Python训练营打卡——DAY22(2025.5.11)
复习日
学习参考如何使用kaggle平台,写下使用注意点,并对下述比赛提交代码
泰坦尼克号——来自灾难的机器学习
数据来源:
kaggle泰坦里克号人员生还预测
挑战
泰坦尼克号沉没是历史上最臭名昭著的海难之一。
1912年4月15日,在被普遍认为“永不沉没”的皇家邮轮泰坦尼克号的处女航中,它与冰山相撞沉没。不幸的是,船上没有足够的救生艇供所有人使用,导致2224名乘客和船员中1502人遇难。
虽然生存需要一些运气的因素,但似乎有些群体比其他群体更有可能生存下来。
在这个挑战中,我们要求您使用乘客数据(即姓名、年龄、性别、社会经济阶层等)建立一个预测模型来回答这个问题:“什么样的人更有可能生存?”
Kaggle 竞赛如何运作
- 参加比赛
阅读挑战描述,接受比赛规则并获得比赛数据集的访问权限。 - 开始工作
下载数据,在本地或 Kaggle Notebooks(我们的无需设置、可定制的 Jupyter Notebooks 环境,带有免费 GPU)上构建模型并生成预测文件。 - 提交
您的预测并将其作为提交上传到 Kaggle 并获得准确度分数。 - 查看排行榜
查看您的模型在我们的排行榜上与其他 Kaggler 的排名。 - 提高您的分数
查看讨论论坛,查找来自其他竞争对手的大量教程和见解。
我将在本次比赛中使用哪些数据?
在本次比赛中,您将获得两个相似的数据集,其中包括乘客信息,如姓名、年龄、性别、社会经济阶层等。一个数据集的标题为train.csv,另一个数据集的标题为test.csv。
Train.csv将包含机上部分乘客(确切地说是 891 人)的详细信息,重要的是,将揭示他们是否幸存,也称为“地面真相”。
数据test.csv集包含类似的信息,但并未披露每位乘客的“基本事实”。你的任务就是预测这些结果。
使用您在数据中发现的模式train.csv,预测机上其他 418 名乘客(在 中找到test.csv)是否幸存。
查看“数据”选项卡,进一步探索数据集。一旦你认为自己创建了一个具有竞争力的模型,就可以将其提交到 Kaggle,看看你的模型在我们的排行榜上与其他 Kaggle 选手的排名。
如何向 Kaggle 提交你的预测
一旦您准备好提交并进入排行榜:
- 点击“提交预测”按钮
- 上传提交文件格式的 CSV 文件。您每天最多可以提交 10 份。
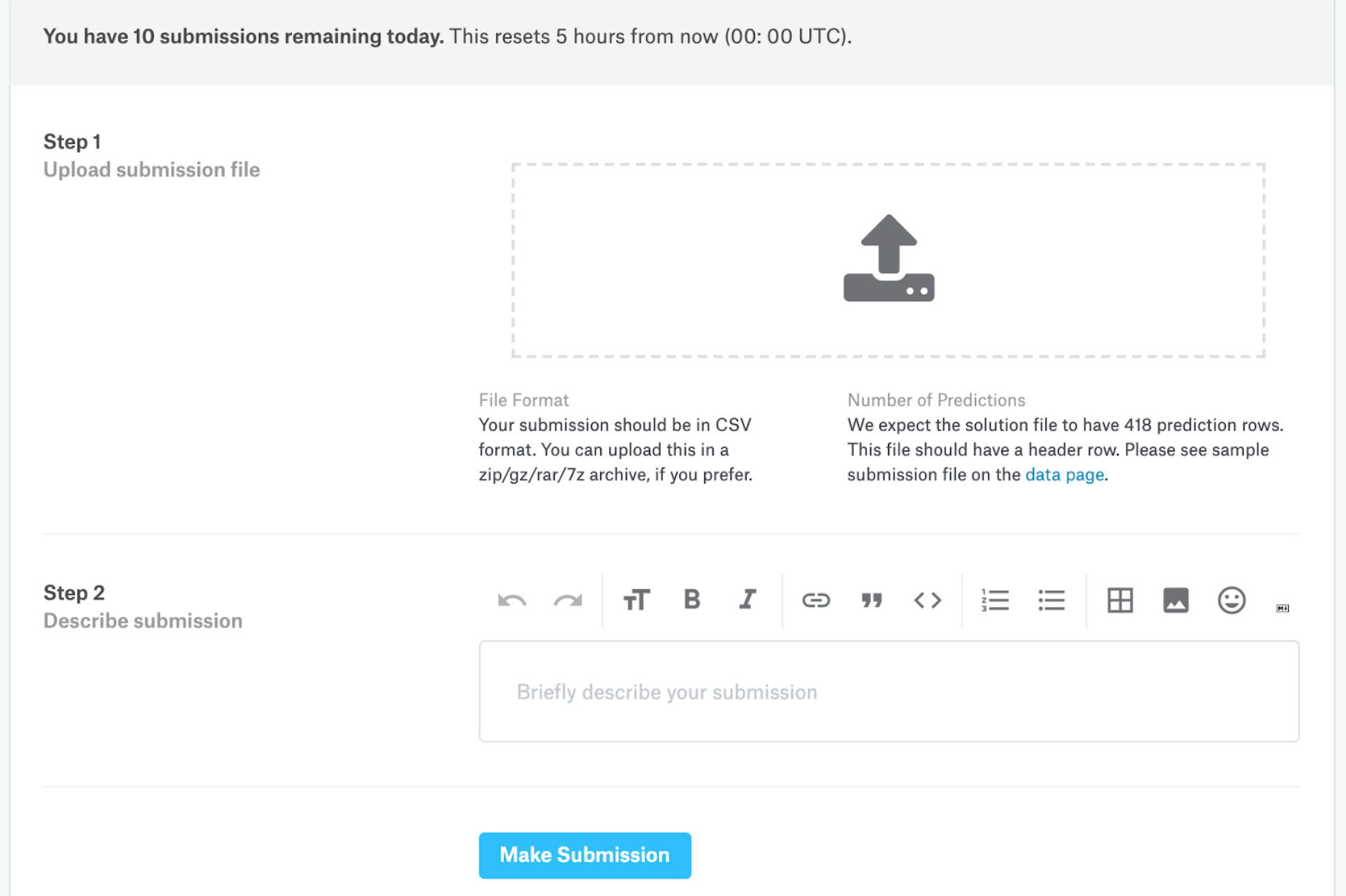
提交文件格式:
PassengerId您应该提交一个包含 418 个条目和一个标题行的 csv 文件。如果您提交的数据包含多余的列(超过和Survived)或行,则会显示错误。
该文件应该恰好有 2 列:
PassengerId(不分先后顺序)Survived(包含您的二进制预测:1 表示幸存,0 表示死亡)
1. 导入包
import warnings
warnings.filterwarnings("ignore") #忽略警告信息# 数据处理清洗包
import pandas as pd
import numpy as np
import random as rnd# 可视化包
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline# 机器学习算法相关包
from sklearn.linear_model import LogisticRegression, Perceptron, SGDClassifier
#逻辑回归、感知机、随机梯度下降法
from sklearn.svm import SVC, LinearSVC
#支持向量机、线性支持向量机
from sklearn.neighbors import KNeighborsClassifier
#最近邻
from sklearn.naive_bayes import GaussianNB
#朴素贝叶斯
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier2. 加载数据集
train_df = pd.read_csv('./titanic/train.csv')
