Python 使用 DrissionPage 模块进行爬虫
目录
- 一、安装 DrissionPage 模块与准备
- 1. 安装模块
- 2. 设置要打开浏览器的路径
- 二、获取并解析数据
- 1. 打开指定网站的页面
- 2. 监听网络数据
- 三、保存数据
- 四、示例
- 五、其他示例
- 1. 定位信息所在的 div 标签
- 2. css 语法定位 + 点击翻页
学习视频:【Python爬虫可视化:采集分析各大招聘网站信息数据(BOSS直聘、前程无忧、智联招聘、猎聘网)】
一、安装 DrissionPage 模块与准备
DrissionPage 模块官网地址:【DrissionPage官网】
1. 安装模块
-
Win + R 输入 cmd 打开命令提示符。
-
输入
pip install DrissionPage,利用 pip 安装模块。
如果想要升级成最新稳定版,则输入命令pip install DrissionPage --upgrade。
参考文档:【安装 | DrissionPage官网】
drissionpage 模块与 requests 模块的区别在于:
-
requests 模块通过模拟浏览器对 utl 地址发送请求从而获取数据;
-
而 drissionpage 模块则直接打开浏览器以访问网站。
2. 设置要打开浏览器的路径
- 在 .py 文件里输入以下代码,填入电脑中 Chrome 或其他浏览器的可执行文件路径,然后执行(执行一遍即可)。
from DrissionPage import ChromiumOptions# 把浏览器路径记录到配置文件,今后启动浏览器皆使用该路径
# 电脑内 Chrome 可执行文件路径
path = r'C:\Program Files\Google\Chrome\Application\chrome.exe'
ChromiumOptions().set_browser_path(path).save()
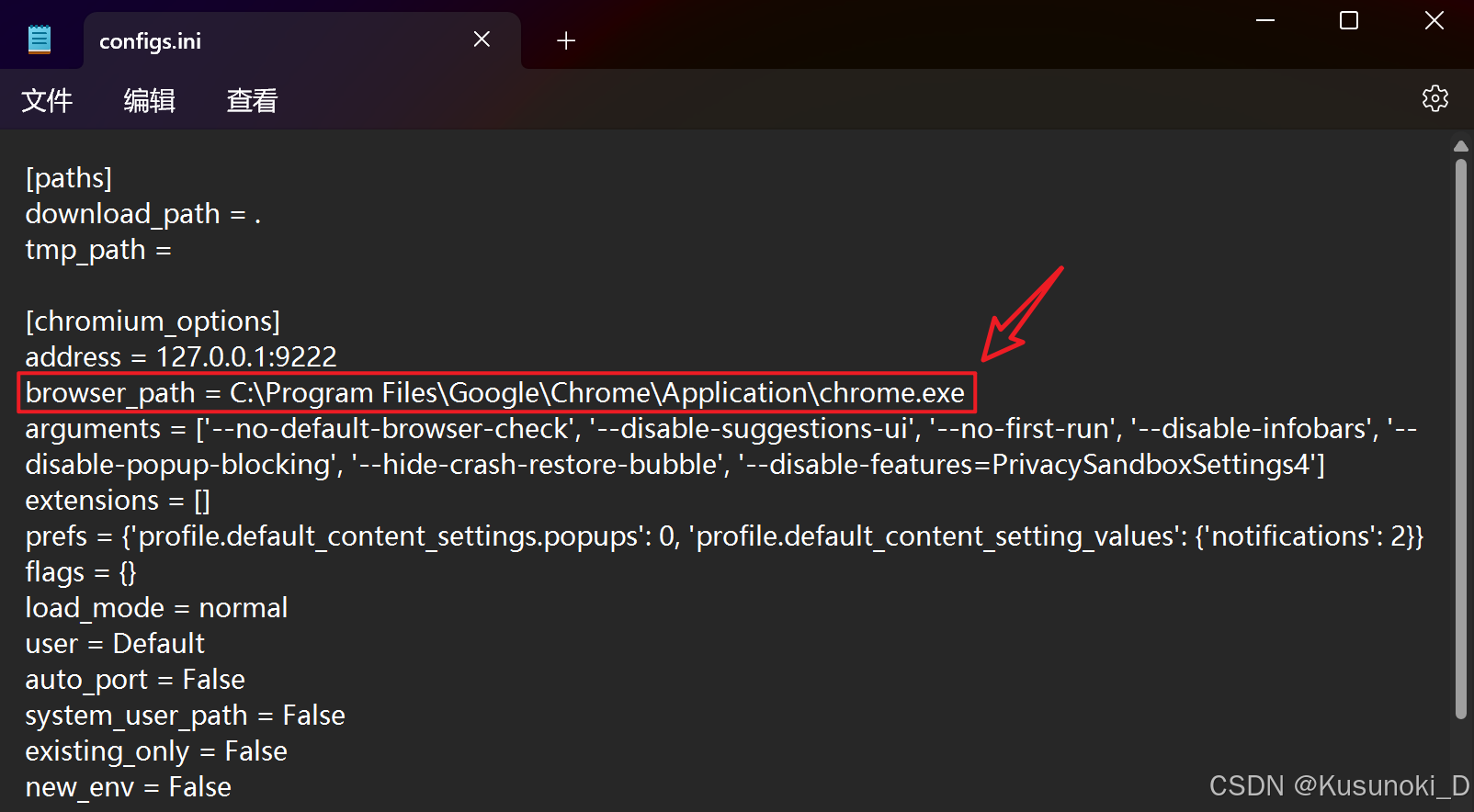
- 运行成功后会出现以下结果。
配置已保存到文件: D:\anaconda3\envs\python312\Lib\site-packages\DrissionPage\_configs\configs.ini
以后程序可自动从文件加载配置
参考文档:【准备工作 | DrissionPage官网】
二、获取并解析数据
-
明确需求:明确采集的网站和数据内容。
-
抓包分析:通过浏览器的开发者工具分析对应的数据位置。
- 打开开发者工具(右键点击 “检查” 或 F12 ,再选择 “网络”);
- Ctrl + R 刷新网页;
- 通过关键字搜索找到对应的数据位置。
- 可以通过 “元素” 面板,即数据标签 css 或 xpath 语法定位;
- 可以通过 “网络” 面板,在执行动作之前监听数据包的特征,获取相应的响应数据。
1. 打开指定网站的页面
# 导入自动化模块
from DrissionPage import ChromiumPage# 打开浏览器(实例化浏览器对象)
google = ChromiumPage()
# 访问指定网站的页面
google.get(r"https://www.zhipin.com/web/geek/jobs?query=%E7%88%AC%E8%99%AB&city=101260100")
