lerobot[act解析]
ACT是具身智能模仿学习中重要的一个算法,本文会先从这个算法是是什么,这个算法如何工作的,到这个算法为什么有效,也就是what->how->why的这么一个顺序来进行解析
ACT 是什么?(What)
核心功能:
ACT 算法是具身智能模仿学习中的核心算法,其核心目标是通过多模态输入(视觉图像 + 关节状态)生成未来k 步的关节角度序列(Action Sequence),为机器人或具身智能体提供连续动作规划能力。
输入:
视觉信息:4 个摄像头的图像(维度 480×640×3),经预处理后提取特征+当前关节状态:2 只手共 14 个关节的角度(维度 14)。
输出:未来k 步的关节角度序列(每一步为关节角度的连续值,构成动作序列)。
ACT 如何工作?(How)
模型架构:基于条件变分自编码器(CVAE)的 Transformer 框架
整体分为编码器(Encoder)、 解码器(Decoder) 两部分,利用 CVAE 建模条件分布,结合 Transformer 处理序列依赖。
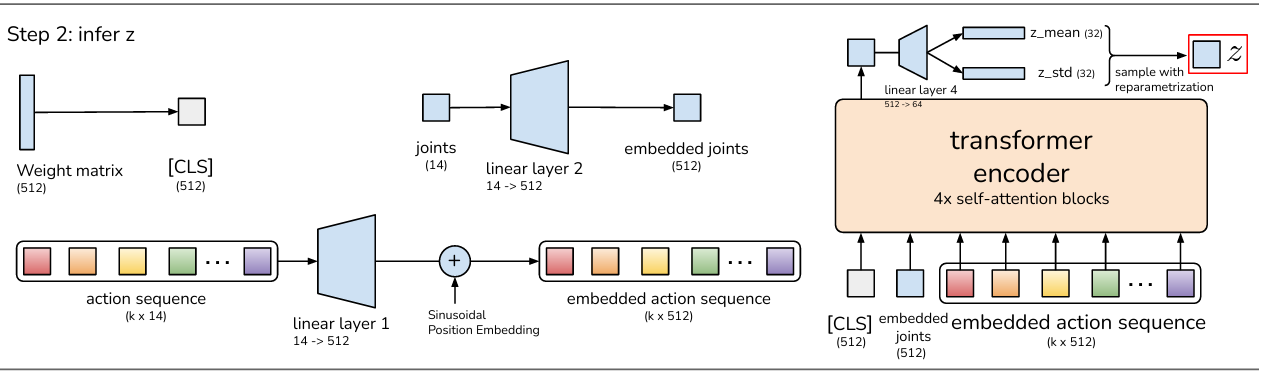
- 编码器(Encoder):构建潜在空间表示
输入处理:
关节位置嵌入:将 14 维关节角度通过线性层映射到 512 维;
动作序列嵌入:将动作序列(每步关节角度)线性映射到 512 维,叠加位置编码以捕获时序信息;
CLS 头:引入可学习的嵌入向量(1→512)作为序列全局表征。
三者按 CLS 头 + 关节嵌入 + 动作序列嵌入 的顺序拼接,形成输入序列。
特征提取:通过 Transformer Encoder 处理拼接序列,输出仅保留 CLS 头的输出(全局特征),也就是output[0],经线性层映射为 64 维向量,前 32 维为均值(μ),后 32 维为两倍对数方差(2logσ²)。
潜在变量采样:通过重参数化技巧,从正态分布 N (μ, σ²) 中采样 32 维向量z,作为潜在空间表示。
重参数化采样:
其中 a ∼ N ( 0 , 1 ) a \sim N(0,1) a∼N(0,1)
z = μ + σ 2 ⋅ a z = \mu+\sigma^{2} \cdot a z=μ+σ2⋅a
使得能够计算梯度
-
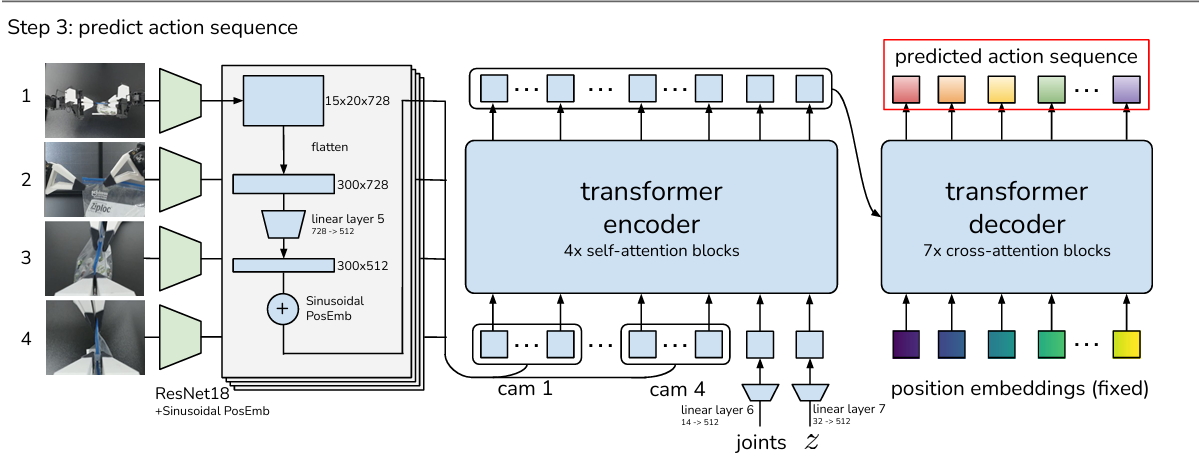
解码器(Decoder):生成动作序列
输入处理:
视觉特征:4 个摄像的图像(图像维度为[4806403])经 ResNet18 提取特征(15×20×728),展平后通过线性层 + 位置编码,转换为 300×512 的图像嵌入;
