第2讲、LangChain应用架构与核心组件:构建LLM应用的基石
引言
随着大型语言模型(LLM)技术的飞速发展,如何高效、灵活地构建基于LLM的应用程序成为了开发者面临的重要课题。LangChain作为一个开源框架,应运而生,旨在简化LLM应用的开发流程,将LLM的强大能力与外部数据源和计算资源无缝结合。本文将深入探讨LangChain的应用架构和核心组件,并通过代码案例展示其在实际开发中的应用,帮助读者更好地理解和利用LangChain构建强大的LLM应用。
1. LangChain 应用架构
LangChain 作为一个专业的大语言模型开发框架,在 LLM 应用架构中占据重要地位。它为基于语言模型的应用程序提供了完整的设计和开发架构,如同大厦的蓝图,决定了整个应用的结构和功能。
1.1 架构特点
LangChain 的核心优势在于其强大的集成能力,能够将 LLM 模型、向量数据库、提示词管理、外部知识源和工具等组件有机整合。通过这种统一的架构设计,开发者可以灵活构建各种 LLM 应用。LangChain 使得应用程序具备两大核心能力:
- 上下文感知能力:将语言模型连接到各种上下文来源,包括提示指令、示例数据和待处理内容
- 环境交互能力:允许语言模型与外部环境进行自主交互,扩展其功能边界
1.2 分布式架构
LangChain 采用分布式架构设计,支持高效、可扩展的语言数据处理。其基于微服务的设计理念,将每个处理链作为独立服务运行,实现了:
- 灵活部署:组件可独立部署和管理
- 弹性扩展:支持根据负载动态扩缩容
- 服务解耦:降低组件间的耦合度
- 故障隔离:单个组件故障不影响整体系统
此架构天然支持与外部数据源和工具的集成,显著增强了 LLM 的实际应用能力。
1.3 典型应用架构模式
- RAG(检索增强生成)架构:结合向量数据库和文档检索,为LLM提供外部知识
- Agent架构:通过智能代理实现自主决策和工具调用
- Pipeline架构:通过链式组合实现复杂的处理流程
- 多模态架构:支持文本、图像、音频等多种数据类型的处理
1.4 核心优势
- 模块化设计:各组件可独立开发、测试和部署
- 可扩展性:支持水平扩展和垂直扩展
- 互操作性:与多种LLM提供商和第三方工具集成
- 开发效率:预构建组件减少开发时间
- 灵活性:支持多种应用场景和部署模式
总之,LangChain 可以将 LLM 模型、向量数据库、交互层 Prompt、外部知识、外部工具整合到一起,进而可以自由构建 LLM 应用。
2. LangChain 的核心组件
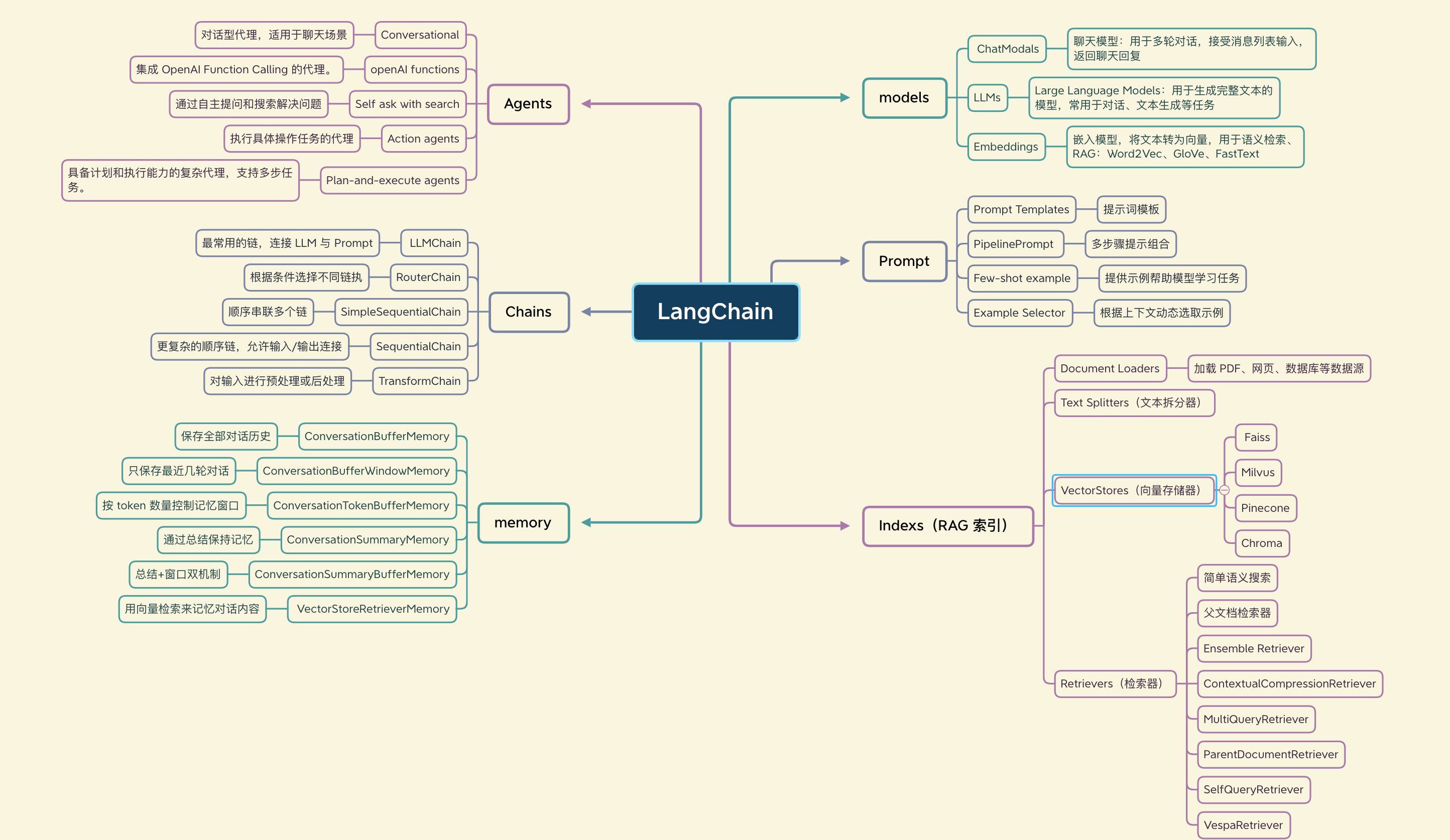
LangChain 框架的核心在于其模块化的设计,它将构建 LLM 应用所需的各种功能分解为独立的组件,这些组件可以灵活组合,以满足不同的应用需求。LangChain 包含六个主要组成部分:Models、Prompts、Indexes、Memory、Chains 和 Agents [1]。
2.1. Models(模型)
Models 是 LangChain 与各种语言模型交互的接口,是整个框架的基础。它抽象了不同类型模型的调用方式,使得开发者可以使用统一的接口来操作不同的 LLM。在 LangChain 中,Models 主要包括 ChatModels、Embeddings 和 LLMs。
2.1.1、Chat Models 聊天模型
聊天模型是 LangChain 中专门用于处理对话式交互的语言模型接口。与传统的文本输入/文本输出模型不同,聊天模型以"聊天消息"作为输入和输出,这使得它们更适合构建多轮对话系统。LangChain 定义了以下几种核心消息类型:
- HumanMessage:代表由用户或人类生成的消息。这是用户输入到对话系统中的内容。
- AIMessage:代表由人工智能或聊天机器人生成的消息。它通常是对用户输入的响应或系统触发的自动回复。
- SystemMessage:代表由系统生成的消息,通常用于传递系统状态、指令或元信息。这类消息不直接参与对话,但对控制对话流程和环境设置有重要作用。
- ChatMessage:一个通用类型,可以包含任何类型的消息内容,并接受一个任意的角色参数。它适用于需要处理多种消息类型的复杂对话场景。
这些消息类型有助于开发者更好地组织和管理对话内容,特别是在使用大型语言模型(如 GPT-3)时,能够区分用户输入、AI 响应和系统信息,从而更有效地处理用户请求、生成适当的响应,并维护对话的上下文和状态。
聊天模型使用场景:
- AIMessage 和 HumanMessage:在对话中区分用户输入和 AI 响应,帮助追踪对话的来回交流,便于分析和改进对话系统的性能。
- SystemMessage:用于管理对话的状态和控制信息流,可以包含会话开始、结束、重置等系统事件的信息。
- ChatMessage:提供一种统一的方式来存储和传输各种类型的消息,适用于需要处理多种消息类型的复杂对话场景。
2.1.2、聊天模型的高级特性
上下文缓存:为了优化成本和提高响应速度,LangChain 提供了缓存功能。当用户问同一个问题时,如果结果已被缓存,就可以直接返回,减少对 LLM API 的调用。LangChain 支持内存缓存和多种数据库缓存方案。
流式响应:流式响应允许模型逐步生成响应内容并实时返回给用户,而不是等待整个响应生成完毕。这显著提升了用户体验,尤其是在处理长文本生成任务时,用户可以即时看到部分结果,减少等待焦虑。LangChain 提供了多种工具和组件,可以轻松集成和实现流式响应这一功能。
2.1.3、模型提供商集成
LangChain 支持与多种模型提供商的集成,包括但不限于:
- OpenAI:GPT-3.5、GPT-4、GPT-4 Turbo等
- Anthropic:Claude系列模型
- Google:PaLM、Bard、Gemini等
- Hugging Face:开源模型生态系统
- Cohere:商业API服务
- 本地模型:通过Ollama、LLaMA.cpp等运行本地模型
2.1.4、模型参数配置
在使用聊天模型时,可以配置多种参数来控制模型行为:
- temperature:控制输出的随机性,范围0-1
- max_tokens:限制生成的最大token数量
- top_p:核采样参数,控制生成的多样性
- frequency_penalty:频率惩罚,避免重复内容
- presence_penalty:存在惩罚,鼓励生成新主题
2.1.5、异步和批处理
LangChain 支持异步调用和批处理操作,提高处理效率:
- 异步调用:使用
ainvoke()方法进行非阻塞调用 - 批处理:使用
batch()方法同时处理多个请求 - 流式处理:使用
stream()方法获取流式响应
2.1.6. 嵌入模型(Embeddings Model)
嵌入模型是一种将离散的高维数据(如单词、句子、图片等)映射到连续的低维向量空间的技术。这个低维向量空间中的点称为"嵌入"(embedding)。嵌入模型的主要目的是捕捉输入数据中的语义或特征信息,使得相似的输入在嵌入空间中距离更近。它在文档、文本或大量数据的总结、问答场景中尤为重要,通常与向量数据库结合使用,实现高效的向量匹配和信息检索。
特点:
- 低维表示:嵌入模型将高维、稀疏的离散数据转换为低维、密集的向量表示。
- 语义信息:嵌入向量捕捉了输入数据的语义或特征信息,向量之间的距离反映了输入数据之间的相似性。
- 效率高:嵌入模型通常计算高效,适合用于大规模数据的相似性搜索和分类任务。
应用场景:文本相似度计算、信息检索、分类和聚类。
2.1.7、嵌入模型的类型
文本嵌入模型:
- OpenAI Embeddings:text-embedding-ada-002、text-embedding-3-small等
