redis存储结构
一、存储结构
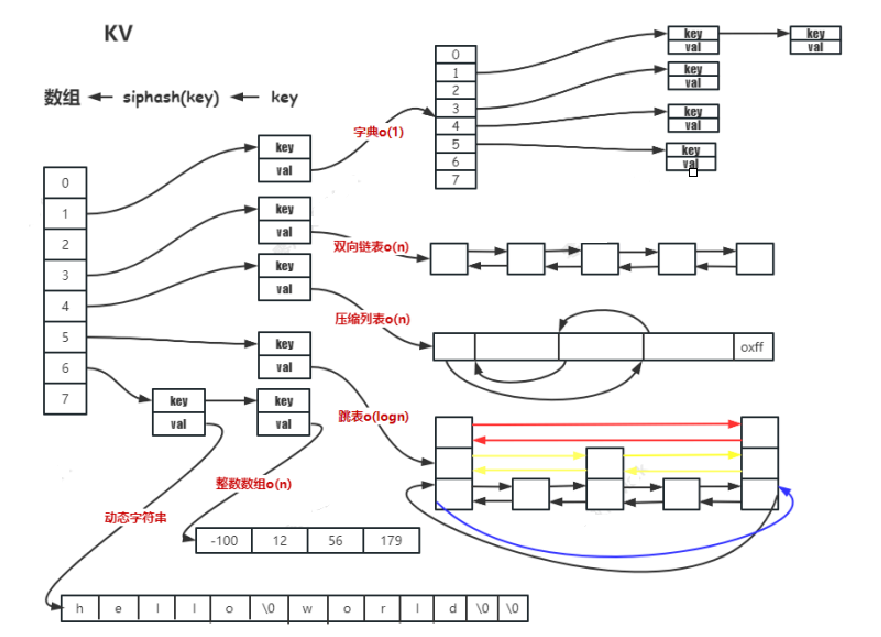
存储转换:
string
- int:字符串长度 ≤ 20 且能转成整数
- raw:字符串长度 > 44
- embstr:字符串长度 ≤ 44
- 附加:CPU 缓存中基本单位为 cacheline 64 字节
list
- quicklist(双向链表)
- ziplist(压缩列表):间接使用
hash
- dict(字典):节点数量 > 512 或字符串长度 > 64
- ziplist(压缩列表):节点数量 ≤ 512(
hash - max - ziplist - entries)且字符串长度 ≤ 64(hash - max - ziplist - value)set
- intset(整数数组):元素都为整数且节点数量 ≤ 512(
set - max - intset - entries)- dict(字典):元素有一个不为整数或数量 > 512
zset
- skiplist(跳表):数量 > 128 或者有一个字符串长度 > 64
- ziplist(压缩列表):子节点数量 ≤ 128(
zset - max - ziplist - entries)且字符串长度 ≤ 64(zset - max - ziplist - value)
二、字典实现
redis 中 KV 组织是通过字典来实现的;hash 结构当节点超过 512 个或者单个字符串长度大于 64 时,hash 结构采用字典实现;
typedef struct dictEntry {void *key;union {void *val;uint64_t u64;int64_t s64;double d;} v;struct dictEntry *next;
} dictEntry;typedef struct dictht {dictEntry **table;unsigned long size;// 数组长度unsigned long sizemask; //size-1unsigned long used;//当前数组当中包含的元素
} dictht;typedef struct dict {dictType *type;void *privdata;dictht ht[2];long rehashidx; /* rehashing not in progress if rehashidx == -1 */int16_t pauserehash; /* If >0 rehashing is paused (<0 indicates coding error)用于安全遍历*/
} dict;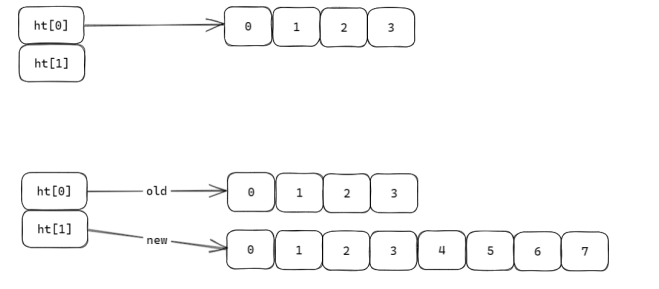
三、冲突
负载因子
负载因子 = used / size ; used 是数组存储元素的个数, size 是数组的长度;
扩容
缩容
四、渐进式rehash
一、什么是渐进式 Rehash?