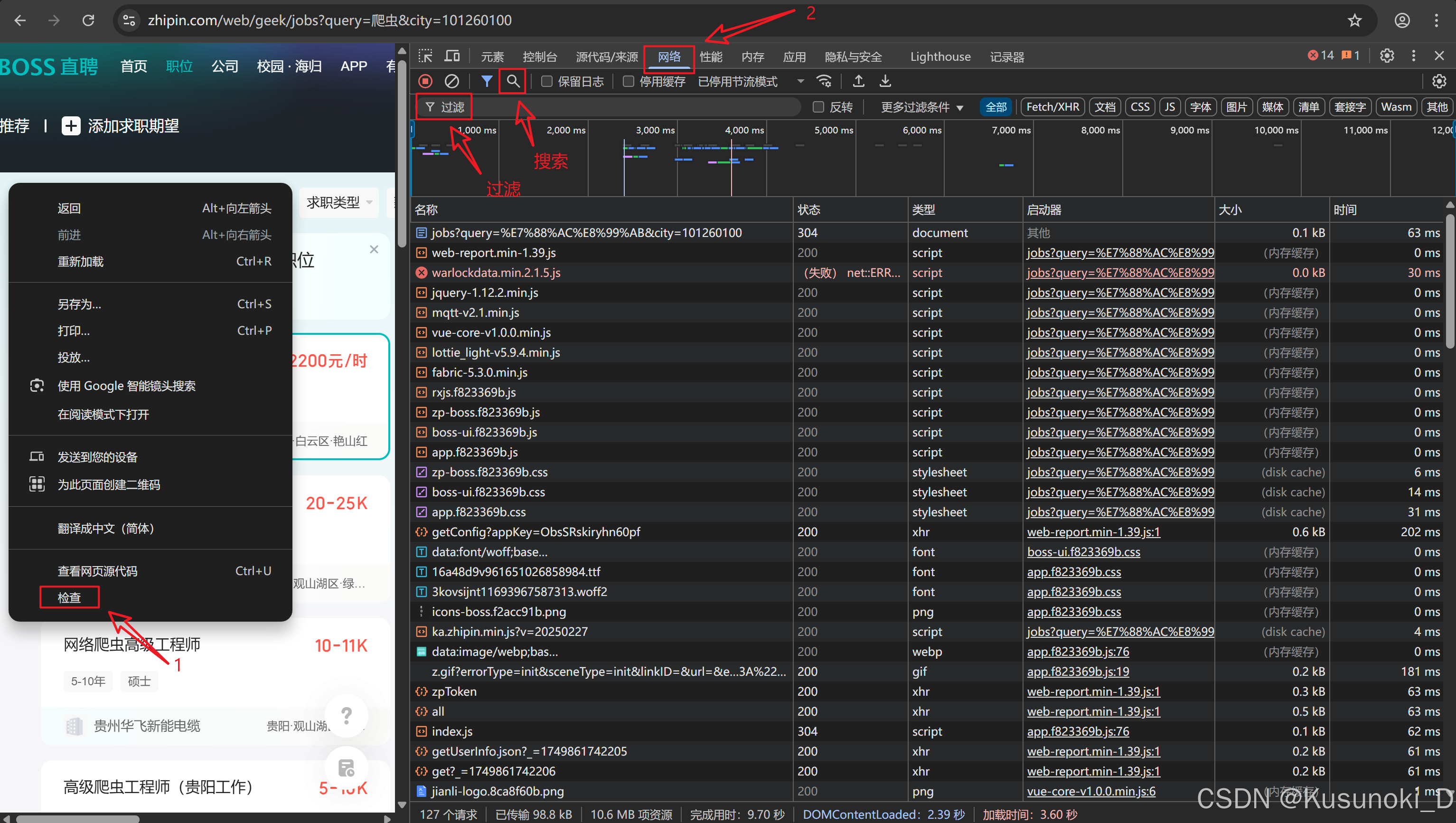
-
运行上述代码会弹出网站页面,右键选择 “检查” 。
-
选择 “网络” ,Ctrl + R 进行刷新。
2. 监听网络数据
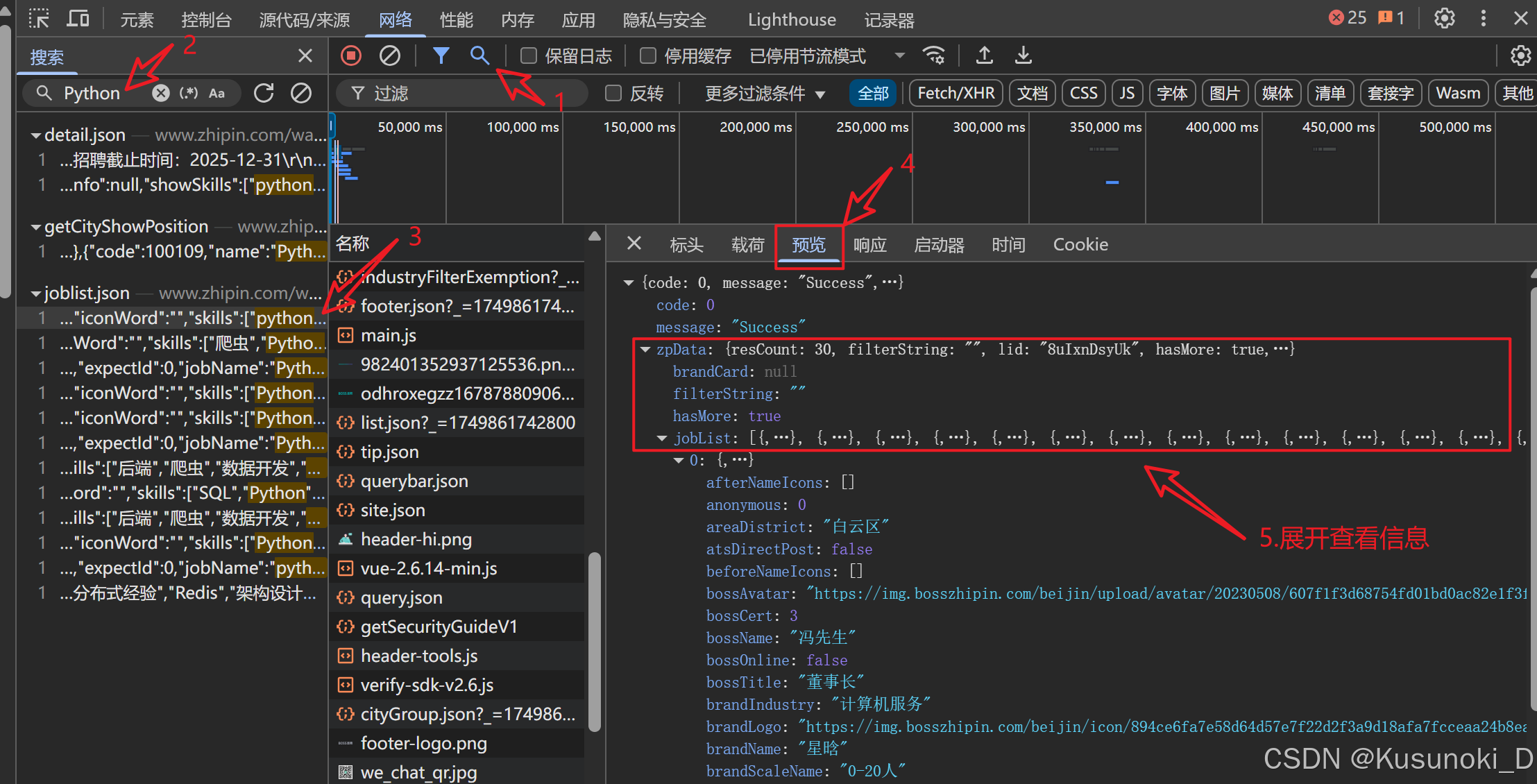
- 通过搜索指定目标特征,并通过 “预览” 查看获取到的信息(展开 zpData 下的 jobList 查看详细信息)。
- 可以通过 listen.start() 函数启动监听器,启动同时可设置获取的目标特征,那么该如何设置?点击 “标头” ,复制下图红框中的内容并进行过滤验证。
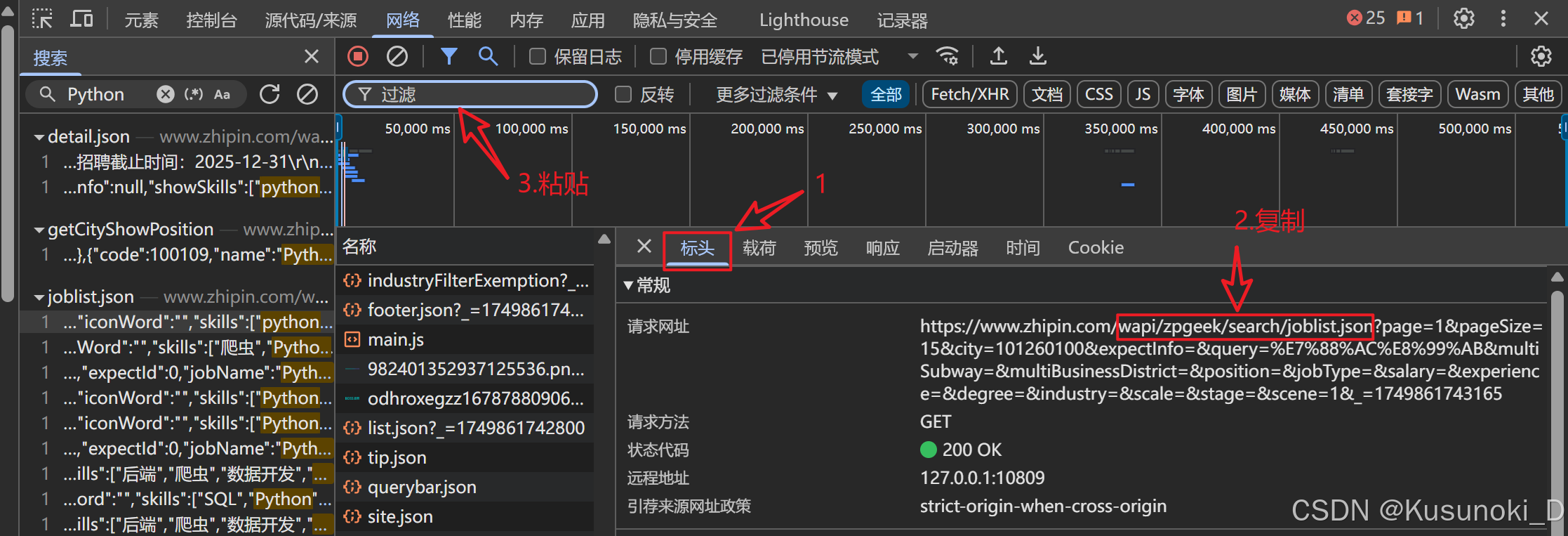
-
如果过滤出只有一条,说明刚刚复制的网址是一个唯一特征,将该网址粘贴进 listen.start() 函数里。
-
如果过滤出多条,可以通过设置 listen.wait() 的 count 字段监听多条,例如:
data_load = google.listen.wait(count=2),然后从返回值中选择需要获取响应数据的那一条进行操作,例如:data_response = data_load[-1].response.body。
# 导入自动化模块
from DrissionPage import ChromiumPage
# 导入格式化输出模块
from pprint import pprint# 打开浏览器(实例化浏览器对象)
google = ChromiumPage()
# 监听数据包
google.listen.start(r"wapi/zpgeek/search/joblist.json")
# 访问指定网站的页面
google.get(r"https://www.zhipin.com/web/geek/jobs?query=%E7%88%AC%E8%99%AB&city=101260100")
# 获取数据包加载
data_load = google.listen.wait()
# 获取响应数据(字典)
data_response = data_load.response.body
print(data_response)
print('-' * 50)
# 键值对取值,提取信息为列表
data_list = data_response['zpData']['jobList']
# for 循环遍历,提取列表里的元素
for index in data_list:# print(index)# ----------------pprint(index)print('-' * 50)
部分结果展示:
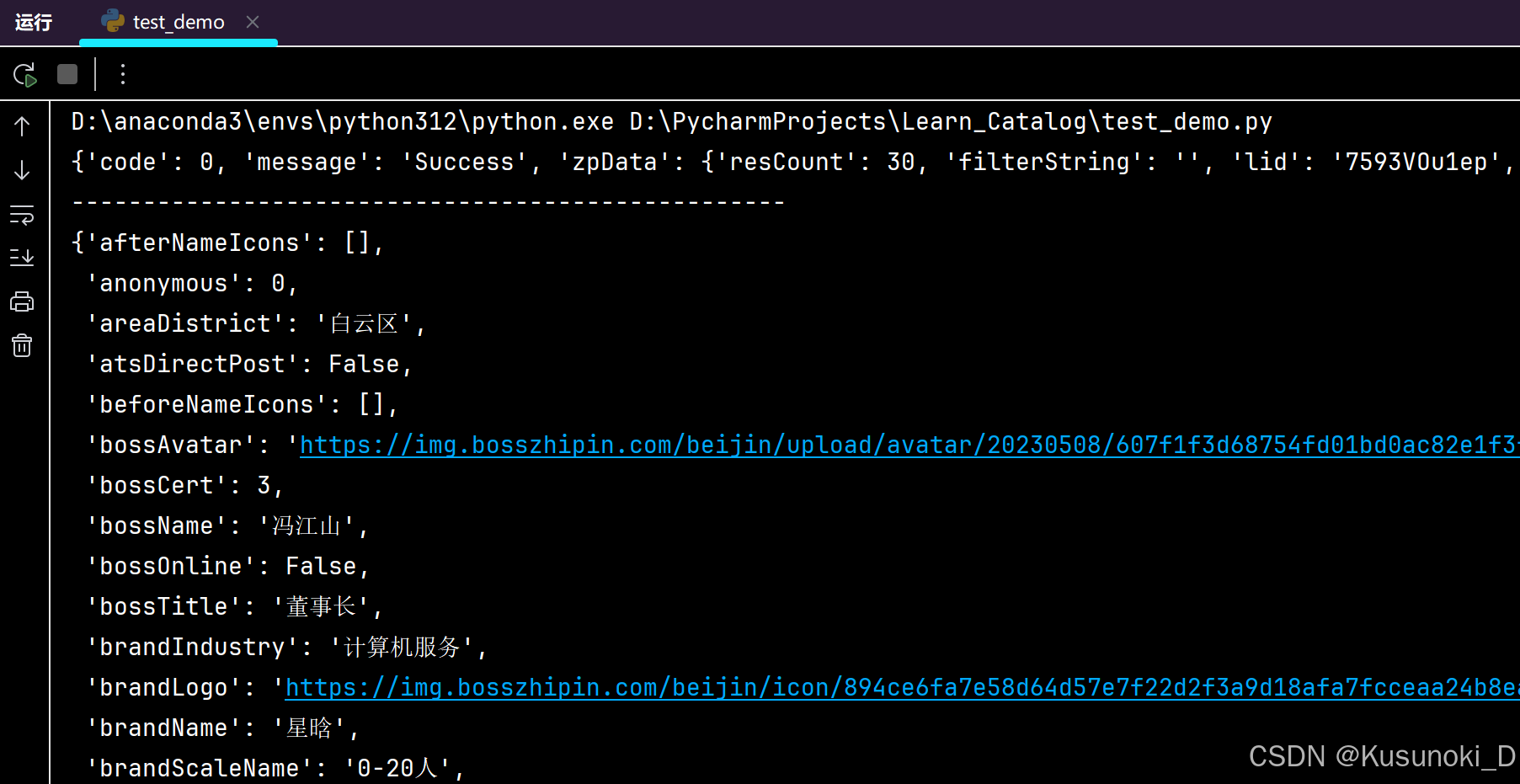
- 提取出需要的内容,以方便查看。
# 导入自动化模块
from DrissionPage import ChromiumPage# 打开浏览器(实例化浏览器对象)
google = ChromiumPage()
# 监听数据包
google.listen.start(r"wapi/zpgeek/search/joblist.json")
