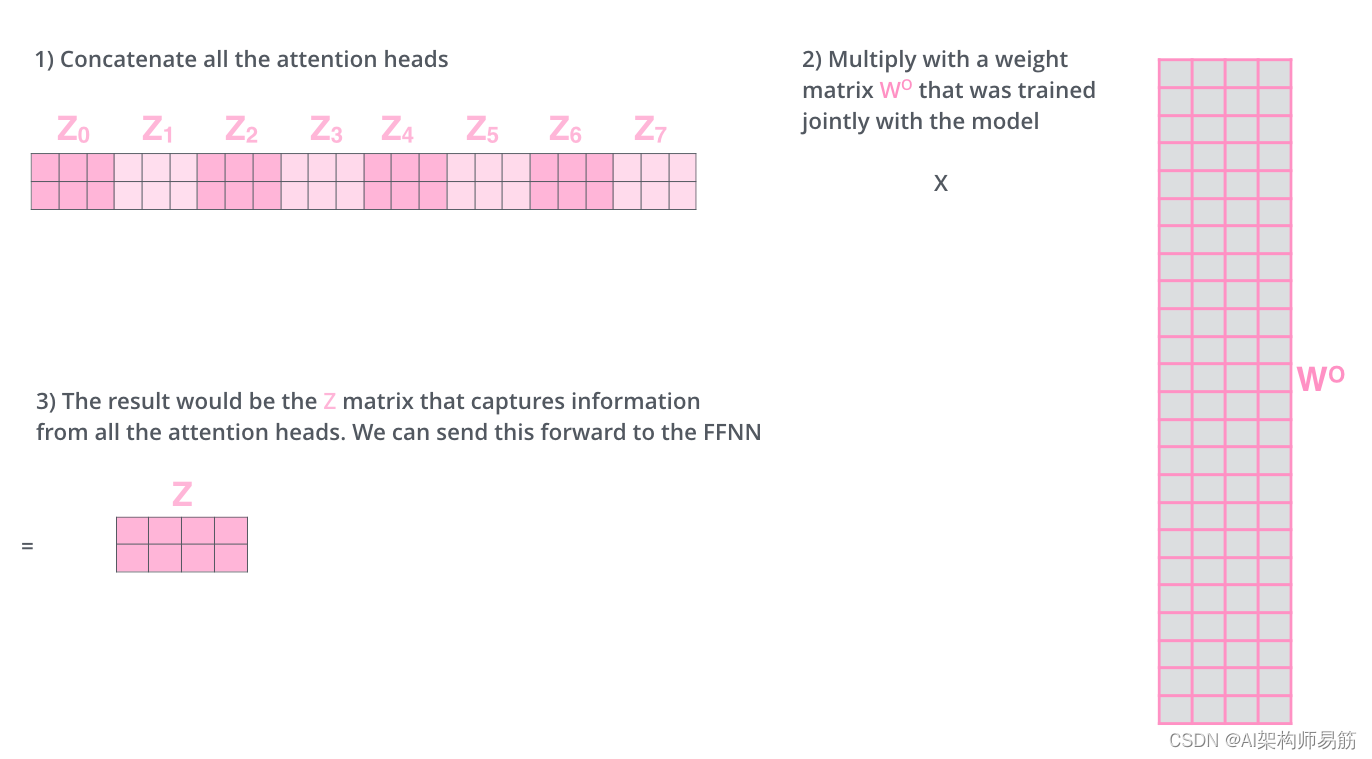
下图展示了这个过程,其中h=8,矩阵Z表示每个头独立计算的结果矩阵。先将Z0,Z1,...,Z7Z_0,Z_1,...,Z_7Z0,Z1,...,Z7拼接成一个矩阵。通过Feed Forward层也就是最后一个线性层融入数据的不同信息,做法是乘以线性层的权重矩阵WOW^OWO,从而得到最后的嵌入矩阵。

Transformer模型里如何使用Attention
**情况1:**编码器中的自注意力层
假设句子的长度是n,编码器的输入是n个长为d的向量。
同一个输入复制三份,分别作为key、value、query,key=value=query,所以这里是自注意力机制。在下图中,红色是输入,每一个块是一个token,蓝色表示query,绿色是query与keyikey_ikeyi对应的注意力权重(自己跟自己的权重肯定是最大的)
输入是n个query,每个query得到一个输出一共有n个输出(长度与value一致),每个query的输出是value的加权和(不考虑多头)。
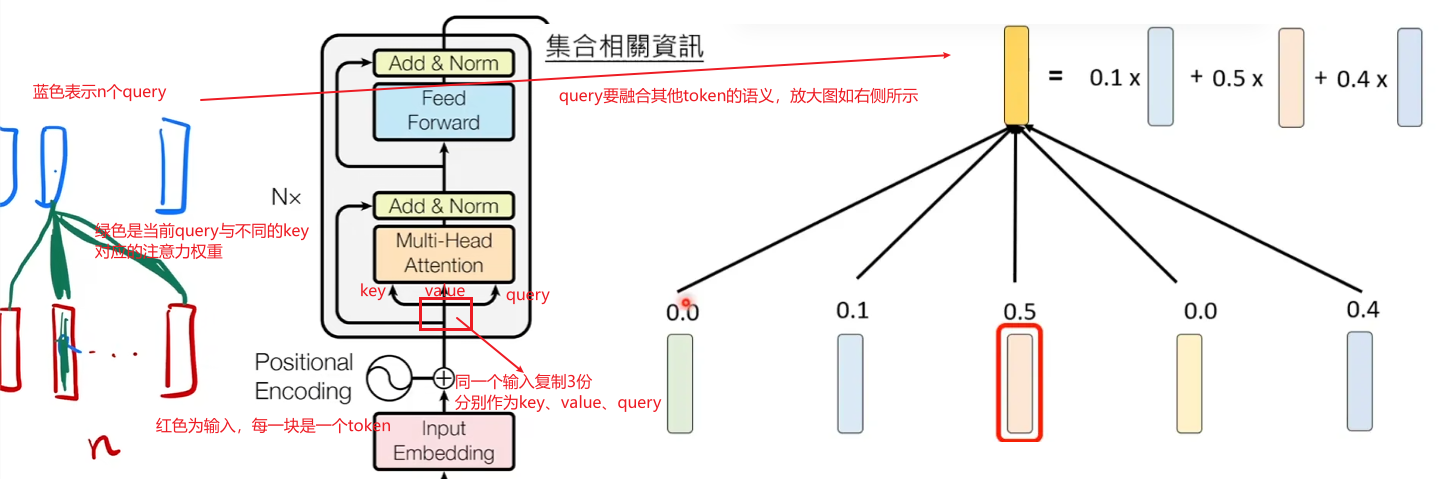
下图可以看出这里query的输出是f(57),使用α(q,ki)\alpha(q,k_i)α(q,ki)来表示qqq与kik_iki对应的注意力权重,与其相乘的是value值。
情况2:解码器中的自注意力层(因果注意力)