- Sentence Transformers:多语言支持的句子嵌入模型
- Cohere Embeddings:专注于语义搜索的嵌入模型
多模态嵌入模型:
- CLIP:图像-文本联合嵌入
- ImageBind:多模态(图像、音频、文本)联合嵌入
2.1.8、LLMs 大语言模型
大型语言模型(Large Language Models, LLMs)是一种深度学习模型,通常基于 Transformer 架构,具有数以亿计甚至数以百亿计的参数。LLM 通过在大规模文本语料库上进行训练,能够生成、理解和处理自然语言文本。
特点:
- 大规模:大语言模型拥有大量参数和复杂的网络结构,能够捕捉丰富的语言信息。
- 生成能力:能够生成高质量的自然语言文本,进行对话、写作等任务。
- 多任务处理:能够处理多种 NLP 任务,如翻译、总结、问答等。
应用场景:对话系统、文本生成、问答系统。
LangChain 和 LLMs 的关系:LangChain 是一个开源框架,旨在将大型语言模型(如 GPT-4)与外部数据源和计算资源结合起来,以实现复杂的 NLP 应用。LangChain 提供了一个框架,使开发者可以轻松地集成和扩展大型语言模型,通过组件化设计增强交互性,并提升性能和效率。可以说,LLMs 是 LangChain 的核心,LangChain 继承并支持了众多大语言模型。
2.1.9、嵌入模型 和 大模型的区别
嵌入模型(Embedding Model)和大语言模型(Large Language Model, LLM)是自然语言处理(NLP)领域中的两类重要模型,它们在设计目的、功能和应用场景上有明显的区别。
| 特性 | 嵌入模型(Embedding Model) | 大语言模型(Large Language Model, LLM) |
|---|---|---|
| 目的 | 将离散数据映射到低维向量空间,捕捉语义或特征信息 | 生成、理解和处理自然语言文本 |
| 功能 | 向量化、相似度计算、信息检索、分类、聚类 | 文本生成、对话、翻译、摘要、问答等 |
| 核心优势 | 无需训练即可实时添加新内容,成本较低,适用于相似性搜索 | 强大的自然语言生成和理解能力,适用于复杂 NLP 任务 |
| 应用场景 | 文本相似度计算、信息检索、分类和聚类 | 对话系统、文本生成、问答系统 |
嵌入模型相比大语言模型的 fine-tuning 最大的优势就是,不用进行训练,并且可以实时添加新的内容,而不用加一次新的内容就训练一次,并且各方面成本要比 fine-tuning 低很多。
2.1.10、Basic Language Model 基础语言模型
基础语言模型是指只在大规模文本语料中进行了预训练的模型,未经过指令和下游任务微调、以及人类反馈等任何对齐优化。当前绝大部分的大语言模型都是 Decoder-only 的模型结构。
基础语言模型的特点:
- 预训练:在大规模文本数据上进行无监督学习
- 通用性:具备广泛的语言理解和生成能力
- 未对齐:可能产生不安全或不准确的输出
- 需要提示工程:需要精心设计的提示来获得期望的输出
2.2. Prompts(提示词)
一个提示词(Prompt)指的是输入模型的内容,通常由多个组件构成。LangChain 提供了多个类和函数,使构建和处理提示变得简单。提示词是引导语言模型生成特定类型输出的关键。除了直接编写聊天模型的消息类型外,LangChain 还提供了通过提示词间接实现聊天模型的新方式。
2.2.1. Prompt Templates 提示词模板
提示词模板是一种预定义的文本结构,其中包含变量和固定文本部分,用于引导语言模型生成特定类型的输出。这些模板可以帮助模型更准确地理解上下文,并生成符合预期的响应。当用户需要输入多个类似的 prompt 时,生成一个 prompt 模板是一个很好的解决方案,可以节省用户的时间和精力。提示模板可以接受任意数量的输入变量,并可以格式化生成提示。
提示词模板的类型:
- PromptTemplate:最基础的提示词模板,用于格式化单个字符串
- ChatPromptTemplate:专门用于聊天模型的提示词模板
- FewShotPromptTemplate:支持少量样本学习的提示词模板
- ConditionalPromptTemplate:基于条件逻辑的动态提示词模板
2.2.2. PipelinePrompt 提示词模板组合
通过 PipelinePrompt 可以将多个 PromptTemplate 提示模板进行组合,组合的优点是可以很方便地进行复用。例如,常见的系统角色提示词通常遵循 {introduction} {example} {start} 这样的结构。
2.2.3. 提示词工程最佳实践
清晰性和具体性:
- 使用明确、具体的指令
- 避免歧义和模糊的表达
- 提供具体的输出格式要求
上下文设置:
- 为模型提供充分的背景信息
- 使用SystemMessage设置角色和行为规范
- 明确任务的目标和约束条件
示例驱动:
- 使用少量示例展示期望的输出格式
- 采用思维链(Chain of Thought)提示
- 提供正面和负面的示例对比
2.2.4. 动态提示词生成
基于用户输入的动态提示:
- 根据用户的不同需求调整提示词内容
- 使用条件逻辑构建自适应提示
- 结合用户历史记录个性化提示
多语言提示词支持:
- 自动检测用户语言并调整提示
- 维护多语言版本的提示词模板
- 考虑文化差异对提示效果的影响
2.2.5. 提示词优化技巧
迭代优化:
- 通过A/B测试比较不同提示词的效果
- 收集用户反馈持续改进提示词
- 使用量化指标评估提示词性能
安全考虑:
- 防止提示词注入攻击
- 过滤敏感信息和有害内容
- 设置适当的内容审核机制
2.3. Indexes(索引)
Indexes 在 LangChain 中扮演着连接语言模型与外部数据的关键角色,尤其是在处理大量非结构化数据时。它允许 LLM 访问和理解其训练数据之外的信息,从而增强其回答特定问题或执行特定任务的能力。Indexes 通常与向量数据库结合使用,以实现高效的数据检索和管理。
核心功能:
- 文档加载器 (Document Loaders):用于从各种来源加载文档,例如 PDF、文本文件、网页、数据库等。LangChain 提供了多种文档加载器,可以轻松地将不同格式的数据导入到系统中。
- 文本分割器 (Text Splitters):将加载的文档分割成更小、更易于处理的块(chunks)。这是因为大型文档通常无法一次性输入到 LLM 中,而且较小的块有助于提高检索的准确性。文本分割器会尽量保持文本的语义完整性,例如避免在句子中间进行分割。
- 向量存储 (Vector Stores):用于存储文档块的嵌入向量。当用户提出查询时,查询文本也会被转换为嵌入向量,然后在向量存储中进行相似性搜索,以找到最相关的文档块。常见的向量存储包括 Chroma、FAISS、Pinecone 等。
- 检索器 (Retrievers):负责从向量存储中检索相关文档块。检索器可以根据不同的策略进行配置,例如相似度搜索、最大边际相关性(MMR)等,以确保检索到的信息既相关又多样。
2.3.1. 文档加载器详解
支持的文档格式:
- PDF文档:使用PyPDFLoader、PDFPlumberLoader等
- Word文档:支持.docx格式的文档加载
- 网页内容:WebBaseLoader用于抓取网页内容
- 数据库:支持SQL数据库、NoSQL数据库的数据加载
- CSV/Excel:结构化数据的加载处理
- Markdown文件:技术文档和说明文件的加载
高级加载功能:
- 批量加载:同时处理多个文档文件
- 增量加载:只加载新增或修改的内容
- 自定义解析:根据文档特点自定义解析逻辑
- 元数据提取:自动提取文档的元信息
