大数据课设——基于电影数据集,分析导演影响力,绘制各种可视化图表
大数据课设(天大22级电信,由本人开源)
一. 数据集准备
1. 选择数据集
电影娱乐:IMDb 完整电影数据集
- 数据规模:5.6 万部电影(CSV 格式 43MB)
- 数据来源:Kaggle
- 字段信息:
title,rating,year,users_rating,votes,metascore,img_url,countries,languages,actors,genre,tagline,description,directors,runtime,imdb_url - 标题、评分、年份、用户评分、投票数、媒体评分、图片网址、国家、语言、演员、类型、宣传语、剧情简介、导演、时长、互联网电影数据库(IMDb)网址
网址:https://www.kaggle.com/datasets/gorochu/complete-imdb-movies-dataset/data
2. 下载数据集
去官网下载到个人电脑
用java程序上传本地文件到 HDFS
写入完成
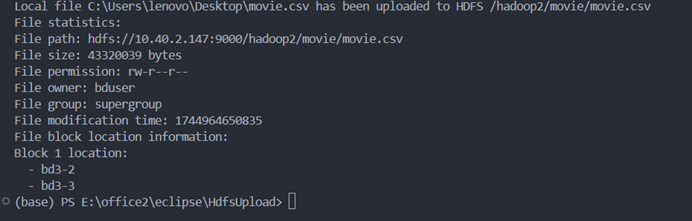
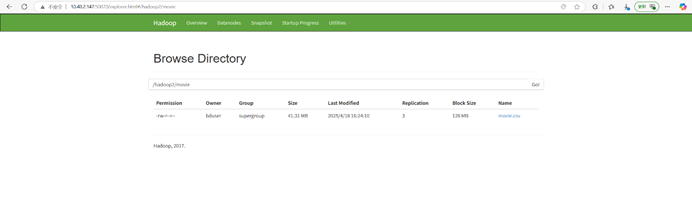
网站上存在
运行 hdfs dfs -cat /hadoop2/movie/movie.csv 查看数据
二、开始实验
1. 数据清洗与预处理
使用MapReduce:清洗缺失字段(如票房、评分)并输出有效数据
Map任务
输入 (Input Key-Value)
- Key:
LongWritable- 表示输入文件中的行偏移量(行号) - Value:
Text- 表示输入文件中的一行文本(CSV格式的电影数据)
处理过程
- 跳过表头:检查是否是第一行(key=0)且包含"title",如果是则跳过
- CSV解析:使用自定义的
parseCSVLine方法解析CSV行,处理引号内的逗号 - 字段提取:
- 从IMDB URL中提取电影ID(使用正则表达式匹配"tt"开头的ID)
- 提取电影名称、评分、类型和导演信息
- 数据清洗:
- 去除字段前后的空格和引号
- 处理列表字段(如类型和导演),将格式从"[‘item1’, ‘item2’]“转换为"item1, item2”
- 数据验证:
- 检查关键字段是否为空(电影名称、导演)
- 验证评分是否为有效数值(使用正则表达式检查数字格式)
- 过滤:如果任何关键字段缺失或无效,则跳过该记录
输出 (Output Key-Value)
- Key:
Text- 电影ID(从IMDB URL提取的"tt"开头的ID) - Value:
Text- 清洗后的电影数据,格式为:“电影ID,电影名称,评分,类型,导演”
Reduce任务
输入 (Input Key-Value)
- Key:
Text- 电影ID(与Map输出Key相同) - Value:
Iterable<Text>- 同一电影ID对应的所有清洗后的电影数据记录(实际上由于电影ID唯一,通常只有一条)
处理过程
- 数据合并:对于每个电影ID,遍历其所有记录
- 输出选择:只取第一条完整的记录(通过
break语句实现)- 注:当前实现中,如果同一电影ID有多条记录,只输出第一条;可根据需求修改为合并逻辑
输出 (Output Key-Value)
- Key:
NullWritable- 不使用Key(设置为空) - Value:
Text- 最终清洗后的电影数据,格式与Map输出相同:“电影ID,电影名称,评分,类型,导演”
编写java程序,代码如下:
package com.movie;import java.io.IOException;
import java.util.Properties;
import java.util.regex.Matcher;
import java.util.regex.Pattern;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;/*** MovieDataCleaner - 清洗电影数据,过滤缺失字段和非法值* 输出格式: 电影ID,电影名称,评分,类型,导演*/
public class MovieDataCleaner {/*** 电影数据清洗的Mapper类:* 1. 解析CSV数据* 2. 过滤缺失字段和非法值* 3. 输出有效数据*/public static class MovieCleanMapper extends Mapper<LongWritable, Text, Text, Text> {private Text outputKey = new Text();private Text outputValue = new Text();// 用于验证评分是否为有效数值的正则表达式private Pattern ratingPattern = Pattern.compile("^\\d+(\\.\\d+)?$");// 用于提取IMDB ID的正则表达式private Pattern imdbIdPattern = Pattern.compile("tt\\d+");@Overridepublic void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {// 跳过CSV文件的头行(如果有)if (key.get() == 0 && value.toString().toLowerCase().contains("title")) {return;}String line = value.toString();String[] fields = parseCSVLine(line);// 检查是否有足够的字段if (fields.length < 15) {return;}// 从IMDB URL中提取电影IDString movieId = extractImdbId(fields[fields.length - 1]);// 如果无法提取ID,则跳过这条记录if (movieId.isEmpty()) {return;}// 提取电影名称(第1个字段)String movieName = cleanField(fields[0]);// 提取评分(第4个字段)- 注意索引从0开始String rating = cleanField(fields[3]);// 提取类型(第10个字段)String genre = cleanField(fields[9]);// 从格式 "['Comedy', 'Drama']" 中提取清洁的类型列表genre = cleanListField(genre);// 提取导演(第13个字段)String director = cleanField(fields[12]);// 从格式 "['Director