1. 背景:哈希表扩容的性能问题
Redis 中的哈希表(Hashtable)使用两个底层数组
ht[0]和ht[1],正常情况下数据存储在ht[0]中。当ht[0]中的元素数量过多(达到扩容阈值,如负载因子超过 1),直接一次性将所有元素迁移到更大的ht[1]会带来两个问题:
- 阻塞主线程:迁移大量数据需要大量计算,可能导致 Redis 长时间无法处理其他命令(如读写请求),影响响应速度。
- 内存峰值:一次性创建新表并迁移数据,可能导致短期内内存占用激增。
为解决上述问题,Redis 采用 渐进式 Rehash,将数据迁移拆分成多个小步骤,逐步完成,避免阻塞。
2. 渐进式 Rehash 的核心步骤
初始化
ht[1]:
首先根据扩容规则(如扩容为ht[0]大小的 2 倍)创建ht[1],并记录当前迁移的进度(如当前处理到ht[0]的哪个槽位)。分批次迁移数据:
每次处理客户端的增、删、改、查操作时,除了执行正常命令外,额外迁移ht[0]中 少量槽位(如 100 个) 的数据到ht[1]。
迁移时,对每个槽位中的元素重新计算哈希值(生成 64 位整数),并根据ht[1]的长度取余,映射到新表的槽位中。定时器辅助迁移:
Redis 内部定时器会定期触发 Rehash 任务,每次最多执行 1 毫秒,确保即使没有客户端操作,迁移也能持续进行,避免无限拖延。双表共存阶段:
在迁移过程中,ht[0]和ht[1]同时存在:
- 读操作:同时查询
ht[0]和ht[1](先查ht[1],若不存在再查ht[0])。- 写操作:直接写入
ht[1],并标记ht[0]对应元素为已迁移,避免重复迁移。3. 渐进式 Rehash 的优势
- 无阻塞:将迁移压力分散到多次操作中,避免单次耗时过长,保证 Redis 的响应能力。
- 平滑过渡:客户端几乎感知不到迁移过程,业务无中断。
- 内存可控:分批次迁移,避免内存突然飙升。
二、为什么渐进式 Rehash 时不会发生扩容或缩容?
