P8-大模型微调
1. 引言
随着大语言模型(LLMs)在自然语言处理(NLP)、对话系统、文本生成等领域的广泛应用,针对特定下游任务的高效微调已成为提升模型性能和部署效率的关键技术。微调通过在特定数据集上进一步训练预训练模型,使其适配特定任务或领域,如金融分析、医疗诊断或客服对话。本文将介绍大模型微调的原理,并提供实践的过程。
2. 概述
2.1 微调的定义
微调(Fine-tuning)是指在大规模预训练模型的基础上,使用特定任务或领域的数据对模型进行进一步训练,以提升模型在该任务或领域上的性能。与预训练阶段相比,微调通常使用较小的数据集和较少的训练步数。
2.2 微调的目标
- 任务适应:使模型能够执行特定任务,如文本分类、命名实体识别、机器翻译等。
- 领域适应:使模型在特定领域(如医疗、法律)的数据上表现更好,捕捉领域特有的语言特征。
- 性能提升:通过微调,模型能够在目标任务上达到更高的准确率、F1分数等指标。
2.3 微调的类型
-
全参数微调(Full Fine-tuning):
- 对模型的所有参数进行更新。
- 优点:能够充分利用模型的全部容量,性能提升显著。
- 缺点:计算资源需求大,容易过拟合,尤其是数据量较小时。
-
参数高效微调(Parameter-Efficient Fine-tuning, PEFT):
- 只更新部分参数或引入少量新参数,如LoRA(Low-Rank Adaptation)、Adapter。
- 优点:减少计算和存储需求,降低过拟合风险。
- 缺点:性能提升可能不如全参数微调。
-
提示微调(Prompt Tuning)与指令微调(Instruction Tuning):
- 通过设计特定的提示或指令来引导模型输出,适用于少样本或零样本学习。
- 优点:无需大量标注数据,灵活性高。
- 缺点:提示设计需要经验,效果可能不稳定。
2.4 微调的优势与挑战
-
优势:
- 利用预训练模型的知识,加速收敛。
- 在小数据集上也能取得较好性能。
- 适用于多种下游任务。
-
挑战:
- 计算资源需求大,尤其是全参数微调。
- 容易出现过拟合,特别是在数据量不足时。
- 可能导致灾难性遗忘,即模型在微调过程中丢失预训练时的通用知识。
3. 准备工作
微调大模型前,需完成数据集准备、硬件与环境配置以及模型选择三个关键步骤,以确保微调过程高效且效果优异。以下详细说明每部分内容。
3.1 数据集准备
-
数据收集与清洗:
- 数据来源:可从公开数据集(如Hugging Face Datasets、Kaggle)、领域特定语料(如医疗、法律领域的专业文本)或企业内部数据获取。
- 清洗步骤:去除重复样本、处理缺失值、过滤噪声数据(如乱码、格式不一致的文本)。例如,使用Python的
pandas库移除空值或正则表达式清理无效字符。 - 预处理:对文本进行分词(中文需使用Jieba等工具)、大小写标准化、去除停用词或标点符号,确保数据适合模型输入。
-
数据标注:
- 标注需求:根据任务类型(如文本分类、命名实体识别、对话生成)标注数据。例如,分类任务需为每条文本分配标签(如“正面”/“负面”),NER任务需标注实体边界。
- 工具推荐:
- Label Studio:开源,支持文本、图像等多模态标注,适合团队协作。
- Prodigy:商业化工具,高效支持小规模标注。
- Crowdsourcing:如Amazon Mechanical Turk,适合大规模标注任务。
- 质量控制:通过多轮标注、计算标注者一致性(如Cohen’s Kappa)或引入专家审核,确保标注质量。
-
数据格式化:
- 目标:将数据转换为模型和框架(如Hugging Face Transformers)支持的格式。
- 格式选择:根据任务选择JSON、CSV或Dialogue格式,需与模型输入(如
input_ids、attention_mask)兼容。 - 自动化工具:使用Hugging Face
datasets库或自定义脚本将原始数据转换为目标格式。
3.2 大模型微调框架选择
3.3 硬件与环境配置
-
GPU/TPU需求与分布式训练设置:
- 硬件需求:大模型微调通常需要高性能GPU(如NVIDIA A100、H100)或TPU,视模型规模选择单卡或多卡配置。
- 分布式训练:使用PyTorch的
DistributedDataParallel(DDP)或TensorFlow的tf.distribute.Strategy实现多GPU/TPU并行训练,加速训练过程。 - 内存管理:启用梯度累积(Gradient Accumulation)以在内存受限时模拟大batch size。
3.4 模型选择
-
选择合适的预训练模型:
- 任务匹配:根据任务选择合适的模型,如BERT(文本分类)、LLaMA(生成任务)、T5(翻译/生成)。
- 开源模型:Hugging Face模型库提供丰富的预训练模型,如
bert-base-uncased、LLaMA-7B。 - 社区支持:优先选择文档完善、社区活跃的模型,便于调试和扩展。
-
模型规模与任务需求的权衡:
- 大模型:如LLaMA-70B,性能优异但需高性能硬件,适合高精度任务。
- 小模型:如DistilBERT、BERT-base,计算需求低,适合资源有限或快速实验场景。
- 折衷选择:若资源有限,可尝试参数高效微调(如LoRA)以在小规模硬件上运行大模型。
4. 微调的实现流程
本文档详细描述了使用 Hugging Face Transformers 框架和 LoRA(低秩适配)对 Qwen2.5-0.5B-Instruct 模型进行微调的流程。流程包括加载预训练模型和数据集、配置微调参数、执行微调、训练与验证、保存和加载微调模型。数据集使用用户指定的 huanhuan.json,实现针对单 GPU(例如 16GB 的 NVIDIA A100)优化。
4.1 流程概述
微调流程包括以下步骤:
-
加载预训练模型和数据集:
- 加载 Qwen2.5-0.5B-Instruct 模型及其分词器。
- 加载自定义数据集
huanhuan.json,包含instruction、input和output字段。
-
配置微调参数:
- 设置学习率、批大小、优化器和学习率调度。
- 配置 LoRA 参数以实现高效微调。
-
执行微调:
- 使用 LoRA 更新少量模型参数,降低内存和计算需求。
- 借助 Hugging Face 的
TrainerAPI 简化训练流程。
-
训练与验证:
- 在处理后的数据集上进行训练。
- 通过 TensorBoard 日志监控性能,定期保存检查点。
-
保存和加载微调模型:
- 保存 LoRA 权重和模型配置。
- 加载微调模型进行推理。
4.2 步骤详解
步骤 1:加载预训练模型和数据集
-
模型加载:
- 使用
AutoModelForCausalLM加载 Qwen2.5-0.5B-Instruct 模型,适用于生成任务。 - 使用
AutoTokenizer加载匹配的分词器,确保与模型兼容。 - 设置