大致的情况和编码器中差不多,但是增加了Mask。
解码器中的自注意力层允许解码器中的每一个位置关注包括该位置在内的之前位置,对于qtq_tqt来说我们希望它只能看见k1,k2,...,kt−1k_1,k_2,...,k_{t-1}k1,k2,...,kt−1。所以需要防止解码器中的信息向左流动,以保持自回归属性。
具体做法是在缩放点积注意力Attention(Q、K、V)=softmax(QKTdk)VAttention(Q、K、V)=softmax(\frac {QK^T}{\sqrt d_k})VAttention(Q、K、V)=softmax(dkQKT)V时,QKQKQK内积正常计算,在Mask操作里把不应该看见的内积值设置为负无穷,softmax时该值会变成0也就是不分配权重。
**情况3:**编码器-解码器注意力(不是自注意力)
key和value来自编码器最后一层的输出(n个长为d的向量),这里的kv已经包含了所有编码后的信息,
query来自解码器自注意力层的输出(m个长为d的向量)。
这使得解码器中的每一个位置都能关注输入序列中的所有位置,当前的query从key和value中提取到需要的信息。假设在做英译中时,中文’好’的时候需要去编码器中找到’hello’做权重和。
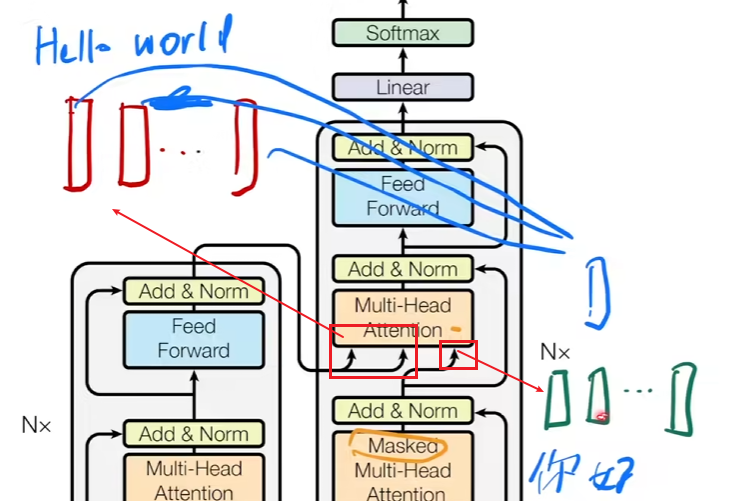
问题1:n和m数量一定要匹配吗?
