CLONE——面向长时任务的闭环全身遥操:其MoE架构可实现“蹲着走”,且通过LiDAR里程计和VR跟踪技术解决位置偏差问题
前言
我司长沙具身团队 经过过去一两个月的疯狂招人——未来一两月还在不断扩招(如有意加入我司 共同推动中国具身的落地与发展,则敬请私我),目前长沙侧已十几人
为了历练新同事们,我给所有的新同事们分为了三个项目组(长沙及各地原有的老同事们 则继续之前的客户订单项目)
- 第一组 通过RL(uc伯克利hil-serl) 实现电源插拔
- 第二组 通过lerobot act/pi0,和VLA openpi 实现USB插拔
- 第三组 在弄人形,这两天搞的过程中 发现缺一些设备,所以下周到位后 正式开搞G1 edu版
以上的前两个组偏机械臂,大伙每天都在全力加速前进,而人形测 我则继续做更多的技术探索、积累、铺垫——更何况,目前我司今年上半年接到的最难的一个订单便是长达十几个工序的超长任务(会做到今25年年底),故对CLONE这种长时任务目标下的全身摇操自然是高度关注了
如此,过程中,关注到了CLONE这个工作,故本文来解读之
第一部分 CLONE——面向长时任务的闭环全身仿人遥操作
1.1 CLONE的提出背景与相关工作
1.1.1 提出背景
如CLONE原论文所说,近年来,人形机器人远程操作与行走操控领域取得了显著进展[13–20]
然而,现有方法在长时间精确远程操作方面仍然存在困难,并且缺乏实现人形机器人与场景交互所需的全身协调能力。要弥合这一能力差距,仍有两项根本性挑战亟需解决
- 第一个挑战在于实现协调的全身动作。许多系统为了稳定性,将上半身和下半身的控制解耦 [18,21],但这种做法牺牲了实现流畅动作所需的自然协同。尽管这种分离能带来安全性,但却从根本上限制了诸如行走中伸手或操作过程中调整姿态等一体化动作的实现
另一些依赖动作捕捉数据的方法 [13,15,19,22–27],通常过于强调稳定性,牺牲了动作的表现力,导致所生成的动作受限于训练数据分布,显得保守
此外,这些方法普遍忽视了诸如手部朝向等对灵巧任务至关重要的关键因素,进一步限制了人形机器人实现复杂全身动作的潜力 - 第二个挑战是,由于缺乏关于机器人在环境中实际位置的实时反馈,随着时间推移会出现累积的位姿漂移。与具有简单里程计的轮式机器人不同,人形机器人在足部与地面之间存在复杂的交互,并且具有非完整性动力学特性,这使得状态估计变得更加困难
如果没有闭环校正,微小的姿态误差会在每一步中累积,逐步削弱操作员的空间感知和控制能力,最终导致任务彻底失败
在需要相对于环境物体进行精确定位的操作任务中,这种漂移尤为严重
为此,25年6月,来自北理工、智源研究院、北大等单位的研究者们提出了CLONE

- 其对应的paper为:CLONE: Closed-Loop Whole-Body Humanoid Teleoperation for Long-Horizon Tasks
作者包括:Yixuan Li∗,1,2、Yutang Lin∗,3,4,5,6、Jieming Cui 2,3,4,6