1. 扩缩容的触发条件
Redis 的扩缩容(扩容或缩容)触发时机是:
- 扩容:当
ht[0]的负载因子(元素数 / 数组大小)超过阈值(如 1,或哈希冲突严重时)。- 缩容:当
ht[0]的负载因子过低(如低于 0.1),为节省内存而缩小数组大小。2. 渐进式 Rehash 期间的状态
在渐进式 Rehash 过程中:
- 双表共存:
ht[0]正在迁移数据到ht[1],此时系统的哈希表状态是 “正在迁移”,而非正常的单表状态。- 迁移优先级更高:Redis 规定,必须先完成当前的 Rehash 任务,才能进行下一次扩缩容。
例如:若在迁移过程中,ht[1]的元素数又达到了扩容条件,系统不会立即触发新的扩容,而是等当前ht[0]数据全部迁移到ht[1]后,将ht[1]设为ht[0],再重新评估是否需要扩缩容。3. 避免操作冲突
若在 Rehash 期间允许扩缩容,会导致以下问题:
- 数据不一致:同时操作两个表的迁移和扩缩容,可能引发哈希表结构混乱。
- 逻辑复杂度激增:需要处理多表之间的多层迁移,增加实现难度和 bug 风险。
因此,Redis 设计为:渐进式 Rehash 是一个 “独占” 过程,期间不会触发任何新的扩缩容操作,确保每次仅处理单一的哈希表调整任务,保证稳定性和正确性。
五、scan
scan cursor [MATCH pattern] [COUNT count] [TYPE type]
Redis 的
SCAN命令是一种渐进式遍历键的机制,用于替代KEYS命令(KEYS会阻塞服务器,不适用于生产环境)。它通过游标逐步遍历数据库中的键,不会对服务器性能造成长时间阻塞。以下是其原理和示例:
一、SCAN 机制原理
游标(Cursor)
SCAN使用一个游标cursor来记录遍历的位置。每次调用SCAN,都会返回一个新的游标,用于下一次遍历。当游标为0时,表示遍历结束。哈希表槽位遍历
Redis 的数据库是一个哈希表,SCAN通过遍历哈希表的槽位(slot)来查找键。它采用 高位进位加法 的顺序遍历槽位,这种算法确保在哈希表rehash(扩容或缩容)后,槽位的遍历顺序仍然相邻,从而尽量保证对SCAN开始时已存在的数据 不重复、不遗漏(特殊情况除外,如两次缩容可能导致重复)。参数控制
MATCH pattern:用于筛选符合特定模式的键(如user:*表示以user:开头的键)。COUNT count:提示 Redis 每次遍历的大致数量,但实际返回的键数量可能因哈希表结构而有所不同。数据变更处理
SCAN仅保证对SCAN开始时已存在的数据进行遍历,不保证遍历过程中新增的键会被扫描到。- 扩容或缩容会改变键的映射,但高位进位加法算法能确保对
SCAN开始时已存在的数据的遍历正确性。
二、具体示例
假设 Redis 中有以下键:
user:1、user:2、order:1、order:2、cache:1。示例 1:基本 SCAN 遍历
第一次调用:
SCAN 010和部分键(如["user:1", "order:1"]),表示游标移动到10。第二次调用:
SCAN 10假设返回
0和剩余键(如["user:2", "order:2", "cache:1"]),表示遍历结束(游标回到0)。示例 2:带模式匹配的 SCAN
查找所有以
user:开头的键:SCAN 0 MATCH "user:*"假设返回
10和["user:1", "user:2"],继续用新游标10遍历,直到游标为0。示例 3:带 COUNT 提示的 SCAN
提示每次遍历约
3个键:SCAN 0 COUNT 3Redis 会尽量返回接近
3个键,但实际数量可能因哈希表结构而变化。
三、注意事项
- 不保证顺序:
SCAN返回的键顺序是不确定的,因为它基于哈希表槽位的遍历。- 数据变更影响:若在
SCAN过程中大量新增或删除键,新增键可能不会被遍历,删除键若已被扫描则会被返回(但实际已不存在,需业务层过滤)。- 缩容重复问题:理论上,若在
SCAN过程中发生两次缩容,可能出现重复键(但这种情况极少,属于特殊场景)。
假设场景
- 初始哈希表
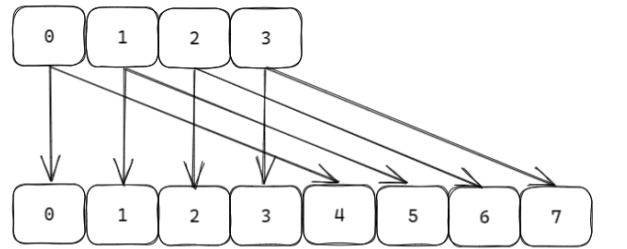
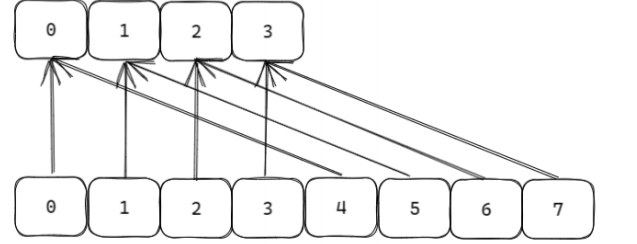
ht[0]有4个槽(编号0~3,二进制表示为2位:00, 01, 10, 11)。- 触发扩容后,新表
ht[1]有8个槽(编号0~7,二进制表示为3位)。- 假设
ht[0]的槽0有键A,槽2有键B。扩容后,槽0对应ht[1]的槽0和4(高位为0和1),槽2对应ht[1]的槽2和6(高位为0和1)。高位进位加法的遍历逻辑
ht[0]阶段(4 个槽,2 位二进制)
遍历顺序按高位进位加法:
0(00) →2(10) →1(01) →3(11)。
此时能覆盖ht[0]所有槽。扩容到
ht[1](8 个槽,3 位二进制)
高位进位加法的遍历顺序为:
0(000) →4(100) →2(010) →6(110) →1(001) →5(101) →3(011) →7(111)。
- 原
ht[0]槽0对应ht[1]的0和4,在遍历顺序中是连续的(0 → 4)。- 原
ht[0]槽2对应ht[1]的2和6,在遍历顺序中也是连续的(2 → 6)。这样,
ht[0]中每个槽的数据在ht[1]中对应的新槽会被连续遍历,确保SCAN开始时已存在的键(如A和B)不会遗漏。
六、expire机制
# 只支持对最外层key过期;
expire key seconds
pexpire key milliseconds
ttl key
pttl keyRedis 的
expire机制用于管理键的生命周期,允许为键设置生存时间(TTL),当时间到期后自动删除键,从而节省内存资源。以下是其详细介绍及示例:一、设置过期时间的命令
EXPIRE key seconds:以秒为单位设置键的过期时间。
例如:EXPIRE mykey 60,表示mykey会在 60 秒后过期。PEXPIRE key milliseconds:以毫秒为单位设置过期时间。EXPIREAT key timestamp:使用 UNIX 时间戳(秒)设置过期时间。PEXPIREAT key timestamp:使用 UNIX 时间戳(毫秒)设置过期时间。TTL key/PTTL key:分别以秒、毫秒为单位返回键的剩余生存时间。若键未设置过期时间,返回-1;若键不存在,返回-2。二、过期键的存储
Redis 内部使用一个名为
expires的字典存储键的过期时间。字典的键是数据库中的键,值是对应键的过期时间(以毫秒为单位的 UNIX 时间戳)。例如,设置mykey60 秒后过期,expires字典会记录mykey对应的过期时间戳。三、过期键的删除策略
惰性删除(Lazy Expiration)
当客户端尝试访问一个键时,Redis 会检查该键是否过期。若过期,则删除该键并返回空值。
- 优点:仅在访问时检查,减少不必要的 CPU 开销。
- 缺点:若键长期不被访问,可能导致内存泄漏(过期键一直占用内存)。
定期删除(Periodic Expiration)
Redis 定期随机抽取一部分键,检查其是否过期,若过期则删除。
- 检查频率和每次检查的键数量可通过配置调整(默认每秒检查 10 次,每次检查 20 个键)。
- 若一批检查中发现有过期键,会继续检查下一批,直到无过期键或达到最大检查次数。
