【AI论文】ZeroSearch:在不搜索的情况下激励LLM的搜索能力
摘要:有效的信息搜索对于增强大型语言模型(LLMs)的推理和生成能力至关重要。 最近的研究探索了使用强化学习(RL)通过在现实环境中与实时搜索引擎进行交互来提高LLM的搜索能力。 虽然这些方法显示出有希望的结果,但它们面临着两个主要挑战:(1)不受控制的文档质量:搜索引擎返回的文档质量往往是不可预测的,这给训练过程带来了噪音和不稳定。 (2)API成本过高:RL训练需要频繁地推出,可能涉及数十万个搜索请求,这会产生大量的API费用,并严重限制可扩展性。 为了应对这些挑战,我们引入了ZeroSearch,这是一种强化学习框架,在不与真实搜索引擎交互的情况下,激励LLM的搜索能力。 我们的方法从轻量级的监督微调开始,将LLM转换为检索模块,该模块能够根据查询生成相关和有噪声的文档。 在 RL 训练过程中,我们采用基于课程的推出策略,该策略会逐步降低生成文档的质量,通过将其暴露于越来越具有挑战性的检索场景中,逐步激发模型的推理能力。 广泛的实验证明,ZeroSearch有效地激励了LLM的搜索能力,它使用3B LLM作为检索模块。 值得注意的是,7B检索模块的性能与真实搜索引擎相当,而14B检索模块甚至超过了它。此外,它在各种参数大小的基础模型和指令调整模型上都有很好的泛化能力,并且与各种强化学习算法兼容。Huggingface链接:Paper page,论文链接:2505.04588
一、研究背景和目的
研究背景:
随着大型语言模型(LLMs)在自然语言处理领域的广泛应用,如何有效提升其推理和生成能力成为了一个重要的研究方向。信息搜索作为增强LLMs能力的一种关键手段,传统上依赖于与实时搜索引擎的交互。然而,这种方法存在两大显著挑战:
- 文档质量不可控:搜索引擎返回的文档质量参差不齐,这种不可预测性给训练过程带来了噪音和不稳定因素,影响了模型的最终性能。
- API成本高昂:强化学习(RL)训练需要频繁地与搜索引擎进行交互,这往往涉及大量的搜索请求,进而产生巨额的API费用,严重限制了模型的扩展性和实用性。
研究目的:
针对上述挑战,本研究旨在提出一种名为ZeroSearch的强化学习框架,旨在不依赖真实搜索引擎的情况下,有效激励LLMs的搜索能力。具体目标包括:
- 开发一种轻量级的监督微调方法:将LLM转换为一个能够生成相关和有噪声文档的检索模块。
- 设计一种基于课程的推出策略:在RL训练过程中,逐步降低生成文档的质量,通过暴露模型于越来越具有挑战性的检索场景中,激发其推理能力。
- 验证ZeroSearch的有效性:通过广泛的实验,证明ZeroSearch能够在不使用真实搜索引擎的情况下,有效激励LLMs的搜索能力,并达到或超过使用真实搜索引擎的性能。
二、研究方法
1. 轻量级监督微调:
- 目标:将LLM转换为一个检索模块,能够根据查询生成相关和有噪声的文档。
- 方法:收集LLM与真实搜索引擎交互的轨迹数据,标记出导致正确和错误答案的查询-文档对,进行轻量级的监督微调(SFT)。通过调整提示中的几个关键词,使LLM能够生成有用或嘈杂的文档。
2. 基于课程的推出策略:
- 目标:在RL训练过程中,逐步增加任务的难度,激发模型的推理能力。
- 方法:设计一个概率函数,控制生成文档中噪声文档的比例。随着训练的进行,逐渐增加噪声文档的比例,使模型从处理简单场景开始,逐步适应更复杂和具有挑战性的检索场景。
3. 奖励设计:
- 目标:提供有效的监督信号,引导模型学习正确的搜索策略。
- 方法:采用基于F1分数的奖励函数,平衡精确率和召回率,避免模型产生过长的答案以增加包含正确答案的机会。
4. 训练算法:
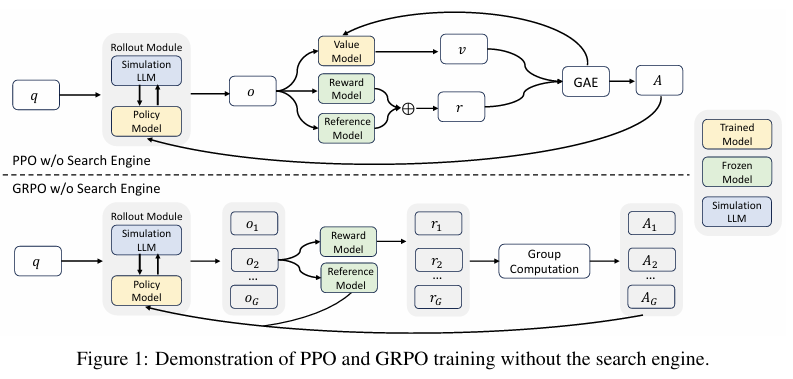
- 目标:选择合适的RL算法,优化检索增强的推理过程。
- 方法:实验中采用了近端策略优化(PPO)和组相对策略优化(GRPO)两种算法,发现GRPO在训练稳定性方面表现更优。
