网络原理9-HTTP2
HTTP请求
认识URL
URL基本格式‘
URL不仅仅是在HTTP中使用,我们在之前的JDBC中与数据库建立连接时也使用过URL:jdbc:mysql://127.0.0.1:3306/java110?characterEncoding=utf8&useSSL=false
平时我们俗称的“网址”,其实说的就是URL(统一资源定位符),它能够描述一个互联网上的资源的位置,即互联网上的每个文件都有一个唯一的URL,它包含的信息指出了文件的位置以及浏览器应该怎去处理它。(URL的详细规则由因特网表述RFC1738进行约定)
我们之前的https://cn.bing.com(只有搜索功能的必应,实际上会有广告、图片等),是一个最简单的URL,https是协议的名称,cn.bing.com是域名。
实际上必应的URL: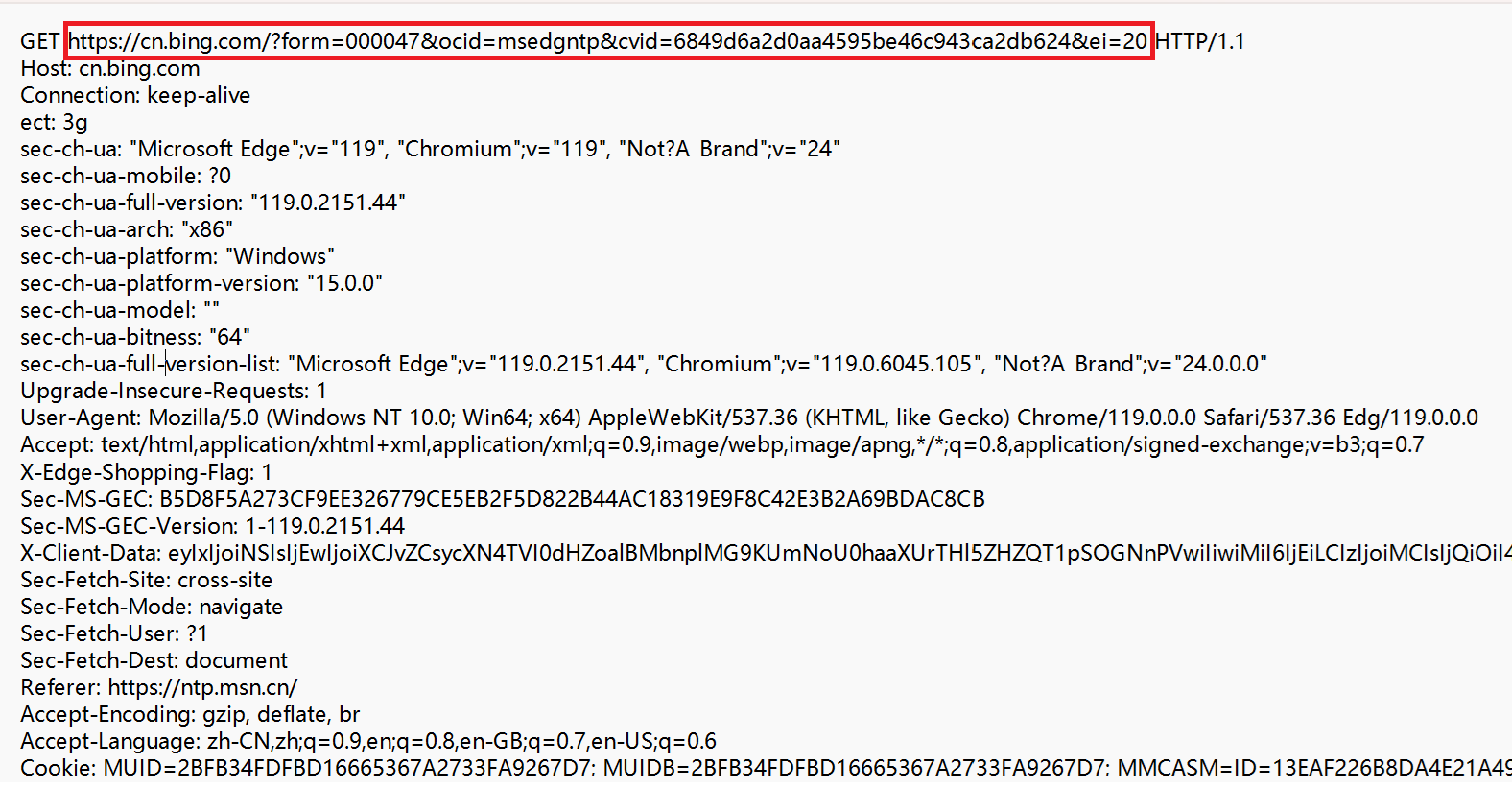
在协议的名称,域名的后面,还跟了一长串的字符,它被称为查询字符串(query string),查询字符串中表达的意思,作为外人是无从得知的,这里面的内容是写这个代码的程序员索定义的。
在查询字符串中,也是键值对的格式,此处的键值对使用“&”来分割键值对,使用“=”来分割键和值。
一个完整的URL结构如下:
http:协议方案名,常见的由http和https,也有其它类型(如jdbc:mysql).
