跨域视角下强化学习重塑大模型推理:GURU框架与多领域推理新突破
跨域视角下强化学习重塑大模型推理:GURU框架与多领域推理新突破
大语言模型(LLM)推理能力的提升是AI领域的重要方向,强化学习(RL)为此提供了新思路。本文提出的GURU框架,通过构建跨领域RL推理语料库,系统性地重新审视了RL在LLM推理中的应用,在多个推理任务上实现性能突破,为通用推理研究带来新启示。
论文标题
Revisiting Reinforcement Learning for LLM Reasoning from A Cross-Domain Perspective
来源
arXiv:2506.14965v1 [cs.LG] + https://arxiv.org/abs/2506.14965
PS: 整理了LLM、量化投资、机器学习方向的学习资料,关注同名公众号 「 亚里随笔」 即刻免费解锁
文章核心
研究背景
近年来,强化学习(RL)已成为提升大语言模型(LLM)推理能力的重要技术,OpenAI-O3、DeepSeek-R1 等前沿模型通过 RL 在数学、代码等领域展现出卓越性能。然而,当前开源社区的 RL 研究高度集中于数学与代码单域,导致两方面局限:其一,对 RL 在推理中的作用机制理解片面,现有结论(如 “RL 仅激发预训练知识”)可能无法推广至其他领域;其二,模型泛化能力受限,单域训练的模型在逻辑、模拟等未覆盖任务中性能显著衰减。核心瓶颈在于跨域 RL 所需的可靠奖励信号与高质量数据集的缺失,亟需系统性的多域研究来拓展通用推理边界。
研究问题
- 跨域Reward信号缺失:缺乏可靠且可扩展的跨领域RL奖励信号设计,导致模型难以在数学、代码之外的逻辑、模拟等领域有效学习。
- pretraining偏见制约:现有研究认为RL主要激发预训练模型的潜在知识,但未明确不同领域在pretraining中的覆盖差异如何影响RL效果。
- 模型泛化能力局限:单一领域训练的模型在跨域任务中性能衰减显著,无法应对多样化推理场景。
主要贡献
- 构建跨域RL语料库GURU:整合数学、代码、科学、逻辑、模拟、表格6大领域92K可验证样本,通过领域特定奖励设计与去重过滤,为RL训练提供可靠数据基础。
- 揭示领域依赖的RL机制:发现pretraining高频领域(如数学、代码)可通过跨域RL获益,而低频领域(如逻辑、模拟)需域内训练才能提升,证明RL兼具知识激发与新技能习得双重作用。
- 训练通用推理模型GURU-7B/32B:在17项跨域任务中超越现有开源模型,7B模型较基线提升7.9%,32B提升6.7%,尤其在复杂约束任务(如Zebra Puzzle)中显著扩展推理边界。

方法论精要
核心框架与数据流程
采用“数据采集-去重-奖励设计-启发式过滤-难度筛选”五步流水线构建GURU数据集,每个领域设计专属验证规则(如数学符号匹配、代码执行验证、科学模型语义对齐)。

