深入理解 Oracle 数据块:行迁移与行链接的性能影响
导语
在 Oracle 数据库的世界中,数据存储的组织方式直接关系到性能的高低。你是否曾遇到过查询速度突然变慢,或者数据库空间利用率异常的情况? 这可能与 Oracle 数据块中隐藏的两个“幕后黑手”——行迁移 (Row Migration) 和行链接 (Row Chaining) 有关。本次,我们将拨开迷雾,深入探索这两种现象的本质、成因以及应对策略,帮助你更好地优化数据库性能,提升数据存储的效率。准备好了吗?让我们一起开始这段技术之旅!
一. 行迁移 (Row Migration)
- 定义: 当数据库执行 UPDATE 操作时,如果更新后的行数据长度超过了当前数据块剩余的空间, Oracle 就会将整行数据迁移到另一个有足够空间的数据块中。 原数据块中会保留一个指向新数据块的指针(row forwarding pointer)。
- 触发条件:
- 主要是 UPDATE 操作,导致行长度增加。
- 数据块剩余空间不足以容纳增长后的行数据。
- 影响:
- 性能下降: 读取被迁移的行时,需要先读取原数据块获取指针,然后再读取新的数据块,增加了 I/O 操作,导致查询性能下降。 就像你要找一个人,结果发现他搬家了,你得先跑到他原来的地址,拿到新地址,然后再去新地址找他,多跑了一趟。
- 存储碎片: 原数据块中留下空间碎片,降低存储效率。
- 如何避免和减少行迁移:
- 合理设置 PCTFREE:
PCTFREE参数用于设置数据块的预留空间百分比,用于 UPDATE 操作。 设置合适的PCTFREE值,可以为行增长预留足够的空间,降低行迁移的概率。 但PCTFREE设置过大也会浪费存储空间。 - 定期整理表空间: 通过表空间重组 (Tablespace Reorganization) 或表重组 (Table Reorganization) 等操作,可以整理数据块,消除碎片,减少行迁移带来的性能影响。 注意,重组操作通常需要停机或在业务低峰期进行。
- 避免频繁更新大字段: 尽量避免对包含大字段(如 CLOB, BLOB)的行进行频繁更新,因为大字段的更新很容易导致行长度增加。
- 使用压缩表: Oracle 压缩表可以减少数据存储空间,从而降低行迁移的概率。
- 监控行迁移: 通过查询
DBA_TABLES视图的MIGRATED_ROWS列,可以监控表的行迁移情况。 也可以使用ANALYZE TABLE ... VALIDATE STRUCTURE CASCADE命令来检查表的结构并检测行迁移。
- 合理设置 PCTFREE:
二、 行链接 (Row Chaining)
- 定义: 当一行数据的长度超过了 Oracle 数据块的最大容量时(通常接近 8KB,取决于数据库配置), Oracle 会将该行数据分割成多个片段,分别存储在多个数据块中。 这些数据块通过指针链接在一起,形成一个链表。
- 触发条件:
- 一行数据长度超过数据块的最大容量。 这通常发生在 VARCHAR2(4000) 或 CLOB 等大型数据类型字段存储大量数据时。
- 影响:
- 严重的性能下降: 读取链式存储的行时,需要读取多个数据块,增加了大量的 I/O 操作,导致查询性能急剧下降。 就像你要读一本书,结果这本书被撕成了很多碎片,分散在不同的地方,你需要跑到不同的地方把这些碎片都找回来才能读完,非常耗时。
- 无法使用索引: 在某些情况下,行链接可能会导致索引失效,进一步降低查询性能。
- 如何避免和减少行链接:
- 设计合理的表结构: 尽量避免使用过多的 VARCHAR2(4000) 或 CLOB 等大型数据类型字段。 如果必须使用,需要仔细评估数据长度,并考虑是否可以拆分成多个字段。
- 调整表空间块大小: 在创建表空间时,可以指定更大的块大小(例如 16KB 或 32KB),以容纳更大的行数据。 但块大小的增加会影响数据库的内存使用和 I/O 效率,需要综合考虑。
- 使用压缩表: Oracle 压缩表可以减少数据存储空间,有助于避免行链接。
- 避免频繁更新导致行增长: 虽然行链接主要由行长度超过块大小引起,但频繁更新也可能导致行增长,增加行链接的风险。
- 监控行链接: 可以使用
ANALYZE TABLE ... VALIDATE STRUCTURE CASCADE命令来检查表的结构并检测行链接。 也可以通过查询DBA_TABLES视图的CHAIN_CNT列来统计表的行链接数量。
三、行迁移和行链接的关系
行迁移是由 UPDATE 语句引起的, INSERT 和 DELETE 永远不会导致行迁移。
默认情况下, Oracle 会保留一个块的 10%用于行扩展。这是段的 PCTFREE(空闲百分比)设置的,一个使用量已经超过了段的 PCTFREE 设置的块由 ASSM 位图归类为FULL,因此该块不可用于插入,即使它实际上还有 10%的空闲空间。
因此,如果块的行在其生存期间增长不超过 10%(平均而言) ,这是没有问题的:行的新版本有足够的空间可用。如果一个行的扩展使得块中没有足够的空间时,它就必须被移动到具有足够空间的块中。这称之为行迁移(Row Migration)。
与行迁移密切相关的是行链接问题。行链接(Chained Row)是比块还要大的行。显然,如果块大小是 8k,而某行是 20k,则该行必须被分布到 3 个块中。在执行插入时,所有三个块将通过搜索 ASSM 位图来定位可用于插入的块,并且以后检索该行时,所有三个块都会被读出。链接行的 ROWID 指向行的第一个块,这与行迁移的情况相同。
3.1 行链接--一个块里只有一行
引用一下官方文档里的说明:
The row is too large to fit into one data block when it is first inserted.In row chaining, Oracle Database stores the data for the row in a chain of one or more data blocks reserved for the segment. Row chaining most often occurs with large rows. Examples include rows that contain a column of data type LONG or LONG RAW , or a row with a huge number of columns. Row chaining in these cases is unavoidable.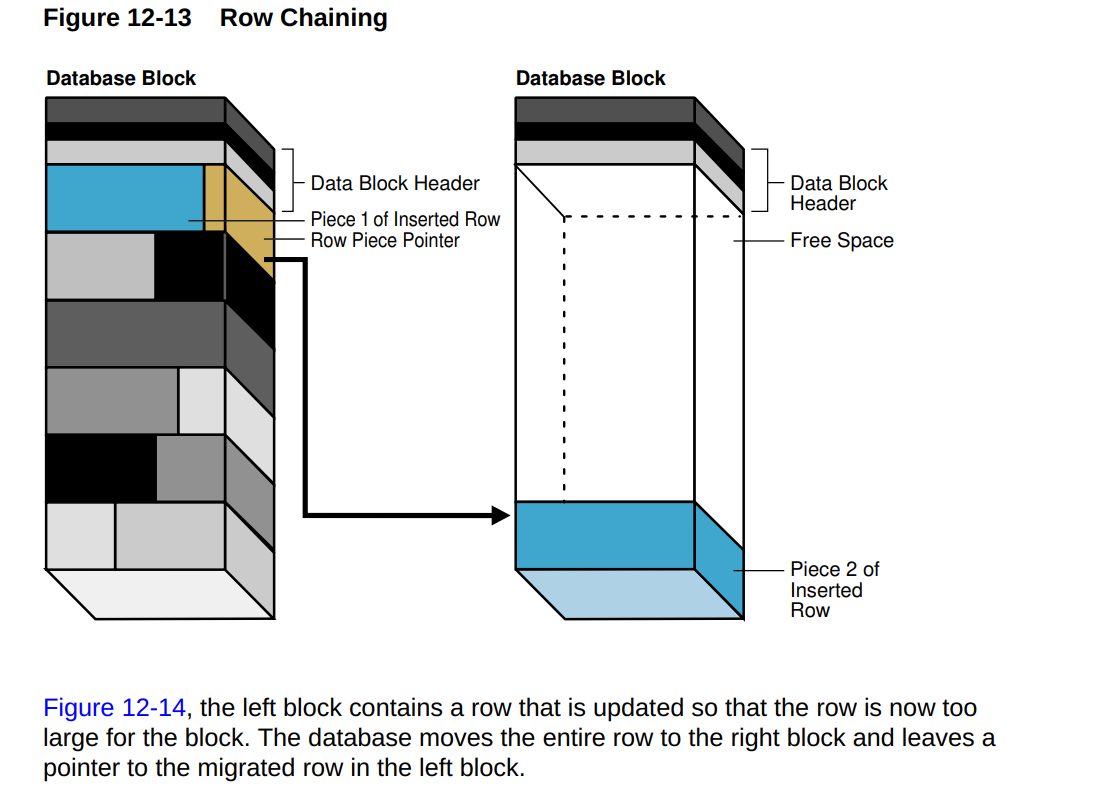
3.2 行迁移-因update导致块中某一行在块中存储不下
A row that originally fit into one data block is updated so that the overall row length increases, but insufficient free space exists to hold the updated row.In row migration, Oracle Database moves the entire row to a new data block,assuming the row can fit in a new block. The original row piece of a migrated row contains a pointer or "forwarding address" to the new block containing the migrated row. The rowid of a migrated row does not change.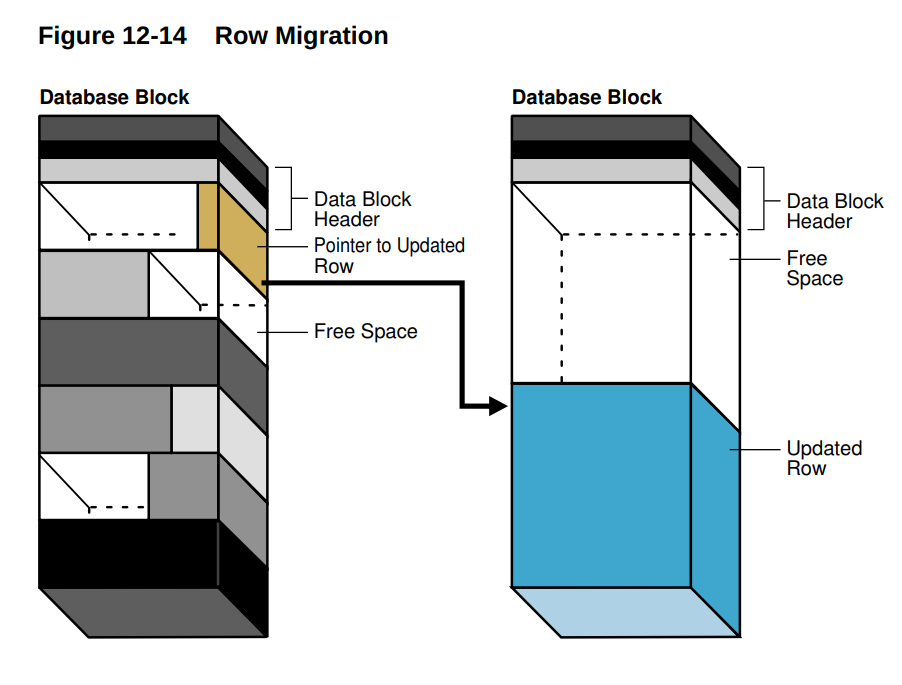
四、行迁移的模拟与消除
4.1、模拟行迁移
1、创建一个4K表空间alter system set db_4k_cache_size=1m scope=both;drop tablespace tbs1 including contents and datafiles;create tablespace tbs1 datafile size 10m blocksize 4k;2、给用户分配表空间配额alter user u1 quota 1m on tbs1;3、创建表。字段类型为char的目的为了将4K表空间一个块占满
conn u1/u1@pdb2create table row_chain_demo(x int primary key,a char(1000),b char(1000),c char(1000),d char(1000)) tablespace tbs1;4、插入数据
insert into row_chain_demo(x,a,b,c,d) values(1,'a','b','c','d');commit;4、分析测试表,检查行链接
--首先建chaind_rows相关表
conn sys/oracle@pdb2drop table CHAINED_ROWS;
@?/rdbms/admin/utlchain.sql--分析表analyze table u1.row_chain_demo list chained rows into chained_rows;5、查看行链接结果select * from chained_rows where table_name='ROW_CHAIN_DEMO';
OWNER_NAME TABLE_NAME CLUSTER_NAME
-------------------------------------------------------------------------------------------------------------------------------- -------------------------------------------------------------------------------------------------------------------------------- --------------------------------------------------------------------------------------------------------------------------------
PARTITION_NAME SUBPARTITION_NAME HEAD_ROWID ANALYZE_TIMESTAMP
-------------------------------------------------------------------------------------------------------------------------------- -------------------------------------------------------------------------------------------------------------------------------- ------------------ -------------------
U1 ROW_CHAIN_DEMON/A AAAR2YAAcAAAAEKAAA 2023-06-30 09:56:026、查看有行链接的情况下,执行计划扫描的块数SYS@pdb> select /*+index(ROW_CHAIN_DEMO,x)*/* from u1.ROW_CHAIN_DEMO where x=1;
xecution Plan