Name']" 中提取清洁的导演名称director = cleanListField(director);// 验证关键字段不为空if (isEmpty(movieName) || isEmpty(director)) {return;}// 验证评分是否为有效数值if (isEmpty(rating) || !isValidRating(rating)) {return;}// 验证类型不为空if (isEmpty(genre)) {return;}// 设置输出outputKey.set(movieId);outputValue.set(movieId + "," + movieName + "," + rating + "," + genre + "," + director);context.write(outputKey, outputValue);}/*** 从IMDB URL中提取电影ID*/private String extractImdbId(String url) {if (url == null || url.isEmpty()) {return "";}Matcher matcher = imdbIdPattern.matcher(url);if (matcher.find()) {return matcher.group();}return "";}/*** 解析CSV行,正确处理引号内的逗号*/private String[] parseCSVLine(String line) {// 这是一个简单的CSV解析器,更复杂的情况可能需要使用专门的CSV解析库java.util.List<String> result = new java.util.ArrayList<>();StringBuilder currentField = new StringBuilder();boolean inQuotes = false;for (int i = 0; i < line.length(); i++) {char c = line.charAt(i);if (c == '"') {inQuotes = !inQuotes;} else if (c == ',' && !inQuotes) {result.add(currentField.toString());currentField = new StringBuilder();} else {currentField.append(c);}}// 不要忘记添加最后一个字段result.add(currentField.toString());return result.toArray(new String[0]);}/*** 清洗字段:去除前后空格和引号*/private String cleanField(String field) {if (field == null) {return "";}return field.trim().replaceAll("^\"|\"$", "");}/*** 清洗列表字段:从格式 "['item1', 'item2']" 提取为 "item1, item2"*/private String cleanListField(String field) {if (field == null || field.isEmpty()) {return "";}// 移除 [' 和 '] 等字符String cleaned = field.replaceAll("\\[\\s*'", "").replaceAll("'\\s*\\]", "").replaceAll("'\\s*,\\s*'", ", ");return cleaned;}/*** 检查字段是否为空*/private boolean isEmpty(String field) {return field == null || field.trim().isEmpty();}/*** 验证评分是否为有效数值*/private boolean isValidRating(String rating) {return ratingPattern.matcher(rating).matches();}}/*** 电影数据清洗的Reducer类:* 合并清洗后的数据并按照要求格式输出*/public static class MovieCleanReducer extends Reducer<Text, Text, NullWritable, Text> {private Text result = new Text();@Overridepublic void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {// 对于每个电影ID,可能有多条记录,我们选择第一条完整的记录for (Text val : values) {result.set(val);context.write(NullWritable.get(), result);break; // 只取第一条记录,如果需要合并多个记录的数据,可以修改这里的逻辑}}}public static void main(String[] args) throws Exception {// 设置Hadoop用户Properties properties = System.getProperties();properties.setProperty("HADOOP_USER_NAME", "bduser");// 创建配置Configuration conf = new Configuration();conf.set("fs.defaultFS", "hdfs://10.40.2.147:9000");// 创建JobJob job = Job.getInstance(conf, "Movie Data Cleaner");job.setJarByClass(MovieDataCleaner.class);// 设置Mapper和Reducerjob.setMapperClass(MovieCleanMapper.class);job.setReducerClass(MovieCleanReducer.class);// 设置Map输出类型job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(Text.class);// 设置Reduce输出类型job.setOutputKeyClass(NullWritable.class);job.setOutputValueClass(Text.class);// 设置输入输出格式job.setInputFormatClass(TextInputFormat.class);job.setOutputFormatClass(TextOutputFormat.class);// 设置输入输出路径FileInputFormat.addInputPath(job, new Path("/hadoop2/movie/movie.csv"));FileOutputFormat.setOutputPath(job, new Path("/hadoop2/movie/clean_output"));// 提交JobSystem.exit(job.waitForCompletion(true) ? 0 : 1);}
