【6-7-6.14学习周报】
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 摘要
- Abstract
- 一、理论方法
- 二、实验
- 1.实验概况
- 2.实验代码
- 3.实验结果
- 总结
摘要
本博客介绍了论文《Text Classification in Memristor-based Spiking
Neural Networks》开发了一个基于经验忆阻器模型的仿真框架,用于进行基于忆阻器的脉冲神经网络(SNN)文本分类任务。提出两种获取训练好的基于忆阻器SNN的方法:将预训练的人工神经网络(ANN)转换为SNN;直接训练SNN。通过IMDB影评数据集的情感分析任务验证这两种方法,并研究全局参数对系统性能的影响。
Abstract
This blog introduces the paper ‘Text Classification in Memristor-based Spiking Neural Networks’, which developed a simulation framework based on empirical memristor models for text classification tasks using memristor-based spiking neural networks (SNNs). Two methods for obtaining trained memristor-based SNNs are proposed: converting a pre-trained artificial neural network (ANN) to SNN; and directly training the SNN. The effectiveness of these two methods is validated through the sentiment analysis task using the IMDB movie review dataset, and the study investigates the impact of global parameters on system performance.
一、理论方法
ANN和SNN之间的主要区别在于传输方法:ANN使用连续值,而SNN使用0或-1脉冲。因此,弥合两个神经网络架构之间的差距的基本思想是找到将连续值映射到尖峰的关系。
SNN的尖峰速率与ANN等效物的ReLU激活输出成比例,其中误差项在浅层网络中是可消除的。考虑到在基于忆阻器的SNN中输入和权重被限制在[0,1]内,ReLU激活输出总是非负的。因此,SNN的尖峰速率与输入电流成比例。
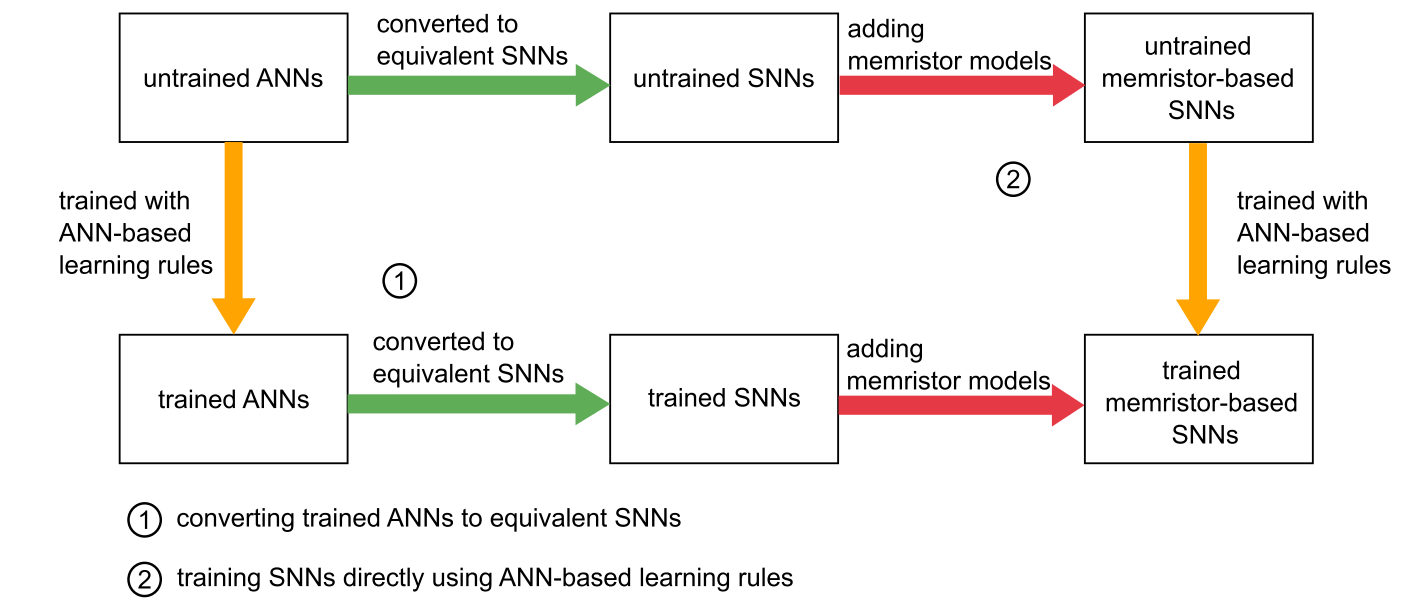
从未训练的ANN开始,方法1使用典型的基于ANN的学习规则训练ANN,然后将训练的ANN转换为训练的SNN;方法2首先将ANN转换为等效的SNN,然后使用基于ANN的学习规则进行训练。在获得训练的SNN之后,添加忆阻器模型以存储权重。
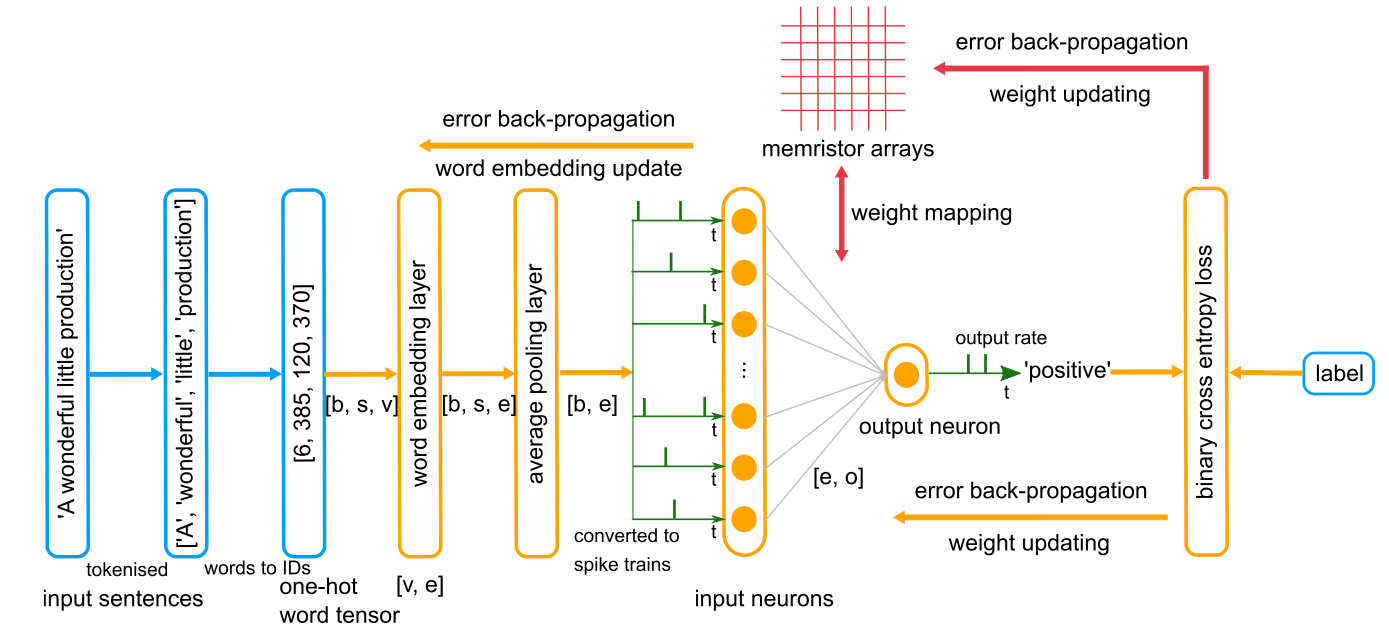
用于在IMDB评审数据集中执行情感分析任务的模拟框架的工作流程。输入、ANN结构、SNN指定的结构和忆阻器相关模块分别用蓝色、橙子、绿色和红色表示。B、s、e和o分别表示批量大小、句子长度、单词嵌入维数和输出维数。我们使用电影评论"A wonderful little production“作为示例来解释输入预处理过程:首先,将输入句子标记为单词列表(在该示例中为”[“A”、“wonderful”、“little”、“production”]“)。其次,单词列表被转换成单词ID的列表(在该示例中为“[6,385,120,370]”)。同一批中的句子将被填充为具有相同的长度。该算法将单词列表进一步转换为单热向量,并将同一批句子的填充单热向量打包成一个大小为(B × s × v)的输入表示张量.值得注意的是,在Pytorch中,单词ID列表不需要被转换为one-hot表示。
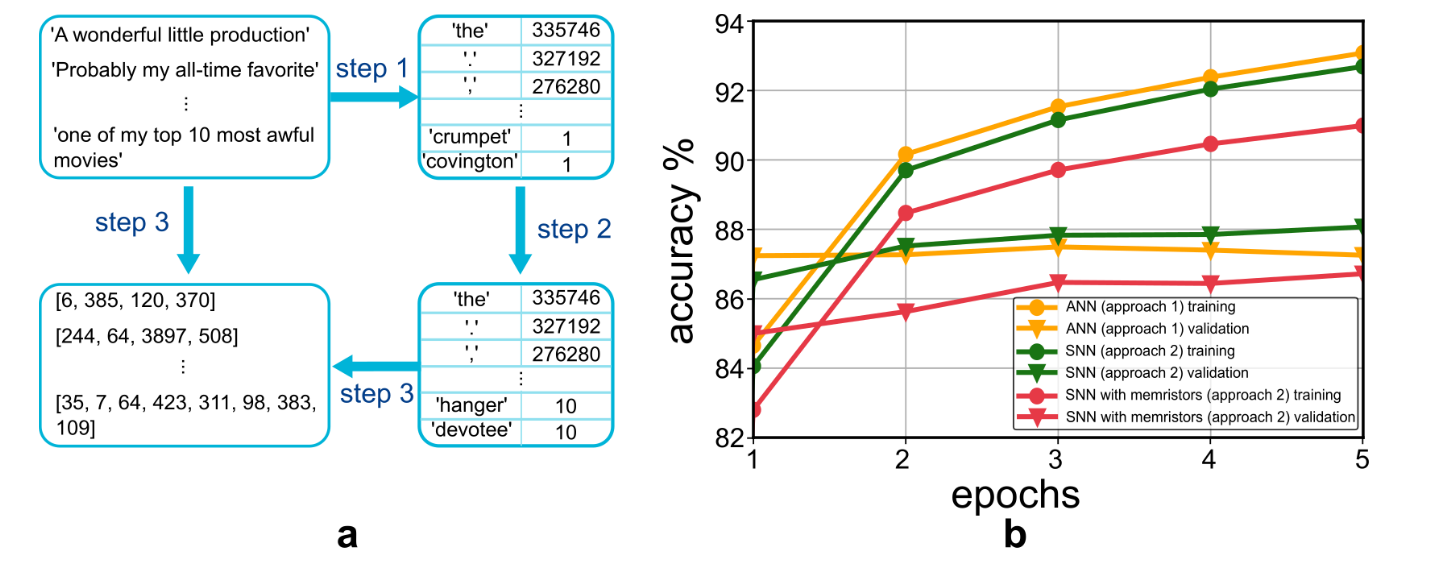