回答:不一定要匹配,比如在英译中时,输入5个单词,输出的中文可能就2个。
Position-wise Feed-Forward Networks 位置感知的前馈神经网络
位置感知的前馈神经网络FFN(x)=max(0,xW1+b1)W2+b2FFN(x)=max(0,xW_1+b_1)W2+b2FFN(x)=max(0,xW1+b1)W2+b2,其中xW1+b1xW_1+b_1xW1+b1是第一个线性层,max(0,xW1+b1)max(0,xW_1+b_1)max(0,xW1+b1)是ReLu的激活层,max(0,xW1+b1)W2+b2max(0,xW_1+b_1)W2+b2max(0,xW1+b1)W2+b2为第二个线性层。
在注意力层中,每个query对应输出的维度为512,所以xxx是一个512的向量。在FFN中,W1W_1W1将512投影成2048,W2W_2W2又把2048投影回了512。
该网络分别且等效地应用于每个位置,每一个token都是一个positon,MLP对每一次token作用一次。位置(Position)即序列中token的索引序号,比如输入序列[“你”, “好”, “吗”]中,你表示位置0,好表示位置1,吗表示位置2。每个位置对应一个512维向量(注意力层的输出向量),FFN对每个位置的向量独立计算,不依赖序列中其他位置的向量。因计算无位置间依赖,所有位置的FFN可同步并行执行。
举例说明