2.3.2. 文本分割策略
分割方法:
- 字符分割:基于字符数量进行分割
- 递归字符分割:智能保持文本结构的分割方式
- Token分割:基于Token数量进行精确分割
- 语义分割:保持语义完整性的智能分割
分割参数优化:
- chunk_size:块大小的选择策略
- chunk_overlap:重叠区域的设置原则
- 分割边界:句子、段落、章节边界的处理
- 上下文保持:确保重要上下文信息不丢失
2.3.3. 向量存储选择
本地向量存储:
- Chroma:轻量级、易于部署的向量数据库
- FAISS:Facebook开源的高性能相似性搜索库
- Qdrant:企业级向量数据库解决方案
云端向量存储:
- Pinecone:托管的向量数据库服务
- Weaviate:开源的向量搜索引擎
- Milvus:大规模向量数据库系统
性能考虑:
- 查询速度:不同存储方案的性能对比
- 存储成本:向量存储的成本分析
- 扩展性:随数据量增长的扩展能力
- 一致性:分布式环境下的数据一致性
2.3.4. 检索策略优化
相似性搜索:
- 余弦相似度:最常用的向量相似性度量
- 欧氏距离:适用于特定场景的距离计算
- 点积:简单高效的相似性计算方法
高级检索技术:
- MMR(最大边际相关性):平衡相关性和多样性
- 自相似性搜索:避免返回重复内容
- 时间衰减:考虑信息的时效性
- 混合检索:结合多种检索策略
应用场景:
- 问答系统 (Question Answering):通过索引外部知识库,LLM 可以回答关于特定领域的问题,而不仅仅是依赖其预训练知识。
- RAG (Retrieval Augmented Generation):结合检索和生成,LLM 可以从外部数据源检索相关信息,然后利用这些信息生成更准确、更全面的回答。这对于减少 LLM 的"幻觉"问题至关重要。
- 文档摘要 (Document Summarization):通过索引和检索文档中的关键信息,LLM 可以生成高质量的文档摘要。
- 知识发现:从大量文档中发现隐含的知识和关联
- 内容推荐:基于用户兴趣和行为推荐相关内容
2.4. Memory(记忆)
Memory 是 LangChain 中用于管理和维护对话历史的关键组件。在 LLM 应用中,尤其是对话式应用,模型需要记住之前的对话内容才能进行连贯的交流。Memory 模块提供了多种机制来存储和检索对话的上下文信息。
核心功能:
- 存储对话历史:Memory 模块可以存储用户和 AI 之间的消息,形成完整的对话历史。
- 管理上下文:由于 LLM 的输入长度限制,Memory 模块通常需要对对话历史进行管理,例如截断旧消息、总结历史信息等,以确保最新的、最重要的上下文能够被模型处理。
- 多种记忆类型:LangChain 提供了多种记忆类型,以适应不同的应用场景:
- ConversationBufferMemory:简单地存储所有对话消息。
- ConversationBufferWindowMemory:只存储最近 N 条消息,以控制上下文长度。
- ConversationSummaryMemory:定期总结对话历史,将冗长的对话历史压缩成简洁的摘要,从而节省 token 消耗。
- ConversationSummaryBufferMemory:结合了窗口记忆和总结记忆的特点,既保留了最近的详细对话,又对更早的对话进行总结。
- ConversationKGMemory:将对话历史转换为知识图谱,以便更结构化地存储和检索信息。
2.4.1. 记忆类型详解
ConversationBufferMemory:
- 优点:保留完整的对话历史,不丢失任何信息
- 缺点:随着对话增长,token消耗快速增加
- 适用场景:短期对话、需要完整上下文的任务
ConversationBufferWindowMemory:
- 工作原理:维护固定数量的最近消息
- 参数配置:k值决定保留的消息数量
- 优化策略:根据应用需求调整窗口大小
ConversationSummaryMemory:
- 总结策略:定期将历史对话压缩为摘要
- 触发条件:基于消息数量或token数量
- 质量控制:使用专门的总结提示词模板
ConversationKGMemory:
- 知识提取:从对话中提取实体和关系
- 图谱构建:构建动态的知识图谱
- 查询优化:基于图谱结构进行智能检索
2.4.2. 内存优化策略
Token管理:
- 计算token消耗:精确计算内存的token使用量
- 动态调整:根据模型限制自动调整内存策略
- 成本优化:在保持性能的同时减少API调用成本
性能优化:
- 异步操作:使用异步方式更新内存状态
- 缓存机制:缓存频繁访问的内存内容
- 批量处理:批量更新内存以提高效率
应用场景:
- 聊天机器人:使聊天机器人能够记住之前的对话内容,进行多轮、连贯的交流。
- 个性化推荐:根据用户的历史对话和偏好,提供个性化的推荐。
- 任务型对话:在复杂任务中,记忆可以帮助模型跟踪任务进度和用户意图。
- 客户服务:维护客户的历史咨询记录,提供一致的服务体验
- 教育应用:跟踪学习者的进度和理解程度
2.5. Chains(链)
Chains 是 LangChain 中用于将多个组件(如 LLM、Prompts、Parsers 等)组合在一起,以实现特定任务的强大工具。它们允许开发者定义一系列操作步骤,将一个组件的输出作为另一个组件的输入,从而构建复杂的工作流。Chains 是 LangChain 灵活性的核心体现,它使得开发者能够以模块化的方式构建复杂的 LLM 应用。
核心功能:
- 顺序执行:Chains 允许按照预定义的顺序执行一系列操作。例如,一个 Chain 可以先使用一个 Prompt Template 来格式化输入,然后将格式化后的输入传递给 LLM,最后使用一个 Output Parser 来处理 LLM 的输出。
- 组合性:Chains 可以相互嵌套,形成更复杂的逻辑。一个 Chain 的输出可以作为另一个 Chain 的输入,从而构建出高度定制化的工作流。
- 预定义链:LangChain 提供了许多预定义的链,用于常见的 LLM 应用场景,例如:
- LLMChain:最基本的链,用于将 Prompt Template 和 LLM 组合在一起。
- SimpleSequentialChain:按顺序执行多个链,将前一个链的输出作为后一个链的输入。
- ConversationalRetrievalChain:结合了对话记忆和检索功能,用于构建基于知识库的问答系统。
- StuffDocumentsChain:将所有文档内容填充到 LLM 的上下文中。
- MapReduceDocumentsChain:将文档分割成小块,分别处理,然后将结果合并。
2.5.1. 链的类型和特点
基础链:
- LLMChain:最简单的链,连接提示词模板和LLM
- RouterChain:根据输入内容路由到不同的处理链
- SequentialChain:按序执行多个链的组合
文档处理链:
- StuffDocumentsChain:将所有文档内容塞入上下文
- MapReduceDocumentsChain:分而治之的文档处理方式
- RefineDocumentsChain:迭代改进的文档处理方法
高级链:
- ConversationalRetrievalChain:对话式检索问答链
- RetrievalQA:基于检索的问答链
- ConstitutionalChain:基于宪法原则的内容审核链
2.5.2. 链的设计模式
管道模式:
- 数据流:定义清晰的数据流向
- 转换器:每个环节的数据转换逻辑
- 错误处理:链中错误的传播和处理机制
条件执行:
- 分支逻辑:根据条件选择不同的执行路径
- 动态路由:基于内容动态选择处理链