# 访问指定网站的页面
google.get(r"https://www.zhipin.com/web/geek/jobs?query=%E7%88%AC%E8%99%AB&city=101260100")
# 获取数据包加载
data_load = google.listen.wait()
# 获取响应数据(字典)
data_response = data_load.response.body
# 键值对取值,提取信息为列表
data_list = data_response['zpData']['jobList']
# for 循环遍历,提取列表里的元素
for index in data_list:# 提取具体数据信息保存字典中temporarily_dict = {'公司区域': index['areaDistrict'],'招聘领域': index['brandIndustry'],'公司名称': index['brandName'],'公司规模': index['brandScaleName'],'学历要求': index['jobDegree'],'工作经验': index['jobExperience'],'职位名称': index['jobName'],'薪资范围': index['salaryDesc'],'所需技能': ' '.join(index['skills']),'公司福利': ' '.join(index['welfareList'])}for key, value in temporarily_dict.items():print(f'{key} : {value}')print('-' * 50)
部分结果展示:
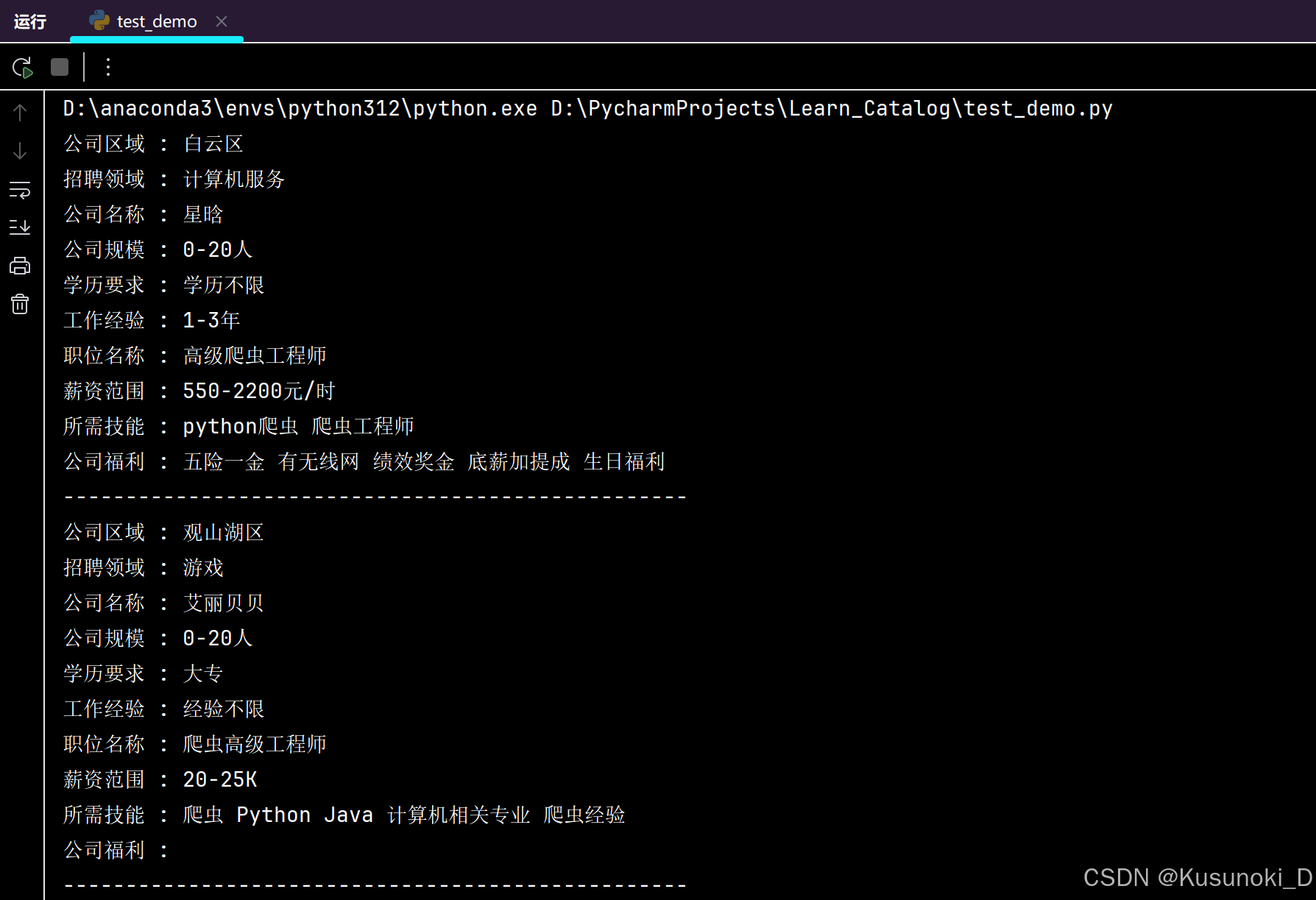
参考文档:
【监听网络数据 | DrissionPage官网】
【Python 基础 (标准库):pprint (数据美化输出)】
三、保存数据
- 用 CSV 文件保存字典数据:
# 导入自动化模块
from DrissionPage import ChromiumPage
import csv# 打开浏览器(实例化浏览器对象)
google = ChromiumPage()
# 监听数据包
google.listen.start(r"wapi/zpgeek/search/joblist.json")
# 访问指定网站的页面
google.get(r"https://www.zhipin.com/web/geek/jobs?query=%E7%88%AC%E8%99%AB&city=101260100")
# 获取数据包加载
data_load = google.listen.wait()
# 获取响应数据(字典)
data_response = data_load.response.body
# 键值对取值,提取信息为列表
data_list = data_response['zpData']['jobList']# 创建文件对象
# 如果只使用 utf-8 编码,则用 Excel 打开 CSV 文件会出现乱码
f = open('recruitment_information.csv', mode='w', encoding='utf-8-sig', newline='')
