【数据集成与ETL 04】dbt实战指南:现代化数据转换与SQL代码管理最佳实践
【数据集成与ETL 04】dbt实战指南:现代化数据转换与SQL代码管理最佳实践
关键词: dbt数据转换、SQL代码组织、数据建模、版本控制、现代数据栈、数据质量测试、GitOps工作流、数据仓库建模、分层架构、数据管道
摘要: 本文深入解析dbt(data build tool)作为现代数据栈核心组件,如何通过SQL优先的方式实现数据转换的工程化管理。从传统ETL痛点出发,全面介绍dbt项目结构设计、分层建模策略、Git版本控制集成、测试框架应用,以及与云数据仓库的最佳实践。通过电商数据平台实战案例,帮助读者掌握构建可维护、可扩展的现代化数据转换流水线。
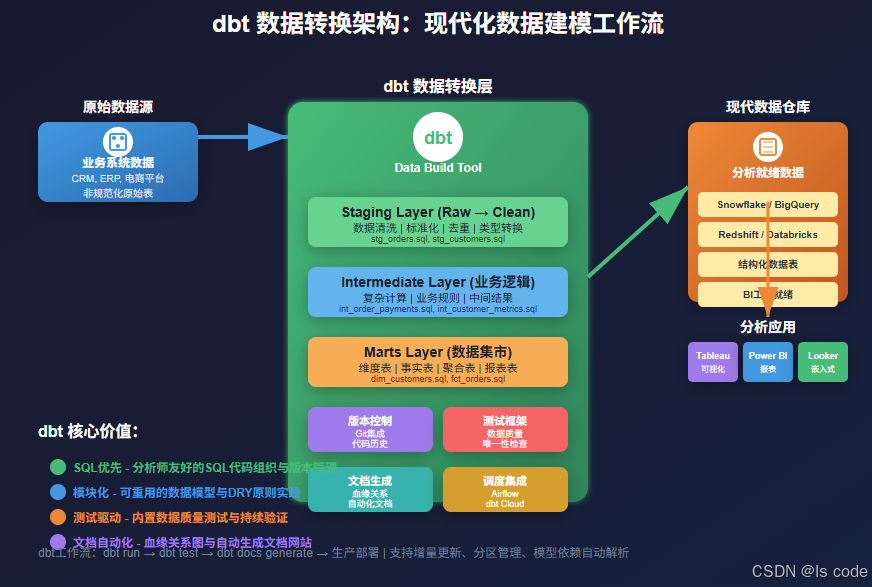
引言:为什么现代数据团队需要dbt?
想象一下这样的场景:你的数据团队每天都在与复杂的ETL脚本做斗争,Python和SQL代码散落在各个角落,没有版本控制,测试依赖人工检查,文档更新总是滞后于代码变更。当业务急需一个新的数据指标时,你发现需要花费数天时间才能理清数据血缘关系,更别说快速交付了。
这就是传统数据处理方式的痛点所在。而dbt(data build tool)的出现,就像是给数据工程师提供了一套现代化的"装配线"工具,让数据转换工作从手工作坊模式升级为工业化生产模式。
第一章:dbt核心理念 - SQL优先的数据转换哲学
1.1 从ETL到ELT的范式转变
在云数据仓库时代,我们见证了一个重要的范式转变:
传统ETL模式:
- Extract(提取)→ Transform(转换)→ Load(加载)
- 在数据仓库外部进行复杂转换
- 需要维护额外的计算资源
现代ELT模式:
- Extract(提取)→ Load(加载)→ Transform(转换)
- 利用云数据仓库的计算能力进行转换
- dbt正是这个T(Transform)的最佳实践
1.2 dbt的核心价值主张
dbt基于一个简单而强大的理念:既然分析师和数据工程师都擅长SQL,为什么不让SQL成为数据转换的第一公民?