使用训练样本构建词汇表。步骤1:创建一个查找表来存储词频。第二步:省略出现次数少于10次的单词,以减少词汇量。步骤3:迭代所有样本,使用词汇表将它们转换为单词ID。如果在词汇表中找不到单词,则将其标记为“[unk]”。当打包成批次时,同一批次中的样本使用“[pad]”标记填充,以具有相同的句子长度。(b)ANN(方法1)、SNN(方法2)和具有忆阻器模型的SNN(方法2)中的训练和验证精度演变曲线。
二、实验
1.实验概况
研究者使用IMDB电影评论数据集演示了一个情感分析任务,以验证两种方法来获得一个经过训练的基于忆阻器的SNN。该数据集包括25k高极性电影评论训练样本和25k测试样本。
2.实验代码
完整项目链接:https://github.com/hjq310/text-
classification-in-memristorsnn
以下展示基于忆阻器SNN的训练代码:
import torch
import torch.nn as nn
from torch import nn
import torch.nn.functional as F
import time
from rram_array import rram_array, WtoRS, RStoWdevice = torch.device("cuda" if torch.cuda.is_available() else "cpu")class SNN(nn.Module):def __init__(self, wordemb_matrix, output_dim, T, thres, lr, xbar, MaxN, RTolerance, Readout, Vread, Vpw, \readnoise, w, b, Ap, An, a0p, a0n, a1p, a1n, tp, tn, Rinit, Rvar, dt, Rmax, Rmin, \pos_pulselist, neg_pulselist):super().__init__()self.device = deviceself.vocab_size, self.embedding_dim = wordemb_matrix.shape[0], wordemb_matrix.shape[1]self.embedding = nn.Embedding(self.vocab_size, self.embedding_dim)self.embedding.load_state_dict({'weight': wordemb_matrix})self.embedding.weight.requires_grad = Falseself.output_dim = output_dimself.fc = nn.Linear(self.embedding_dim, self.output_dim, bias = False)self.fc.weight.requires_grad = Falseself.T = Tself.lr = lrself.fc_s = 0self.emb_s = 0self.ep = 1e-10self.thres= thresself.xbar = xbarself.MaxN = MaxNself.RTolerance = RToleranceself.readout = Readoutself.Vread = Vreadself.Vpw = Vpwself.readnoise = readnoiseself.w = wself.b = bself.Ap = Apself.An = Anself.a0p = a0pself.a0n = a0nself.a1p = a1pself.a1n = a1nself.tp = tpself.tn = tnself.Rinit = Rinitself.Rvar = Rvarself.dt = dtself.Rmax = Rmaxself.Rmin = Rminself.pos_pulselist = pos_pulselistself.neg_pulselist = neg_pulselistself.rramArray = rram_array(self.w, self.b, self.Ap, self.An, self.a0p, self.a0n, self.a1p, self.a1n, \self.tp, self.tn, self.Rinit, self.Rvar, self.dt)self.memristorRS = self.rramArray.read(Readout = self.readout, Vread = self.Vread, \Vpw = self.Vpw, readnoise = self.readnoise)self.memristorWeight = RStoW(self.memristorRS.flatten(), self.Rmax, self.Rmin).reshape(-1, self.fc.weight.shape[1])self.memristorWeight.clamp_(0, 1)#torch.nn.init.uniform_(self.memristorWeight).to(self.device)self.fc.load_state_dict({'weight': self.memristorWeight})def initVariables(self, batch_size, output_dim, TLen):self.membraneV = torch.zeros(batch_size, output_dim, TLen).to(device)self.spikes = torch.zeros(batch_size, output_dim, TLen).to(device)def forward(self, text):self.text = textself.batch_size, self.sentLen = self.text.shape[0], self.text.shape[1]self.embedded = self.embedding(self.text) # [batch size, sent len, emb dim]self.pooled = F.avg_pool2d(self.embedded, (self.embedded.shape[1], 1)).squeeze(1) # [batch size, embedding_dim]self.rand_matrix = torch.rand(self.batch_size, self.embedding_dim, self.T).to(device) # [batch size, embedding_dim, T]self.inputSpike = (self.pooled.unsqueeze(2).expand(-1, -1, self.T) > self.rand_matrix).float() # [batch size, embedding_dim, T]self.initVariables(self.batch_size, self.output_dim, self.T)if self.xbar:for t in range(self.T):self.memristorRS = self.rramArray.read(Readout = self.readout, Vread = self.Vread, \Vpw = self.Vpw, readnoise = self.readnoise)self.memristorWeight = RStoW(self.memristorRS.flatten(), self.Rmax, self.Rmin).reshape(-1, self.fc.weight.shape[1])self.memristorWeight.clamp_(0, 1)if t == 0:self.membraneV[:, :, t] = torch.mm(self.inputSpike[:, :, t], self.memristorWeight.t())else:self.membraneV[:, :, t] = self.membraneV[:, :, t-1] - self.spikes[:, :, t-1] * self.thres + \torch.mm(self.inputSpike[:, :, t], self.memristorWeight.t())self.spikes = (self.membraneV > self.thres).float()else:for t in range(self.T):if t == 