Tengyu Liu 2,7、Wei Liang,1、Yixin Zhu,3,4,6,8、Siyuan Huang,2,7 - 其对应的项目地址为:humanoid-clone.github.io
这是一种新颖的基于专家混合MoE的闭环遥操作系统,通过三项关键技术创新,在长轨迹上实现全身协调且位置漂移极小
- 模型架构:他们开发了一个MoE框架,实现了多样化运动技能的统一学习,同时保持了自然的上下半身协调
- 系统集成:他们融合了激光雷达LiDAR里程计[12],与Apple Vision Pro跟踪技术(该AR进行头部和手部跟踪),实现了闭环误差校正,从而持续提供全局姿态反馈并防止位置漂移的累积
- 数据整理:他们构建了一个综合性数据集CLONED,在AMASS[29]基础上补充了额外的动作捕捉序列和在线手部朝向生成方法,确保了对涉及全身协调运动的复杂操作场景的强泛化能力
1.1.2 相关工作
第一,全身仿人远程操作
- 仿人远程操作使机器人能够通过
动作捕捉系统
24-Exbody2
17-icub3 avatar system: Enabling remote fully immersive embodiment of humanoid robots
30-Whole-body geometric retargeting for humanoid robots
触觉设备
31-Humanoid robot teleoperation with vibrotactile based balancing feedback
32-Learning of compliant human–robot interaction using full-body haptic interface
33-Dynamic locomotion synchronization of bipedal robot and human operator via bilateral feedback teleoperation
或虚拟现实界面
15-Hover: Versatile neural whole-body controller for humanoid robots
19-Omnih2o
34-Humanoid loco-manipulation of pushed carts utilizing virtual reality teleoperation
35-A multimode teleoperation framework for humanoid loco-manipulation: An application for the icub robot
36-Telesar vi: Telexistence surrogate anthropomorphic robot vi
以复制人类动作以完成复杂任务
主要挑战在于开发能够平衡机器人稳定性与动作跟踪精度的全身控制策略whole-body con-trol policies
在机器人学文献中,整体身体控制(Whole-Body Control, WBC)[37–39] 传统上被表述为一个优化问题 [3,40],通过分层控制目标来协调多个相互竞争的任务(如平衡与到达)