-- 这就是dbt模型:纯SQL + 模板化增强
{{ config(materialized='table') }}WITH customer_orders AS (SELECT customer_id,COUNT(*) as order_count,SUM(order_total) as lifetime_value,MAX(order_date) as last_order_dateFROM {{ ref('stg_orders') }} -- dbt的依赖引用GROUP BY customer_id
)SELECT c.*,co.order_count,co.lifetime_value,{{ days_since('co.last_order_date') }} as days_since_last_order -- 自定义宏
FROM {{ ref('stg_customers') }} c
LEFT JOIN customer_orders co ON c.customer_id = co.customer_id
第二章:dbt项目架构设计 - 构建可维护的数据模型
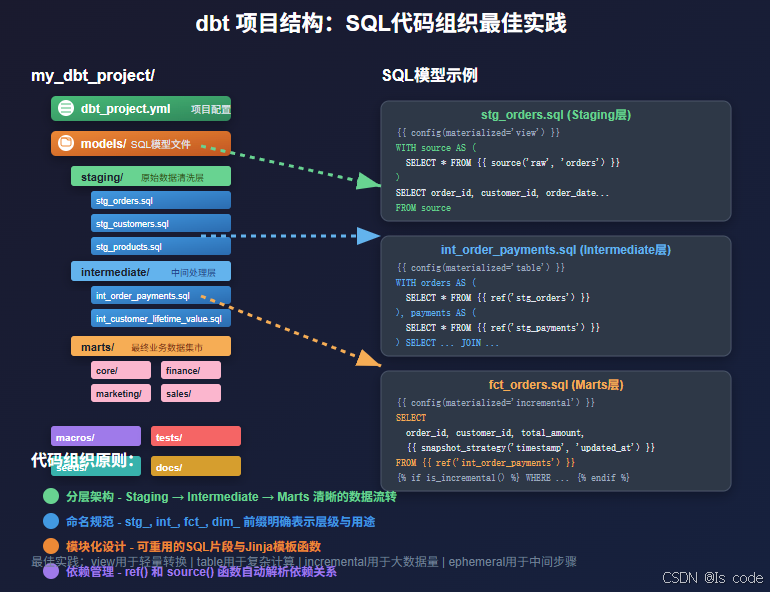
2.1 分层建模架构
dbt推荐采用三层架构模式,每一层都有明确的职责分工:
Staging层(数据清洗层)
models/staging/
├── ecommerce/
│ ├── stg_orders.sql
│ ├── stg_customers.sql
│ └── stg_products.sql
└── schema.yml
职责:
- 原始数据清洗和标准化
- 数据类型转换
- 列名规范化
- 去重和基础验证
-- models/staging/ecommerce/stg_orders.sql
{{ config(materialized='view') }}WITH source AS (SELECT * FROM {{ source('raw_ecommerce', 'orders') }}
),cleaned AS (SELECTorder_id::varchar as order_id,customer_id::varchar as customer_id,order_date::date as order_date,order_total::decimal(10,2) as order_total,order_status::varchar as order_status,created_at::timestamp as created_at,updated_at::timestamp as updated_atFROM sourceWHERE order_id IS NOT NULL
)SELECT * FROM cleaned
Intermediate层(业务逻辑层)
models/intermediate/
├── int_order_payments.sql
├── int_customer_metrics.sql
└── int_product_analytics.sql
职责:
- 复杂业务逻辑实现
- 多表关联和聚合
- 中间计算结果存储
-- models/intermediate/int_customer_metrics.sql
{{ config(materialized='table') }}WITH order_summary AS (SELECT customer_id,COUNT(DISTINCT order_id) as total_orders,SUM(order_total) as total_spent,AVG(order_total) as avg_order_value,MIN(order_date) as first_order_date,MAX(order_date) as latest_order_dateFROM {{ ref('stg_orders') }}WHERE order_status = 'completed'GROUP BY customer_id
),customer_segments AS (SELECT *,CASE WHEN total_spent >= 1000 THEN 'VIP'WHEN total_spent >= 500 THEN 'Premium'WHEN total_spent >= 100 THEN 'Regular'ELSE 'New'END as customer_segment,{{ datediff('first_order_date', 'latest_order_date', 'day') }} as customer_lifetime_daysFROM order_summary