0:self.membraneV[:, :, t] = torch.mm(self.inputSpike[:, :, t], self.fc.weight.t())else:self.membraneV[:, :, t] = self.membraneV[:, :, t-1] - self.spikes[:, :, t-1] * self.thres + \torch.mm(self.inputSpike[:, :, t], self.fc.weight.t())self.spikes = (self.membraneV > self.thres).float()self.spikeRate = torch.sum(self.spikes, dim = 2) / self.Tself.result = self.embedding_dim * (self.spikeRate.squeeze(1) - 0.5) / 2return self.resultdef plast(self, label):self.label = labelself.delta = (torch.sigmoid(self.result) - label).unsqueeze(1) / self.batch_sizeself.fc_grad = torch.sum(torch.bmm(self.delta.unsqueeze(2), self.pooled.unsqueeze(1)), dim=0) # [emb_dim, output_dim]self.fc_s += self.fc_grad ** 2if self.xbar:self.emb_grad = torch.mm(self.delta, self.memristorWeight)self.memristorWeight_expected = self.memristorWeight - self.lr * self.fc_grad / (self.fc_s ** 0.5 + self.ep)self.memristorRS_expected = WtoRS(self.memristorWeight_expected, self.Rmax, self.Rmin)print('expected R:', float(self.memristorRS_expected[0, 0]))self.rramArray.write(self.memristorRS_expected.reshape(self.w, self.b), self.pos_pulselist, self.neg_pulselist, \MaxN = self.MaxN, RTolerance = self.RTolerance, Readout = self.readout, Vread = self.Vread, \Vpw = self.Vpw, readnoise = self.readnoise)print('updated R:', float(self.rramArray.R[0, 0]))print('R diff:', float(self.rramArray.R[0, 0]) - float(self.memristorRS_expected[0, 0]))else:self.emb_grad = torch.mm(self.delta, self.fc.weight)self.fc.weight.data = self.fc.weight.data - self.lr * self.fc_grad / (self.fc_s ** 0.5 + self.ep)self.fc.weight.data.clamp_(0, 1)self.input = torch.bincount(self.text.flatten(), minlength = self.vocab_size).float() / (self.sentLen * self.batch_size)self.emb_grad = torch.sum(torch.mm(self.emb_grad.reshape(-1, 1), self.input.reshape(1, -1)).reshape(self.batch_size, self.embedding_dim, -1), dim = 0).t()self.emb_s += self.emb_grad ** 2self.embedding.weight.data = self.embedding.weight.data - self.lr * self.emb_grad / (self.emb_s ** 0.5 + self.ep)self.embedding.weight.data.clamp_(0, 1)def network_init(seed, wordemb_matrix, output_dim, T, thres, lr, xbar, MaxN, RTolerance, Readout, Vread, Vpw, readnoise, \w, b, Ap, An, a0p, a0n, a1p, a1n, tp, tn, Rinit, Rvar, dt, Rmax, Rmin, pos_pulselist, neg_pulselist):torch.manual_seed(seed)torch.cuda.manual_seed(seed)modelSNN = SNN(wordemb_matrix, output_dim, T, thres, lr, xbar, MaxN, RTolerance, Readout, Vread, Vpw, readnoise, w, b, \Ap, An, a0p, a0n, a1p, a1n, tp, tn, Rinit, Rvar, dt, Rmax, Rmin, pos_pulselist, neg_pulselist)print('initial weight:', float(modelSNN.memristorWeight[0, 0]))modelSNN = modelSNN.to(device)criterionSNN = nn.BCEWithLogitsLoss()return modelSNN, criterionSNNdef binary_accuracySNN(preds, y):rounded_preds = torch.round(torch.sigmoid(preds))correct = (rounded_preds == y).float()acc = correct.sum()/len(correct)return accdef trainSNN(model, iterator, criterionSNN):epoch_loss = 0epoch_acc = 0model.eval()with torch.no_grad():for _, (label, text) in enumerate(iterator):predictions = model(text)model.plast(label)loss = criterionSNN(predictions, label.float())acc = binary_accuracySNN(predictions, label)epoch_loss += loss.item()epoch_acc += acc.item()return epoch_loss / len(iterator), epoch_acc / len(iterator)def evaSNN(model, iterator, criterionSNN):epoch_loss = 0epoch_acc = 0model.eval()with torch.no_grad():for _, (label, text) in enumerate(iterator):predictions = model(text)loss = criterionSNN(predictions, label.float())acc = binary_accuracySNN(predictions, label)epoch_loss += loss.item()epoch_acc += acc.item()return epoch_loss / len(iterator), epoch_acc / len(iterator)def epoch_time(start_time, end_time):elapsed_time = end_time - start_timeelapsed_mins = int(elapsed_time / 60)elapsed_secs = int(elapsed_time - (elapsed_mins * 60))return