近期,基于学习的方法 [13,19,24] 将这一概念扩展为强化学习问题中的整体身体控制。他们将他们的方法称为整体身体控制策略,因为它同样以统一的方式协调人形机器人所有自由度
然目前的方法难以再现人类动作的多样性与流畅性[41-Teleoperation methods and enhancement techniques for mobile robots: A comprehensive survey]
其根本原因在于基于单一MLP的架构无法充分处理不同动作类型(如行走与下蹲)之间的冲突目标
42-Moe-loco: Mixture of experts for multitask locomotion
43-On the convergence of stochastic multi-objective gradient manipulation and beyond
44-Teleoperation of humanoid robots: A survey - 虽然混合模型在其他领域已展现出潜力
45-Multi-expert learning of adaptive legged locomotion
46-Learning soccer juggling skills with layer-wise mixture-of-experts
47-Germ: A generalist robotic model with mixture-of-experts for quadruped robot
48-Multi-task reinforcement learning with attentionbased mixture of experts
但在仿人远程操作中的应用仍有待深入探索
为了解决这些局限,作者采用MoE框架,实现对多样化动作模式的自适应学习与统一表示,从而集成于单一策略中
第二,长时域本体操作任务
- 该类任务的执行[49-Integrated task and motion planning]已在
固定基座机械臂
50-Mimicplay
51-Hierarchical human-to-robot imitation learning for long-horizon tasks via cross-domain skill alignment
52-Robocook: Long-horizon elasto-plastic object manipulation with diverse tools
53-Tac-man: Tactile-informed prior-free manipulation of articulated objects
移动操作机器人
54–Efficient task planning for mobile manipulation: a virtual kinematic chain perspective
55-Consolidating kinematic models to promote coordinated mobile manipulations
56-Planning sequential tasks on contact graph