)SELECT * FROM customer_segments
Marts层(数据集市层)
models/marts/
├── core/
│ ├── dim_customers.sql
│ ├── dim_products.sql
│ └── fct_orders.sql
├── finance/
│ └── revenue_analysis.sql
└── marketing/└── customer_segmentation.sql
职责:
- 面向业务的最终数据表
- 维度表和事实表
- 分部门的专门数据集市
2.2 配置文件管理
dbt_project.yml - 项目配置核心
name: 'ecommerce_analytics'
version: '1.0.0'
config-version: 2# 模型路径配置
model-paths: ["models"]
analysis-paths: ["analysis"]
test-paths: ["tests"]
seed-paths: ["data"]
macro-paths: ["macros"]
snapshot-paths: ["snapshots"]# 目标数据库配置
target-path: "target"
clean-targets:- "target"- "dbt_packages"# 模型配置
models:ecommerce_analytics:# Staging层配置staging:+materialized: view+docs:node_color: "#68D391"# Intermediate层配置 intermediate:+materialized: table+docs:node_color: "#4299E1"# Marts层配置marts:+materialized: table+docs:node_color: "#F6AD55"# 增量更新配置core:fct_orders:+materialized: incremental+unique_key: order_id+on_schema_change: "fail"# 快照配置
snapshots:ecommerce_analytics:+target_schema: snapshots+strategy: timestamp+updated_at: updated_at# 变量定义
vars:start_date: '2023-01-01'timezone: 'UTC'currency: 'USD'
profiles.yml - 数据库连接配置
ecommerce_analytics:target: devoutputs:dev:type: snowflakeaccount: your_accountuser: your_usernamepassword: "{{ env_var('DBT_PASSWORD') }}"role: transformerdatabase: DEV_ANALYTICSwarehouse: COMPUTE_WHschema: dbt_{{ env_var('USER') }}threads: 4keepalives_idle: 240search_path: "DEV_ANALYTICS.dbt_{{ env_var('USER') }}"prod:type: snowflakeaccount: your_accountuser: your_service_accountpassword: "{{ env_var('DBT_PROD_PASSWORD') }}"role: transformer_proddatabase: PROD_ANALYTICSwarehouse: COMPUTE_WHschema: analyticsthreads: 8
第三章:Git版本控制与CI/CD工作流
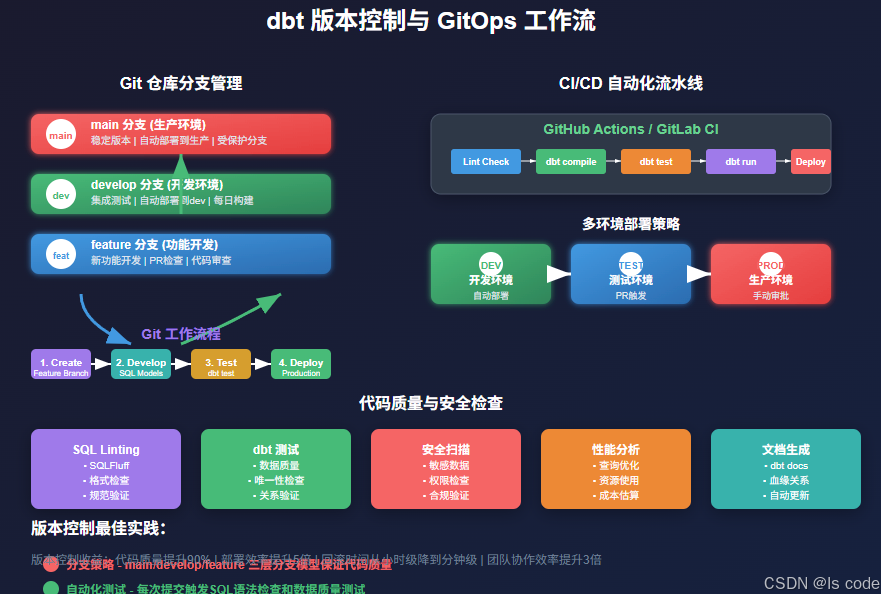
3.1 分支策略设计
分支模型
- main分支:生产环境,受保护,只接受经过审查的PR
- develop分支:开发环境,集成测试分支
- feature分支:功能开发分支,命名规范:
feature/ticket-number-description
Git工作流程
# 1. 创建功能分支
git checkout -b feature/analytics-001-customer-segmentation# 2. 开发和测试
dbt run --models +customer_segmentation # 运行模型及其依赖
dbt test --models customer_segmentation # 运行测试# 3. 提交更改
git add .