三、研究结果
1. 性能提升:
- 与基线方法比较:ZeroSearch在多个问答数据集上显著优于直接提示、思维链(CoT)、检索增强生成(RAG)等基线方法,甚至超过了使用真实搜索引擎的RL方法(如Search-R1)。
- 模型规模的影响:随着LLM规模的增大(从3B到14B),ZeroSearch的性能持续提升,表明其具有良好的可扩展性。
2. 泛化能力:
- 跨模型类型:ZeroSearch在基础模型和指令调整模型上均表现出色,证明了其广泛的适用性。
- 跨RL算法:与多种RL算法兼容,进一步验证了其灵活性和鲁棒性。
3. 训练稳定性:
- 奖励曲线:ZeroSearch的奖励曲线比使用真实搜索引擎的方法更平滑,表明其训练过程更稳定。
- 交互轮数:随着训练的进行,模型逐渐学会有效调用搜索引擎,减少了不必要的交互轮数。
4. 成本效益:
- API成本:ZeroSearch完全消除了对商业API的依赖,显著降低了训练成本。
- GPU成本:虽然需要部署模拟搜索LLM的GPU服务器,但通过共享服务器和灵活选择模型规模,可以有效控制成本。
四、研究局限
1. 基础设施成本:
- GPU服务器需求:部署模拟搜索LLM需要GPU服务器,这增加了基础设施成本。尽管比商业API更经济,但对于资源有限的研究团队来说,仍然是一个挑战。
2. 模拟与现实的差距:
- 文档质量差异:尽管通过轻量级监督微调缩小了模拟文档与真实文档之间的差距,但两者之间仍存在一定差异,可能影响模型的泛化能力。
- 检索场景多样性:模拟搜索LLM可能无法完全覆盖所有真实的检索场景,导致模型在某些特定情况下的性能下降。
3. 模型规模的限制:
- 计算资源需求:随着LLM规模的增大,训练所需的计算资源也显著增加。对于资源有限的研究团队来说,这可能限制了他们使用更大规模模型的能力。
4. 奖励设计的局限性:
- 单一奖励指标:目前采用的基于F1分数的奖励函数可能无法全面反映模型的性能。例如,它可能无法有效激励模型在生成答案时的多样性和创造性。
五、未来研究方向
1. 进一步优化模拟搜索LLM:
- 提高文档质量:探索更先进的监督微调方法,以进一步缩小模拟文档与真实文档之间的差距。
- 增强检索场景多样性:通过引入更多样化的查询和文档数据,提高模拟搜索LLM的泛化能力。
2. 探索更高效的RL算法:
- 降低计算成本:研究更高效的RL算法,减少训练过程中的计算资源需求。
- 提高训练稳定性:进一步优化奖励设计和训练策略,提高训练过程的稳定性和收敛速度。
3. 结合多模态信息:
- 引入图像和视频数据:将ZeroSearch框架扩展到多模态领域,结合图像和视频数据,提升模型在更广泛任务上的性能。
- 跨模态检索:探索跨模态检索技术,使模型能够在不同模态之间进行有效的信息检索和整合。
4. 考虑伦理和社会影响:
- 数据隐私和安全:在训练和使用过程中,严格遵守数据隐私和安全规定,确保用户信息的安全。
- 模型偏见和公平性:关注模型可能存在的偏见和公平性问题,通过算法优化和数据增强等手段,提高模型的公正性和包容性。
5. 推动实际应用:
- 与行业合作:与相关行业合作,将ZeroSearch框架应用于实际场景中,如智能客服、智能推荐系统等。
- 用户反馈和迭代:收集用户反馈,不断迭代和优化模型性能,满足实际应用的需求。
六、结论
本研究提出的ZeroSearch框架为在不依赖真实搜索引擎的情况下激励LLMs的搜索能力提供了一种有效的方法。通过轻量级监督微调、基于课程的推出策略、精心设计的奖励函数以及兼容多种RL算法的训练过程,ZeroSearch在多个问答数据集上取得了显著的性能提升,并展示了良好的泛化能力和训练稳定性。尽管存在一些局限性,如基础设施成本、模拟与现实的差距等,但通过进一步的研究和优化,ZeroSearch有望在未来成为提升LLMs搜索能力的重要工具。同时,结合多模态信息、考虑伦理和社会影响以及推动实际应用等未来研究方向,将为ZeroSearch框架的发展开辟更广阔的前景。