考虑最简单情况,没有残差连接、layerNorm、单头Attention。Attention的作用是把整个序列里面的信息抓取出来,做一次汇聚。由于MLP的输入已经包含了序列信息,所以每个MLP只要在每个点独立做就行了。
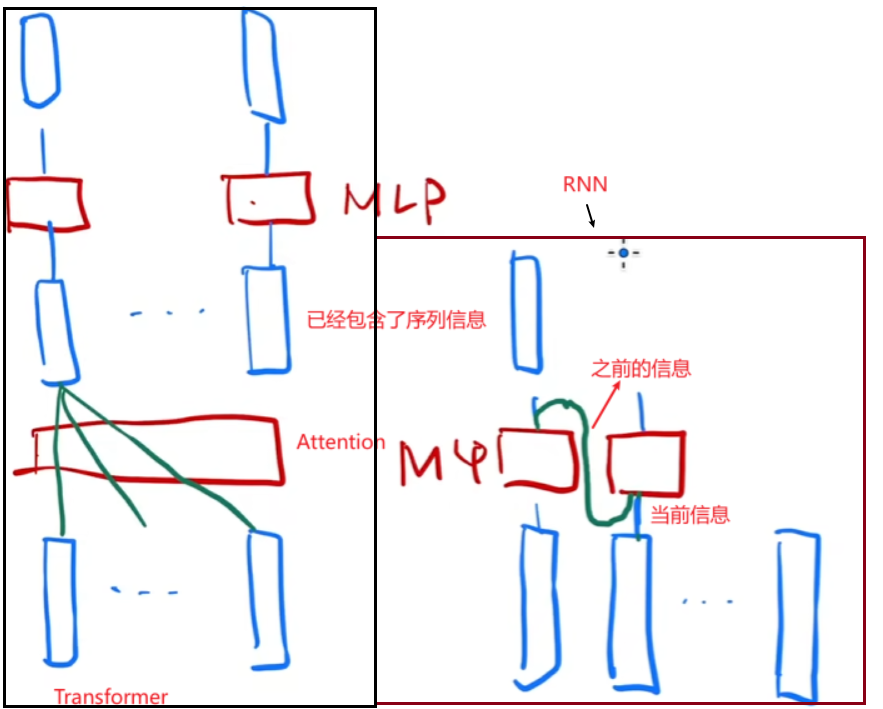
Transformer和RNN都是使用MLP来做语义空间的转换,区别在如何传递序列信息。
- RNN:上一个时刻的隐藏状态(ht−1h_{t−1}ht−1)与当前输入(xtx_txt)共同计算当前状态hth_tht。hth_tht 的计算必须等待 ht−1h_{t−1}ht−1 完成,导致无法并行处理序列
- Transformer:通过Attention层全局拿到整个序列里面的信息,然后MLP做语义转换。任意位置都独立计算,彻底解决长程依赖问题。
Embeddings
Embedding:将输入的词源token映射成一个长为d的向量表示,也就是说给定任何一个词学习一个长d的向量来表示。
- 嵌入层(Embedding)在输入阶段之后,将离散符号转换位向量表示
- Linear层(输出投影层)在解码器输出阶段(softmax前),将向量投影会词汇
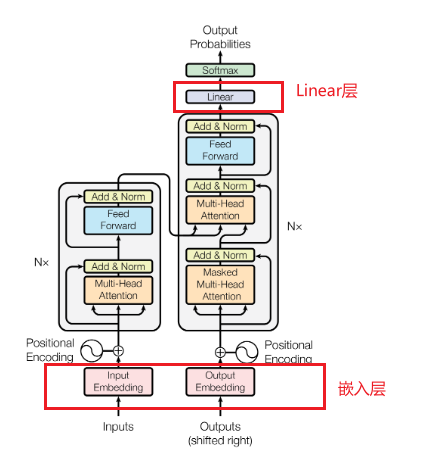
输入嵌入层与输出投影层使用相同的权重矩阵(转置关系),模型的参数会减少,训练简单。

权重矩阵 = 嵌入矩阵