elapsed_mins, elapsed_secsdef snntrain(N_EPOCHS, train_dataloader, valid_dataloader, modelSNN, criterionSNN):best_valid_loss = float('inf')for epoch in range(N_EPOCHS):start_time = time.time()train_loss, train_acc = trainSNN(modelSNN, train_dataloader, criterionSNN)valid_loss, valid_acc = evaSNN(modelSNN, valid_dataloader, criterionSNN)end_time = time.time()epoch_mins, epoch_secs = epoch_time(start_time, end_time)if valid_loss < best_valid_loss:best_valid_loss = valid_losstorch.save(modelSNN.state_dict(), 'best-snntrainingmodel.pt')print(f'Epoch: {epoch+1:02} | Epoch Time: {epoch_mins}m {epoch_secs}s')print(f'\t Val. Loss: {train_loss:.3f} | Train. Acc: {train_acc*100:.2f}%')print(f'\t Val. Loss: {valid_loss:.3f} | Val. Acc: {valid_acc*100:.2f}%')def snntest(test_dataloader, modelSNN, criterionSNN):start_time = time.time()modelSNN.load_state_dict(torch.load('best-snntrainingmodel.pt'))test_loss, test_acc = evaSNN(modelSNN, test_dataloader, criterionSNN)end_time = time.time()epoch_mins, epoch_secs = epoch_time(start_time, end_time)print(f'Time: {epoch_mins}m {epoch_secs}s')print(f'\t test. Loss: {test_loss:.3f} | test. Acc: {test_acc*100:.2f}%')def snntraining(N_EPOCHS, seed, wordemb_matrix, output_dim, T, thres, lr, xbar, \MaxN, RTolerance, Readout, Vread, Vpw, readnoise, w, b, Ap, An, a0p, a0n, \a1p, a1n, tp, tn, Rinit, Rvar, dt, Rmax, Rmin, pos_pulselist, neg_pulselist,\train_dataloader, valid_dataloader, test_dataloader):modelSNN, criterionSNN = network_init(seed, wordemb_matrix, output_dim, T, thres, lr, \xbar, MaxN, RTolerance, Readout, Vread, Vpw, readnoise, \w, b, Ap, An, a0p, a0n, a1p, a1n, tp, tn, Rinit, Rvar,\dt, Rmax, Rmin, pos_pulselist, neg_pulselist)print('snn initialised!')snntrain(N_EPOCHS, train_dataloader, valid_dataloader, modelSNN, criterionSNN)print('snn trained!')snntest(test_dataloader, modelSNN, criterionSNN)print('snn tested!')