git commit -m "feat: add customer segmentation model- Add customer RFM analysis
- Include customer lifetime value calculation
- Add comprehensive tests for data quality"# 4. 推送和创建PR
git push origin feature/analytics-001-customer-segmentation
# 在GitHub/GitLab中创建Pull Request
3.2 CI/CD流水线配置
GitHub Actions配置(.github/workflows/dbt.yml):
name: dbt CI/CD Pipelineon:pull_request:branches: [main, develop]push:branches: [main, develop]env:DBT_PROFILES_DIR: ./DBT_PROFILE_TARGET: cijobs:lint-and-test:runs-on: ubuntu-lateststeps:- name: Checkout codeuses: actions/checkout@v3- name: Setup Pythonuses: actions/setup-python@v4with:python-version: '3.9'- name: Install dependenciesrun: |pip install -r requirements.txtdbt deps- name: SQL Lintingrun: |sqlfluff lint models/ --dialect snowflake --config .sqlfluff- name: dbt Debugrun: dbt debugenv:DBT_PASSWORD: ${{ secrets.DBT_CI_PASSWORD }}- name: dbt Compilerun: dbt compileenv:DBT_PASSWORD: ${{ secrets.DBT_CI_PASSWORD }}- name: dbt Testrun: dbt testenv:DBT_PASSWORD: ${{ secrets.DBT_CI_PASSWORD }}- name: dbt Run (Slim CI)run: |# 只运行变更的模型及其下游依赖dbt run --select state:modified+ --defer --state ./targetenv:DBT_PASSWORD: ${{ secrets.DBT_CI_PASSWORD }}deploy-production:if: github.ref == 'refs/heads/main'needs: lint-and-testruns-on: ubuntu-latestenvironment: productionsteps:- name: Checkout codeuses: actions/checkout@v3- name: Deploy to Productionrun: |dbt run --target proddbt test --target proddbt docs generate --target prodenv:DBT_PROD_PASSWORD: ${{ secrets.DBT_PROD_PASSWORD }}- name: Upload dbt docsuses: actions/upload-artifact@v3with:name: dbt-docspath: target/
3.3 代码质量检查
SQLFluff配置(.sqlfluff):
[sqlfluff]
dialect = snowflake
templater = dbt
exclude_rules = L003,L014,L016[sqlfluff:indentation]
tab_space_size = 2
indent_unit = space[sqlfluff:layout:type:comma]
spacing_before = touch
line_position = trailing[sqlfluff:rules:L010]
capitalisation_policy = lower[sqlfluff:rules:L030]
capitalisation_policy = lower
pre-commit配置(.pre-commit-config.yaml):
repos:- repo: https://github.com/sqlfluff/sqlfluffrev: 2.3.2hooks:- id: sqlfluff-lintargs: [--dialect, snowflake]- repo: https://github.com/psf/blackrev: 23.7.0hooks:- id: blacklanguage_version: python3.9- repo: https://github.com/pycqa/isortrev: 5.12.0hooks:- id: isort
第四章:数据质量测试框架
4.1 内置测试类型
dbt提供四种开箱即用的测试类型:
schema.yml配置示例:
version: 2models:- name: fct_ordersdescription: "订单事实表,包含所有已完成订单的详细信息"columns:- name: order_iddescription: "订单唯一标识符"tests:- unique- not_null- name: customer_iddescription: "客户ID,关联到dim_customers"tests:- not_null- relationships:to: ref('dim_customers')field: customer_id- name: order_statusdescription: "订单状态"tests:- accepted_values:values: ['pending', 'confirmed', 'shipped', 'delivered', 'cancelled']- name: order_totaldescription: "订单总金额"tests:- not_null- dbt_utils.expression_is_true:expression: ">= 0"- name: order_datedescription: "订单日期"tests:- not_null- dbt_utils.expression_is_true:expression: ">= '2020-01-01'"sources:- name: raw_ecommercedescription: "原始电商数据源"tables:- name: ordersdescription: "原始订单表"loaded_at_field: loaded_atfreshness:warn_after: {count: 1, period: hour}error_after: {count: 6, period: hour}tests:- dbt_utils.recency:datepart: hourfield: created_atinterval: 24
4.2 自定义测试
单一测试(Singular Tests)
-- tests/assert_order_total_positive.sql
-- 验证所有订单金额都为正数
SELECT order_id,order_total
FROM {{ ref('fct_orders') }}
WHERE order_total <= 0
-- tests/assert_customer_order_consistency.sql