user:pass:登录信息,之前是直接把相关认证信息直接在URL中展示的,后来发现不太安全,因此现在都是通过单独的登录页面来完成身份验证。
www.examole.jp:80:服务器地址和服务器端口号,这里也可以是域名,也可以是服务器IP地址+服务器端口号,可以表示我们要访问哪个服务器的哪个窗口,如果URL中不带端口号,浏览器就会自动给一个默认的端口 (这里是服务器的端口,而非客户端的端口),此处用什么端口作为默认值,取决于我们在应用层使用什么协议:http -- 80,https -- 443
dir/index.html:带有层次的文件路径
uid = 1:查询字符串,是客户端给服务器传递信息的重要途经,这里的组织方式是按照键值对来组织的,这里面的内容是程序员自定义的。
ch1:片段标识符,主要用于页面跳转,常用于通过不同的片段标识跳转到文档的不同章节。
结合上述IP地址,端口号,带层次的文件路径,查询字符串,就可以描述出一个网络资源了:
http://xx大学商业街:18/烤冷面/火腿烤冷面/?葱=不要&辣椒=不要
关于URL encode
在query string中都是程序员自定义的键值对,但在URL中,本身有些特殊符号具有特定的含义:/ :?@ ……
如果URL中的query string中也包含相同的符号,怎么办呢?
如果直接写入query string中,就有可能会使服务器/浏览器解析失败。因此,我们可以对上述符号进行“转义”。包括中文字符或者其它由UTF-8或者GBK这样的编码方式构成的字符,虽然在URL中没有特殊含义,但是浏览器可能会把编码中的某个字节当作URL中特殊符号,也需要进行转义。
转义的规则:将需要转码的字符转为16进制表示,前面加上%即可。
比如搜索C++:
可以看到,query string 中显示的是C%2B%2B