57-Closed-loop openvocabulary mobile manipulation with gpt-4v
58-Learning unified force and position control for legged loco-manipulation
以及空中操作机器人[59-Sequential manipulation planning for over-actuated unmanned aerial manipulators]等结构化环境下得到了广泛研究
相比之下,仿人机器人远程操作仍主要局限于短时域的动作复现
19-Omnih2o
23-Exbody
24-Exbody2
由于双足系统难以实现实时的全局状态估计,因此通常采用开环控制 - 尽管近期的里程计技术进展提升了足式机器人状态跟踪的能力
60-Vilens: Visual, inertial, lidar, and leg odometry for all-terrain legged robots
61-Leg-kilo: Robust kinematic-inertial-lidar odometry for dynamic legged robots
但其在长时域仿人机器人控制中的应用仍鲜有探索
为弥补这一空白,作者将LiDAR里程计集成到远程操作框架中,实现闭环误差修正,并显著降低累计漂移
第三,用于训练人形机器人数据集
- 大规模动作捕捉(MoCap)数据集 [29-AMASS,62-Robust motion in-betweening] 在训练人形机器人控制策略方面发挥了重要作用
15-Hover
19-Omnih2o
23-Exbody
63-Styleloco: Generative adversarial distillation for natural humanoid robot locomotion
即使通过生成式模型对数据集进行增强 [24-Exbody2]
为提升动作多样性,ExBody2 对 AMASS 进行了筛选,并应用了基于条件变分自编码器(CVAE)的生成模型来合成新的轨迹
这些数据集仍主要局限于动画和图形领域
64-Humanise: Language-conditioned human motion generation in 3d scenes
25-Scaling up dynamic human-scene interaction modeling
而非机器人应用
虽然其中包含了语义上不同的动作(如挥手、拥抱、喝水),但它们对实际场景下稳健且可泛化控制器训练所需的运动学配置和动态转换表现不足 - 为了解决这一问题,作者通过动作编辑和收集额外的人体动作捕捉(MoCap)数据,对AMASS [29]进行扩展,推出了CLONED,专门为类人控制器量身定制
这一扩展显著增加了与类人控制任务相关的动作及其过渡的覆盖范围
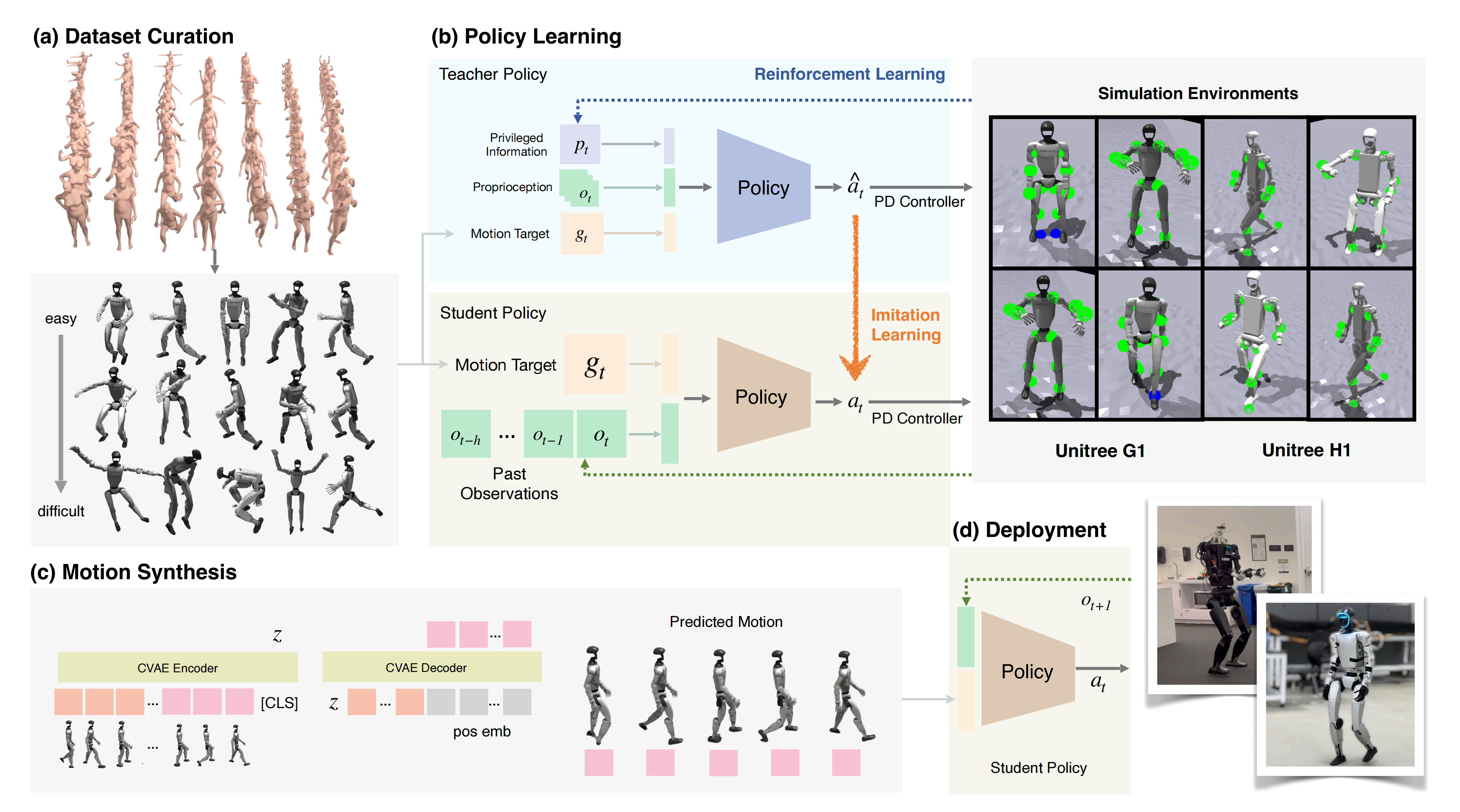
1.2 CLONE的完整方法论
如下图图3所示