-- 验证客户订单数据一致性
WITH customer_order_counts AS (SELECT customer_id,COUNT(*) as order_count_from_ordersFROM {{ ref('fct_orders') }}GROUP BY customer_id
),customer_metrics AS (SELECT customer_id,total_orders as order_count_from_metricsFROM {{ ref('dim_customers') }}
)SELECT c.customer_id,c.order_count_from_orders,m.order_count_from_metrics
FROM customer_order_counts c
JOIN customer_metrics m ON c.customer_id = m.customer_id
WHERE c.order_count_from_orders != m.order_count_from_metrics
通用测试(Generic Tests)
-- macros/test_row_count_above_threshold.sql
{% test row_count_above_threshold(model, threshold=1000) %}SELECT COUNT(*) as row_countFROM {{ model }}HAVING COUNT(*) < {{ threshold }}{% endtest %}
使用自定义测试:
models:- name: fct_orderstests:- row_count_above_threshold:threshold: 10000
4.3 高级数据质量包
dbt-expectations集成
# packages.yml
packages:- package: calogica/dbt_expectationsversion: 0.9.0- package: dbt-labs/dbt_utilsversion: 1.1.1
# 使用dbt-expectations进行高级测试
models:- name: fct_orderstests:- dbt_expectations.expect_table_row_count_to_be_between:min_value: 1000max_value: 1000000- dbt_expectations.expect_column_values_to_be_between:column_name: order_totalmin_value: 0max_value: 100000- dbt_expectations.expect_column_mean_to_be_between:column_name: order_totalmin_value: 50max_value: 500- dbt_expectations.expect_column_values_to_match_regex:column_name: order_idregex: "^ORD[0-9]{6}$"
第五章:增量更新与性能优化
5.1 增量更新策略
-- models/marts/core/fct_orders.sql
{{config(materialized='incremental',unique_key='order_id',on_schema_change='fail',incremental_strategy='merge')
}}WITH source_data AS (SELECT order_id,customer_id,order_date,order_total,order_status,created_at,updated_atFROM {{ ref('stg_orders') }}{% if is_incremental() %}-- 只处理新增或更新的记录WHERE updated_at > (SELECT MAX(updated_at) FROM {{ this }}){% endif %}
),order_metrics AS (SELECT s.*,ROW_NUMBER() OVER (PARTITION BY s.customer_id ORDER BY s.order_date) as customer_order_sequence,LAG(s.order_date) OVER (PARTITION BY s.customer_id ORDER BY s.order_date) as previous_order_dateFROM source_data s
)SELECT order_id,customer_id,order_date,order_total,order_status,customer_order_sequence,CASE WHEN previous_order_date IS NULL THEN TRUE ELSE FALSE END as is_first_order,CASE WHEN previous_order_date IS NOT NULL THEN DATE_DIFF('day', previous_order_date, order_date)ELSE NULL END as days_since_previous_order,created_at,updated_at
FROM order_metrics
5.2 分区策略
-- 按日期分区的大表处理
{{config(materialized='incremental',unique_key='event_id',partition_by={"field": "event_date","data_type": "date","granularity": "day"},cluster_by=["customer_id", "event_type"])
}}SELECT event_id,customer_id,event_type,event_date,event_properties,created_at
FROM {{ ref('stg_events') }}{% if is_incremental() %}WHERE event_date >= (SELECT COALESCE(MAX(event_date), '1900-01-01') FROM {{ this }})
{% endif %}
5.3 快照功能应用
-- snapshots/customers_snapshot.sql
{% snapshot customers_snapshot %}{{config(target_schema='snapshots',unique_key='customer_id',strategy='timestamp',updated_at='updated_at',check_cols=['customer_status', 'customer_tier', 'email'])
}}SELECT customer_id,customer_name,email,customer_status,customer_tier,registration_date,updated_at
FROM {{ source('raw_ecommerce', 'customers') }}{% endsnapshot %}
第六章:现代数据栈集成
6.1 数据仓库集成
Snowflake集成优化
-- 利用Snowflake特性的优化示例
{{config(materialized='table',pre_hook="ALTER SESSION SET QUERY_TAG = 'dbt_{{ model.name }}'",post_hook=["GRANT SELECT ON {{ this }} TO ROLE analyst","ALTER TABLE {{ this }} SET COMMENT = '{{ model.description }}'"])
