Day 47 训练
Day47 训练
为什么需要注意力热力图?
模型解释性:理解模型为何做出特定预测。例如,一个猫狗分类器在识别猫时,是真的关注了猫的耳朵、胡须,还是仅仅因为背景中的某个巧合?
调试模型:如果模型关注了不相关的区域(比如背景噪声),这可能意味着模型训练不足或数据集存在偏差。
建立信任:在医疗诊断等关键应用中,了解模型的决策依据至关重要。
代码解读:一步步实现注意力可视化
让我们来看看这段神奇的代码是如何工作的:
python
复制代码
import torch
import numpy as np
import matplotlib.pyplot as plt
from scipy.ndimage import zoom # 用于调整热力图大小
```dart
# 假设我们已经有了 model, test_loader, device, class_names
# model: 训练好的CNN模型
# test_loader: 测试数据加载器
# device: 'cuda' or 'cpu'
# class_names: 类别名称列表def visualize_attention_map(model, test_loader, device, class_names, num_samples=3):"""可视化模型的注意力热力图,展示模型关注的图像区域"""model.eval() # 1. 设置为评估模式with torch.no_grad(): # 2. 关闭梯度计算for i, (images, labels) in enumerate(test_loader):if i >= num_samples: # 只可视化前几个样本breakimages, labels = images.to(device), labels.to(device)# 3. 创建一个钩子,捕获中间特征图activation_maps = []def hook(module, input, output):activation_maps.append(output.cpu())# 4. 为目标卷积层注册钩子(这里假设是model.conv3)# 你需要根据你的模型结构选择一个合适的卷积层,通常是较深层的卷积层# 例如:hook_handle = model.layer4[-1].conv3.register_forward_hook(hook) # 对于ResNet# 这里我们遵循原始代码,假设模型有一个名为 conv3 的层if hasattr(model, 'conv3'): # 确保模型有 conv3 属性hook_handle = model.conv3.register_forward_hook(hook)else:# 如果没有 conv3,可以选择模型中最后一个卷积层或一个有意义的深层卷积层# 这部分需要根据具体模型结构进行修改# 例如,对于一个简单的 Sequential 模型,可能是 model[-2] 或 model.features[-1]# 此处为了示例,我们尝试获取最后一个模块,但实际应用中需要更精确的定位target_layer = Nonefor layer in reversed(list(model.children())): # 尝试找到最后一个卷积层if isinstance(layer, torch.nn.Conv2d):target_layer = layerbreakelif hasattr(layer, '__iter__'): # 处理Sequential等容器for sub_layer in reversed(list(layer.children())):if isinstance(sub_layer, torch.nn.Conv2d):target_layer = sub_layerbreakif target_layer:breakif target_layer:print(f"Hook registered on layer: {target_layer}")hook_handle = target_layer.register_forward_hook(hook)else:print("Error: Could not find a suitable Conv2d layer to attach hook. Please specify.")return# 5. 前向传播,触发钩子outputs = model(images)# 6. 移除钩子hook_handle.remove()# 7. 