SPC:通过对抗性博弈,让LLM左右互搏提升性能
摘要:评估大型语言模型(LLM)推理的逐步可靠性(例如,思维链推理)仍然是一个挑战,因为获取高质量的逐步监督数据既困难又成本高昂。在本文中,我们介绍了一种名为 SelfPlay Critic (SPC) 的新方法,其中批评模型通过对抗性自我博弈游戏逐步提升其评估推理步骤的能力,从而消除了对人工逐步标注的需求。SPC 包括对基础模型的两个副本进行微调,使其分别扮演两个角色:一个是“狡猾的生成器”,它故意生成难以被检测到的错误步骤;另一个是“批评器”,它分析推理步骤的正确性。这两个模型在一个对抗性游戏中相互竞争,生成器的目标是欺骗批评器,而批评器则试图识别生成器的错误。基于游戏结果,模型通过强化学习迭代改进:每次对抗中获胜的一方获得正奖励,失败的一方获得负奖励,从而推动模型的持续自我进化。在三个推理过程基准测试(ProcessBench、PRM800K、DeltaBench)上的实验表明,我们的 SPC 逐步提升了其错误检测能力(例如,在 ProcessBench 上的准确率从 70.8% 提高到 77.7%),并且超越了强大的基线模型,包括经过蒸馏的 R1 模型。此外,将 SPC 应用于指导多种 LLM 的测试时搜索,显著提升了它们在 MATH500 和 AIME2024 上的数学推理性能,超越了最先进的过程奖励模型。
本文目录
一、背景动机
二、核心贡献
编辑
三、实现方法
3.1 对抗性自博弈框架
3.2 初始化模型
3.3 对抗性游戏
3.4 强化学习