test_df = pd.read_csv('./titanic/test.csv')
combine = [train_df, test_df] # 合并数据
#这只是放到一个列表,以便后续合并,现在还没合并
#combined_df = pd.concat([train_df, test_df], axis=1, ignore_index=True)这才是合并
#combine.head()会报错,因为列表没有head方法3. 描述性统计分析
# 获取所有特征名
print(train_df.columns.values)# 预览数据
train_df.head()train_df.tail()print(train_df.isnull().sum())
# 返回每列(特征)中的缺失值数量
print('_'*40)
#打印一行分隔线,其中包含40个连续的下划线字符
test_df.isnull().sum()train_df.info()
print('_'*40)
test_df.info()
#714 non-null意为714个非空值
# RangeIndex: 891 entries, 0 to 890 表示891行数据
# Data columns (total 12 columns) 表示12列(11个特征 1个标签)round(train_df.describe(percentiles=[.5, .6, .7, .75, .8, .9, .99]),2)
#describe(percentiles=[.5, .6, .7, .75, .8, .9, .99])指定百分位描述
#round()保留2位小数
#describe()方法只描述数值型数据,12个特征中有5个object所以不表示train_df.describe(include=['O'])
# 获取非数值型(对象型)列的描述性统计信息的方法
# count:非缺失值的数量。
# unique:唯一值的数量,表示多少种数值
# top:出现次数最多的值。
# freq:出现次数最多的值的频数。4. 基于数据分析的假设
# 针对Pclass和Survived进行分类汇总
# pclass是票价等级
train_df[['Pclass','Survived']].groupby(['Pclass'], as_index=False).mean().sort_values(by='Survived', ascending=False)
# groupby是分类汇总函数,这个功能类似于数据透视表,选择分类列和汇总列
# sort_values(by='Survived', ascending=False)意思为根据survive这一列降序排序
# 另一种写法为pd.DataFrame(train_df.groupby('Pclass', as_index=False)['Survived'].mean()).sort_values(by='Survived', ascending=False)train_df[['Sex','Survived']].groupby(['Sex'], as_index=False).mean().sort_values(by='Survived', ascending=False)train_df[['SibSp','Survived']].groupby(['SibSp'], as_index=False).mean().sort_values(by='Survived',ascending=False)train_df[['Parch','Survived']].groupby(['Parch'], as_index=False).mean().sort_values(by='Survived',ascending=False)5. 可视化数据分析
g = sns.FacetGrid(train_df, col='Survived') #FacetGrid(data, row, col, hue, height, aspect, palette, ...)
