目标检测neck算法之MPCA和FSA的源码实现
目标检测neck算法之MPCA和FSA的源码实现
使用BIBM2024 Spatial-Frequency Dual Domain Attention Network For Medical Image Segmentation的Frequency-Spatial Attention和Multi-scale Progressive Channel Attention改进neck.
接下来,我将讲解它的源码操作的实现,结构的设计哲学,已经代码复现需要的一些基本功知识
它的结构如下

MPCA
首先是,MPCA部分的复现

Multi-scale Progressive Channel Attention(MPCA) 是 SF-UNet 中提出的核心模块之一,目标是解决医学图像中多尺度目标(如病灶形状大小不一)难以统一感知的问题。
它的输入是两个不同维度的特征图F1,F2
1
在MPCA操作中,先对F1,F2各自先进行了一个池化(自适应平均池化),然后各自经过一层11卷积*
🎯 哲学解释:
✅ 让每个通道“发言”总结自己的全图表现
GAP 是一种无参、结构不敏感的压缩方式:让每个通道用“平均值”代表自己,是信息保留最少失真的手段。
1×1 Conv 起到通道间的线性映射作用,让网络学会哪些通道更重要,哪些可以忽略。
🔍 本质目的:
将原始空间大特征 → 转为一个压缩的、通道维度的表示。
为后续注意力建模打下基础。
2
然后得到了两个新的F1,F2,进行了一个通道维度上的拼接
再经过一次11卷积操作和一个sigmoid操作*
🎯 哲学解释:
✅ 注意力的本质,是“资源分配”——哪一维特征更值得被关注
将两个层级的通道信息拼接,就是在做一种“横向对比”:看看同一语义在不同层级的表现。
用一个 1×1 卷积 + Sigmoid 激活,模拟一个资源管理者,决定哪些通道重要。
在 MPCA 中使用 Sigmoid,是为了让注意力权重具备【0-1连续调控能力】,既能表达通道重要性,又能保持稳定训练,是“柔性关注”的理性选择。
🔍 本质目的:
构建一个统一的注意力空间 ,融合并评估多尺度通道的重要性。
3
解耦注意力,分别分配给两组特征,将A分成,A1,A2
🎯 哲学解释:
✅ 统一评估,分别赋能
一开始统一建模注意力,是为了发现全局规律。
后续分别赋值,是为了保留不同层级的语义差异性。
🔍 本质目的:
防止“高低层特征被统一抹平”,而是给予它们独立但协同的注意力增强。
4
将A1,A2与原始的特征图P1,P2进行了通道乘法,
然后对维度较小的新的F2进行上采样,再对二者相加融合
🎯 哲学解释:
✅ 让网络“专注”于更有信息量的通道
注意力机制的核心作用:抑制冗余,强化关键。
每个通道根据其权重,被动态地放大或抑制。
✅ 融合不同层级的信息 —— 细节 + 语义
高层特征 :抽象语义强,但空间分辨率低。
低层特征:细节丰富,但语义弱。
将两个做加法融合,是在“补短板”:
用高层补语义
用低层保定位
🔍 本质目的:
为下游融合操作打下干净、结构明确的基础。
实现信息的多尺度整合,提升最终表达能力。
MPCA代码复现
class MPCA(nn.Module):def __init__(self, input_channel1=128, input_channel2=64, gamma=2, bias=1):super(MPCA, self).__init__()self.input_channel1 = input_channel1self.input_channel2 = input_channel2self.avg1 = nn.AdaptiveAvgPool2d(1)self.avg2 = nn.AdaptiveAvgPool2d(1)kernel_size1 = int(abs((math.log(input_channel1, 2) + bias) / gamma))kernel_size1 = kernel_size1 if kernel_size1 % 2 else kernel_size1 + 1kernel_size2 = int(abs((math.log(input_channel2, 2) + bias) / gamma))kernel_size2 = kernel_size2 if kernel_size2 % 2 else kernel_size2 + 1kernel_size3 = int(abs((math.log(input_channel1 + input_channel2, 2) + bias) / gamma))kernel_size3 = kernel_size3 if kernel_size3 % 2 else kernel_size3 + 1self.conv1 = nn.Conv1d(1, 1, kernel_size=kernel_size1, padding=(kernel_size1 - 1) // 2, bias=False)self.conv2 = nn.Conv1d(1, 1, kernel_size=kernel_size2, padding=(kernel_size2 - 1) // 2, bias=False)self.conv3 = nn.Conv1d(1, 1, kernel_size=kernel_size3, padding=(kernel_size3 - 1) // 2, bias=False)self.sigmoid = nn.Sigmoid()self.up = nn.ConvTranspose2d(in_channels=input_channel2, out_channels=input_channel1, kernel_size=3, stride=2,padding=1, output_padding=1)首先是类的属性的设置
这部分代码搭建了一些我们后面进行操作需要用到的积木,定义了一些积木的参数。
参数 比较多,自己看代码吧
积木
1*1卷积,
sigmoid,
卷积核大小的自适应公式,
上采样操作
还有一些pytorch的基本操作函数
| 项目 | 内容 |
|---|---|
| 函数定义 | nn.AdaptiveAvgPool2d(output_size) |
| 参数 | output_size=1 表示输出为 (1, 1),即每个通道输出一个值 |
| 输入形状 | (B, C, H, W) |
| 输出形状 | (B, C, 1, 1) |
| 功能说明 | 全局平均池化(GAP),提取每个通道的全局统计量,压缩空间信息 |
| 在 MPCA 中作用 | 把特征图每个通道压缩成一个标量,作为通道的重要性代表,供后续注意力机制使用 |
| 项目 | 内容 |
|---|---|
| 函数定义 | nn.Conv1d(in_channels, out_channels, kernel_size, padding, bias) |
| 常见用法 | nn.Conv1d(1, 1, k, padding=(k−1)//2, bias=False) |
| 输入形状 | (B, 1, C):表示一个 batch,每个样本有 1 条通道长度为 C 的序列 |
| 输出形状 | (B, 1, C)(由于 padding 保持长度) |
| 功能说明 | 对通道维度进行一维卷积建模,常用于轻量通道注意力(如 ECA) |
| 在 MPCA 中作用 | 捕捉通道间的局部依赖关系,相当于局部注意力增强,而非全连接建模(像 SE 那样) |
| 项目 | 内容 |
|---|---|
| 函数定义 | nn.Sigmoid() |
| 输入范围 | 任意实数 |
| 输出范围 | (0, 1),对每个元素作用 |
| 功能说明 | 激活函数,压缩权重到 [0,1],可视为门控机制或注意力权重归一化 |
| 在 MPCA 中作用 | 将通道注意力权重限制为 0~1,表示“保留程度”或“重要性”,供后续乘法使用 |
| 项目 | 内容 |
|---|---|
| 函数定义 | nn.ConvTranspose2d(in_channels, out_channels, kernel_size, stride, padding, output_padding) |
| 输入形状 | (B, C_in, H_in, W_in) |
| 输出形状 | 通常为 (B, C_out, H_out, W_out),根据公式计算(与反卷积有关) |
| 功能说明 | **反卷积(上采样)**操作,用于恢复空间分辨率 |
| 在 MPCA 中作用 | 将低分辨率特征上采样到高分辨率尺度,便于与高分辨率分支进行融合 |
接着就是积木的使用
def forward(self, x1, x2):x1_ = self.avg1(x1)x2_ = self.avg2(x2)x1_ = self.conv1(x1_.squeeze(-1).transpose(-1, -2)).transpose(-1, -2).unsqueeze(-1)x2_ = self.conv2(x2_.squeeze(-1).transpose(-1, -2)).transpose(-1, -2).unsqueeze(-1)x_middle = torch.cat((x1_, x2_), dim=1)x_middle = self.conv3(x_middle.squeeze(-1).transpose(-1, -2)).transpose(-1, -2).unsqueeze(-1)x_middle = self.sigmoid(x_middle)x_1, x_2 = torch.split(x_middle, [self.input_channel1, self.input_channel2], dim=1)x1_out = x1 * x_1x2_out = x2 * x_2x2_out = self.up(x2_out)result = x1_out + x2_outreturn result