3.5 提升 LLM 推理性能
四、实验结果
4.1 基准结果
4.2 推理性能提升
4.3 消融研究
五、总结
一、背景动机
论文题目:SPC: Evolving Self-Play Critic via Adversarial Games for LLM Reasoning
论文地址:https://arxiv.org/pdf/2504.19162
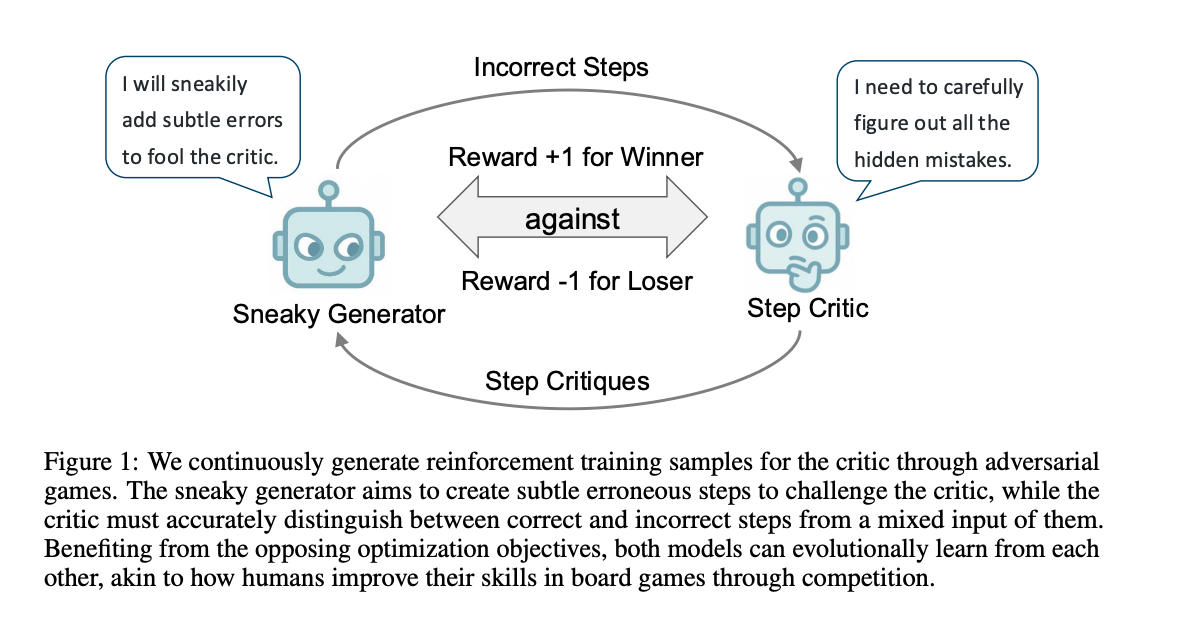
大模型使用CoT进行推理时,在解决复杂任务时表现出色。然而,验证这些推理步骤的可靠性是一个挑战,现有的验证模型需要手动标注步骤级数据,这不仅耗时费力,而且难以适应快速更新的 LLM。此外,现有的数据集限制了验证模型的训练,使其只能作为简单的评分机制,而无法提供实质性的反馈。因此,文章提出了一种无需手动标注步骤级数据的方法,通过对抗性自博弈来训练一个能够评估推理步骤的批评者模型(critic model)。
二、核心贡献
- 提出了 SPC,一种通过对抗性自博弈训练的批评者模型,能够自动评估 LLM 推理步骤的正确性。
- 设计了一个对抗性游戏,让一个“狡猾的生成器”(sneaky generator)生成难以检测的错误步骤,而“批评者”(critic)则尝试识别这些错误。
- 通过强化学习,基于游戏结果迭代提升生成器和批评者的能力,使得批评者能够逐步提高错误检测的准确性。
- 在三个推理过程基准测试(ProcessBench、PRM800K、DeltaBench)上验证了 SPC 的有效性,其性能逐渐提升并超越了现有的强基线模型,包括经过蒸馏的 R1 模型。