# 字典写入方法
cd = csv.DictWriter(f, fieldnames=['公司区域','招聘领域','公司名称','公司规模','学历要求','工作经验','职位名称','薪资范围','所需技能','公司福利'
])
cd.writeheader()# for 循环遍历,提取列表里的元素
for index in data_list:# 提取具体数据信息保存字典中temporarily_dict = {'公司区域': index['areaDistrict'],'招聘领域': index['brandIndustry'],'公司名称': index['brandName'],'公司规模': index['brandScaleName'],'学历要求': index['jobDegree'],'工作经验': index['jobExperience'],'职位名称': index['jobName'],'薪资范围': index['salaryDesc'],'所需技能': ' '.join(index['skills']),'公司福利': ' '.join(index['welfareList'])}cd.writerow(temporarily_dict)
- 用 Excel 文件保存字典数据:
# 导入自动化模块
from DrissionPage import ChromiumPage
import pandas as pd# 打开浏览器(实例化浏览器对象)
google = ChromiumPage()
# 监听数据包
google.listen.start(r"wapi/zpgeek/search/joblist.json")
# 访问指定网站的页面
google.get(r"https://www.zhipin.com/web/geek/jobs?query=%E7%88%AC%E8%99%AB&city=101260100")
# 获取数据包加载
data_load = google.listen.wait()
# 获取响应数据(字典)
data_response = data_load.response.body
# 键值对取值,提取信息为列表
data_list = data_response['zpData']['jobList']
# 创建一个空列表
job_info = []
# for 循环遍历,提取列表里的元素
for index in data_list:# 提取具体数据信息保存字典中temporarily_dict = {'公司区域': index['areaDistrict'],'招聘领域': index['brandIndustry'],'公司名称': index['brandName'],'公司规模': index['brandScaleName'],'学历要求': index['jobDegree'],'工作经验': index['jobExperience'],'职位名称': index['jobName'],'薪资范围': index['salaryDesc'],'所需技能': ' '.join(index['skills']),'公司福利': ' '.join(index['welfareList'])}job_info.append(temporarily_dict)# 转换数据
df = pd.DataFrame(job_info)