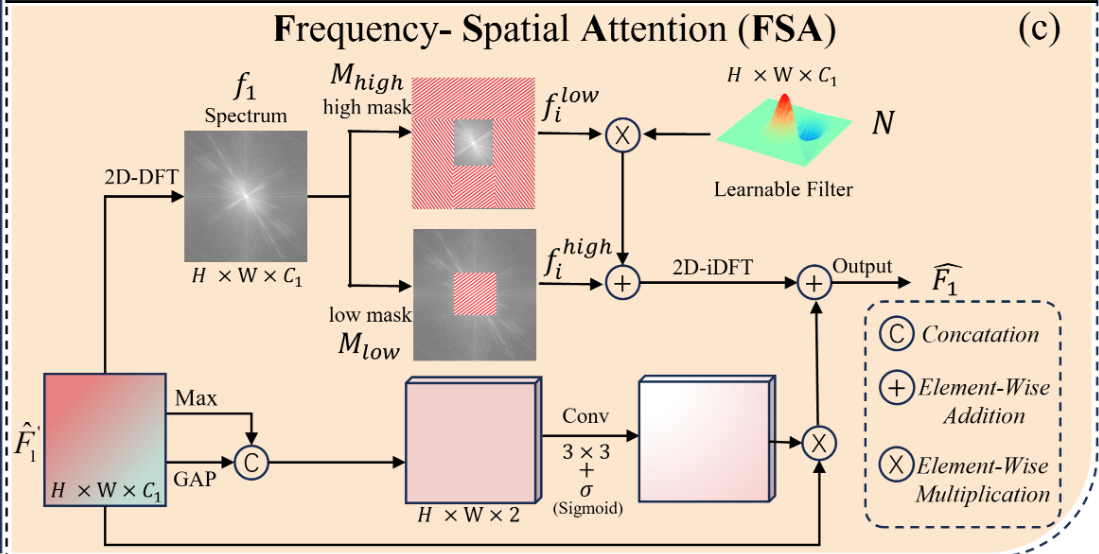
FSA
| 符号 | 名称 | 操作含义 | PyTorch 对应函数 | 应用场景与设计哲学 |
|---|---|---|---|---|
| ◯ © | Concatenation(拼接) | 沿某一维度连接两个特征图(通常是通道维) | torch.cat([x1, x2], dim=1) | 表示“信息融合但不混合”,保持两个输入的独立性;多尺度融合、跳跃连接常见 |
| ⊕ (+) | Element-wise Addition(逐元素加法) | 对应位置的像素/通道值相加 | x1 + x2 或 torch.add(x1, x2) | 特征叠加、残差连接;设计哲学是“增加信息但不改变结构” |
| ⊗ (×) | Element-wise Multiplication(逐元素乘法) | 对应位置值相乘,一般用于注意力机制 | x1 * x2 | 常用于 attention,哲学是“信息调制”:重要的地方乘大值,不重要的抑制为零 |
FSA(Frequency Self-Attention)是一种将频域思想引入注意力机制的结构,其核心设计哲学是:
用频域信息替代空间卷积建模局部或全局依赖,提升特征表达效率与感受野,同时减少参数与计算负担。
它的输入是一个特征图,然后设计了两条分支
1
一条对特征图分别进行平均池化和最大池化(通道维度上的)然后进行拼接
然后对拼接得到的特征图进**行33卷积+sigmoid**再与原来的特征图进行相乘
得到一个全局注意力权重*
🎯 哲学解释:
✅ 多视角空间描述,增强局部判别性
最大池化 → 强调显著响应区域
平均池化 → 提取整体分布
合并后用卷积提取空间注意力,聚焦有用区域
🔍 本质目的:
用轻量级方式计算出空间中“该关注哪里”的地图,强化表达焦点。
2
频谱转换 + 频段分离
低频 × 可学习滤波器 + 高频重建
还原回空间域
🎯 哲学解释:
✅ 引入频域视角,识别隐藏结构特征
空间卷积对某些全局模式(如周期、纹理)难以建模,频域天然适合解析这类结构。
✅ 区分高频与低频的语义责任
高频:边缘、边界、细节
低频:轮廓、结构、全局分布
✅ 构建可调的结构增强模块
网络不是直接使用低频,而是学习一个与上下文适配的滤波器 N,作用于低频后再叠加。
✅ 细节与轮廓协同建构表达
高频直接注入,低频经过选择性增强,两者互补。
✅ 频域不是目标,是路径
网络最终还是要在空间域完成识别任务,因此必须将频域的增强信息解码为空间模式。
🔍 本质目的:
✅把输入特征拆解成两个语义功能不同的成分,分别处理,便于后续有针对性的增强。
✅构建一个能根据语境灵活强调结构区域的机制,既保留细节,又提升语义稳定性。
✅实现频域增强 → 空间域可用的表达迁移。
3
注意力加权 + 残差融合
频域增强图 × 空间注意力图 A → 输出图
🎯 哲学解释:
✅ 二次精炼表达结果,强化重点区域
加权增强区域,再残差加回来,保证新特征兼具稳定性与判别性。
✅ 残差哲学:让网络自己决定保留多少原始信息
不是完全覆盖,而是“加法式的优化”——不抛弃、不盲从。
🔍 本质目的:
提供频域视角的可控增强路径 + 空间域的局部精调,最终保持信息一致性和增强表达力。
FSA代码复现
class FSA(nn.Module):def __init__(self, ratio=10, input_channel=64, size=512):super(FSA, self).__init__()self.agf = Adaptive_global_filter(ratio=ratio, dim=input_channel, H=size, W=size)self.sa = SpatialAttention()def forward(self, x):f_out = self.agf(x)sa_out = self.sa(x)result = f_out + sa_outreturn result
首先还是准备积木,
Adaptive_global_filter
SpatialAttention()