- (a) CLONED 通过动作编辑,对重新定向的 AMASS [29] 数据进行筛选和增强,引入多样化的人形动作和细致的手部运动
- (b) 教师策略利用特权信息进行训练,包括完整的机器人状态和环境上下文
- (c) MoE 网络作为学生策略,从教师策略中蒸馏,仅依赖真实世界观测进行操作
- (d) 在实际部署中,作者集成了 LiDAR 里程计,以获取实时人形状态,从而在远程操作过程中实现闭环误差修正
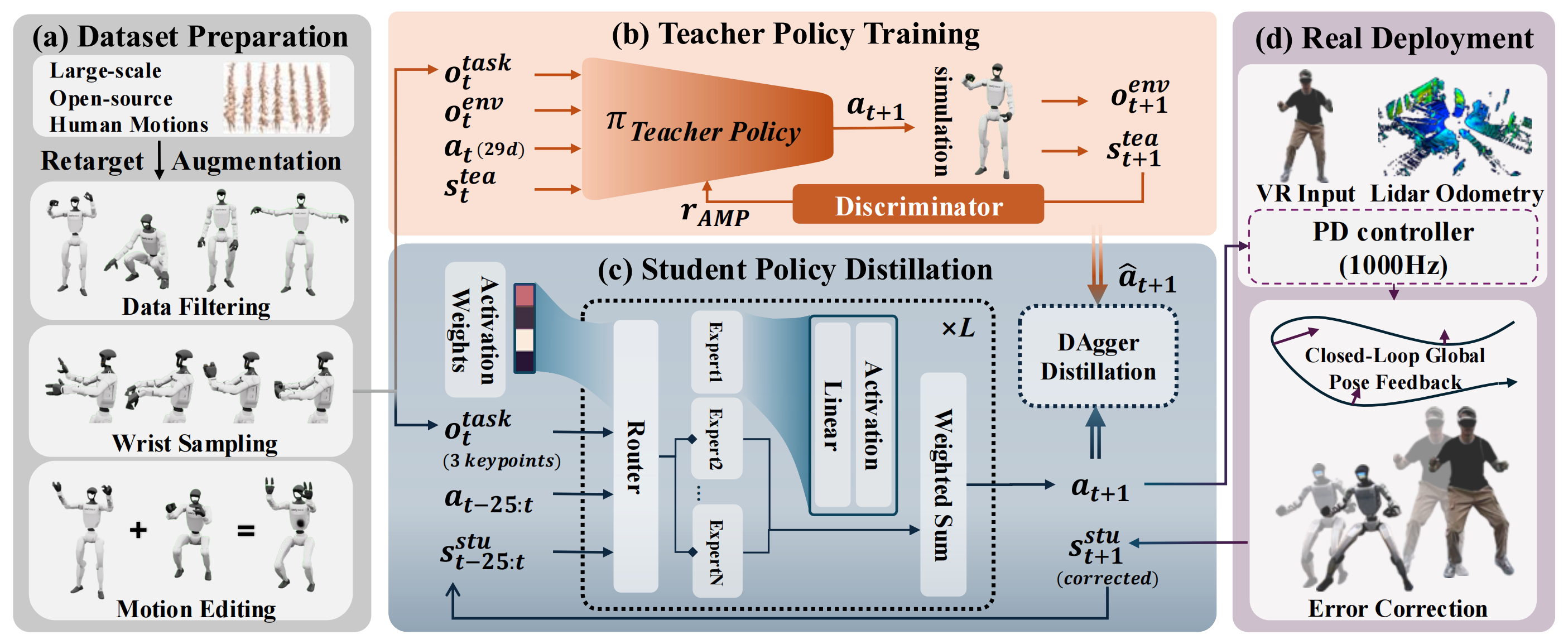
且如下图图2所示
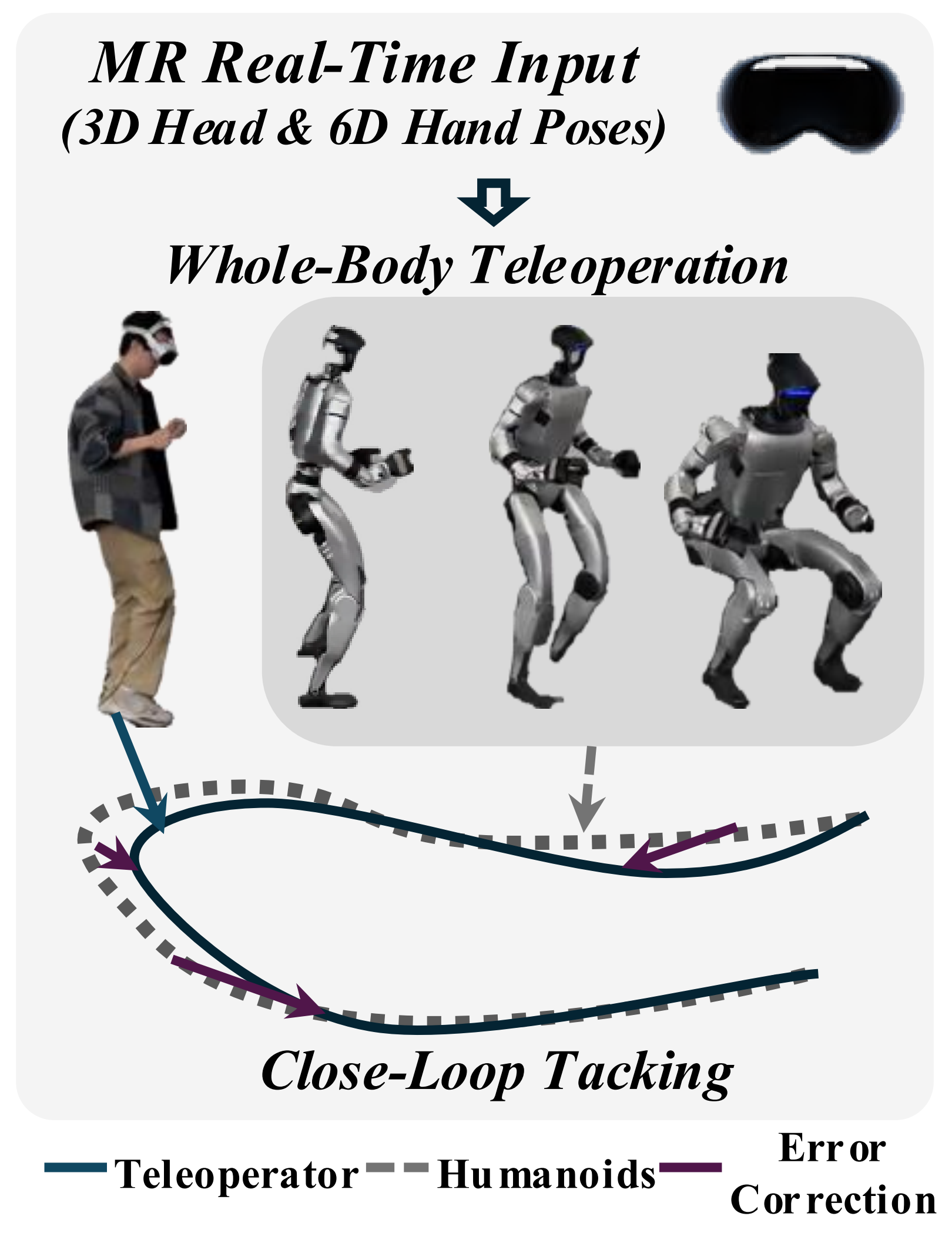
- 他们的远程操作框架CLONE,仅从操作者处获取最小化的控制信号集,这些信号仅包括通过 Apple Vision Pro 头显设备追踪的双手腕的6D位姿(位置和朝向),以及头部的3D位置
Our teleoperation framework, CLONE, captures a minimal set of control signalsfrom the teleopera-tor, consisting solely of the 6D poses (position and orientation) of both wrists and the 3D position ofthe head, tracked using an AVP headset - 这三个位点points构成了完整的控制界面,既直观又强大,使操作者能够指挥人形机器人实现全身运动,同时保持了简单的设置,无需额外硬件或复杂的校准流程
1.2.1 策略学习:教师-学生策略
作者采用了教师-学生训练策略来进行远程操作策略的学习——将稀疏的控制信号转化为协调的全身动作,遵循了OmniH2O [7] 的整体框架(问题的具体表述见附录A.1)
该方法首先利用特权信息训练教师策略,然后将这些知识蒸馏到仅依赖真实世界观测的学生策略中
- 对于教师策略
训练教师策略被实现为一个多层感知机(MLP),利用了真实机器人无法获得的全面状态信息
在每个时间步,教师策略以观测
作为输入,并输出用于PD控制的目标关节位置
对于各项输入,其中
特权状态
,包括每个关节的角位置
,所有机器人连杆的6D 位姿
、线速度
和角速度
,同时捕捉参考运动(用
表示)以及参考状态与当前状态之间的跟踪误差
提供了包括地面摩擦系数和机器人质量分布等上下文信息
- 对于学生策略
学生策略必须在没有特权信息的情况下运行,遵循
其中
,包括通过设备上的IMU 在过去25 帧内获得的关节位置
、关节速度
、根部角速度
,和根部重力向量
The robot state sequence sstut−25:t contains joint positionsq, joint velocities ˙q, root angular velocity ωroot, and root gravity vector g obtained from on-deviceIMU over the past 25 frames
,包括
,
和
,其中
是通过LiDAR 里程计和前向运动学获得的头部和两个手腕的三维位置