----------------------------------------------------------
Plan hash value: 3029137777----------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 4007 | 1 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| ROW_CHAIN_DEMO | 1 | 4007 | 1 (0)| 00:00:01 |
|* 2 | INDEX UNIQUE SCAN | SYS_C007584 | 1 | | 0 (0)| 00:00:01 |
----------------------------------------------------------------------------------------------Predicate Information (identified by operation id):
---------------------------------------------------2 - access("X"=1)Statistics
----------------------------------------------------------0 recursive calls0 db block gets3 consistent gets0 physical reads0 redo size4869 bytes sent via SQL*Net to client432 bytes received via SQL*Net from client2 SQL*Net roundtrips to/from client0 sorts (memory)0 sorts (disk)1 rows processed7、查看该行的文件号块号
SYS@pdb> select dbms_rowid.rowid_relative_fno(rowid) file#,dbms_rowid.rowid_block_number(rowid) block# from u1.row_chain_demo;FILE# BLOCK#
---------- ----------28 2668、dump 28号文件266号
oradebug setmypid
alter system dump datafile 28 block 266;
oradebug close_trace;
oradebug tracefile_namedump内容如下
data_block_dump,data header at 0x7aa9d064
===============
tsiz: 0xf98
hsiz: 0x14
pbl: 0x7aa9d06476543210
flag=--------
ntab=1
nrow=1
frre=-1
fsbo=0x14
fseo=0xba1
avsp=0xb8d
tosp=0xb8d
0xe:pti[0] nrow=1 offs=0
0x12:pri[0] offs=0xba1
block_row_dump:
tab 0, row 0, @0xba1
tl: 1015 fb: --H-F--- lb: 0x1 cc: 2 -->正常的行记录为--H-FL--,而这里为只有F(fisrt)而没有L(last),说明在这个数据块中只有行的开始,而没有行的结束,同样cc为2说明这个块中只包含了表的两个列
nrid: 0x07000109.0 -->nrid表示数据块的下一个指针,即其他列数据存放的数据块地址
col 0: [ 2] c1 02
col 1: [1000]61 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 2020 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 29、查看行链接指向的块select dbms_utility.data_block_address_file(to_number(ltrim('0x07000109','0x'),'xxxxxxxx')) file_id,dbms_utility.data_block_address_block(to_number(ltrim('0x07000109','0x'),'xxxxxxxx')) block_id from dual;FILE_ID BLOCK_ID
---------- ----------28 26510、继续dump 28号文件265号
data_block_dump,data header at 0x7f2993e5407c
===============
tsiz: 0xf80
hsiz: 0x14
pbl: 0x7f2993e5407c76543210
flag=--------
ntab=1
nrow=1
frre=-1
fsbo=0x14
fseo=0x3bc
avsp=0x3a8
tosp=0x3a8
0xe:pti[0] nrow=1 offs=0
0x12:pri[0] offs=0x3bc
block_row_dump:
tab 0, row 0, @0x3bc
tl: 3012 fb: -----L-- lb: 0x1 cc: 3 -->这里表示行的LAST尾部
col 0: [1000]62 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 2020 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 2020 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 204.2、消除行迁移