}
运行任务:
网页上可以看到成功了
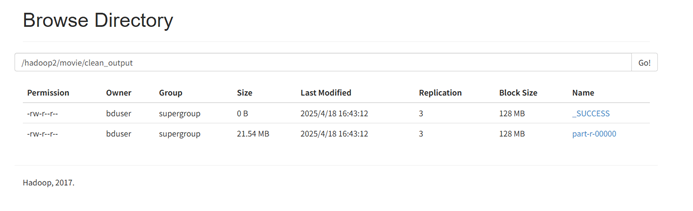
运行 hdfs dfs -cat /hadoop2/movie/clean_output/part-r-00000
2. 导演影响力分析
基于MapReduce清洗后的电影数据,使用Spark,从以下两个维度进行评估:
- 作品数量:统计每位导演执导的电影数量
- 作品质量:计算每位导演的平均电影评分
最终目标是找出:
- 最高产的导演(执导电影数量最多)
- 最受好评的导演(平均评分最高,且至少有5部作品)
运行命令:
PYSPARK_DRIVER_PYTHON=jupyter PYSPARK_DRIVER_PYTHON_OPTS="notebook" HADOOP_CONF_DIR=/opt/bigdata/hadoop/etc/hadoop pyspark --master yarn --deploy-mode client
打开网页
新增python文件 director_influence_analysis.ipynb,编写代码并运行。
代码如下 (director_influence_analysis.py):
from pyspark.sql import SparkSession
from pyspark.sql.functions import (col,count,avg,desc,split,explode,regexp_replace, # regexp_replace 仍然可能用于清理split后的单个导演名,但主要用于清理列表格式的逻辑会简化length,trim,
)# 创建Spark会话
spark = (SparkSession.builder.appName("Director Influence Analysis from MR").master("local[*]").getOrCreate()
)# 读取MapReduce作业的输出数据
# MapReduce输出格式:电影ID,电影名称,评分,类型,导演 (无表头)
df_mr = spark.read.csv("/hadoop2/movie/clean_output/part-r-00000", header=False, inferSchema=False
)# 数据清洗与准备
# MapReduce输出的列默认为 _c0, _c1, _c2, _c3, _c4
# _c0: 电影ID
# _c1: 电影名称
# _c2: 评分
# _c3: 类型 (此脚本中未使用,但列在那里)
# _c4: 导演 (逗号分隔的字符串)
cleaned_df = df_mr.select(col("_c0").alias("movie_id"),col("_c1").alias("title"),col("_c2").cast("float").alias("rating"),col("_c4").alias("directors_str"), # 导演字符串,例如 "Director A, Director B"
)# 过滤无效数据
cleaned_df = cleaned_df.filter(col("rating").isNotNull()& col("directors_str").isNotNull()& (col("directors_str") != "")
)# 处理导演字段:MapReduce输出的导演是逗号分隔的字符串
# 直接使用split和explode
cleaned_df = cleaned_df.withColumn("director_clean", explode(split(col("directors_str"), ","))
)# 清理单个导演名称(去除可能存在的前后空格)
cleaned_df = cleaned_df.withColumn("director_clean", trim(col("director_clean")))# 过滤掉包含"more credits"或"more credit"的条目和空白导演名
# 注意:MapReduce的清洗步骤可能已经处理了部分这类情况,但再次检查是好的实践
cleaned_df = cleaned_df.filter((~col("director_clean").rlike("(?i)more credit")) # 使用rlike进行不区分大小写的匹配& (length(col("director_clean")) > 0)
)# 按导演分组统计作品数量和平均评分
director_stats = (cleaned_df.groupBy("director_clean").agg(count("*").alias("movie_count"), avg("rating").alias("avg_rating")).orderBy(desc("movie_count"))
)# 显示结果
print("导演影响力分析 (来自MapReduce数据) - 按作品数量排序:")
director_stats.show(20, truncate=False)# 提高最小作品数量阈值,确保分析更有意义
influential_directors = director_stats.filter(col("movie_count") >= 5)# 按平均评分排序
print("导演影响力分析 (来自MapReduce数据) - 按平均评分排序(至少5部作品):")
influential_directors.orderBy(desc("avg_rating")).show(20, truncate=False)# 保存结果
# 注意:输出路径与原脚本不同,以区分是基于MapReduce结果的分析
director_stats.write.csv("/movie/output_from_mr/director_influence_stats", header=True, mode="overwrite"
)# 关闭Spark会话
spark.stop()
该Spark程序分析了从MapReduce作业清洗后的电影数据,旨在评估导演的影响力。主要通过两个维度进行分析:
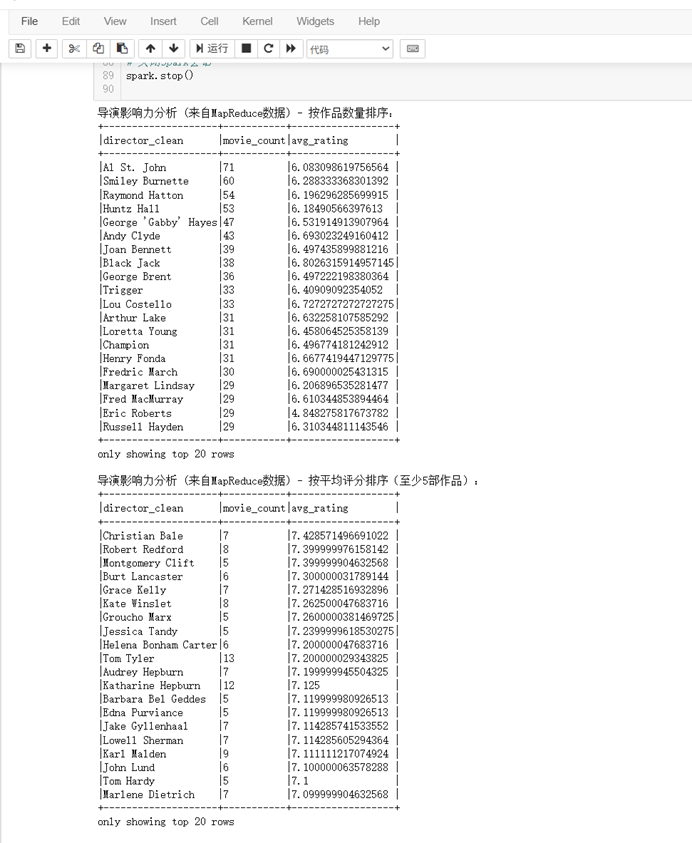
- 按作品数量排序的导演影响力分析:
director_clean: 清洗后的导演名称。movie_count: 该导演执导的电影作品数量。avg_rating: 该导演所有作品的平均用户评分。- 此部分列出了所有导演,并按照他们执导的电影数量从多到少进行排序。
- 例如,在结果中:
- Al St. John 执导了 71 部电影,其作品的平均评分为约 6.08。
- Smiley Burnette 执导了 60 部电影,其作品的平均评分为约 6.29。
- 这个列表可以帮助识别最多产的导演。
- 按平均评分排序的导演影响力分析(至少5部作品):
- 筛选条件:为了使评分更具代表性,此分析仅包含了那些至少执导了 5 部电影的导演。
director_clean: 清洗后的导演名称。movie_count: 该导演执导的电影作品数量(满足>=5的条件)。avg_rating: 该导演所有作品的平均用户评分。- 输出表格解读:
- 此部分列出了满足作品数量阈值的导演,并按照他们作品的平均评分从高到低进行排序。
- 例如,在结果中:
- Christian Bale 执导了 7 部电影,其作品的平均评分为约 7.43。
- Robert Redford 执导了 8 部电影,其作品的平均评分为约 7.40。
- 这个列表可以帮助识别那些作品平均质量较高的导演(在有一定作品量的基础上)。
该程序首先从MapReduce的输出(/hadoop2/movie/clean_output)加载数据,然后对导演字段进行处理(分割和清理)。接着,它计算每位导演的作品总数和平均评分。最后,它以两种不同的方式展示了这些统计数据:一种是按作品数量降序排列,另一种是筛选出作品数量不少于5部的导演后按平均评分降序排列。这些结果最终会保存到HDFS路径 /movie/output_from_mr/director_influence_stats。
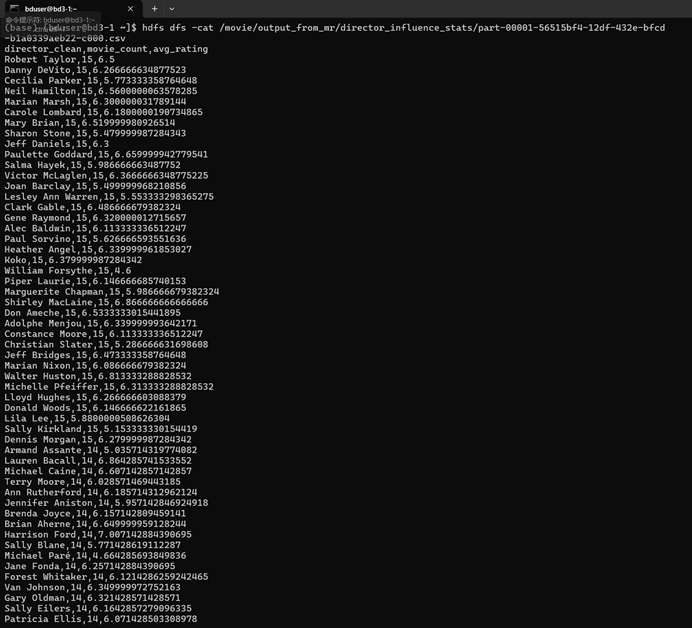
这是网页版的运行结果:
在终端查看运行结果:
3. 多维度可视化展示
使用Spark:生成票房与评分的关联分析图表
对MapReduce清洗后的电影数据进行可视化分析,通过生成专业的数据图表和交互式网页报告,帮助用户直观理解以下内容:
- 电影评分的整体分布情况
- 最高产的电影导演排名
- 评分最高的电影作品排名
- 通过网页形式展示所有可视化结果
visualization.py
import os
import shutil
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from pyspark.sql import SparkSession
import http.server
import socketserver
import threading
import webbrowser
import time
import platform# 根据平台设置适当的字体
system = platform.system()
if system == "Windows":plt.rcParams["font.sans-serif"] = ["SimHei"] # Windows黑体plt.rcParams["axes.unicode_minus"] = False
elif system == "Linux":# 在Linux上,确保安装了支持CJK字符的字体(如果需要)# 否则,使用一个适合英文显示的常见无衬线字体# 使用DejaVu Sans作为处理英文良好的常见默认字体plt.rcParams["font.sans-serif"] = ["DejaVu Sans"]plt.rcParams["axes.unicode_minus"] = False
elif system == "Darwin": # macOS# Arial Unicode MS是macOS上不错的选择(如果可用)# 否则,默认的macOS字体通常能很好地处理英文plt.rcParams["font.sans-serif"] = ["Arial Unicode MS"]plt.rcParams["axes.unicode_minus"] = Falsedef create_spark_session():"""创建并返回一个Spark会话"""return (SparkSession.builder.appName("Movie Data Visualization from MR").master("local[*]").getOrCreate())def load_data(spark):"""从MapReduce输出加载电影数据"""# 从MapReduce输出目录读取数据# MR输出格式:movie_id,title,rating,genre_str,directors_str(无表头)movie_df = spark.read.csv("/hadoop2/movie/clean_output", # Spark读取目录中的所有part文件header=False,inferSchema=False, # 显式定义模式或稍后进行类型转换)# 根据MR输出结构重命名列# _c0: movie_id, _c1: title, _c2: rating, _c3: genre_str , _c4: directors_strpandas_df = movie_df.select(movie_df["_c0"].alias("movie_id"),movie_df["_c1"].alias("title"),movie_df["_c2"].cast("float").alias("rating"),movie_df["_c3"].alias("genre_str_problematic"), # 保留原始问题字段以供参考,但不用于主流派图movie_df["_c4"].alias("directors_str"), # 这是导演字段).toPandas()# 评分数据清洗(虽然在Spark中已进行类型转换,但再次确保)pandas_df["rating"] = pd.to_numeric(pandas_df["rating"], errors="coerce")pandas_df.dropna(subset=["rating"], inplace=True) # 移除评分无法转换的行return pandas_dfdef create_rating_histogram(pandas_df, output_dir):"""创建电影评分分布直方图"""plt.figure(figsize=(12, 8))# 如有必要,将评分过滤到合理范围(如0-10)# 不过MapReduce应该已经清洗过数据# 对于这个图表,假设评分主要在0-10范围内ratings_to_plot = pandas_df["rating"].dropna()# 可选:过滤掉极端异常值(如果存在且扭曲图表)# ratings_to_plot = ratings_to_plot[(ratings_to_plot >= 0) & (ratings_to_plot <= 10)]if ratings_to_plot.empty:print("没有有效的评分数据用于绘制直方图。")