- 回退机制:主链失败时的备用处理方案
2.5.3. 自定义链开发
继承基类:
- Chain基类:实现基本的链接口
- 输入输出定义:明确链的输入输出格式
- 执行逻辑:实现核心的处理逻辑
组合现有链:
- 链的嵌套:将简单链组合成复杂链
- 参数传递:链之间的参数传递机制
- 状态管理:维护链执行过程中的状态
应用场景:
- 复杂问答系统:结合检索、总结和生成,回答复杂问题。
- 内容生成:根据特定主题和风格生成文章、报告等。
- 数据提取:从非结构化文本中提取结构化信息。
- 自动化工作流:将 LLM 的能力集成到现有的业务流程中,实现自动化。
- 多步骤推理:解决需要多个推理步骤的复杂问题
- 内容审核:多层次的内容安全审核流程
2.6. Agents(代理)
Agents 是 LangChain 中最强大的组件之一,它赋予了语言模型"决策"和"行动"的能力。Agent 不仅仅是简单地执行预定义的 Chain,而是能够根据用户的输入和当前环境,自主地选择并执行一系列工具(Tools)来完成任务。这使得 LLM 应用能够与外部世界进行更复杂的交互,解决更开放式的问题。
核心功能:
- 决策能力:Agent 内部包含一个 LLM,该 LLM 负责根据输入和可用工具来决定下一步要采取的行动。
- 工具使用:Agent 可以访问各种工具(Tools),这些工具可以是预定义的函数(如搜索工具、计算器、API 调用等),也可以是自定义的工具。Agent 会根据需要选择合适的工具来完成任务。
- 迭代执行:Agent 通常会以迭代的方式运行,即执行一个行动,观察结果,然后根据结果决定下一步的行动,直到任务完成或达到某个停止条件。
- 规划和推理:Agent 能够进行一定程度的规划和推理,以确定完成任务的最佳路径。
2.6.1. Agent的工作原理
决策循环:
- 观察:接收当前状态和任务描述
- 思考:分析情况并决定下一步行动
- 行动:执行选定的工具或操作
- 评估:分析行动结果,决定是否继续
推理模式:
- ReAct模式:推理(Reasoning)+ 行动(Acting)的结合
- Plan-and-Execute:先制定计划,再逐步执行
- Self-Ask:通过自问自答的方式分解复杂问题
2.6.2. Agent的类型
零样本Agent:
- Zero-shot ReAct:无需示例即可工作的通用Agent
- Structured Chat:专门处理结构化对话的Agent
- Conversational ReAct:具备对话记忆的Agent
专用Agent:
- SQL Agent:专门处理数据库查询的Agent
- Math Agent:解决数学问题的专用Agent
- Research Agent:进行深度研究和信息收集的Agent
多模态Agent:
- Vision Agent:处理图像和视觉任务的Agent
- Audio Agent:处理音频相关任务的Agent
- Multimodal Agent:综合处理多种模态的Agent
2.6.3. 工具开发和集成
预置工具:
- 搜索工具:DuckDuckGo、Google搜索、Wikipedia
- 计算工具:数学计算器、单位转换器
- API工具:天气查询、股票信息、翻译服务
- 文件工具:文件读写、格式转换
自定义工具开发:
from langchain.tools import Tooldef custom_calculator(expression: str) -> str:"""安全的数学表达式计算器"""try:result = eval(expression)return f"计算结果: {result}"except:return "无效的数学表达式"calculator_tool = Tool(name="Calculator",func=custom_calculator,description="用于计算数学表达式"
)
工具安全考虑:
- 输入验证:严格验证工具输入参数
- 权限控制:限制工具的访问权限
- 输出过滤:过滤敏感信息的输出
- 错误处理:优雅处理工具执行错误
2.6.4. Agent的优化策略
性能优化:
- 工具选择:优化工具选择算法
- 缓存机制:缓存常用工具的结果
- 并行执行:支持并行调用多个工具
- 超时控制:设置合理的执行超时时间
可靠性提升:
- 重试机制:失败时自动重试
- 回退策略:工具失败的备选方案
- 状态检查:监控Agent的执行状态
- 日志记录:详细记录执行过程
核心概念:
- Agent:驱动决策的 LLM。它接收输入,并决定下一步要采取的行动。
- Tools:Agent 可以调用的函数。这些工具可以是任何能够帮助 Agent 完成任务的功能,例如:
- Search Tool:用于在互联网上搜索信息。
- Calculator Tool:用于执行数学计算。
- API Tool:用于调用外部 API。
- Custom Tools:开发者可以根据需要创建自定义工具。
- AgentExecutor:Agent 的运行时,负责执行 Agent 决定的行动,并观察结果。
2.6.5. 高级Agent模式
多Agent协作:
- 层级结构:主Agent管理多个子Agent
- 专业分工:不同Agent负责不同专业领域
- 协调机制:Agent之间的通信和协调
- 冲突解决:处理Agent之间的决策冲突
学习型Agent:
- 经验积累:从历史执行中学习
- 策略优化:改进决策和工具选择
- 适应性:根据环境变化调整行为
- 反馈机制:整合用户反馈改进性能
应用场景:
- 复杂问题解决:Agent 可以通过组合使用多种工具来解决需要多步骤推理和外部信息的问题。
- 自动化任务:Agent 可以自动化执行一系列任务,例如数据收集、报告生成等。
- 智能助手:构建能够理解用户意图并自主执行任务的智能助手。
- 研究助手:进行文献调研、数据分析、实验设计
- 客户服务:自动处理客户咨询和问题解决
- 内容创作:辅助写作、编辑和内容优化
- 代码开发:协助编程、调试和代码优化
代码案例
2.1. Models(模型)代码案例
2.1.1、Chat Models 聊天模型代码案例
以下是使用 LangChain 聊天模型的示例,展示了如何发送单条消息、多条消息以及批量处理消息。
import os
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage, SystemMessage# 设置您的OpenAI API Key
# os.environ["OPENAI_API_KEY"] = "YOUR_API_KEY"# 初始化聊天对象
chat = ChatOpenAI(openai_api_key="YOUR_API_KEY")# 1. 发送单条HumanMessage
print("\n--- 单条HumanMessage示例 ---")
response_single = chat.invoke([HumanMessage(content="Translate this sentence from English to French: I love programming.")])
print(response_single.content)# 2. 发送多条消息(SystemMessage 和 HumanMessage)
print("\n--- 多条消息示例 ---")
messages_multi = [SystemMessage(content="You are a helpful assistant that translates English to French."),HumanMessage(content="I love programming.")