既然一个块装载不下一行数据,那可以用更大的块来装载,这样就可以消除行迁移
1、创建32kb的表空间
--CDB执行alter system set db_32k_cache_size=1m scope=both;--pdb执行
drop tablespace tbs2 including contents and datafiles;create tablespace tbs2 datafile size 10m blocksize 32k;alter user u1 quota unlimited on tbs2;2、将目标表移动到新的表空间alter table u1.row_chain_demo move tablespace tbs2;3、将主键索引rebuild
select index_name from dba_indexes where table_name='ROW_CHAIN_DEMO';INDEX_NAME
--------------------------------------------------------------------------------------------------------------------------------
SYS_C007584alter index u1.SYS_C007584 rebuild;4、清除行连接记录表,再次分析,查看行链接消除
delete from chained_rows;
commit;analyze table u1.ROW_CHAIN_DEMO list chained rows into chained_rows;select * from chained_rows where table_name='CHAIN_ROW_DEMO';
--无数据5、再次查看执行计划select /*+index(ROW_CHAIN_DEMO,x)*/* from u1.ROW_CHAIN_DEMO where x=1;
Execution Plan
----------------------------------------------------------
Plan hash value: 3029137777----------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 4021 | 1 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| ROW_CHAIN_DEMO | 1 | 4021 | 1 (0)| 00:00:01 |
|* 2 | INDEX UNIQUE SCAN | SYS_C007584 | 1 | | 0 (0)| 00:00:01 |
----------------------------------------------------------------------------------------------Predicate Information (identified by operation id):
---------------------------------------------------2 - access("X"=1)Hint Report (identified by operation id / Query Block Name / Object Alias):
Total hints for statement: 1 (U - Unused (1))
---------------------------------------------------------------------------1 - SEL$1 / ROW_CHAIN_DEMO@SEL$1U - index(ROW_CHAIN_DEMO,x) / index specified in the hint doesn't existStatistics
----------------------------------------------------------0 recursive calls0 db block gets2 consistent gets0 physical reads0 redo size4707 bytes sent via SQL*Net to client420 bytes received via SQL*Net from client1 SQL*Net roundtrips to/from client0 sorts (memory)0 sorts (disk)1 rows processed结论:消除行链接的办法,主要是通过更大块来装载数据。
通过消除行链接实验,逻辑的块数从3降为2。原因是原来一行占用2个块,现在只占用1个块。
五、模拟行链接产生和消除
5.1 模拟行迁移
1、创建行迁移的表
--创建测试表,保证修改表之后产生行迁移
drop table row_mig_demo;create table row_mig_demo(
x int primary key,
a char(1000),
b char(1000),
c char(1000),
d char(1000),
e char(1000)
) tablespace users;2、插入数据
insert into row_mig_demo values(1,'a','b','c','d','');insert into row_mig_demo(x) values(2);commit;3、分析表发现此时没有行迁移delete from chained_rows;