关节嵌入:当前关节位置线性映射至 512 维;
潜在变量嵌入:将 z 线性映射至 512 维。
三者拼接后输入 Transformer Encoder,生成多模态融合特征。
时序解码:
生成k (对应动作序列长度)个位置嵌入(维度 512与encoder输出匹配),作为 Decoder 的输入查询向量;
通过 Transformer Decoder 与 Encoder 输出的多模态特征进行交叉注意力交互,逐步预测每一步的关节角度,最终输出k 步动作序列。
-
训练与推理
训练阶段:
先从录制的数据集中采样,然后前向传播生成预测动作,然后计算损失

损失函数包含两部分:
重构损失:预测动作序列与真实序列的均方误差(MSE),衡量动作精度;
KL 散度(lreg):约束潜在变量 z 接近标准正态分布,避免过拟合。
反向传播优化模型参数,使生成动作尽可能接近专家演示。
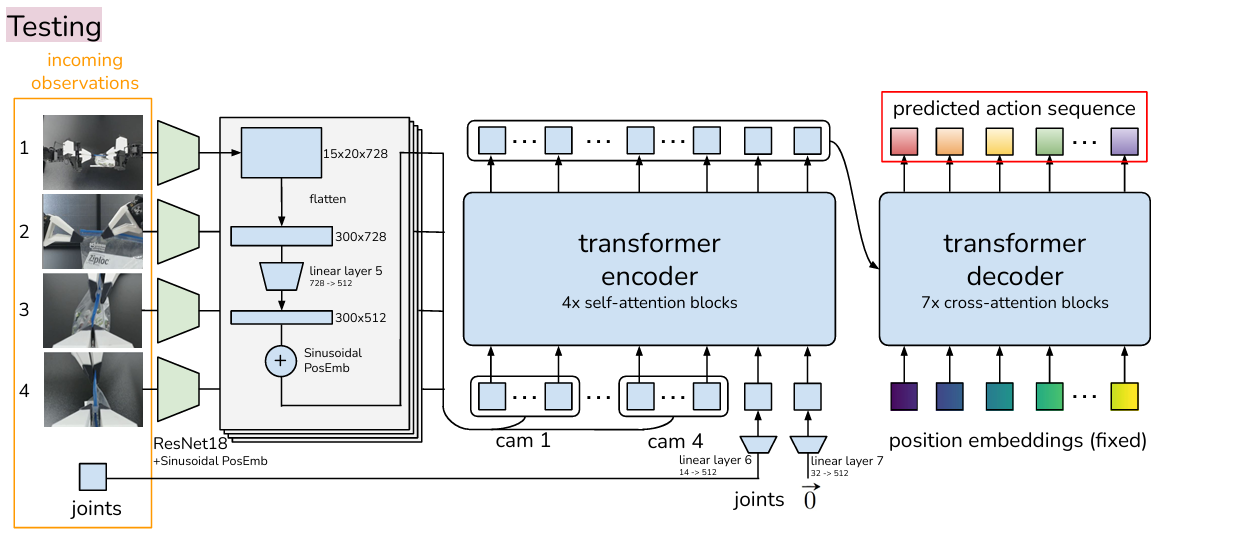
推理阶段:
无需编码器,直接使用解码器,以 32 维零向量(0 嵌入)替代训练中的潜在变量 z,结合当前视觉与关节状态生成动作序列,提升泛化性。
ACT 为何有效?(Why)
- 核心原理:条件生成与时序建模的融合
CVAE 的优势:
通过潜在变量 z 压缩专家演示中的关键信息(如动作风格、物理约束),将复杂动作规划转化为低维空间的分布建模,降低学习难度;
条件输入(图像 + 关节状态)使模型聚焦当前场景,生成符合环境约束的动作。
Transformer 的时序能力:
Encoder 通过自注意力捕捉关节状态与动作序列的全局依赖,Decoder 利用交叉注意力融合视觉特征与潜在表示,精准建模多模态时序关系。 - 设计优势:Action Chunking 与 Temporal Ensemble
Action Chunking(动作分块):
将长程动作序列分解为 k 步的局部块,通过递归生成多步动作,避免直接预测长序列的累积误差,提升稳定性;
位置编码与 Transformer 的结合显式建模动作的时序顺序,增强对动作节奏(如加速、减速)的捕捉能力。
Temporal Ensemble(时序集成):
训练中通过随机采样潜在变量 z,生成多样化的动作序列(类似集成学习),推理时使用零向量隐式平均化潜在分布,提升动作生成的鲁棒性与泛化性;
多摄像头视觉输入提供环境的全局视角,结合关节状态形成闭环反馈,确保动作的物理可行性(如避障、抓握稳定性)。
复现
lerobot[so100搭建,遥操作,采集数据集,ACT复现]