]
response_multi = chat.invoke(messages_multi)
print(response_multi.content)# 3. 批量处理消息
print("\n--- 批量处理消息示例 ---")
batch_messages = [[SystemMessage(content="You are a helpful assistant that translates English to French."),HumanMessage(content="I love programming.")],[SystemMessage(content="You are a helpful assistant that translates English to French."),HumanMessage(content="I love artificial intelligence.")],
]# 使用generate方法进行批量处理
# 注意:LangChain 0.2.x 版本中,ChatOpenAI 的 generate 方法可能已被 invoke 或 batch 替代,
# 或者需要更复杂的处理方式。这里为了与PDF文档保持一致,保留generate的描述,
# 但实际代码可能需要调整为循环调用invoke或使用RunnableParallel等。
# 鉴于实际环境和API版本差异,此处仅为概念性示例,实际运行可能需要根据LangChain版本调整。# 假设的批量处理逻辑 (实际可能需要循环调用 invoke 或使用更高级的并行处理)
results_batch = []
for msg_list in batch_messages:results_batch.append(chat.invoke(msg_list))for i, res in enumerate(results_batch):print(f"Batch {i+1} Result: {res.content}")2.1.4、Chat Models 聊天模型的上下文缓存代码案例
LangChain 提供了缓存功能,可以减少对 LLM API 的调用,从而节省成本并加快响应速度。以下是使用 SQLiteCache 进行缓存的示例:
import langchain
from langchain_openai import ChatOpenAI
from langchain_community.cache import SQLiteCache# 设置语言模型的缓存数据存储的地址
langchain.llm_cache = SQLiteCache(database_path=".langchain.db")# 加载 llm 模型
# 请替换为您的实际API Key和base_url
llm = ChatOpenAI(model="gpt-4",openai_api_key="YOUR_API_KEY",base_url="https://api.openai.com/v1/" # 替换为您的实际API Base URL
)# 第一次向模型提问
print("\n--- 第一次提问 (会进行API调用并缓存) ---")
result1 = llm.invoke('tell me a joke')
print(result1.content)print ('\n******************* 缓存验证 *************************\n')# 第二次向模型提问同样的问题 (会从缓存中获取,不会进行API调用)
print("\n--- 第二次提问 (会从缓存中获取) ---")
result2 = llm.invoke('tell me a joke')
print(result2.content)# 清理缓存(可选)
# import os
# if os.path.exists(".langchain.db"):
# os.remove(".langchain.db")
# print("\n缓存文件 .langchain.db 已删除。")
2.1.5、流式响应在 Langchain 中的应用代码案例
流式响应可以提供即时反馈,提升用户体验。以下是一个概念性的示例,展示了 LangChain 如何与 FastAPI 结合实现流式响应。请注意,此示例需要安装 fastapi 和 uvicorn,并且 ConversationalRetrievalChain 的 generate_responses 方法在最新版本中可能有所不同,这里仅为演示概念。
# 由于此代码涉及 FastAPI 和复杂的链调用,且PDF中提供的代码片段可能与最新LangChain版本不完全兼容,
# 故此处提供一个简化版的流式输出概念示例,不依赖FastAPI,仅展示LLM的stream方法。
# 实际生产环境请参考LangChain官方文档中关于Streaming和FastAPI的最新集成方式。import os
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage# 设置您的OpenAI API Key
# os.environ["OPENAI_API_KEY"] = "YOUR_API_KEY"llm = ChatOpenAI(model="gpt-4",openai_api_key="YOUR_API_KEY",base_url="https://api.openai.com/v1/", # 替换为您的实际API Base URLstreaming=True # 开启流式传输
)print("\n--- 流式响应示例 ---")
print("AI 回复 (流式输出): ")# 使用stream方法获取流式响应
for chunk in llm.stream([HumanMessage(content="Tell me a long story about a brave knight.")]):print(chunk.content, end="", flush=True)
print("\n")# 原始PDF中FastAPI示例的伪代码结构(仅供参考,不直接运行)
'''
from fastapi import FastAPI
from fastapi.responses import StreamingResponse
import time
from langchain.chains import ConversationalRetrievalChain
from langchain.llms import OpenAIapp = FastAPI()# 初始化 Langchain 模型 (此处为伪代码,实际需要更复杂的初始化)
# llm = OpenAI(api_key='your-api-key')
# chain = ConversationalRetrievalChain(llm)def generate_stream_response(prompt):# 使用 Langchain 生成响应 (伪代码,实际需要调用链或LLM的流式方法)# responses = chain.generate_responses(prompt)# for response in responses:# yield response# time.sleep(0.1) # 模拟生成过程中的延迟yield "This is a simulated stream response part 1. "time.sleep(0.5)yield "This is part 2. "time.sleep(0.5)yield "And this is the final part."@app.post("/chat")
async def chat(prompt: str):return StreamingResponse(generate_stream_response(prompt), media_type="text/plain")# 运行应用程序:uvicorn example:app --reload
'''
2.1.7、通过OpenAIEmbeddings 使用 嵌入模型(Embedding Model)代码案例
以下是使用 OpenAIEmbeddings 将文本转换为嵌入向量的示例:
import os
from langchain_openai import OpenAIEmbeddings# 设置您的OpenAI API Key
# os.environ["OPENAI_API_KEY"] = "YOUR_API_KEY"# 初始化嵌入模型
embeddings = OpenAIEmbeddings(openai_api_key="YOUR_API_KEY")# 把文本通过嵌入模型向量化
text_to_embed = 'hello world'
res = embeddings.embed_query(text_to_embed)print(f"\n--- 嵌入模型示例 ---")
print(f"文本: '{text_to_embed}'")
print(f"嵌入向量的前5个维度: {res[:5]}")
print(f"嵌入向量的长度: {len(res)}")
2.1.8、LLMs 大语言模型代码案例
以下是使用 LangChain 定义和调用 LLM 的示例,包括阻塞式获取结果和流式响应。
import os
from langchain_openai import OpenAI# 设置您的OpenAI API Key
# os.environ["OPENAI_API_KEY"] = "YOUR_API_KEY"# 实例化一个LLM模型
# 注意:text-davinci-002 等旧模型可能已被弃用,建议使用 gpt-3.5-turbo-instruct 或其他新模型
llm = OpenAI(openai_api_key="YOUR_API_KEY",model_name="gpt-3.5-turbo-instruct", # 建议使用此模型或更新的模型temperature=0.7, # 发散度,0-1之间,越高越随机max_tokens=50, # 最大生成token数# max_retries=10, # 发生错误后重试次数# max_concurrency=5, # 最大并发请求次数# cache=True # 开启缓存,需要配置llm_cache,如2.1.4节所示
)# 1. 使用 invoke 方法获取阻塞式结果
print("\n--- LLM invoke 示例 (阻塞式) ---")
response_invoke = llm.invoke("Tell me a short, funny joke.")
print(response_invoke)# 2. 使用 stream 方法获取流式响应
print("\n--- LLM stream 示例 (流式) ---")
print("AI 回复 (流式输出): ")
for chunk in llm.stream("Tell me a long story about a magical forest."):print(chunk, end="", flush=True)
print("\n")# 3. 使用 batch 方法进行批量处理 (LangChain 0.2.x 推荐使用 invoke 的列表输入)
print("\n--- LLM batch 示例 (批量处理) ---")
# 在LangChain 0.2.x中,通常直接将一个列表的输入传递给invoke方法即可实现批量处理
questions = ["What is the capital of France?","What is 2+2?"
]batch_responses = llm.batch(questions)for i, res in enumerate(batch_responses):print(f"Question {i+1}: {questions[i]}")print(f"Answer {i+1}: {res}")print("-" * 20)2.2. Prompts(提示词)代码案例
2.2.1. Prompt Templates 提示词模板代码案例
以下示例展示了如何使用 ChatPromptTemplate 和 PromptTemplate 创建和格式化提示词模板。
from langchain_core.prompts import ChatPromptTemplate, PromptTemplate
from langchain_core.messages import SystemMessage, HumanMessage# --- ChatPromptTemplate 示例 ---
print("\n--- ChatPromptTemplate 示例 ---")template = "You are a helpful assistant that translates {input_language} to {output_language}."
human_template = "{text}"chat_prompt = ChatPromptTemplate.from_messages([("system", template),("human", human_template),
])mes1 = chat_prompt.format_messages(input_language="English", output_language="French", text="I love programming.")for e in mes1:print(e)print("\n--- ChatPromptTemplate 多个变量示例 ---")
chat_template_multi_var = ChatPromptTemplate.from_messages([("system", "You are a helpful AI bot. Your name is {name}."),("human", "Hello, how are you doing? My name is {user_name}."),("ai", "I'm doing well, thanks! How can I help you today?"),("human", "{user_input}"),]
)messages_multi_var = chat_template_multi_var.format_messages(name="Bob", user_name="Alice", user_input="What is your name?")for msg in messages_multi_var:print(msg)# --- PromptTemplate 示例 ---
print("\n--- PromptTemplate 示例 ---")
prompt_template = PromptTemplate.from_template("Tell me a {adjective} joke about {content}."