# 导出保存为 Excel 表格
df.to_excel('recruitment_information.xlsx', index=False)
注:如果不想在第一次运行时弹出浏览器,可设置无头模式:【无头模式 | DrissionPage官网】
四、示例
要求:用 DrissionPage 模块爬虫某网站,通过 “网络” 面板,在执行动作之前监听数据包的特征,获取相应的响应数据,需要实现翻页和保存至 CSV 文件。
# 导入自动化模块
from DrissionPage import ChromiumPage
# # 导入格式化输出模块
# from pprint import pprint
# import csv# def deal_with_data(data_r, cd_p, cd_i, cd_o):
def deal_with_data(data_r):# 键值对取值,提取信息为列表data_list = data_r['data']# for 循环遍历,提取列表里的元素for index in data_list:# pprint(index)# print('-' * 50)# 分解 recommendTagsrecommend_info = [d['text'] for d in index['recommendTags'] if 'text' in d]# 提取具体数据信息保存字典中if index['dataTypeTag'] == '预测':temporarily_pre_dict = {'单位': index['dataId'],'类型': index['dataTypeTag'],'地区': recommend_info[1],'根据': recommend_info[0],'预测': ''.join([d['text'] for d in index['title'] if 'text' in d])}# cd_p.writerow(temporarily_pre_dict)for key, value in temporarily_pre_dict.items():print(f'{key} : {value}')print('-' * 50)else:if len(recommend_info) == 0:area = '未知'money = '未知'elif len(recommend_info) == 1:area = recommend_info[0]money = '未知'else:area = recommend_info[0]money = recommend_info[1]if index['dataTypeTag'] == '采购意向':temporarily_intent_dict = {'标题': ''.join([d['text'] for d in index['title'] if 'text' in d]),'类型': index['dataTypeTag'],'地区': area,'金额': money,'匹配类型': index['keywordMatchType'],'发布时间': index['timeTags'][0]}# cd_i.writerow(temporarily_intent_dict)for key, value in