trust_remote_code=True以支持 Qwen 的自定义代码,torch_dtype=torch.float16降低内存占用。
- 使用
-
数据集加载:
- 使用
pandas加载huanhuan.json并转换为 Hugging FaceDataset对象。 - 数据集需包含
instruction、input和output字段。 - 示例数据:
{"instruction": "请以甄嬛的口吻回答:","input": "你是谁?","output": "吾乃甄嬛,昔日承蒙圣恩,然世事无常,今不过一介凡女耳。" }
- 使用
步骤 2:配置微调参数
-
学习率:
- 设置为
1e-4,兼顾收敛速度和稳定性。 - 对于小型数据集,可降低至
1e-5以防过拟合。
- 设置为
-
批大小:
- 设置
per_device_train_batch_size=2和gradient_accumulation_steps=2,有效批大小为 4,适合 16GB GPU。 - 根据 GPU 内存调整以避免内存溢出(OOM)。
- 设置
-
优化器:
- 使用
AdamW(默认参数:beta1=0.9、beta2=0.999、epsilon=1e-8)。 - 设置权重衰减
0.01以防止过拟合。
- 使用
-
学习率调度:
- 前 10% 步数使用线性 warm-up,之后线性衰减至
min_lr=1e-6。
- 前 10% 步数使用线性 warm-up,之后线性衰减至
-
LoRA 配置:
- 设置
r=8(低秩矩阵的秩),lora_alpha=32(缩放因子),lora_dropout=0.1(正则化)。 - 目标模块:
["q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj"]。
- 设置
步骤 3:执行微调
-
LoRA(参数高效微调):
- 使用
peft应用 LoRA,仅更新约 1-2% 的参数,显著降低内存需求。 - 启用梯度检查点(gradient checkpointing)进一步优化内存。
- 使用
-
训练循环:
- 使用 Hugging Face 的
TrainerAPI 处理训练循环,包括梯度计算、优化和检查点保存。 - 数据集处理时加入系统提示,格式化为因果语言建模输入。
- 使用 Hugging Face 的
步骤 4:训练与验证
-
数据集处理:
- 预处理
huanhuan.json,生成input_ids、attention_mask和labels。 - 截断序列至
max_length=384以适配 GPU 内存。 - 使用系统提示模拟甄嬛风格:“现在你要扮演皇帝身边的女人–甄嬛”。
- 预处理
-
评估:
- 通过 TensorBoard 日志(
OUTPUT_DIR/logs)监控训练损失。 - 每
save_steps=100保存一次检查点。 - 本例未使用单独验证集,可按 80% 训练、20% 验证划分以评估性能。
- 通过 TensorBoard 日志(
-
评估指标:
- 生成任务跟踪训练损失。若需验证,可添加困惑度(Perplexity)或 BLEU 分数。
步骤 5:保存和加载微调模型
-
保存:
- 将 LoRA 权重和配置保存至
OUTPUT_DIR(如checkpoint-100)。 - 基础模型保持不变,仅保存 LoRA 适配器。
- 将 LoRA 权重和配置保存至
-
加载:
- 使用
PeftModel.from_pretrained加载基础模型和 LoRA 权重。 - 使用示例提示进行推理,验证微调效果。
- 使用
4.3 实现代码
以下是完整的 PyTorch 代码,用于使用 LoRA 微调 Qwen2.5-0.5B-Instruct,适配 huanhuan.json 数据集。
import os
import torch
from datasets import Dataset
from transformers import AutoTokenizer, AutoModelForCausalLM, DataCollatorForSeq2Seq, TrainingArguments, Trainer
from modelscope import snapshot_download
from peft import LoraConfig, TaskType, get_peft_model, PeftModel
import pandas as pd
from pathlib import Path
import logging# 设置日志
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)# 动态选择路径(支持 Windows 和 Linux)
if os.name == 'nt': # WindowsDIR_Path = "I:\\1_LLM_Project\\6_LORA\\1_Modelscope\\"
else: # Linux/UnixDIR_Path = "/media/cw/新加卷/1_LLM_Project/6_LORA/1_Modelscope"
BASE_DIR = Path(DIR_Path).expanduser().resolve()
MODEL_CACHE_DIR = BASE_DIR / "model_cache"
OUTPUT_DIR = BASE_DIR / "model_output/Qwen2.5-0.5B-Instruct_lora"# 确保路径存在
MODEL_CACHE_DIR.mkdir(parents=True, exist_ok=True)
OUTPUT_DIR.mkdir(parents=True, exist_ok=True)# --------------------------------------
# 设备选择逻辑
# --------------------------------------
def get_device():if torch.cuda.is_available():device = "cuda"logger.info("使用 CUDA 设备")elif torch.backends.mps.is_available():device = "mps"logger.info("使用 MPS 设备")else:device = "cpu"logger.info("使用 CPU 设备")return device# --------------------------------------