基于Qwen2.5-7B/32B基线,使用GRPO算法进行RL训练,混合域数据均匀采样,避免领域干扰。
关键参数与设计原理
奖励函数分类:数学/逻辑采用规则匹配(如\boxed{}格式提取答案),代码依赖执行验证(通过测试用例),科学借助1.5B验证模型进行语义评估。
难度过滤机制:通过弱模型(Qwen2.5-7B-Instruct)和强模型(Qwen3-30B-A8B)的通过率差筛选样本,剔除过易 ( P w e a k ≥ 15 / 16 ) (P_{weak}≥15/16) (Pweak≥15/16)或过难 ( P s t r o n g = 0 ) (P_{strong}=0) (Pstrong=0)的噪声数据。
创新性技术组合
跨域迁移实验设计:对比单域与混合域训练效果,发现混合域训练在保持域内性能的同时,显著提升跨域泛化能力。
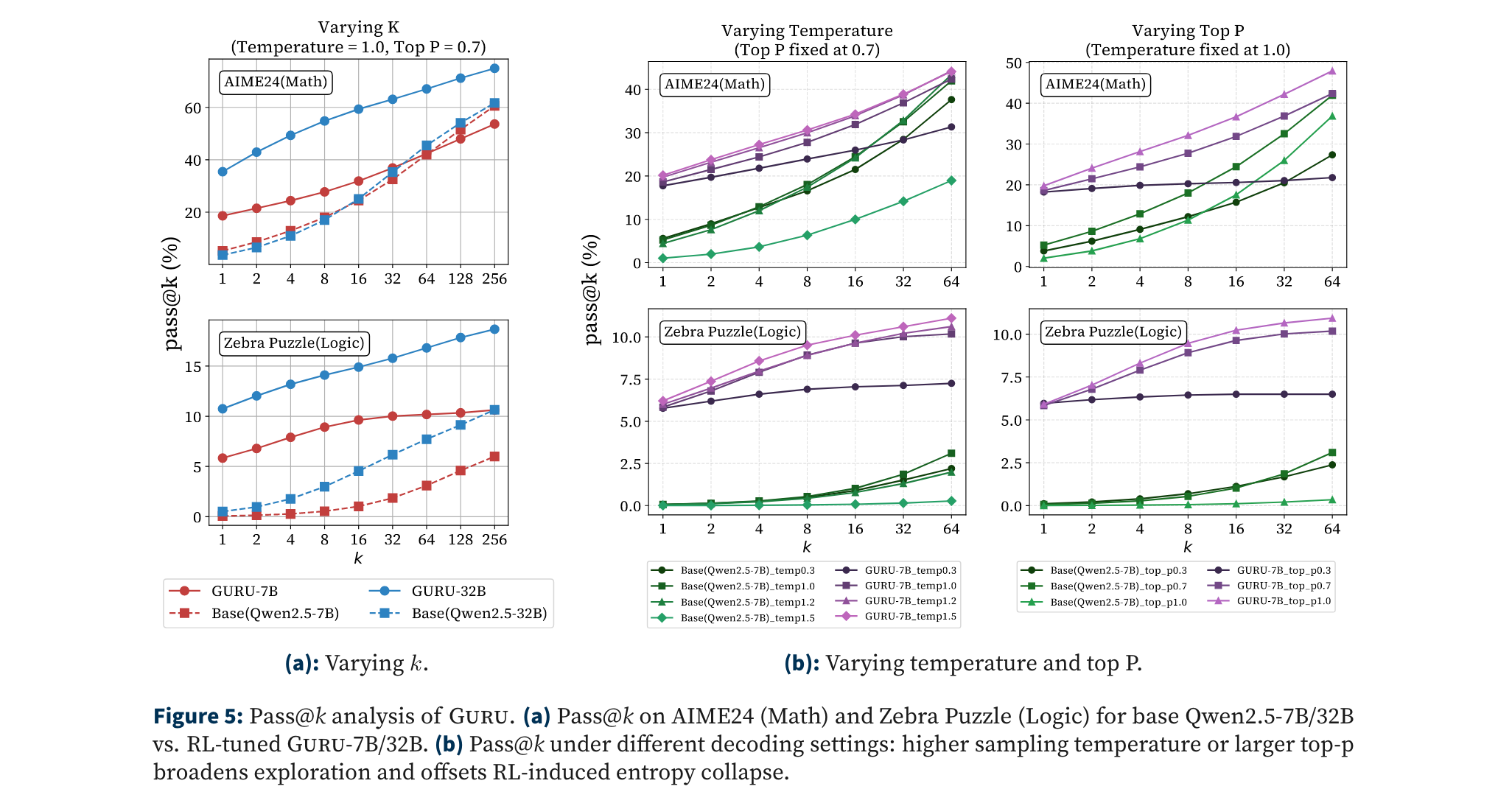
Pass@k分析框架:结合生成温度与top-p参数调整,揭示RL对模型推理空间探索的影响,如高温设置可缓解熵减导致的推理边界收缩。
实验验证逻辑
数据集:使用MATH500、HumanEval、ARC-AGI等17项基准,覆盖6大领域,离线评估生成4-32样本/问题,在线评估监控13项信号任务。
基线对比:General Reasoner、Open-Reasoner-Zero、SimpleRL等开源RL模型,均直接基于Qwen2.5基线训练以确保公平性。