和
分别为参考运动中的目标位置和速度
关键挑战在于如何在单一策略中处理多样化的运动模式。行走所需的控制策略与下蹲或伸展动作截然不同,而传统的单体架构难以同时应对这些相互冲突的目标
作者通过MoE 架构解决了这一问题,该架构允许针对不同的运动类型进行专门化处理
具体而言,对于该MoE架构
- 它由
层组成,每层包含N 个专家。些专家作为具有不同参数的独立前馈子层运行
- 在每一层中,路由器会根据输入动态选择激活哪些专家,并在所有专家之间生成权重分布
该层的输出是来自路由权重最高的前个专家(通过加权求和)组合起来
其中是第
个被选中专家的路由权重,
是第
这一设计使得不同的专家能够关注不同的运动模式 - 为防止模型仅依赖少数专家而发生塌陷,就像deepseek moe那样——引入了平衡损失来正则化路由器,以(在训练和推理过程中)促进专家选择的均匀性
平衡损失定义为
其中,表示专家
的期望激活概率,
是一个松弛常数,允许与完全均匀性存在轻微偏差
1.2.2 闭环误差校正
传统的人形机器人远程操作系统采用开环配置,其中位置跟踪中的微小误差会随着时间的推移而不断累积,导致长时间操作过程中出现显著漂移——这一根本性限制在需要持续位置精度的长时任务中尤为突出
为了解决这一根本性限制,作者实现了一个闭环误差校正机制,能够持续监测并补偿远程操作员与人形机器人之间的位置偏差
- 他们的系统利用激光雷达LiDAR 里程计为人形机器人和远程操作员保持精确的全局位置估计
具体而言,他们采用了FAST-LIO2 [12],这是一种通过迭代卡尔曼滤波器且紧密融合IMU和激光雷达数据的算法,即使在动态运动过程中也能实现稳健的实时状态估计(详见附录A.2)——这一选择确保了从行走到复杂操作任务等多样运动模式下的可靠跟踪性能 - 该系统跟踪两个体的全局位置
由机载传感器计算得到,而远程操作员的位置
同样通过配备有类似里程计算流程的VR/MR硬件进行跟踪
与
之间的差值,使其能够生成:系统性减少位置漂移,并保持操作者与类人机器人之间准确对应的动作
1.2.3 奖励设计与领域随机化
作者以 OmniH2O [19] 的奖励项和域随机化为基础,构建了他们的方法,并针对现实世界远程操作的挑战进行了具体改进。详细的奖励函数和域随机化设置见附录 B
为了增强对LiDAR里程计误差的鲁棒性,他们在训练过程中引入了一个与速度相关的随机微分方程(SDE)噪声模型——以反映真实世界的误差特性
对于头部位位置,他们将随机化后的位置
定义为
- 其中
是一个标准Wiener 过程,
和
是常数,分别用于按运动速度比例缩放噪声并设定最小随机化水平
这一公式反映了现实世界中的动力学,即更快的运动往往会产生更大的里程计误差 - 作者使用前向运动学根据随机化后的头部位置计算其他身体部位的位置,同时定期重置并限制最大偏差,以避免出现不现实的漂移
- 由于CLONE仅提供上半身的参考信息(头部和手腕),作者必须在没有明确指导的情况下生成合适的下半身动作
为了解决这一挑战,作者采用了对抗性运动先验(AMP)奖励[65],以规范下半身动作并促进自然、稳定的行为
最终,通过专门的领域随机化与奖励设计相结合,CLONE能够在保持与操作者指令高度一致的上半身控制的同时,学习生成鲁棒的下半身行为