return# 为0-10评分范围定义更合适的柱状图区间# 例如,20个区间表示每0.5评分一个区间,或10个区间表示每1.0评分一个区间# 或者让matplotlib根据数据决定,但指定范围min_rating = 0 # 如果不为空则使用ratings_to_plot.min(),否则使用0max_rating = 10 # 如果不为空则使用ratings_to_plot.max(),否则使用10# 确保min_rating不大于max_ratingif min_rating > max_rating:min_rating = 0max_rating = 10elif min_rating == max_rating and min_rating == 0: # 如果过滤后所有评分都是0max_rating = 1 # 确保有绘图范围elif min_rating == max_rating: # 如果所有评分都是相同的非零值min_rating = max_rating - 1 # 确保有范围# 如果所有评分都相同,hist可能只产生一个柱子# 我们希望展示分布,所以为典型的0-10电影评分范围# 使用合理数量的柱子num_bins = 20# 如果范围很小,减少柱子数量以避免空柱子if (max_rating - min_rating) < 5 and (max_rating - min_rating) > 0:num_bins = int((max_rating - min_rating) * 4) # 例如每0.25一个区间if num_bins < 5: # 确保至少有几个柱子num_bins = 5elif (max_rating - min_rating) == 0: # 所有评分都相同num_bins = 1 # 只有一个柱子才有意义plt.hist(ratings_to_plot,bins=num_bins, # 对0-10范围使用20个柱子,每0.5评分一个柱子range=(min_rating, max_rating), # 明确设置范围alpha=0.75,color="cornflowerblue",edgecolor="black",)plt.title("Distribution of Movie Ratings", fontsize=16)plt.xlabel("User Rating (0-10 Scale)", fontsize=12)plt.ylabel("Number of Movies", fontsize=12)plt.grid(True, linestyle="--", alpha=0.7)# 设置x轴刻度,使0-10范围的评分更易读plt.xticks(ticks=[i for i in range(int(min_rating), int(max_rating) + 1, 1)])plt.xlim(min_rating - 0.5, max_rating + 0.5) # 给x轴添加一些填充plt.savefig(os.path.join(output_dir, "rating_distribution.png"), dpi=300)plt.close()def create_top_directors_bar_chart(pandas_df, output_dir):"""创建顶级导演电影数量的水平条形图"""# MapReduce输出的导演已经是逗号分隔的字符串# 如果一个电影有多个导演,他们会在一个字符串中,例如 "Director A, Director B"# 我们需要分割这些字符串,然后计算每个独立导演的出现次数# 检查 'directors_str' 列是否存在且不为空if ("directors_str" not in pandas_df.columnsor pandas_df["directors_str"].dropna().empty):print("没有有效的导演数据用于绘制条形图。")returndirector_series = (pandas_df["directors_str"].dropna().apply(lambda x: [director.strip() for director in x.split(",") if director.strip()]))all_directors = []for sublist in director_series:all_directors.extend(sublist)# 过滤掉可能的空字符串或其他无效条目,例如 "[]" 或仅包含空格的条目all_directors_cleaned = [d for d in all_directors if d and d != "[]" and not d.isspace()]if not all_directors_cleaned:print("清洗后没有有效的导演数据用于绘制条形图。")returndirector_counts = pd.Series(all_directors_cleaned).value_counts()# 选择前N个导演以提高可读性top_n = 15top_directors = director_counts.head(top_n)if top_directors.empty:print("筛选后没有导演数据用于绘制条形图。")returnplt.figure(figsize=(12, 10))bars = plt.barh(top_directors.index,top_directors.values,color=sns.color_palette("viridis", len(top_directors)),edgecolor="black",)plt.title(f"Top {top_n} Directors by Movie Count", fontsize=16)plt.xlabel("Number of Movies", fontsize=12)plt.ylabel("Director", fontsize=12) # Y轴标签改为Directorplt.gca().invert_yaxis()for bar in bars:plt.text(bar.get_width() + 0.05 * bar.get_width(),bar.get_y() + bar.get_height() / 2,f"{int(bar.get_width())}",ha="left",va="center",fontsize=9,)plt.grid(True, linestyle="--", alpha=0.7, axis="x")plt.tight_layout()plt.savefig(os.path.join(output_dir, "top_directors_barchart.png"), dpi=300) # 更新文件名plt.close()def create_top_rated_movies(pandas_df, output_dir):"""创建评分最高的N部电影条形图"""top_n = 10# 过滤掉评分超过10分的电影(可能是异常值)filtered_df = pandas_df[pandas_df["rating"] <= 10]# 如果过滤后数据太少,输出警告信息if len(filtered_df) < top_n:print(f"警告:过滤评分后只剩下{len(filtered_df)}部电影,少于请求的{top_n}部。")