知识链(Chain-of-Knowledge):通过对异构来源的动态知识适配实现大语言模型的知识落地
《CHAIN-OF-KNOWLEDGE: GROUNDING LARGE LANGUAGE MODELS VIA DYNAMIC KNOWLEDGE ADAPTING OVER HETEROGENEOUS SOURCES》这篇论文介绍了一个名为“chain-of-knowledge”(CoK)的框架,旨在通过动态整合来自异构知识源的信息来增强大型语言模型(LLMs)的性能,减少生成中的幻觉(hallucination)现象,并提高回答的准确性。论文详细描述了CoK框架的设计、实现和实验验证。
研究背景
大型语言模型(LLMs)如ChatGPT在语言生成方面表现出色,但存在一个主要挑战:幻觉(hallucination),即模型倾向于生成看似合理但事实上错误的文本。这种现象在需要事实知识回答的问题中尤为明显。尽管LLMs能够从训练数据中回忆信息,但有效更新或控制模型中的事实知识仍然具有挑战性。因此,研究者们尝试通过外部知识增强LLMs,以减少幻觉现象。
研究方法
CoK框架包含三个阶段:推理准备(reasoning preparation)、动态知识适应(dynamic knowledge adapting)和答案整合(answer consolidation)。
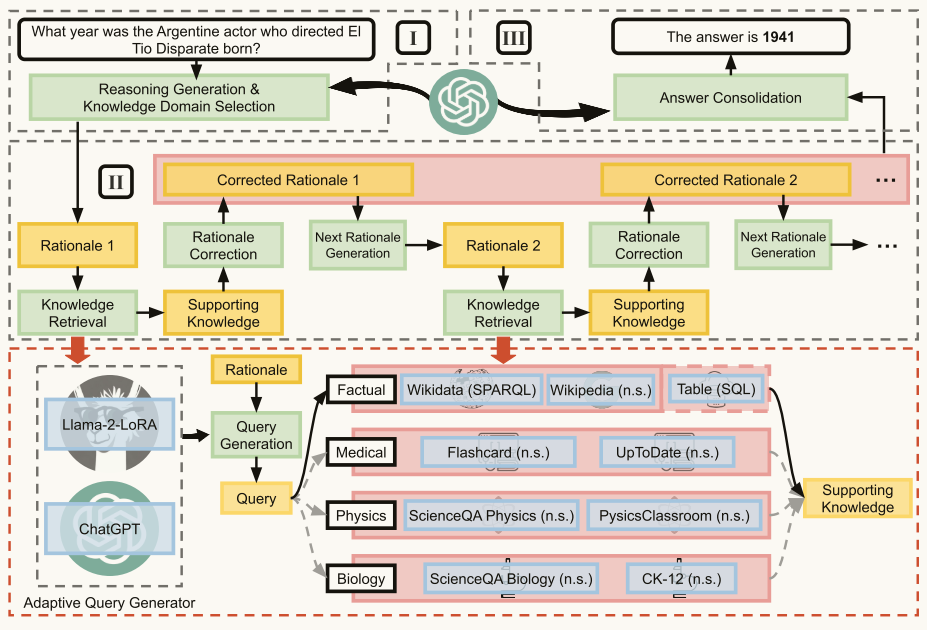
图2:我们提出的知识链(CoK)框架,包括:(I)推理准备、(II)动态知识适配,以及(III)答案整合。n.s.:自然语言句子(natural sentence)

表1:一个关于 SPARQL 推理理由的示例,包括生成的查询、执行结果以及格式化后的知识。
Knowl. 表示知识(knowledge)
-
推理准备阶段:
-
推理生成:使用少样本链式思考(CoT)提示生成推理步骤(rationales),即推理链中的中间推理单元/句子。
-
知识领域选择:通过上下文学习识别与问题相关的知识领域,如事实、医学、物理和生物学等。
-
-
动态知识适应阶段:
-
知识检索:根据识别的知识领域,从相应的知识源中检索知识。这包括查询生成和执行。
-
查询生成:根据知识源的类型,生成相应的查询语言,如SPARQL、SQL或自然语言句子。为此,提出了一个自适应查询生成器(AQG),它可以是微调模型(如LLaMA-2)或现成的LLM(如ChatGPT)。
-
查询执行:执行生成的查询,获取并格式化知识,以便后续使用。
-
-
推理纠正:基于检索到的知识,逐步纠正推理步骤,防止错误传播。
-
-
答案整合阶段:
-