1.2.4 CLONED数据集
训练数据集CLONED由三个互补的组成部分构成,以支持稳健的全身远程操作:
- 增强版AMASS [13] 子集,包含 149 个精心挑选的序列,涵盖多样的上下半身动作组合,并通过有针对性的动作编辑,以提升组合的多样性和策略泛化能力
an augmented AMASS [13] subset of 149 curated sequences featuring diverse pairings of upper- and lower-body movements, enhanced via targeted motion editing to increase compositional diversity and policy generalization - 采用基于惯性测量单元(IMU)的 Xsens 动作捕捉系统采集的14条自定义序列,以填补覆盖空白,重点关注连续过渡,以及对操作任务至关重要的多样化的上半身姿势
14 custom sequences captured withan IMU-based Xsens MoCap system to fill coverage gaps, emphasizing continuous transitions anddiverse upper-body poses critical for manipulation - 通过程序生成的6D手腕目标,系统性地增强手部朝向,并利用球面线性插值(SLERP)进行平滑处理,以确保远程操作中手部动作的连贯性与自然性
systematic hand orientation augmen-tation through procedurally generated 6D wrist targets, smoothed via Spherical Linear Interpola-tion (SLERP) to ensure coherent and natural hand motions for teleoperation
1.3 4个真实世界中的实验与仿真评估
1.3.1 4个真实世界中的实验
// 待更
1.3.2 仿真评估:跟踪多样姿态、消融实验、专家激活分析
在本节中,作者通过大量的模拟实验和实际部署,对CLONE进行了全面评估。具体而言,他们的评估包括四个部分:
- 在Isaac Gym仿真环境[40]中对运动跟踪精度的定量基准测试
- 针对多样化站姿配置的鲁棒性评估
- 针对关键架构决策的消融研究
- 在Unitree G1人形机器人上的实际验证,展示了前所未有的全身运动保真度和精确的位置跟踪
作者进行了全面的定量实验,以评估CLONE在精确跟踪参考动作方面的能力。他们的模拟评估涵盖了四种不同的设置:参考动作跟踪、多样站姿跟踪、消融研究和专家激活分析
他们在CLONED 的运动追踪任务中使用五个指标评估了CLONE:
- 成功率SR ( %)
- 平均每关键体位误差(MPKPE)
- 根相对平均每关键体位误差(R-MPKPE)
- 平均关节速度误差
- 手部朝向追踪误差