temporarily_intent_dict.items():print(f'{key} : {value}')print('-' * 50)else:# 分解 thisProjectContactif len(index['thisProjectContact']) == 0:project_contact = '暂无'else:project_contact = ' '.join(index['thisProjectContact'])temporarily_dict = {'标题': ''.join([d['text'] for d in index['title'] if 'text' in d]),'类型': index['dataTypeTag'],'地区': area,'金额': money,'匹配类型': index['keywordMatchType'],'项目联系人': project_contact,'发布时间': index['timeTags'][0]}# cd_o.writerow(temporarily_dict)for key, value in temporarily_dict.items():print(f'{key} : {value}')print('-' * 50)# def create_csv_head(f, head_name):
# # 字典写入方法
# cd = csv.DictWriter(f, fieldnames=head_name)
# cd.writeheader()
# return cddef main():# # 创建文件对象——预测招标# f_predict = open('forecast_bidding.csv', mode='a', encoding='utf-8-sig', newline='')# head_name_predict = ['单位', '类型', '地区', '根据', '预测']# cd_predict = create_csv_head(f_predict, head_name_predict)# # 创建文件对象——采购意向# f_intent = open('intent_bidding.csv', mode='a', encoding='utf-8-sig', newline='')# head_name_intent = ['标题', '类型', '地区', '金额', '匹配类型', '发布时间']# cd_intent = create_csv_head(f_intent, head_name_intent)# # 创建文件对象——其他招标# f_other = open('other_bidding.csv', mode='a', encoding='utf-8-sig', newline='')# head_name_other = ['标题', '类型', '地区', '金额', '匹配类型', '项目联系人', '发布时间']# cd_other = create_csv_head(f_other, head_name_other)# 打开浏览器(实例化浏览器对象)google = ChromiumPage()# 监听数据包google.listen.start(r"api/search/bidInfoSearchV232")# 