commit;analyze table u1.row_mig_demo list chained rows into chained_rows;select * from chained_rows where table_name='ROW_MIG_DEMO';no rows selected4、查看此行所在在块
select dbms_rowid.rowid_relative_fno(rowid) file#,dbms_rowid.rowid_block_number(rowid) block# from row_mig_demo;FILE# BLOCK#
---------- ----------12 29512 2955、查看此时的执行计划
set autot trace
set linesize 1000
select * from ROW_MIG_DEMO where x=2;
Execution Plan
----------------------------------------------------------
Plan hash value: 4113747091--------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 5023 | 1 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| ROW_MIG_DEMO | 1 | 5023 | 1 (0)| 00:00:01 |
|* 2 | INDEX UNIQUE SCAN | SYS_C007597 | 1 | | 1 (0)| 00:00:01 |
--------------------------------------------------------------------------------------------Predicate Information (identified by operation id):
---------------------------------------------------2 - access("X"=2)Statistics
----------------------------------------------------------0 recursive calls0 db block gets2 consistent gets0 physical reads0 redo size758 bytes sent via SQL*Net to client388 bytes received via SQL*Net from client1 SQL*Net roundtrips to/from client0 sorts (memory)0 sorts (disk)1 rows processed6、dump 28号文件277号块
oradebug setmypid
alter system dump datafile 12 block 295;
oradebug close_trace;
oradebug tracefile_name----dump内容如下
data_block_dump,data header at 0x7faefba4f064
===============
tsiz: 0x1f98
hsiz: 0x16
pbl: 0x7faefba4f06476543210
flag=--------
ntab=1
nrow=2
frre=-1
fsbo=0x16
fseo=0xfe0
avsp=0xfc7
tosp=0xfc7
0xe:pti[0] nrow=2 offs=0
0x12:pri[0] offs=0xfe6
0x14:pri[1] offs=0xfe0
block_row_dump:
tab 0, row 0, @0xfe6
tl: 4018 fb: --H-FL-- lb: 0x1 cc: 5
col 0: [ 2] c1 02
col 1: [1000]61 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20
。。省略第一条数据
tab 0, row 1, @0xfe0
tl: 6 fb: --H-FL-- lb: 0x1 cc: 1 -->cc: 1 --FL:说明此时数据行的头和尾都在block内,cc:1,即只有一个字段的数据
col 0: [ 2] c1 032
end_of_block_dump7、修改第二条数据update row_mig_demo set a='a',b='b',c='c',d='d',e='e' where x=2;commit;6、分析表之后发现产生了行迁移
delete from chained_rows;
commit;analyze table row_mig_demo list chained rows into chained_rows;select * from chained_rows where table_name='ROW_MIG_DEMO';
OWNER_NAME TABLE_NAME CLUSTER_NAME
-------------------------------------------------------------------------------------------------------------------------------- -------------------------------------------------------------------------------------------------------------------------------- --------------------------------------------------------------------------------------------------------------------------------