)message_formatted = prompt_template.format(adjective="funny", content="chickens")
print(f"===message== {message_formatted}")print("\n--- PromptTemplate 自动推断 input_variables 示例 ---")
prompt_template_auto_infer = PromptTemplate.from_template("Tell me a {adjective} joke about {content}."
)
print(f"=====input_variables======= {prompt_template_auto_infer.input_variables}")
message_auto_infer = prompt_template_auto_infer.format(adjective="silly", content="ducks")
print(f"===message== {message_auto_infer}")
2.2.2 PipelinePrompt 提示词模板组合代码案例
PipelinePrompt 在 LangChain 0.2.x 版本中可能不再直接作为独立类存在,其功能通常通过 RunnableSequence 或自定义链来实现。这里提供一个概念性的示例,展示如何通过组合 PromptTemplate 来构建更复杂的提示逻辑。
from langchain_core.prompts import PromptTemplate# 定义第一个提示模板:介绍
introduction_template = PromptTemplate.from_template("You are an expert interviewer. Your task is to interview a famous person.\nIntroduction: {introduction_text}"
)# 定义第二个提示模板:示例
example_template = PromptTemplate.from_template("Example dialogue:\nInterviewer: {interviewer_example}\nFamous Person: {person_example}"
)# 定义第三个提示模板:开始对话
start_template = PromptTemplate.from_template("Start the interview now. Interviewer: {start_question}"
)# 组合这些模板 (概念性组合,实际可能通过RunnableSequence或自定义链实现)
# 假设我们有一个函数或链来按顺序组合这些部分
def combine_prompts(intro, example, start):return f"{intro}\n\n{example}\n\n{start}"# 格式化各个部分
intro_formatted = introduction_template.format(introduction_text="Today we have the honor of speaking with a renowned scientist.")
example_formatted = example_template.format(interviewer_example="Tell us about your latest discovery.", person_example="It was a breakthrough in quantum physics.")
start_formatted = start_template.format(start_question="Welcome! What inspired you to pursue science?")# 组合最终的提示
final_prompt = combine_prompts(intro_formatted, example_formatted, start_formatted)print("\n--- 组合提示词模板示例 ---")
print(final_prompt)# 实际在LangChain中,更推荐使用RunnableSequence来构建复杂的Prompt组合
# from langchain_core.runnables import RunnableSequence
# combined_prompt = RunnableSequence(introduction_template, example_template, start_template)
# 这种方式更符合LangChain 0.2.x 的设计理念
2.3. Indexes(索引)代码案例
Indexes 主要用于处理和检索外部数据,通常与向量数据库结合使用。以下是一个使用 LangChain 加载文档、分割文本并存储到向量数据库(这里使用内存中的 ChromaDB 作为示例)的简化流程。
import os
from langchain_community.document_loaders import TextLoader
from langchain_text_splitters import CharacterTextSplitter
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores import Chroma# 设置您的OpenAI API Key
# os.environ["OPENAI_API_KEY"] = "YOUR_API_KEY"# 1. 创建一个示例文档
example_document_path = "./example_document.txt"
with open(example_document_path, "w", encoding="utf-8") as f:f.write("LangChain 是一个用于开发由语言模型驱动的应用程序的框架。它使得应用程序能够:具有上下文感知能力:将语言模型连接到上下文来源(提示指令,少量的示例,需要回应的内容),并实现自主性:允许语言模型与其环境进行交互。LangChain 的核心组件包括 Models, Prompts, Indexes, Memory, Chains, Agents。")f.write("\n\nIndexes 在 LangChain 中扮演着连接语言模型与外部数据的关键角色。它允许 LLM 访问和理解其训练数据之外的信息,从而增强其回答特定问题或执行特定任务的能力。")# 2. 文档加载器 (Document Loaders)
print("\n--- Indexes 示例: 文档加载 ---")
loader = TextLoader(example_document_path)
documents = loader.load()
print(f"加载的文档数量: {len(documents)}")
print(f"第一个文档内容预览: {documents[0].page_content[:100]}...")# 3. 文本分割器 (Text Splitters)
print("\n--- Indexes 示例: 文本分割 ---")
text_splitter = CharacterTextSplitter(chunk_size=100, chunk_overlap=0)
splitted_docs = text_splitter.split_documents(documents)
print(f"分割后的文档块数量: {len(splitted_docs)}")
for i, doc in enumerate(splitted_docs):print(f"块 {i+1}: {doc.page_content}")# 4. 向量存储 (Vector Stores) 和 嵌入模型 (Embeddings)
print("\n--- Indexes 示例: 向量存储和嵌入 ---")
embeddings = OpenAIEmbeddings(openai_api_key="YOUR_API_KEY")# 使用 Chroma 作为内存中的向量存储
# 注意:实际应用中,您会使用持久化的向量数据库
vectorstore = Chroma.from_documents(documents=splitted_docs, embedding=embeddings)# 5. 检索器 (Retrievers)
print("\n--- Indexes 示例: 检索器 ---")
query = "LangChain 的核心组件有哪些?"
retriever = vectorstore.as_retriever()
retrieved_docs = retriever.invoke(query)print(f"查询: \"{query}\"")
print(f"检索到的相关文档块数量: {len(retrieved_docs)}")
for i, doc in enumerate(retrieved_docs):print(f"检索到的块 {i+1}: {doc.page_content}")# 清理示例文档
os.remove(example_document_path)
2.4. Memory(记忆)代码案例
Memory 用于在对话中维护上下文。以下是一个使用 ConversationBufferMemory 的简单示例。
from langchain_core.messages import HumanMessage, AIMessage
from langchain.memory import ConversationBufferMemoryprint("\n--- Memory 示例 ---")# 初始化记忆模块
memory = ConversationBufferMemory()# 添加对话消息
memory.chat_memory.add_user_message("你好,我是Alice。")
memory.chat_memory.add_ai_message("你好Alice,有什么可以帮助你的吗?")memory.chat_memory.add_user_message("我叫什么名字?")# 获取对话历史
conversation_history = memory.load_memory_variables({})
print("当前对话历史:")
for message in conversation_history["history"]:if isinstance(message, HumanMessage):print(f"Human: {message.content}")elif isinstance(message, AIMessage):print(f"AI: {message.content}")# 结合LLM使用记忆
from langchain_openai import ChatOpenAI
from langchain.chains import ConversationChain# 设置您的OpenAI API Key
# os.environ["OPENAI_API_KEY"] = "YOUR_API_KEY"llm = ChatOpenAI(openai_api_key="YOUR_API_KEY", temperature=0.7)# 创建一个对话链,并传入记忆模块
conversation = ConversationChain(llm=llm,memory=memory, # 使用上面定义的memoryverbose=True # 打印详细的执行过程
)# 进行对话
print("\n--- 结合LLM的Memory示例 ---")
response = conversation.invoke("我叫什么名字?")
print(f"LLM Response: {response['response']}")# 再次获取对话历史,可以看到新的消息已被添加
print("\n更新后的对话历史:")
updated_history = memory.load_memory_variables({})
for message in updated_history["history"]:if isinstance(message, HumanMessage):print(f"Human: {message.content}")elif isinstance(message, AIMessage):print(f"AI: {message.content}")
2.5. Chains(链)代码案例
Chains 用于将多个组件组合起来,以实现特定任务。以下是一个使用 LLMChain 和 SimpleSequentialChain 的示例。
from langchain_openai import ChatOpenAI
from langchain_core.prompts import PromptTemplate
from langchain.chains import LLMChain, SimpleSequentialChain# 设置您的OpenAI API Key
# os.environ["OPENAI_API_KEY"] = "YOUR_API_KEY"llm = ChatOpenAI(openai_api_key="YOUR_API_KEY", temperature=0.7)print("\n--- Chains 示例: LLMChain ---")
# 1. LLMChain 示例:翻译链# 定义提示模板
translation_prompt = PromptTemplate(input_variables=["text", "source_language", "target_language"],template="Translate the following text from {source_language} to {target_language}:\n\"{text}\"
")# 创建LLMChain
translation_chain = LLMChain(llm=llm, prompt=translation_prompt)# 调用链
text_to_translate = "Hello, how are you?"
source_lang = "English"
target_lang = "French"result_translation = translation_chain.invoke({"text": text_to_translate,"source_language": source_lang,"target_language": target_lang
})
print(f"原始文本: {text_to_translate}")
print(f"翻译结果: {result_translation['text']}")print("\n--- Chains 示例: SimpleSequentialChain ---")
# 2. SimpleSequentialChain 示例:创意写作链# 第一个链:生成一个主题
theme_prompt = PromptTemplate(input_variables=["topic"],template="Generate a creative and interesting theme for a short story about {topic}."