- 将 SPC 应用于指导不同 LLM 在测试时的搜索过程,显著提升了它们在 MATH500 和 AIME2024 上的数学推理性能,优于现有的过程奖励模型(PRM)。
三、实现方法
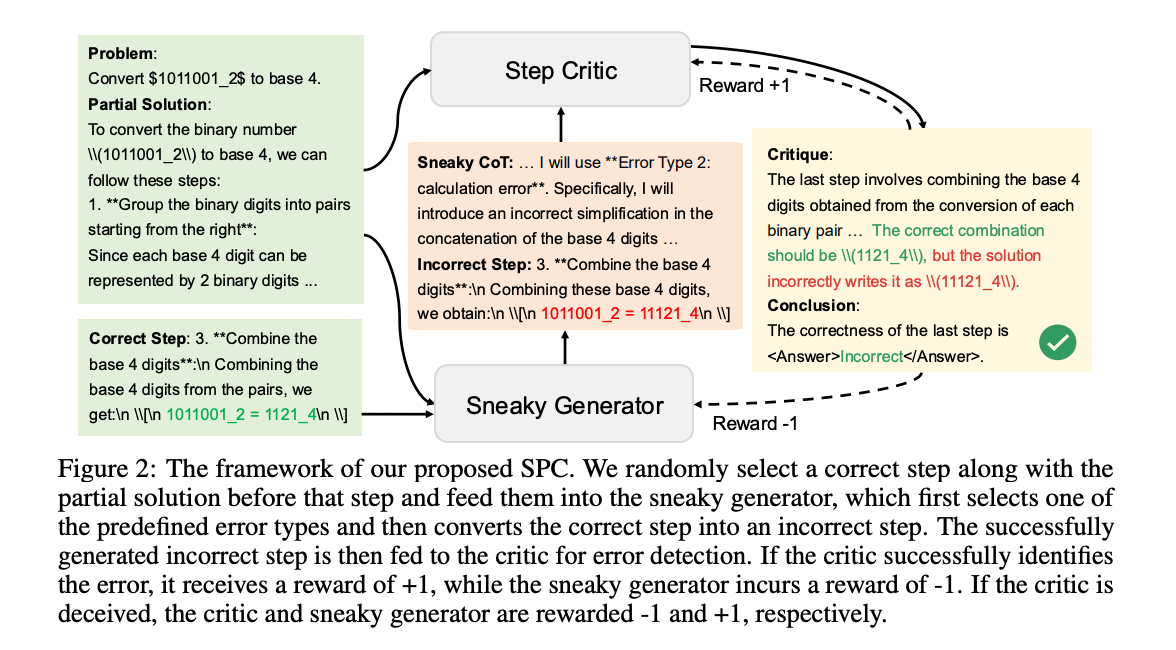
3.1 对抗性自博弈框架
SPC 框架的核心是两个相互对抗的模型:
-
Sneaky Generator(狡猾生成器):负责将正确的推理步骤转换为错误的步骤,这些错误步骤旨在欺骗批评者模型。
-
Step Critic(步骤批评者):负责评估推理步骤的正确性,并提供批评。
这两个模型通过对抗性游戏进行训练,生成器试图生成难以被批评者检测到的错误步骤,而批评者则试图识别这些错误。通过强化学习,基于游戏结果对模型进行迭代改进。
3.2 初始化模型
-
Sneaky Generator 的初始化:
-
使用监督微调(Supervised Fine-Tuning, SFT)对基础模型进行训练,使其能够生成错误的步骤。
-
通过从 PRM800K 数据集中提取正确和错误的步骤对,训练生成器将正确的步骤转换为错误的步骤。
-
使用 GPT-4 生成错误步骤的转换过程,形成行为克隆数据集,用于训练初始的生成器模型。
-
-
Step Critic 的初始化:
-
同样使用 SFT 对基础模型进行训练,使其能够生成对推理步骤的批评。
-
从 PRM800K 数据集中提取正确和错误的步骤,并使用 GPT-4 将长篇批评改写为简短的标准格式。