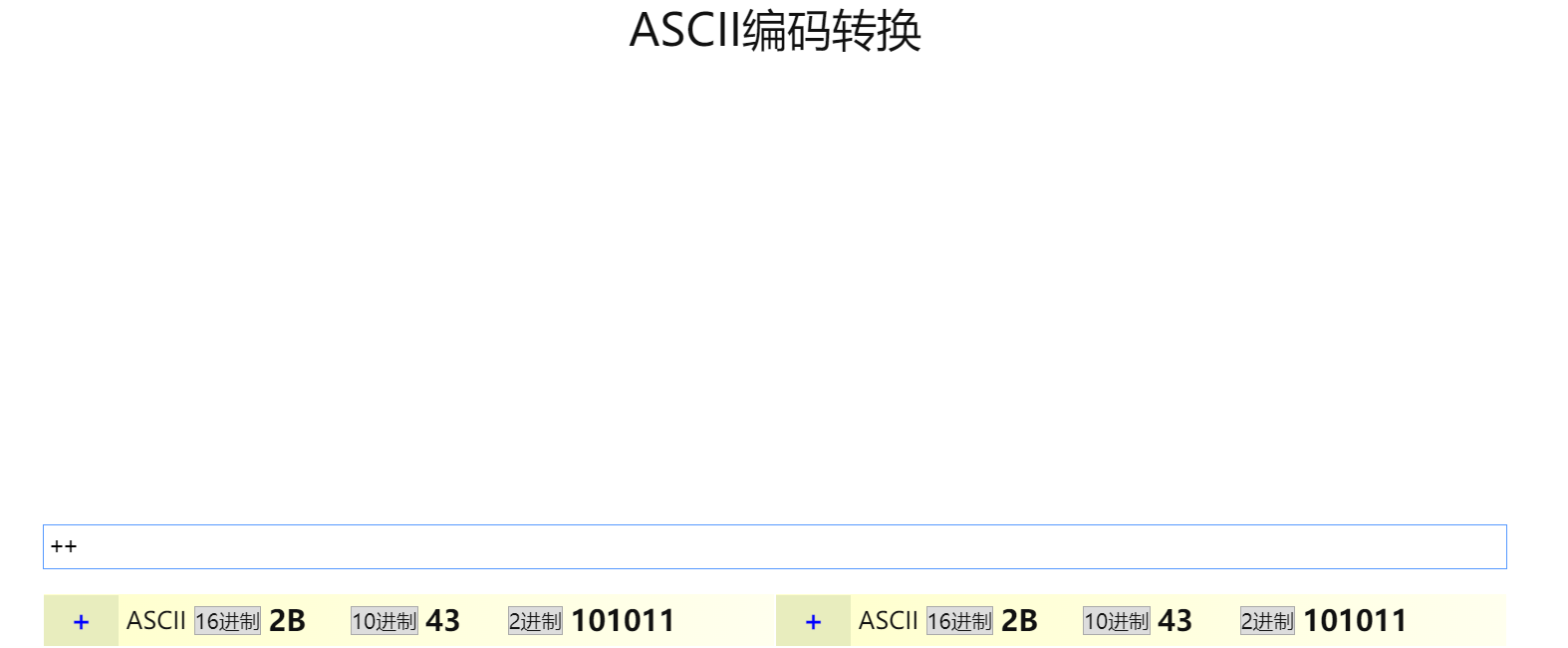 通过ASCLL编码查询软件,+的16进制正好就是2B,对应了C++就是C%2B%2B。
通过ASCLL编码查询软件,+的16进制正好就是2B,对应了C++就是C%2B%2B。
我们还可以搜索一个枫叶:
在上面的query string中虽然直接显示的是枫叶,这是因为浏览器自动进行了解析,我们可以复制粘贴到文本文档中就可以显示出来了:
我们对“枫叶”进行utf-8编码: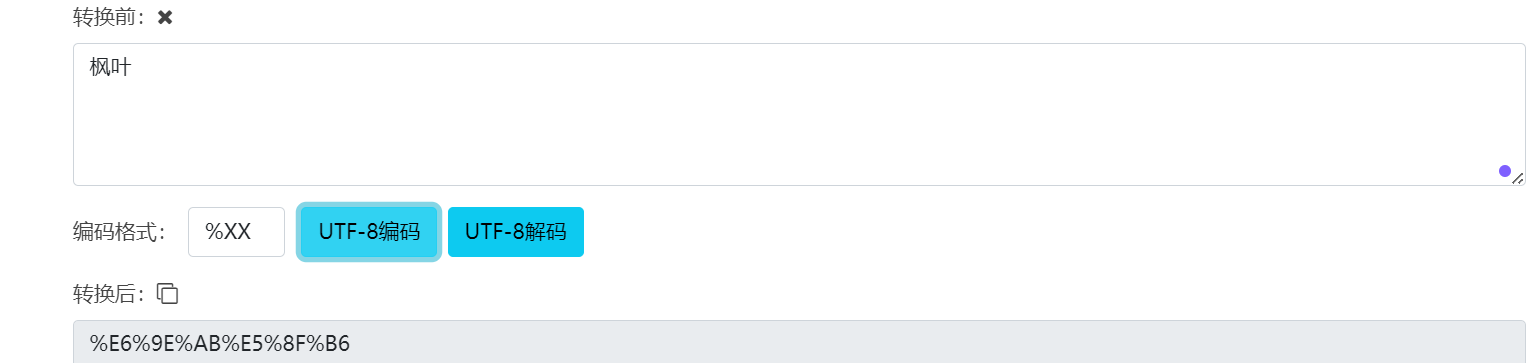 结果相符。
结果相符。
注意:这里的URL encode是非常非常重要的!!!在实际开发中,当我们要构造一个URL的时候,尤其是URL的query string中要包含中文的时候,务必要进行编码!!!
认识方法(method)
请求的首行中,包含了方法 URL 版本号。
方法就描述了这次请求想干啥。
所有方法如下: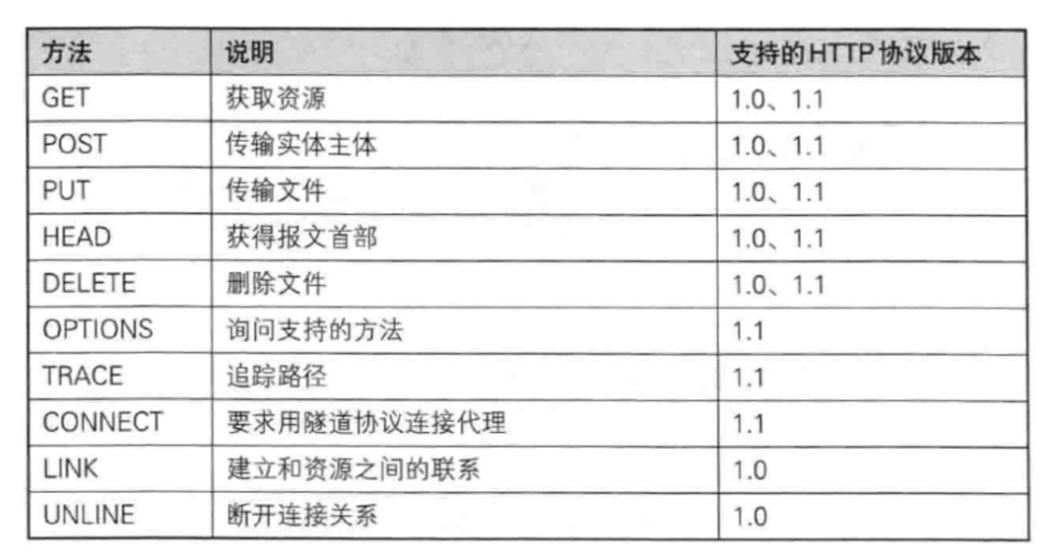
虽然方法很多,但是我们常使用的只有两个:GET方法和POST方法。
1、GET方法
GET方法是最常用的HTTP方法,常用于获取服务器上的某个资源(读操作)。在浏览器中直接输入一个URL,此时浏览器就会发送出一个GET请求。另外,HTML中的link,img,script等标签,也会触发GET请求。
在浏览器访问必应主页,观察Fiddler的抓包结果: 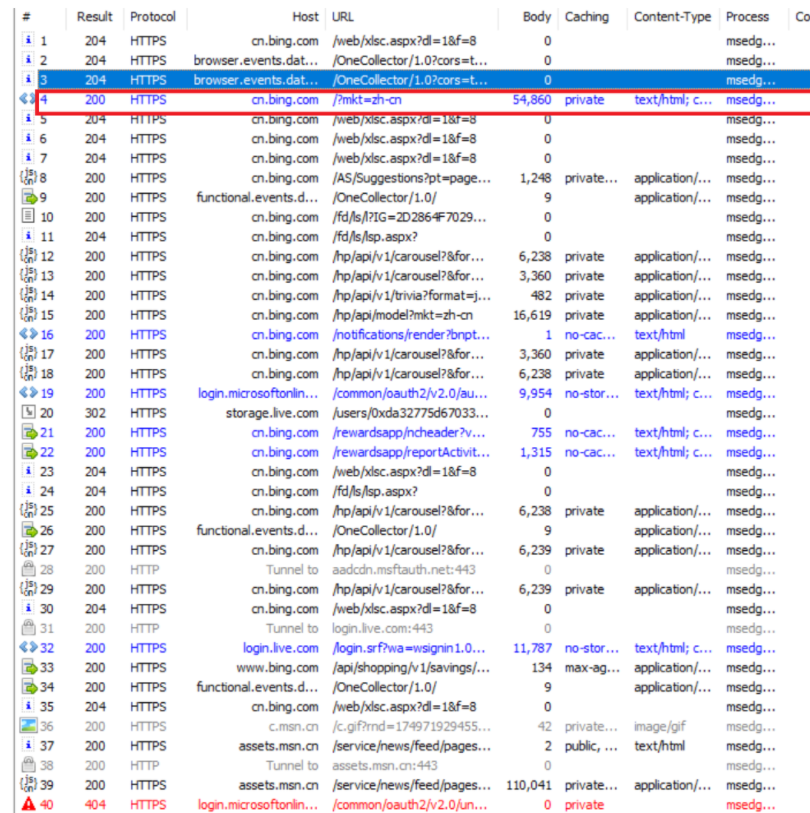
可以看到,最上面蓝色的,是通过浏览器地址发送的GET请求,下面还有一些必应域名相关的请求,有些是通过HTML中的link/script/img标签产生的,有些是通过ajax的方式产生的。
我们选中刚才使用红色框住的抓包结果,观察GET方法的特点: 
GET请求的特点:
首行的方法部分为GET,GET会把补充数据放到query string的url中(query string可能为空也可能不为空),body部分通常为空(通常没有正文)。
2、POST方法
POST方法也是一种常见的方法,多用于用户输入的数据给服务器(多出现在登录和上传页面)
我们可以登录学校的教务系统进行抓包: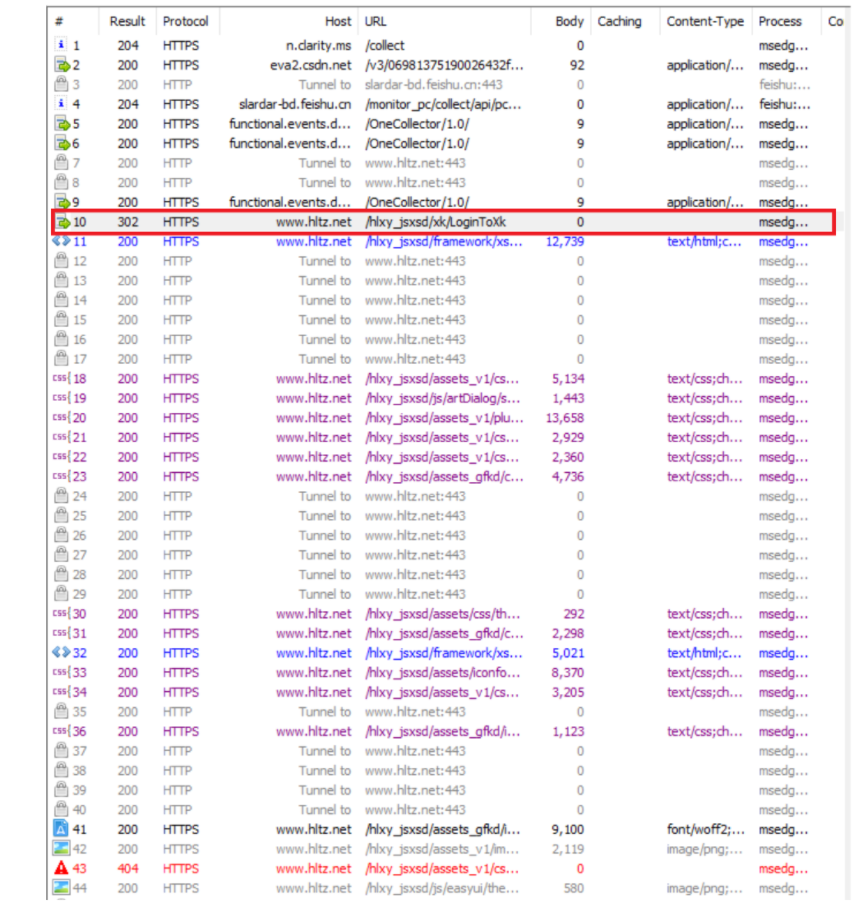
红色框的部分就是我们登录教务系统所抓到的包,点击查看详细: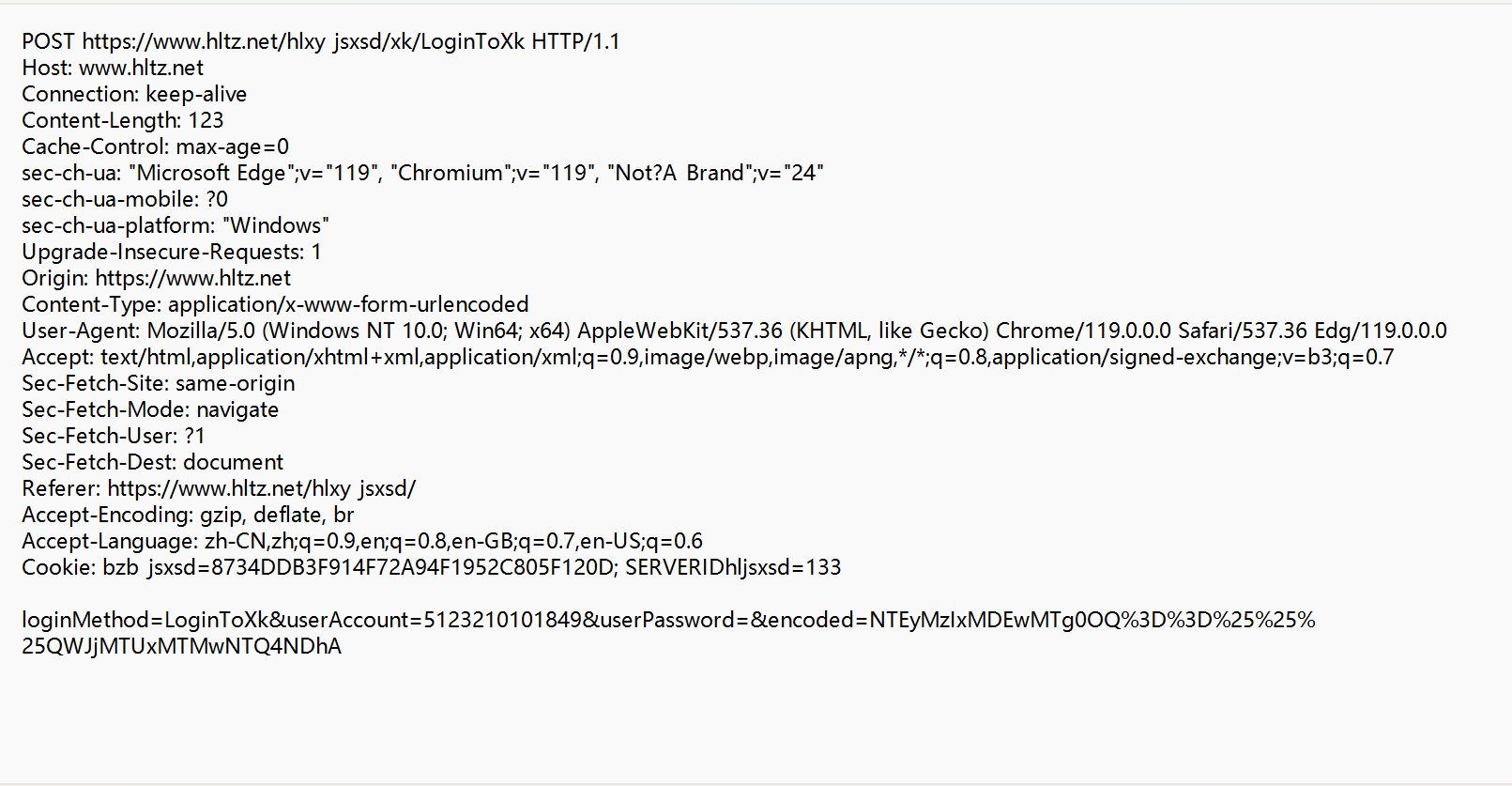 POST请求的特点:
POST请求的特点:
首行的方法部分为POST,POST通常有body,POST会把补充数据放到body中。(body内的数据格式通过header中的Content-Type指定。body的长度由header中的Content-Length指定)。
面试题:POST和GET方法的区别
盖棺定论:GET和POST本质上没有区别。使用GET的场景,也可以替换成POST,使用POST的场景,也可以替换成GET(这里主要取决于程序员的代码是怎么写的,尤其是服务器和客户端都是同一个程序员实现的情况)(部分服务器/部分浏览器,在某些情况下GET和POST不能完美替换,但是大部分情况都能够相互替换)。
但是GET和POST还是有一些区别的:
1、从使用习惯上看:GET习惯于把数据放到URL的query string中。POST习惯于把数据放到body中。(GET也可以把数据放到body,POST也可以把数据放到query string)。
2、从语义上看:在标准文档中,GET的语义是用来获取数据的,POST的语义是给服务器传输数据的(实际使用还是程序员说了算)
3、从幂等性上看:在标准文档中,建议GET请求实现成幂等(每次输入的内容一定,输出的结果也一定,就称为幂等;每次输入的内容一定,输出的结果不一定,就称为不幂等的)的,POST无要求。(标准文档这么要求,也不是非要实现幂等)。