模型有一个预设的词汇库,包含了所有可能的词汇以及每个词汇对应的嵌入矩阵Embedding matrix=[词汇表大小 V × 嵌入维度 d]。单词是通过“查找”嵌入矩阵(Embedding Matrix)来转化为向量的。
- 根据预设词汇库里的词进行句子划分块。
Embedding matrix里每一列决定了第一步中,每个单词对应的向量,每个向量只能编码单个单词的含义。
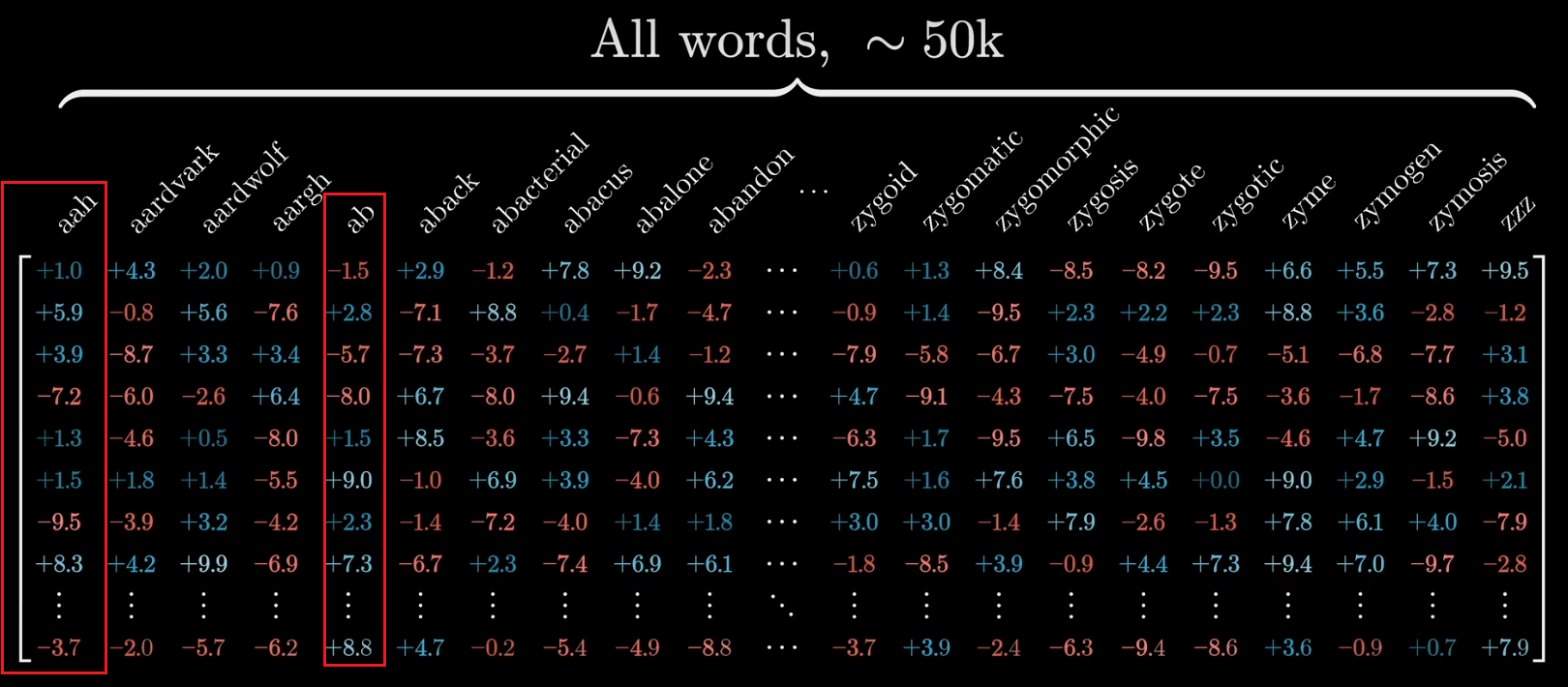
问题:怎么获得嵌入矩阵
Embedding matrix嵌入矩阵写为WEW_EWE,和其他矩阵一样,初始值随机。然后基于数据进行学习,在Transformer出现之前,将单词转换为向量就是机器学习中的常见做法。
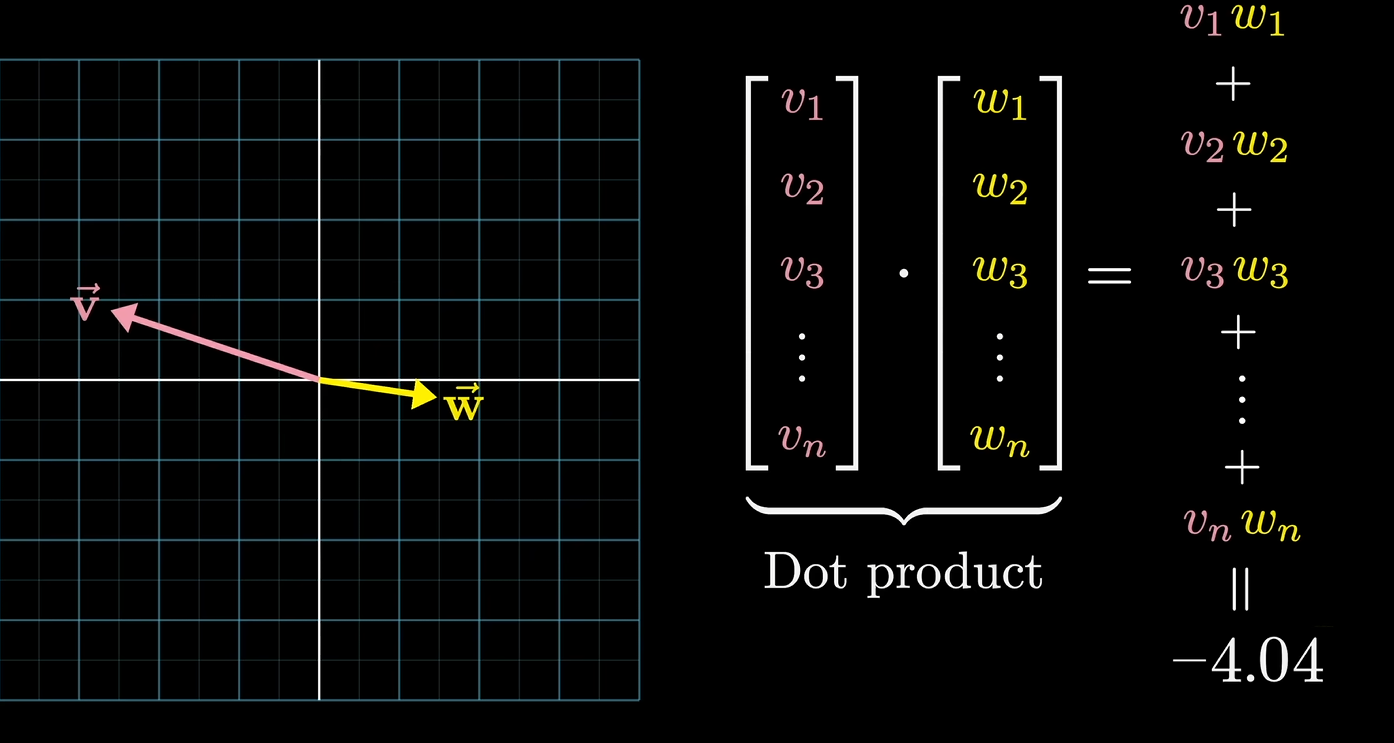
点积的一个角度
两个向量的点积可以看作是衡量他们对齐程度的一种方法,从代数的角度来看点积实际上是将所有对应分量相乘然后求和.
从几何方向看,向量的方向相近则点积为正,两向量垂直则点积为0,向量指向相反则点积为负,方向越接近,点积越大。
假设两个向量表示用户对电影的评分(维度:动作分、浪漫分、喜剧分):
- 用户A:A=[8,2,1](爱动作片)
- 用户B:B=[7,3,0](也爱动作片)
- 用户C:C=[1,9,5](爱浪漫喜剧)
=> 用户A与B的点积更高 → 两人兴趣对齐度高
在嵌入层中,将权重矩阵乘以 dmodel\sqrt {d_{model}}dmodel