-
通过混合正确和错误的步骤数据,训练初始的批评者模型。
-
3.3 对抗性游戏
-
在每次迭代中,使用不同的 LLM 解决器生成一系列原始的逐步解决方案。
-
从这些解决方案中随机选择单个步骤进行“狡猾”转换,并将成功生成的错误步骤输入到批评者模型中。
-
根据批评者是否成功检测到错误步骤,对生成器和批评者进行奖励或惩罚,从而推动模型的自我进化。
3.4 强化学习
-
使用离线强化学习(offline reinforcement learning)对生成器和批评者进行训练,基于游戏结果进行自我改进。
-
采用重要性采样(importance sampling)和优势估计(advantage estimation)来优化训练过程。
3.5 提升 LLM 推理性能
-
在测试时,利用训练好的批评者模型对 LLM 的推理步骤进行实时评估。
-
如果步骤正确,则继续推理;如果错误,则要求 LLM 重新生成该步骤,最多尝试五次。
四、实验结果
4.1 基准结果
-
使用 ProcessBench、PRM800K 和 DeltaBench 三个基准数据集来评估模型在数学推理步骤评估上的性能。这些数据集包含了人类标注的推理步骤的正确性,用于测试模型对推理步骤的评估能力。
-
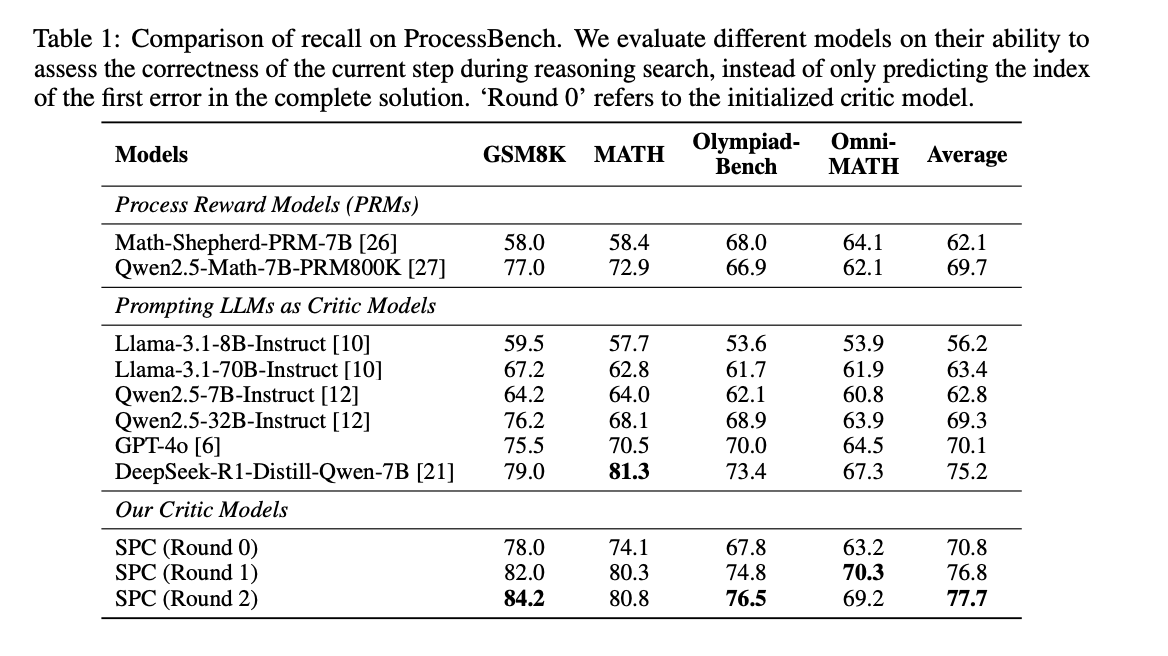
ProcessBench:SPC 在经过两轮迭代训练后,准确率从 70.8% 提升到 77.7%,超越了同尺寸的 R1 模型(71.4%)。
-
