Dify1.RAG学习(未完待续)
1.简介
RAG 检索增强生成(Retrieval Augmented Generation),简称 RAG,已经成为当前最火热的LLM应用方案。
理解不难,就是通过自有垂域数据库检索相关信息,然后合并成为提示模板,给大模型生成漂亮的回答。
经历23年年初那一波大模型潮,想必大家对大模型的能力有了一定的了解,但是当我们将大模型应用于实际业务场景时会发现,通用的基础大模型基本无法满足我们的实际业务需求,主要有以下几方面原因:
(1)知识的局限性:模型自身的知识完全源于它的训练数据,而现有的主流大模型(ChatGPT、文心一言、通义千问…)的训练集基本都是构建于网络公开的数据,对于一些实时性的、非公开的或离线的数据是无法获取到的,这部分知识也就无从具备。
(2)幻觉问题:所有的AI模型的底层原理都是基于数学概率,其模型输出实质上是一系列数值运算,大模型也不例外,所以它有时候会一本正经地胡说八道,尤其是在大模型自身不具备某一方面的知识或不擅长的场景。而这种幻觉问题的区分是比较困难的,因为它要求使用者自身具备相应领域的知识。
(3)数据安全性:对于企业来说,数据安全至关重要,没有企业愿意承担数据泄露的风险,将自身的私域数据上传第三方平台进行训练。这也导致完全依赖通用大模型自身能力的应用方案不得不在数据安全和效果方面进行取舍。
而RAG是解决上述问题的一套有效方案。
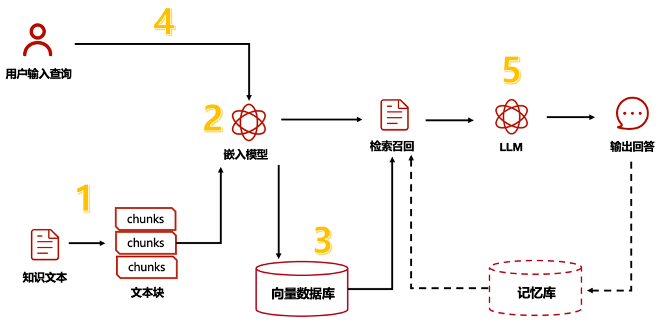
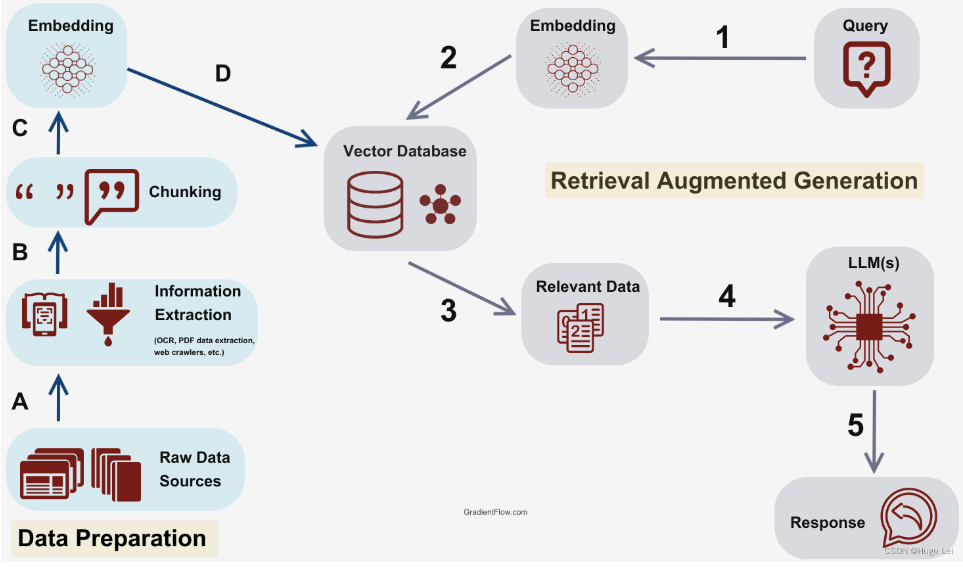
一句话总结:RAG(中文为检索增强生成) = 检索技术 + LLM 提示。例如,我们向 LLM 提问一个问题(answer),RAG 从各种数据源检索相关的信息,并将检索到的信息和问题(answer)注入到 LLM 提示中,LLM 最后给出答案。
这就是 RAG 系统所做的事情:帮助大模型临时性地获得他所不具备的外部知识,允许它在回答问题之前先找答案。
RAG 概念简介 - Dify Docs
2. 详解
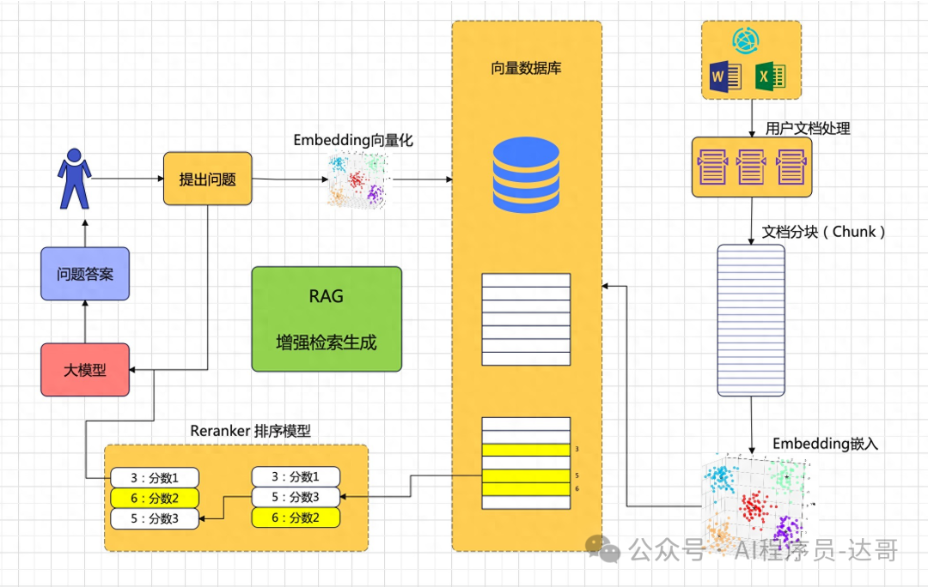
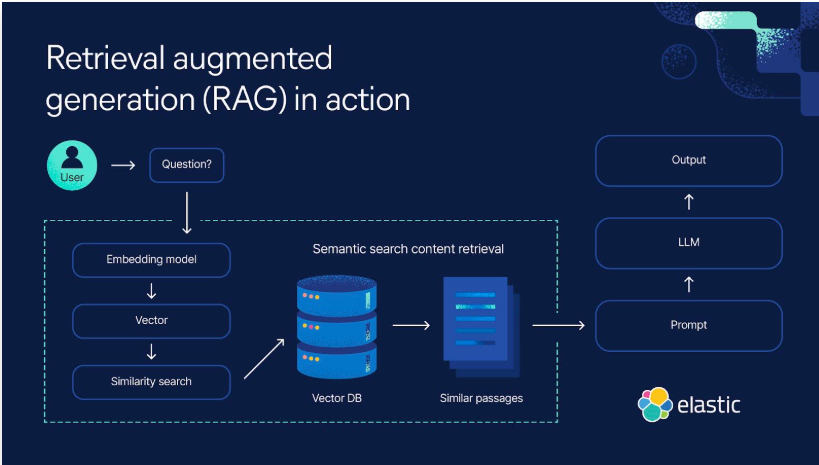
RAG 涉及的核心流程如下所示:
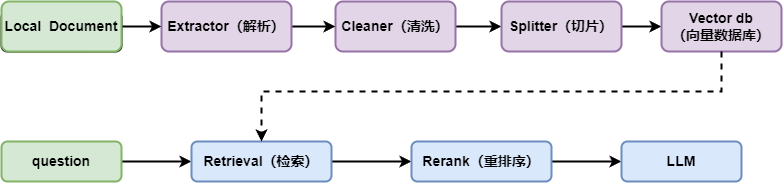
2.1 Extractor
Extractor 对应的 Dify 中的文件解析模块,用于从原始文件中提取文字内容。核心的文件解析流程在 api/core/rag/extractor/extract_processor.py 中实现。如下可以看出该模块能够提取传入的文本内容,为后续的处理做准备。
2.2 Cleaner 数据清洗
对收集到的数据进行清洗,去除噪声、重复项和无关信息,确保数据的质量和准确性。
Cleaner 对应的解析内容的清洗模块,可以去除无关的字符,减少后续 token 的消耗。最核心的清洗流程在 api/core/rag/cleaner/clean_processor.py 中,目前主要是基于特定规则进行过滤:
import reclass CleanProcessor:@classmethoddef clean(cls, text: str, process_rule: dict) -> str:# default clean# remove invalid symbol 清除无效字符text = re.sub(r"<\|", "<", text) # 将 "<|" 替换为 "<"text = re.sub(r"\|>", ">", text) # 将 "|>" 替换为 ">"## 删除控制字符和非法 Unicode 字符text = re.sub(r"[\x00-\x08\x0B\x0C\x0E-\x1F\x7F\xEF\xBF\xBE]", "", text)# Unicode U+FFFEtext = re.sub("\ufffe", "", text)# 从 process_rule 中提取预处理规则,遍历每条规则并根据条件执行rules = process_rule["rules"] if process_rule else {}if "pre_processing_rules" in rules:pre_processing_rules = rules["pre_processing_rules"]for pre_processing_rule in pre_processing_rules:if pre_processing_rule["id"] == "remove_extra_spaces" and pre_processing_rule["enabled"] is True:# Remove extra spaces 移除多余空格# 合并连续换行符(3+ 换行为 2 换行)pattern = r"\n{3,}"text = re.sub(pattern, "\n\n", text)# 合并连续空白字符(空格、制表符等)pattern = r"[\t\f\r\x20\u00a0\u1680\u180e\u2000-\u200a\u202f\u205f\u3000]{2,}"text = re.sub(pattern, " ", text)elif pre_processing_rule["id"] == "remove_urls_emails" and pre_processing_rule["enabled"] is True:# Remove email 移除emailpattern = r"([a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+\.[a-zA-Z0-9-.]+)"text = re.sub(pattern, "", text)# Remove URL but keep Markdown image URLs# First, temporarily replace Markdown image URLs with a placeholdermarkdown_image_pattern = r"!\[.*?\]\((https?://[^\s)]+)\)"placeholders: list[str] = []def replace_with_placeholder(match, placeholders=placeholders):url = match.group(1)placeholder = f"__MARKDOWN_IMAGE_URL_{len(placeholders)}__"placeholders.append(url)return f""text = re.sub(markdown_image_pattern, replace_with_placeholder, text)# Now remove all remaining URLs 删除剩余URLSurl_pattern = r"https?://[^\s)]+"text = re.sub(url_pattern, "", text)# Finally, restore the Markdown image URLsfor i, url in enumerate(placeholders):text = text.replace(f"__MARKDOWN_IMAGE_URL_{i}__", url)return textdef filter_string(self, text):return text
目前支持的内容清洗主要是清理空格换行符以及清理email和url,默认情况下会清理空格换行符,但是不会开启清理 Email 和 Url。用户可以在前端页面进行调整。
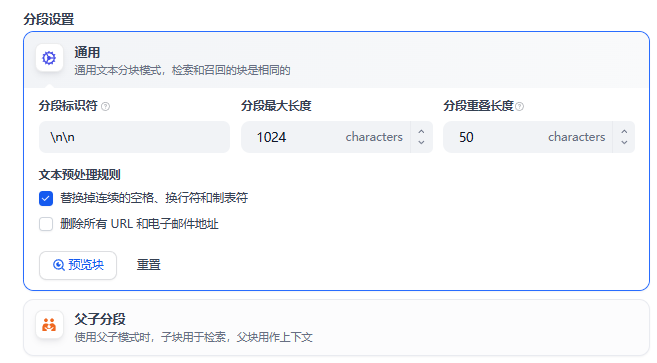
2.3 知识库构建
splitter 切块 + embeding + 存储
知识库构建: 将清洗后的数据构建成知识库。这通常包括将文本分割成较小的片段(chunks),使用文本嵌入模型(如GLM)将这些片段转换成向量,并将这些向量存储在向量数据库(如FAISS、Milvus等)中。
2.3.1 split
为什么说分块很重要?
文档通常包含丰富的上下文信息和复杂的语义结构,通过将文档分块,模型可以更有效地提取关键信息,并减少不相关内容的干扰。分块的目标在于确保每个片段在保留核心语义的同时,具备相对独立的语义完整性,从而使模型在处理时不必依赖广泛的上下文信息,增强检索召回的准确性。
分块策略最大的挑战在于确定分块的大小。如果片段过大,可能导致向量无法精确捕捉内容的特定细节并且计算成本增加;若片段过小,则可能丢失上下文信息,导致句子碎片化和语义不连贯。较小的块适用于需要细粒度分析的任务,例如情感分析,能够精确捕捉特定短语或句子的细节。更大的块则更为合适需要保留更广泛上下文的场景,例如文档摘要或主题检测。因此,块大小的确定必须在计算效率和上下文信息之间取得平衡。
分块策略
最佳的分块策略取决于具体的应用场景,而非行业内的统一标准。根据场景中文档内容的特点和查询问题的需求,选择最合适该场景的分块策略,以确保RAG系统中大模型能够更精确地处理和检索数据。
多种分块策略从本质上来看,由以下三个关键组成部分构成:
- 大小:每个文档块所允许的最大字符数。
- 重叠:在相邻数据块之间,重叠字符的数量。
- 拆分:通过段落边界、分隔符、标记,或语义边界来确定块边界的位置。
上述三个组成部分共同决定了分块策略的特性及其适用场景。基于这些组成部分,常见的分块策略包括:固定大小分块(Fixed Size Chunking)、重叠分块(Overlap Chunking)、递归分块(Recursive Chunking)、文档特定分块(Document Specific Chunking)、语义分块(Semantic Chunking)、混合分块(Mix Chunking)。
2.3.2 Embeding
Text-Embedding 技术是一种将文本数据转换为向量的技术,通过深度学习模型将文本的语义信息嵌入到高维向量空间中。这些向量不仅能表达文本内容,还能捕捉文本之间的相似性和关系,从而让计算机高效地进行文本检索、分类、聚类等任务。
Text-Embedding 的工作原理
- 文本处理与输入:对原始文本进行预处理(如分词、去除停用词、规范化)后,将其输入深度学习模型。
- 词嵌入生成:每个词、子词或字符被映射到高维空间中的向量。基于 Transformer 架构的模型(如 BERT)能够生成上下文感知的嵌入,例如 "bank" 在不同上下文中有不同的嵌入表示。
- 上下文建模:通过 Transformer 的自注意力机制,模型学习文本中单词之间的关系,使嵌入包含上下文信息。
- 文本向量生成:经过多层神经网络计算,模型将文本转换为固定长度的向量,用于相似度计算、分类、聚类等任务。
2.3.3 向量存储
在人工智能(AI)主导的时代,文字、图像、语音、视频等多模态数据的复杂性显著增加。由于这些数据具有非结构化和多维特征,向量表示能够有效表示语义和捕捉其潜在的语义关系,促使向量数据库成为存储、检索和分析高维数据向量的关键工具。
下图展示了向量数据库的分类,依据是否开源与是否为专用向量数据库,将其分为四类。
- 第一类是开源的专用向量数据库,如 Chroma、Vespa、LanceDB、Marqo、Qdrant 和 Milvus,这些数据库专门设计用于处理向量数据。
- 第二类是支持向量搜索的开源数据库,如 OpenSearch、PostgreSQL、ClickHouse 和 Cassandra,它们是常规数据库,但支持向量搜索功能。
- 第三类是商用的专用向量数据库,如Weaviate和Pinecone,它们专门用于处理向量数据,但属于商业产品或通过商业许可获得源码。
- 第四类是支持向量搜索的商用数据库,如Elasticsearch、Redis、Rockset和SingleStore,这些常规数据库支持向量搜索功能,同时属于商业产品或可通过商业许可获得源码。
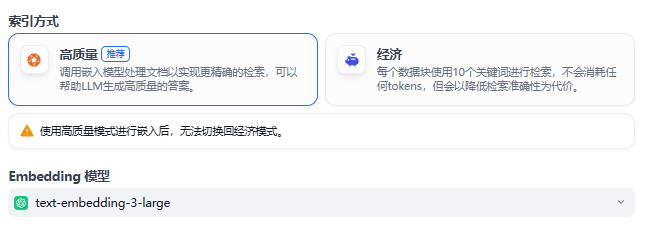
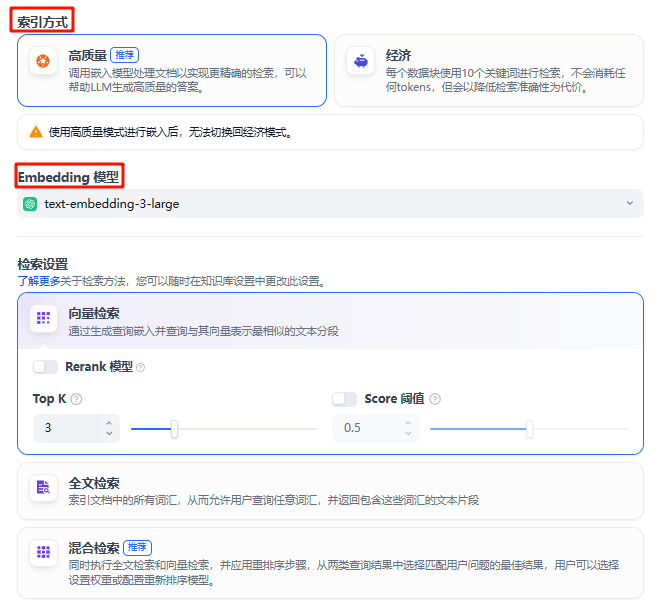
2.4 Retrieval 检索
用户查询(question)转换为向量,从数据库中检索相关知识。
- 关键词检索(经济)
- 向量检索
- 全文检索
- 混合检索
检索
- RAG 从输入查询开始。这可以是用户的问题,或者需要详细回复的任意一段文本。
- 检索模型会从知识库、数据库或外部来源(或者同时从多个来源)抓取相关信息。模型在何处搜索取决于输入查询所询问的内容。检索到的这一信息现在可以作为模型所需要的任何事实或背景信息的参考来源。
- 检索到的信息会被转化为高维度空间中的向量。这些知识向量存储在向量数据库中。
- 向量模型会基于与输入查询的相关性,对检索到的信息进行排序。分数最高的文档或段落会被选中,以进行进一步的处理。
Rerank
Rerank 就是对检索的结果进行重新排序,重排序的效果与 Rerank 模型和对应的配置有关,用户可以在检索设置页进行设置:
生成
- 接下来,生成模型(例如 LLM)会使用检索到的信息来生成文本回复。
- 生成的文本可能会经过额外的后处理步骤,以确保其语法正确,语义连贯。
- 整体而言,这些回复更加准确,也更符合语境,因为这些回复使用的是检索模型所提供的补充信息。在缺少公共互联网数据的专业领域,这一功能尤其重要。
3. RAG一些流程图
什么是检索增强生成 (RAG)?| RAG 全面指南 | Elastic
RAG概述(一):RAG架构的演进_rag的三个阶段-CSDN博客
RAG检索增强之ReRank(重新排序)模型 - 53AI-AI知识库|大模型知识库|大模型训练|智能体开发
05 RAG向量数据库原理与常用向量库 - 极客时间文档