- 平衡了 CPU 开销和内存回收效率,避免过期键长时间留存。
四、示例
127.0.0.1:6379> SET mykey "hello" # 创建键值对 OK 127.0.0.1:6379> EXPIRE mykey 10 # 设置 mykey 10 秒后过期 (integer) 1 127.0.0.1:6379> TTL mykey # 查看剩余生存时间(秒) (integer) 8 127.0.0.1:6379> PTTL mykey # 查看剩余生存时间(毫秒) (integer) 7890 # 等待 10 秒后再次操作 127.0.0.1:6379> GET mykey # 键已过期删除,返回 (nil) (nil) 127.0.0.1:6379> TTL mykey # 键不存在,返回 -2 (integer) -2通过
expire机制,Redis 能有效管理过期数据,结合惰性删除和定期删除策略,在性能和内存管理上取得平衡,适用于缓存失效、限时数据等场景(如购物车超时自动清理、验证码有效期控制等)。
七、大KEY
在 redis 实例中形成了很大的对象,比如一个很大的 hash 或很大的 zset,这样的对象在扩容的时 候,会一次性申请更大的一块内存,这会导致卡顿;如果这个大 key 被删除,内存会一次性回收, 卡顿现象会再次产生;
# 每隔0.1秒 执行100条scan命令
redis-cli -h 127.0.0.1 --bigkeys -i 0.1Redis 中的 大 key 指占用内存大、包含元素数量多的键,常见于
hash、zset、list等集合类型。例如一个hash键包含数万甚至数十万字段,或一个zset拥有海量成员。这类大 key 在扩容时需申请大量内存,可能引发卡顿;删除时内存一次性回收,也会导致 Redis 服务停顿,且会使内存波动明显。解决方案
发现大 key
使用redis - cli - h <host> --bigkeys - i <interval>命令(如redis - cli - h 127.0.0.1 --bigkeys - i 0.1,每隔 0.1 秒执行 100 条scan命令),快速定位大 key。拆分大 key
- 对
hash,按业务属性拆分。例如,原大 keyuser:1000(存储某用户所有信息,含 10 万字段),可拆分为user:1000:basic(基础信息)、user:1000:detail(详细信息)等小hash,减少单个键的字段数。- 对
zset,按范围或时间拆分。如一个存储全年数据的zset,可按月份拆分为多个zset(zset:202401、zset:202402等)。优化设计避免大 key
- 写入时控制集合大小,如分页存储数据。
- 定期清理无用元素,避免集合无限增长。
一、为什么拆分前后存储量一样却能解决大 key 问题?
虽然拆分前后数据总量未变,但拆分后单个键(小 key)的元素数量和内存占用显著减少,核心优势体现在操作的 粒度和压力分散 上:
- 操作粒度变小:大 key 操作(如扩容、删除)需一次性处理大量元素,耗时久且占用资源集中。拆分后,每个小 key 的操作仅涉及少量元素,耗时短,对 Redis 性能影响小。
- 压力分散:大 key 操作可能导致内存申请或释放的 “瞬间峰值”,拆分后,这些操作的压力分散到多个小 key 上,避免 Redis 因单次操作压力过大而卡顿。例如,删除一个包含 10 万字段的大 hash 会瞬间回收大量内存,可能阻塞 Redis;但拆分为 10 个小 hash 后,每次删除仅回收少量内存,压力分散。
二、为什么大 key 会出现问题?