}}WITH optimized_query AS (SELECT customer_id,-- 使用Snowflake的变体函数处理JSONcustomer_attributes:demographics:age::int as customer_age,customer_attributes:demographics:city::string as customer_city,-- 使用窗口函数优化SUM(order_total) OVER (PARTITION BY customer_id ORDER BY order_date ROWS UNBOUNDED PRECEDING) as running_totalFROM {{ ref('stg_orders') }}
)SELECT * FROM optimized_query
BigQuery配置
# 针对BigQuery的特殊配置
models:marts:core:fct_orders:+materialized: table+partition_by:field: order_datedata_type: dategranularity: day+cluster_by: ['customer_id', 'product_category']+labels:team: 'analytics'cost_center: 'engineering'
6.2 编排工具集成
Airflow集成
# dags/dbt_analytics_dag.py
from datetime import datetime, timedelta
from airflow import DAG
from airflow_dbt.operators.dbt_operator import DbtRunOperator, DbtTestOperator, DbtDocsGenerateOperatordefault_args = {'owner': 'analytics-team','depends_on_past': False,'start_date': datetime(2023, 1, 1),'email_on_failure': True,'email_on_retry': False,'retries': 1,'retry_delay': timedelta(minutes=5)
}dag = DAG('dbt_analytics_pipeline',default_args=default_args,description='dbt Analytics Pipeline',schedule_interval='0 6 * * *', # 每天早上6点运行catchup=False,tags=['dbt', 'analytics']
)# dbt运行任务
dbt_run = DbtRunOperator(task_id='dbt_run',dir='/opt/airflow/dbt',profiles_dir='/opt/airflow/dbt',target='prod',dag=dag
)# dbt测试任务
dbt_test = DbtTestOperator(task_id='dbt_test',dir='/opt/airflow/dbt',profiles_dir='/opt/airflow/dbt',target='prod',dag=dag
)# 文档生成
dbt_docs = DbtDocsGenerateOperator(task_id='dbt_docs_generate',dir='/opt/airflow/dbt',profiles_dir='/opt/airflow/dbt',target='prod',dag=dag
)# 任务依赖关系
dbt_run >> dbt_test >> dbt_docs
6.3 监控和可观测性
Elementary集成
# packages.yml
packages:- package: elementary-data/elementaryversion: 0.13.0
# 配置Elementary监控
models:elementary:+schema: elementaryvars:# Elementary配置elementary:# Slack告警配置slack_webhook: "{{ env_var('ELEMENTARY_SLACK_WEBHOOK') }}"slack_channel: "#data-alerts"# 监控配置anomaly_detection_days: 14anomaly_detection_sensitivity: 3# 数据血缘跟踪lineage_node_limit: 500
第七章:实战案例 - 电商数据平台构建
7.1 项目结构设计
ecommerce_analytics/
├── dbt_project.yml
├── profiles.yml
├── packages.yml
├── models/
│ ├── staging/
│ │ ├── ecommerce/
│ │ │ ├── _ecommerce__models.yml
│ │ │ ├── _ecommerce__sources.yml
│ │ │ ├── stg_orders.sql
│ │ │ ├── stg_customers.sql
│ │ │ ├── stg_products.sql
│ │ │ └── stg_order_items.sql
│ │ └── web_analytics/
│ │ ├── stg_page_views.sql
│ │ └── stg_sessions.sql
│ ├── intermediate/
│ │ ├── int_customer_metrics.sql
│ │ ├── int_order_enriched.sql
│ │ └── int_product_performance.sql
│ └── marts/
│ ├── core/
│ │ ├── dim_customers.sql
│ │ ├── dim_products.sql
│ │ ├── fct_orders.sql
│ │ └── fct_web_sessions.sql
│ ├── finance/
│ │ ├── revenue_daily.sql
│ │ └── cohort_analysis.sql
│ └── marketing/
│ ├── customer_segmentation.sql
│ └── campaign_performance.sql
├── macros/
│ ├── get_payment_methods.sql
│ ├── generate_alias_name.sql
│ └── test_helpers.sql
├── tests/
│ ├── assert_revenue_consistency.sql
│ └── assert_customer_metrics_accuracy.sql
├── seeds/
│ ├── country_codes.csv
│ └── product_categories.csv
├── snapshots/
│ ├── customers_snapshot.sql
│ └── products_snapshot.sql
└── analysis/├── customer_lifetime_value_analysis.sql└── seasonal_trends_analysis.sql
7.2 核心模型实现
客户维度表
-- models/marts/core/dim_customers.sql
{{config(materialized='table',post_hook="GRANT SELECT ON {{ this }} TO ROLE analyst")