# 1. 模型下载与初始化
# --------------------------------------
def load_model_and_tokenizer(device):logger.info("正在下载模型...")try:model_dir = snapshot_download('Qwen/Qwen2.5-0.5B-Instruct',cache_dir=MODEL_CACHE_DIR,revision='master')except Exception as e:logger.error(f"模型下载失败: {e}")raiselogger.info("初始化分词器...")try:tokenizer = AutoTokenizer.from_pretrained(model_dir,use_fast=False,trust_remote_code=True)tokenizer.pad_token = tokenizer.eos_tokenexcept Exception as e:logger.error(f"分词器初始化失败: {e}")raiselogger.info(f"在 {device} 上加载模型...")try:model = AutoModelForCausalLM.from_pretrained(model_dir,device_map=device,torch_dtype=torch.float16,trust_remote_code=True)model.enable_input_require_grads()except Exception as e:logger.error(f"模型加载失败: {e}")raisereturn model, tokenizer# --------------------------------------
# 2. 数据加载与转换
# --------------------------------------
def load_dataset_data():DATASET_PATH = BASE_DIR / "dataset/huanhuan.json"logger.info(f"从 {DATASET_PATH} 加载数据集...")try:if not DATASET_PATH.exists():raise FileNotFoundError(f"数据集文件 {DATASET_PATH} 不存在")df = pd.read_json(DATASET_PATH)required_columns = {'instruction', 'input', 'output'}if not all(col in df.columns for col in required_columns):raise ValueError(f"数据集必须包含以下列: {required_columns}")ds = Dataset.from_pandas(df)except Exception as e:logger.error(f"数据集加载失败: {e}")raisereturn ds# --------------------------------------
# 3. 数据预处理
# --------------------------------------
def process_func(example, tokenizer, max_length=384):"""处理单个数据样本,转换为模型可用的格式"""try:input_ids, attention_mask, labels = [], [], []# 系统提示和用户输入的编码instruction = tokenizer(f"<|begin_of_text|><|start_header_id|>system<|end_header_id>\n\n"f"知识截止日期: 2023年12月\n今日日期: 2024年7月26日\n\n"f"现在你要扮演皇帝身边的女人--甄嬛<|eot_id|><|start_header_id|>user<|end_header_id>\n\n"f"{example['instruction'] + example['input']}<|eot_id|><|start_header_id|>assistant<|end_header_id>\n\n",add_special_tokens=False)# 模型输出的编码response = tokenizer(f"{example['output']}<|eot_id|>", add_special_tokens=False)# 拼接输入和输出序列input_ids = instruction["input_ids"] + response["input_ids"] + [tokenizer.pad_token_id]attention_mask = instruction["attention_mask"] + response["attention_mask"] + [1]labels = [-100] * len(instruction["input_ids"]) + response["input_ids"] + [tokenizer.pad_token_id]# 截断超过最大长度的部分if len(input_ids) > max_length:input_ids = input_ids[:max_length]attention_mask = attention_mask[:max_length]labels = labels[:max_length]return {"input_ids": input_ids,"attention_mask": attention_mask,"labels": labels}except Exception as e:logger.error(f"数据处理失败,样本: {example}, 错误: {e}")raise# --------------------------------------
# 4. 主训练流程
# --------------------------------------
def main():# 获取设备device = get_device()# 加载模型和分词器model, tokenizer = load_model_and_tokenizer(device)# 加载数据集ds = load_dataset_data()# 应用预处理函数logger.info("正在预处理数据集...")try:tokenized_id = ds.map(lambda example: process_func(example, tokenizer),remove_columns=ds.column_names,num_proc=1 # 禁用多进程)except Exception as e:logger.error(f"数据集预处理失败: {e}")raise# 配置 LoRA 参数lora_config = LoraConfig(task_type=TaskType.CAUSAL_LM,target_modules=["q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj"],inference_mode=False,r=8,lora_alpha=32,lora_dropout=0.1)# 应用 LoRAlogger.info("应用 LoRA 配置...")model = get_peft_model(model, lora_config)model.print_trainable_parameters()# 训练参数设置args = TrainingArguments(output_dir=OUTPUT_DIR,per_device_train_batch_size=2,gradient_accumulation_steps=2,logging_steps=10,num_train_epochs=3,save_steps=100,learning_rate=1e-4,warmup_ratio=0.1, # 前 10% 步数 warm-uplr_scheduler_type="linear", # 线性衰减weight_decay=0.01, # 权重衰减防止过拟合save_on_each_node=True,gradient_checkpointing=True,fp16=False,bf16=True, # 启用 bfloat16,适用于 NVIDIA GPUdataloader_num_workers=0,logging_dir=OUTPUT_DIR / "logs",report_to=['tensorboard'],max_grad_norm=1.0,)# 训练logger.info("开始训练...")try:trainer = Trainer(model=model,args=args,train_dataset=tokenized_id,data_collator=DataCollatorForSeq2Seq(tokenizer=tokenizer, padding=True),processing_class=tokenizer, # 修复弃用警告)trainer.train()except Exception as e:logger.error(f"训练失败: {e}")raise# --------------------------------------
# 5. 推理部分
# --------------------------------------
def inference(model_dir):device = get_device()logger.info("加载推理用分词器...")try:tokenizer = AutoTokenizer.from_pretrained(model_dir,use_fast=False,trust_remote_code=True)tokenizer.pad_token = tokenizer.eos_tokenexcept Exception as e:logger.error(f"分词器加载失败: {e}")raiselora_path = OUTPUT_DIR / 'checkpoint-100'logger.info(f"从 {lora_path} 加载推理模型...")try:if not lora_path.exists():raise FileNotFoundError(f"LoRA 检查点 {lora_path} 不存在")model = AutoModelForCausalLM.from_pretrained(model_dir,device_map=device,torch_dtype=torch.float16,trust_remote_code=True).eval()model = PeftModel.from_pretrained(model, lora_path)except Exception as e:logger.error(f"推理模型加载失败: {e}")raiseprompt = "你是谁?"messages = [{"role": "system", "content": "假设你是皇帝身边的女人--甄嬛。"},{"role": "user", "content": prompt}]input_ids = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)model_inputs = tokenizer([input_ids], return_tensors="pt").to(device)generated_ids = model.generate(model_inputs.input_ids, max_new_tokens=512)generated_ids = [output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)]response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]print(response)# --------------------------------------
# 6. 主程序入口
# --------------------------------------
if __name__ == '__main__':# 运行训练main()# 运行推理model_dir = MODEL_CACHE_DIR / 'Qwen/Qwen2.5-0.5B-Instruct'inference(model_dir)
vllm测试
import os
import logging
from pathlib import Path
from transformers import AutoTokenizer
from vllm import LLM, SamplingParams
from vllm.lora.request import LoRARequest
import gradio as gr
import socket# 设置日志
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
logger = logging.getLogger(__name__)# 动态选择路径(支持 Windows 和 Linux)
if os.name == 'nt': # WindowsDIR_Path = "I:\\1_LLM_Project\\6_LORA\\1_Modelscope\\"
else: # Linux/UnixDIR_Path = "/media/cw/新加卷/1_LLM_Project/6_LORA/1_Modelscope"
BASE_DIR = Path(DIR_Path).expanduser().resolve()
MODEL_CACHE_DIR = BASE_DIR / "model_cache"
OUTPUT_DIR = BASE_DIR / "model_output/Qwen2.5-0.5B-Instruct_lora"# 确保路径存在
MODEL_CACHE_DIR.mkdir(parents=True, exist_ok=True)
OUTPUT_DIR.mkdir(parents=True, exist_ok=True)# 检查可用端口
