Python•元组集合字符串
ʕ⸝⸝⸝˙Ⱉ˙ʔ ♡
- 元组🛥️
- 创建
- 访问
- 修改
- 解包
- 其他操作
- 比较的依据
- 集合🛸
- 创建
- 添加和删除
- 其他操作
- 字符串🪂
- 创建
- 索引和切片
- 基本操作
- 连接
- 加号
- join()
- 重复
- 查找
- in 关键字
- index()
- find()
- startswith()
- endswith()
- 替换
- 分割
- 大小写
- 删除
- 能量站😚
元组🛥️
Python中的元组(tuple)是一种不可变的序列类型,用于存储一组有序的元素。元组中的元素可以是不同类型的数据,如整数点数、字符串、列表、字典等。元组使用圆括号()包围,元素之间用逗号,分隔。
创建
🛥️可以使用圆括号创建元组,也可以省略圆括号,只使用逗号分隔元素。
# 使用圆括号创建元组
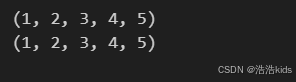
t1 = (1, 2, 3, 4, 5)# 省略圆括号创建元组
t2 = 1, 2, 3, 4, 5print(t1) # 输出: (1, 2, 3, 4, 5)
print(t2) # 输出: (1, 2, 3, 4, 5)
运行截图:
🛥️当元组中只有一个元素时,需要在元素后面加逗号,否则会被当作普通变量而非元组。
# 创建只有一个元素的元组
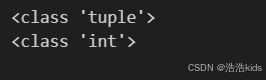
t3 = (42,)
print(type(t3)) # 输出: <class 'tuple'># 不加逗号,会被当作整数
t4 = (42)
print(type(t4)) # 输出: <class 'int'>
运行截图:
访问
可以使用下标索引访问元组中的元素,下标从0开始。还可以使用切片操作获取元组的子序列。切片相关知识可以看Python•列表哦~
t = (0, 1, 2, 3, 4, 5)# 访问第一个元素
first_element = t[0]
print(first_element) # 输出: 0# 访问最后一个元素
last_element = t[-1]
print(last_element) # 输出: 5# 切片操作
sub_tuple = t[1:4]
print(sub_tuple) # 输出: (1, 2, 3)
运行截图:

修改
元组是不可变的,这意味着不能修改元组中的元素。但是,如果元组中包含可变对象(如列表),那么可以修改这些可变对象的内容。此外,可以将元组与其他元组连接,创建一个新的元组。
t1 = (1, 2, 3)
t2 = (4, 5, 6)# 连接两个元组
t3 = t1 + t2
print(t3) # 输出: (1, 2, 3, 4, 5, 6)# 修改元组中的可变对象
t = (1, 2, [3, 4])
t[2][0] = 99
print(t) # 输出: (1, 2, [99, 4])
运行截图:

解包
元组解包是将元组中的元素分配给多个变量的过程。解包时,变量的数量必须与元组中的元素数量相等。
🛥️变量的数量必须与元组中的元素数量相等:
t = (1, 2, 3)
a, b, c = t
print(a) # 输出: 1
print(b) # 输出: 2
print(c) # 输出: 3
运行截图:

🛥️还可以使用星号*来解包元组中的一部分元素(只能有一个用星号*):
t = (1, 2, 3, 4, 5)
a, *b, c = t
print(a) # 输出: 1
print(b) # 输出: [2, 3, 4]
print(c) # 输出: 5
运行截图:

其他操作
元组支持一些其他操作,如计算长度、连接、重复等。这些操作与列表类似,但请注意,元组是不可变的,因此无法修改其内容。
t1 = (1, 2, 3)
t2 = (4, 5, 6)# 计算元组长度
length = len(t1)
print(length) # 输出: 3# 连接两个元组
t3 = t1 + t2
print(t3) # 输出: (1, 2, 3, 4, 5, 6)# 重复元组元素
t4 = t1 * 3
print(t4) # 输出: (1, 2, 3, 1, 2, 3, 1, 2, 3)# 元组比较
print(t1 < t2) # 输出: True# 元组索引
print(t1[1]) # 输出: 2# 元组切片
print(t1[1:3]) # 输出: (2, 3)
运行截图:
因为 1 < 4,所以t1 被认为小于 t2。

比较的依据
逐元素比较:
- Python首先比较两个元组的第一个元素。
- 如果第一个元素不同,则根据这两个元素的大小关系确定整个元组的大小关系。
如果第一个元素相同,则继续比较第二个元素,依此类推。
长度比较:
如果所有对应的元素都相同,但一个元组比另一个元组长,则较短的元组被认为是“小于”较长的元组。
🛥️示例一:
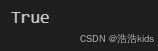
t1 = (1, 2, 4)
t2 = (1, 1, 6)print(t1 < t2) # 输出: False
运行截图:
因为 2 > 1,所以t1 被认为大于 t2,即t1 < t2的结果是False。

