机器学习中的数据准备关键技术
有效的数据准备对于构建强大的机器学习模型至关重要。本文档总结并阐述了为监督和非监督学习任务准备数据的关键技术。
1. 理解数据类型
有两种数据类型。定性数据描述对象的特征,而定量数据描述对象的数量。
定性(分类)数据
- 名义:无序的命名类别(例如,性别,国家)。
- 无法执行算术运算。
- 使用独热编码或标签编码。
- 有序:具有自然顺序的类别(例如,满意度:低,中,高)。
- 通常用整数映射编码,保留顺序。
定量(数值)数据
- 区间:具有有意义差异的数值数据,但无真实零点(例如,摄氏温度)。
- 可以计算均值、中位数、标准差。
- 比率:具有真实零点的数值数据(例如,收入,年龄)。
- 所有算术运算有效。
离散与连续属性
- 离散:可计数的值(例如,子女数量)。
- 连续:范围内无限值(例如,身高,体重)。
2. 探索与总结数据
一旦从现实世界获取数据(数据收集),我们需要探索和总结数据(数据分析)。在这个阶段通常使用可视化来理解数据分布(数据分散度量)。
中心趋势度量
- 均值:对异常值敏感。
- 中位数:对异常值鲁棒,适用于偏态数据。
- 众数:出现频率最高的值。
分布度量
- 方差与标准差:显示数据如何围绕均值分布。
- 范围、四分位数、四分位距:帮助检测异常值和数据偏态。
3. 数据可视化
可视化数据有很多方法。以下是一些常见的方法。
在示例中,我们将使用 matplotlib 库来绘制它们。
箱线图
- 可视化五数概括:最小值,Q1,中位数,Q3,最大值。
- 突出显示超出 1.5 × 四分位距的异常值。
直方图
- 显示频率分布。
- 帮助识别偏态、模态和分布范围。
散点图
- 用于双变量关系。
- 揭示两个变量之间的相关性和模式。
交叉表
- 用于探索分类变量之间的关系。
- 在矩阵中显示频率分布。
4. 数据质量问题与修复
处理缺失值和异常值是数据准备的重要步骤。现实世界的数据往往不完美。缺失数据、异常值和其他问题需要在此步骤中解决,以实现有效的机器学习。
缺失值
- 原因:调查未响应、手动输入错误、数据损坏。
- 修复方法:
- 删除:移除缺失数据的行/列(仅在安全的情况下)。
- 插补:
- 均值/中位数(数值)
- 众数(分类)
- 基于组的插补(例如,按相似行)
- 基于模型的估计:使用预测建模或相似性函数。
删除通常在删除一些数据行不会损失太多信息时应用。这通常与 dropna() 方法相关。另一方面,插补可能是一种更实际的方法,通过为缺失数据提供人工值来保留重要数据属性,同时不影响数据分布。
什么是插补?
插补是用替代值替换缺失数据的过程。这很关键,因为大多数机器学习算法无法直接处理缺失值。
常见的插补方法:
- 均值/中位数插补:用列的均值或中位数替换缺失值。
- 适用于:无异常值的正态分布数据
- 使用场景:数据完全随机缺失时
- 基于组的插补:用组的均值/中位数替换缺失值
- 适用于:数据有意义的组
- 示例:根据汽车气缸数填充缺失的马力
- KNN插补:使用k近邻插补缺失值
- 适用于:数据存在模式
- 最准确但计算成本高
- 任意值插补:用-999等值替换
- 适用于:基于树的模型
- 使用场景:希望缺失值突出时
异常值
异常值是与其他观测值显著不同的数据点。可能由测量错误、数据输入错误或自然变异引起。
异常值的影响:
- 可能使统计度量偏斜
- 可能影响模型性能
- 可能导致模型受极端值影响过大
检测方法:
- 四分位距方法:
- 计算Q1(25th百分位)和Q3(75th百分位)
- 四分位距 = Q3 - Q1
- 下限 = Q1 - 1.5*四分位距
- 上限 = Q3 + 1.5*四分位距
- 超出这些界限的点被视为异常值
- Z分数方法:
- 计算Z分数:z = (x - 均值) / 标准差
- |z| > 3 的点通常被视为异常值
处理技术:
- 封顶(Winsorization):将异常值替换为最近的非异常值
- 转换:应用对数、平方根或其他转换
- 移除:如果异常值是错误或不具代表性
- 单独建模:为异常值创建单独的模型
5. 特征缩放
许多机器学习算法在特征具有相似尺度时表现更好或收敛更快。缩放还确保不同量级的特征不会主导模型学习。
标准化(Z分数)
x ′ = x − μ σ x' = \frac{x - \mu}{\sigma} x′=σx−μ
- 将数据中心化到均值为0,单位方差。
- 用于数据有异常值或正态分布时。
归一化(最小-最大缩放)
x ′ = x − x min x max − x min x' = \frac{x - x_{\text{min}}}{x_{\text{max}} - x_{\text{min}}} x′=xmax−xminx−xmin
- 将特征缩放到[0, 1]范围。
- 对异常值敏感。
鲁棒缩放
- 使用中位数和四分位距
- 公式:(x - 中位数) / 四分位距
- 适用于:有异常值的数据
何时缩放?
- 需要缩放的场景:
- 基于距离的算法(KNN、K均值、带RBF核的SVM)
- 神经网络
- 正则化模型(Ridge、Lasso)
- 主成分分析(PCA)
- 无需缩放的场景:
- 基于树的模型(决策树、随机森林、XGBoost)
- 朴素贝叶斯
6. 降维
减少特征数量,同时保留重要信息。
为什么降维?
- 维度灾难:随着维度增加,数据变得稀疏
- 减少过拟合:更少的特征意味着更少的参数需要学习
- 加速训练:减少计算需求
- 改进可视化:更容易可视化2D或3D数据
主成分分析(PCA)
- 将数据投影到最大化方差的主成分上
- 步骤:
- 标准化数据
- 计算协方差矩阵
- 计算特征向量和特征值
- 选择前k个特征向量
- 将数据转换到新空间
何时使用:
- 当特征相关时
- 用于可视化
- 在训练具有许多特征的模型之前
- 用于噪声减少
奇异值分解(SVD)
- 矩阵分解方法,用于识别潜在特征。
7. 特征选择
选择最相关的特征子集以:
- 减少过拟合
- 提高模型可解释性
- 降低计算成本
特征类型:
- 无关:无预测能力。
- 冗余:与其他特征重复信息。
方法:
- 过滤方法:
- 根据统计测试选择特征
- 示例:相关系数、卡方检验
- 快速但不考虑特征交互
- 包装方法:
- 使用特征子集训练模型
- 示例:递归特征消除(RFE)
- 计算成本高但更准确
- 嵌入方法:
- 特征选择作为模型训练的一部分
- 示例:Lasso回归、决策树
- 高效且准确,但特定于模型
总结表
| 任务 | 技术 |
|---|---|
| 识别变量类型 | 名义、有序、区间、比率 |
| 总结数值数据 | 均值、中位数、标准差、四分位距 |
| 可视化数据 | 直方图、箱线图、散点图 |
| 处理缺失值 | 删除、插补、预测 |
| 处理异常值 | 移除、封顶、调查 |
| 缩放特征 | 标准化、归一化 |
| 降维 | 主成分分析、奇异值分解 |
| 选择特征 | 过滤、包装、嵌入方法 |
此笔记本使用关于汽车属性和燃油效率的假数据集说明数据准备的关键技术点。
示例数据集
# 导入所需库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.preprocessing import StandardScaler, MinMaxScaler, RobustScaler
from sklearn.impute import SimpleImputer, KNNImputer
from sklearn.decomposition import PCA
from sklearn.feature_selection import SelectKBest, f_regression, RFE
from sklearn.linear_model import LinearRegression# 假数据集
data = {"car_name": ["car_a", "car_b", "car_c", "car_d", "car_e", "car_f"],"cylinders": [4, 6, 8, 4, 4, 8],"displacement": [140, 200, 360, 150, 130, 3700],"horsepower": [90, 105, 215, 92, np.nan, 220], # np (numpy - 数字Python - 用于科学计算的库。nan: 非数字/空值)"weight": [2400, 3000, 4300, 2500, 2200, 4400],"acceleration": [15.5, 14.0, 12.5, 16.0, 15.0, 11.0],"model_year": [80, 78, 76, 82, 81, 77],"origin": [1, 1, 1, 2, 3, 1],"mpg": [30.5, 24.0, 13.0, 29.5, 32.0, 10.0]
}
df = pd.DataFrame(data)
df
| car_name | cylinders | displacement | horsepower | weight | acceleration | model_year | origin | mpg | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | car_a | 4 | 140 | 90.0 | 2400 | 15.5 | 80 | 1 | 30.5 |
| 1 | car_b | 6 | 200 | 105.0 | 3000 | 14.0 | 78 | 1 | 24.0 |
| 2 | car_c | 8 | 360 | 215.0 | 4300 | 12.5 | 76 | 1 | 13.0 |
| 3 | car_d | 4 | 150 | 92.0 | 2500 | 16.0 | 82 | 2 | 29.5 |
| 4 | car_e | 4 | 130 | NaN | 2200 | 15.0 | 81 | 3 | 32.0 |
| 5 | car_f | 8 | 3700 | 220.0 | 4400 | 11.0 | 77 | 1 | 10.0 |
数据类型
car_name:名义(分类)cylinders,origin:有序/分类displacement,horsepower,weight,acceleration,mpg:比率(数值)model_year:区间
处理缺失值
# 1. 处理缺失值示例
print("=== 插补前的缺失值 ===")
print(df.isna().sum())# 均值插补
mean_imputer = SimpleImputer(strategy='mean')
df['horsepower_mean'] = mean_imputer.fit_transform(df[['horsepower']])# 基于组的插补
group_means = df.groupby('cylinders')['horsepower'].transform('mean')
df['horsepower_group'] = df['horsepower'].fillna(group_means)# KNN插补
knn_imputer = KNNImputer(n_neighbors=2)
df['horsepower_knn'] = knn_imputer.fit_transform(df[['horsepower']])print("\n=== 插补后 ===")
df[['horsepower', 'horsepower_mean', 'horsepower_group', 'horsepower_knn']]
=== 插补前的缺失值 ===
car_name 0
cylinders 0
displacement 0
horsepower 1
weight 0
acceleration 0
model_year 0
origin 0
mpg 0
dtype: int64=== 插补后 ===
| horsepower | horsepower_mean | horsepower_group | horsepower_knn | |
|---|---|---|---|---|
| 0 | 90.0 | 90.0 | 90.0 | 90.0 |
| 1 | 105.0 | 105.0 | 105.0 | 105.0 |
| 2 | 215.0 | 215.0 | 215.0 | 215.0 |
| 3 | 92.0 | 92.0 | 92.0 | 92.0 |
| 4 | NaN | 144.4 | 91.0 | 144.4 |
| 5 | 220.0 | 220.0 | 220.0 | 220.0 |
处理异常值
# 2. 处理异常值示例
def detect_and_handle_outliers(df, column):# 计算四分位距Q1 = df[column].quantile(0.25)Q3 = df[column].quantile(0.75)IQR = Q3 - Q1lower_bound = Q1 - 1.5 * IQRupper_bound = Q3 + 1.5 * IQR# 检测异常值outliers = df[(df[column] < lower_bound) | (df[column] > upper_bound)]print(f'在 {column} 中检测到 {len(outliers)} 个异常值')# 可视化前后对比plt.figure(figsize=(12, 4))plt.subplot(1, 2, 1)sns.boxplot(y=df[column])plt.title(f'原始 {column}')# 封顶异常值df[f'{column}_capped'] = np.where(df[column] > upper_bound, upper_bound,np.where(df[column] < lower_bound, lower_bound, df[column]))plt.subplot(1, 2, 2)sns.boxplot(y=df[f'{column}_capped'])plt.title(f'封顶后的 {column}')plt.tight_layout()plt.show()return dfdf = detect_and_handle_outliers(df, 'displacement')
在 displacement 中检测到 1 个异常值
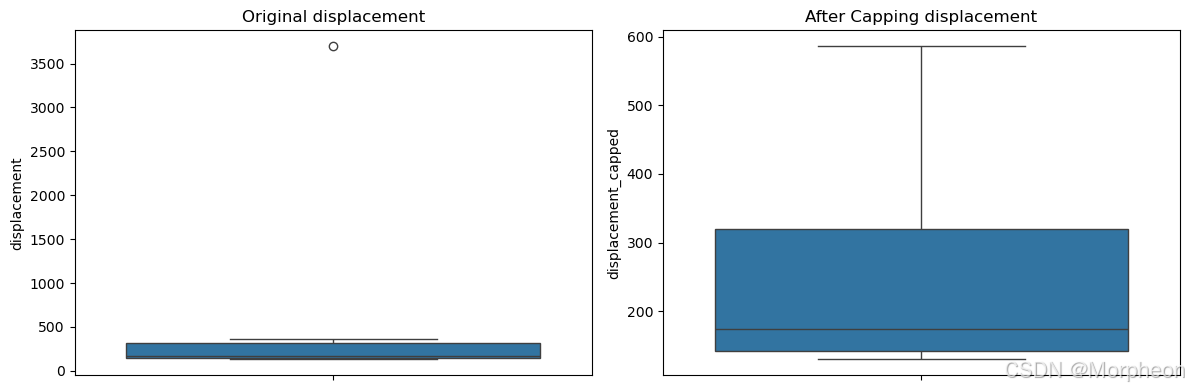
特征缩放(标准化)
# 3. 特征缩放示例
# 原始数据
numeric_cols = ['weight', 'acceleration', 'displacement']
print('原始数据:')
print(df[numeric_cols].head())# 标准化
scaler = StandardScaler()
df_std = df.copy()
df_std[numeric_cols] = scaler.fit_transform(df[numeric_cols])# 最小-最大缩放
minmax = MinMaxScaler()
df_minmax = df.copy()
df_minmax[numeric_cols] = minmax.fit_transform(df[numeric_cols])print('\n标准化数据 (均值=0, 标准差=1):')
print(df_std[numeric_cols].head())print('最小-最大缩放数据 (范围 [0,1]):')
print(df_minmax[numeric_cols].head())
原始数据:weight acceleration displacement
0 2400 15.5 140
1 3000 14.0 200
2 4300 12.5 360
3 2500 16.0 150
4 2200 15.0 130标准化数据 (均值=0, 标准差=1):weight acceleration displacement
0 -0.820462 0.854242 -0.489225
1 -0.149175 0.000000 -0.443360
2 1.305280 -0.854242 -0.321054
3 -0.708580 1.138990 -0.481581