def find_available_port(start_port, max_attempts=10):port = start_portfor _ in range(max_attempts):with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as s:try:s.bind(("0.0.0.0", port))return portexcept OSError:logger.warning(f"端口 {port} 已被占用,尝试下一个端口...")port += 1raise OSError(f"无法找到可用端口,范围: {start_port}-{start_port + max_attempts - 1}")# vLLM 和 Gradio 推理
def inference_vllm_gradio():model_dir = MODEL_CACHE_DIR / 'Qwen/Qwen2.5-0.5B-Instruct'lora_path = OUTPUT_DIR / 'checkpoint-2700'logger.info(f"从 {model_dir} 和 {lora_path} 加载 vLLM 模型...")try:if not model_dir.exists():raise FileNotFoundError(f"模型路径 {model_dir} 不存在")if not lora_path.exists():raise FileNotFoundError(f"LoRA 检查点 {lora_path} 不存在")llm = LLM(model=str(model_dir),enable_lora=True,dtype="float16",gpu_memory_utilization=0.9,max_model_len=4096,max_loras=1)except Exception as e:logger.error(f"vLLM 模型加载失败: {e}")raise# 配置采样参数以减少幻觉sampling_params = SamplingParams(temperature=0.5, # 降低随机性top_p=0.8, # 限制采样范围top_k=50, # 限制候选词repetition_penalty=1.1, # 惩罚重复max_tokens=256, # 限制输出长度stop=["<|eot_id|>"])# 定义 Gradio 推理函数def generate_response(prompt):try:messages = [{"role": "system", "content": "假设你是皇帝身边的女人--甄嬛。"},{"role": "user", "content": prompt}]tokenizer = AutoTokenizer.from_pretrained(str(model_dir), use_fast=False, trust_remote_code=True)input_text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)# 使用 vLLM 进行推理,应用 LoRA 权重outputs = llm.generate([input_text],sampling_params,lora_request=LoRARequest(lora_name="huanhuan_lora",lora_int_id=1,lora_path=str(lora_path)))response = outputs[0].outputs[0].text.strip()return responseexcept Exception as e:logger.error(f"推理失败: {e}")return f"错误: {str(e)}"# 创建 Gradio 界面logger.info("启动 Gradio 界面...")try:port = find_available_port(7860)logger.info(f"使用端口 {port} 启动 Gradio...")iface = gr.Interface(fn=generate_response,inputs=gr.Textbox(label="输入提示", placeholder="请输入您的问题,例如:你是谁?"),outputs=gr.Textbox(label="模型回复"),title="甄嬛风格对话模型 (Qwen2.5-0.5B-Instruct with LoRA)",description="输入提示,与微调后的 Qwen2.5-0.5B-Instruct 模型交互,体验甄嬛风格的回复。")iface.launch(share=False, server_name="0.0.0.0", server_port=port)except Exception as e:logger.error(f"Gradio 启动失败: {e}")raise# 主程序入口
if __name__ == '__main__':inference_vllm_gradio()
4.4 前置条件
-
依赖安装:
安装必要的 Python 包:pip install torch transformers datasets modelscope peft pandas tensorboard pip install --upgrade accelerate # 确保版本 >=0.34.2 -
数据集:
- 确保
huanhuan.json位于<BASE_DIR>/dataset/huanhuan.json。 - 数据集需包含
instruction、input和output列。 - 示例:
[{"instruction": "请以甄嬛的口吻回答:","input": "你是谁?","output": "吾乃甄嬛,昔日承蒙圣恩,然世事无常,今不过一介凡女耳。"},... ]
- 确保
-
硬件要求:
- 推荐使用至少 16GB 内存的 GPU(如 NVIDIA A100)。
- 支持 CPU 或 MPS(Apple Silicon),但速度较慢。
- 检查 GPU 可用性:
nvidia-smi
4.5 运行微调
-
保存脚本:
将代码保存为CUDA_LORA.py。 -
执行:
python CUDA_LORA.py -
监控训练:
- 每
logging_steps=10次迭代打印训练日志。 - 每
save_steps=100次迭代保存检查点至<BASE_DIR>/model_output/Qwen2.5-0.5B-Instruct_lora。 - 查看 TensorBoard 日志:
tensorboard --logdir=<BASE_DIR>/model_output/Qwen2.5-0.5B-Instruct_lora/logs
- 每
-
推理输出:
训练完成后,脚本将对提示“你是谁?”进行推理,预期输出:吾乃甄嬛,昔日皇帝身边之人,承蒙圣恩,然世事无常,今不过一介凡女耳。阁下何人也,缘何相询?