成功率(SR)表示以下两种情况的回合比例
- 机器人在不摔倒的情况下保持平衡
- 机器人与参考动作之间的平均每关键体距离在三个受控关节上始终低于1.5 m
作者将手部朝向跟踪误差定义为,其中
和
分别表示参考和机器人手部的四元数
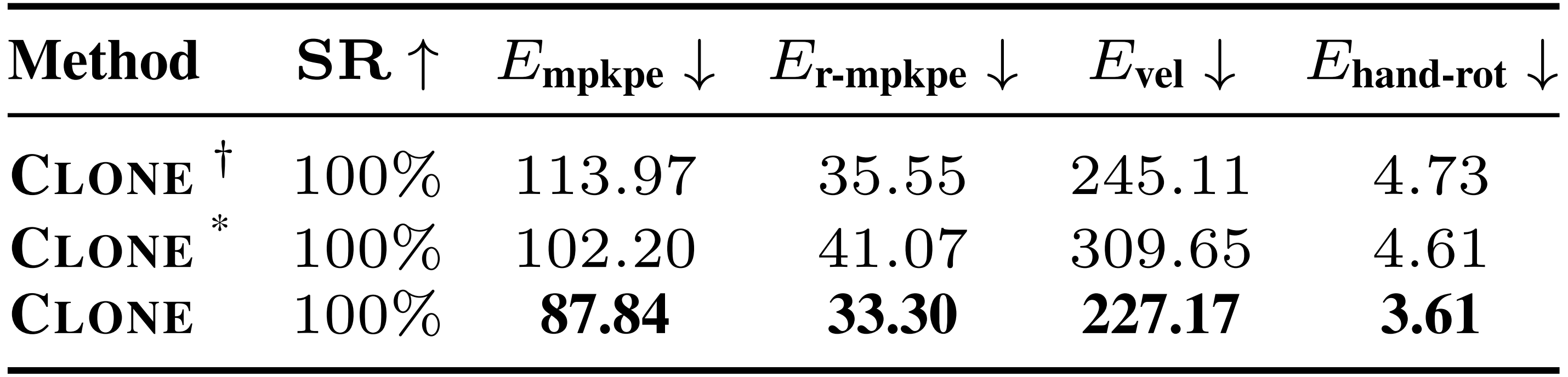
作者将CLONE与两个经过裁剪的基线模型CLONE†和CLONE*进行了对比
- CLONE†采用MLP作为学生策略,类似于在他们的数据和任务上训练的OmniH2O基线
此举是为了证明原装CLONE所采用的MoE架构 更好 - CLONE∗则在OmniH2O数据上而非CLONED数据集上进行训练
此举是为了证明原装CLONE所增强的数据 更好
下表表1中的定量结果显示,MoE架构和CLONED(数据集)都对精确的参考运动跟踪有显著贡献
第一,对于跟踪多样姿态
为了评估CLONE在不同姿态下的鲁棒性,他们测试了其在跟踪头部高度从1.2米(站立)到0.6米(深蹲),以0.1米递减的动作中的表现——相当于从站立到慢慢下蹲
他们通过系统性地编辑CLONED数据集中的序列,生成了这些具有挑战性的动作,创造出未见过的姿态,以考验远程操作系统的极限
- 如下图图7所示「CLONE(蓝色实线)、在OmniH2O数据上训练的CLONE∗(绿色虚线)和采用MLP作为学生策略的CLONE†(红色虚线)之间的运动跟踪性能比较。对于所有误差指标,数值越低表示性能越好」
从上图可知,CLONE 展现出有趣的权衡:虽然在绝对位置精度(MPKPE)上不如基线方法,但在局部指标(R-MPKPE、速度误差和手部朝向)上始终优于它们——毕竟数值越低表示性能越好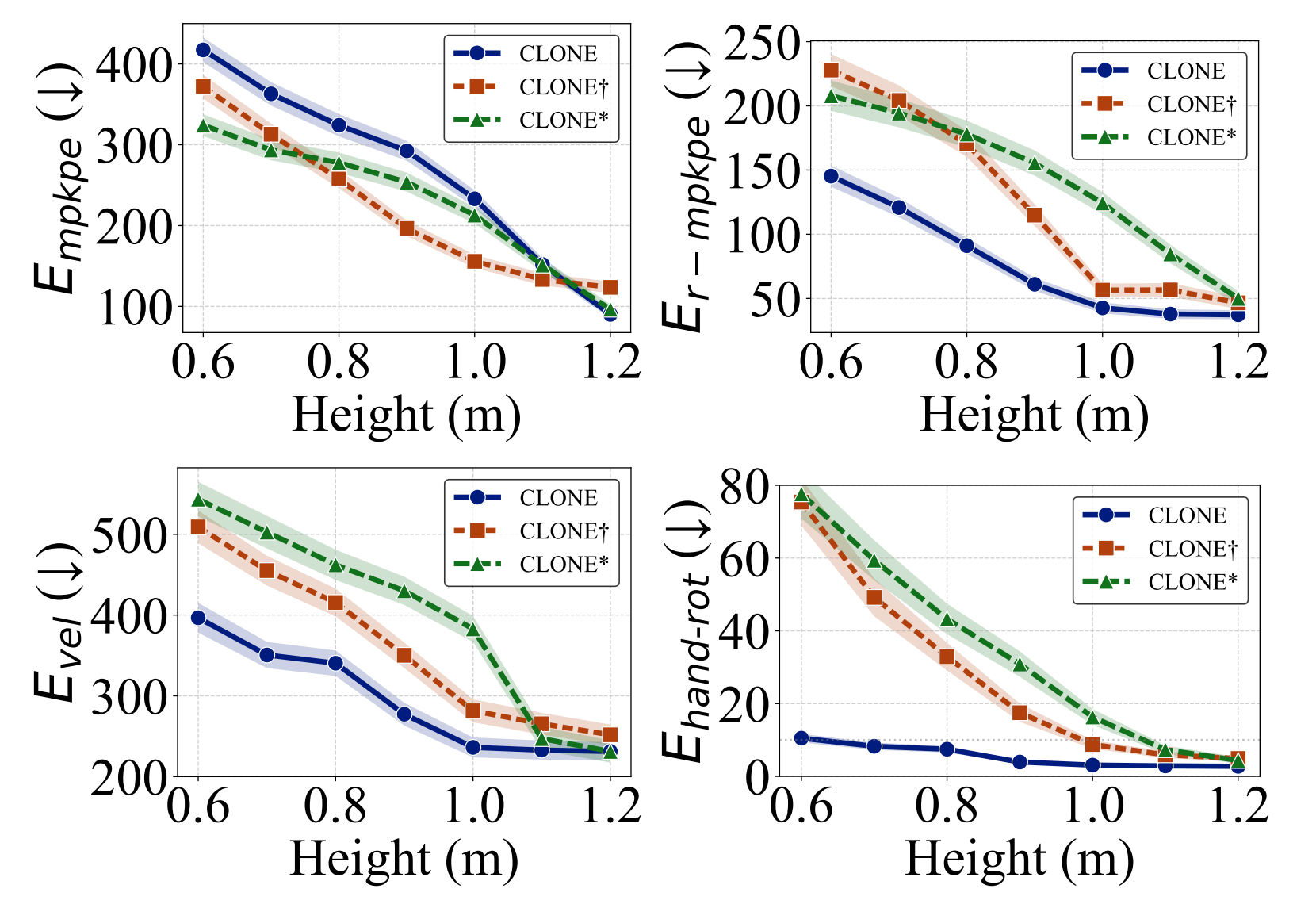
- 这一模式表明,CLONE更注重对参考动作的忠实还原——尤其是在处理具有挑战性的姿态时——有时会以牺牲全局定位精度为代价
所有方法在较低高度下的跟踪误差均有所增加,这进一步证实了远程操作机器人在下蹲姿态下本身就具有较大难度
第二,对于消融实验
作者通过系统性的消融实验(见下表表2)研究了关键设计选择的影响,特别是历史长度和MoE参数
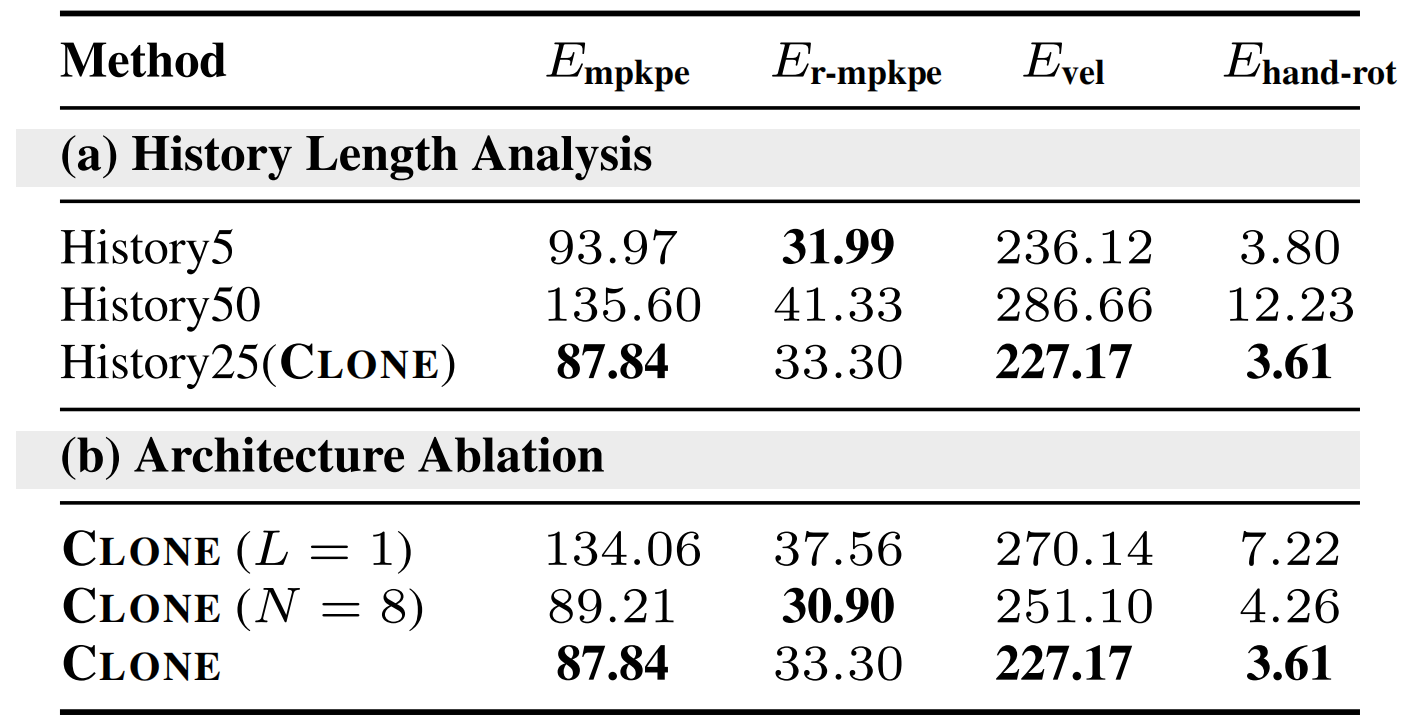
- 实验结果表明,采用25步历史、三层MoE以及每层四个专家的配置,在大多数评估指标上实现了最佳性能
- 且他们还发现,较短的历史长度和增加专家数量可能会导致R-MPKPE值略有降低,但全局跟踪误差增大,这表明在局部与全局运动保真度之间存在权衡
第三,对于专家激活分析
为了更好地理解我们专家混合架构中的专业化现象,他们在图A2中可视化了九种不同动作类型下的专家激活权重。结果显示出明显的专业化模式:需要相似技能的动作会激活特定专家
- 在第一层中,专家1和专家2主要在站立动作中被激活,而专家3和专家4则在下蹲动作中表现出更强的激活
- 值得注意的是,在跳跃和击打等动态动作中,第一层的所有四个专家都会被激活,这表明了协同作用——对复杂运动的协同处理
在后续层中也出现了类似的专门化模式,尽管在不同运动类别之间的方差有所降低
// 待更