访问指定网站的页面google.get(r"https://bidradar.com.cn/pc/homeSearch?searchType=project&keyword=%E7%8E%AF%E5%A2%83%E7%9B%91%E6%B5%8B")num = 4# 构建循环加载下一页for page in range(1, num):print(f'正在采集第 {page} 页的内容……')# 加载新获取数据包data_load = google.listen.wait()# 获取响应数据(字典)data_response = data_load.response.body# 处理数据deal_with_data(data_response)# deal_with_data(data_response, cd_predict, cd_intent, cd_other)# 下滑页面到底部google.scroll.to_bottom()if page != num - 1:# 定位 “加载更多” 并点击button = google('点击加载更多')button.run_js('this.click();')# f_predict.close()# f_intent.close()# f_other.close()if __name__ == '__main__':main()
部分结果展示:
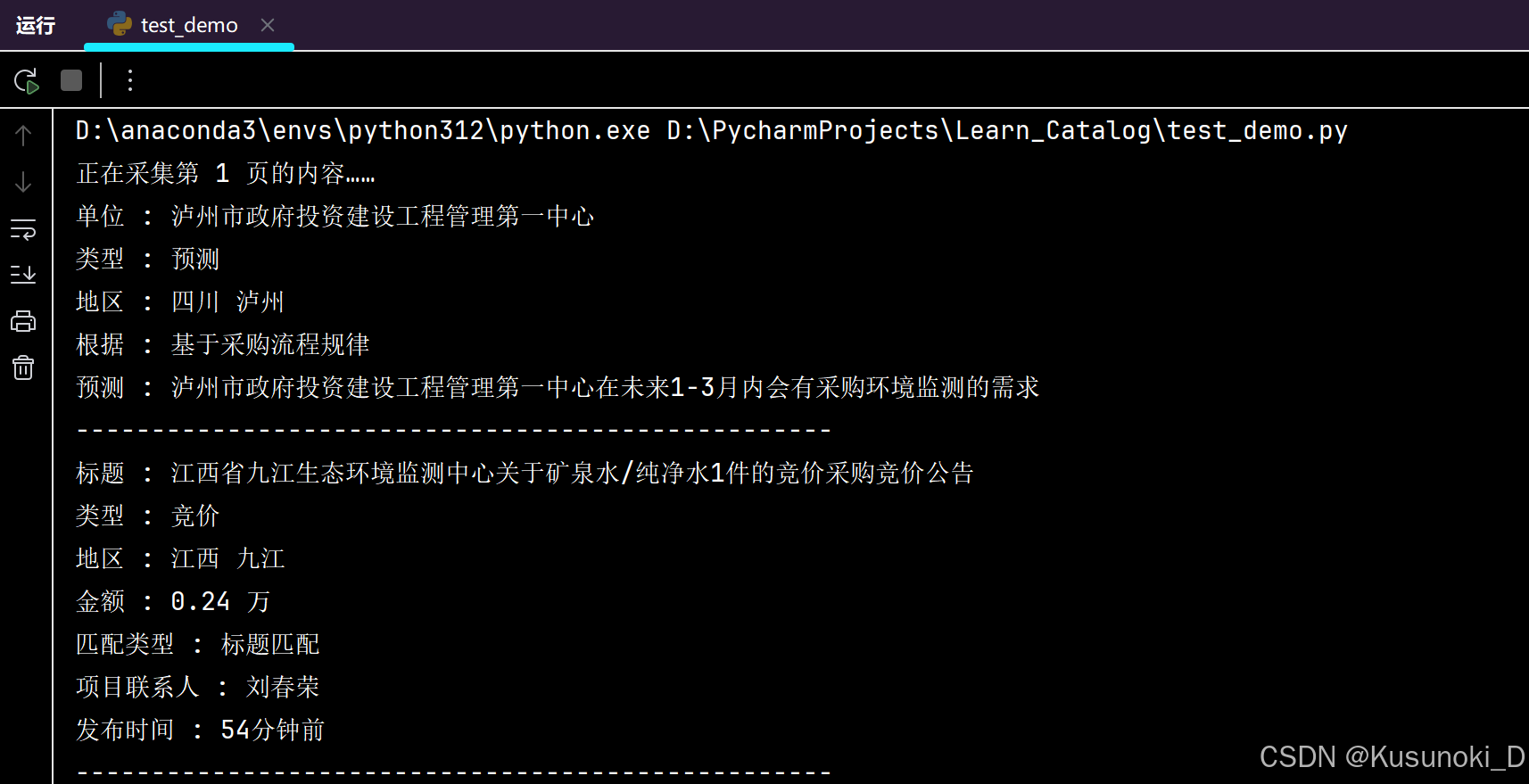
参考:【DrissionPage中处理无位置元素点击问题的解决方案】
五、其他示例
1. 定位信息所在的 div 标签
点击 “元素” ,再点击左上角的那个按钮,然后选择需要定位的信息,其对应的 div 标签会高亮。
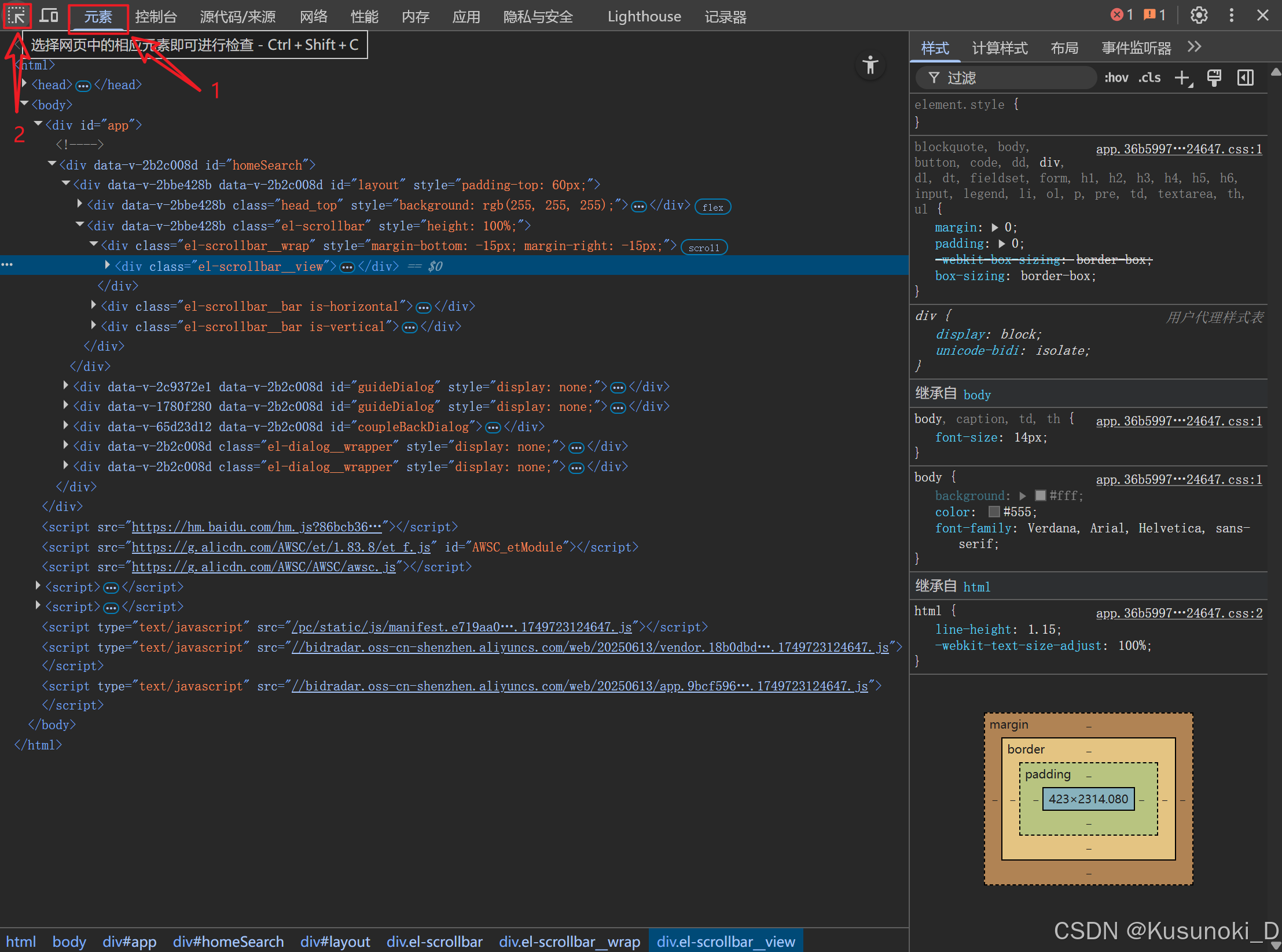
2. css 语法定位 + 点击翻页
参考文档:【页面或元素内查找 | DrissionPage官网】
通过 “元素” 面板,即数据标签 css 语法定位。
# 导入自动化模块
from DrissionPage import ChromiumPage
# 导入序列化模块
import json
# from pprint import pprint
# 导入csv模块
# import csv# 打开浏览器(实例化浏览器对象)
google = ChromiumPage()
# 访问指定网站的页面
google.get(r"https://we.51job.com/pc/search?jobArea=260200&keyword=%E7%88%AC%E8%99%AB&searchType=2&keywordType=")# # 创建文件对象
# f = open('51job.csv', mode='w', encoding='utf-8-sig', newline='')
# # 字典写入方式
# cd = csv.DictWriter(f, fieldnames=['职位名称', '薪资范围', '薪资制度', '所在城市', '所在区域',
# '所需经验', '所需学历', '发布时间', '公司名称', '公司领域',
# '公司性质', '公司规模', '公司详情页'])
# cd.writeheader()# 构建循环翻页
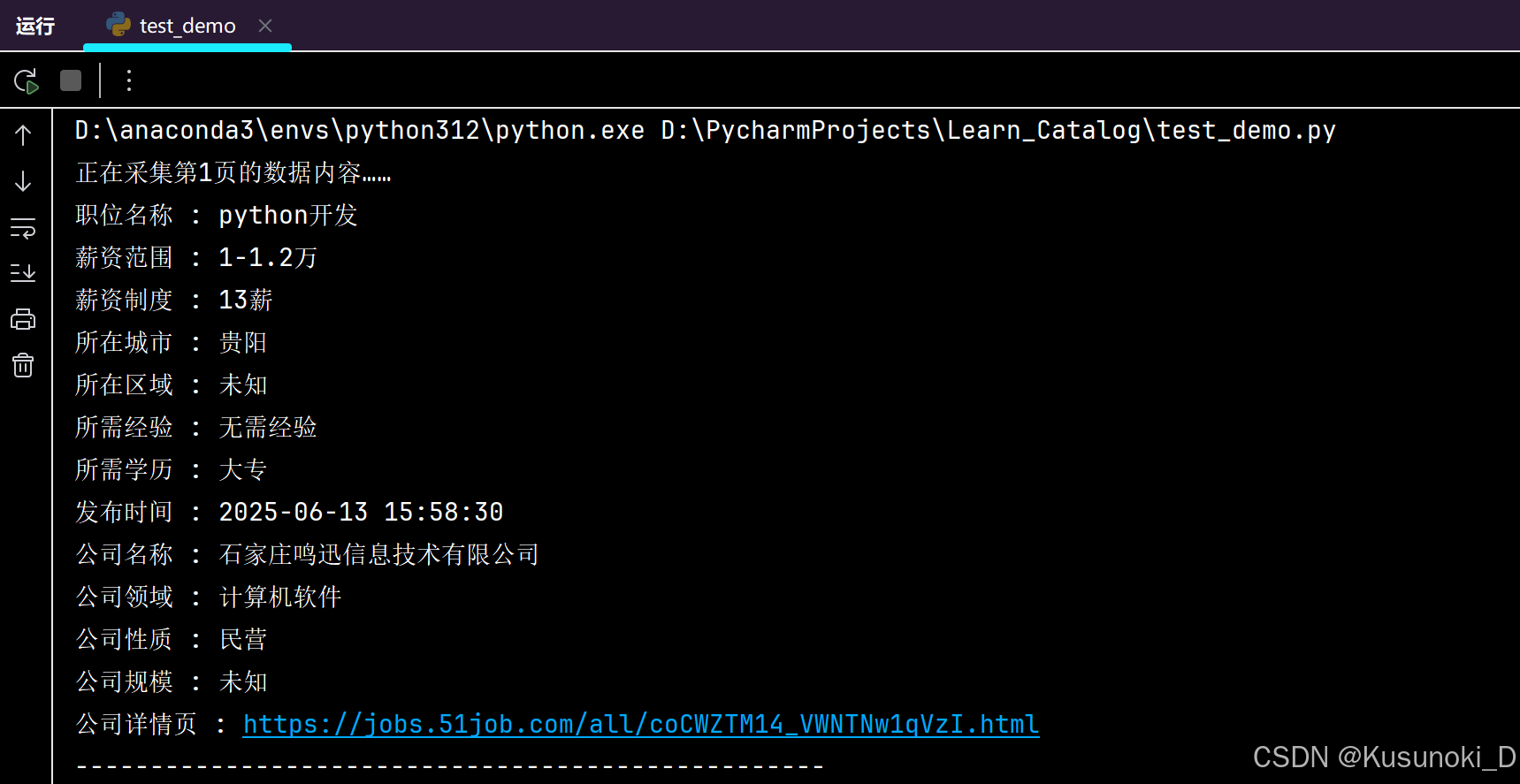