4 -1.044224 0.569495 -0.496869
最小-最大缩放数据 (范围 [0,1]):weight acceleration displacement
0 0.090909 0.9 0.002801
1 0.363636 0.6 0.019608
2 0.954545 0.3 0.064426
3 0.136364 1.0 0.005602
4 0.000000 0.8 0.000000
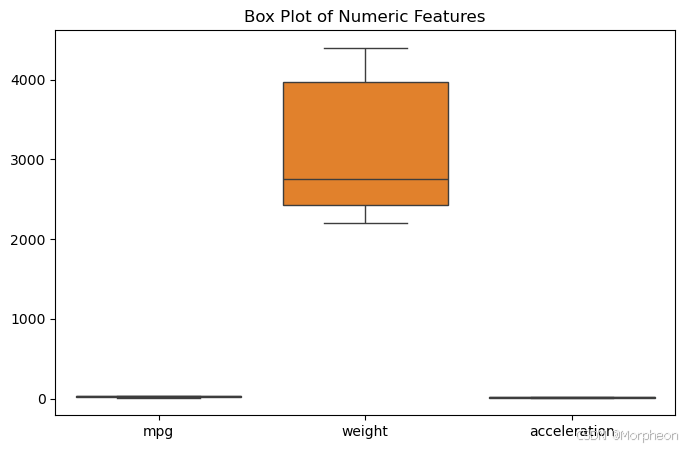
箱线图可视化
import matplotlib.pyplot as plt
import seaborn as snsplt.figure(figsize=(8, 5))
sns.boxplot(data=df[['mpg', 'weight', 'acceleration']])
plt.title("数值特征的箱线图")
plt.show()
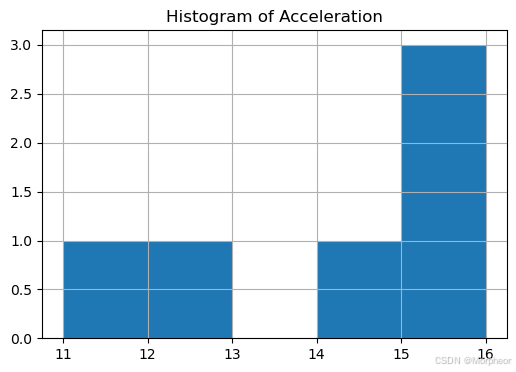
直方图
df[['acceleration']].hist(bins=5, figsize=(6, 4))
plt.title("加速直方图")
plt.show()
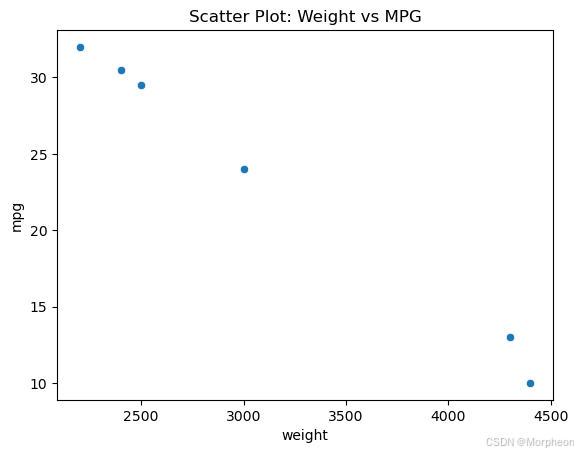
散点图
sns.scatterplot(x='weight', y='mpg', data=df)
plt.title("散点图:重量 vs 每加仑英里数")
plt.show()
交叉表
pd.crosstab(df['origin'], df['cylinders'])
| cylinders | 4 | 6 | 8 |
|---|---|---|---|
| origin | |||
| 1 | 1 | 1 | 2 |
| 2 | 1 | 0 | 0 |
| 3 | 1 | 0 | 0 |
降维(主成分分析)
# 4. 降维示例
# 准备PCA数据
X = df[['weight', 'acceleration', 'displacement_capped']]
y = df['mpg']# 首先标准化数据
X_scaled = StandardScaler().fit_transform(X)# 应用PCA
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X_scaled)# 创建主成分的新数据框
df_pca = pd.DataFrame(data=X_pca, columns=['PC1', 'PC2'])
df_pca['mpg'] = y.values# 绘制结果
plt.figure(figsize=(8, 6))
scatter = plt.scatter(df_pca['PC1'], df_pca['PC2'], c=df_pca['mpg'], cmap='viridis')
plt.xlabel('第一主成分')
plt.ylabel('第二主成分')
plt.colorbar(scatter, label='每加仑英里数')
plt.title('汽车特征的PCA')
plt.show()print(f'解释方差比例: {pca.explained_variance_ratio_}')
print(f'总解释方差: {sum(pca.explained_variance_ratio_):.2f}%')
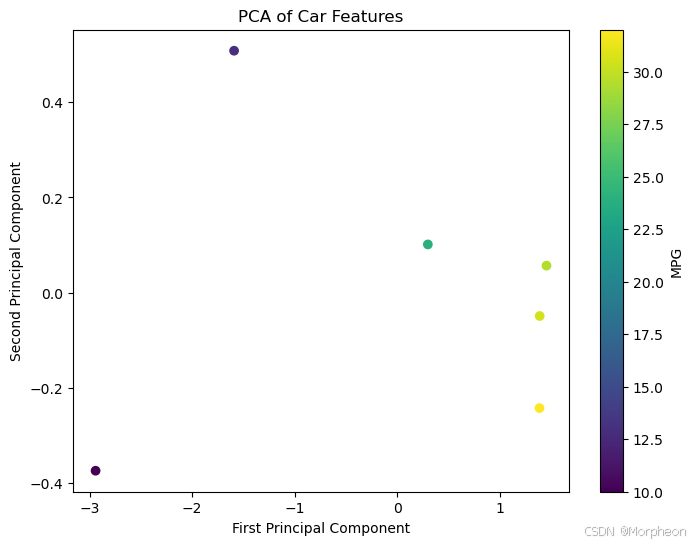
解释方差比例: [0.95929265 0.02632386]
总解释方差: 0.99%
特征选择
如果通过特征重要性技术发现 car_name 或 model_year 无关,我们可能会删除它们。