Embedding(xi)=W[xi]×dmodelEmbedding(x_i)=W[x_i]×\sqrt {d_{model}}Embedding(xi)=W[xi]×dmodel(其中 W[xi]W[x_i]W[xi]是查表得到的原始向量)
问题根源:点积注意力的方差膨胀

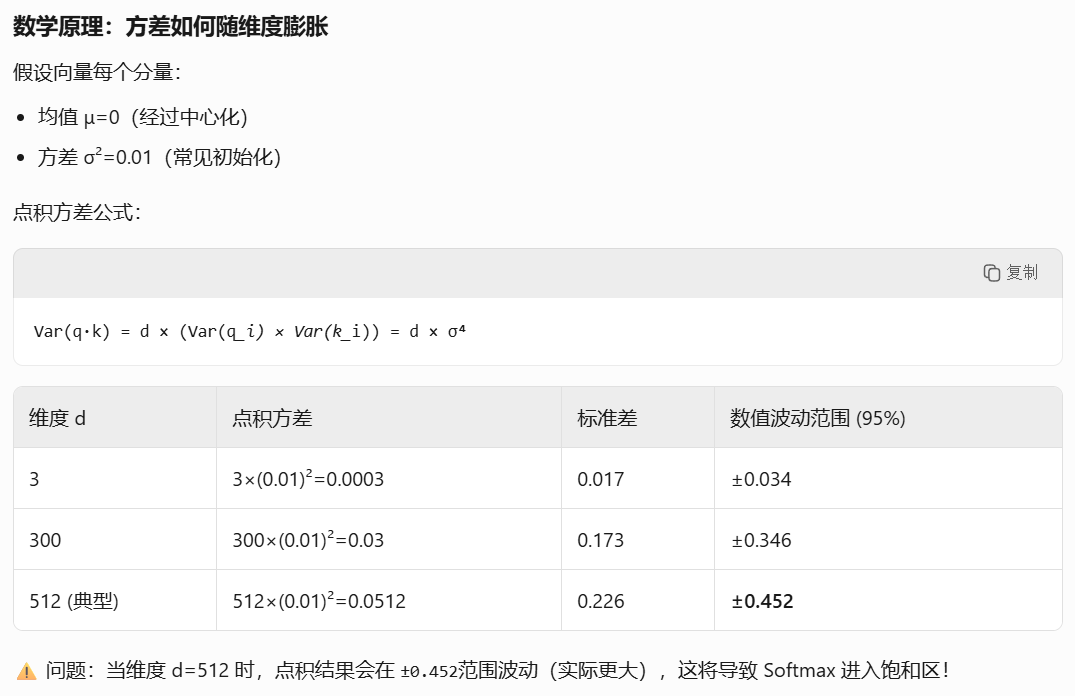
原则:在神经网络中,为了保持信号在层间的稳定性,我们希望各层输出的方差接近1。

一般情况下,为了使向量能力不过大也不过小,通常设定d⋅Var=>Var=1dd·Var => Var = \frac{1}{d}d⋅Var=>Var=d1
解决步骤1:嵌入层放大dmodel\sqrt {d_{model}}dmodel
嵌入向量初始方差很小,点积之后的方差也很小,softmax趋近于0,无法有效学习。
这一步的目的是解决信号太弱问题,提升表示能力。
方差=(dmodel)2×1d=1方差=(\sqrt {d_{model}})^2×\frac{1}{d}=1方差=(dmodel)2×d1=1
解决步骤2:点积后除以dmodel\sqrt {d_{model}}dmodel
当我们将向量放大后,点积的方差大幅度增长,如果不缩小会导致softmax输入值过大,梯度消失。
这一步的目的是解决数值爆炸问题。
方差=dmodel×1×1dmodel=1方差= \frac{d_{model}×1×1}{d_{model}}=1方差=dmodeldmodel×1×1=1