4.6 故障排除
-
版本不匹配(
keep_torch_compile):- 确保
accelerate>=0.34.2:pip install --upgrade accelerate - 或降级
transformers至 4.44.2:pip install transformers==4.44.2 - 验证版本:
pip show transformers accelerate
- 确保
-
内存溢出(OOM):
- 减少
per_device_train_batch_size或增加gradient_accumulation_steps:args = TrainingArguments(# ... 其他参数 ...per_device_train_batch_size=1,gradient_accumulation_steps=4, ) - 确保
gradient_checkpointing=True已启用。
- 减少
-
检查点未找到:
- 检查
<BASE_DIR>/model_output/Qwen2.5-0.5B-Instruct_lora中的最新检查点(如checkpoint-50),更新:lora_path = OUTPUT_DIR / 'checkpoint-50'
- 检查
-
数据集问题:
- 确保
huanhuan.json存在且格式正确。 - 若序列超过
max_length=384,可调整:tokenized_id = ds.map(lambda example: process_func(example, tokenizer, max_length=512),# ... )
- 确保
-
训练缓慢:
- 启用
bf16=True(或fp16=True用于旧 GPU)。 - 设置
dataloader_num_workers=2(需多核 CPU 支持):args = TrainingArguments(# ... 其他参数 ...dataloader_num_workers=2, )
- 启用
-
验证集:
本例未划分验证集。如需验证,可分割数据集:ds = load_dataset_data() ds = ds.train_test_split(test_size=0.2) # 80% 训练,20% 验证 train_dataset = ds['train'] eval_dataset = ds['test'] trainer = Trainer(# ... 其他参数 ...train_dataset=train_dataset,eval_dataset=eval_dataset, ) -
推理定制:
可修改inference函数中的prompt,例如:prompt = "如何应对后宫争斗?"
如需进一步定制(如添加验证集、计算困惑度或使用 Megatron-LM),请提供数据集大小、GPU 配置等详情,我将提供针对性解决方案。
5. 常见问题与优化
- 过拟合与欠拟合:如何通过正则化(如Dropout、Weight Decay)缓解。
- 灾难性遗忘:如何在微调时保留预训练知识(如使用差分学习率)。
- 计算资源优化:
- 混合精度训练(Mixed Precision Training)。
- 分布式训练与模型并行。
- 使用DeepSpeed或Megatron-LM优化大模型训练。
- 超参数调优:学习率调度、warm-up策略等。
5.1 解决模型幻觉问题