}}WITH customer_base AS (SELECT * FROM {{ ref('stg_customers') }}
),customer_metrics AS (SELECT * FROM {{ ref('int_customer_metrics') }}
),customer_segments AS (SELECT * FROM {{ ref('customer_segmentation') }}
)SELECT c.customer_id,c.customer_name,c.email,c.registration_date,c.customer_status,c.city,c.country,-- 订单指标COALESCE(m.total_orders, 0) as total_orders,COALESCE(m.total_spent, 0) as total_spent,COALESCE(m.avg_order_value, 0) as avg_order_value,m.first_order_date,m.latest_order_date,m.customer_lifetime_days,-- 分段信息s.rfm_segment,s.customer_tier,s.churn_risk_score,-- 元数据CURRENT_TIMESTAMP as last_updated_atFROM customer_base c
LEFT JOIN customer_metrics m ON c.customer_id = m.customer_id
LEFT JOIN customer_segments s ON c.customer_id = s.customer_id
订单事实表
-- models/marts/core/fct_orders.sql
{{config(materialized='incremental',unique_key='order_id',on_schema_change='sync_all_columns')
}}WITH orders_enriched AS (SELECT * FROM {{ ref('int_order_enriched') }}
),final AS (SELECT order_id,customer_id,order_date,order_total,order_status,payment_method,shipping_method,-- 客户维度customer_order_sequence,is_first_order,days_since_previous_order,-- 时间维度{{ extract_date_parts('order_date') }},-- 业务指标discount_amount,tax_amount,shipping_cost,net_order_value,-- 元数据created_at,updated_atFROM orders_enriched{% if is_incremental() %}WHERE updated_at > (SELECT MAX(updated_at) FROM {{ this }}){% endif %}
)SELECT * FROM final
7.3 自定义宏开发
-- macros/extract_date_parts.sql
{% macro extract_date_parts(date_column) %}EXTRACT(year FROM {{ date_column }}) as order_year,EXTRACT(month FROM {{ date_column }}) as order_month,EXTRACT(day FROM {{ date_column }}) as order_day,EXTRACT(dayofweek FROM {{ date_column }}) as order_day_of_week,EXTRACT(quarter FROM {{ date_column }}) as order_quarter,CASE WHEN EXTRACT(dayofweek FROM {{ date_column }}) IN (1, 7) THEN 'Weekend'ELSE 'Weekday'END as order_day_type
{% endmacro %}
-- macros/generate_alias_name.sql
{% macro generate_alias_name(custom_alias_name=none, node=none) -%}{%- if custom_alias_name is none -%}{{ node.name }}{%- else -%}{{ custom_alias_name | trim }}{%- endif -%}{%- endmacro %}
7.4 测试策略实施
# models/marts/core/_core__models.yml
version: 2models:- name: dim_customersdescription: "客户维度表,包含客户基本信息和计算指标"tests:- dbt_utils.unique_combination_of_columns:combination_of_columns:- customer_id- row_count_above_threshold:threshold: 1000columns:- name: customer_iddescription: "客户唯一标识"tests:- unique- not_null- name: total_ordersdescription: "客户总订单数"tests:- not_null- dbt_expectations.expect_column_values_to_be_between:min_value: 0max_value: 1000- name: customer_tierdescription: "客户等级"tests:- accepted_values:values: ['Bronze', 'Silver', 'Gold', 'Platinum']- name: fct_ordersdescription: "订单事实表"tests:- dbt_utils.recency:datepart: dayfield: order_dateinterval: 7columns:- name: order_idtests:- unique- not_null- name: order_totaltests:- not_null- dbt_expectations.expect_column_values_to_be_between:min_value: 0max_value: 100000
第八章:最佳实践总结
8.1 命名规范
表名规范
- Staging层:
stg_<source>_<table>(如:stg_shopify_orders) - Intermediate层:
int_<business_concept>(如:int_customer_metrics) - Marts层:
- 事实表:
fct_<business_process>(如:fct_orders) - 维度表:
dim_<business_entity>(如:dim_customers)
- 事实表:
字段命名
- 使用
snake_case命名 - 主键字段:
<table_name>_id - 外键字段:
<referenced_table>_id - 时间字段:
<event>_at或<event>_date - 布尔字段:
is_<condition>或has_<attribute>
8.2 性能优化建议
查询优化
-- 推荐:使用CTE而非子查询