PARTITION_NAME SUBPARTITION_NAME HEAD_ROWID ANALYZE_TIMESTAMP
-------------------------------------------------------------------------------------------------------------------------------- -------------------------------------------------------------------------------------------------------------------------------- ------------------ -------------------
SYS ROW_MIG_DEMON/A AAAR3EAAMAAAAEnAAB 2023-07-01 10:04:217、查看执行计划
SYS@pdb> select * from ROW_MIG_DEMO where x=2;
Execution Plan
----------------------------------------------------------
Plan hash value: 4113747091--------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 5023 | 1 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| ROW_MIG_DEMO | 1 | 5023 | 1 (0)| 00:00:01 |
|* 2 | INDEX UNIQUE SCAN | SYS_C007597 | 1 | | 1 (0)| 00:00:01 |
--------------------------------------------------------------------------------------------Predicate Information (identified by operation id):
---------------------------------------------------2 - access("X"=2)Statistics
----------------------------------------------------------0 recursive calls0 db block gets3 consistent gets -->多扫描了一个块0 physical reads0 redo size5931 bytes sent via SQL*Net to client399 bytes received via SQL*Net from client2 SQL*Net roundtrips to/from client0 sorts (memory)0 sorts (disk)1 rows processed8、再次dump datafile 12 block 295;
oradebug setmypid
alter system dump datafile 12 block 295;
oradebug close_trace;
oradebug tracefile_name--以下是dump关键信息tab 0, row 1, @0xfd7
tl: 9 fb: --H----- lb: 0x2 cc: 0
nrid: 0x03000123.0
end_of_block_dump查看行迁移指向块select dbms_utility.data_block_address_file(to_number(ltrim('0x03000123','0x'),'xxxxxxxx')) file_id,dbms_utility.data_block_address_block(to_number(ltrim('0x03000123','0x'),'xxxxxxxx')) block_id from dual;FILE_ID BLOCK_ID
---------- ----------12 291继续dump datafile 12 block 291
oradebug setmypid
alter system dump datafile 12 block 291;
oradebug close_trace;
oradebug tracefile_name--dump的关键信息
tab 0, row 0, @0xbdd
tl: 5027 fb: ----FL-- lb: 0x1 cc: 6
hrid: 0x03000127.1
col 0: [ 2] c1 03
col 1: [1000]61 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 2020 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20 20
。。。
六、总结:
行迁移和行链接都是影响 Oracle 数据库性能的重要因素。 行迁移主要由 UPDATE 操作引起,而行链接主要由行长度超过块大小引起。 通过合理设计表结构、设置 PCTFREE 参数、定期整理表空间、以及避免频繁更新大字段等措施,可以有效地避免和减少这两种现象,从而提升数据库的性能和稳定性。 同时,定期监控行迁移和行链接的情况,可以帮助我们及时发现潜在问题并采取相应的优化措施。
#Oracle #逻辑结构 #行迁移 #行链接