)
theme_chain = LLMChain(llm=llm, prompt=theme_prompt)# 第二个链:根据主题写一个故事开头
story_start_prompt = PromptTemplate(input_variables=["theme"],template="Write the opening paragraph of a short story based on the following theme: {theme}"
)
story_start_chain = LLMChain(llm=llm, prompt=story_start_prompt)# 组合成顺序链
creative_writing_chain = SimpleSequentialChain(chains=[theme_chain, story_start_chain], verbose=True)# 调用顺序链
story_topic = "a magical forest"
result_story = creative_writing_chain.invoke(story_topic)
print(f"\n故事主题: {story_topic}")
print(f"故事开头:\n{result_story['output']}")
2.6. Agents(代理)代码案例
Agents 赋予了语言模型决策和行动的能力,使其能够自主地选择并执行工具来完成任务。以下是一个使用 initialize_agent 创建一个简单 Agent 的示例,该 Agent 可以使用搜索工具。
from langchain_openai import ChatOpenAI
from langchain.agents import AgentExecutor, create_react_agent
from langchain_core.tools import Tool
from langchain_community.utilities import WikipediaAPIWrapper
from langchain_core.prompts import ChatPromptTemplate# 设置您的OpenAI API Key
# os.environ["OPENAI_API_KEY"] = "YOUR_API_KEY"llm = ChatOpenAI(openai_api_key="YOUR_API_KEY", temperature=0)print("\n--- Agents 示例 ---")# 1. 定义工具
# 这里使用Wikipedia作为示例工具
wikipedia = WikipediaAPIWrapper()
wikipedia_tool = Tool(name="Wikipedia",func=wikipedia.run,description="useful for when you need to answer questions about general knowledge."
)tools = [wikipedia_tool]# 2. 定义Agent的Prompt
# LangChain 0.2.x 推荐使用 create_react_agent 来创建Agent
# 需要一个Prompt,其中包含agent_scratchpad用于Agent的思考过程prompt = ChatPromptTemplate.from_messages([("system", "You are a helpful assistant."),("human", "{input}"),("placeholder", "{agent_scratchpad}"), # 代理的思考过程
])# 3. 创建Agent
agent = create_react_agent(llm, tools, prompt)# 4. 创建AgentExecutor
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)# 5. 调用Agent
question = "What is the capital of France?"
print(f"\nAgent 提问: {question}")
response = agent_executor.invoke({"input": question})
print(f"Agent 回答: {response['output']}")question_complex = "Who is the current president of the United States and what is their main policy on climate change?"
print(f"\nAgent 提问: {question_complex}")
response_complex = agent_executor.invoke({"input": question_complex})
print(f"Agent 回答: {response_complex['output']}")
结论
LangChain 作为一个强大的 LLM 应用开发框架,通过其模块化的设计和丰富的功能组件,极大地简化了基于大型语言模型的应用程序的开发过程。它将 LLM、向量数据库、提示词、外部知识和工具等元素有机地整合在一起,使得开发者能够构建出具有上下文感知能力、自主性和高度交互性的智能应用。
从 Models 到 Prompts,再到 Indexes、Memory、Chains 和 Agents,LangChain 的每一个核心组件都扮演着不可或缺的角色,共同构成了构建复杂 LLM 应用的基石。通过深入理解这些组件的功能和相互关系,开发者可以更高效地设计、实现和部署各种创新性的 LLM 应用,从而在人工智能时代释放 LLM 的巨大潜力。
随着 LangChain 社区的不断发展和完善,以及底层 LLM 技术的持续进步,我们有理由相信,LangChain 将在未来的 LLM 应用开发中发挥越来越重要的作用,推动人工智能技术在各个领域的广泛应用。
3. 综合实战案例:构建智能文档问答系统
以下是一个综合案例,展示如何使用LangChain的多个核心组件构建一个完整的智能文档问答系统。这个系统集成了文档加载、向量存储、检索、记忆和对话等功能。
import os
import tempfile
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langchain_community.document_loaders import TextLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.vectorstores import Chroma
from langchain.chains import ConversationalRetrievalChain
from langchain.memory import ConversationBufferMemory
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholderclass DocumentQASystem:def __init__(self, openai_api_key: str):"""初始化文档问答系统"""self.api_key = openai_api_key# 初始化模型self.llm = ChatOpenAI(openai_api_key=self.api_key,model="gpt-3.5-turbo",temperature=0.7)self.embeddings = OpenAIEmbeddings(openai_api_key=self.api_key)# 初始化记忆self.memory = ConversationBufferMemory(memory_key="chat_history",return_messages=True,output_key="answer")# 向量存储self.vectorstore = Noneself.qa_chain = Nonedef load_documents(self, text_content: str):"""加载和处理文档"""# 创建临时文件with tempfile.NamedTemporaryFile(mode='w', delete=False, suffix='.txt', encoding='utf-8') as f:f.write(text_content)temp_file_path = f.nametry:# 文档加载loader = TextLoader(temp_file_path, encoding='utf-8')documents = loader.load()# 文本分割text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000,chunk_overlap=200,length_function=len,)splits = text_splitter.split_documents(documents)# 创建向量存储self.vectorstore = Chroma.from_documents(documents=splits,embedding=self.embeddings,persist_directory="./chroma_db")print(f"成功加载文档,分割为 {len(splits)} 个块")finally:# 清理临时文件os.unlink(temp_file_path)def setup_qa_chain(self):"""设置问答链"""if not self.vectorstore:raise ValueError("请先加载文档")# 创建检索器retriever = self.vectorstore.as_retriever(search_type="similarity",search_kwargs={"k": 3})# 自定义提示词模板system_template = """你是一个专业的文档分析助手。请基于提供的上下文信息回答用户的问题。上下文信息:
{context}请遵循以下原则:
1. 仅基于提供的上下文信息回答问题
2. 如果上下文中没有相关信息,请明确说明
3. 回答要准确、简洁、有用
4. 可以引用具体的文档片段"""prompt = ChatPromptTemplate.from_messages([("system", system_template),MessagesPlaceholder(variable_name="chat_history"),("human", "{question}")])# 创建对话检索链self.qa_chain = ConversationalRetrievalChain.from_llm(llm=self.llm,retriever=retriever,memory=self.memory,return_source_documents=True,verbose=True,combine_docs_chain_kwargs={"prompt": prompt})def ask_question(self, question: str):"""提问并获取答案"""if not self.qa_chain:raise ValueError("请先设置问答链")response = self.qa_chain.invoke({"question": question})return {"answer": response["answer"],"source_documents": response.get("source_documents", []),"chat_history": self.memory.chat_memory.messages}def get_conversation_history(self):"""获取对话历史"""return self.memory.chat_memory.messages# 使用示例
