【大模型分布式训练】多卡解决单卡训练内存不足的问题
本文将介绍如何在单机多卡环境下,使用 Hugging Face Accelerate 和 DeepSpeed ZeRO-2 实现 大模型 的 LoRA 高效微调。文章涵盖环境安装、accelerate config 交互式配置、DeepSpeed JSON 配置详解、训练命令示例及实战建议,帮助你在两块 GPU 上顺利启动分布式训练。
一、背景介绍
在大模型微调场景中,单卡显存常常成为瓶颈。DeepSpeed 的 ZeRO 技术通过分片优化器状态、梯度(Stage 2)或参数(Stage 3),将显存压力近似降至 1/N 。
Hugging Face Accelerate 提供一键式多进程启动方案,无需改动训练代码,即可与 DeepSpeed 联动,自动处理 NCCL、混合精度和分布式环境变量 。
ps: 我们这里使用这个 deepseep的目的主要是:因为模型太大了,单卡不能用,如果你是单卡都能训练,只是为了多卡并行加速,最小修改代码,可以使用下面的代码(缺点:高通信)
import torch.nn as nn
# 11. 将模型移动到指定设备(GPU/CPU)
model = model.to(pc.device)
# 11a. 多卡并行
model = nn.DataParallel(model)
# 打印可训练参数信息(兼容 DataParallel)
real_model = model.module if isinstance(model, nn.DataParallel) else model
print('模型训练参数:', real_model.print_trainable_parameters())
best_dir = os.path.join(pc.save_dir, "model_best")
# 保存时取底层 module
#real_model = model.module if isinstance(model, nn.DataParallel) else model
save_model(real_model, cur_save_dir)
tokenizer.save_pretrained(cur_save_dir)
print(f"Best model has saved at {best_dir}.")二、环境准备
-
安装依赖
pip install deepspeed>=0.14 accelerate peft transformers==4.41.0-
以上命令会同时安装 DeepSpeed、Accelerate 及微调所需的 PEFT 与 Transformers 库 。
-
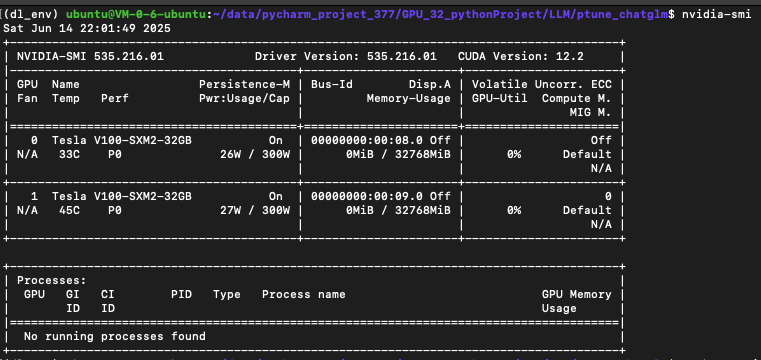
确认 GPU 信息
执行 nvidia-smi 可查看到两块 V100 32 GB GPU,为分布式训练做好硬件准备。
![]()
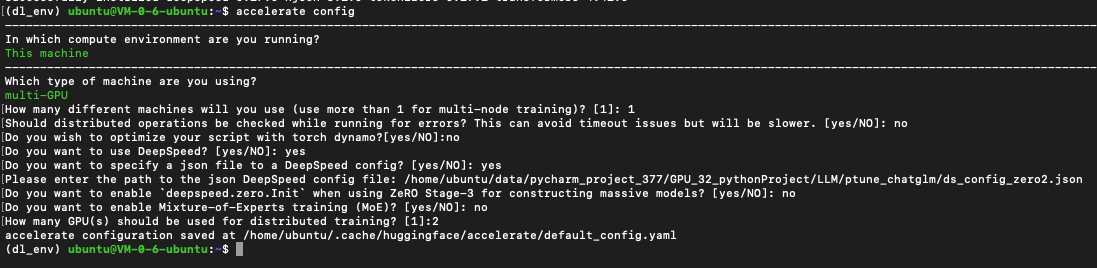
三、Accelerate 交互式配置
在项目根目录或任意终端执行:
accelerate config依次回答如下:
-
Compute environment:This machine
-
Machine type:multi-GPU
-
Number of machines:1
-
Use DeepSpeed:yes
-
Deepspeed JSON path:/home/ubuntu/.../ds_config_zero2.json
-
ZeRO Stage-3 Init:no
-
Enable MoE:no
-
GPU 数量:2 (几个卡写几)
最终会在 ~/.cache/huggingface/accelerate/default_config.yaml 生成默认配置文件,Accelerate 启动时即自动加载 。
⚠️注意:这里显示的是你的json配置文件的路径!(DeepSpeed JSON内容见下文)
四、DeepSpeed JSON 配置详解
将下面内容保存为项目根目录下的 ds_config_zero2.json:
{"train_batch_size": 4,"gradient_accumulation_steps": 4,"optimizer": { "type": "AdamW", "params": { "lr": 2e-5 } },"zero_optimization": {"stage": 2,"contiguous_gradients": true,"overlap_comm": true,"reduce_scatter": true,"allgather_partitions": true,"offload_optimizer": { "device": "none" },"prefetch_bucket_size": 2e8,"param_persistence_threshold": 1e6},"bf16": { "enabled": true },"gradient_clipping": 1.0
}-
train_batch_size:全局批量大小,等效微批×累积步×GPU 数
-
gradient_accumulation_steps:梯度累积步数,显存受限时常用技巧
-
zero_optimization.stage=2:仅分片优化器状态和梯度,代码无侵入式改动
-
contiguous_gradients/overlap_comm/reduce_scatter/allgather_partitions:各类通信与缓冲区优化选项,提升多卡效率并减少显存碎片
-
bf16.enabled:启用 bfloat16 混合精度,适用于 V100/H100 架构
-
gradient_clipping:防止梯度爆炸,保证训练稳定性
五、启动训练
在项目根目录执行:
train.py 是你自己的训练脚本
accelerate launch train.pyAccelerate 会根据 default_config.yaml 生成等同于 torchrun --nproc_per_node=2 的命令,并自动加载 DeepSpeed 配置,启动多卡训练流程 。
六、实战建议
-
ChatGLM-3/6B LoRA:保持以上 Stage 2 配置,无需 MoE 支持 。
-
DeepSeekMoE 系列:若后续微调带 MoE 的 DeepSeek 模型(如 DeepSeekMoE 16B/671B),请单独准备 ds_config_moe.json,在其中添加 "moe": {"enabled": true},并在代码中集成 DeepSpeed-MoE Expert 层,以激活专家并行与稀疏路由 。
-
多配置切换:可用
accelerate launch --config_file ds_config_moe.json train_deepseek.py-
覆盖默认 DeepSpeed JSON,实现 ChatGLM 与 DeepSeek 两种场景的无缝切换。
通过以上步骤,你即可在多块 GPU 上完成单卡显存不够的问题,借助 Accelerate + DeepSpeed ZeRO-2,高效完成大规模 LoRA 微调与分布式训练。祝你训练顺利!
——————————
后计:如果模型特别大的情况下,一般是用的 ZeRO-3 进行分片,通常是大公司采用的规模,我们这里ZeRO-2 就够用了,配置的时候,用几个卡,如实填写就好了。