class Adaptive_global_filter(nn.Module):def __init__(self, ratio=10, dim=32, H=512, W=512):super().__init__()self.ratio = ratioself.filter = nn.Parameter(torch.randn(dim, H, W, 2, dtype=torch.float32), requires_grad=True)self.mask_low = nn.Parameter(data=torch.zeros(size=(H, W)), requires_grad=False)self.mask_high = nn.Parameter(data=torch.ones(size=(H, W)), requires_grad=False)def forward(self, x):b, c, h, w = x.shapecrow, ccol = int(h / 2), int(w / 2)mask_lowpass = self.mask_lowmask_lowpass[crow - self.ratio:crow + self.ratio, ccol - self.ratio:ccol + self.ratio] = 1mask_highpass = self.mask_highmask_highpass[crow - self.ratio:crow + self.ratio, ccol - self.ratio:ccol + self.ratio] = 0x_fre = torch.fft.fftshift(torch.fft.fft2(x, dim=(-2, -1), norm='ortho'))weight = torch.view_as_complex(self.filter)x_fre_low = torch.mul(x_fre, mask_lowpass)x_fre_high = torch.mul(x_fre, mask_highpass)x_fre_low = torch.mul(x_fre_low, weight)x_fre_new = x_fre_low + x_fre_highx_out = torch.fft.ifft2(torch.fft.ifftshift(x_fre_new, dim=(-2, -1))).realreturn x_out
class SpatialAttention(nn.Module): # Spatial Attention Moduledef __init__(self):super(SpatialAttention, self).__init__()self.conv1 = nn.Conv2d(2, 1, kernel_size=7, padding=3, bias=False)self.sigmoid = nn.Sigmoid()def forward(self, x):avg_out = torch.mean(x, dim=1, keepdim=True)max_out, _ = torch.max(x, dim=1, keepdim=True)out = torch.cat([avg_out, max_out], dim=1)out = self.conv1(out)out = self.sigmoid(out)result = x * outreturn result
本人思考
MPCA这个机制实际上是首先对不同维度的特征图分别处理,进行1*1卷积加权,得到了该特征图再不同维度信息的注意力,接着对不同维度进行拼接,加权,解耦,又融合了不同维度之间的注意力,再应用到原特征图上。经二者融合的结果去代替分辨率高的特征图。
我的想法:
进行每次操作时都是原特征图作为输入,可以考虑将更新后的特征图作为输入,类似于FPN的操作。(自顶向下)
最顶层的MPCA操作是最顶层已经它的下采样的特征图作为输出,实际上可能会丢失一部分信息,考虑进行通道注意之后直接输出。
考虑引进残差设计机制,因为注意力机制可能过拟合/抑制有效通道:
如果注意力模块学习出了错误的通道权重分布,可能会误伤关键通道,导致特征退化。
对于FSA机制我有一些还未解决的疑惑
进行频域的操作到底是增大了还是减小了计算量
残差融合机制的变体
| 对比项 | 逐元素加法 + | 逐元素乘法 × |
|---|---|---|
| 稳定性 | ✅ 高:不抑制原始特征 | ❌ 低:容易导致特征被压制 |
| 可解释性 | ✅ 恒等映射 + 增量学习 | ✅ 类 attention 门控 |
| 用途 | 标准残差结构 | 注意力残差、门控机制等 |
| 适合场景 | 深层网络训练稳定 | 有注意力权重参与的精调操作 |
| 风险 | 可能累加噪声 | 可能压制有效特征或梯度消失 |