Positional Encoding
单独看Attention步骤时,其实是没有包含时序信息。从输出看是value的加权和,权重是query和key的注意力分数。也就是说如果把一句话打乱,attention出来的结果都是一样的。这样肯定是不行的,所以在Attenion之前需要添加时序信息。
token在词嵌入层Embedding使用512的向量表示,这里同样使用一个512的向量来表示位置(0123…),位置信息的具体值是使用周期不一样的sin和cos函数计算而来。其中,pos代表位置,i代表维度。也就是说,位置编码的每个维度对应一个正弦波。
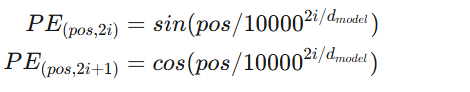
将Embedding的结果加上时序信息的向量就将时序信息加到了Embedding中。
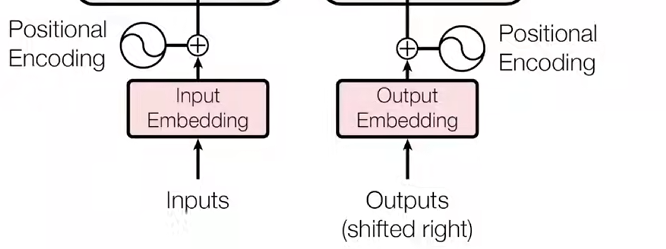
为什么使用自注意力
比较了自注意力层、循环层、卷积层、受限的自注意力层(query只跟最近的r个邻居做运算),第一列表示计算复杂度(越低越好),第二列表示下一步计算必须等前面多少步计算完成(越少表示并行度越高),第三列表示信息从一个数据点走到另外一个数据点要走多远(越短越好)
n序列的长度,d向量的长度,自注意力其实就是矩阵做运算,矩阵里面并行度比较高。query会和所有key做运算,输出value的加权和,任何query和很远key-value只需要一次矩阵计算就可以知道。