if len(filtered_df) == 0:print("没有评分小于等于10分的电影,无法创建图表。")return# 选择评分最高的N部电影top_movies = filtered_df.nlargest(top_n, "rating")plt.figure(figsize=(12, 8))bars = plt.barh(top_movies["title"],top_movies["rating"],color="mediumseagreen",edgecolor="black",)plt.title(f"Top {top_n} Highest Rated Movies (Rating ≤ 10)", fontsize=16)plt.xlabel("User Rating", fontsize=12)plt.ylabel("Movie Title", fontsize=12)plt.gca().invert_yaxis() # 在顶部显示评分最高的电影plt.grid(True, linestyle="--", alpha=0.7, axis="x")for bar in bars:width = bar.get_width()plt.text(width + 0.05, # 从条形末端稍微偏移bar.get_y() + bar.get_height() / 2,f"{width:.2f}", # 显示评分,保留2位小数ha="left",va="center",fontsize=9,)plt.tight_layout() # 调整布局以防止标签重叠plt.savefig(os.path.join(output_dir, "top_rated_movies.png"), dpi=300)plt.close()def clear_directory(directory):"""清空指定目录中的所有文件和子目录"""if os.path.exists(directory):for item in os.listdir(directory):item_path = os.path.join(directory, item)if os.path.isfile(item_path):os.remove(item_path)elif os.path.isdir(item_path):shutil.rmtree(item_path)print(f"目录 {directory} 已清空")else:print(f"目录 {directory} 不存在,将创建该目录")def create_html_page(output_dir):"""创建一个HTML页面来显示所有图表"""# 定义要包含的图表及其英文标题和描述charts_info = [{"file": "rating_distribution.png","title": "Movie Rating Distribution","description": "This histogram shows the frequency distribution of movie ratings. It helps to understand the overall rating landscape, such as whether most movies are rated high, low, or cluster around an average.","purpose": "To visualize how ratings are spread across the dataset and identify common rating ranges.",},{"file": "top_directors_barchart.png", # 更新文件名"title": "Top Directors by Movie Count", # 更新标题"description": "This horizontal bar chart displays the counts of movies for the most frequent directors in the dataset. Longer bars indicate more movies directed by that person.", # 更新描述"purpose": "To identify the most prolific directors based on the number of movies they have directed in this dataset.", # 更新目的},{"file": "top_rated_movies.png","title": "Top 10 Highest Rated Movies","description": "This bar chart lists the top 10 movies with the highest user ratings. The length of the bar corresponds to the rating.","purpose": "To highlight critically acclaimed movies based on user scores and showcase top-performing titles.",},# 在此处添加更多图表(如果重新引入的话)]# 检查哪些图像文件实际存在available_charts_info = []for chart_info in charts_info:if os.path.exists(os.path.join(output_dir, chart_info["file"])):available_charts_info.append(chart_info)else:print(f"Warning: Chart file {chart_info['file']} not found. Skipping from