什么是音频?
引言:声音的本质
什么是音频?振动与感知
音频,在其最核心的层面,即是我们通常所说的声音。它起源于物体的振动。这些振动扰动了其周围的介质(例如空气或水),在介质中产生了微小的压力变化,这些压力变化以波的形式传播开来。当这些压力波到达我们的耳朵时,耳内的复杂机制会探测到这些变化,并将其转换成神经信号,我们的大脑随后将这些信号解读为声音。正如一段简练的描述所言:“普遍物体的振动形成声波,即声音”。
这种对音频物理基础的理解至关重要,因为它揭示了音频并非一个抽象概念,而是一种可触可感的物理现象。所有我们听到的声音,本质上都是空气(或其他介质)的压力变化以不同的速率撞击我们的耳朵。这一基本原理构成了所有音频技术的基础。无论是麦克风的设计(旨在捕捉这些压力变化),还是扬声器的构造(旨在重现这些变化),乃至各种音频存储方法(如模拟唱片的凹槽、磁带上的磁性图案,或数字文件中的采样数据),都是对这一物理现实进行操控或再现的尝试。因此,音频技术的整个领域,从根本上说,是建立在对这种物理过程的理解和互动之上的。它不仅仅关乎抽象的信号处理,更是对真实世界物理事件的精确表达与重塑。这意味着,在捕捉或再现这些物理事件过程中的任何局限性,例如麦克风的灵敏度不足或扬声器的频率响应范围有限,都会直接影响最终感知到的音频质量。
声音的物理特性
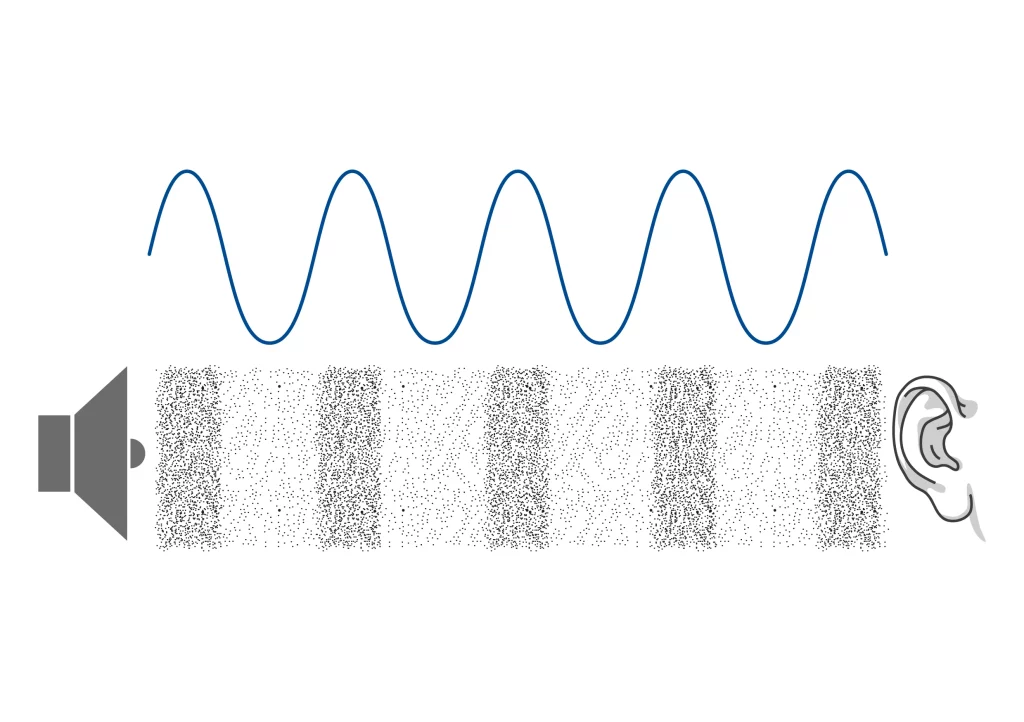
声波:传播的能量
声音以声波的形式传播,这是一种能量的传播方式。声波属于纵向波,意味着介质中的粒子(如空气分子)的振动方向与波的传播方向平行。声波由一系列的压缩区(高压区)和稀疏区(低压区)组成,交替向前推进。理解声音是作为波传播的能量,有助于解释波长、声速等概念,以及声音如何与环境相互作用(如反射、吸收)。
核心要素
声音的特性可以通过几个核心物理要素来描述,它们共同决定了我们听到的声音的特性。
频率 (Frequency) 与 音调 (Pitch)
频率是指声压波每秒钟重复振动的次数,其单位是赫兹 (Hz)。我们感知到的频率即为音调的高低;频率越高,音调越高,反之,频率越低,音调则越低沉。例如,鼓声的频率远低于哨声。更具体地说,“声波的频率越高(音调越高),我们听起来的声音就越高音”。频率是描述声音的一个基本参数,直接影响我们对音乐和环境声音的感知,并且是音频处理(如均衡器调整)中的一个关键参数。
振幅 (Amplitude) 与 响度 (Loudness)
振幅是指声波的相对强度或波动幅度,我们将其感知为声音的响度或音量。振幅通常用分贝 (dB) 来衡量。声波的振幅越大,我们感知到的声音就越大。例如,用力拨动吉他弦会使其振动幅度更大,从而产生更大的振幅和更响亮的声音。值得注意的是,分贝是一个对数标度,这意味着响度的感知变化与声能的绝对变化不成线性关系。振幅决定了声音的感知强度,这对于从日常交流到音乐动态表现乃至听力保护都至关重要。
波长 (Wavelength) 与 声速 (Velocity)
波长是指一个完整的波形(例如,从一个压缩区中心到下一个压缩区中心)所传播的距离。声速则是声波在特定介质中每秒传播的距离,它会因介质的种类和状态(如温度、密度)而变化。这三个物理量之间存在固定的关系:声速等于频率乘以波长。波长在声学中非常重要,它影响声音如何与物体和空间相互作用,例如,长波长的低频声音更容易绕过障碍物。
相位 (Phase)
相位描述了一个声波相对于另一个声波在时间上的起始位置或同步状态。这是一个非常关键的概念,因为当多个声波相遇时,它们的相位关系会决定它们是相互增强(同相叠加)还是相互抵消(反相叠加)。例如,如果两个麦克风从不同距离拾取同一个声源,它们接收到的信号可能会因相位差异而导致某些频率成分的抵消,从而改变最终录制的声音效果。在多麦克风录音、扬声器摆位以及某些音频效果(如移相器)的应用中,对相位的理解和控制至关重要。
这些声波的物理特性——频率、振幅、波长和相位——并非孤立存在,而是内在关联并共同定义了一个声音事件。更重要的是,每一个物理特性都有其直接且通常直观的感知对应物:频率对应音调,振幅对应响度。在更复杂的场景中,例如我们感知声音的空间位置,很大程度上依赖于声音到达双耳时的微小相位差异。同样,当不同相位的声波叠加时,它们会发生相长干涉(声音变大)或相消干涉(声音变小甚至消失)。因此,对“音频”的完整理解不仅需要掌握单个属性,还需要理解它们如何物理地相互作用,以及这些互动如何塑造我们的听觉感知。
虽然频率主要决定音调,振幅主要决定响度,但声音独特的“质感”或“色彩”,即音色(Timbre),则源于基频及其一系列泛音(谐波)的复杂组合,包括这些泛音的相对振幅和相位关系。这就是为什么钢琴和小提琴以相同的音高和响度演奏同一个音符时,我们依然能够轻易区分它们。一个单一频率的声音被称为纯音,例如音叉发出的声音。然而,现实世界中的大多数声音,尤其是乐器的声音,都是由一个基准频率(决定了音符的音高)和一系列频率更高、振幅各异的泛音叠加而成的复杂波形。正是这些泛音的特定组合及其相对强度和相位,构成了特定乐器或人声独特的波形结构,从而产生了其特有的音色。因此,音色并非单一的物理属性,而是整体波形结构(由多种频率、振幅和相位关系构成)所产生的感知结果。这也解释了为何音色常被认为由声源的材料和结构决定,因为这些物理特性直接影响了物体可能的振动模式,进而决定了其泛音的构成。
人耳的聆听:我们如何感知声音
听觉范围:赫兹与分贝
人类的听觉系统对声音的感知有一定的范围限制。在频率方面,听力正常的人通常可以听到大约 20 Hz 到 20,000 Hz (即 20 kHz) 范围内的声音。低于 20 Hz 的声音被称为次声波 (Infrasound),而高于 20,000 Hz 的声音则被称为超声波 (Ultrasound)。有趣的是,婴儿的听觉上限可以略高于 20 kHz,但这种能力通常会随着年龄的增长而下降。
在响度方面,人类听觉的动态范围通常从 0 dB(可听阈,即人耳能察觉到的最微弱声音的水平)开始,一直延伸到大约 120-130 dB(痛阈,超过此水平的声音会引起不适甚至疼痛)。了解这些听觉极限对于音频工程(例如,设计能够再现可听频率范围的设备)、心理声学(例如,为音频压缩建立听觉模型)以及听力保护都至关重要。
响度感知与声音安全
分贝标度是一个对数标度,这意味着声强增加十倍,感知到的响度大约增加一倍(约增加 10 dB)。一般而言,持续暴露在 70 dB 或以下的声音环境中被认为是安全的。然而,长时间暴露在 85 dB 以上的声音中则可能导致听力损伤。例如,美国环境保护署 (EPA) 和世界卫生组织 (WHO) 均建议,为避免听力受损,应将 24 小时内的平均噪音暴露量控制在 70 dBA 以下;而 85 dBA 则被认为是职业噪音暴露 8 小时的上限阈值。每当声音强度增加 3 dB,其能量就增加一倍,相应的安全暴露时间则减半。这些知识对于公共卫生、职业安全以及培养健康的个人聆听习惯以预防噪音性听力损失至关重要。
尽管音频技术力求实现标准化的测量和再现(例如,统一的频率响应曲线、分贝等级),但人类的实际听觉感知却具有主观性,并且因年龄、健康状况和个体差异而显著不同。例如,“正常”的人类听觉频率范围是 20 Hz 到 20 kHz,但这个上限会随着年龄增长而降低,也会受到噪音暴露的影响。听力测试通常关注 250 Hz 到 8000 Hz 的频率范围,因为这个范围对理解语音至关重要。音频设备通常被设计为覆盖 20 Hz 到 20 kHz 的范围,音频内容也基于这些通用能力进行混音和母带处理。然而,一位年长者可能无法感知到年轻人或音频工程师刻意营造的 14 kHz 以上的高频“空气感”。这揭示了音频的客观技术规格与其主观接收之间可能存在的差异,并强调了听力保护的重要性,以维持感知预期音频的能力。
采用对数标度的分贝 (dB) 来衡量声音强度并非偶然,它深刻反映了人类感官(包括听觉)感知刺激强度的方式。我们对响度变化的感知更接近对数关系而非线性关系。这意味着,在高声压级时,需要声功率有更大的变化才能产生与低声压级时相同的感知响度增量。例如,从 10 dB 增加到 20 dB 所感知到的响度变化,远比从 100 dB 增加到 110 dB 所感知到的变化更为显著,尽管后者的绝对声功率增量要大得多。这种特性与心理物理学中的韦伯-费希纳定律或史蒂文斯幂定律所描述的人类感官特性相符。因此,分贝标度是一种实用且与感知高度相关的量化声音级别的方法,它使测量系统与我们的实际响度体验相一致,这对于音频工程师进行有意义的音量和动态调整至关重要。
音频的记录与再现:从模拟到数字
声音的捕获和重放技术经历了从模拟到数字的重大变革,每种方式都有其独特的原理和特点。
模拟音频:连续的信号
模拟录音技术将声音作为连续变化的波形记录在物理介质上。这些信号被直接存储在介质之中或其表面,例如,黑胶唱片上刻录的物理凹槽,或是磁带上磁场强度的波动。因此,模拟信号是声波的一种连续、平滑的物理表征。
模拟磁带录音在第二次世界大战后随着德国磁带录音机 (Magnetophon) 的出现而兴起,并迅速成为主流。它相较于当时的醋酸盐盘录音,提供了更长的录音时间(超过30分钟)和前所未有的编辑能力,首次使得音频可以被后期处理和操控。吉他手莱斯·保罗 (Les Paul) 在此基础上进一步推动了多轨录音技术的发展,使得录音从最初的双轨逐步发展到 24 轨甚至更多,并在 20 世纪 70 年代和 80 年代成为专业录音棚的标准配置。模拟录音过程通常涉及磁头将音频电信号转换为变化的磁场,从而磁化涂覆在聚酯薄膜带基上的氧化铁颗粒,以此“捕获”声音信号。模拟音频因其特有的“温暖感”而受到一些人的喜爱,但这通常与其固有的非线性和失真特性有关,同时也易受物理磨损和环境因素影响而发生信号衰减。
数字音频:离散的表达
与模拟音频的连续性不同,数字音频通过采样 (Sampling) 和量化 (Quantization) 这两个核心过程,将连续的声音信号转换成离散的数值数据,通常以二进制的0和1来表示。它不再是连续的波形,而是代表原始音频波形在特定时间点上的一系列离散数值。这种从连续到离散的转变是数字音频的根本特征,也是理解后续如采样率、位深度等关键概念的基础。
数模转换 (ADC) 与模数转换 (DAC)
在数字音频系统中,模拟到数字转换器 (Analog-to-Digital Converter, ADC) 和数字到模拟转换器 (Digital-to-Analog Converter, DAC) 扮演着至关重要的角色。ADC 负责将来自麦克风或其他声源的连续模拟声波,通过在规律的时间间隔内进行“采样”(测量),转换成离散的数字数据流。反之,DAC 则执行相反的过程,它将存储或处理后的数字音频数据转换回连续的模拟电信号,这个信号随后可以被放大并驱动扬声器或耳机,从而重放出声音。ADC 和 DAC 是连接真实世界的模拟声音与虚拟世界的数字处理和存储之间的关键桥梁,它们的性能好坏直接影响最终音频的保真度。
关键概念
-
采样率 (Sampling Rate) 采样率是指在一秒钟内对模拟音频信号进行采样(即测量)的次数,单位是赫兹 (Hz)。采样率越高,意味着对原始声波的捕捉越频繁,从而能够更精确地记录音频波形,尤其是高频部分的信息。常见的采样率包括 44.1 kHz(CD 音质标准)、48 kHz(常用于数字视频和专业音频制作)以及 96 kHz 或更高(用于高解析度音频)。
根据奈奎斯特定理(Nyquist Theorem),为了无失真地再现某一特定频率的声音,采样率必须至少是该频率的两倍。因此,一个采样系统能够记录的最高音频频率(称为奈奎斯特频率)是其采样率的一半。例如,44.1 kHz 的采样率能够记录最高约 22.05 kHz 的音频,这恰好覆盖了人类的平均听觉上限。
如果在采样过程中,输入信号中包含了高于奈奎斯特频率的成分,这些高频成分会被错误地表现为原始信号中不存在的较低频率,这种现象被称为混叠 (Aliasing)。混叠会产生听得见的失真,听起来像是奇怪的、非音乐性的谐波。为防止混叠,ADC 在采样前通常会使用抗混叠滤波器(一种低通滤波器)来滤除高于奈奎斯特频率的信号成分。采样率的选择直接决定了数字音频系统能够捕捉的最高频率,而奈奎斯特定理是数字音频领域的一块基石。
-
位深度 (Bit Depth) 位深度是指用多少个二进制位 (bit) 来表示每一个音频样本的振幅值,它决定了声音记录的精度或“分辨率”。位深度直接影响了数字音频的动态范围(即最轻柔声音和最响亮声音之间的差距)以及本底噪声(即系统固有的背景噪声水平)。每增加一个比特的位深度,理论上动态范围大约增加 6 dB。例如,16 位位深度可以表示 216(即 65,536)个不同的振幅级别,其理论动态范围约为 96 dB。常见的位深度有 16 位(CD 音质标准)、24 位(广泛用于专业音频录制和处理,提供约 144 dB 的动态范围)和 32 位浮点(用于需要极高精度和极大动态范围的场合)。更高的位深度意味着对每个样本振幅的描述更精确,能够记录更细微的响度变化,并拥有更低的噪声基底。
-
比特率 (Bit Rate) 比特率是指每秒钟处理或传输的数据量(比特数),通常以千比特每秒 (kbps) 或兆比特每秒 (Mbps) 为单位。对于未经压缩的数字音频(如 PCM 编码的 WAV 文件),比特率可以通过以下公式计算得出:采样率 × 位深度 × 声道数。例如,一个双声道、采样率为 44.1 kHz、位深度为 16 位的 CD 音质音频,其比特率约为 1411.2 kbps。而对于经过压缩的音频格式(尤其是有损压缩格式如 MP3),比特率则表示压缩后的数据流速率,是衡量其音质的一个重要指标,比特率越高通常意味着保留的原始信息越多,音质越好。比特率对于理解音频文件的大小以及在线流媒体的带宽需求至关重要。
关于模拟音频与数字音频孰优孰劣的争论由来已久,但这个问题往往被过度简化。两者各有其理论上的优势和实际应用中的局限性。高质量的数字音频能够实现极其精确的声音再现,而模拟音频则常因其“温暖”的特质受到赞誉,这种“温暖感”部分源于其固有的非线性特性和一些听者认为悦耳的失真(例如磁带饱和)。数字音频提供了精确性、便捷的编辑能力以及播放时无信号衰减的优点。然而,早期或质量欠佳的数字音频系统可能会引入可闻的失真,如量化噪声或混叠效应。实际上,“声音本身是模拟的。模拟和数字声音之间没有本质区别,只有正确和不正确的声音之分。数字声音可以被正确地再现,而模拟声音则带有录音介质的局限性”。最终的选择往往取决于工作流程的需求、期望的音色美学以及所用设备的具体质量,而非某种格式固有的绝对优越性。现代数字技术甚至可以模拟出模拟设备的特性。
数字音频参数(如采样率和位深度)的选择并非随意的,它们代表了在保真度与数据量之间,依据人类感知极限所做出的权衡。例如,CD 音质采用 44.1 kHz 的采样率和 16 位的位深度,这是经过精心设计的工程折衷:44.1 kHz 的采样率根据奈奎斯特定理,足以捕捉高达约 22.05 kHz 的频率,略高于人类的平均听觉上限(约 20 kHz)。16 位的位深度提供了约 96 dB 的理论动态范围,这能够覆盖大多数音乐的动态起伏,并且在许多聆听环境下其本底噪声也低于环境噪声。更高的参数,如 96 kHz 采样率和 24 位位深度,虽然在理论上能提供更高的保真度(例如,捕捉超声波频率,进一步降低混叠失真,提供更大的动态范围和更低的噪声基底),但也带来了显著增加的数据存储和传输开销。对于普通听众在典型条件下,这些更高参数所带来的感知益处可能并不明显,但在专业录音和混音过程中,它们能提供更大的处理裕度和更精细的细节捕捉能力。因此,“CD 音质”是在其时代技术条件下,为满足多数人听觉需求并兼顾数据管理可行性而取得的平衡点。而“高解析度音频”则进一步提升这些参数,追求潜在的更高保真度,但伴随着更高的数据成本。
音频格式:存储与传输的艺术
数字音频在被存储或传输之前,通常会被编码成特定的文件格式。这些格式可以大致分为三类:无压缩格式、无损压缩格式和有损压缩格式。
无压缩格式 (如 WAV, AIFF)
无压缩音频格式直接存储原始的数字音频数据,通常是脉冲编码调制 (Pulse Code Modulation, PCM) 数据,不经过任何压缩处理。这使得它们能够提供最高的音频保真度,完全保留了录制时的所有细节。然而,代价是文件体积非常庞大。WAV (Waveform Audio File Format) 是在 Windows 平台上非常常见的无压缩格式,而 AIFF (Audio Interchange File Format) 则多用于 macOS 系统。AIFF 格式采用分块结构,能支持更丰富的元数据(如音轨名称、版权信息等),而 WAV 结构相对简单,但兼容性更广。由于其高保真特性,无压缩格式是专业音频制作流程中(如录音、编辑、母带处理)的首选,以确保在最终压缩输出前保留最佳音质。
无损压缩格式 (如 FLAC, ALAC)
无损压缩格式通过特定的算法减小音频文件的体积,但与有损压缩不同的是,它们在压缩过程中不会丢弃任何原始的音频信息。这意味着解压缩后得到的音频数据与压缩前完全一致,音质没有任何损失。FLAC (Free Lossless Audio Codec) 是一种开源的无损压缩格式,因其高效的压缩率(通常能将文件大小缩减至原始无压缩文件的一半左右,同时保持音质不变)和广泛的平台支持而备受欢迎。ALAC (Apple Lossless Audio Codec) 则是苹果公司开发的无损压缩格式,主要用于其自家的生态系统(如 iTunes、iOS 设备)。尽管 FLAC 在压缩效率和跨平台兼容性上略优于 ALAC,但两者在音质上是等同的。无损压缩格式为那些既关注音质又希望节省存储空间的音乐爱好者和档案管理者提供了一个理想的平衡点。
有损压缩格式 (如 MP3, AAC) 与心理声学
有损压缩格式通过永久性地移除一部分音频数据来显著减小文件体积。这种数据移除并非随机进行,而是基于心理声学 (Psychoacoustics) 模型。心理声学研究人类听觉系统感知声音的方式和局限性,例如频率掩蔽(一个响亮的声音会使得其附近频率的较轻声音难以被察觉)和时间掩蔽(一个强音之后紧接着的弱音可能听不见)等现象。有损压缩算法利用这些原理,优先去除那些被认为人耳最不敏感或最不容易察觉的声音成分,从而在尽可能保持可接受音质的前提下,最大限度地压缩文件。
MP3 (MPEG-1 Audio Layer III) 是最早普及也是最为人熟知的有损压缩格式,它彻底改变了音乐的存储和分发方式。AAC (Advanced Audio Coding) 是作为 MP3 的后继者而被设计的,通常在相同的比特率下能提供比 MP3 更好的音质,因此被苹果公司以及许多流媒体服务所采用。有损压缩格式因其极小的文件体积,极大地推动了便携式音乐播放器和在线音乐流媒体的发展。