使用问题和纠正后的推理步骤生成最终答案,以提高回答的准确性。
-
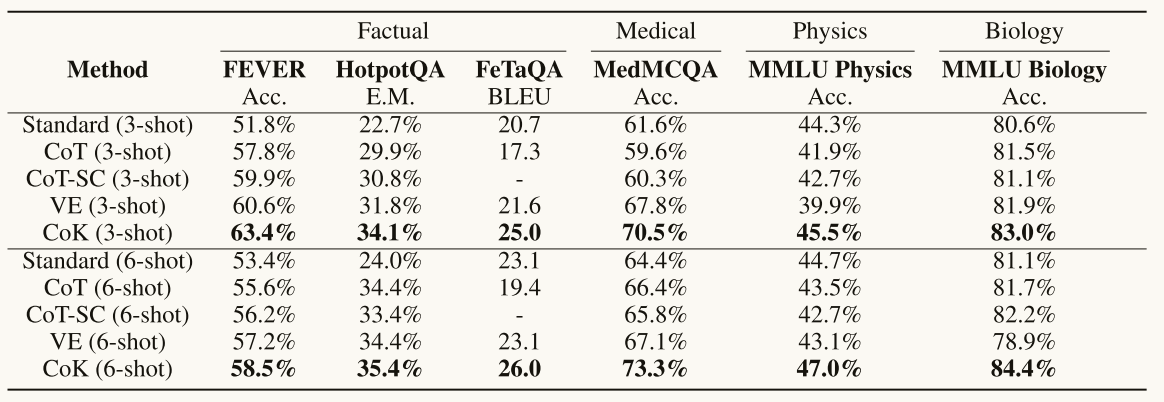
表2:在不同领域中的主要实验结果。Acc.:准确率(accuracy);E.M.:完全匹配率(exact match)
实验
实验部分评估了CoK框架在不同知识密集型任务上的性能,包括事实、医学、物理和生物学领域的任务。实验使用了多种数据集,如FEVER、HotpotQA、MedMCQA和MMLU等。
-
与基线方法的比较:CoK在所有数据集上均优于或显著优于基线方法,包括标准提示(Standard)、链式思考(CoT)、链式思考自一致性(CoT-SC)和验证编辑(Verify-and-Edit,VE)。
-
多领域知识源的必要性:实验表明,使用多个知识领域和源可以进一步提高性能。例如,在MedMCQA数据集上,仅使用医学领域知识时准确率为67.1%,而加入生物学领域知识后,准确率提升至70.5%。
-
动态知识适应与并行编辑的对比:动态知识适应可以有效防止错误传播,从而提高性能。例如,在HotpotQA数据集上,动态知识适应的CoK准确率为34.1%,而并行编辑的准确率为31.2%。
-
推理步骤的事实性改进:CoK显著提高了推理步骤的事实性。例如,在HotpotQA数据集上,CoK的第一步和第二步推理的事实性分别为66.3%和69.5%,而CoT-SC分别为54.3%和52.1%。
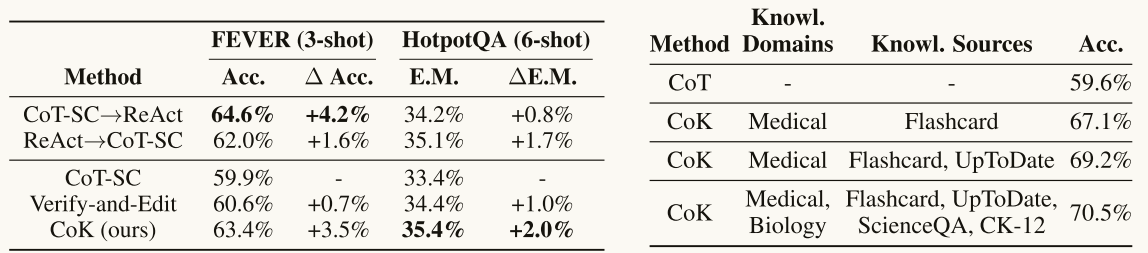
表3:基于检索的方法在 FEVER 和 HotpotQA 数据集上的结果
表4:在 MedMCQA 数据集上(3-shot 设置)使用单一或多种知识领域与来源的结果
关键结论
-
CoK框架通过动态整合异构知识源,有效减少了LLMs的幻觉现象,提高了回答的准确性。
-
AQG能够生成适用于不同类型知识源的查询,提高了知识检索的效率和准确性。
-
动态知识适应方法可以有效防止错误传播,进一步提升了模型的性能。
-
CoK在多个领域的知识密集型任务上均取得了显著的性能提升,证明了其在减少LLMs幻觉方面的有效性。
讨论与局限性
尽管CoK取得了显著的性能提升,但论文也讨论了其局限性:
-
知识源的可靠性:CoK依赖于外部知识源,如果知识源包含不可靠信息,可能会导致模型生成不准确的内容。
-
知识检索的局限性:如果知识检索步骤无法检索到与问题相关的事实,CoK可能无法产生有用的输出。
-
LLMs的推理能力:CoK依赖于LLMs的推理能力,因此推理错误可能导致最终答案错误。
总体而言,CoK框架为减少LLMs的幻觉现象提供了一种有效的解决方案,并在多个领域的知识密集型任务上验证了其有效性。