HTML.")html_content = """<!DOCTYPE html><html lang="en"><head><meta charset="UTF-8"><meta name="viewport" content="width=device-width, initial-scale=1.0"><title>Movie Data Visualization Analysis</title><style>body { font-family: 'Segoe UI', Tahoma, Geneva, Verdana, sans-serif; margin: 0; padding: 20px; background-color: #eef1f5; color: #333; }.header { text-align: center; padding: 25px 20px; background-color: #2c3e50; color: white; margin-bottom: 30px; border-radius: 0 0 10px 10px; box-shadow: 0 4px 6px rgba(0,0,0,0.1); }.header h1 { margin: 0; font-size: 2.5em; font-weight: 300; }.container { display: flex; flex-direction: column; align-items: center; gap: 30px; }.chart-section { width: 85%; max-width: 1000px; margin: 0 auto; padding: 25px; background-color: white; box-shadow: 0 5px 15px rgba(0,0,0,0.08); border-radius: 10px; }.chart-title { font-size: 1.8em; margin-bottom: 15px; color: #2c3e50; border-bottom: 2px solid #3498db; padding-bottom: 10px; font-weight: 400;}.chart-img { width: 100%; height: auto; border-radius: 5px; margin-bottom:15px; }.chart-description p { margin: 5px 0; line-height: 1.6; font-size: 0.95em; }.chart-description strong { color: #3498db; }</style></head><body><div class="header"><h1>Movie Data Visualization Analysis (from MapReduce Output)</h1></div><div class="container">"""for chart_info in available_charts_info:html_content += f"""<div class="chart-section"><div class="chart-title">{chart_info['title']}</div><img class="chart-img" src="{chart_info['file']}" alt="{chart_info['title']}"><div class="chart-description"><p><strong>Meaning:</strong> {chart_info['description']}</p><p><strong>Purpose:</strong> {chart_info['purpose']}</p></div></div>"""html_content += """</div></body></html>"""html_path = os.path.join(output_dir, "index.html")with open(html_path, "w", encoding="utf-8") as f:f.write(html_content)print(f"HTML page created: {html_path}")return html_pathdef start_http_server(directory, port=32123):"""启动HTTP服务器以显示HTML页面"""# 切换到输出目录os.chdir(directory)# 创建HTTP服务器handler = http.server.SimpleHTTPRequestHandlerclass MyServer(socketserver.TCPServer):# 允许服务器重用地址,解决端口占用问题allow_reuse_address = Truetry:with MyServer(("", port), handler) as httpd:print(f"Starting HTTP server at: http://localhost:{port}")# 在单独的线程中运行服务器server_thread = threading.Thread(target=httpd.serve_forever)server_thread.daemon = (True # 设置为守护线程,这样主程序退出时,服务器也会停止)server_thread.start()# 尝试在浏览器中打开页面try:time.sleep(1) # 给服务器一点启动时间webbrowser.open(f"http://localhost:{port}")print("Visualization page opened in browser")except Exception as e:print(f"Cannot automatically open browser: {str(e)}")print(f"Please visit http://localhost:{port} manually")# 保持主线程运行,直到用户按下Ctrl+Cprint("Server is running... Press Ctrl+C to stop")while True:time.sleep(1)except KeyboardInterrupt:print("Server stopped")except Exception as e:print(f"Error starting server: {str(e)}")def main():"""运行所有可视化的主函数"""output_dir = "/home/bduser/visualizations_mr" # 