4、GET请求可以被浏览器的收藏夹收藏,POST不可以。
关于POST方法和GET方法的区别,网上还有一些模棱两可的说法:
1、POST比GET更加安全
论据:登录的时候,如果使用GET,用户密码会显示在URL中,此时很容易被别人看到,不安全。
如今用户密码都会有一个单独的登录页面了,不会显示在URL中,即使使用POST,不会显示在URL中,但POST也是可以被黑客抓包进行获取的……真正保证安全的关键在于加密。
2、GET传输的数据量小(存在上限),POST传输的数据量更大
这句话描述的是以前的情况,实际上,HTTP标准文档上明确说了,对于GET的URL长度是不进行限制的,只不过老版本的IE浏览器在实现的时候,URL的长度有限制。
3、GET只能携带文本数据,POST可以携带二进制数据
这个说法,并不是完全错误,只是有一些局限性。query string是只能包含文本的,是对二进制数据进行url encode了。到了服务器再进行url decode,就能把数据再还原成二进制。
POST请求中,body虽然可以携带二进制数据,但也不是经常携带的,很多时候都是对二进制数据进行url encode/base64(将四个字节的数据转换为三个字节的)等等方式进行转码的
认识请求“报头”(header)
header的整体格式也是“键值对"结构。
每个键值对占一行,键和值之间使用:进行分割。
Host
表示访问的服务器主机的地址和端口(URL中已经有Host了,这里的Host和URL中的IP地址端口什么的,绝大部分都是相同的)
Content-Length Content-Type
Content-Length表示body中的数据长度
Content-Type表示请求的body中的数据格式。
这两个字段都是和body相关,如果没有body,也就不会有这两个字段。