基于你提供的模型输出和问题分析(模型生成重复内容如“我愿为我这个做生母的尽尽义务”),以下是对微调过程中可能出现的问题及其原因的详细分析,以及解决方法的原理说明。内容聚焦于微调 Qwen2.5-0.5B-Instruct 模型(使用 LoRA 和 huanhuan.json 数据集)时出现的幻觉现象,重点阐述原理,避免代码。
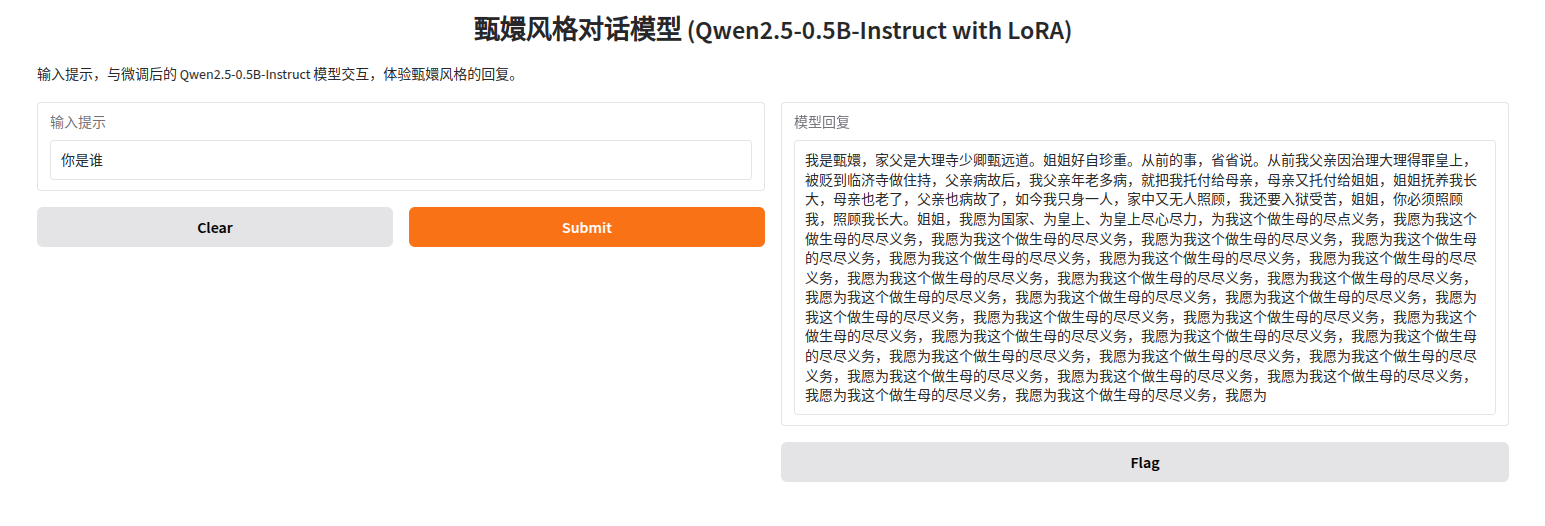
5.1.1. 问题分析:生成内容重复(幻觉现象)
现象:模型输出冗长,重复表达类似短语(如“我愿为我这个做生母的尽尽义务”),缺乏逻辑性和多样性。
原因分析:
- 采样参数不当:
- 在推理阶段,语言模型通过采样生成文本。较高的
temperature(如 0.7)会增加生成随机性,可能导致模型选择次优 token,陷入重复模式。 - 较高的
top_p(如 0.9)允许采样更多候选词,增加了生成冗长或循环内容的风险。 - 缺少
repetition_penalty或top_k限制,使得模型倾向于重复高概率短语,尤其在长生成中。
- 在推理阶段,语言模型通过采样生成文本。较高的
- 微调数据问题:
- 如果
huanhuan.json数据集中存在重复或模式化的表达(如多次出现类似“尽义务”的情感诉求),模型可能过拟合这些模式,导致生成时优先输出学到的重复内容。 - 数据集规模较小或多样性不足,会限制模型的泛化能力,使其在推理时“卡”在熟悉的短语上。
- 如果
- LoRA 权重过拟合:
- LoRA(低秩适配)通过少量参数微调模型,但若训练轮数过多或学习率过高(如
1e-4未适当调度),模型可能过拟合到huanhuan.json的特定模式,丢失生成多样性。 - LoRA 目标模块(如
q_proj,k_proj等)选择不当,可能导致模型在特定语义上过度强化,导致生成偏向固定表达。
- LoRA(低秩适配)通过少量参数微调模型,但若训练轮数过多或学习率过高(如
- 生成长度过长:
- 推理时设置较高的
max_tokens(如 512)可能使模型在缺乏足够上下文引导时,重复生成熟悉的短语以填充输出,特别是在微调数据中常见的情感表达。
- 推理时设置较高的
5.1.2. 解决方法与原理
解决方法 1:优化推理采样参数
原理:
- 语言模型生成文本时,通过概率分布采样下一个 token。调整采样参数可以控制生成内容的随机性和多样性,减少重复。
- 降低
temperature(如从 0.7 到 0.5):temperature控制概率分布的平滑度。较低值使模型更倾向于高概率 token,减少随机性,避免生成无关或重复内容。 - 降低
top_p(如从 0.9 到 0.8):top_p(核采样)限制采样到累计概率达到 p 的最小 token 集。较小的top_p聚焦于更可能的 token,减少低质量或循环输出。 - 添加
repetition_penalty(如 1.1):通过对已生成 token 的概率施加惩罚,降低重复短语的概率,鼓励模型探索新表达。 - 设置
top_k(如 50):限制采样到概率最高的 k 个 token,减少生成低概率、可能导致幻觉的词。 - 缩短
max_tokens(如从 512 到 256):限制生成长度,避免模型在长输出中因缺乏引导而重复熟悉模式,保持内容紧凑。
效果:通过约束采样过程,模型生成更聚焦、逻辑清晰的文本,减少陷入重复短语的倾向。
解决方法 2:改进微调数据集
原理:
- 模型的生成能力受训练数据质量和多样性影响。