3.实验结果
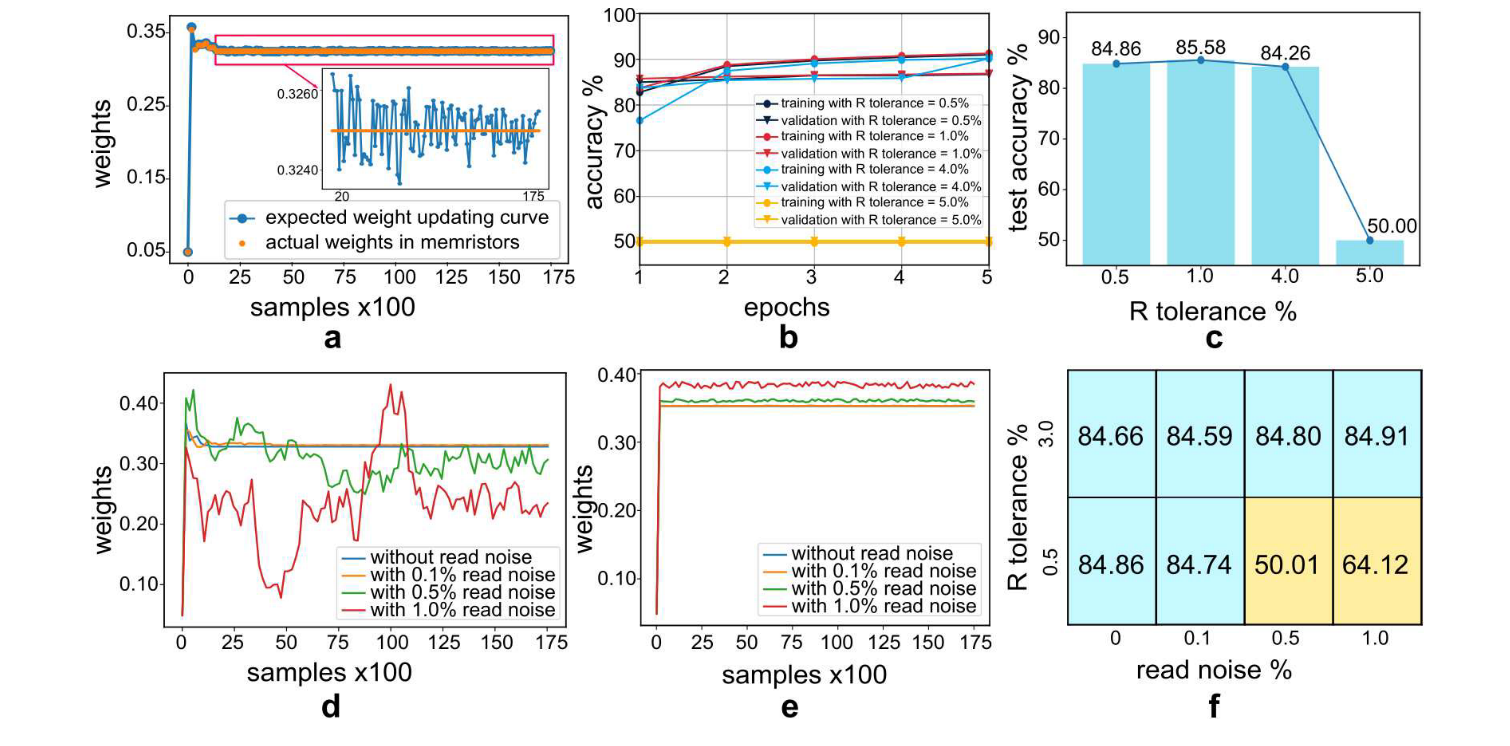
研究者实现了85.88%和84.86%的测试精度从这两种方法只有0.14%和1.16%的退化,分别给出了86.02%的基线精度从等效的人工神经网络。最后,我们研究了SNN的随机性和忆阻器的非理想性如何影响系统的性能。

结果分析,用于直接训练基于忆阻器的SNN。(a)训练时期1期间单层SNN中突触0的权重演化曲线。每175个样品绘制曲线。计算出的预期权重以蓝色绘制,映射到忆阻器阵列的实际权重以橙子绘制。值得注意的是,一旦所请求的更新下降到R容限以下,忆阻器件就停止更新。(B)-(c)不同R容差值的训练/验证和测试精度。(d)-(e)当R容限为0.5%和3.0%时,在训练时期1中具有不同读取噪声值的突触0的测量权重演变。蓝色曲线是没有读取噪声的基线。每175个样品绘制重量。(f)具有不同读取噪声值(x轴)和不同R容差(y轴)的测试准确度(%)的Shmoo图。阳性和阴性结果分别为蓝色和黄色。
总结
开发的仿真框架可实现基于忆阻器的SNN文本分类任务。两种方法与等效ANN相比,分类准确率下降较小,在仿真中可实现相似性能。还研究了全局参数对系统性能的影响。
可进一步优化仿真框架,提高分类准确率;探索更多基于忆阻器的SNN学习规则;在硬件上实现基于忆阻器的SNN文本分类,验证仿真结果。