深度学习的相关术语介绍(杂乱版-想到啥介绍啥)
损失函数(Loss Function)
- 交叉熵损失(Cross-Entropy Loss):分类任务常用。
- 均方误差(MSE, Mean Squared Error):回归任务常用,如预测药物分子结合能。
- 二元交叉熵(Binary Cross-Entropy):二分类任务(如药物毒性预测)。
- 对比损失(Contrastive Loss):度量学习(如分子相似性比较)
数据预处理与表示
- 分子表示方法
- SMILES:字符串表示(如
CCO代表乙醇)。 - SELFIES:更鲁棒的分子字符串编码方式。
- 分子图(Molecular Graph):节点(原子)、边(化学键)的图结构。
- 3D分子构象:通过RDKit或分子动力学模拟生成。
- SMILES:字符串表示(如
- 特征工程
- 分子描述符(Descriptors):如分子量、LogP、极性表面积。
- 分子指纹(Fingerprints):二进制向量表示分子特征,MACCS、ECFP4(Extended Connectivity Fingerprint)
正则化技术
- 过拟合:过拟合是指模型在训练数据上表现过于优秀,但在未见过的测试数据上表现显著下降的现象。模型过度记忆了训练数据中的噪声和细节,而非学习到泛化规律。
- 欠拟合:欠拟合是指模型在训练数据和测试数据上均表现不佳,无法捕捉数据中的基本模式。
1.L1/L2正则化
- 原理:在损失函数中增加权重的惩罚项,限制模型复杂度,防止过拟合。
- L1正则化:添加权重绝对值之和(λ∑∣w∣λ∑∣w∣),使部分权重趋近于0(特征选择)。
- L2正则化:添加权重平方和(λ∑w2λ∑w2),使权重均匀变小。
- 例子:
- 药物预测:假设模型用100个分子描述符预测活性,L1正则化可能筛选出其中10个关键描述符(如LogP、极性表面积),忽略无关特征。
- 通俗比喻:L1像严格导师,逼你只学重点;L2像温和导师,让你所有知识都学但别钻牛角尖。
2.Dropout
- 原理:训练时随机屏蔽部分神经元,强迫网络不依赖单一通路,增强泛化能力。
- 例子:
- 药物预测:小数据集训练毒性分类模型时,Dropout可防止模型死记硬背某些分子结构,提高对未知分子的泛化能力。
- 通俗比喻:考试前复习时,随机跳过某些知识点,逼自己全面掌握。
优化算法
1.梯度下降(Gradient Descent)
- 原理:沿损失函数梯度方向更新参数,寻找最小值。
- 批量梯度下降:用全部数据计算梯度(稳定但慢)。
- 随机梯度下降(SGD):用单个样本计算梯度(快但不稳定)。
- 小批量梯度下降:折中方案(常用)。
- 例子:
- 药物预测:调整模型参数,使预测的pIC50(药物活性)更接近实验值。
- 通俗比喻:蒙眼下山,每走一步用脚试探坡度最陡的方向。
2.Adam
- 原理:结合动量(惯性)和自适应学习率(每个参数单独调整步长)。
- 例子:
- 药物预测:训练复杂图神经网络时,Adam能快速收敛,避免手动调整学习率。
- 通俗比喻:下山时不仅看坡度,还考虑之前几步的动量,胖的人惯性大,瘦的人灵活调整方向。
3.RMSProp
- 原理:对梯度平方进行指数移动平均,缓解非平稳目标(如稀疏梯度)的影响。
- 例子:
- 药物预测:处理基因序列数据(某些区域梯度变化剧烈),RMSProp比SGD更稳定。
- 通俗比喻:下山时遇到乱石坡,穿防滑鞋(调整步幅)比普通鞋更稳。
训练流程与数据处理
1.前向传播 & 反向传播
- 前向传播:数据从输入层到输出层的计算过程。
- 反向传播:根据损失函数计算梯度,从输出层反向传播到输入层。
- 例子:
- 药物预测:输入分子指纹→模型预测活性(前向);若预测错误,反向调整权重(反向)。
- 通俗比喻:前向像学生答题,反向像老师批改后指出错误并让学生订正。
2.特征工程
- 原理:人工设计或选择对任务有用的特征。
- 例子:
- 药物预测:从分子结构中提取描述符(如氢键供体数、分子量)。
- 通俗对比:深度学习模型可以自动学习特征,但小数据时仍需人工特征(如用RDKit计算分子性质)。
3.数据增强
- 原理:通过变换生成新样本,增加数据多样性。
- 例子:
- 药物预测:对分子3D结构进行旋转、镜像生成新构象。
- 通俗比喻:拍照时换角度和光线,让模型学会识别不同姿态的同一个人。
4.标签平滑(Label Smoothing)
- 原理:将硬标签(如0或1)替换为软标签(如0.1或0.9),防止模型过度自信。
- 例子:
- 药物预测:毒性标签可能存在实验误差,将标签从[1, 0]改为[0.9, 0.1]。
- 通俗比喻:老师批卷时,不确定答案是否全错,给部分分数而非0分。
超参数调优
1.学习率(Learning Rate)
- 原理:控制参数更新步长。
- 例子:
- 药物预测:学习率太大会跳过最优解(如预测IC50时误差震荡),太小则训练过慢。
- 通俗比喻:下山时步幅太大可能跨过山谷,太小则半天走不到。
2.网格搜索 vs 随机搜索 vs 贝叶斯优化
- 网格搜索:暴力遍历所有超参数组合(如学习率[0.1, 0.01],隐藏层[64, 128])。
- 随机搜索:随机抽样超参数,更高效。
- 贝叶斯优化:基于已有结果动态调整搜索方向。
- 例子:
- 药物预测:优化GNN的超参数(层数、Dropout率),贝叶斯优化比网格搜索快10倍。
- 通俗比喻:网格搜索像地毯式搜山,随机搜索像扔飞镖,贝叶斯优化像用探测器找宝藏。
梯度问题与归一化
1.梯度消失/爆炸
- 原理:深层网络中梯度连乘后趋近于0(消失)或无穷大(爆炸)。
- 例子:
- 药物预测:训练10层GNN时,梯度消失导致底层参数无法更新。
- 解决:用残差连接(ResNet)、LSTM、梯度裁剪(限制梯度的大小,防止参数更新步长过大,同时保持梯度方向不变)。
2.残差连接(Residual Connection)
- 原理:H(x)=F(x)+x,允许梯度直接跳过某些层。
- 例子:
- 药物预测:在深层GNN中,残差连接防止梯度消失,提升模型性能。
- 通俗比喻:快递员送货时走主路(残差路径),堵车时可绕小路(非线性变换)。
归一化与标准化
1.归一化的作用
调整数据分布,使其更符合模型学习的假设(如线性可分性、梯度稳定性)。
(1). 加速模型训练
- 原因:输入数据或中间层输出的分布差异过大会导致梯度不稳定(如某些特征值远大于其他特征)。
- 示例:
- 药物分子特征:若分子量范围是[0, 1000],而氢键数范围是[0, 10],未归一化时模型会过度关注分子量。
- 归一化后:所有特征被缩放到相近范围(如[-1, 1]),梯度更新更均衡。
(2). 缓解梯度问题
- 梯度消失/爆炸:深层网络中,输入分布剧烈变化(变化幅度大)会导致梯度异常(如激活函数饱和)。
- 示例:
- 使用Sigmoid激活函数时,未归一化的输入可能集中在函数饱和区(梯度趋近于0)。
- 归一化后:输入集中在激活函数敏感区(如Sigmoid的线性区),梯度正常传播。
(3). 减少对参数初始化的依赖
- 未归一化时:模型对初始权重的选择极其敏感,可能导致训练失败。
- 归一化后:无论初始权重如何,输入分布会被调整到稳定范围内,模型更容易收敛。
2.归一化与标准化的区别
(1). 标准化(Standardization)
-
定义:将数据转换为均值为0、标准差为1的分布,公式:
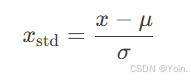
-
特点:
- 适用于数据分布近似高斯(正态分布)的场景。
- 全局性调整:不改变数据范围,保留异常值信息。
-
应用场景:
- 数据预处理:在输入模型前标准化原始数据(如药物分子描述符)。
- 示例:将IC50值标准化为均值为0的分布。
(2). 归一化(Normalization)
-
定义:将数据缩放到特定范围(如[0, 1]或[-1, 1]),常用方法:
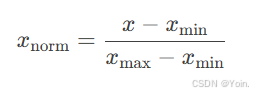
-
特点:
- 适用于数据分布不明确或需要强制限定范围的场景。
- 局部性调整:可能丢失异常值信息(如最大值远大于其他值)。
-
应用场景:
- 图像像素值:缩放到[0, 1]或者[-1,1]范围。
- 药物分子特征:将分子量归一化到[0, 1]方便模型处理。
| 对比点 | 归一化 | 标准化 |
|---|---|---|
| 概念 | 将数值规约到(0,1)或(-1,1)区间 | 将对应数据的分布规约在均值为0,标准差为1的分布上 |
| 侧重点 | 数值的归一,丢失数据的分布信息,对数据之间的距离未保留,但保留了权重 | 数据分布的归一,保留样本之间的距离,但丢失权值 |
| 缺点 | 1. 丢失样本间的距离信息; 2. 鲁棒性差(新样本易影响最值) | 1. 丢失样本间的权重信息 |
| 适合场景 | 1. 小数据/固定数据; 2. 不涉及距离度量、数据非正态分布; 3. 多指标综合评价 | 1. 需距离度量的分类/聚类; 2. 鲁棒性要求高或数据范围未知 |
| 缩放方式 | 先平移(减最小值),后缩放(除以最值差) | 先平移(减均值),后缩放(除以标准差) |
| 目的 | 消除量纲,便于多指标综合评价 | 便于梯度下降和激活函数处理(数据以0为中心分布,匹配Sigmoid/Tanh等函数) |
3.深度学习中的归一化技术
(1). 批量归一化(Batch Norm)
- 原理:对每个特征通道在批次维度上进行归一化(即同一批次的所有样本)。
- γ和β是可学习参数,用于恢复模型的表达能力。
- 优点:
- 加速训练,允许更大的学习率。
- 减少对初始化的依赖。
- 缺点:
- 依赖批次大小,小批次时效果不稳定(如药物小数据集)。
- 不适用于序列数据(如RNN处理可变长蛋白质序列)。
- 药物预测示例:
- 在分子图神经网络中,对每个原子的特征进行批量归一化,加速训练。
(2). 层归一化(Layer Norm)
- 原理:对单个样本的所有特征进行归一化(同一层的神经元)。
- 优点:
- 不依赖批次大小,适合小批次或动态序列(如蛋白质序列)。
- 在Transformer和RNN中表现稳定。
- 缺点:
- 对特征间的相关性敏感(如分子图中原子特征可能需独立处理)。
- 药物预测示例:
- 处理长度不一的蛋白质序列时,对每个氨基酸的特征进行层归一化。
多模态与高级技术
1.跨模态注意力(Cross-Modal Attention)
- 原理:让不同模态数据(如图像和文本)互相引导注意力。
- 例子:
- 药物-靶点预测:分子图和蛋白质序列分别编码,通过注意力机制交互。
- 通俗比喻:医生同时看CT片(图像)和病历(文本),综合判断病情。
2.混合专家系统(MoE)
- 原理:多个专家模型分别处理不同子任务,门控网络动态组合结果。
- 例子:
- 多任务药物预测:专家1预测活性,专家2预测毒性,门控网络根据输入分配权重。
- 通俗比喻:会诊时,内科、外科专家分别发言,主任综合意见。