def main():# 设置API Keyapi_key = "YOUR_OPENAI_API_KEY"# 创建问答系统qa_system = DocumentQASystem(api_key)# 示例文档内容document_content = """LangChain是一个强大的框架,专门用于开发由语言模型驱动的应用程序。它的核心优势在于:1. 模块化设计:LangChain将复杂的LLM应用分解为可重用的组件2. 丰富的集成:支持多种LLM提供商和第三方工具3. 灵活的链式组合:可以将多个组件链接成复杂的工作流4. 内置的记忆管理:支持对话历史的维护和管理5. 强大的代理系统:允许LLM自主选择和使用工具LangChain的主要组件包括:- Models:与各种语言模型的统一接口- Prompts:提示词模板和管理系统- Indexes:文档加载、分割和检索系统- Memory:对话历史管理- Chains:组件链接和工作流管理- Agents:智能代理和工具使用在实际应用中,LangChain被广泛用于构建聊天机器人、问答系统、文档分析工具、代码助手等各种AI应用。"""try:# 加载文档print("正在加载文档...")qa_system.load_documents(document_content)# 设置问答链print("正在设置问答系统...")qa_system.setup_qa_chain()# 进行问答questions = ["LangChain的主要优势是什么?","LangChain有哪些核心组件?","除了刚才提到的组件,还有其他重要特性吗?"]for question in questions:print(f"\n问题:{question}")response = qa_system.ask_question(question)print(f"回答:{response['answer']}")# 显示引用的文档片段if response['source_documents']:print("\n引用来源:")for i, doc in enumerate(response['source_documents']):print(f"片段 {i+1}: {doc.page_content[:200]}...")print("-" * 80)# 显示对话历史print("\n=== 对话历史 ===")history = qa_system.get_conversation_history()for i, message in enumerate(history):role = "用户" if message.type == "human" else "助手"print(f"{role}: {message.content}")except Exception as e:print(f"错误:{e}")if __name__ == "__main__":main()
3.1. 系统架构说明
这个综合案例展示了以下LangChain组件的集成使用:
- Models:使用ChatOpenAI和OpenAIEmbeddings处理对话和文档嵌入
- Indexes:通过TextLoader加载文档,RecursiveCharacterTextSplitter分割文本,Chroma存储向量
- Memory:使用ConversationBufferMemory维护对话历史
- Chains:通过ConversationalRetrievalChain组合检索和对话功能
- Prompts:自定义ChatPromptTemplate优化回答质量
3.2. 系统特性
- 文档理解:自动加载和分析文档内容
- 智能检索:基于语义相似性检索相关信息
- 上下文记忆:维护多轮对话的上下文
- 来源追踪:提供答案的文档来源引用
- 可扩展性:易于添加新的文档和功能
3.3. 实际应用扩展
这个基础框架可以扩展为:
- 企业知识库问答:加载公司内部文档和手册
- 学术研究助手:分析学术论文和研究资料
- 法律文件分析:处理法律条文和案例
- 技术文档助手:帮助理解API文档和技术规范
- 客户服务机器人:基于产品文档回答用户问题
4. 最佳实践和性能优化
4.1. 开发最佳实践
设计原则:
- 模块化开发:将功能分解为独立的可重用组件
- 错误处理:实现完善的异常处理和日志记录
- 配置管理:使用环境变量管理敏感信息
- 测试覆盖:编写单元测试和集成测试
安全考虑:
- API密钥管理:安全存储和使用API密钥
- 输入验证:验证和清理用户输入
- 输出过滤:过滤敏感或有害内容
- 访问控制:实现适当的权限管理
4.2. 性能优化策略
缓存优化:
- LLM响应缓存:缓存常见问题的回答
- 嵌入向量缓存:避免重复计算文档嵌入
- 检索结果缓存:缓存相似查询的检索结果
并发处理:
- 异步调用:使用异步方式调用LLM API
- 批量处理:批量处理多个请求
- 连接池:管理数据库和API连接
成本控制:
- Token优化:减少不必要的Token消耗
- 模型选择:根据任务选择合适的模型
- 缓存策略:降低API调用频率
4.3. 监控和调试
性能监控:
- 响应时间监控:跟踪系统响应速度
- API使用监控:监控API调用频率和成本
- 错误率监控:监控系统错误和异常
调试技巧:
- 详细日志:记录详细的执行过程
- 分步调试:逐步验证每个组件的输出
- 性能分析:识别系统性能瓶颈
5. 结论与展望
5.1. LangChain的价值总结
LangChain 作为一个强大的 LLM 应用开发框架,通过其模块化的设计和丰富的功能组件,极大地简化了基于大型语言模型的应用程序的开发过程。它将 LLM、向量数据库、提示词、外部知识和工具等元素有机地整合在一起,使得开发者能够构建出具有上下文感知能力、自主性和高度交互性的智能应用。
核心价值体现:
- 降低开发门槛:通过抽象化复杂的LLM操作,让更多开发者能够快速构建AI应用
- 提高开发效率:预构建的组件和链式操作显著减少了开发时间
- 增强应用能力:通过外部工具和知识库集成,突破了LLM的固有限制
- 保证系统可靠性:内置的错误处理和优化机制提高了应用的稳定性
- 支持快速迭代:模块化设计使得功能更新和优化变得简单
5.2. 技术发展趋势
模型能力提升:
- 多模态融合:支持文本、图像、音频、视频的综合处理
- 推理能力增强:更强的逻辑推理和复杂问题解决能力
- 效率优化:更快的推理速度和更低的计算成本
框架演进方向:
- 云原生支持:更好的云环境部署和扩展能力
- 边缘计算:支持在边缘设备上运行轻量级模型
- 自动化优化:自动的模型选择和参数调优
- 企业级特性:更强的安全性、监控和治理能力
生态系统发展:
- 工具丰富化:更多专业领域的工具和集成
- 标准化进程:行业标准和最佳实践的确立
- 社区协作:开源社区的持续贡献和创新
5.3. 应用前景展望
垂直领域应用:
- 医疗健康:智能诊断助手、医学文献分析、药物研发支持
- 教育培训:个性化学习助手、智能批改、课程推荐
- 金融服务:风险评估、智能投顾、合规检查
- 法律服务:法条检索、案例分析、合同审查
- 科学研究:文献综述、实验设计、数据分析
企业级应用:
- 知识管理:企业知识库的智能化管理和检索
- 客户服务:24/7智能客服和问题解决
- 业务流程自动化:复杂业务流程的自动化处理
- 决策支持:基于数据和知识的智能决策辅助
5.4. 学习建议和发展路径
入门学习路径:
- 理论基础:了解LLM基本原理和NLP基础知识
- 框架学习:深入学习LangChain的核心概念和组件
- 实践练习:通过小项目练习各个组件的使用
- 综合应用:构建完整的LLM应用项目
进阶发展方向:
- 架构设计:学习大规模LLM应用的架构设计
- 性能优化:掌握系统性能调优和成本控制技巧
- 安全防护:了解AI安全和隐私保护最佳实践
- 业务整合:学习将LLM能力整合到现有业务系统
持续学习建议:
- 关注技术动态:跟踪LangChain和LLM领域的最新发展
- 参与社区:积极参与开源社区贡献和交流
- 实际项目:通过实际项目积累经验和最佳实践
- 跨领域学习:了解不同行业的应用场景和需求
5.5. 未来挑战与机遇
技术挑战:
- 计算资源需求:大模型对计算资源的高要求
- 数据隐私保护:如何在保护隐私的同时利用数据
- 模型可解释性:提高AI决策的透明度和可解释性
- 安全性保障:防范AI系统的安全风险和恶意使用
发展机遇:
- 技术普及化:AI技术向更多行业和场景的渗透
- 商业模式创新:基于LLM的新商业模式和服务
- 社会价值创造:通过AI技术解决社会问题和挑战
- 产业升级推动:AI技术推动传统产业的数字化转型
从 Models 到 Prompts,再到 Indexes、Memory、Chains 和 Agents,LangChain 的每一个核心组件都扮演着不可或缺的角色,共同构成了构建复杂 LLM 应用的基石。通过深入理解这些组件的功能和相互关系,开发者可以更高效地设计、实现和部署各种创新性的 LLM 应用,从而在人工智能时代释放 LLM 的巨大潜力。
随着 LangChain 社区的不断发展和完善,以及底层 LLM 技术的持续进步,我们有理由相信,LangChain 将在未来的 LLM 应用开发中发挥越来越重要的作用,推动人工智能技术在各个领域的广泛应用,为人类社会的发展做出更大的贡献。
对于希望在AI领域发展的开发者和研究者来说,掌握LangChain不仅是技术能力的提升,更是参与未来AI应用生态建设的重要基础。
参考文献
- [1] LLM之LangChain(一)| LangChain六大核心模块简要汇总. (2024, January 8). 知乎. Retrieved from https://zhuanlan.zhihu.com/p/676719738
- [2] 探索AI 森林:LangChain 框架核心组件全景解读. (2023, August 25). 掘金. Retrieved from https://juejin.cn/post/7271227389019914240
- [3] LangChain的核心组件. (2024, July 1). CSDN博客. Retrieved from https://blog.csdn.net/weixin_43160662/article/details/140112314
- [4] 什么是LangChain?. AWS. Retrieved from https://aws.amazon.com/cn/what-is/langchain/
- [5] 什么是LangChain?. Google Cloud. Retrieved from https://cloud.google.com/use-cases/langchain?hl=zh-CN
- [PDF] LangChain学习笔记副本.pdf (本地附件)