这三种主要的音频格式类型——无压缩、无损压缩和有损压缩——并非偶然形成,而是代表了在音频保真度、存储/传输效率以及感知影响这三个关键因素之间进行工程妥协后产生的一系列解决方案。无压缩格式(如 WAV、AIFF)将绝对保真度置于首位,完整保存所有原始数据,但文件体积巨大。无损压缩格式(如 FLAC、ALAC)则试图在不损失任何音频信息的前提下减小文件体积,实现了中等程度的压缩。而有损压缩格式(如 MP3、AAC)则以牺牲部分(理论上人耳不敏感的)数据为代价,优先追求文件体积的显著减小,这不可避免地会带来一定程度的音质损失,尽管在较高比特率下这种损失可能难以察觉。MP3 的出现正是为了满足当时互联网带宽有限、便携设备存储空间小等技术瓶颈下的需求。专业音频制作依然依赖无压缩格式进行母带处理,而音乐归档常采用无损格式,流媒体服务则主要使用有损格式。这清晰地表明,每种格式类型都是针对特定约束条件和目标的特定解决方案,不存在适用于所有情况的“最佳”格式,选择总是在这些因素间进行权衡。
音频格式的演变与存储技术、处理器能力和互联网带宽等使能技术的进步紧密相连。从模拟录音到数字化的无压缩 PCM(如 CD),再到为适应早期互联网和便携设备限制而生的有损压缩 MP3,每一步都反映了当时的技术水平。随着存储成本大幅下降、处理器速度飞快提升以及互联网带宽日益充裕,曾经迫使人们广泛采用高强度有损压缩的限制逐渐缓解。这使得对更高保真度格式的需求得以满足,无损格式(如 FLAC)在发烧友中流行起来,流媒体服务也开始提供更高质量的有损编码(如 AAC)乃至无损/高解析度音频选项。这一历程显示,尽管心理声学为有损压缩提供了理论基础,但其广泛应用的需求是由当时的技术局限性驱动的。当这些局限性减弱时,人们对更高音质(更少或没有“损失”)的偏好便能得到更广泛的实现。
建议表格:常见音频格式对比
为了更直观地比较这些常见的音频格式,下表总结了它们的主要特性:
| 特性 (Feature) | WAV | AIFF | FLAC | ALAC | MP3 | AAC |
|---|---|---|---|---|---|---|
| 压缩类型 (Compression Type) | 无压缩 (Uncompressed) | 无压缩 (Uncompressed) | 无损压缩 (Lossless) | 无损压缩 (Lossless) | 有损压缩 (Lossy) | 有损压缩 (Lossy) |
| 音质 (Sound Quality) | 极佳 (Excellent) | 极佳 (Excellent) | 极佳 (Excellent) | 极佳 (Excellent) | 好/尚可 (Good/Fair) | 较好/好 (Better/Good) |
| 文件大小 (File Size) | 非常大 (Very Large) | 非常大 (Very Large) | 中等/较大 (Medium/Large) | 中等/较大 (Medium/Large) | 小 (Small) | 小/较小 (Small/Smaller than MP3 at same quality) |
| 主要用途 (Primary Use) | 专业制作、母带 (Pro Production, Mastering) | 专业制作、母带 (Pro Production, Mastering) (Apple生态) | 音乐存档、高保真聆听 (Archiving, Hi-Fi Listening) | 音乐存档、高保真聆听 (Archiving, Hi-Fi Listening) (Apple生态) | 便携播放、流媒体 (Portable, Streaming) | 流媒体、Apple设备 (Streaming, Apple Devices) |