🛥️示例二:
t1 = (1, 2)
t2 = (1, 2, 0)print(t1 < t2) # 输出: True
运行截图:
如果前面的所有对应元素都相同,但一个元组更长,那么较短的元组被认为是“小于”较长的元组。
集合🛸
Python中的集合(Set)是一种内建的数据类型,用于存储不重复的元素。
创建
可以使用大括号 {} 或者 set() 函数来创建集合。需要注意的是,空的大括号 {} 用于创建空字典,而不是空集合。要创建空集合,请务必使用 set() 函数。
# 使用大括号创建集合
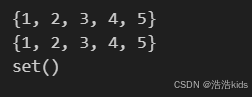
my_set = {1, 2, 3, 4, 5}
print(my_set) # 输出: {1, 2, 3, 4, 5}# 使用 set() 函数创建集合
another_set = set([1, 2, 3, 4, 5])
print(another_set) # 输出: {1, 2, 3, 4, 5}# 创建空集合
empty_set = set()
print(empty_set) # 输出: set()
运行截图:
添加和删除
使用 add() 方法可以向集合添加元素,而 remove() 方法可以从集合中删除元素。
my_set = {1, 2, 3}
my_set.add(4) # 添加元素 4
print(my_set) # 输出: {1, 2, 3, 4}my_set.remove(2) # 删除元素 2
print(my_set) # 输出: {1, 3, 4}
运行截图:

其他操作
集合还具有许多其他操作,有个大概印象就行。
my_set = {1, 2, 3}
my_set.add(4) # 添加元素 4
print(my_set) # 输出: {1, 2, 3, 4}
set1 = {1, 2, 3}
set2 = {3, 4, 5}# 并集
print(set1 | set2) # 输出: {1, 2, 3, 4, 5}
print(set1.union(set2)) # 输出: {1, 2, 3, 4, 5}# 交集
print(set1 & set2) # 输出: {3}
print(set1.intersection(set2)) # 输出: {3}# 差集
print(set1 - set2) # 输出: {1, 2}
print(set1.difference(set2)) # 输出: {1, 2}# 对称差集
print(set1 ^ set2) # 输出: {1, 2, 4, 5}
print(set1.symmetric_difference(set2)) # 输出: {1, 2, 4, 5}# 添加元素到集合
set1.update(set2) # 等价于 set1 |= set2
print(set1) # 输出: {1, 2, 3, 4, 5}# 删除集合中的所有元素
set1.clear()
print(set1) # 输出: set()# 是否为子集
print(set2.issubset(set1)) # 输出: False
运行截图:

字符串🪂
Python中的字符串(String)是一种基本的数据类型,用于表示文本信息。字符串是由字符组成的序列,可以包含字母、数字、标点符号以及特殊字符。在Python中,字符串是不可变的,这意味着一旦创建了一个字符串,就不能修改它的内容。尽管如此,你仍然可以通过创建新的字符串来实现对字符串的修改。
创建
在Python中,可以使用单引号(')、双引号(")或三引号(''' 或 """)来创建字符串。
# 使用单引号创建字符串
s1 = 'Hello, World!'# 使用双引号创建字符串
s2 = "Hello, World!"# 使用三引号创建多行字符串
s3 = '''这是一个
多行字符串
示例'''s4 = """这也是一个
多行字符串
示例"""print(s1)
print(s2)
print(s3)
print(s4)
运行截图:

索引和切片
🪂字符串中的每个字符都有一个索引,索引从0开始。可以使用索引来访问字符串中的单个字符。
s = 'Hello'
print(s[0]) # 输出: H
print(s[4]) # 输出: o
运行截图:

🪂还可以使用切片来访问字符串中的一部分字符。切片操作使用冒号(:)分隔起始索引和结束索引。
切片是[开始:结束:步长],最终不包括结束。
s = 'Hello, World!'
print(s[0:5]) # 输出: Hello
print(s[7:12]) # 输出: World
print(s[0:11:2]) # 输出: Hlo ol
运行截图:

基本操作
连接
加号
使用加号(+)来连接两个或多个字符串。
s1 = 'Hello'
s2 = 'World'
s3 = s1 + ', ' + s2 + '!'
print(s3) # 输出: Hello, World!
运行截图:
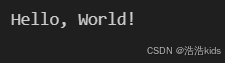
join()
拼接字符串还有一种方法,那就是用join()方法。当使用这个函数时,要指出需要拼接哪些字符串,另外如果需要,还可以指定在各个字符串拼接处插入什么样的字符。
# 定义一个字符串列表
words = ['你', '要', '开', '心', '哦']# 使用♡作为分隔符连接列表中的元素
sentence = '♡'.join(words)
print(sentence)
# 输出: 你♡要♡开♡心♡哦
运行截图:

重复
可以使用星号(*)来重复一个字符串多次。
s = 'Hi'
print(s * 3) # 输出: HiHiHi
运行截图:

查找
in 关键字
关键字in可以判断正在检查的字符串是否包含特定子串。
a = "我爱你"
if "你" in a:print("我找到你了♡")运行截图:

index()
关键字in只能判断正在检查的字符串是否包含特定子串,并不能指明子串的具体位置。如果要知道具体位置,就要用到index()方法。注意,在调用index()方法之前,我们先用关键字in检查这个长字符串是否包含子串。这样做的原因是,在调用index()方法时,如果字符串中没有要查找的内容,系统就会返回一条错误消息,而先用关键字in来检查则可以避免这种情况。
a = "我爱你"
if "你" in a:print(f"我找到你了♡,虽然你有时候有点{a.index("你")}")
运行截图:

find()
find() 方法用于查找子字符串在字符串中的位置,找到就返回要查找的子字符串的第一个字符所在的位置,如果找不到则返回 -1。
s = 'Hello, World!'
print(s.find('World')) # 输出: 7
运行截图:
,后还有一个空格哦~

startswith()
startswith() 方法用于判断字符串是否以指定的前缀开始。如果字符串以指定前缀开始,则返回 True,否则返回 False。
🪂基本语法:
str.startswith(prefix[, start[, end]])
prefix:要检查的前缀,可以是一个字符串或元组。
start(可选):开始检查的位置,默认为 0。
end(可选):结束检查的位置,默认为字符串的长度。
🪂示例:
text = "Hello, World!"# 检查是否以 "Hello" 开头
print(text.startswith("Hello")) # 输出: True# 检查是否以 "World" 开头
print(text.startswith("World")) # 输出: False# 指定开始和结束位置
print(text.startswith("World", 7)) # 输出: True
print(text.startswith("o", 4, 6)) # 输出: True# 使用元组作为前缀
prefixes = ("Hi", "Hello", "Hey")
print(text.startswith(prefixes)) # 输出: True
运行截图:

endswith()
endswith() 方法用于判断字符串是否以指定的后缀结尾。如果字符串以指定后缀结尾,则返回 True,否则返回 False。
🪂基本语法:
str.endswith(suffix[, start[, end]])
suffix:要检查的前缀,可以是一个字符串或元组。
start(可选):开始检查的位置,默认为 0。
end(可选):结束检查的位置,默认为字符串的长度。
🪂示例:
text = "Hello, World!"# 检查是否以 "World!" 结尾
print(text.endswith("World!")) # 输出: True# 检查是否以 "Hello" 结尾
print(text.endswith("Hello")) # 输出: False# 指定开始和结束位置
print(text.endswith("o!", 5, 7)) # 输出: False
print(text.endswith("Hello", 0, 5)) # 输出: True# 使用元组作为后缀
suffixes = (".txt", ".csv", "!")
print(text.endswith(suffixes)) # 输出: True
运行截图:

替换
replace() 方法用于替换字符串中的子字符串。
s = 'Hello, World!'
print(s.replace('World', 'Python')) # 输出: Hello, Python!
运行截图:

分割
split() 方法用于根据指定的分隔符将字符串分割成多个部分。
🪂基本语法:
str.split(sep=None, maxsplit=-1)
sep(可选):指定用于分割字符串的分隔符。如果未提供,默认使用任何空白字符(如空格、制表符 \t、换行符\n 等)作为分隔符。
maxsplit(可选):指定分割的最大次数。如果提供了该参数,字符串将被分割成最多 maxsplit + 1 个子字符串。默认值为 -1,表示不限制分割次数。不限制分割次数时,split() 方法会根据分隔符出现的次数尽可能多地进行分割。
这个方法会丢掉分解标记,比如print(s.split(',banana'))会丢掉,banana。
🪂示例:
s = 'apple,banana,orange'
print(s.split(',')) # 输出: ['apple', 'banana', 'orange']
运行截图:

大小写
upper() 和 lower() 方法分别用于将字符串转换为大写和小写。
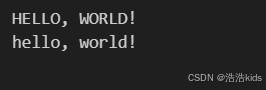
s = 'Hello, World!'
print(s.upper()) # 输出: HELLO, WORLD!
print(s.lower()) # 输出: hello, world!
运行截图:
删除
strip() 方法是 Python 字符串对象的内置方法,用于移除字符串两端的指定字符(默认为移除空白字符)。该方法不会修改原始字符串,而是返回一个新的处理后的字符串,因为在 Python 中字符串是不可变的。注意,strip() 方法不会移除字符串中间的字符。如果字符串两端根本没有要移除的字符,那什么也不会删除。
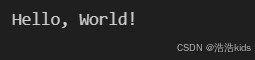
s = ' Hello, World! '
print(s.strip()) # 输出: Hello, World!
运行截图:
🪂基本语法:
str.strip([chars])
chars(可选):指定要移除的字符集合。如果未提供,默认移除字符串两端的所有空白字符(包括空格 ' '、制表符 '\t'、换行符 ' ' 等)。chars 参数可以包含多个不同的字符,strip() 会依次移除这些字符。
🪂示例:
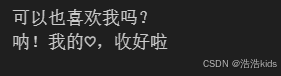
a = "♡可以也喜欢我吗?♡"
clean_text = a.strip('♡')
print(clean_text) # 输出: "可以也喜欢我吗?"b = "--♡-呐!我的♡,收好啦--♡-"
clean_text = b.strip('-♡')
print(clean_text) # 输出: "呐!我的♡,收好啦"
运行截图:
能量站😚
这样的日子,我是过不够的。而当我终于意识到我愿意过这样的日子,已是多年以后。

❤️进步ing❤️