Content - Length可以解决”粘包“问题(HTTP的底层是TCP),空行标志着请求报头的结束,此时如果后面还有数据就说明body部分不为空,此时body要读多长就取决于Content - Length。(粘包问题的解决办法:明确包之间的边界:1、通过特殊符号作为分隔符。2、指定出包的长度),这里我们使用的是方法2,读完当前长度就说明这个包结束了。
Content-Type中的常见选项:
请求中:
1、 application/json:body 中的数据为 json 格式。
2、application/x-www-form-urlencode:称为form表单,通过HTML中的form标签构造出来的一种格式,这种格式的特点:把query string放到body中了。
3、multipart/form-data:当需要表单中上传文件,或者包含二进制数据的时候使用。再HTML的from标签中需要设置enctype=“multipart/form=data“。
例如: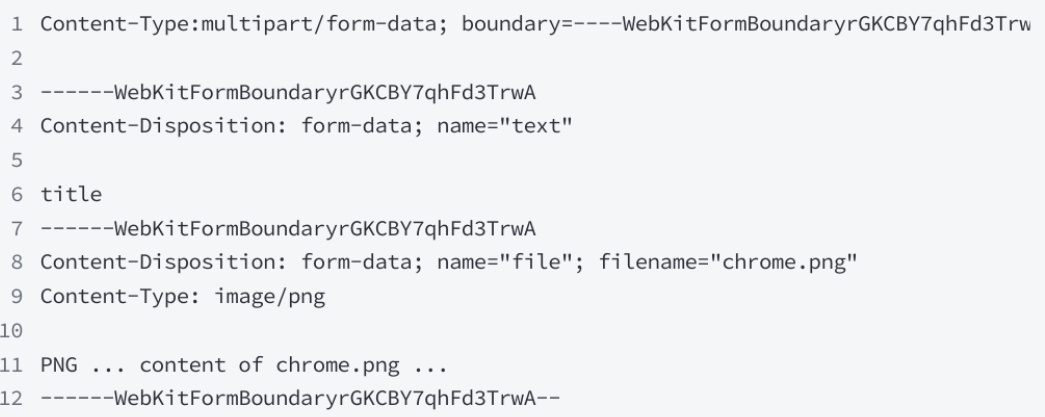
使用 boundary(边界标识符,如 ---------WebKitFormBoundaryrGKCBY7qhFd3TrwA)来分割不同表单数据部分。每个部分包含自身的元数据(如 Content-Disposition 指定数据类型和名称,Content-Type 指定具体的数据类型)。
这里上传的第二个文件类型是png文件(图片)。
响应中:
1、text/plain 纯文本
2、text/html html页面
3、text/css css页面
4、application/javascript js
5、applition/json json(格式)页面
6、image/png 图片文件
7、image/jpg 图片文件
……
补充:
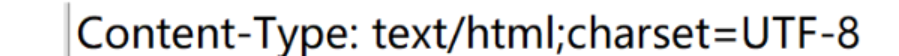
我们后面自己写服务器程序返回网页,如果发现网页乱码,就可以检查下这里的编码方式是否是没有设置或者设置有误。
User-Agent(简称UA)
表示浏览器/操作系统的属性,描述了用户使用什么样的设备上网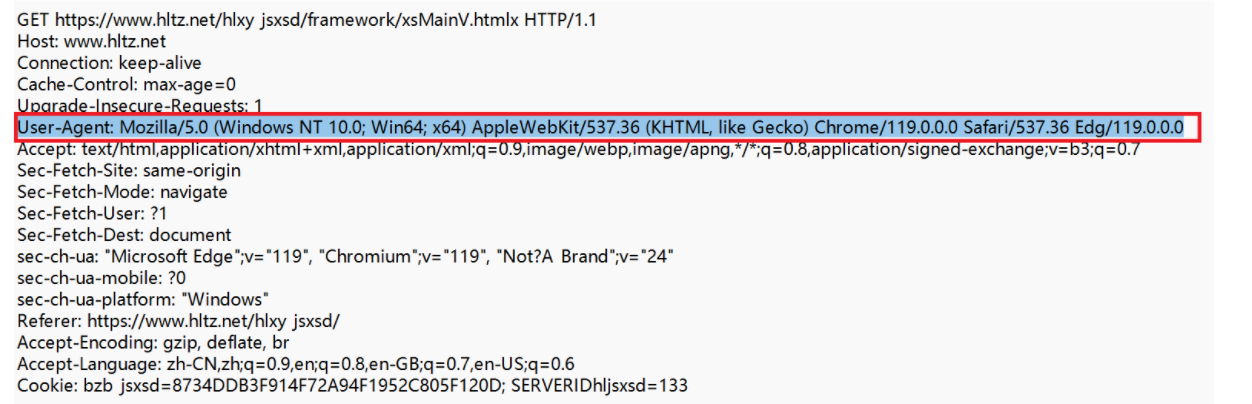
操作系统:WindowsNT 10.0;Win64;x64
浏览器信息:Chrome/119.0.0.0 、Edg/135.0.0.0……(除了操作系统信息之外都是浏览器信息)
上古时期,UA是非常关键的内容,由于计算机发展迅速,不同用户使用的上网设备差异很大,UA就可以表明该用户上网的设备具体信息。如果用户使用的是比较老的设备,返回的页面就不包含新特性,确保这个页面可以正常地访问;如果用户使用地是新设备,返回的页面就包含新特性,确保这个页面体验感足够好。
随着时间推移,浏览器现在都差不多了~~但UA仍然很有用,很多网站再PC端和手机端,由于其设备大小区别,返回地页面也会有差异,这都是通过UA进行控制的。
Referer
表示这个页面是从哪个页面跳转过来的。在浏览器中,直接输入URL或者点击收藏夹打开的网页此时是没有Referer的。
使用必应搜索跳转到搜狗搜索”

举个例子:
这里的Referer多使用于广告中,广告都是按照点击计费的,用户每次点击广告,负责的企业都能赚钱,所以必须要记录某个广告在某个时间段被点击多少次。
比如在搜狗上搜索“蛋糕”,当我们用户点击相关的广告,搜狗就能赚到钱。这个点击次数,搜狗和广告方都要进行统计。
搜狗中,用户只要点击就会把请求发送到搜狗服务器上,此时就能通过记录日志来知道当前的点击次数。
但是,广告方会在各个平台投放广告(如:360、百度等等),它是怎么知道这些点击的用户是从哪个平台跳转过来的,从而支付广告费呢?——只需要借助Referer即可.