| 元数据支持 (Metadata) | 有限 (Limited) | 较好 (Better than WAV) | 良好 (Good) | 良好 (Good) | 良好 (ID3 tags) | 良好 (Good) |
| 兼容性 (Compatibility) | 广泛 (Windows) | 较好 (macOS) | 广泛 (Broad) | Apple生态系统 (Apple Ecosystem) | 非常广泛 (Very Broad) | 广泛 (Broad, esp. Apple) |
体验音频:声道与沉浸感
我们体验音频的方式也随着技术的发展而不断演进,从单一的声源感知到被声音完全包围的沉浸式体验。
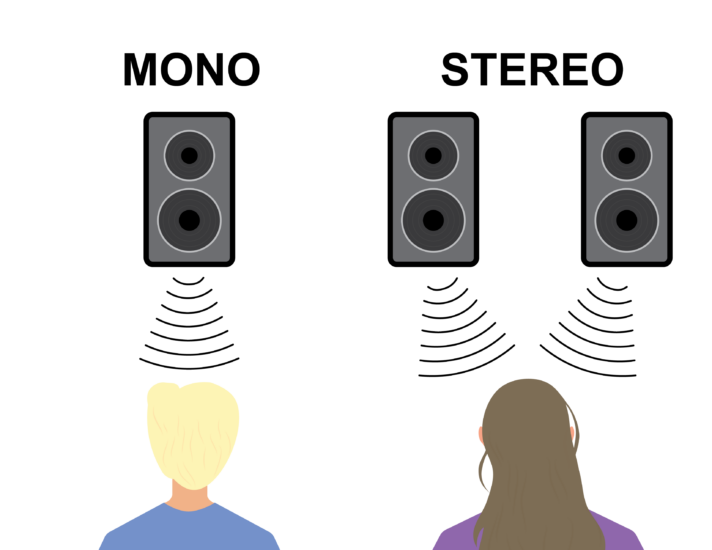
单声道 (Mono) 与 立体声 (Stereo)
单声道 (Monophonic) 音频使用单一的音频通道进行录制和播放。无论有多少个扬声器,所有声音听起来都像是从同一个点发出的。这在早期的录音和某些特定应用(如电话通话、某些公共广播)中很常见。
立体声 (Stereophonic) 音频则使用两个独立的音频通道(左声道和右声道)来录制和播放声音。通过这两个通道传送不同的声音信息,并在两个扬声器(或耳机的左右单元)上播放,可以营造出声音在听者面前形成一定宽度和空间分布的感觉,听者可以大致辨别出不同声源的左右位置。因为人类拥有双耳,立体声能够更好地模拟我们日常生活中感知声音的方式,提供比单声道更自然、更具空间感的聆听体验,因此已成为音乐聆听的主流标准。
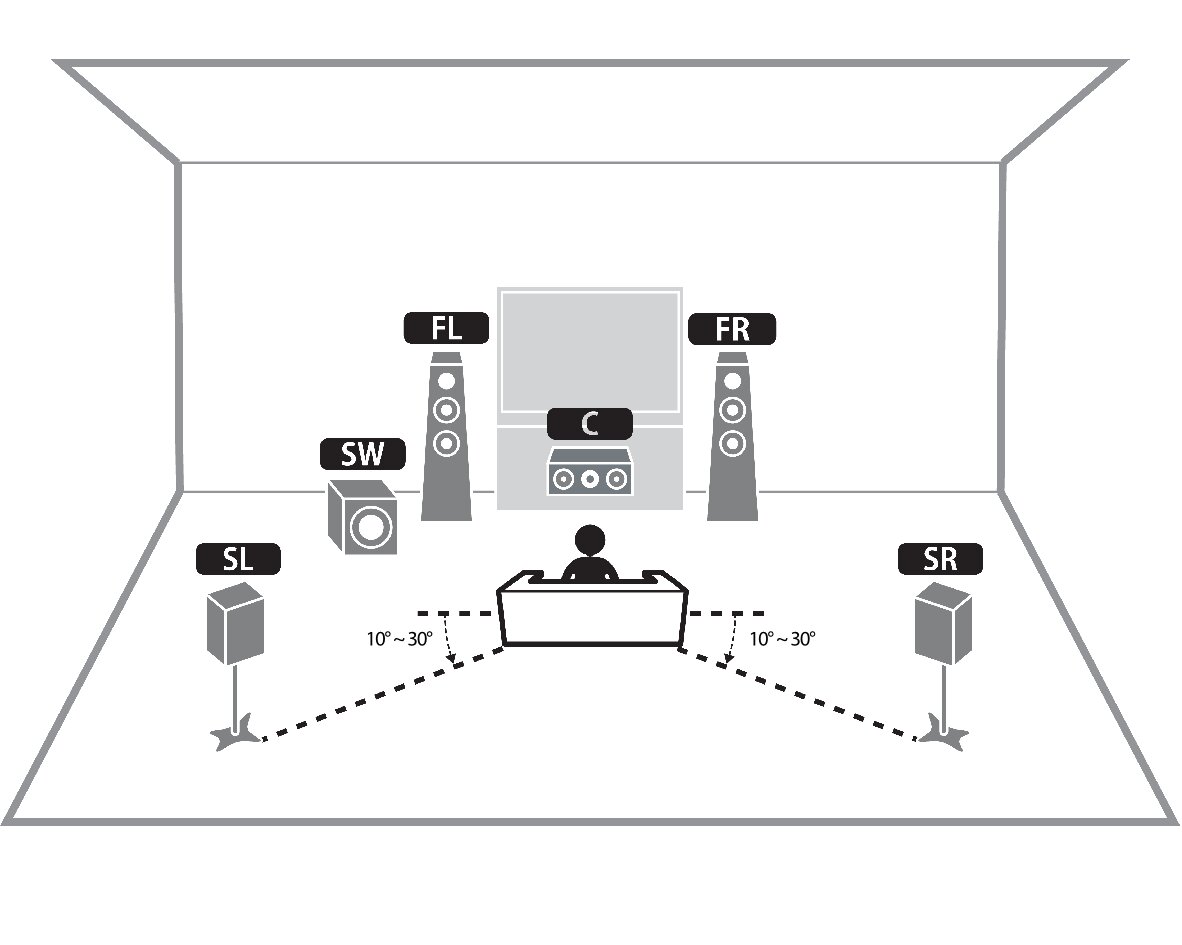
环绕声 (Surround Sound) (如 5.1, 7.1 声道)
传统的环绕声系统,如 5.1 声道和 7.1 声道,通过在听者周围布置多个扬声器,进一步扩展了声音的空间表现力。
- 5.1 声道 系统通常包含六个声道:三个前置扬声器(左前、中置、右前),两个后置或侧置环绕扬声器(左环绕、右环绕),以及一个专门用于播放低频效果 (Low-Frequency Effects, LFE) 的超低音扬声器(即“.1”声道)。中置声道主要负责人声对白,而环绕声道则用于营造环境氛围和表现来自侧面或后方的声音效果。
- 7.1 声道 系统在 5.1 的基础上增加了两个额外的环绕声道(通常是侧环绕或后中置环绕),从而能够提供更精确的声音定位和更平滑的声像移动,进一步增强包围感。
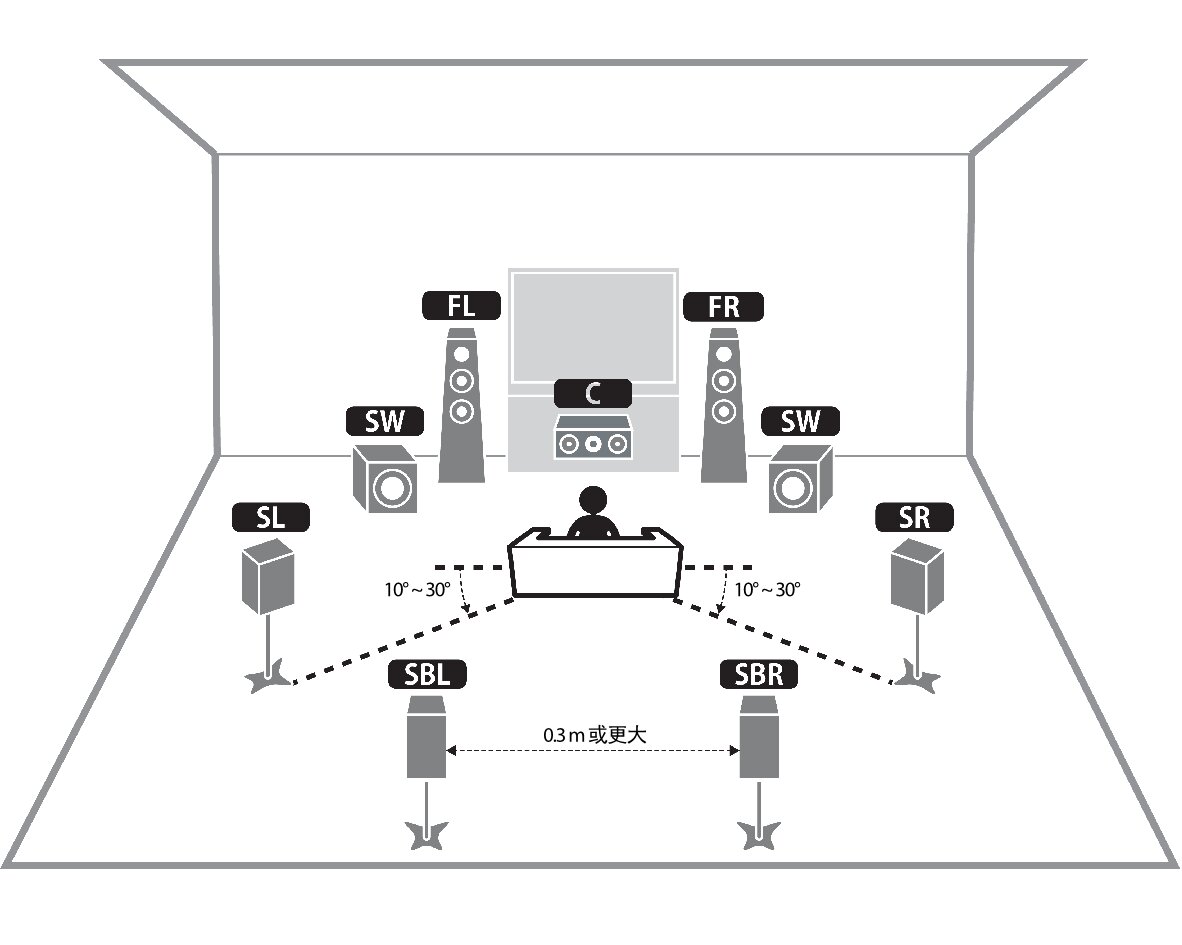
环绕声技术极大地提升了电影、游戏等视听娱乐的沉浸感,让听众感觉仿佛置身于场景之中。
空间音频与基于对象的音频简介 (如 Dolby Atmos, DTS:X)
空间音频 (Spatial Audio) 和基于对象的音频 (Object-Based Audio) 技术,如杜比全景声 (Dolby Atmos) 和 DTS:X,是沉浸式音频领域的最新进展,它们超越了传统基于声道的环绕声概念。与预先将声音混合到固定数量的声道中不同,基于对象的音频将每一个独立的声音元素(如一个人的脚步声、一架飞机的轰鸣声)视为一个“音频对象”。这些对象携带着自身的音频数据以及描述其在三维空间中精确位置和运动轨迹的元数据。在播放时,支持这些格式的音频系统(如接收器或条形音箱)会实时解读这些元数据,并根据实际可用的扬声器配置(包括顶部扬声器以实现高度感)来动态渲染这些音频对象,从而在听者周围营造出一个包含高度信息的三维声场。