获取预测结果_, predicted = torch.max(outputs, 1)# 8. 获取并处理原始图像img_tensor = images[0].cpu().permute(1, 2, 0) # 取第一个样本,并转换维度顺序# 反标准化处理 (这里的均值和标准差需要与你训练时使用的一致)# 假设 CIFAR10 的均值和标准差mean = np.array([0.4914, 0.4822, 0.4465])std = np.array([0.2023, 0.1994, 0.2010])img = img_tensor.numpy() * std.reshape(1, 1, 3) + mean.reshape(1, 1, 3)img = np.clip(img, 0, 1) # 确保像素值在[0,1]范围内# 9. 获取激活图(目标卷积层的输出)feature_map = activation_maps[0][0].cpu() # 取第一个样本的激活图# 10. 计算通道“重要性”权重(这里使用全局平均池化作为一种简化方式)channel_weights = torch.mean(feature_map, dim=(1, 2)) # 形状: [C]# 11. 按权重对通道排序,获取最重要的通道sorted_indices = torch.argsort(channel_weights, descending=True)# 12. 创建子图进行可视化fig, axes = plt.subplots(1, 4, figsize=(16, 4)) # 1行4列,显示原图和3个热力图# 显示原始图像axes[0].imshow(img)axes[0].set_title(f'原始图像\n真实: {class_names[labels[0].item()]}\n预测: {class_names[predicted[0].item()]}')axes[0].axis('off')# 显示前3个最活跃通道的热力图for j in range(min(3, len(sorted_indices))): # 最多显示3个或实际通道数channel_idx = sorted_indices[j]# 获取对应通道的特征图channel_map = feature_map[channel_idx].numpy()# 归一化到[0,1]以便可视化channel_map_normalized = (channel_map - channel_map.min()) / (channel_map.max() - channel_map.min() + 1e-8) # 防止除零# 调整热力图大小以匹配原始图像 (假设原始图像是32x32)# 这里需要根据你的输入图像大小和特征图大小动态调整# 例如,如果原始图像是 H_img x W_img,特征图是 H_fm x W_fm# heatmap_resized = zoom(channel_map_normalized, (H_img/H_fm, W_img/W_fm))# 假设原始图像是32x32,这里我们用图像的实际高宽img_height, img_width, _ = img.shapefm_height, fm_width = channel_map_normalized.shapeheatmap_resized = zoom(channel_map_normalized, (img_height/fm_height, img_width/fm_width))# 显示热力图axes[j+1].imshow(img) # 先画原图作为背景axes[j+1].imshow(heatmap_resized, alpha=0.5, cmap='jet') # 再叠加半透明热力图axes[j+1].set_title(f'注意力热力图 - 通道 {channel_idx.item()}')axes[j+1].axis('off')plt.tight_layout()plt.show()# 假设你已经定义好了 model, test_loader, device, class_names
# class_names = ['plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck'] # CIFAR10示例
# 调用可视化函数
# visualize_attention_map(model, test_loader, device, class_names, num_samples=3)
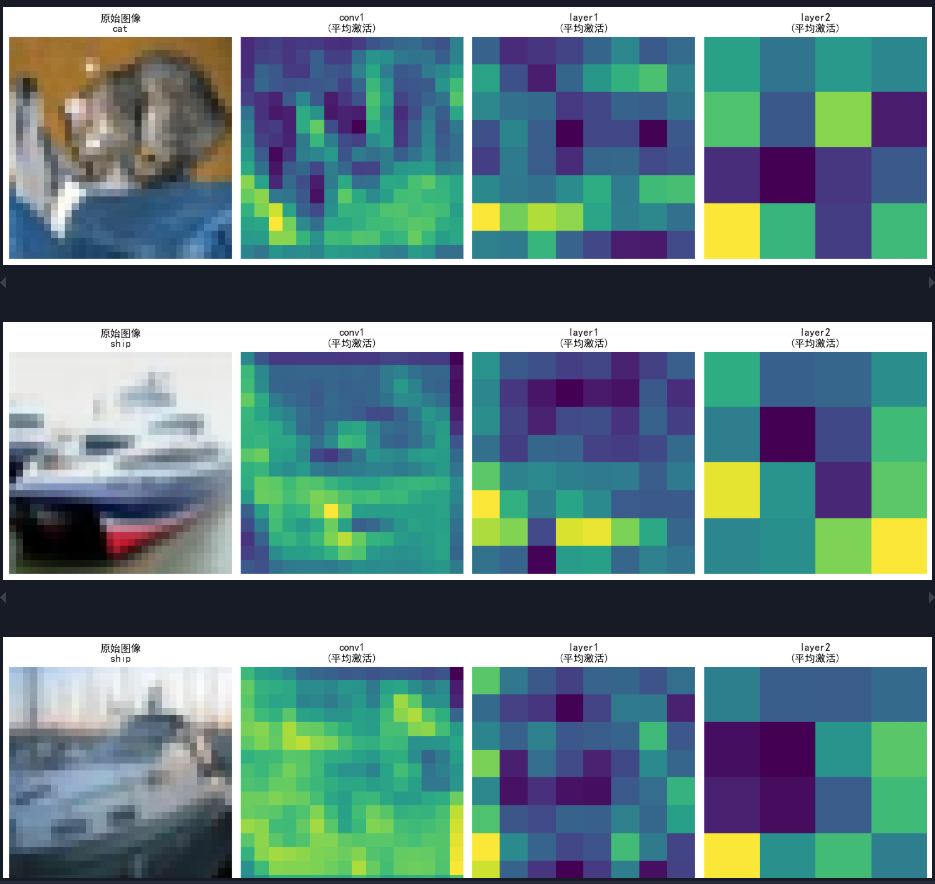