for page in range(1, 5):print(f'正在采集第{page}页的数据内容……')# 提取所有职位信息所在的 div 标签divs = google.eles('css:.joblist-item')# print(divs)# for 循环遍历,提取列表里的元素for div in divs:# 提取具体职位信息,返回一个json字符串info = div.ele('css:.joblist-item-job').attr('sensorsdata')# 将json字符串转换为json字典json_data = json.loads(info)# pprint(json_data)# print('-' * 50)# 提取公司名称并去除两端的空格c_name = div.ele('css:.cname').text.strip()# 公司详情页c_link = div.ele('css:.cname').attr('href')# 提取公司信息c_info = [i.text for i in div.eles('css:.dc')]# 判断是否有公司规模数据if len(c_info) == 3:c_num = c_info[-1]else:c_num = '未知'# 分割城市数据country_list = json_data['jobArea'].split('·')city = country_list[0]if len(country_list) == 2:area = country_list[1]else:area = '未知'# 分割薪资制度salary_list = json_data['jobSalary'].split('·')salary = salary_list[0]if len(salary_list) == 2:salary_system = salary_list[1]else:salary_system = '未知'# 通过键值对取值,提取相关信息,保存到字典中info_dict = {'职位名称': json_data['jobTitle'],'薪资范围': salary,'薪资制度': salary_system,'所在城市': city,'所在区域': area,'所需经验': json_data['jobYear'],'所需学历': json_data['jobDegree'],'发布时间': json_data['jobTime'],'公司名称': c_name,'公司领域': c_info[0],'公司性质': c_info[1],'公司规模': c_num,'公司详情页': c_link}# cd.writerow(info_dict)for k, v in info_dict.items():print(f'{k} : {v}')print('-' * 50)# 滑到页面底部google.scroll.to_bottom()# 定位下一页按钮并点击google.ele('css:.el-icon-arrow-right').click()
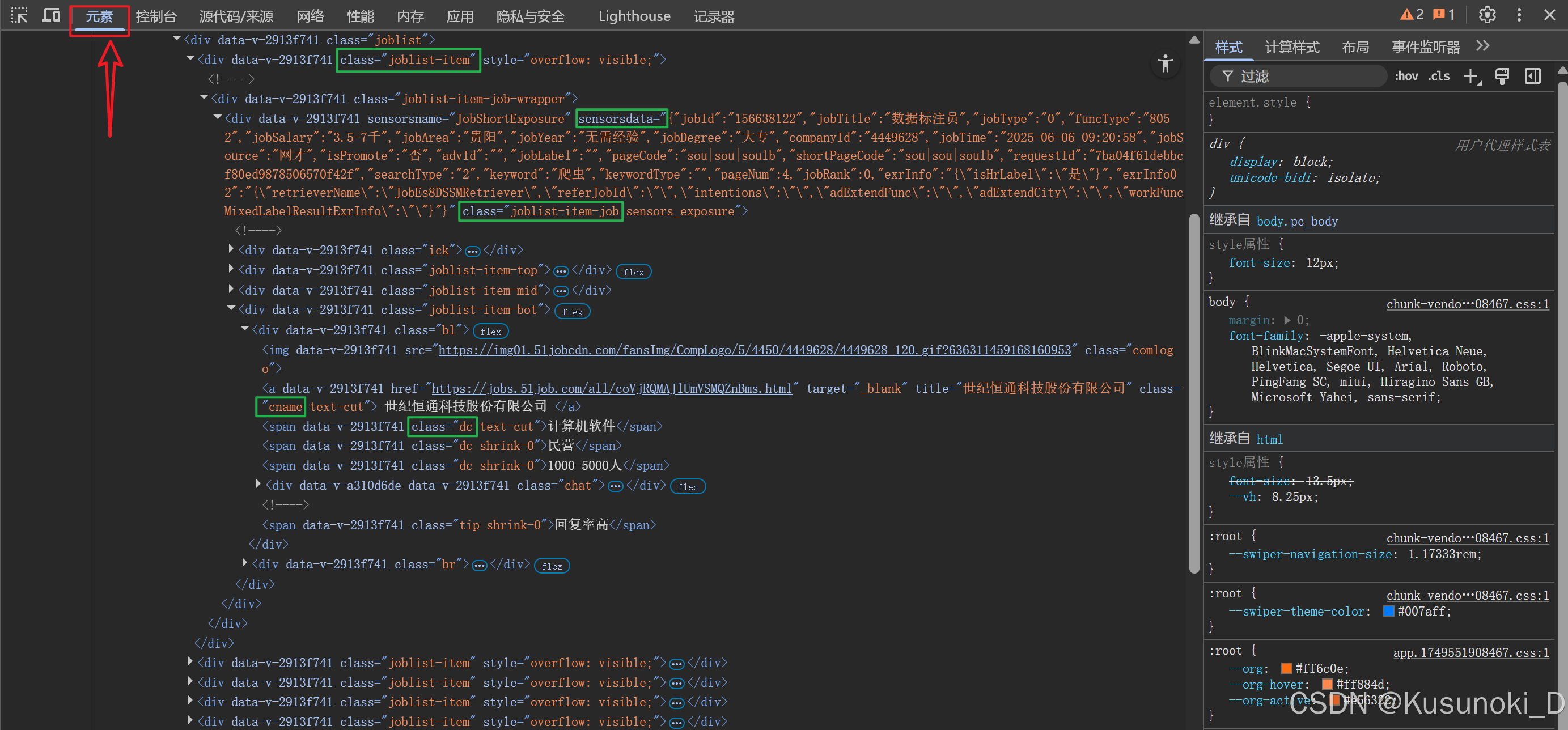
部分结果展示: