Spark Streaming 内部运行机制详解
核心思想:将实时数据流切割为“微批次”,利用 Spark Core 的批处理能力进行准实时计算。
1. 核心流程拆解
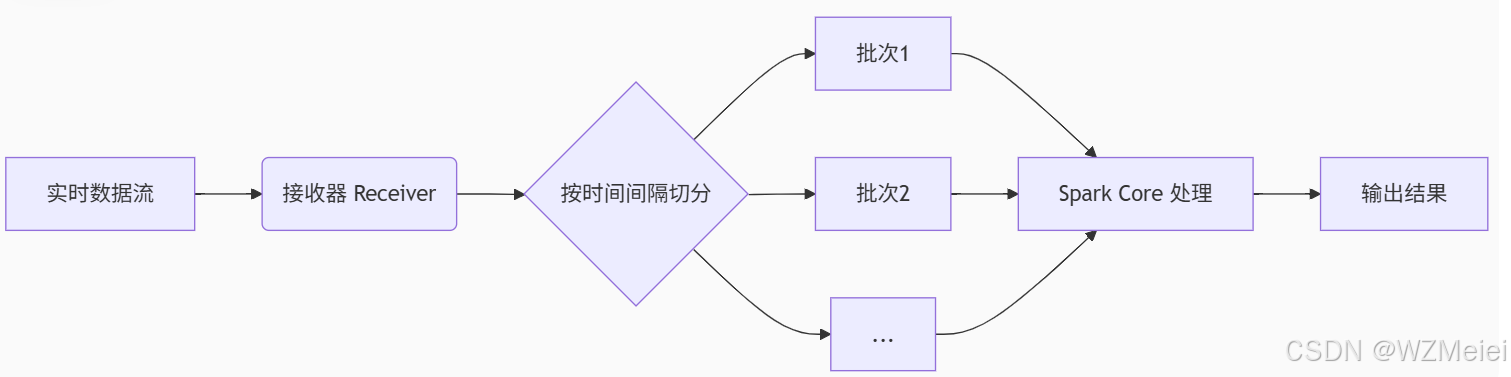
-
数据接收(Input Data Stream)
-
输入源:Kafka、Flume、Socket 等实时数据流。
-
接收器(Receiver):Spark Streaming 启动接收器线程,持续监听数据流并缓存到内存(或磁盘)。
-
-
批次划分(Micro-Batching)
-
时间窗口:按固定时间间隔(如 1秒、5秒)将数据流切割为多个小批次(DStream)。
-
示例:若间隔为 2秒,则每 2秒的数据组成一个批次,形成
Batch 1,Batch 2...
-
-
Spark Core 处理
-
RDD 转换:每个批次的数据转换为一个 RDD,调用 Spark Core 的算子(如
map、reduce)处理。 -
并行计算:Driver 将任务分发给 Executor,各节点并行处理对应分区的数据。
-
-
结果输出
-
输出操作:处理完一个批次后,结果写入外部系统(如 HDFS、数据库)或展示在实时仪表盘。
-
2. 核心概念:DStream(离散化流)
-
本质:DStream 是 Spark Streaming 的核心抽象,表示按时间切分的 RDD 序列。
-
特性:
-
每个时间间隔生成一个 RDD(如
DStream = [RDD1, RDD2, ...])。 -
支持与 RDD 类似的转换操作(如
map、filter、reduceByKey)。
-
示例代码:
// 创建 DStream(从 Socket 接收数据,批次间隔 1秒)
val ssc = new StreamingContext(sparkConf, Seconds(1))
val lines = ssc.socketTextStream("localhost", 9999)// 处理数据:按单词拆分并计数
val words = lines.flatMap(_.split(" "))
val wordCounts = words.map(word => (word, 1)).reduceByKey(_ + _)// 输出结果
wordCounts.print()
ssc.start() // 启动计算
ssc.awaitTermination() // 等待终止3. 为何称为“准实时”?
-
微批处理(Micro-Batching):
-
数据按固定时间窗口(如 1秒)分批处理,延迟 = 窗口间隔 + 处理时间(通常秒级)。
-
对比真正的实时处理(如 Flink 的逐事件处理),延迟稍高但吞吐量更大。
-
-
适用场景:
-
日志分析、实时仪表盘、异常检测等允许秒级延迟的场景。
-
不适用于毫秒级延迟需求(如高频交易)。
-
4. 容错与可靠性
-
数据恢复:
-
Checkpoint 机制:定期保存 DStream 的血缘(Lineage)和元数据,故障时从检查点恢复。
-
WAL(Write-Ahead Log):接收器将数据写入预写日志,确保数据不丢失。
-
-
Exactly-Once 语义:
-
结合事务性写入(如数据库事务),保证每个批次的数据处理且仅处理一次。
-
5. 性能优化要点
| 优化方向 | 方法 |
|---|---|
| 减少批次间隔 | 缩小窗口间隔(如从 2秒 → 1秒),但需平衡吞吐量和延迟。 |
| 并行度调整 | 增加接收器和 Executor 的数量,提升数据接收与处理并行度。 |
| 内存管理 | 控制接收器缓存大小(spark.streaming.receiver.maxRate),避免 OOM。 |
| 背压机制 | 启用 spark.streaming.backpressure.enabled,动态调整接收速率。 |
总结
Spark Streaming = 微批处理 + Spark Core 批处理引擎
-
优势:继承 Spark 的易用性、容错性和高吞吐量。
-
局限:秒级延迟,不适合超低延迟场景(此类需求可转向 Structured Streaming 或 Flink)。
-
核心公式:
实时数据流 → 按时间切分为 DStream → 转换为 RDD 批次处理 → 输出结果