核心步骤解析:
model.eval():将模型设置为评估模式。这会关闭 Dropout 和 BatchNorm 的更新行为,确保评估结果的一致性。
torch.no_grad():在该上下文管理器中,所有计算都不会追踪梯度,从而减少内存消耗并加速计算,因为我们只是进行前向传播获取特征图,不需要反向传播。
钩子(Hook):这是PyTorch中一个强大的特性。register_forward_hook 允许我们在模块(比如一个卷积层)完成前向传播后,立即执行一个自定义函数(hook函数)。这个hook函数可以访问模块的输入和输出。在这里,我们用它来捕获目标卷积层(model.conv3)输出的特征图(activation_maps)。
选择哪个层? 通常选择模型中较深层的卷积层,因为它们通常能学习到更高级、更抽象的语义特征。代码中使用了model.conv3,你需要根据你自己的模型结构来指定。我添加了一些逻辑来尝试自动查找最后一个卷积层,但这部分在实际应用中可能需要根据具体模型精确指定。
前向传播:执行outputs = model(images),这会正常计算模型的输出,并在经过model.conv3时触发我们注册的钩子,从而将特征图存入activation_maps。
移除钩子:hook_handle.remove() 是一个好习惯,确保钩子在完成任务后被移除,避免不必要的开销或意外行为。
图像反标准化:训练时,图像通常会进行标准化处理(减去均值,除以标准差)。为了正确显示原始图像,我们需要进行反向操作。代码中的均值和标准差 [0.2023, 0.1994, 0.2010] 和 [0.4914, 0.4822, 0.4465] 应该是你训练时所用的值(注意:原始代码中的均值和标准差顺序可能需要调整,通常是 img * std + mean)。我这里使用了CIFAR10常用的均值和标准差作为示例。
特征图提取:activation_maps[0][0] 表示获取第一个样本([0])的、由钩子捕获的第一个(也是唯一一个)输出特征图([0])。
通道“重要性”:torch.mean(feature_map, dim=(1, 2)) 对每个通道的特征图在空间维度(高和宽)上取平均值。这可以看作是一种简化的方式来衡量每个通道的整体激活强度。激活强度越高的通道,可能对最终的决策贡献越大(这是一种启发式方法,更复杂的方法如Grad-CAM会使用梯度信息)。
排序与选择:通过torch.argsort找到平均激活值最高的几个通道。
热力图生成与叠加:
对选定通道的特征图进行归一化处理,使其值在 [0, 1] 范围内,方便映射为颜色。
使用 scipy.ndimage.zoom 将较小的特征图上采样(放大)到与原始图像相同的大小。
使用 matplotlib.pyplot.imshow 将原始图像和调整大小后的热力图叠加显示。alpha=0.5 设置热力图的透明度,cmap=‘jet’ 使用常见的“jet”色谱,从蓝(低)到红(高)表示注意力强度。
如何解读热力图?
生成的图像会包含:
左侧:原始图像,以及模型的真实标签和预测标签。
右侧(多个):原始图像上叠加了不同通道产生的注意力热力图。
热力图中的红色区域表示该通道在该位置的激活值较高,可以理解为模型在做决策时,对这些区域“更感兴趣”或“更关注”。通过观察这些高亮区域是否与图像中物体的关键部分相对应,我们就能对模型的行为有更深入的了解。
例如,如果模型在识别一只鸟,我们期望热力图能够高亮鸟的头部、翅膀等关键部位。如果热力图高亮了背景中的无关物体,那可能说明模型学到了一些 spurious correlations(虚假关联)。
进一步的思考
虽然这种方法为我们提供了一个观察模型内部的窗口,但它也有其局限性:
它显示的是特定通道的激活,而不是所有通道综合作用的结果。
“通道重要性”的计算方式(全局平均池化)相对简单。
更高级的技术,如类激活映射(CAM)、梯度加权类激活映射(Grad-CAM)及其变种(Grad-CAM++, Score-CAM等),通过结合梯度信息来计算特征图的权重,通常能提供更精确、更与类别相关的注意力可视化。
总结
通过钩子捕获中间层特征图,并对其进行可视化,我们能够一窥CNN的“内心世界”。这不仅满足了我们对AI工作原理的好奇心,更重要的是,它为模型调试、提升模型性能和建立对AI系统信任提供了有力的工具。
@浙大疏锦行