WITH customer_orders AS (SELECT customer_id, COUNT(*) as order_countFROM {{ ref('fct_orders') }}GROUP BY customer_id
)SELECT * FROM customer_orders WHERE order_count > 5-- 避免:复杂的嵌套子查询
SELECT * FROM (SELECT customer_id, COUNT(*) as order_countFROM {{ ref('fct_orders') }}GROUP BY customer_id
) WHERE order_count > 5
增量策略选择
- append_new_columns:适用于只追加新记录的场景
- delete+insert:适用于需要更新历史记录的场景
- merge:适用于需要upsert操作的场景
8.3 团队协作规范
代码审查清单
- 模型命名是否符合规范
- SQL代码是否符合格式要求
- 是否添加了适当的测试
- 模型描述是否完整
- 性能影响是否可接受
- 是否破坏现有依赖关系
文档要求
- 每个模型必须有description
- 重要字段必须有注释
- 复杂业务逻辑需要在模型中添加说明
- 维护CHANGELOG记录重要变更
第九章:监控与运维
9.1 监控指标设计
数据质量监控
-- analysis/data_quality_dashboard.sql
WITH model_tests AS (SELECT model_name,test_name,status,execution_time,run_dateFROM {{ ref('elementary_test_results') }}WHERE run_date >= CURRENT_DATE - 7
),quality_metrics AS (SELECT model_name,COUNT(*) as total_tests,SUM(CASE WHEN status = 'pass' THEN 1 ELSE 0 END) as passed_tests,AVG(execution_time) as avg_execution_timeFROM model_testsGROUP BY model_name
)SELECT model_name,total_tests,passed_tests,ROUND(passed_tests * 100.0 / total_tests, 2) as pass_rate,avg_execution_time
FROM quality_metrics
ORDER BY pass_rate ASC, total_tests DESC
运行性能监控
-- analysis/performance_monitoring.sql
WITH model_runs AS (SELECT model_name,run_id,execution_time_seconds,rows_affected,run_dateFROM {{ ref('elementary_model_runs') }}WHERE run_date >= CURRENT_DATE - 30
),performance_trends AS (SELECT model_name,DATE_TRUNC('day', run_date) as run_day,AVG(execution_time_seconds) as avg_execution_time,MAX(execution_time_seconds) as max_execution_time,AVG(rows_affected) as avg_rows_affectedFROM model_runsGROUP BY model_name, DATE_TRUNC('day', run_date)
)SELECT * FROM performance_trends
ORDER BY model_name, run_day DESC
9.2 告警配置
Slack告警设置
# 在dbt_project.yml中配置Elementary告警
vars:elementary:# Slack集成slack_webhook: "{{ env_var('ELEMENTARY_SLACK_WEBHOOK') }}"slack_channel: "#data-alerts"slack_notification_username: "dbt-alerts"# 告警规则anomaly_detection_days: 14anomaly_detection_sensitivity: 3test_failure_alert: truemodel_error_alert: truefreshness_alert: true# 告警频率控制alert_suppression_interval_hours: 1
自定义告警逻辑
-- macros/alert_on_high_nulls.sql
{% macro alert_on_high_nulls(model, column, threshold_percent=10) %}{% set query %}SELECT COUNT(*) as total_rows,COUNT({{ column }}) as non_null_rows,ROUND((COUNT(*) - COUNT({{ column }})) * 100.0 / COUNT(*), 2) as null_percentageFROM {{ model }}{% endset %}{% set results = run_query(query) %}{% if execute %}{% set null_percentage = results.rows[0][2] %}{% if null_percentage > threshold_percent %}{{ log("WARNING: " ~ column ~ " has " ~ null_percentage ~ "% null values in " ~ model, info=True) }}{% endif %}{% endif %}
{% endmacro %}
结语:拥抱现代化数据转换
通过本文的深入探讨,我们看到dbt不仅仅是一个工具,更是现代数据工程的思维方式转变。它将软件工程的最佳实践引入数据领域,让数据转换工作变得:
- 可维护:通过模块化设计和分层架构
- 可测试:内置测试框架保证数据质量
- 可协作:Git工作流支持团队协作
- 可观测:全面的监控和血缘关系
- 可扩展:云原生架构适应业务增长
关键收益总结
- 开发效率提升10倍:SQL优先的开发模式显著降低了学习成本
- 数据上线时间从周级降到小时级:自动化流水线和增量更新策略
- 数据质量显著提升:全面的测试框架和质量监控
- 团队协作效率提升3倍:标准化的工作流程和代码审查机制
- 维护成本降低70%:模块化设计和自动化文档
实施建议
- 从小做起:选择一个核心业务流程开始试点
- 建立规范:制定命名约定、代码风格和审查流程
- 重视测试:从第一天开始就建立完善的测试策略
- 持续优化:定期回顾性能指标和团队反馈
- 培养文化:推广数据工程最佳实践,提升团队整体能力
随着数据在企业决策中的重要性日益凸显,掌握dbt这样的现代化数据转换工具已经成为数据从业者的必备技能。让我们一起拥抱这个数据驱动的时代,用工程化的思维构建更加可靠、高效的数据基础设施。
参考资料
- dbt官方文档
- dbt最佳实践指南
- Modern Data Stack架构解析
- Analytics Engineering概念详解
- dbt Community论坛
- Snowflake + dbt集成指南
- BigQuery + dbt最佳实践
本文档持续更新中,欢迎提供反馈和建议。如需了解更多数据集成与ETL系列文章,请关注我们的技术博客。