实验洞察
性能优势
- 数学推理:GURU-32B在AIME24上Pass@32达34.89%,较ORZ-32B提升12.39%;MATH500准确率78.8%,超SimpleRL-32B约2.05%。
- 逻辑与模拟:Zebra Puzzle任务中,GURU-7B准确率39.4%,较基线ORZ-7B提升39.33%;CodeI/O模拟推理中,32B模型较SimpleRL-32B提升2.88%。
- 跨域泛化:混合域训练的模型在Tabular任务HiTab上准确率82.0%,较单域训练提升27.6%,验证多域数据的互补性。


效率与稳定性
训练效率:20节点×8 Hopper GPU完成7B(3轮)/32B(2轮)训练各需3天,GRPO算法通过梯度裁剪 ( ϵ = 0.2 ) (\epsilon=0.2) (ϵ=0.2)确保训练稳定。
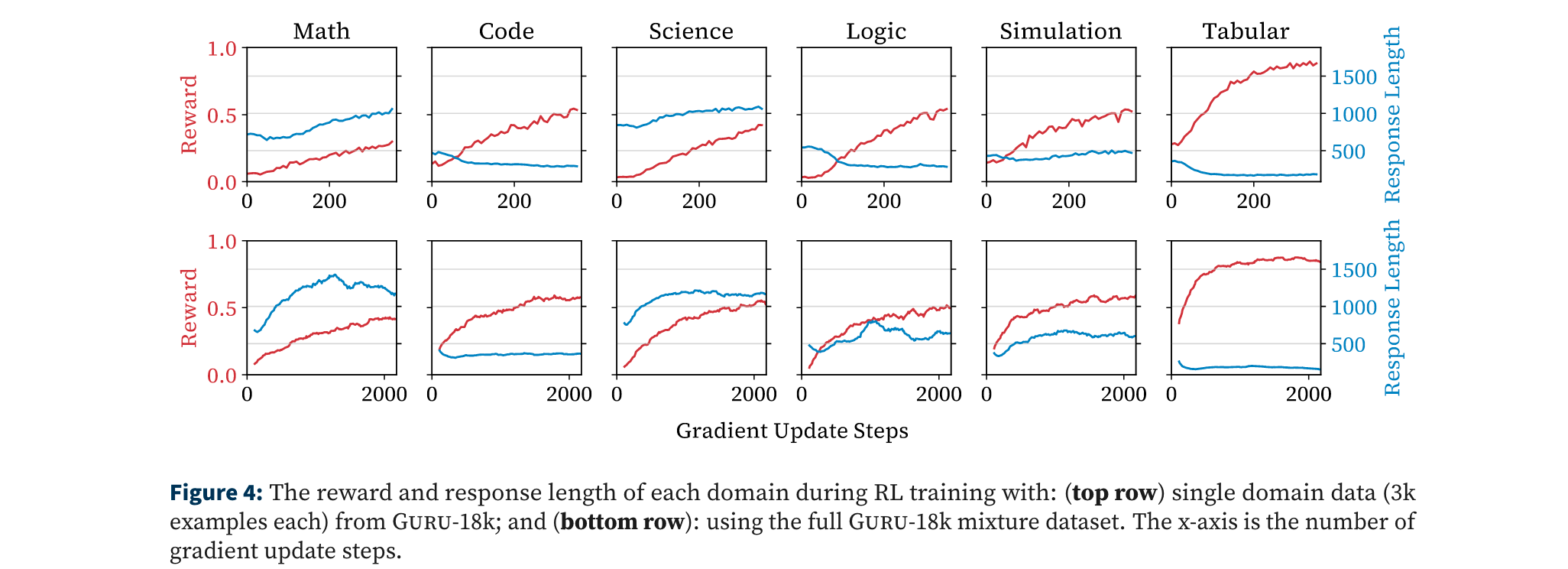
响应动态:RL训练中,代码/逻辑任务输出长度缩短,科学/数学变长,混合域训练可调节长度偏好,如逻辑任务先变长后收缩,体现表征共享效应。
实验分析
- 难度过滤影响:数学域难度过滤后,AIME24准确率提升5.9%,但HumanEval等简单跨域任务下降9.2%,表明域内难度提升与跨域迁移存在权衡。

- 模型规模效应:32B模型在AIME24的Pass@k曲线始终优于基线,而7B模型在k=64时与基线交叉,暗示大模型更易通过RL发掘新推理路径。