# col='Survived'指定了将数据分成两列,分别对应于Survived列的0和1g.map(plt.hist, 'Age', bins=20)
# plt.hist来绘制直方图,并传递了'Age'列作为数据,,bins=20指定了直方图的分箱数#grid = sns.FacetGrid(train_df, col='Survived', row='Pclass', size=2.5, aspect=1.6)
grid = sns.FacetGrid(train_df, col='Pclass', hue='Survived')
grid.map(plt.hist, 'Age', alpha=0.5, bins=20)
grid.add_legend();grid = sns.FacetGrid(train_df, col='Embarked')
grid.map(sns.pointplot, 'Pclass', 'Survived', 'Sex', palette='deep')
grid.add_legend();grid = sns.FacetGrid(train_df, col='Embarked', hue='Survived', palette={0: 'b', 1: 'r'})
grid.map(sns.barplot, 'Sex', 'Fare', alpha=.5, ci=None)
grid.add_legend()1
print("Before", train_df.shape, test_df.shape, combine[0].shape, combine[1].shape)train_df = train_df.drop(['Ticket', 'Cabin'], axis=1)
test_df = test_df.drop(['Ticket', 'Cabin'], axis=1)
combine = [train_df, test_df]"After", train_df.shape, test_df.shape, combine[0].shape, combine[1].shapetrain_df['Name'].head(10)# 使用正则表达式提取Title特征
for dataset in combine:dataset['Title'] = dataset.Name.str.extract('([A-Za-z]+)\.', expand=False)
# 从姓名字符串中匹配一个或多个字母,并且以句点 (.) 结尾的部分,这通常是表示称号的部分
# 提取的称号被存储在一个新的 Title 列中
pd.crosstab(train_df['Title'], train_df['Sex']).sort_values(by='female', ascending=False) # pd.crosstab列联表
#这部分代码使用 pd.crosstab 来创建一个列联表,用于计算不同称号 和性别之间的关系
#crosstab 会统计每个组合的数量,并返回一个交叉表。combine
#还没有按列合并,还是2个数据表# 可以用更常见的名称替换许多标题或将它们归类为稀有
for dataset in combine:dataset['Title'] = dataset['Title'].replace(['Lady', 'Countess','Capt', 'Col','Don', 'Dr', 'Major', 'Rev', 'Sir', 'Jonkheer', 'Dona'], 'Rare')dataset['Title'] = dataset['Title'].replace(['Mlle', 'Ms'], 'Miss')dataset['Title'] = dataset['Title'].replace('Mme', 'Mrs')train_df[['Title', 'Survived']].groupby(['Title'], as_index=False).mean()train_df.head()# 将分类标题转换为序数
title_mapping = {"Mr": 1, "Miss": 2, "Mrs": 3, "Master": 4, "Rare": 5}
for dataset in combine:dataset['Title'] = dataset['Title'].map(title_mapping) # 将序列中的每一个元素,输入函数,最后将映射后的每个值返回合并,得到一个迭代器dataset['Title'] = dataset['Title'].fillna(0) train_df.head()# 现在可以从训练和测试数据集中删除Name特征以及训练集中的PassengerId 特征
train_df = train_df.drop(['Name', 'PassengerId'], axis=1)
test_df = test_df.drop(['Name'], axis=1)
combine = [train_df, test_df]
train_df.shape, test_df.shape# 转换分类特征Sex
for dataset in combine:dataset['Sex'] = dataset['Sex'].map( {'female': 1, 'male': 0} ).astype(int) #男性赋值为0,女性赋值为1,并转换为整型数据train_df.head()# 绘制Age, Pclass, Sex复合直方图
#grid = sns.FacetGrid(train_df, row='Pclass', col='Sex', size=2.2, aspect=1.6)
grid = sns.FacetGrid(train_df, col='Pclass', hue='Sex')
grid.map(plt.hist, 'Age', alpha=.5, bins=20)
grid.add_legend()# 创建空数组
guess_ages = np.zeros((2,3))
guess_ages# 遍历 Sex (0 或 1) 和 Pclass (1, 2, 3) 来计算六种组合的 Age 猜测值
for dataset in combine:# 第一个for循环计算每一个分组的Age预测值for i in range(0, 2):for j in range(0, 3):guess_df = dataset[(dataset['Sex'] == i) & \(dataset['Pclass'] == j+1)]['Age'].dropna()# age_mean = guess_df.mean()# age_std = guess_df.std()# age_guess = rnd.uniform(age_mean - age_std, age_mean + age_std)age_guess = guess_df.median()# 将随机年龄浮点数转换为最接近的 0.5 年龄(四舍五入)guess_ages[i,j] = int( age_guess/0.5 + 0.5 ) * 0.5# 第二个for循环对空值进行赋值 for i in range(0, 2):for j in range(0, 3):dataset.loc[ (dataset.Age.isnull()) & (dataset.Sex == i) & (dataset.Pclass == j+1),\'Age'] = guess_ages[i,j]dataset['Age'] = dataset['Age'].astype(int)