这里的Referer会不会被篡改呢?
这是很有可能的,特别是接了相同广告的运营商,他们通过篡改这里的Referer,将其它平台点击跳转的广告改成从自己平台跳转,从而谋取更多的利益。所以就有了HTTPS协议,这里的S是SSL(网络中用于加密的协议),加密就能把header和body都进行加密,网络上传输的就是密文了。
其他人想要修改,就得先进行破解,就算能破解,也无法篡改,一旦进行修改,用户的浏览器就能清楚地感知到。
Cookie
Cookie是一个浏览器这边本地持久化存储数据(在硬盘上存储)的机制。
浏览器作为电脑上地一个程序,是可以直接读写本地磁盘文件的,系统提供了API操作文件。浏览器上运行的网页,理论上也是可以通过浏览器提供的API来读写本地的磁盘文件,但是浏览器禁止了这种做法。
但是,有些网站是需要把一些信息保存到浏览器这边的,比如当前登录的用户的身份信息。因此浏览器退而求其次,给网页提供了只能有限度存储数据的API,而不能随意访问文件系统。
HTTP请求中的Cookie字段,就是把本地存储的Cookie信息发送到服务器这边。HTTP响应中会有一个Set-Cookie字段,就是服务器告诉浏览器你要在本地保存哪些信息。
上述的请求和响应字段,都是以键值对的形式进行的(程序员可以自定义的)。
Cookie中存储了一个字符串,它可能是客户端(网页)自行通过JavaScript写入的,也可能是来自于服务器(服务器在HTTP响应的header中通过Set-Cookie字段给浏览器返回数据)
一般可以通过这个字段来实现“身份标识”的功能。(每个不同的域名下都可以有不同的Cookie,换句话说,不同网站之间的Cookie并不冲突)。
举个例子:
Cookie的作用就非常类似于学校的学生证
1、注册学生证(初始设置Cookie)
当我们刚来到学校,学校就会给我们发一个学生证,这就类比是服务器给客户端设置Cookie,学生证上记录了我们的信息,比如:姓名、班级、学生号、宿舍地址……,这些信息就如同Cookie里面存储的用户标识等基础数据。
2、第一次使用学生证(第一次请求携带Cookie)
当我们第一次进入宿舍时,学生证扫描仪会扫描我们的学生证。这就类似于客户端向服务器发起请求时带上了Cookie。学生证扫描仪通过扫描,就知道我们是这栋宿舍的学生,放我们进宿舍,这就像服务器根据Cookie里面的信息,来识别出用户,并作出响应的处理,比如提供个性化的页面展示和服务,
3、后面使用学生证(后续请求携带Cookie)
之后我们再进出宿舍,每次进出宿舍都扫描学生证。宿管每次都能通过学生证来查到我们之前进出宿舍的记录。这就如同客户端后续每次向服务器发送请求时,Cookie持续发挥作用,让服务器可以基于之前的交互历史,持续为用户提供连贯、个性化的服务~~
关于Cookie的几个重要结论:
1、Cookie从哪里来的?
服务器返回给浏览器的。通常时首次访问/登录成功之后。
2、Cookie到哪里去?
Cookie会存储到浏览器本地主机的硬盘上。后续每次访问该服务器Cookie。不同的客户端,保存的Cookie说不同的,即使是同一个主机,使用不同的浏览器,Cookie大概率也不同。
3、Cookie中存储什么?
Cookie以键值对的形式对数据进行存储。这里的内容都是程序员自定义的,和query string一样,外人无从理解。不同网站的Cookie是不同的。
4、Cookie在浏览器如何组织
在硬盘本地保存,按照不同域名进行存储的。
5、Cookie的用途是什么?
用来在客户端保存数据,其中最主要的是保存用户的身份标识,使得服务器可以通过标识来区分用户,一般其他业务不会存在Cookie中。
认识请求“正文”(body)

正文中常见的就是我们上面 Content - Type 中的一些格式内容。