深度学习编译器
1)深度学习编译器复杂个JB
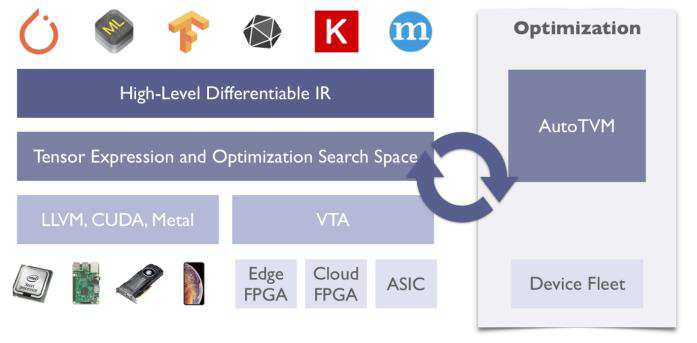
与通用自动编译工具不同,深度学习编译器结构更加复杂,包括图层优化、张量
(Tensor)优化、代码生成、硬件部署、自动调优(Auto Tuning)等几个部分。以TVM
为例,图1.1 为TVM 的结构示意图。
最上层表示不同的深度学习框架,TVM 将不同深度
学习框架实现的算法转化为高层IR 表示,高层IR 以算子为原子单元,将不同类型的算法
抽象成图节点对图进行融合优化。之后,TVM 将高层IR 转换为中间层IR,通过将不同
的算子转换成循环嵌套和对应的矩阵乘法或加法运算,实现对循环嵌套和计算的张量优化,
优化过程中通过自动调优方法进行参数调整。而后,通过张量优化实现计算任务在底层硬
件上的自动部署。最后,TVM 将优化后带有部署标记的中间IR 传递给代码生成,面向不
同的加速部件实现相应的代码生成和部署
2)TVM 结构示意图
3)
在深度学习编译器中,张量优化是最核心的过程,不仅要实现面向底层硬件的各种循
环优化,还要负责神经网络算法到硬件体系结构的自动部署。在面向人工智能专用加速芯
片进行循环优化和任务部署过程中,张量优化需要充分考虑加速芯片的硬件架构,最具挑
战性的就是芯片架构上的存储结构。
张量就是多重数组计算的优化,好像也没有什么特别的吧?
4)Ascend 910 芯片的达芬奇结构示意图
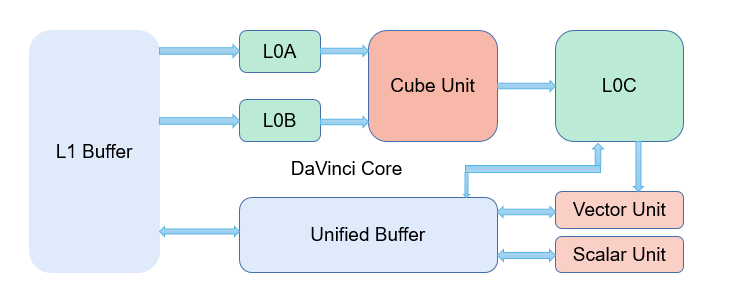
其中,Cube 计算单元用于计算张量/矩阵计算,L0A 和L0B 分别为该计算单元的一级
缓存,L0C 则用于存储Cube 计算单元的结果;L1 是介于L0A/L0B 和片外存储之间的二
级缓存。Vector 和Scalar 计算单元用于计算向量和标量计算,可向UB 缓存写入或从UB
读取数据;同时,L0C 的数据也可以作为Vector 计算单元的输入。作为二级缓存,L1 和
UB 之间可以相互传输数据。类似地,TPU 和GPU 图灵体系结构也具有类似的多元化计
算单元和复杂的存储层次。
达芬奇结构采用的是脉冲架构?怪不得不兼容CUDA。华为晟腾的生态也做不起来,尽管赚了秀多钱。
5)深度学习的算法优化,估计目前还是靠人力吧
面对深度学习应用的海量数据,为了充分利用人工智能专用加速芯片的多级缓存结构,
张量优化在实现算子层的循环优化时要以循环分块为前提。在此基础上,实现图层优化的
融合、张量优化的其它优化技术(如合并、分布等)以及在计算任务的调度、自动部署和
自动调优过程中使用的调优算法等。例如:循环合并需要在分块后计算块内所需其它计算
任务总量决定合并的策略,而计算任务的自动部署阶段需要根据循环分块后的循环维度实
现与并行硬件抽象之间的映射。
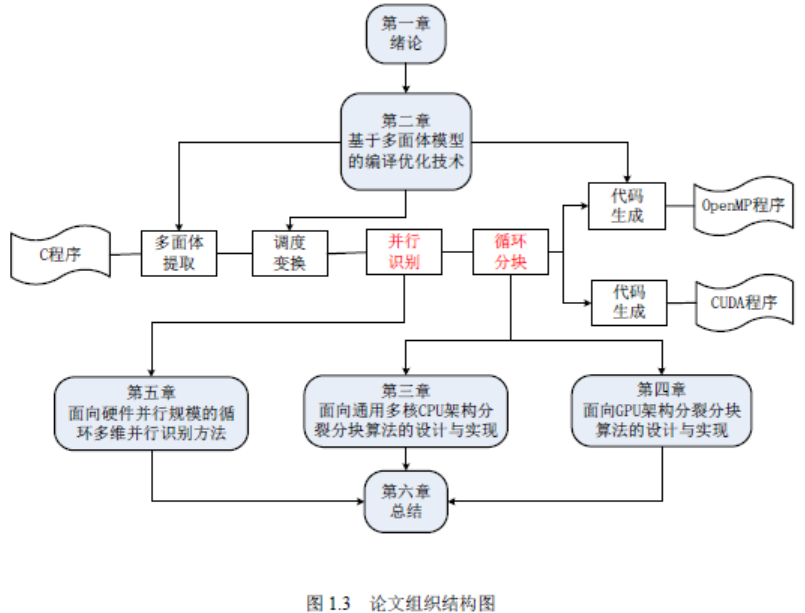
6)第二章对多面体模型和基于该模型的编译优化技术的研究进展进行了系统全面的总
结。研究了多面体模型的工作原理,分析了多面体模型编译工具的编译流程,给出了利用
多面体模型提升程序并行性和数据局部性的主要方法。最后介绍了多面体模型中的调度树
中间表示。
感觉 第二章应该写得比较好。
第三章以多级存储层次进行局部性优化为目标,对分块技术的自动生成展开研究。基
于多面体模型已经实现的平行四边形分块设计了一种新型的分裂分块算法,并在多面体模
型编译器PPCG 中对该算法进行了实现,可针对通用多核CPU 架构生成带有分裂分块的
OpenMP 代码。
PPCG也可以生成OpenMP代码,是这个意思吧
也很清楚
6)
感谢《面向异构系统的多面体编译优化关键技术研究_李颖颖》