train_df.head()# 创建了一个新的列:年龄段AgeBand,并确定其与Survived的相关性
# 一般在建立分类模型时,需要对连续变量离散化,特征离散化后,模型会更稳定,降低了模型过拟合的风险
train_df['AgeBand'] = pd.cut(train_df['Age'], 5) # 将年龄分割为5段,等距分箱
train_df[['AgeBand', 'Survived']].groupby(['AgeBand'], as_index=False).mean().sort_values(by='AgeBand', ascending=True)# 将这些年龄区间替换为序数
for dataset in combine: dataset.loc[ dataset['Age'] <= 16, 'Age'] = 0dataset.loc[(dataset['Age'] > 16) & (dataset['Age'] <= 32), 'Age'] = 1dataset.loc[(dataset['Age'] > 32) & (dataset['Age'] <= 48), 'Age'] = 2dataset.loc[(dataset['Age'] > 48) & (dataset['Age'] <= 64), 'Age'] = 3dataset.loc[ dataset['Age'] > 64, 'Age'] = 4
train_df.head()train_df = train_df.drop(['AgeBand'], axis=1) # 删除训练集中的AgeBand特征
combine = [train_df, test_df]
train_df.head()
test_dffor dataset in combine:dataset['FamilySize'] = dataset['SibSp'] + dataset['Parch'] + 1train_df[['FamilySize', 'Survived']].groupby(['FamilySize'], as_index=False).mean().sort_values(by='Survived', ascending=False)# 创建新特征IsAlone
for dataset in combine:dataset['IsAlone'] = 0dataset.loc[dataset['FamilySize'] == 1, 'IsAlone'] = 1train_df[['IsAlone', 'Survived']].groupby(['IsAlone'], as_index=False).mean()train_df = train_df.drop(['Parch', 'SibSp', 'FamilySize'], axis=1)
test_df = test_df.drop(['Parch', 'SibSp', 'FamilySize'], axis=1)
combine = [train_df, test_df]train_df.head(20)# 创建Age*Pclass特征以此用来结合Age和Pclass变量
for dataset in combine:dataset['Age*Pclass'] = dataset.Age * dataset.Pclasstrain_df.loc[:, ['Age*Pclass', 'Age', 'Pclass']].head(10)
train_df[['Age*Pclass', 'Survived']].groupby(['Age*Pclass'], as_index=False).mean()freq_port = train_df.Embarked.dropna().mode()[0]
# mode() 计算众数,这里只有一个值,加不加[0] 都一样,一般返回的众数是每一列的众数构成的series
for dataset in combine:dataset['Embarked'] = dataset['Embarked'].fillna(freq_port)train_df[['Embarked', 'Survived']].groupby(['Embarked'], as_index=False).mean().sort_values(by='Survived', ascending=False)# 同样转换分类特征为序数
for dataset in combine:dataset['Embarked'] = dataset['Embarked'].map( {'S': 0, 'C': 1, 'Q': 2} ).astype(int)train_df.head()# 测试集中Fare有一个缺失值,用中位数进行填补
test_df['Fare'].fillna(test_df['Fare'].dropna().median(), inplace=True)
test_df.head()plt.hist(train_df['Fare'])# 对票价进行连续数据离散化
train_df['FareBand'] = pd.qcut(train_df['Fare'], 4) # 根据样本分位数进行分箱,等频分箱
train_df[['FareBand', 'Survived']].groupby(['FareBand'], as_index=False).mean().sort_values(by='FareBand', ascending=True)for dataset in combine:dataset.loc[ dataset['Fare'] <= 7.91, 'Fare'] = 0dataset.loc[(dataset['Fare'] > 7.91) & (dataset['Fare'] <= 14.454), 'Fare'] = 1dataset.loc[(dataset['Fare'] > 14.454) & (dataset['Fare'] <= 31), 'Fare'] = 2dataset.loc[ dataset['Fare'] > 31, 'Fare'] = 3dataset['Fare'] = dataset['Fare'].astype(int)train_df = train_df.drop(['FareBand'], axis=1)
combine = [train_df, test_df]train_df.head(10)test_df.head(10)