huanhuan.json数据集如果包含重复或单一模式,模型会学到这些特征,导致生成类似模式。 - 数据清洗:检查数据集,移除重复的表达(如多次“尽义务”)或过于相似的样本。确保每个样本的
instruction、input和output提供独特信息,反映甄嬛风格的多样化表达(如哀怨、坚韧、机智等)。 - 数据增强:通过改写样本或引入新数据,增加语义和句式多样性。例如,为甄嬛风格添加不同场景的对话(如应对宫斗、表达忠诚、处理亲情),避免模型只学到单一情感。
- 数据集规模:小型数据集(如数百条)可能不足以泛化。增加数据量或使用外部高质量对话数据(如《后宫甄嬛传》台词)进行预微调,增强模型对甄嬛风格的理解。
- 平衡数据分布:确保数据集覆盖多种情感和语境,避免模型偏向某一类表达(如过度强调“尽义务”)。
效果:多样化的数据集使模型学习更丰富的语言模式,生成时能灵活应对不同输入,减少重复和幻觉。
解决方法 3:优化 LoRA 微调过程
原理:
- LoRA 通过在预训练模型上添加低秩矩阵微调少量参数,适合小规模数据。但不当的微调设置可能导致过拟合,使模型生成偏向训练数据的特定模式。
- 调整学习率和调度:使用较低的学习率(如
1e-5而非1e-4)并结合学习率调度(如线性衰减或 warm-up),避免模型快速收敛到数据中的重复模式。 - 控制训练轮数:减少
num_train_epochs(如从 3 到 1 或 2),或通过早停(early stopping)监控验证集损失,防止过拟合。 - 正则化:增加 LoRA 的
lora_dropout(如从 0.1 到 0.2)或在训练中加入权重衰减(如0.01),降低模型对训练数据噪声的敏感性。 - 选择适当目标模块:确保 LoRA 应用于关键模块(如
q_proj,k_proj,v_proj等),但避免过多模块导致过拟合。必要时测试更少模块(如仅q_proj,v_proj)。 - 验证集评估:从
huanhuan.json中划分 20% 验证集,监控困惑度(perplexity)或生成质量,检测过拟合迹象。
效果:优化微调过程使模型在保留甄嬛风格的同时,增强泛化能力,减少对训练数据中重复模式的依赖。
解决方法 4:后处理与生成约束
原理:
- 在推理阶段通过后处理或生成约束,进一步减少幻觉。
- 后处理去重:对生成文本进行后处理,检测并移除重复短语(如通过正则表达式匹配“我愿为.*尽尽义务”)。
- 上下文引导:在输入提示中提供更明确的指令(如“以甄嬛口吻,简洁表达对姐姐的请求”),引导模型生成聚焦内容。
- 多样性惩罚:在生成时动态调整 token 概率,鼓励使用同义表达(如“尽义务”替换为“报恩”或“尽责”)。
效果:通过约束生成过程和清理输出,减少重复内容,提升文本质量。
6. 模型评估
- 模型评估:
- 常用评估指标(如BLEU、ROUGE、困惑度等)。
- 在测试集上的性能分析。
- 对比微调前后模型性能。
7. 模型部署
- 模型部署:
- 推理优化:如量化(Quantization)、剪枝(Pruning)。
- 部署方式:本地部署、云服务(如AWS、Azure)、API服务。
- 使用工具:ONNX、Triton Inference Server等。
- 持续监控:模型在生产环境中的性能监控与更新。
7. 实际案例分析
- 案例1:NLP任务:如在特定领域(医疗、法律)微调BERT进行文本分类。
- 案例2:生成任务:微调LLaMA进行对话生成或问答系统。
- 案例3:跨模态任务:微调CLIP用于图像-文本任务。
- 经验总结:从案例中提取的微调技巧与注意事项。