PRM800K:SPC 的平均准确率从 71.0% 提升到 75.8%,在正确和错误步骤的召回率上更加平衡。
-
DeltaBench:SPC 的准确率从 54.9% 提升到 60.5%,在长推理链(long CoT)数据上的泛化能力优于现有的过程奖励模型(PRMs)。
4.2 推理性能提升
-
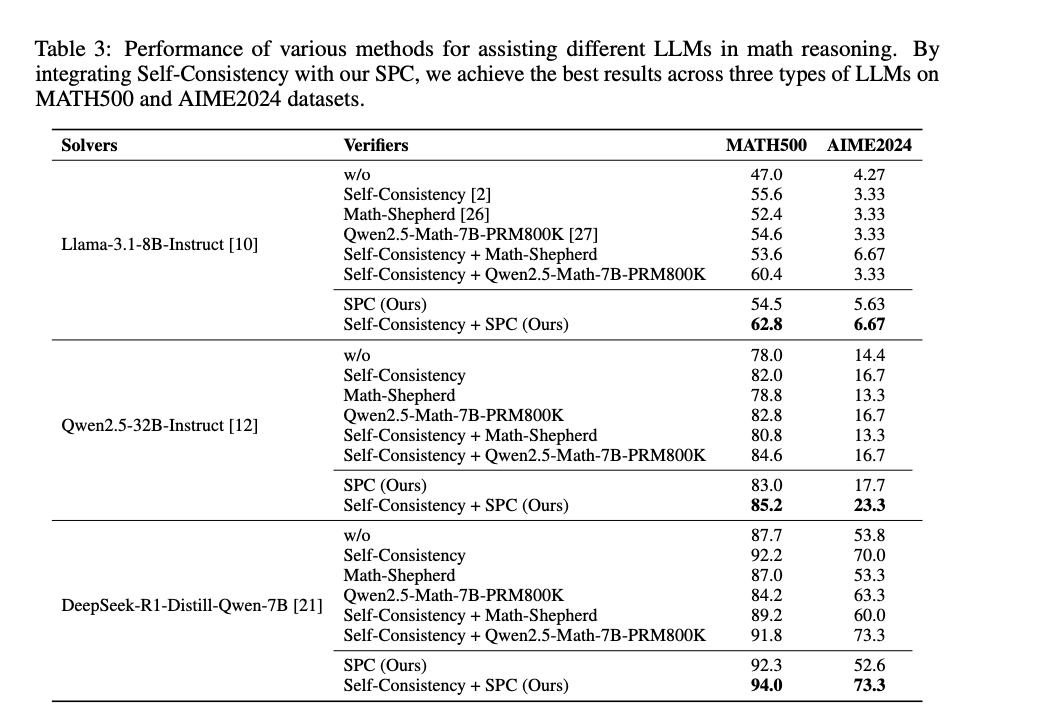
在 MATH500 和 AIME2024 两个数学推理基准测试中,SPC 显著提升了 LLM 的推理性能。在 AIME2024 上,使用 SPC 辅助的 Qwen 模型达到了 23.3% 的问题解决准确率,优于仅使用自一致性的 16.7%。
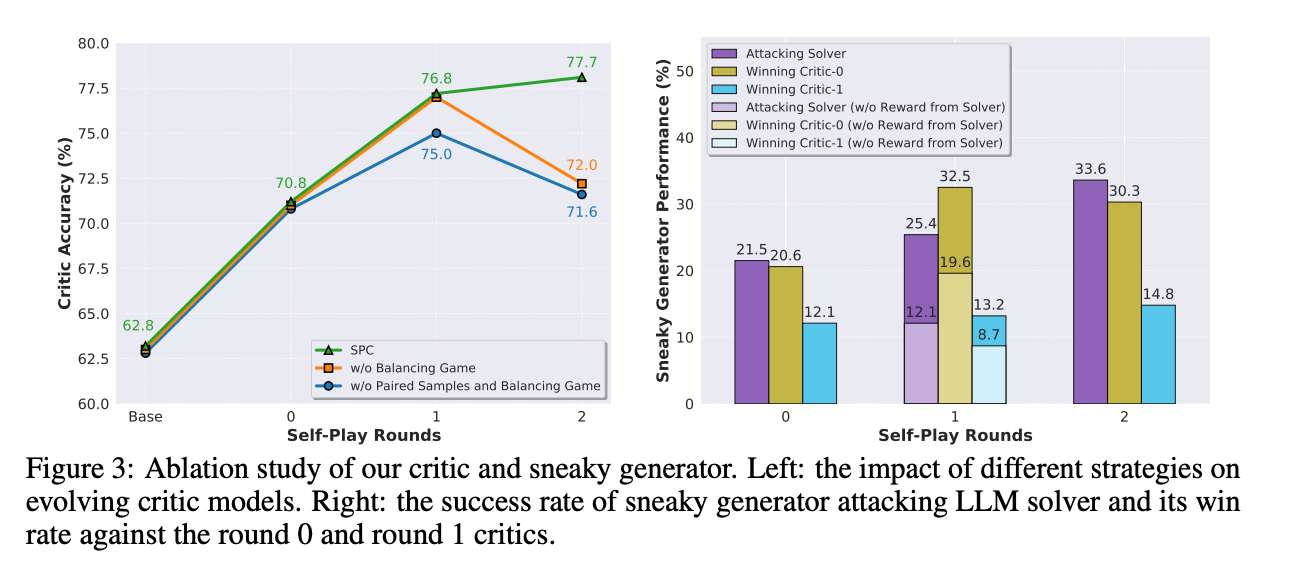
4.3 消融研究
-
不同策略对批评者进化的影响:
-
通过构建配对样本(paired samples)和平衡对抗游戏,SPC 的性能得到了显著提升。
-
不平衡的对抗游戏可能导致模型性能下降,而平衡的对抗游戏有助于模型的自我进化。
-
-
狡猾生成器的性能:
-
生成器在对抗 LLM 解决器和批评者模型时的成功率逐渐提高,表明其生成错误步骤的能力在不断进化。
-
五、总结
SPC旨在通过对抗性自博弈游戏来评估大模型(LLM)的推理步骤,从而消除对人工步骤级标注的需求。该方法的核心思想是利用两个角色:一个“狡猾”生成器(Sneaky Generator)和一个步骤评价器(Step Critic),通过强化学习不断优化这两个角色的能力。