为MR结果更改输出目录clear_directory(output_dir)os.makedirs(output_dir, exist_ok=True)print("Starting movie data visualization analysis from MapReduce output...")spark = create_spark_session()pandas_df = load_data(spark)print(f"Total {len(pandas_df)} movie records loaded from MapReduce output.")if pandas_df.empty:print("No data loaded. Exiting visualization.")spark.stop()returntry:print("Generating Rating Distribution Histogram...")create_rating_histogram(pandas_df, output_dir)print("Generating Top Directors Bar Chart...") # 更新打印信息create_top_directors_bar_chart(pandas_df, output_dir) # 调用新函数print("Generating Top Rated Movies Bar Chart...")create_top_rated_movies(pandas_df, output_dir)print(f"All visualization charts saved to {output_dir}")html_path = create_html_page(output_dir)start_http_server(output_dir, 32123)except Exception as e:print(f"Error during visualization generation: {str(e)}")import tracebacktraceback.print_exc()finally:# 关闭Spark会话spark.stop()print("Spark session closed")if __name__ == "__main__":main()
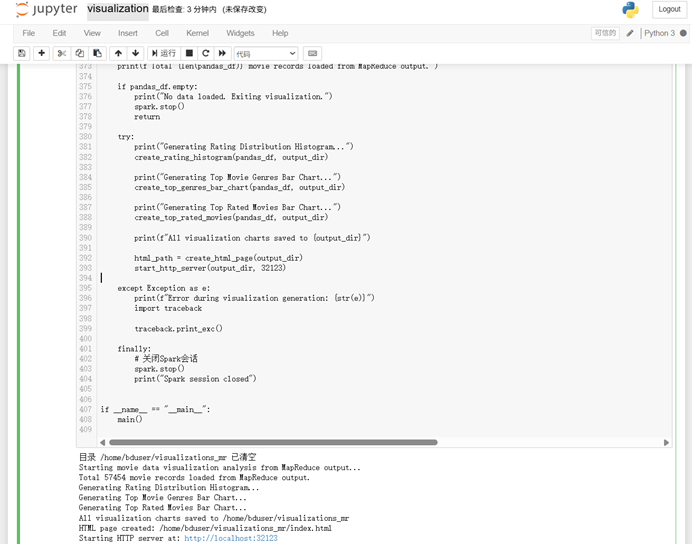
使用很少被使用的32123端口
运行成功:
打开 http://10.40.2.147:32123/
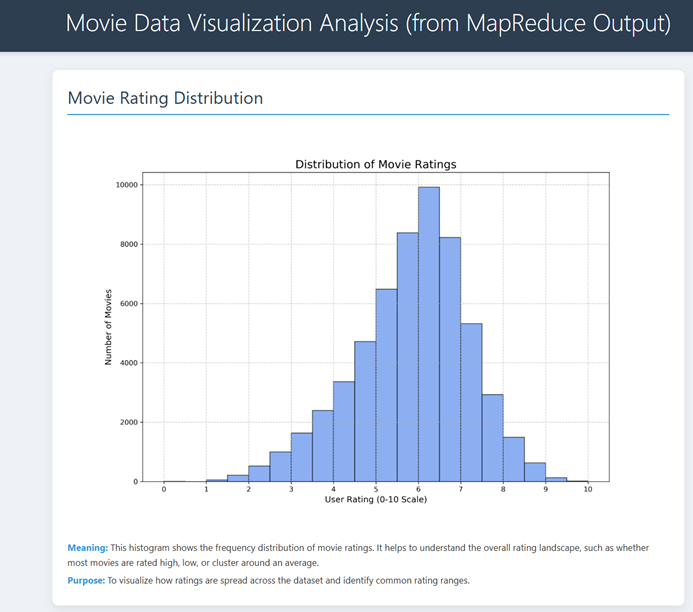
电影评分分布 (Movie Rating Distribution)
- 图表类型:直方图
- 标题:Distribution of Movie Ratings(电影评分分布)
- 横轴:User Rating (0-10 Scale)(用户评分,0-10分制)
- 纵轴:Number of Movies(电影数量)
图中内容:
这张直方图展示了数据集中所有电影评分的频率分布。从图中我们可以观察到评分主要集中在4-8分之间,呈近似正态分布,峰值出现在6分附近(约10000部电影)。5分和7分的电影数量紧随其后(各约8000部)。低于3分和高于9分的电影相对较少,表明极端评分不太常见。
图像意义:
这张图使我们能够一目了然地了解整个数据库中电影评分的整体分布情况。它告诉我们大多数电影获得中等偏上的评分,数据整体呈钟形分布,这符合人们对电影质量评价的一般认知。通过这个分布,我们可以确定数据集中"优质"或"劣质"电影的评分阈值,为后续分析提供基础。
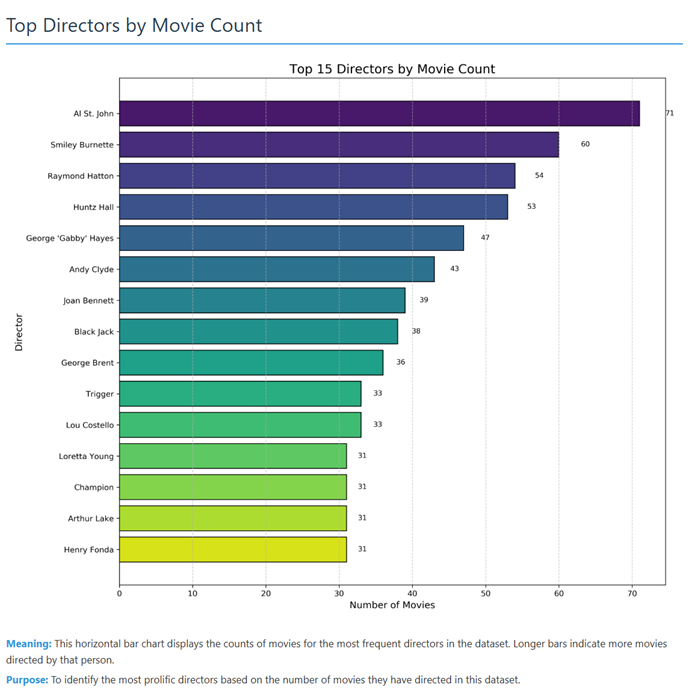
按电影数量排名的顶级导演 (Top Directors by Movie Count)
- 图表类型:水平条形图
- 图表内部标题:Top 15 Directors by Movie Count (按电影数量排名的前15位导演)
- 横轴 (X轴):Number of Movies (电影数量)
- 此轴显示了每位导演执导的电影数量,范围从0到大约70多部。
- 纵轴 (Y轴):Director (导演)
- 此轴列出了数据集中执导电影数量最多的15位导演的姓名。条目按执导电影数量降序排列。
图中反映的结果:
这张图表清晰地展示了数据集中最多产的15位导演及其各自执导的电影数量。
Al St. John 以71部电影高居榜首,是名单中最多产的导演。
Smiley Burnette 以60部电影位列第二。
Raymond Hatton 以54部电影排在第三。
其后是 Huntz Hall (53部), George ‘Gabby’ Hayes (47部), Andy Clyde (43部), Joan Bennett (39部), Black Jack (38部), George Brent (36部)。
接下来有几位导演的电影数量较为接近:Trigger 和 Lou Costello 均为33部。
最后是 Loretta Young, Champion, Arthur Lake, 和 Henry Fonda,他们都执导了31部电影。
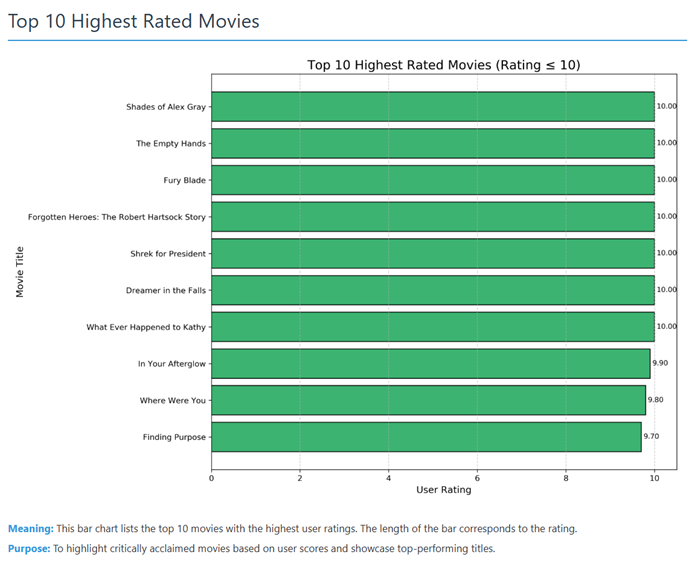
评分最高的十部电影 (Top 10 Highest Rated Movies)
- 图表类型:水平条形图
- 标题:Top 10 Highest Rated Movies (Rating ≤ 10)(评分最高的十部电影,评分≤10)
- 横轴:User Rating(用户评分,0-10分)
- 纵轴:Movie Title(电影标题)
图中内容:
这张水平条形图展示了数据集中评分最高的10部电影。从图中可以清晰地看到,有7部电影获得了满分10分,它们是:
- Shades of Alex Gray
- The Empty Hands
- Fury Blade
- Forgotten Heroes: The Robert Hartsock Story
- Shrek for President
- Dreamer in the Falls
- What Ever Happened to Kathy
其余3部电影评分略低:
- In Your Afterglow(9.9分)
- Where Were You(9.8分)
- Finding Purpose(9.7分)
这些电影的评分都非常接近满分,显示出它们在观众中获得了极高的评价。
图像意义:
这张图直观地展示了数据集中最受好评的电影作品。通过设置评分上限为10分,成功过滤掉了之前分析中发现的异常高评分(如2000多分)数据,使结果更加符合常规评分标准。这些高评分电影代表了观众认为的最优质内容,可以用于推荐系统或进一步分析这些电影的共同特点(如导演、类型、年代等)。从商业角度看,了解这些高评分电影的特征可以帮助电影制作人把握观众喜好。