- 扩容卡顿:
大 key(如大 hash、大 zset)在扩容时需申请一块远大于当前大小的连续内存。例如,一个已用 1GB 内存的大 hash 扩容,可能需申请 2GB 内存,这一过程会阻塞 Redis,直到内存分配完成。- 删除卡顿:
删除大 key 时,内存会被一次性回收,产生大量 “空闲内存块”,可能导致 Redis 主进程暂停(类似 “stop-the-world” 现象),影响服务响应。- 内存管理低效:
大 key 易导致内存碎片化,后续分配内存时,虽有总空闲内存,但缺乏连续大块内存,影响新数据写入,甚至触发频繁扩容。
八、跳表
一、跳表的作用与特性
跳表是一种 多层有序链表结构,主要用于实现有序集合(如 Redis 中的有序集合类型),支持高效的范围查询(如
zrange、zrevrange)。其设计目标是在节点间建立直接连接,确保增删改操作后结构依然有序,同时维持较低的时间复杂度。二、理想跳表
- 结构特点:
每隔一个节点生成一个层级节点,模拟二叉树结构。例如,底层链表包含所有节点,上一层级每隔一个节点抽取一个形成高层链表,以此类推。这种结构使得搜索时间复杂度达到 O(log2n),通过 “空间换时间” 提升查询效率。- 操作问题:
若对理想跳表直接进行删除或增加操作,容易破坏其结构,重构代价巨大。因此,引入概率方法优化。- 概率优化:
从每个节点出发,每增加一个节点都有 21 的概率增加一个层级,41 的概率增加两个层级,81 的概率增加三个层级,以此类推。当数据量足够大(如 128 个节点时),通过概率构造的跳表趋近于理想跳表。此时,若删除节点,无需重构跳表结构,时间复杂度为 (1−w1)∗O(log2n)(w 为平均层级宽度)。三、Redis 跳表的优化
- 结构扁平化:
为节约内存,Redis 牺牲少许时间复杂度,使跳表结构更扁平(类似将二叉堆改为四叉堆),减少层级数量。- 层级限制:
Redis 限制跳表的最高层级为 32,避免层级过多导致内存浪费。- 使用条件:
当节点数量大于 128 或有一个字符串长度大于 64 时,Redis 会使用跳表。这种设计在内存占用和操作效率间取得平衡。四、与其他结构的对比
- 有序数组:通过二分查找可获得 O(log2n) 的时间复杂度,但增删操作代价高(需移动大量元素)。
- 平衡二叉树:也能达到 O(log2n) 的时间复杂度,但实现复杂,插入、删除时需频繁调整树结构(如旋转操作)。
- B+ 树:时间复杂度为 h∗O(log2n)(h 为树高),但存在复杂的节点分裂操作,实现难度大。
跳表则通过链表层级结构,在保证接近上述结构时间复杂度的同时,简化了增删改操作的实现,尤其适合 Redis 对有序集合的操作需求。
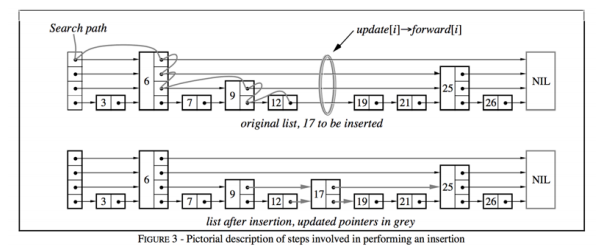
数据结构:
#define ZSKIPLIST_MAXLEVEL 32 /* Should be enough for 2^64 elements */
#define ZSKIPLIST_P 0.25 /* Skiplist P = 1/4 */
/* ZSETs use a specialized version of Skiplists */
typedef struct zskiplistNode {sds ele;double score; // WRN: score 只能是浮点数struct zskiplistNode *backward;struct zskiplistLevel {struct zskiplistNode *forward;unsigned long span; // 用于 zrank} level[];
} zskiplistNode;typedef struct zskiplist {struct zskiplistNode *header, *tail;unsigned long length; // zcardint level; // 最高层
} zskiplist;typedef struct zset {dict *dict; // 帮助快速索引到节点zskiplist *zsl;
} zset;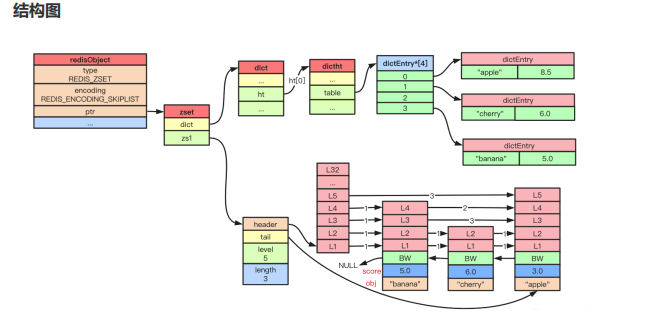
0voice · GitHub