从单声道到立体声,再到基于声道的环绕声,直至今日基于对象的空间音频,音频通道和播放方式的演进清晰地反映了人类对提升听觉感知真实感和沉浸感的不懈追求。单声道仅提供一个点声源,这与我们拥有双耳、能够感知声音空间方位的生理特性相去甚远。立体声的出现是一个重大进步,它通过两个声道在听者面前构建了一个具有宽度和一定定位感的声场,更好地模拟了我们的双耳听觉。基于声道的环绕声(如5.1、7.1)则将声场扩展至听者周围的二维平面,增加了前后和侧向的声音线索,显著增强了(尤其是在影院和家庭影院中)的包围感。而基于对象的空间音频(如杜比全景声、DTS:X)则通过引入高度维度,并将声音视为可在三维空间中任意定位和移动的独立“对象”,将沉浸式体验推向了新的高度。这一系列发展,其核心驱动力在于更有效地“欺骗”我们的大脑,使其将录制的声音环境感知为真实的物理空间。每一步都增加了更多的空间信息,从而带来了更具包围感和可信度的听觉体验,最终目标是让听者完全融入所听内容之中。
基于对象的音频技术代表了一种从依赖特定扬声器布局到由内容定义空间体验的范式转变。传统的基于声道的音频(如杜比数字、DTS),其混音结果与特定的扬声器配置(例如,5.1声道的混音针对5.1系统)紧密绑定。如果在扬声器数量较少的系统上播放,需要进行“下混”;如果扬声器数量更多,则可能无法充分利用所有扬声器,或需要进行“上混”。相比之下,基于对象的音频格式(如杜比全景声、DTS:X)将声音定义为包含三维位置元数据的“对象”。播放系统会实时“解码”这些元数据,“以使其空间定位适应所部署的特定扬声器阵列”。这意味着,无论听众拥有的是一套完整的 7.1.4 杜比全景声系统,还是一台支持该格式的普通条形音箱,创作者的艺术意图(例如,直升机从头顶飞过)都能得到保留和恰当的呈现。虽然不同配置下的精确度和沉浸感会有所不同,但核心的空间信息得到了有效的转换。这标志着一个根本性的转变:混音不再仅仅是一组扬声器信号,而是对声场景的描述,由播放系统根据自身能力进行解读和再现,为内容创作者提供了更大的灵活性,也为消费者带来了更具适应性的体验。
结论:音频的旅程
音频的旅程,是从最基本的物理振动开始,通过人类巧妙的感知系统被赋予意义,再经由不断发展的技术手段被捕捉、记录、处理、存储、传输和再现。我们已经探讨了声音作为压力波的物理特性,如频率、振幅、波长和相位,以及它们如何分别对应于我们感知到的音调、响度和音色。我们了解了人类听觉的范围和局限性,以及响度感知与听力安全的重要性。
技术的发展引领我们从模拟时代迈入数字时代。模拟音频以连续信号的形式记录声音,而数字音频则通过采样和量化将声音转换为离散的数字信息,其核心参数——采样率和位深度——直接决定了数字音频的保真度。为了有效地存储和传输这些数字信息,各种音频格式应运而生,从无压缩的 WAV、AIFF,到无损压缩的 FLAC、ALAC,再到广泛应用的基于心理声学模型的有损压缩格式 MP3 和 AAC,它们在音质、文件大小和应用场景之间做出了不同的权衡。
最终,我们通过不同的声道配置来体验音频,从简单的单声道、普遍的立体声,到影院级的环绕声,乃至当前最前沿的、能够营造三维沉浸式声场的空间音频技术,如杜比全景声和 DTS:X。
音频在我们的生活中无处不在,它不仅是沟通交流的基础,也是艺术表达、娱乐体验和技术创新的重要载体。展望未来,音频技术仍在不断演进。人工智能 (AI) 正在音频处理领域展现出巨大潜力,例如用于智能降噪、自动均衡、音源分离、音频修复乃至音乐创作与生成。同时,空间音频技术也在持续完善,致力于为用户带来更加逼真和个性化的沉浸式听觉盛宴。
从最初对声音物理本质的探索,到发展出能够精确复制和创造性地操控声音的复杂数字算法和沉浸式播放系统,整个音频技术领域的发展历程,是人类智慧在捕捉、处理和重塑一种基本感官体验方面不懈追求的生动证明。这种持续的创新,源于人类利用和增强声音体验以服务于沟通、艺术和娱乐的内在驱动力,彰显了音频技术作为人类重要创造领域的核心价值。